OpenKG

大模型专辑
导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期特别邀请到东南大学漆桂林教授、南京柯基数据科技有限公司杨成彪(CTO)和吴刚(CEO)等分享“知识图谱和大语言模型的共存之道”。
分享嘉宾 | 漆桂林(东南大学),杨成彪(南京柯基数据科技有限公司),吴刚(南京柯基数据科技有限公司)
笔记整理 | 邓鸿杰(OpenKG)
自从2022年11月30日OpenAI公司推出ChatGPT以来,大语言模型(Large Language Model)受到了学术界和业界的广泛关注,由于ChatGPT在语言理解和知识问答方面的优异表现,大语言模型被认为具备记忆和应用世界知识(world knowledge)的能力,这就使得有一些观点认为另外一种世界知识的表示和推理模型知识图谱(Knowledge Graph)将要被以ChatGPT为代表的大语言模型所取代。关于知识图谱是否会被大模型取代这个话题,已经有一些学者做出过回应[Yang 2023] [Pan 2023] [Suchanek 2023],同时也有一些评测论文讨论ChatGPT和GPT4的知识问答能力[Tan 2023]。为了更好地理解大模型跟知识图谱的关系,我们需要先了解一下大语言模型和知识图谱的历史,然后我们讨论一下大语言模型和知识图谱作为知识库(Knowledge Base)的优缺点,从而得出大语言模型和知识图谱不是互相替代,而是相互依存的关系这一结论,最后我们讨论大语言模型和知识图谱如何从知识库服务平台的角度融合。
01
知识图谱和大语言模型的历史
回顾人工智能的历史我们会发现,知识图谱和大语言模型有着极深的渊源。知识图谱来源于语义网络(Semantic Network)[Sowa, 1991],而大语言模型是来源于神经网络(Neural Network)[Anderson 1995],两种都是基于图的表示方法。一般认为,以知识图谱为代表的符号化知识表示方法更适合表示需要精确化描述的知识和支撑需要可靠而且完备的推理(这一学派被称为符号主义),而以神经网络为代表的参数化知识表示方法更适合表示非精确描述的知识和进行非精确的推理(这一学派被称为连接主义)。

图1
那么什么是知识呢,根据牛津字典,知识是通过经历或者教育获取的事实、信息或者技巧或者技巧。举例来说,“南京位于江苏”是一类事实性知识,新闻文本是一类描述性知识,而开酒瓶的技能是一类技能类知识。人类可以通过视觉、语言、教育或者实践和推理等方式获取知识。
知识图谱是一种采用图模型(即由点和线组成的图形)来对人类知识进行表示的知识库或者知识的集合。

图2
