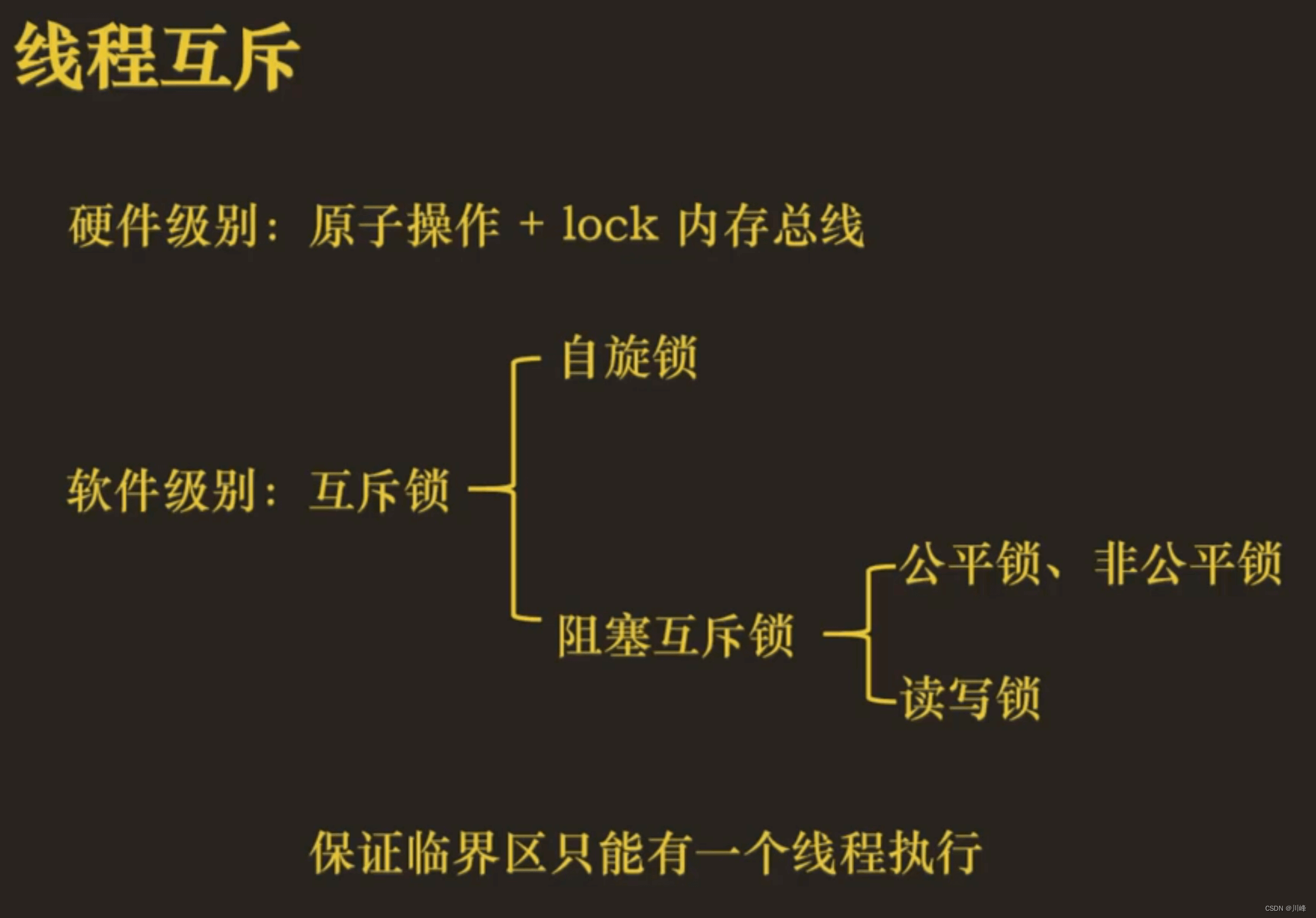
