一、ELK+Filebead+zookeeper+kafka架构

第一层:数据采集层(Filebeat)
- 数据采集层位于最左边的业务服务集群上,在每个业务服务器上面安装了filebead做日志收集,然后把采集到的原始日志发送到kafka+zookeeper集群上。
第二层:消息队列层(kafka+zookeeper集群)
- 原始日志发送到kafka+zookeeper集群上后,会进行集中存储,此时filebead是消息的生产者,存储的消息可以随时被消费。
第三层:数据分析层(Logstash)
- logstash作为消费者,回去kafka+zookeeper集群节点时实拉去原始日志,然后将获取到的原始日志根据规则进行分析、格式化处理,最后将格式化的日志转发至Elasticsearch集群中。
第四层:数据持久化存储(Elasticsearch集群)
- Elasticsearch集群接收到logstash发送过来的数据后,执行写入磁盘,建立索引等操作,最后将结构化数据存储到Elasticsearch集群上。
第五层:数据查询,展示层(kibana)
- kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析.
二、部署实验
| 主机名 | ip地址 | 所属集群 | 安装软件包 |
|---|---|---|---|
| filebead | 192.168.247.20 | 数据采集级层 | filebead+apache |
| kafka1 | 192.168.247.21 | kafka+zookeeper集群 | kafka+zookeeper |
| kafka2 | 192.168.247.22 | kafka+zookeeper集群 | kafka+zookeeper |
| kafka3 | 192.168.247.23 | kafka+zookeeper集群 | kafka+zookeeper |
| logstash | 192.168.247.60 | 数据处理层 | logstash |
| node1 | 192.168.247.70 | ES集群 | Eslasticsearch+node+phantomis+head |
| node2 | 192.168.247.80 | ES集群+kibana展示 | Elasticsearch+node+phantomis+head+kibana |
1、安装kafaka+zookeeper集群(192.168.247.21、192.168.247.22、192.168.247.23)
1.1 安装zookeeper集群
- 关闭防火墙和安全机制
- 下载安装依赖环境
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
- 安装软件
- 修改配置文件
方法一:下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
方法二:或者直接将软件包上传到/opt目录下。
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
修改配置文件
cd /usr/local/zookeeper-3.5.7/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数( tickTime的数量),这里表示为10*2s
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data
#●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/1ogs
#●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.247.21:3188:3288
server.2=192.168.247.22:3188:3288
server.3=192.168.247.23:3188:3288
- 拷贝配置好的 Zookeeper 配置文件到其他机器上
- 在每个节点上创建数据目录和日志目录
- 设置三台机器的myid
//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.247.22:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.247.23:/usr/local/zookeeper-3.5.7/conf/
//在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
- 配置 Zookeeper 启动脚本
- 设置开机自启
- 分别启动 Zookeeper
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
//分别启动 Zookeeper
service zookeeper start
//查看当前状态
service zookeeper status
1.2 部署 kafka 集群
- 安装软件
- 修改配置文件
方法一:下载安装包
官方下载地址:http://kafka.apache.org/downloads.html
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
方法二:或者直接将软件包上传到/opt目录下。
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka- kafka1配置文件修改