比如说<南京, 位于, 江苏>就是一条知识,对应到图谱中就是以南京和江苏为节点,位于为标签的边。
神经网络可以用于存储知识,但是这类知识是以参数的形式存在于神经网络,无法直观看到。
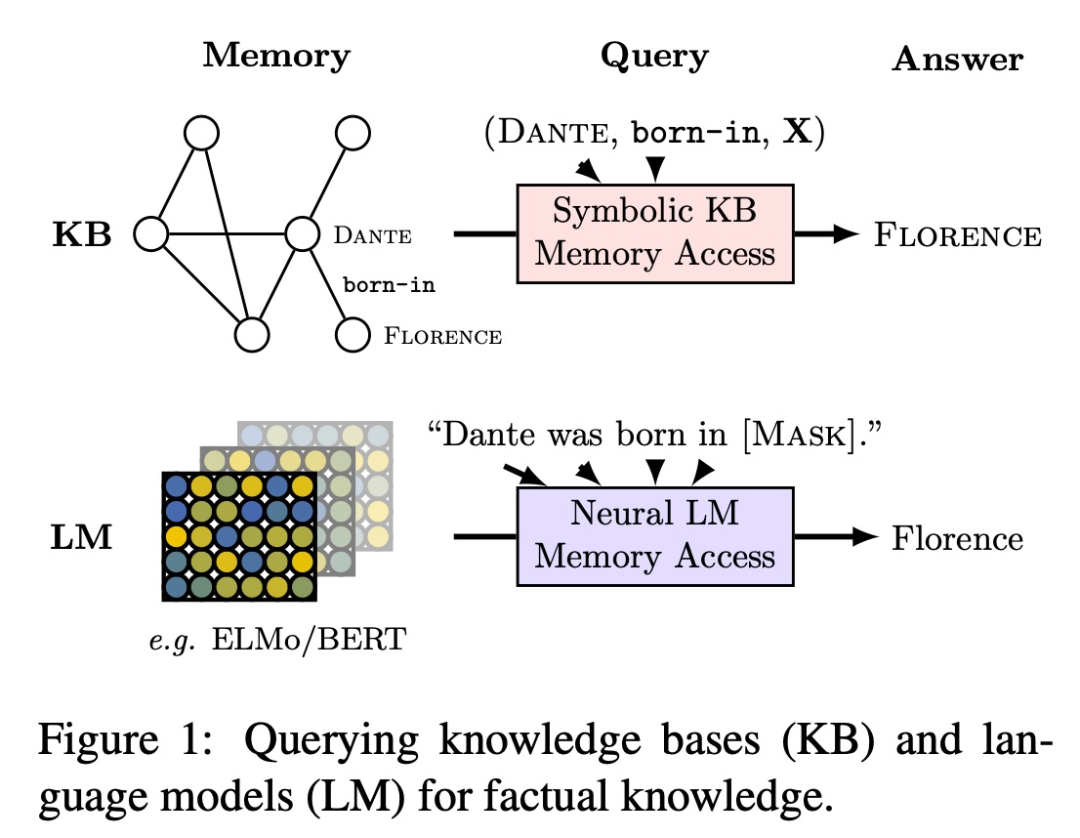
图3
在文献[Petroni 2019]中,作者提出了一个观点,即语言模型可以作为知识库(Language Model as Knowledge Bases),并且给出了一个从语言模型中提取事实性知识的方法(见图3)。更多语言模型作为知识库的工作综述可以参考[AlKhamissi 2022]。

图4
图4给出了知识图谱的历史发展,可以看出,知识图谱是起源于语义网络,并且跟语义网(Semantic Web)有着极深的渊源。知识图谱采取了语义网络的图表示方法,同时参考了语义网的标准化语言RDF和OWL,从而具有严格的逻辑语义支撑,可以确保从知识图谱中查询得到的结果是正确的。同时知识图谱可以跟专家系统中的规则引擎结合用于企业应用中的决策支持类任务。

图5
再来看看大模型的历史发展, 1958年Rosenblatt提出了感知机,从而为神经网络的发展奠定了基础,但是由于感知机无法解决异或(XOR)等线性不可分问题,导致神经网络的研究不受重视。80年代,随着多层感知机和反向传播算法的应用,神经网络开始得到快速发展,并且跟专家系统一起使得人工智能进入了一个高潮时期。1998年和2012年LSTM和AlexNet的提出让神经网络具备了更好的实用性,特别是AlexNet在ImageNet 大规模视觉识别挑战赛取得优异成绩,AlexNet的成功引领了深度学习的浪潮。2017年,基于注意力机制的的深度神经网络模型Transformer被提出,并且很快就在自然语言处理和计算机视觉中被广泛应用。Transformer开启了预训练模型的大门,之后2018年BERT和GPT-1都是基于Transformer提出的预训练语言模型,而GPT-1最终演化成了GPT-3,ChatGPT和GPT-4。
纵观知识图谱和大语言模型的发展历史,我们可以发现,以知识图谱为代表的符号主义和以ChatGPT为代表的连接主义在人工智能的发展历史上具有举足轻重的地位。人工智能的三次发展高潮,都是跟符号主义和连接主义同时发力有关,即第一次人工智能发展高潮中的感知机和语义网络,第二次人工智能发展高潮中的多层神经网络和专家系统,第三次人工智能发展高潮中的深度学习(以及之后的大语言模型)和知识图谱。
02
知识图谱和大语言模型作为知识库的优缺点