用户态抢占和内核态抢占
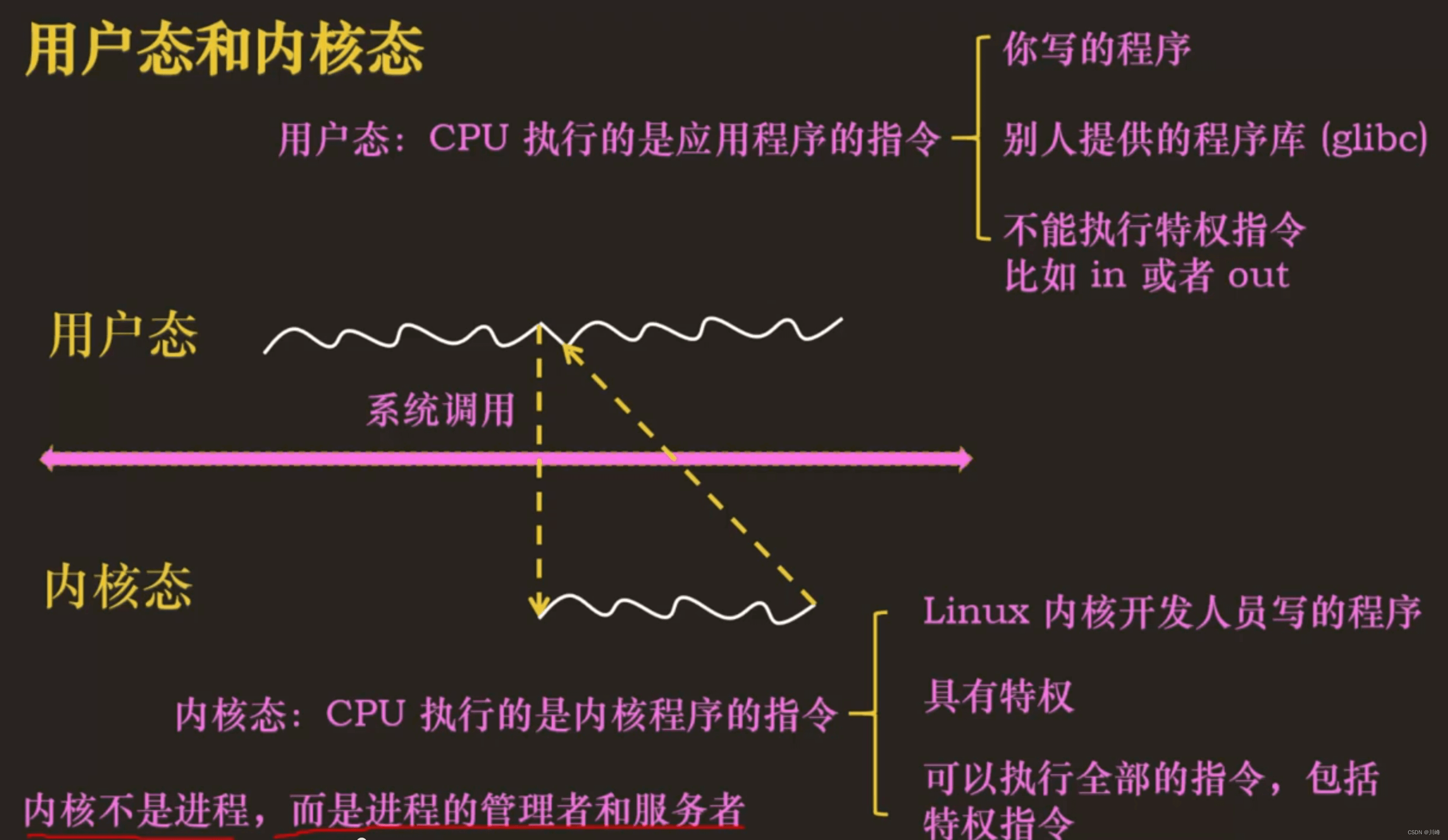