//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置
listeners=PLAINTEXT://192.168.247.21:9092 ●31行,指定监听本机的IP和端口
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
zookeeper.connect=192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 ●123行,配置连接Zookeeper集群地址- kafka2配置文件修改
//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=1 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置
listeners=PLAINTEXT://192.168.247.22:9092 ●31行,指定监听本机的IP和端口
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
zookeeper.connect=192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 ●123行,配置连接Zookeeper集群地址- kafka3配置文件修改
//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=2 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置
listeners=PLAINTEXT://192.168.247.23:9092 ●31行,指定监听本机的IP和端口
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
zookeeper.connect=192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 ●123行,配置连接Zookeeper集群地址- 修改环境变量
- 配置 Zookeeper 启动脚本
- 设置开机自启,分别启动 Kafka
//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//分别启动 Kafka
service kafka start
//查看端口
netstat -antp |grep 9092
1.2.1 Kafka 命令行操作
创建topic
kafka-topics.sh --create --zookeeper 192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 --replication-factor 2 --partitions 3 --topic test
#--zookeeper:定义zookeeper集群服务器地址,如果有多个ip以逗号分隔。
#--replication-factor:定义分区副本,1代表但副本,建议为2
#--partitions: 定义分区数
#--topic :定义topic名称
查看当前服务器中的所有topic
kafka-topics.sh --list --zookeeper 192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181发布消息
kafka-console-producer.sh --broker-list 192.168.247.21:9092,192.168.247.22:9092,192.168.247.23:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.247.21:9092,192.168.247.22:9092,192.168.247.23:9092 --topic test --from-beginning
#--from-beginning:会把主题中以往所有的数据都读取出来
修改分区数
kafka-topics.sh --zookeeper 192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 --alter --topic test --partitions 6
删除 topic
kafka-topics.sh --delete --zookeeper 192.168.247.21:2181,192.168.247.22:2181,192.168.247.23:2181 --topic test
2、部署Filebead(192.168.247.20)
- 关闭防火墙
- 安装httpd服务,并启动
systemctl stop firewalld.service
setenforce 0
//安装httpd服务
yum -y install httpd
systemctl start httpd.service - 安装 Filebeat
- 设置 filebeat 的主配置文件
安装 Filebeat
#上传软件包 filebeat-6.6.0-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.6.0-linux-x86_64.tar.gz
mv filebeat-6.6.0-linux-x86_64/ /usr/local/filebeat