知识图谱和大语言模型都可以作为知识库,并且都可以通过自然语言方式进行访问,但是两者在知识表示方面的差异使得它们在知识检索和查询、知识可视化、知识推理支持等方面有较大差异。下面就从知识问答的角度来分析一下知识图谱和大语言模型的优缺点。
1、从问答的形式来看,知识图谱和大语言模型都支持自然语言的方式进行查询,但是存在以下差异:
(1)基于知识图谱的问答系统对于自然语言问句的解析存在困难,这是因为需要先将自然语言问句转化成一个结构化查询语言,即SPARQL,但是现有的算法在做转化的时候需要大量的标注数据进行训练,从而很难应对用户千变万化的问法。
(2)大语言模型不仅仅是一个知识库,还是一个神经网络模型,所以可以直接对自然语言进行理解,将一个自然语言问句进行解析并且自动生成答案,在这个过程中基本上不需要人类的参与,所以大语言模型在问答形式方面泛化能力更强,语言解析能力更强,用户体验更好。
2、从知识库包含的知识量来看,现有的知识图谱虽然包含了大规模的常识和领域知识,但是规模跟大模型相比不是一个数量级。比如说,著名的大规模开放知识图谱WikiData[Tanon 2016]目前包含的三元组数量级为亿级别,主要的知识来源是维基百科的Inforbox和一些半结构化数据,互联网和各种书籍、论文中包含的文本数据并没有有效利用起来,这是因为知识图谱的构建需要做好质量控制,而采取信息抽取的方法从开放域抽取结构化知识往往质量低下,所以WikiData的数据来源主要还是结构化和半结构化数据,这就使得WikiData的知识量跟ChatGPT这样的大语言模型相比要小很多。
3、从知识的质量来看,知识图谱的构建有一套严格的质量控制流程,首先,现有企业知识图谱构建大部分是基于数据库的结构化数据,这些数据经过了大数据平台处理后质量非常高,再经过知识图谱平台可以在保持质量的情况下转成大规模知识图谱,对于非结构化数据,随着信息抽取技术的进步,从文本、图像、视频中抽取三元组数据的质量比较高,再经过众包等方式对抽取后的知识进行加工才能进入知识库,所以企业知识图谱的质量是有保障的。其次,对于开放的知识图谱,比如说WikiData,绝大多数的知识来源于维基百科的Infobox以及人类编辑,在此基础上还有利用规则和冲突检测方法来进一步提高知识图谱质量的技术[Tanon 2019]。相比而言,以ChatGPT为代表的大语言模型虽然在知识数量级上超过了大规模知识图谱,但是知识库的质量是一个大问题,这是因为大语言模型的知识获取过程是一个黑盒方式,容易受到训练语料质量的影响,即便是通过人类反馈技术(如RLHF[Ouyang 2022])和知识编辑[Cao 2021]技术提升质量,由于大语言模型的黑盒属性,整体质量相比大规模知识图谱有一定差距。
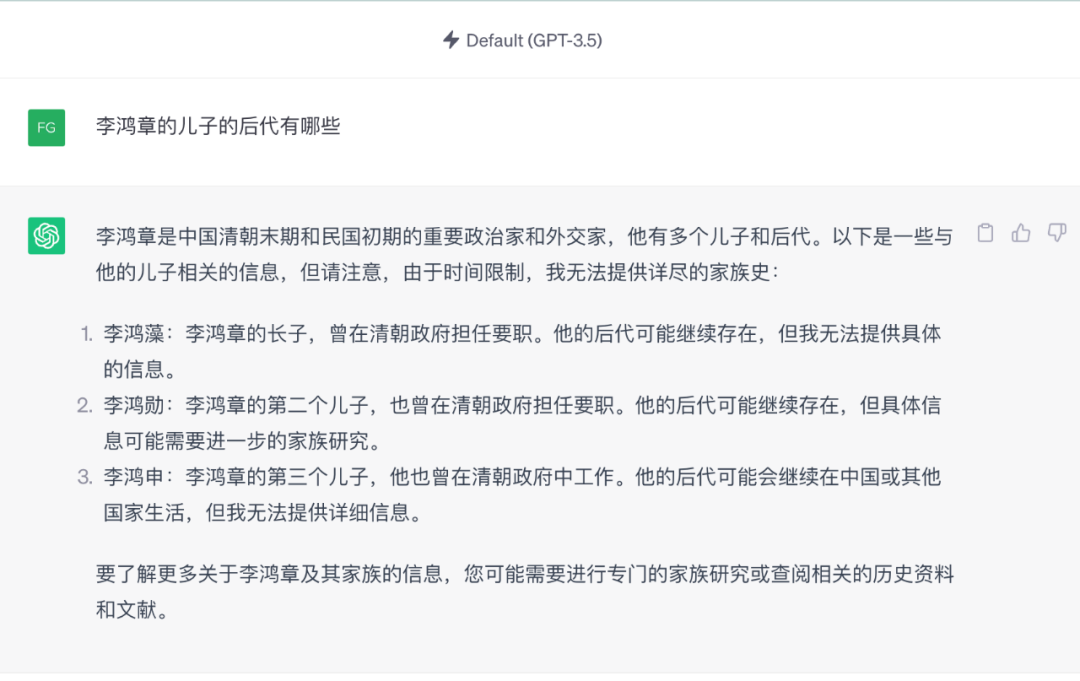
