Flume 1.9.0 Developer Guide【Flume 1.9.0开发人员指南】
Introduction【介绍】
摘自:Flume 1.9.0 Developer Guide — Apache Flume
Overview【概述】
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Apache Flume是一个分布式、可靠且可用的系统,用于高效地收集、聚合来自许多不同来源的大量日志数据,并将其移动到集中的数据存储中。
Apache Flume is a top-level project at the Apache Software Foundation. There are currently two release code lines available, versions 0.9.x and 1.x. This documentation applies to the 1.x codeline. For the 0.9.x codeline, please see the Flume 0.9.x Developer Guide.
Apache Flume是Apache软件基金会的一个顶级项目。目前有两个可用的发布代码行,版本0.9.x和1.x。此文档适用于1.x代码行。有关0.9.x代码行,请参阅Flume 0.9.x开发人员指南。
Architecture【结构】
Data flow model【数据流模型】
An Event is a unit of data that flows through a Flume agent. The Event flows from Source to Channel to Sink, and is represented by an implementation of the Event interface. An Event carries a payload (byte array) that is accompanied by an optional set of headers (string attributes). A Flume agent is a process (JVM) that hosts the components that allow Events to flow from an external source to a external destination.
事件是流经Flume代理的数据单元。事件从Source流到Channel再流到Sink,并由Event接口的实现表示。Event携带一个有效负载(字节数组),该有效负载附带一组可选的标头(字符串属性)。Flume代理是一个进程(JVM),它承载允许事件从外部源流到外部目标的组件。
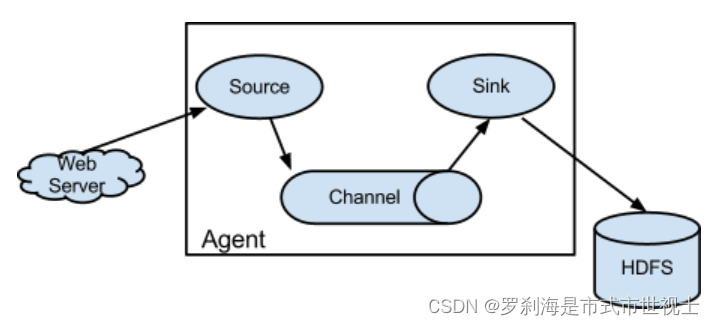
A Source consumes Events having a specific format, and those Events are delivered to the Source by an external source like a web server. For example, an AvroSource can be used to receive Avro Events from clients or from other Flume agents in the flow. When a Source receives an Event, it stores it into one or more Channels. The Channel is a passive store that holds the Event until that Event is consumed by a Sink. One type of Channel available in Flume is the FileChannel which uses the local filesystem as its backing store. A Sink is responsible for removing an Event from the Channel and putting it into an external repository like HDFS (in the case of an HDFSEventSink) or forwarding it to the Source at the next hop of the flow. The Source and Sink within the given agent run asynchronously with the Events staged in the Channel.
Source使用具有特定格式的事件,这些事件由外部源(如web服务器)传递给Source。例如,AvroSource可用于从客户端或流中的其他Flume代理接收Avro事件。当源接收到一个事件时,它会将其存储到一个或多个通道中。通道是一个被动存储,它保存事件,直到接收器消耗该事件为止。Flume中可用的一种通道是FileChannel,它使用本地文件系统作为其后备存储。Sink负责从通道中删除事件,并将其放入HDFS等外部存储库(在HDFSEventSink的情况下),或在流的下一跳将其转发给Source。给定代理中的源和接收器与通道中暂存的事件异步运行。
Reliability【可靠性】
An Event is staged in a Flume agent’s Channel. Then it’s the Sink‘s responsibility to deliver the Event to the next agent or terminal repository (like HDFS) in the flow. The Sink removes an Event from the Channel only after the Event is stored into the Channel of the next agent or stored in the terminal repository. This is how the single-hop message delivery semantics in Flume provide end-to-end reliability of the flow. Flume uses a transactional approach to guarantee the reliable delivery of the Events.
Flume代理的频道中正在上演一个事件。然后,Sink负责将事件传递到流中的下一个代理或终端存储库(如HDFS)。只有在事件存储到下一个代理的通道中或存储在终端存储库中之后,接收器才会从通道中删除事件。Flume中的单跳消息传递语义就是这样提供流的端到端可靠性的。Flume使用事务性方法来保证事件的可靠传递。
The Sources and Sinks encapsulate the storage/retrieval of the Events in a Transaction provided by the Channel. This ensures that the set of Events are reliably passed from point to point in the flow. In the case of a multi-hop flow, the Sink from the previous hop and the Source of the next hop both have their Transactions open to ensure that the Event data is safely stored in the Channel of the next hop.
