Python爬虫技术系列-01请求响应获取-urllib库
- 1 urllib库
- 1.1 urllib概述
- 1.1.1 urllib简介
- 1.1.2 urllib的robotparser模块
- 1.1.3 request模块
- 1.1.4 Error
- 1.1.5 parse模块
- 1.2 urllib高级应用
- 1.2.1Opener
- 1.2.2 代理设置
1 urllib库
参考连接:
https://zhuanlan.zhihu.com/p/412408291
1.1 urllib概述
1.1.1 urllib简介
Urllib是python内置的一个http请求库,不需要额外的安装。只需要关注请求的链接,参数,提供了强大的解析功能
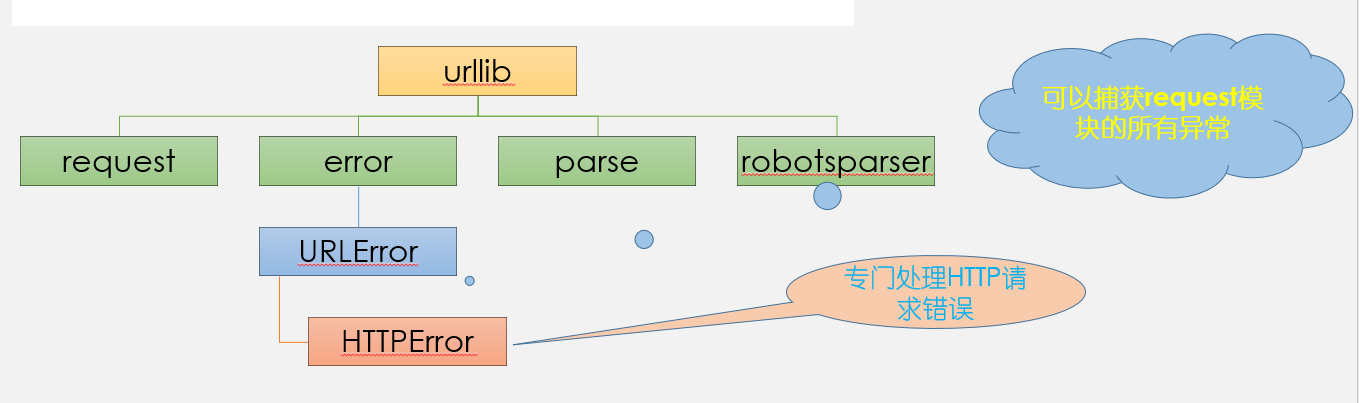
Urllib库有四个模块:request,error, parse, robotparser
request:发起请求(重要)
error:处理错误
parse:解析RUL或目录等
robotparser(不怎么用):解析网站的robot.txt
1.1.2 urllib的robotparser模块
Robots协议也称作爬虫协议、机器人协议,它的全名是网络爬虫排除标准(RobotsExclusingProtocol),主要用来告诉爬虫和搜索引擎哪些网页可以抓取,哪些网页不可以抓取。该协议的内容通常存放在名叫robots.txt的文本文件中,这个文件一般位于网站的根目录下。

User-agent后的*表示该规则对所有的爬虫有效;/robot目录不允许访问,仅允许访问/test/print目录
看一下淘宝的robots.txt
https://www.taobao.com/robots.txt
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
基于robots查看是否可以爬取
from urllib.robotparser import RobotFileParser
robot=RobotFileParser() # 创建一个解析器,用来存储Robots协议内容
robot.set_url('https://www.taobao.com/robots.txt') # set_url()用于设置robots.txt文件的路径
robot.read() # //read()用于读取并分析robots.txt文件的内容,并把结果存储到解析器中
print(robot) # 输出robot协议
print("*"*10)
print(robot.can_fetch('*','https://www.taobao.com/test.js')) # can_fetch()用于判断指定的搜索引擎是否能抓取这个URL
print(robot.can_fetch('Baiduspider','https://www.taobao.com/test.js'))
输出为:
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
**********
True
False
1.1.3 request模块
请求方法
urllib.request.urlopen(url, data=None, [timeout, ]*)
url:地址,可以是字符串,也可以是一个Request对象
data:请求参数
timeout:设置超时
"""
# 爬虫就是模拟用户,向服务器发起请求,服务器会返回对应数据
# 数据抓包,使用chrome,尽量不要使用国产浏览器
# F12打开界面,点击network,刷新,会显示网页的请求,常见的请求有GET, POST, PUT, DELETE, HEAD, OPTIONS, TRACE,其中GET 和 POST 最常用
# GET请求把请求参数都暴露在URL上
# POST请求的参数放在request body,一般会对密码进行加密
# 请求头:用来模拟一个真实用户
# 相应状态码:200表示成功
推荐一个测试网站,用于提交各种请求:http://httpbin.org/,该网站的更多的用法自行搜索
"""
# 引入请求模块
import urllib.request
# 发起请求,设置超时为1s
response = urllib.request.urlopen('http://httpbin.org/', timeout = 1)
print(response.status) # 状态码,判断是否成功,200
print(response.getheaders()) # 响应头 得到的一个元组组成的列表
print(response.getheader('Server')) #得到特定的响应头
print(response.getheader('User-Agent')) #得到特定的响应头
# 使用read()读取整个页面内容,使用decode('utf-8')对获取的内容进行编码
print(response.read().decode('utf-8'))
输出为:
200
[('Date', 'Fri, 22 Sep 2023 01:23:18 GMT'), ('Content-Type', 'text/html; charset=utf-8'), ('Content-Length', '9593'), ('Connection', 'close'), ('Server', 'gunicorn/19.9.0'), ('Access-Control-Allow-Origin', '*'), ('Access-Control-Allow-Credentials', 'true')]
gunicorn/19.9.0
None
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>httpbin.org</title>
<link href="https://fonts.googleapis.com/css?family=Open+Sans:400,700|Source+Code+Pro:300,600|Titillium+Web:400,600,700"
rel="stylesheet">
<link rel="stylesheet" type="text/css" href="/flasgger_static/swagger-ui.css">
<link rel="icon" type="image/png" href="/static/favicon.ico" sizes="64x64 32x32 16x16" />
<style>
html {
box-sizing: border-box;
overflow: -moz-scrollbars-vertical;
overflow-y: scroll;
}
*,
*:before,
*:after {
box-sizing: inherit;
}
body {
margin: 0;
background: #fafafa;
}
</style>
</head>
<body>
...