图6
在百科中已有的一些知识,通过知识图谱很容易得出正确的回答,但是对于大模型来说要准确学到则是非常困难。如图6所示,当提问ChatGPT“李鸿章的儿子的后代有哪些“,给出的回答是错误的,但是,如果我们有一个包含李鸿章的人物图谱,那么基于知识图谱的问答系统可以给出正确的答案,并且给出可视化的解释(见图7)。
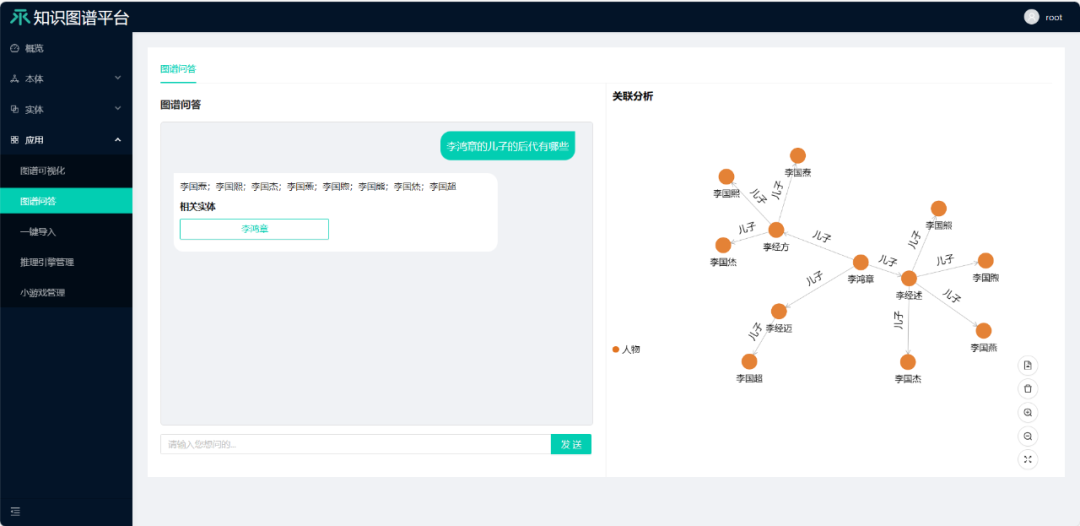
图7
4、从知识问答的准确性和可解释性来看,基于知识图谱的问答系统虽然在语言解析的泛化性方面不如大语言模型,而且由于知识量的限制,很多问题无法回答,但是在知识问答的准确性方面要优于大语言模型。文献[Tan 2023]给出了基于知识图谱的问答系统和大语言模型的一个详细对比,在这个论文中,我们评估了ChatGPT及其LLM家族在八个真实世界基于KB的复杂问题回答数据集上的表现,其中包括六个英文数据集和两个多语言数据集,测试用例的总数约为190,000。为了凸显测试问题的复杂性和测试数据集的广泛性,在仔细考虑后,我们选择了六个代表性的英文单语KBQA数据集和两个多语言KBQA数据集进行评估。这些数据集包括经典数据集,如WebQuestionSP [51],ComplexWebQuestions [43],GraphQ [42]和QALD-9 [24],以及新提出的数据集,如KQApro [5],GrailQA [12]和MKQA [22]。由于OpenAI API的限制,我们对一些数据集进行了抽样,如按答案类型抽样的MKQA和仅使用测试集的GrailQA。
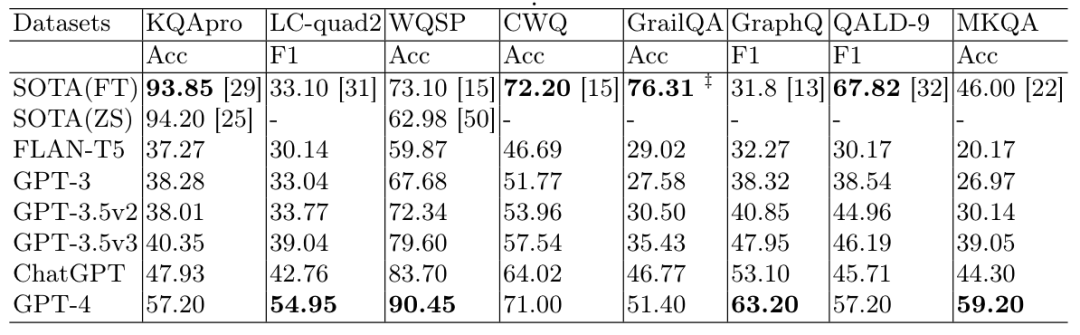
表1
表1中呈现了总体结果。首先,单语QA测试中,GPT-4模型在2018年之前的数据集上的表现基本优于传统SOTA模型,但在2018年后的新数据集上相比传统KBQA模型还有显著差距。多语言QA测试中,经典数据集QALD-9的SOTA模型显著优于LLM,但2021年提出的MKQA数据集上,GPT-4则实现了对SOTA模型的显著超越。其次,比较GPT家族中的模型,新模型的性能如预期般优于前一代。
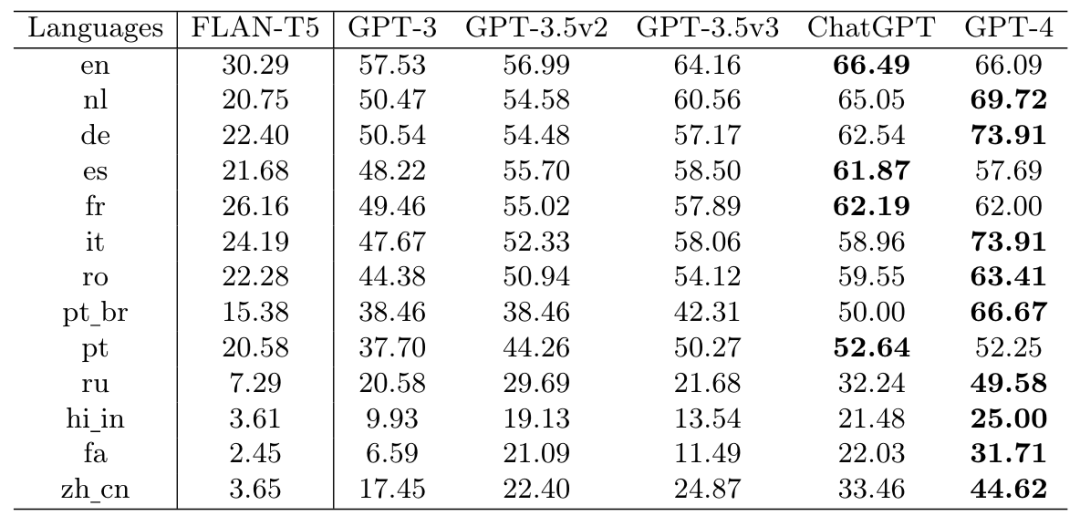
表2
我们在表2中进一步呈现了LLMs在多语言QA上的性能。尽管随着GPT家族持续迭代,模型回答不同语言问题的能力呈现出整体上的改善趋势,但我们观察到GPT-4在四种语言上均未超过ChatGPT。这表明GPT的多语言能力的演变可能开始放缓。