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
vim filebeat.yml
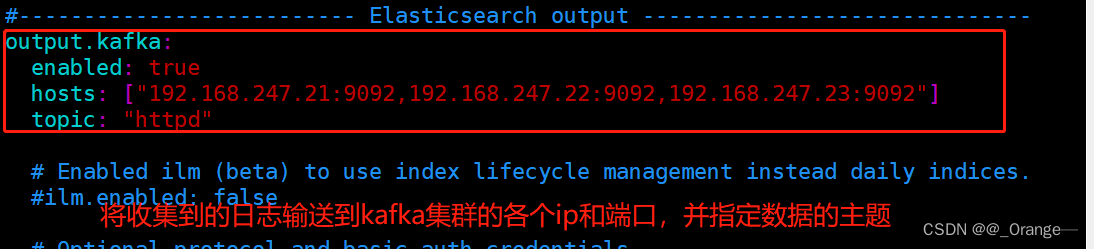
- 启动服务
./filebeat -e -c filebeat.yml3、部署ES服务(192.168.247.70 192.168.247.80)
3.1 安装JDK
java -version #如果没有安装,yum -y install java
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)3.2 安装ES服务
配置本地解析,上传安装包安装并启动
配置本地解析
echo "192.168.247.70 node1" >> /etc/hosts
echo "192.168.247.80 node2" >> /etc/hosts
#上传elasticsearch-5.5.0.rpm到/opt目录下
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm
#加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service
修改配置文件
#修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]查看配置文件,创建数据目录
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
(4)创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
(5)启动elasticsearch是否成功开启
systemctl start elasticsearch.service
netstat -antp | grep 92003.3 安装 Elasticsearch-head 插件
编译安装node
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make && make install
安装 phantomjs(前端的框架)
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有
//重启es
systemctl restart elasticsearch
启动 elasticsearch-head 服务
cd /usr/local/src/elasticsearch-head/
npm run start &
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100
3.4 Kiabana 部署
1.安装 Kiabana
#上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
2.设置 Kibana 的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.247.70:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
3.启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601
4、部署logstash(192.168.247.60)
- 安装Java环境
- 安装logstash
//安装Java环境
yum -y install java
java -version
//安装logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/- 在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d/
vim kafka.conf
input {
kafka {
bootstrap_servers => "192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092" #kafka集群地址
topics => "httpd" #拉取的kafka的指定topic
type => "httpd_kafka" #指定 type 字段
codec => "json" #解析json格式的日志数据
auto_offset_reset => "latest" #拉取最近数据,earliest为从头开始拉取
decorate_events => true #传递给elasticsearch的数据额外增加kafka的属性数据
}
}
output {
if "access" in [tags] {
elasticsearch {
hosts => ["192.168.10.15:9200"]
index => "httpd_access-%{+YYYY.MM.dd}"
}
}
if "error" in [tags] {
elasticsearch {
hosts => ["192.168.10.15:9200"]
index => "httpd_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
#启动 logstash
logstash -f kafka.conf
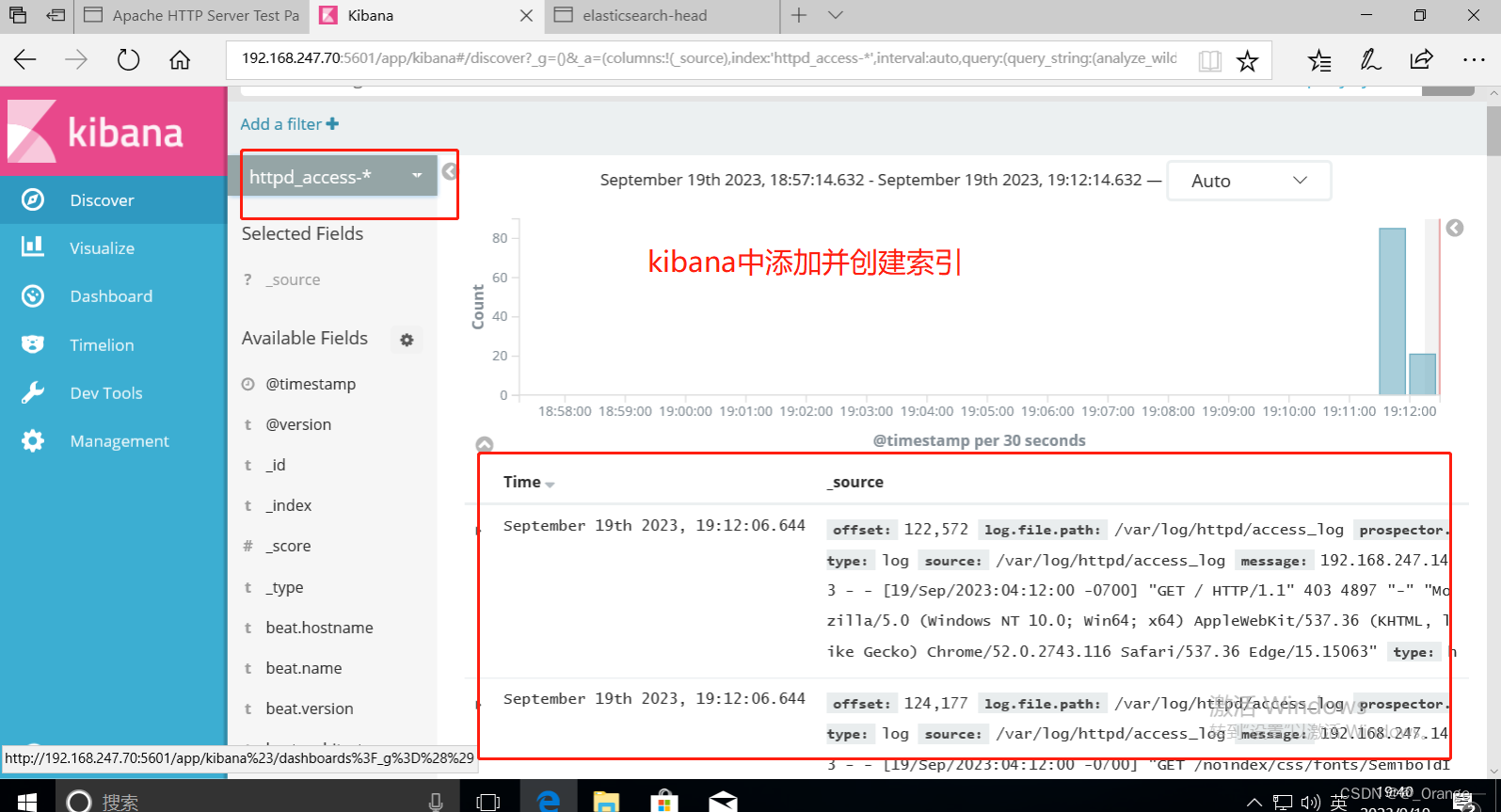
三、验证
访问192.168.247.20 apache,生成日志