</body>
</html>
POST请求
import urllib.parse
import urllib.request
# data需要的是字节流编码格式的内容,此时请求方式为post
data = bytes(urllib.parse.urlencode({"name": "WenAn"}), encoding= 'utf-8')
response = urllib.request.urlopen('http://httpbin.org/post', data= data)
print(response.read().decode('utf-8'))
输出为:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "WenAn"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.10",
"X-Amzn-Trace-Id": "Root=1-650ced1b-365667a33f287edd7b5579ab"
},
"json": null,
"origin": "120.194.158.199",
"url": "http://httpbin.org/post"
}
通过返回的内容可以返现包含了User-Agent数据,这是因为浏览器发起请求时都会有请求头header,但urlopen无法添加其他参数,这会让服务器识别出我们是一个爬虫,因此我们需要声明一个request对象来添加header
import urllib.request
import urllib.parse
url = 'http://httpbin.org/post'
# 添加请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 'Host':'httpbin.org'}
dict = {
'name':'WenAn'
}
data = bytes(urllib.parse.urlencode(dict), encoding = 'utf-8')
request = urllib.request.Request(url, data=data, headers=headers, method='POST')
response = urllib.request.urlopen(request)
# response = urllib.request.urlopen('http://httpbin.org/post', data= data)
print(response.read().decode('utf-8'))
输出为:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "WenAn"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-650cee11-094d85e314f07a847244a399"
},
"json": null,
"origin": "120.194.158.199",
"url": "http://httpbin.org/post"
}
输出的数据中User-Agent值为
“Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36”
urlretrieve将数据下载到本地
import urllib.request
urllib.request.urlretrieve("https://www.youdao.com","youdao.html")
urllib.request.urlretrieve("https://www.httpbin.org/get","httpbin/get.html")
from urllib import request, error
#导入request和error模块
def schedule(num,size,tsize):
"""
回调函数,num:当前已经下载的块;
size:每次传输的块大小;
tsize:网页文件总大小
"""
if tsize == 0:
percent = 0
else:
percent = num * size / tsize
if percent > 1.0:
percent = 1.0
percent = percent * 100
print("\r[%-100s] %.2f%%" % ('=' * int(percent), percent),end='')
url = "https://oimageb3.ydstatic.com/image?\
id=5951384821510112623&product=xue" # 下载文件的url
path = r"img1.jpg"
# 文件下载后保存的本地路径
request.urlretrieve(url, path, schedule)
print('\r\n' + url + ' download successfully!')