5、从知识更新的角度来看,由于知识图谱采用了图的表示,知识更新可以通过图上的节点和边的插入、删除和修改操作完成,难点在于如何检测到新的插入节点,节点插入到图中哪个位置,插入后是否会导致逻辑冲突等[Qi 2015] [Wu 2020],这些符号化的操作比较直观,而且可以利用逻辑推理机来辅助,从而确保更新后图谱的质量可以得到保障。相比而言,大语言模型在知识更新方面的能力一直被诟病,比如说ChatGPT刚刚出来的时候,只能回答2021年之前的知识类问题,因为ChatGPT没有采用2021年之后的数据进行训练,而用新的数据训练成本非常高。跟知识图谱采取图操作相比,对大语言模型进行更新需要耗费大量的服务器资源,如果是频繁更新,大语言模型付出的代价远远超过知识图谱。
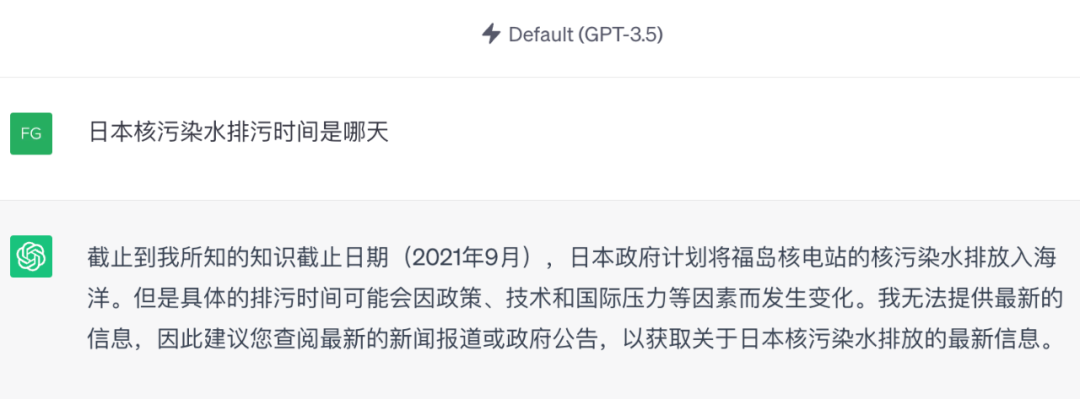
图8
图8给出了一个ChatGPT对最新发生的一个事件的示例,从这个示例可以看出,ChatGPT对于新发生的事是没有更新的,而且到现在还会提到自己所知的知识截止2021年9月。但是,如果采用知识图谱平台,这一问题可以得到精确回答,而且可以给出可视化解释。值得注意的是,知识图谱的更新成本要远远低于大语言模型的更新成本。
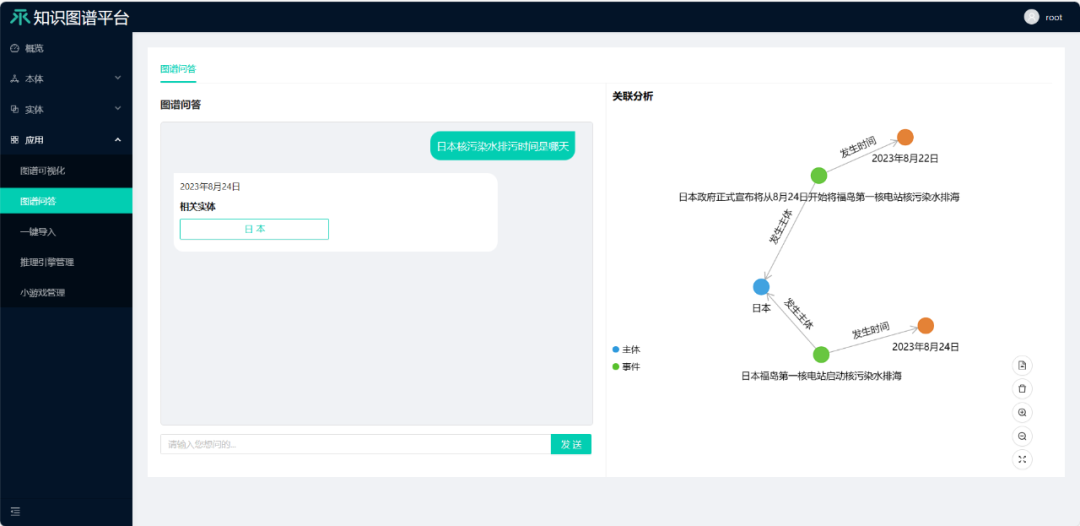
图9
03
知识图谱和大语言模型双知识平台融合
根据前面的讨论我们知道,知识图谱和大语言模型都可以看出是知识库,前者是符号化的知识库,而后者则是参数化的知识库,一个自然的问题就是,这两种知识库怎么融合。有一些工作从知识图谱和大语言模型技术角度对知识图谱和大语言模型如何进行融合进行了讨论[Pan 2023] [陈2023],下面我们从知识图谱平台的角度来讨论知识图谱跟大语言模型如何融合。
首先,知识图谱平台如何增强大语言模型平台呢?
知识图谱平台可以通过人机交互创建和推理高质量知识(比如说处理知识的逻辑冲突),并且通过知识增强的方法用于增强大语言模型。
知识图谱平台可以表示和生成思维链,通过结构化更好的思维链提升大模型的推理能力。
知识图谱平台可以用于解决大模型不擅长解决的问题,比如说上下文知识遗忘、复杂知识推理、知识可视化、关联分析和决策类任务。
其次,大语言模型平台如何增强知识图谱平台呢?
大语言模型作为一种基础模型,为知识图谱平台的知识获取自动化提供了有效的解决方案。
知识图谱的表示学习和推理(比如说KG embedding和部分的ontology reasoning)可以基于大模型完成,即知识图谱的表示学习和大语言模型的表示学习互相增强。
本体和规则的学习可以通过大模型平台实现高度自动化(还是需要引入人机交互来更好实现)。
最后,知识图谱平台和大语言模型平台如何协同完成复杂知识处理任务?