源和接收器封装通道提供的事务中事件的存储/检索。这确保了事件集在流中从一个点可靠地传递到另一个点。在多跳流的情况下,来自上一跳的接收器和下一跳的源都打开了它们的事务,以确保事件数据安全地存储在下一跳通道中。
Building Flume 【建筑水槽】
Getting the source 【获取源】
Check-out the code using Git. Click here for the git repository root.
The Flume 1.x development happens under the branch “trunk” so this command line can be used:
git clone GitHub - apache/flume: Mirror of Apache Flume
使用Git查看代码。单击此处获取git存储库根目录。
Flume1.x的开发发生在分支“trunk”下,因此可以使用以下命令行:
git克隆https://git-wip-us.apache.org/repos/asf/flume.git
Compile/test Flume 【编译/测试Flume】
The Flume build is mavenized. You can compile Flume using the standard Maven commands:
Flume构建是专业化的。您可以使用标准的Maven命令编译Flume:
- Compile only: mvn clean compile
- Compile and run unit tests: mvn clean test
- Run individual test(s): mvn clean test -Dtest=<Test1>,<Test2>,... -DfailIfNoTests=false
- Create tarball package: mvn clean install
- Create tarball package (skip unit tests): mvn clean install -DskipTests
1.仅编译:mvn clean Compile
2.编译并运行单元测试:mvn clean测试
3.进行单独测试:
mvn clean test-Dtest=<Test1>,<Test2>,。。。-DfailIfNoTests=false
4.创建tarball包:mvn clean install
5.创建tarball包(跳过单元测试):mvn-clean-install-DskipTests
Please note that Flume builds requires that the Google Protocol Buffers compiler be in the path. You can download and install it by following the instructions here.
请注意,Flume构建要求Google Protocol Buffers编译器位于路径中。您可以按照此处的说明下载并安装它。
Updating Protocol Buffer Version 【正在更新协议缓冲区版本】
File channel has a dependency on Protocol Buffer. When updating the version of Protocol Buffer used by Flume, it is necessary to regenerate the data access classes using the protoc compiler that is part of Protocol Buffer as follows.
文件通道依赖于协议缓冲区。当更新Flume使用的Protocol Buffer版本时,有必要使用Protocol Buffer的协议编译器重新生成数据访问类,如下所示。
- Install the desired version of Protocol Buffer on your local machine
- Update version of Protocol Buffer in pom.xml
- Generate new Protocol Buffer data access classes in Flume: cd flume-ng-channels/flume-file-channel; mvn -P compile-proto clean package -DskipTests
- Add Apache license header to any of the generated files that are missing it
- Rebuild and test Flume: cd ../..; mvn clean install
1.在本地计算机上安装所需版本的协议缓冲区
2.更新pom.xml中的Protocol Buffer版本
3.在Flume中生成新的Protocol Buffer数据访问类:cd Flume ng channels/Flume file channel;mvn-P编译proto clean包-DskipTests
4.将Apache许可证标头添加到任何缺少它的生成文件中
5.重建并测试Flume:cd./。。;mvn干净安装
Developing custom components 【开发自定义组件】
Client 【客户端】
The client operates at the point of origin of events and delivers them to a Flume agent. Clients typically operate in the process space of the application they are consuming data from. Flume currently supports Avro, log4j, syslog, and Http POST (with a JSON body) as ways to transfer data from a external source. Additionally, there’s an ExecSource that can consume the output of a local process as input to Flume.
客户端在事件的起源点进行操作,并将它们传递给Flume代理。客户端通常在其使用数据的应用程序的进程空间中操作。Flume目前支持Avro、log4j、syslog和HttpPOST(带有JSON主体)作为从外部源传输数据的方法。此外,还有一个ExecSource,它可以使用本地进程的输出作为Flume的输入。
The client operates at the point of origin of events and delivers them to a Flume agent. Clients typically operate in the process space of the application they are consuming data from. Flume currently supports Avro, log4j, syslog, and Http POST (with a JSON body) as ways to transfer data from a external source. Additionally, there’s an ExecSource that can consume the output of a local process as input to Flume.
有一个用例中这些现有选项是不够的,这是很可能的。在这种情况下,您可以构建一个自定义机制来向Flume发送数据。实现这一点有两种方法。第一个选项是创建一个自定义客户端,该客户端与Flume现有的源之一(如AvroSource或SyslogTcpSource)通信。在这里,客户端应该将其数据转换为这些Flume源可以理解的消息。另一种选择是编写一个自定义Flume Source,它使用某些IPC或RPC协议直接与现有的客户端应用程序进行对话,然后将客户端数据转换为Flume Events以发送到下游。请注意,Flume代理的通道中存储的所有事件都必须作为Flume事件存在。
Client SDK 【客户端SDK】
Though Flume contains a number of built-in mechanisms (i.e. Sources) to ingest data, often one wants the ability to communicate with Flume directly from a custom application. The Flume Client SDK is a library that enables applications to connect to Flume and send data into Flume’s data flow over RPC.