输出为:

1.1.4 Error
以上讲述的是使用urlopen发送请求的过程,而且是正常情况下的情形。若是非正常情况,比如url地址是错误的或者网络不通,那么就会抛出异常。当有异常发生时,需要利用python的异常控制机制,也就是使用try…except语句来捕获异常进行处理,否则程序就会异常退出。在使用try…except时,except子句一般会加上错误类型,以便针对不同的错误类型采取相应的措施。
Error模块下有三个异常类:
URLError
处理程序在遇到问题时会引发此异常(或其派生的异常)只有一个reason属性
HTTPError
是URLError的一个子类,有更多的属性,如code, reason,headers适用于处理特殊 HTTP 错误例如作为认证请求的时候。
ContentTooShortError
此异常会在 urlretrieve() 函数检测到已下载的数据量小于期待的数据量(由 Content-Length 头给定)时被引发。 content 属性中将存放已下载(可能被截断)的数据。
from urllib import request, error
try:
# 打开httpbin里面的a.html页面,因为它根本不存在,所以会抛出异常
response = request.urlopen('http://httpbin.org/a.html')
except error.URLError as e:
print(e.reason) #Not Found
输出为:
NOT FOUND
HTTPError案例
# 把URLError换成了HTTPError
from urllib import request, error
try:
# 打开httpbin里面的a.html页面,因为它根本不存在,所以会抛出异常
response = request.urlopen('http://httpbin.org/a.html')
except error.HTTPError as e:
print(e.reason)
print(e.code)
print(e.headers)
输出为:
NOT FOUND
404
Date: Fri, 22 Sep 2023 01:40:11 GMT
Content-Type: text/html
Content-Length: 233
Connection: close
Server: gunicorn/19.9.0
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
1.1.5 parse模块
Parse模块
parse模块定义了url的标准接口,实现url的各种抽取,解析,合并,编码,解码
编码
urlencode()介绍—参数编码
它将字典构形式的参数序列化为url编码后的字符串,在前面的request模块有用到
import urllib.parse
dict = {
'name':'WenAn',
'age': 20
}
params = urllib.parse.urlencode(dict)
print(params)
输出为:
name=WenAn&age=20
quote()介绍—中文URL编解码
import urllib.parse
params = '少年强则国强'
base_url = 'https://www.baidu.com/s?wd='
url = base_url + urllib.parse.quote(params)
print(url)
# https://www.baidu.com/s?wd=%E5%B0%91%E5%B9%B4%E5%BC%BA%E5%88%99%E5%9B%BD%E5%BC%BA
# 使用unquote()对中文解码
url1 = 'https://www.baidu.com/s?wd=%E5%B0%91%E5%B9%B4%E5%BC%BA%E5%88%99%E5%9B%BD%E5%BC%BA'
print(urllib.parse.unquote(url1))
# https://www.baidu.com/s?wd=少年强则国强
中文在字典中案例
from urllib import parse
from urllib import request
url='http://www.baidu.com/s?'
dict_data={'wd':'百度翻译'}
#unlencode() 将字典{k 1:v 1,k2:v2}转化为k1=v1&k2=v2
url_data=parse.urlencode(dict_data)
#urldata:wd=%E7%99%BE%E5%BA%A6%E7%BF%BB%E8%AF%91
print(url_data)#读取URL响应结果
res_data=request.urlopen((url+url_data)).read()#用utf 8对响应结果编码
data=res_data.decode('utf-8')
print(data)
输出为:
wd=%E7%99%BE%E5%BA%A6%E7%BF%BB%E8%AF%91
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>百度安全验证</title>
...
</head>
<body>
...
</body>
</html>
在爬取过程中,当获得一个URL时,如果想把这个URL中的各个组成部分分解后使用,那么就要用到url.parse()和url.split()。
使用urlparse()进行URL的解析
from urllib import parse
url = "http://www.youdao.com/s?username=spider"
result = parse.urlparse(url)
print ("urlparse解析出来的结果:\n%s"%str(result))
输出为:
urlparse解析出来的结果:
ParseResult(scheme='http', netloc='www.youdao.com', path='/s', params='', query='username=spider', fragment='')
urlsplit()方法和urlparse()方法的作用相似,区别在于它不再单独解析params部分,而仅返回5个结果,将params合并到path中。
使用urlsplit()进行URL的解析。
from urllib import parse
url = "http://www.youdao.com/s?username=spider"
result = parse.urlsplit(url)
print ("urlsplit解析出来的结果:\n%s"%str(result))
输出为:
urlsplit解析出来的结果:
SplitResult(scheme='http', netloc='www.youdao.com', path='/s', query='username=spider', fragment='')
1.2 urllib高级应用
1.2.1Opener
opener是 urllib.request.OpenerDirector 的实例,如上文提到的urlopen便是一个已经构建好的特殊opener,但urlopen()仅提供了最基本的功能,如不支持代理,cookie等
自定义Opener的流程
使用相关的 Handler处理器来创建特定功能的处理器对象通过 urllib.request.build_opener()方法使用处理器对象,
创建自定义opener对象使用自定义的opener对象,
调用open()方法发送请求
关于全局Opener
如果要求程序里面的所有请求都使用自定义的opener,使用urllib.request.install_opener()
import urllib.request
# 创建handler
http_handler = urllib.request.HTTPHandler()
# 创建opener
opener = urllib.request.build_opener(http_handler)
# 创建Request对象
request = urllib.request.Request('http://httpbin.org/get')
# 局部opener,只能使用.open()来访问
# response = opener.open(request)
# 全局opener,之后调用urlopen,都将使用这个自定义opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(request)
print(response.read().decode('utf8'))
输出为:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.10",
"X-Amzn-Trace-Id": "Root=1-650cf628-059816f8524cf7ec7d9cee6e"
},
"origin": "120.194.158.199",
"url": "http://httpbin.org/get"
}
1.2.2 代理设置
推荐几个提供免费代理服务的网站:
http://www.xiladaili.com/
https://www.kuaidaili.com/free/
https://ip.jiangxianli.com/?page=1
import urllib.request
# 创建handler
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://182.34.103.79:9999'
})
# 创建opener
opener = urllib.request.build_opener(proxy_handler)
header = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
request = urllib.request.Request('https://www.httpbin.org/get', headers=header)
# 配置全局opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
代理设置未成功