大语言模型平台可以利用知识图谱平台生成的符号化知识对企业中的各种知识进行集成,对大语言模型平台的指令进行分解,完成复杂任务(比如说微软Office 365 Copilot)。
知识图谱平台和大语言模型平台协同完成复杂问题的知识问答,这里可以发挥大语言模型的语义理解能力和知识量大的优势,同时发挥基于知识图谱的问答系统的知识精确性和答案可解释性的优势。
知识图谱平台用于沉淀大模型平台中任务驱动的关键知识,用于完成需要精确、可解释的问答和行动。
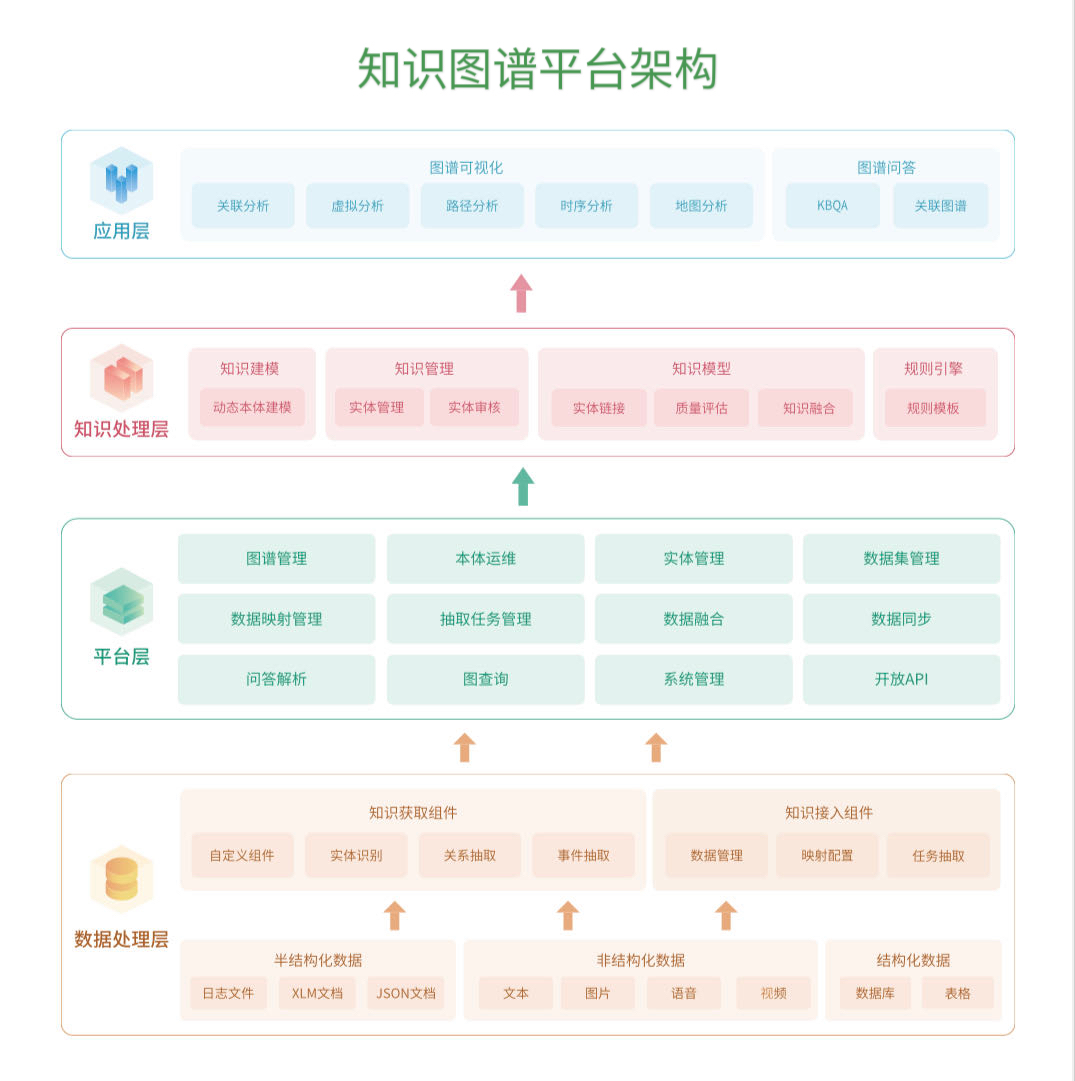
图10
图10给出了一个知识图谱平台的架构图,包括数据处理层、平台层、知识处理层和应用层。数据处理层利用知识获取组件和知识接入组建处理结构化、半结构化和非结构化数据,形成三元组知识;平台层对数据和知识进行运维和管理(数据融合、运维和任务管理);知识处理层对数据处理层和平台层处理的知识进行质量评估和知识融合;应用层则是利用知识图谱来支撑各种应用,比如说关联分析和智能问答。
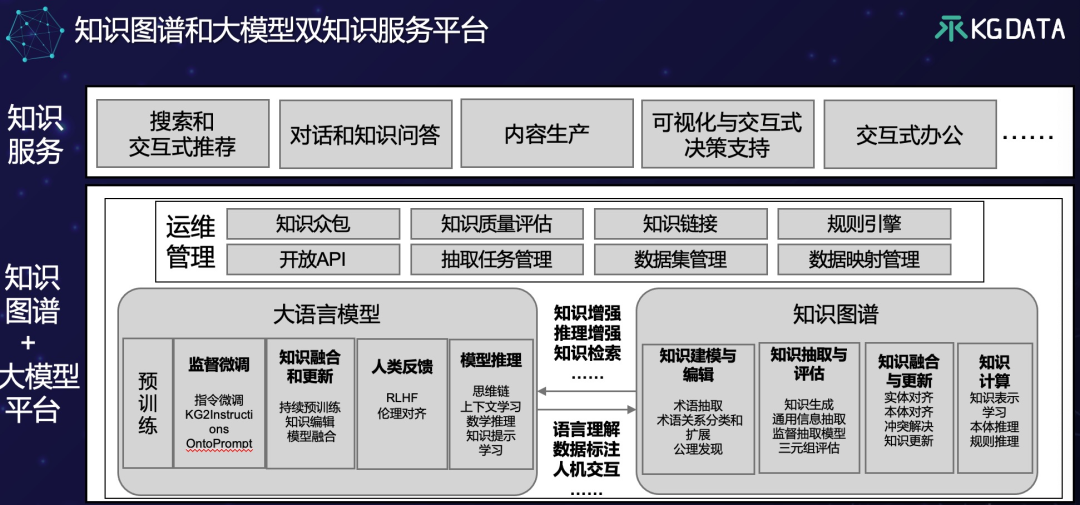
图11
参考图10的知识图谱平台设计,图11给出了我们设计的一个知识图谱和大语言模型融合的双知识服务平台架构。从这个架构中我们可以清晰地看出大语言模型跟知识图谱的核心技术具有惊人的相似性:大语言模型的预训练跟知识图谱的知识建模相似,都需要人工整理和理解数据,但是也可以通过某种自动化方式提升效率;监督微调跟知识抽取对应,都是用于从数据中提取知识,只不过大语言模型利用微调提取的知识存储与神经网络;大语言模型跟知识图谱一样需要做知识更新和融合,大语言模型的推理对应于知识图谱的知识计算。另外,大模型和知识图谱都需要考虑知识管理,而且都需要考虑知识众包、知识质量评估、知识链接等。
从图11还可以看出,知识图谱构建成本可以通过大语言模型得到极大的降低,大语言模型可以提升知识自动建模的效率(具体方法可以参考[Giglou 2023]),可以为知识抽取生成标注数据,利用大语言模型的知识理解能力,可以设计通用信息抽取方法,利用一个模型抽取实体、关系、属性值、事件,大语言模型还可以做零样本知识生成,利用通用信息抽取得到的三元组,通过人工校对形成大标注数据还可以用于训练监督模型,大语言模型可以有助于提升知识融合的自动化[Zhang 2023]与冲突解决[Wang 2023],并且大模型可以有助于知识图谱的知识表示学习[Pan 2023]。另外,知识图谱可以为大语言模型提供语料生成,Prompt增强和推理增强。
反之,知识图谱可以为大语言模型提供知识增强、推理增强和知识检索等能力提升。在监督微调阶段,可以通过KG2Instruction技术将知识图谱的转化成指令用于微调,还可以通过OntoPrompt将本体用于提示微调[Ye 2022];在知识融合和更新阶段,可以通过知识图谱的三元组对大语言模型进行编辑从而实现知识更新[Cao 2021],并且可以将大语言模型跟知识图谱通过表示学习进行融合[Nayyeri 2023],以及将一个大模型的知识迁移给另外一个大模型[Choi 2022];在模型推理阶段,可以通过知识图谱生成提示[Chen 2022]或者指令[Du, 2022]用于增强模型的推理能力。
大语言模型和知识图谱作为知识库都需要运维管理,两者都会涉及到API开放、数据管理和知识质量评估。如何评估一个大模型的内容生成质量,关系到大模型能否落地[Chang 2023],而知识图谱有比较完善的质量控制体系[Wang 2021]。另外,大语言模型和知识图谱的管理都涉及到知识众包的工作,从而提升模型训练的质量和知识图谱构建的质量。
04
总结与展望