尽管Flume包含许多内置机制(即Source)来获取数据,但人们通常希望能够从自定义应用程序直接与Flume通信。Flume客户端SDK是一个库,使应用程序能够连接到Flume并通过RPC将数据发送到Flume的数据流中。
RPC client interface 【RPC客户端接口】
An implementation of Flume’s RpcClient interface encapsulates the RPC mechanism supported by Flume. The user’s application can simply call the Flume Client SDK’s append(Event) or appendBatch(List<Event>) to send data and not worry about the underlying message exchange details. The user can provide the required Event arg by either directly implementing the Event interface, by using a convenience implementation such as the SimpleEvent class, or by using EventBuilder‘s overloaded withBody() static helper methods.
Flume的RpcClient接口的实现封装了Flume支持的RPC机制。用户的应用程序可以简单地调用Flume Client SDK的append(Event)或appendBatch(List<Event>)来发送数据,而不必担心底层的消息交换细节。用户可以通过直接实现Event接口、使用SimpleEvent类等方便的实现或使用EventBuilder的重载withBody()静态辅助方法来提供所需的Event arg。
RPC clients - Avro and Thrift 【RPC客户端-Avro和Thrift】
As of Flume 1.4.0, Avro is the default RPC protocol. The NettyAvroRpcClient and ThriftRpcClient implement the RpcClient interface. The client needs to create this object with the host and port of the target Flume agent, and can then use the RpcClient to send data into the agent. The following example shows how to use the Flume Client SDK API within a user’s data-generating application:
从Flume 1.4.0开始,Avro是默认的RPC协议。NettyAvroRpcClient和ThriftRpcClient实现了RpcClient接口。客户端需要使用目标Flume代理的主机和端口创建此对象,然后可以使用RpcClient将数据发送到代理中。以下示例显示如何在用户的数据生成应用程序中使用Flume Client SDK API:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
public class MyApp {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
// 使用远程Flume代理的主机和端口初始化客户端
client.init("host.example.org", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
// 向远程Flume代理发送10个事件。应将该代理配置为使用AvroSource进行侦听。
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection 设置RPC连接
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// 使用以下方法创建旧款客户端(而不是上面的行):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
// this.client=RpcClientFactory.getThriftInstance(主机名,端口);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
// 创建一个Flume Event对象,用于封装示例数据
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
// 发送事件
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
// 清理并重新创建客户端
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// 使用以下方法创建旧款客户端(而不是上面的行):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
// this.client=RpcClientFactory.getThriftInstance(主机名,端口);
}
}
public void cleanUp() {
// Close the RPC connection
// 关闭RPC连接
client.close();
}
}The remote Flume agent needs to have an AvroSource (or a ThriftSource if you are using a Thrift client) listening on some port. Below is an example Flume agent configuration that’s waiting for a connection from MyApp:
远程Flume代理需要在某个端口上侦听AvroSource(如果您使用的是Thrift客户端,则为ThriftSource)。以下是等待MyApp连接的Flume代理配置示例:
a1.channels = c1
a1.sources = r1
a1.sinks = k1
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
# For using a thrift source set the following instead of the above line.
#对于使用节俭源,请设置以下内容,而不是上面的行。
# a1.source.r1.type = thriftce
#a1.source.r1.type=节俭
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sinks.k1.channel = c1
a1.sinks.k1.type = loggerFor more flexibility, the default Flume client implementations (NettyAvroRpcClient and ThriftRpcClient) can be configured with these properties:
为了获得更大的灵活性,默认的Flume客户端实现(NettyAvroRpcClient和ThriftRpcClient)可以使用以下属性进行配置:
client.type = default (for avro) or thrift (for thrift)
hosts = h1 # default client accepts only 1 host 默认客户端只接受1台主机
# (additional hosts will be ignored)(将忽略其他主机)
hosts.h1 = host1.example.org:41414 # host and port must both be specified 必须同时指定主机和端口
# (neither has a default) (两者都没有默认值)
batch-size = 100 # Must be >=1 (default: 100) 必须>=1(默认值:100)
connect-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)
request-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)Secure RPC client - Thrift 【安全RPC客户端-Thrift】
As of Flume 1.6.0, Thrift source and sink supports kerberos based authentication. The client needs to use the getThriftInstance method of SecureRpcClientFactory to get hold of a SecureThriftRpcClient. SecureThriftRpcClient extends ThriftRpcClient which implements the RpcClient interface. The kerberos authentication module resides in flume-ng-auth module which is required in classpath, when using the SecureRpcClientFactory. Both the client principal and the client keytab should be passed in as parameters through the properties and they reflect the credentials of the client to authenticate against the kerberos KDC. In addition, the server principal of the destination Thrift source to which this client is connecting to, should also be provided. The following example shows how to use the SecureRpcClientFactory within a user’s data-generating application:
从Flume 1.6.0开始,Thrift源和汇支持基于kerberos的身份验证。客户端需要使用SecureRpcClientFactory的getThriftInstance方法来获取SecureThriftRpcClient。SecureStriftRpcClient扩展了实现RpcClient接口的ThriftRpcClient。kerberos身份验证模块位于flume ng auth模块中,当使用SecureRpcClientFactory时,该模块在类路径中是必需的。客户端主体和客户端密钥选项卡都应该作为参数通过属性传递,它们反映了客户端根据kerberos KDC进行身份验证的凭据。此外,还应提供此客户端连接到的目标Thrift源的服务器主体。以下示例显示如何在用户的数据生成应用程序中使用SecureRpcClientFactory:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.api.SecureRpcClientFactory;
import org.apache.flume.api.RpcClientConfigurationConstants;
import org.apache.flume.api.RpcClient;
import java.nio.charset.Charset;
import java.util.Properties;
public class MyApp {
public static void main(String[] args) {
MySecureRpcClientFacade client = new MySecureRpcClientFacade();
// Initialize client with the remote Flume agent's host, port
// 使用远程Flume代理的主机、端口初始化客户端
Properties props = new Properties();
props.setProperty(RpcClientConfigurationConstants.CONFIG_CLIENT_TYPE, "thrift");
props.setProperty("hosts", "h1");
props.setProperty("hosts.h1", "client.example.org"+":"+ String.valueOf(41414));
// Initialize client with the kerberos authentication related properties
// 使用kerberos身份验证相关属性初始化客户端
props.setProperty("kerberos", "true");
props.setProperty("client-principal", "flumeclient/client.example.org@EXAMPLE.ORG");
props.setProperty("client-keytab", "/tmp/flumeclient.keytab");
props.setProperty("server-principal", "flume/server.example.org@EXAMPLE.ORG");
client.init(props);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
// 向远程Flume代理发送10个事件。应将该代理配置为使用AvroSource进行侦听。
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}
}
class MySecureRpcClientFacade {
private RpcClient client;
private Properties properties;
public void init(Properties properties) {
// Setup the RPC connection
// 设置RPC连接
this.properties = properties;
// Create the ThriftSecureRpcClient instance by using SecureRpcClientFactory
// 使用SecureRpcClientFactory创建ThriftSecureRpcClient实例
this.client = SecureRpcClientFactory.getThriftInstance(properties);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
// 创建一个Flume Event对象,用于封装示例数据
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
// 发送事件
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
// 清理并重新创建客户端
client.close();
client = null;
client = SecureRpcClientFactory.getThriftInstance(properties);
}
}
public void cleanUp() {
// Close the RPC connection
// 关闭RPC连接
client.close();
}
}The remote ThriftSource should be started in kerberos mode. Below is an example Flume agent configuration that’s waiting for a connection from MyApp:
远程ThriftSource应该在kerberos模式下启动。以下是等待MyApp连接的Flume代理配置示例:
a1.channels = c1
a1.sources = r1
a1.sinks = k1
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sources.r1.type = thrift
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sources.r1.kerberos = true
a1.sources.r1.agent-principal = flume/server.example.org@EXAMPLE.ORG
a1.sources.r1.agent-keytab = /tmp/flume.keytab
a1.sinks.k1.channel = c1
a1.sinks.k1.type = loggerFailover Client 【故障转移客户端】
This class wraps the default Avro RPC client to provide failover handling capability to clients. This takes a whitespace-separated list of <host>:<port> representing the Flume agents that make-up a failover group. The Failover RPC Client currently does not support thrift. If there’s a communication error with the currently selected host (i.e. agent) agent, then the failover client automatically fails-over to the next host in the list. For example:
此类包装默认的Avro RPC客户端,为客户端提供故障转移处理功能。这采用了一个以空格分隔的<host>:<port>列表,表示组成故障转移组的Flume代理。故障转移RPC客户端当前不支持节俭。如果当前选择的主机(即代理)代理发生通信错误,则故障转移客户端会自动故障转移到列表中的下一台主机。例如:
// Setup properties for the failover
// 故障转移的设置属性
Properties props = new Properties();
props.put("client.type", "default_failover");
// List of hosts (space-separated list of user-chosen host aliases)
// 主机列表(用户选择的主机别名的空格分隔列表)
props.put("hosts", "h1 h2 h3");
// host/port pair for each host alias
// 每个主机别名的主机/端口对
String host1 = "host1.example.org:41414";
String host2 = "host2.example.org:41414";
String host3 = "host3.example.org:41414";
props.put("hosts.h1", host1);
props.put("hosts.h2", host2);
props.put("hosts.h3", host3);
// create the client with failover properties
// 创建具有故障转移属性的客户端
RpcClient client = RpcClientFactory.getInstance(props);For more flexibility, the failover Flume client implementation (FailoverRpcClient) can be configured with these properties:
为了获得更大的灵活性,故障转移Flume客户端实现(FailoverRpcClient)可以使用以下属性进行配置:
client.type = default_failover
hosts = h1 h2 h3 # at least one is required, but 2 or
# more makes better sense
# 至少需要一个,但2个或更多更有意义
hosts.h1 = host1.example.org:41414
hosts.h2 = host2.example.org:41414
hosts.h3 = host3.example.org:41414
max-attempts = 3 # Must be >=0 (default: number of hosts
# specified, 3 in this case). A '0'
# value doesn't make much sense because
# it will just cause an append call to
# immmediately fail. A '1' value means
# that the failover client will try only
# once to send the Event, and if it
# fails then there will be no failover
# to a second client, so this value
# causes the failover client to
# degenerate into just a default client.
# It makes sense to set this value to at
# least the number of hosts that you
# specified.
# 必须>=0(默认值:指定的主机数,在本例中为3)。
# “0”值没有多大意义,因为它只会导致追加调用立即失败。“1”值表示故障转移客户端将只尝试发送一次事件,
# 如果失败,则不会向第二个客户端进行故障转移,因此此值会导致故障转移客户端退化为默认客户端。
# 将此值设置为至少指定的主机数是有意义的。
batch-size = 100 # Must be >=1 (default: 100) 必须>=1(默认值:100)
connect-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)
request-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)LoadBalancing RPC client 【负载平衡RPC客户端】
The Flume Client SDK also supports an RpcClient which load-balances among multiple hosts. This type of client takes a whitespace-separated list of <host>:<port> representing the Flume agents that make-up a load-balancing group. This client can be configured with a load balancing strategy that either randomly selects one of the configured hosts, or selects a host in a round-robin fashion. You can also specify your own custom class that implements the LoadBalancingRpcClient$HostSelector interface so that a custom selection order is used. In that case, the FQCN of the custom class needs to be specified as the value of the host-selector property. The LoadBalancing RPC Client currently does not support thrift.
Flume Client SDK还支持RpcClient,它可以在多个主机之间实现负载平衡。这种类型的客户端采用以空格分隔的<host>:<port>列表,表示组成负载平衡组的Flume代理。该客户端可以使用负载平衡策略进行配置,该策略可以随机选择配置的主机之一,也可以以循环方式选择主机。您还可以指定自己的自定义类来实现LoadBalancingRpcClient$HostSelector接口,以便使用自定义选择顺序。在这种情况下,需要将自定义类的FQCN指定为主机选择器属性的值。LoadBalancing RPC客户端当前不支持节俭。
If backoff is enabled then the client will temporarily blacklist hosts that fail, causing them to be excluded from being selected as a failover host until a given timeout. When the timeout elapses, if the host is still unresponsive then this is considered a sequential failure, and the timeout is increased exponentially to avoid potentially getting stuck in long waits on unresponsive hosts.
如果启用了回退,则客户端将暂时将出现故障的主机列入黑名单,导致它们在指定超时之前无法被选为故障转移主机。超时过后,如果主机仍然没有响应,则这被视为连续故障,并且超时会成倍增加,以避免在没有响应的主机上陷入长时间等待。
The maximum backoff time can be configured by setting maxBackoff (in milliseconds). The maxBackoff default is 30 seconds (specified in the OrderSelector class that’s the superclass of both load balancing strategies). The backoff timeout will increase exponentially with each sequential failure up to the maximum possible backoff timeout. The maximum possible backoff is limited to 65536 seconds (about 18.2 hours). For example:
可以通过设置maxBackoff(以毫秒为单位)来配置最大回退时间。maxBackoff默认值为30秒(在OrderSelector类中指定,该类是两种负载平衡策略的超类)。退避超时将随着每次连续故障呈指数级增加,直至可能的最大退避超时。最大可能退避时间限制为65536秒(约18.2小时)。例如:
// Setup properties for the load balancing
// 设置负载平衡的属性
Properties props = new Properties();
props.put("client.type", "default_loadbalance");
// List of hosts (space-separated list of user-chosen host aliases)
// 主机列表(用户选择的主机别名的空格分隔列表)
props.put("hosts", "h1 h2 h3");
// host/port pair for each host alias
// 每个主机别名的主机/端口对
String host1 = "host1.example.org:41414";
String host2 = "host2.example.org:41414";
String host3 = "host3.example.org:41414";
props.put("hosts.h1", host1);
props.put("hosts.h2", host2);
props.put("hosts.h3", host3);
props.put("host-selector", "random");
// For random host selection 用于随机主机选择
// props.put("host-selector", "round_robin"); props.put(“主机选择器”、“round_robin”);
// For round-robin host 对于循环主机
// selection 选择
props.put("backoff", "true"); // Disabled by default. 默认情况下已禁用。
props.put("maxBackoff", "10000");
// Defaults 0, which effectively becomes 30000 ms 默认值为0,实际变为30000毫秒
// Create the client with load balancing properties 创建具有负载平衡属性的客户端
RpcClient client = RpcClientFactory.getInstance(props);For more flexibility, the load-balancing Flume client implementation (LoadBalancingRpcClient) can be configured with these properties:
为了获得更大的灵活性,负载平衡Flume客户端实现(LoadBalancingRpcClient)可以使用以下属性进行配置:
client.type = default_loadbalance
hosts = h1 h2 h3 # At least 2 hosts are required 至少需要2台主机
hosts.h1 = host1.example.org:41414
hosts.h2 = host2.example.org:41414
hosts.h3 = host3.example.org:41414
backoff = false # Specifies whether the client should
# back-off from (i.e. temporarily
# blacklist) a failed host
# (default: false).
maxBackoff = 0 # Max timeout in millis that a will
# remain inactive due to a previous
# failure with that host (default: 0,
# which effectively becomes 30000)
# 指定客户端是否应退出(即暂时列入黑名单)故障主机(默认值:false)。
host-selector = round_robin # The host selection strategy used
# when load-balancing among hosts
# (default: round_robin).
# Other values are include "random"
# or the FQCN of a custom class
# that implements
# LoadBalancingRpcClient$HostSelector
# 在主机之间进行负载平衡时使用的主机选择策略(默认值:round_robin)。其他值包括“random”或实现LoadBalancingRpcClient$HostSelector的自定义类的FQCN
batch-size = 100 # Must be >=1 (default: 100) 必须>=1(默认值:100)
connect-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)
request-timeout = 20000 # Must be >=1000 (default: 20000) 必须>=1000(默认值:20000)Embedded agent 【嵌入式代理】
Flume has an embedded agent api which allows users to embed an agent in their application. This agent is meant to be lightweight and as such not all sources, sinks, and channels are allowed. Specifically the source used is a special embedded source and events should be send to the source via the put, putAll methods on the EmbeddedAgent object. Only File Channel and Memory Channel are allowed as channels while Avro Sink is the only supported sink. Interceptors are also supported by the embedded agent.
Flume有一个嵌入式代理api,允许用户在应用程序中嵌入代理。此代理是轻量级的,因此不允许使用所有源、汇和通道。具体来说,使用的源是一个特殊的嵌入式源,事件应该通过EmbeddedAgent对象上的put、putAll方法发送到源。只有文件通道和内存通道被允许作为通道,而Avro接收器是唯一受支持的接收器。嵌入式代理也支持拦截器。
Note: The embedded agent has a dependency on hadoop-core.jar.
注意:嵌入式代理依赖于hadoop-core.jar。
Configuration of an Embedded Agent is similar to configuration of a full Agent. The following is an exhaustive list of configration options:
嵌入式代理的配置类似于完整代理的配置。以下是配置选项的详尽列表:
Required properties are in bold.
必填属性以粗体显示。
| Property Name | Default | Description |
| source.type | embedded | The only available source is the embedded source. 唯一可用的源是嵌入式源。 |
| channel.type | - | Either memory or file which correspond to MemoryChannel and FileChannel respectively. 内存或文件,分别对应MemoryChannel和FileChannel。 |
| channel.* | - | Configuration options for the channel type requested, see MemoryChannel or FileChannel user guide for an exhaustive list. 请求的通道类型的配置选项,请参阅MemoryChannel或FileChannel用户指南以获取详细列表。 |
| sinks | - | List of sink names 接收器名称列表 |
| sink.type | - | Property name must match a name in the list of sinks. Value must be avro |
| sink.* | - | Configuration options for the sink. See AvroSink user guide for an exhaustive list, however note AvroSink requires at least hostname and port. 接收器的配置选项。有关详细列表,请参阅AvroSink用户指南,但请注意,AvroSink至少需要主机名和端口。 |
| processor.type | - | Either failover or load_balance which correspond to FailoverSinksProcessor and LoadBalancingSinkProcessor respectively. 分别对应FailoverSinksProcessor和LoadBalancingSinkProcessor的failover或load_balance。 |
| processor.* | - | Configuration options for the sink processor selected. See FailoverSinksProcessor and LoadBalancingSinkProcessor user guide for an exhaustive list. 所选接收器处理器的配置选项。有关详细列表,请参阅FailoverSinksProcessor and LoadBalancingSinkProcessor用户指南。 |
| source.interceptors | - | Space-separated list of interceptors 以空格分隔的拦截器列表 |
| source.interceptors.* | - | Space-separated list of interceptors 以空格分隔的拦截器列表 |
Below is an example of how to use the agent:
以下是如何使用代理的示例:
Map<String, String> properties = new HashMap<String, String>();
properties.put("channel.type", "memory");
properties.put("channel.capacity", "200");
properties.put("sinks", "sink1 sink2");
properties.put("sink1.type", "avro");
properties.put("sink2.type", "avro");
properties.put("sink1.hostname", "collector1.apache.org");
properties.put("sink1.port", "5564");
properties.put("sink2.hostname", "collector2.apache.org");
properties.put("sink2.port", "5565");
properties.put("processor.type", "load_balance");
properties.put("source.interceptors", "i1");
properties.put("source.interceptors.i1.type", "static");
properties.put("source.interceptors.i1.key", "key1");
properties.put("source.interceptors.i1.value", "value1");
EmbeddedAgent agent = new EmbeddedAgent("myagent");
agent.configure(properties);
agent.start();
List<Event> events = Lists.newArrayList();
events.add(event);
events.add(event);
events.add(event);
events.add(event);
agent.putAll(events);
...
agent.stop();Transaction interface 【交易接口】
The Transaction interface is the basis of reliability for Flume. All the major components (ie. Sources, Sinks and Channels) must use a Flume Transaction.
