目录
1.Decoupled Head介绍
2.Yolov5加入Decoupled_Detect
2.1 DecoupledHead加入common.py中:
2.2 Decoupled_Detect加入yolo.py中:
2.3修改yolov5s_decoupled.yaml
1.Decoupled Head介绍
Decoupled Head是一种图像分割任务中常用的网络结构,用于提取图像特征并预测每个像素的类别。传统的图像分割网络通常将特征提取和像素预测过程集成在同一个网络中,而Decoupled Head则将这两个过程进行解耦,分别处理。
Decoupled Head的核心思想是通过引入额外的分支网络来进行像素级的预测。这个分支网络通常被称为“头”(head),因此得名Decoupled Head。具体而言,Decoupled Head网络在主干网络的特征图上添加一个或多个额外的分支,用于预测像素的类别。
Decoupled Head的优势在于可以更好地处理不同尺度和精细度的语义信息。通过将像素级的预测与特征提取分开,可以更好地利用底层和高层特征之间的语义信息,从而提高分割的准确性和细节保留能力。
Decoupled Head的优点:
-
分离特征提取和像素预测:Decoupled Head将特征提取和像素级预测分离开来,使得网络可以更加灵活地处理不同尺度和语义信息。
-
多尺度特征融合:通过在主干网络的不同层级添加分支,Decoupled Head可以融合来自不同尺度的特征信息,从而提高对多尺度目标的分割能力。
-
更好的像素级预测:由于Decoupled Head将像素级的预测作为独立的任务进行处理,可以更好地保留细节和边缘信息,提高分割的精确性。
-
可扩展性:Decoupled Head结构可以根据需要进行扩展和修改,例如添加更多的分支或调整分支的结构,以适应不同的任务和数据集需求。
YOLOv6 采用了解耦检测头(Decoupled Head)结构,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。
原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,因此加入 Decoupled Head。
为什么要用到解耦头?
因为分类和定位的关注点不同;
分类更关注目标的纹理内容;
定位更关注目标的边缘信息
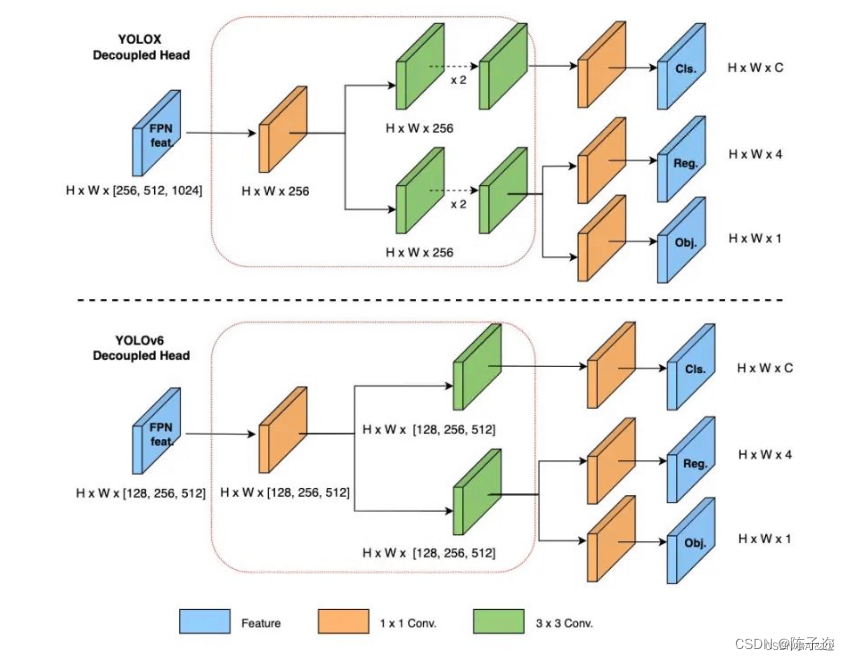
2.Yolov5加入Decoupled_Detect
2.1 DecoupledHead加入common.py中:
#======================= 解耦头=============================#
class DecoupledHead(nn.Module):
def __init__(self, ch=256, nc=80, anchors=()):
super().__init__()
self.nc = nc # number of classes
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.merge = Conv(ch, 256 , 1, 1)
self.cls_convs1 = Conv(256 , 256 , 3, 1, 1)
self.cls_convs2 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs1 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs2 = Conv(256 , 256 , 3, 1, 1)
self.cls_preds = nn.Conv2d(256 , self.nc * self.na, 1) # 一个1x1的卷积,把通道数变成类别数,比如coco 80类(主要对目标框的类别,预测分数)
self.reg_preds = nn.Conv2d(256 , 4 * self.na, 1) # 一个1x1的卷积,把通道数变成4通道,因为位置是xywh
self.obj_preds = nn.Conv2d(256 , 1 * self.na, 1) # 一个1x1的卷积,把通道数变成1通道,通过一个值即可判断有无目标(置信度)
def forward(self, x):
x = self.merge(x)
x1 = self.cls_convs1(x)
x1 = self.cls_convs2(x1)
x1 = self.cls_preds(x1)
x2 = self.reg_convs1(x)
x2 = self.reg_convs2(x2)
x21 = self.reg_preds(x2)
x22 = self.obj_preds(x2)
out = torch.cat([x21, x22, x1], 1) # 把分类和回归结果按channel维度,即dim=1拼接
return out
class Decoupled_Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(DecoupledHead(x, nc, anchors) for x in ch)
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid(y, x, indexing='ij')
else:
yv, xv = torch.meshgrid(y, x)
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid2.2 Decoupled_Detect加入yolo.py中:
class BaseModel(nn.Module):
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment,Decoupled_Detect)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return selfclass DetectionModel(BaseModel):
def _initialize_dh_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
# reg_bias = mi.reg_preds.bias.view(m.na, -1).detach()
# reg_bias += math.log(8 / (640 / s) ** 2)
# mi.reg_preds.bias = torch.nn.Parameter(reg_bias.view(-1), requires_grad=True)
# cls_bias = mi.cls_preds.bias.view(m.na, -1).detach()
# cls_bias += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
# mi.cls_preds.bias = torch.nn.Parameter(cls_bias.view(-1), requires_grad=True)
b = mi.b3.bias.view(m.na, -1)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
mi.b3.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
b = mi.c3.bias.data
b += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.c3.bias = torch.nn.Parameter(b, requires_grad=True) if isinstance(m, (Detect, Segment,ASFF_Detect)):
s = 256 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_biases() # only run once
elif isinstance(m, Decoupled_Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m) # must be in pixel-space (not grid-space)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_dh_biases() # only run oncedef parse_model(d, ch): # model_dict, input_channels(3)
elif m in {Detect, Segment,Decoupled_Detect}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)2.3修改yolov5s_decoupled.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5),解耦
]