大语言模型的出现打开了通用人工智能的大门,而且令人惊叹的是,大语言模型学习了人类的知识,并且可以利用这些知识来解决问题。人工智能发展到现在,一直想做的事就是让机器能够跟人类一样学习海量知识,这就是“知识工程”提出的目标,之后知识工程专家们孜孜不倦地努力构建了不少“大规模”知识库,比如说wordnet, wikidata,这些开放知识库对于人工智能的成功起到了很好的促进作用,但是还不是实际意义的大知识,而以ChatGPT为代表的大语言模型的出现改变了这个现状。但是大语言模型作为一个知识库存在很多问题,比如说知识质量问题、问答精确度不足和不可解释问题,如果跟知识图谱或者其他符号化知识结合,将有无限想象空间,人工智能将进入真正的大知识时代。为了实现这一目标,我们认为融合知识图谱平台和大语言模型平台势在必行,并且基于一个已经落地的知识图谱平台架构,提出了一个可能的知识图谱和大语言模型的融合框架,希望可以对新一代知识工程的发展起到一点微薄之力。
参考文献
[Anderson 1995] James A. Anderson, An Introduction to Neural Networks, The MIT Press,1995.
[AlKhamissi 2022] Badr AlKhamissi, A Review on Language Models as Knowledge Bases,arXiv:2204.06031 [cs.CL],2022.
[陈2023] 陈华钧. 大模型时代的知识图谱技术栈. 中国计算机学会通讯. 19卷9期. 2023。
[Chang 2023] Yupeng Chang, et.al., A Survey on Evaluation of Large Language Models, arXiv:2307.03109 [cs.CL], 2023.
[Chen 2022] Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, Huajun Chen: KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction. WWW 2022: 2778-2788
[Choi 2022] Dongha Choi, HongSeok Choi, Hyunju Lee, Domain Knowledge Transferring for Pre-trained Language Model via Calibrated Activation Boundary Distillation, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022.
[Cao 2021] Nicola De Cao, Wilker Aziz, Ivan Titov, Editing Factual Knowledge in Language Models, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021.
[Du, 2022] Haowei Du, et.al., Knowledge-Enhanced Iterative Instruction Generation and Reasoning for Knowledge Base Question Answering, In Proceeding of 2022 CCF International Conference on Natural Language Processing and Chinese Computing (NLPCC), 2022.