事务接口是Flume可靠性的基础。所有主要组件(即源、接收器和通道)都必须使用Flume事务。
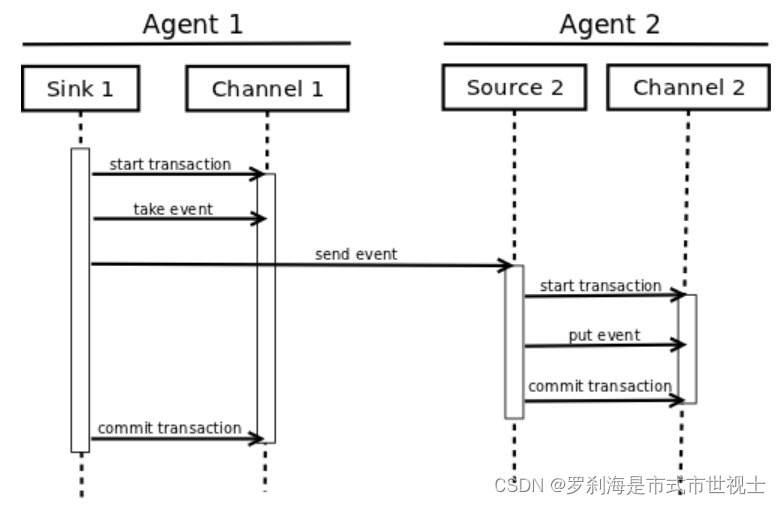
A Transaction is implemented within a Channel implementation. Each Source and Sink that is connected to a Channel must obtain a Transaction object. The Sources use a ChannelProcessor to manage the Transactions, the Sinks manage them explicitly via their configured Channel. The operation to stage an Event (put it into a Channel) or extract an Event (take it out of a Channel) is done inside an active Transaction. For example:
事务是在通道实现中实现的。连接到通道的每个源和接收器都必须获得一个Transaction对象。Source使用ChannelProcessor来管理事务,Sink通过其配置的通道显式管理事务。暂存事件(将其放入通道)或提取事件(从通道中取出)的操作是在活动事务中完成的。例如:
Channel ch = new MemoryChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
// 此try子句包括您想要执行的任何Channel操作
Event eventToStage = EventBuilder.withBody("Hello Flume!",
Charset.forName("UTF-8"));
ch.put(eventToStage);
// Event takenEvent = ch.take(); 事件takenEvent=ch.take();
// ...
txn.commit();
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
// 记录异常,根据需要处理个别异常
// re-throw all Errors 重新抛出所有错误
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}Here we get hold of a Transaction from a Channel. After begin() returns, the Transaction is now active/open and the Event is then put into the Channel. If the put is successful, then the Transaction is committed and closed.
在这里,我们从一个渠道获得一个交易。在begin()返回后,事务现在处于活动/打开状态,然后事件被放入通道中。如果看跌期权成功,则交易被提交并结束。
Sink 【输出】
The purpose of a Sink to extract Events from the Channel and forward them to the next Flume Agent in the flow or store them in an external repository. A Sink is associated with exactly one Channels, as configured in the Flume properties file. There’s one SinkRunner instance associated with every configured Sink, and when the Flume framework calls SinkRunner.start(), a new thread is created to drive the Sink (using SinkRunner.PollingRunner as the thread’s Runnable). This thread manages the Sink’s lifecycle. The Sink needs to implement the start() and stop() methods that are part of the LifecycleAware interface. The Sink.start() method should initialize the Sink and bring it to a state where it can forward the Events to its next destination. The Sink.process() method should do the core processing of extracting the Event from the Channel and forwarding it. The Sink.stop() method should do the necessary cleanup (e.g. releasing resources). The Sink implementation also needs to implement the Configurable interface for processing its own configuration settings. For example:
接收器的目的是从通道中提取事件,并将它们转发到流中的下一个Flume代理,或将它们存储在外部存储库中。接收器与Flume属性文件中配置的一个通道正好关联。每个配置的Sink都有一个SinkRunner实例,当Flume框架调用SinkRunner.start()时,会创建一个新线程来驱动Sink(使用SinkRunner.PollingRunner作为线程的Runnable)。此线程管理接收器的生命周期。Sink需要实现作为LifecycleAware接口一部分的start()和stop()方法。Sink.start()方法应该初始化Sink,并使其处于可以将Events转发到下一个目标的状态。Sink.process()方法应该完成从通道中提取事件并将其转发的核心处理。Sink.stop()方法应进行必要的清理(例如释放资源)。Sink实现还需要实现可配置接口以处理其自己的配置设置。例如:
public class MySink extends AbstractSink implements Configurable {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation)
// 处理myProp值(例如验证)
// Store myProp for later retrieval by process() method
// 存储myProp以便稍后通过process()方法检索
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external repository (e.g. HDFS) that
// this Sink will forward Events to ..
// 初始化到此接收器将事件转发到的外部存储库(例如HDFS)的连接。。
}
@Override
public void stop () {
// Disconnect from the external respository and do any
// additional cleanup (e.g. releasing resources or nulling-out
// field values) ..
// 断开与外部存储的连接,并进行任何额外的清理(例如释放资源或清空字段值)。。
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction 开始交易
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
// 此try子句包括您想要执行的任何Channel操作
Event event = ch.take();
// Send the Event to the external repository. 将事件发送到外部存储库。
// storeSomeData(e);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
// 记录异常,根据需要处理个别异常
status = Status.BACKOFF;
// re-throw all Errors 重新抛出所有错误
if (t instanceof Error) {
throw (Error)t;
}
}
return status;
}
}Source 【来源】
The purpose of a Source is to receive data from an external client and store it into the configured Channels. A Source can get an instance of its own ChannelProcessor to process an Event, commited within a Channel local transaction, in serial. In the case of an exception, required Channels will propagate the exception, all Channels will rollback their transaction, but events processed previously on other Channels will remain committed.
源的目的是从外部客户端接收数据,并将其存储到配置的通道中。Source可以获得自己的ChannelProcessor实例来处理在Channel本地事务中串行提交的事件。在出现异常的情况下,所需的通道将传播该异常,所有通道都将回滚其事务,但以前在其他通道上处理的事件将保持提交状态。
Similar to the SinkRunner.PollingRunner Runnable, there’s a PollingRunner Runnable that executes on a thread created when the Flume framework calls PollableSourceRunner.start(). Each configured PollableSource is associated with its own thread that runs a PollingRunner. This thread manages the PollableSource’s lifecycle, such as starting and stopping. A PollableSource implementation must implement the start() and stop() methods that are declared in the LifecycleAware interface. The runner of a PollableSource invokes that Source‘s process() method. The process() method should check for new data and store it into the Channel as Flume Events.
类似于SinkRunner。PollingRunner Runnable,在Flume框架调用PollableSourceRunner.start()时创建的线程上执行一个PollingRunnerRunnable。每个配置的PollableSource都与自己的线程关联,该线程运行一个Polling Runner。该线程管理PollableSource的生命周期,例如启动和停止。PolableSource实现必须实现在LifecycleAware接口中声明的start()和stop()方法。PollableSource的运行程序调用该Source的process()方法。process()方法应该检查新数据,并将其作为FlumeEvents存储到Channel中。
Note that there are actually two types of Sources. The PollableSource was already mentioned. The other is the EventDrivenSource. The EventDrivenSource, unlike the PollableSource, must have its own callback mechanism that captures the new data and stores it into the Channel. The EventDrivenSources are not each driven by their own thread like the PollableSources are. Below is an example of a custom PollableSource:
请注意,实际上有两种类型的Source。PollableSource已被提及。另一个是EventDrivenSource。EventDrivenSource与PollableSource不同,它必须有自己的回调机制来捕获新数据并将其存储到通道中。EventDrivenSources并不像PolableSources那样由各自的线程驱动。下面是一个自定义PollableSource的示例:
public class MySource extends AbstractSource implements Configurable, PollableSource {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation, convert to another type, ...)
// 处理myProp值(例如验证、转换为其他类型等)
// Store myProp for later retrieval by process() method
// 存储myProp以便稍后通过process()方法检索
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external client
// 初始化与外部客户端的连接
}
@Override
public void stop () {
// Disconnect from external client and do any additional cleanup
// (e.g. releasing resources or nulling-out field values) ..
// 断开与外部客户端的连接并进行任何额外的清理(例如释放资源或清空字段值)。。
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
try {
// This try clause includes whatever Channel/Event operations you want to do
// 此try子句包括要执行的任何通道/事件操作
// Receive new data 接收新数据
Event e = getSomeData();
// Store the Event into this Source's associated Channel(s)
// 将事件存储到此源的关联通道中
getChannelProcessor().processEvent(e);
status = Status.READY;
} catch (Throwable t) {
// Log exception, handle individual exceptions as needed
// 记录异常,根据需要处理个别异常
status = Status.BACKOFF;
// re-throw all Errors 重新抛出所有错误
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}Channel 【渠道】
TBD


![buuctf web [极客大挑战 2019]BabySQL](https://img-blog.csdnimg.cn/0398041fe0594451b91e3270176959bd.png)