[Giglou 2023] Hamed Babaei Giglou,et.al., LLMs4OL: Large Language Models for Ontology Learning, arXiv:2307.16648 [cs.AI], 2023.
[Nayyeri 2023] Mojtaba Nayyeri, et.al. Integrating Knowledge Graph embedding and pretrained Language Models in Hypercomplex Spaces, In Proceedings of the 22nd International Semantic Web Conference (ISWC), 2023.
[Ouyang 2022] Long Ouyang, et al, Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
[Pan 2023] Shirui Pan, et.al., Unifying Large Language Models and Knowledge Graphs: A Roadmap, arXiv:2306.08302 [cs.CL], 2023.
[Petroni 2019] Fabio Petroni, et.al., Language Models as Knowledge Bases? Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019.
[Qi 2015] Guilin Qi, Zhe Wang, Kewen Wang, Xuefeng Fu, Zhiqiang Zhuang: Approximating Model-Based ABox Revision in DL-Lite: Theory and Practice. Proceedings of the 29th Conference on Artificial Intelligence (AAAI), 254-260, 2015.
[Suchanek 2023] Fabian M. Suchanek, Anh Tuan Luu, Knowledge Bases and Language Models: Complementing Forces, Proceeding of International Joint Conference on Rules and Reasoning (RuleML+RR), 2023.
[Sowa, 1991] J. F. Sowa: Principles of Semantic Networks: Exploration in the Representation of Knowledge, Morgan Kaufmann Publishers, INC. San Mateo, California, 1991.
[Tan 2023] Yiming Tan, et.al., Can ChatGPT Replace Traditional KBQA Models? An In-depth Analysis of the Question Answering Performance of the GPT LLM Family, Proceedings of the 22nd International Semantic Web Conference (ISWC), 2023.
[Tanon 2016] Thomas Pellissier Tanon, Denny Vrandecic, Sebastian Schaffert, Thomas Steiner, Lydia Pintscher: From Freebase to Wikidata: The Great Migration. Proceedings of 25th International World Wide Web Conference (WWW), 1419-1428, 2016
[Tanon 2019] Thomas Pellissier Tanon, Camille Bourgaux, Fabian M. Suchanek:
Learning How to Correct a Knowledge Base from the Edit History. Proceedings of 28th International World Wide Web Conference (WWW), 1465-1475, 2019.
[Wang 2021] Xiangyu Wang, et.al., Knowledge graph quality control: A survey, Fundamental Research, Vol.1(5), 2021.
[Wang 2023] Keyu Wang, et.al., An Embedding-based Approach to Inconsistency-tolerant Reasoning with Inconsistent Ontologies, arXiv:2304.01664 [cs.AI], 2023.
[Wu 2020] Tianxing Wu, Haofen Wang, Cheng Li, Guilin Qi, Xing Niu, Meng Wang, Lin Li, Chaomin Shi: Knowledge graph construction from multiple online encyclopedias. World Wide Web 23(5): 2671-2698 (2020)
[Yang 2023] Linyao Yang, et.al., ChatGPT is not Enough: Enhancing Large Language Models with Knowledge Graphs for Fact-aware Language Modeling, arXiv:2306.11489 [cs.CL], 2023.
[Ye 2022] Hongbin Ye,et.al., Ontology-enhanced Prompt-tuning for Few-shot Learning. Proceedings of the ACM Web Conference (WWW), 778-787, 2022.
[Zhang 2023] Rui Zhang, et.al., AutoAlign: Fully Automatic and Effective Knowledge Graph Alignment enabled by Large Language Models, arXiv:2307.11772 [cs.IR], 2023.
以上就是本次分享的内容,谢谢。


作者简介
INTRODUCTION

漆桂林

漆桂林,东南大学教授,博士生导师,东南大学认知智能研究所所长,获得江苏省六大人才高峰计划资助。现任中国中文信息学会语言与知识计算专业委员会副主任和中国科学技术情报学会知识组织专业委员会副主任。是澳大利亚Griffith大学访问教授(2011年11月-2012年2月和2013年6月-2013年7月)和法国图卢兹第一大学访问教授(2013年1月-2013年2月)。1998年毕业于宜春学院数学专业,2002年获得江西师范大学数学与信息系硕士学位,2006年获得英国贝尔法斯特女皇大学计算机博士学位。2006年8月至2009年8月在德国Karlsruhe大学AIFB研究所做博士后研究。

作者简介
INTRODUCTION

杨成彪

杨成彪,南京柯基数据CTO,东南大学人工智能方向博士,知识图谱和自然语言处理技术专家。申请知识图谱、深度学习相关发明专利十余项。在人工智能和大数据行业10年的产品研发经验,成功研发多款现象级AI产品,荣获了“江苏省优秀人工智能产品金奖”、“十佳优秀人工智能软件产品”等奖项。

作者简介
INTRODUCTION

吴刚

吴刚,南京柯基数据CEO。中国人民大学信息学院硕导,毕业于中科院软件所,人机交互与智能信息处理专业。现担任中华预防医学会慢性病预防与控制分会委员,中国生物医药产业链创新与转化联盟医药情报专委会副主委,中文信息学会语言与知识计算专业委员会委员,医疗健康与生物信息专委委员,中国卫生信息与健康医疗大数据学会委员。曾在全球领先的医药和科技、金融信息服务商汤森路透担任中国首席顾问,负责产品解决方案咨询工作。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。