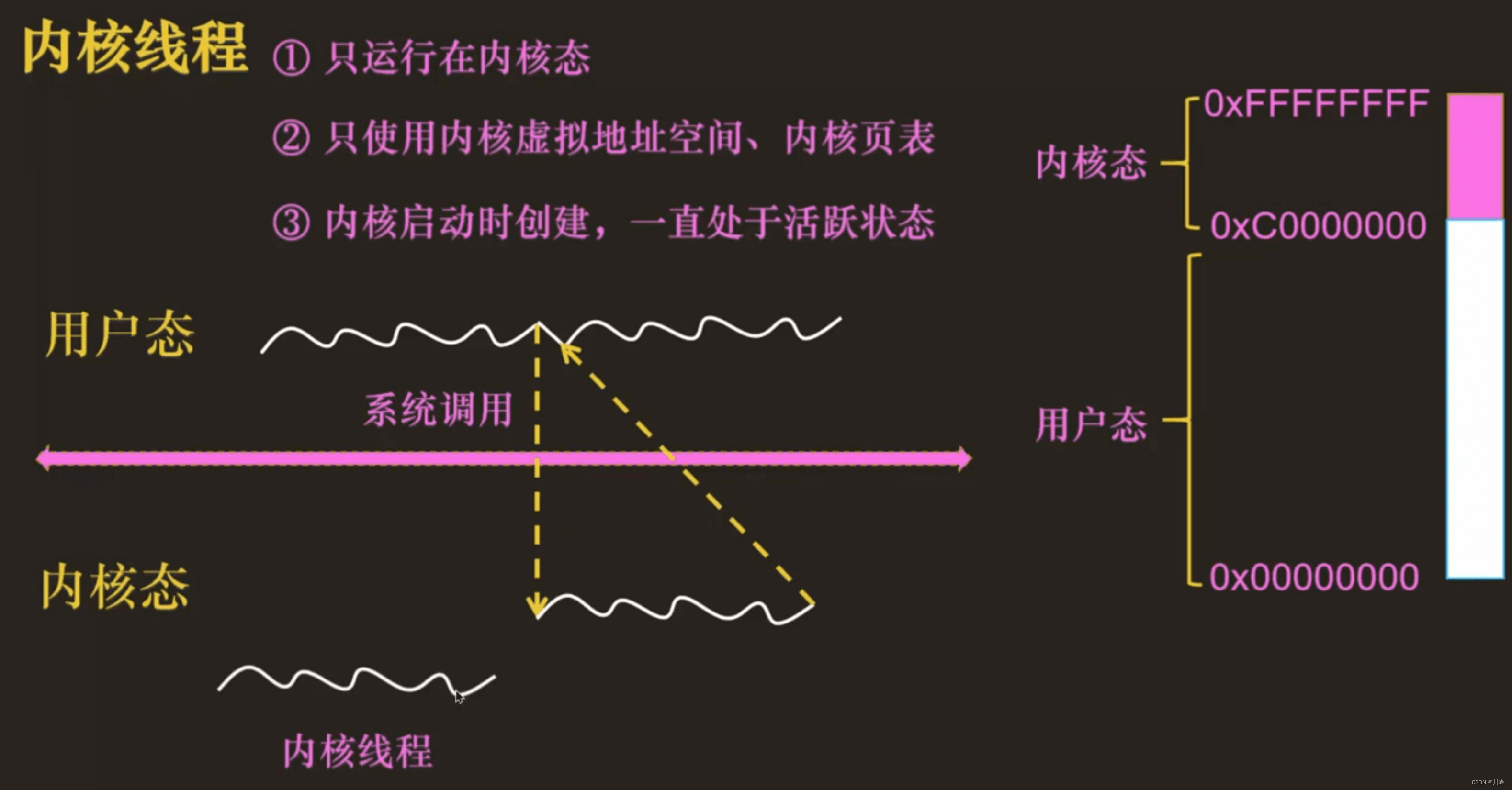
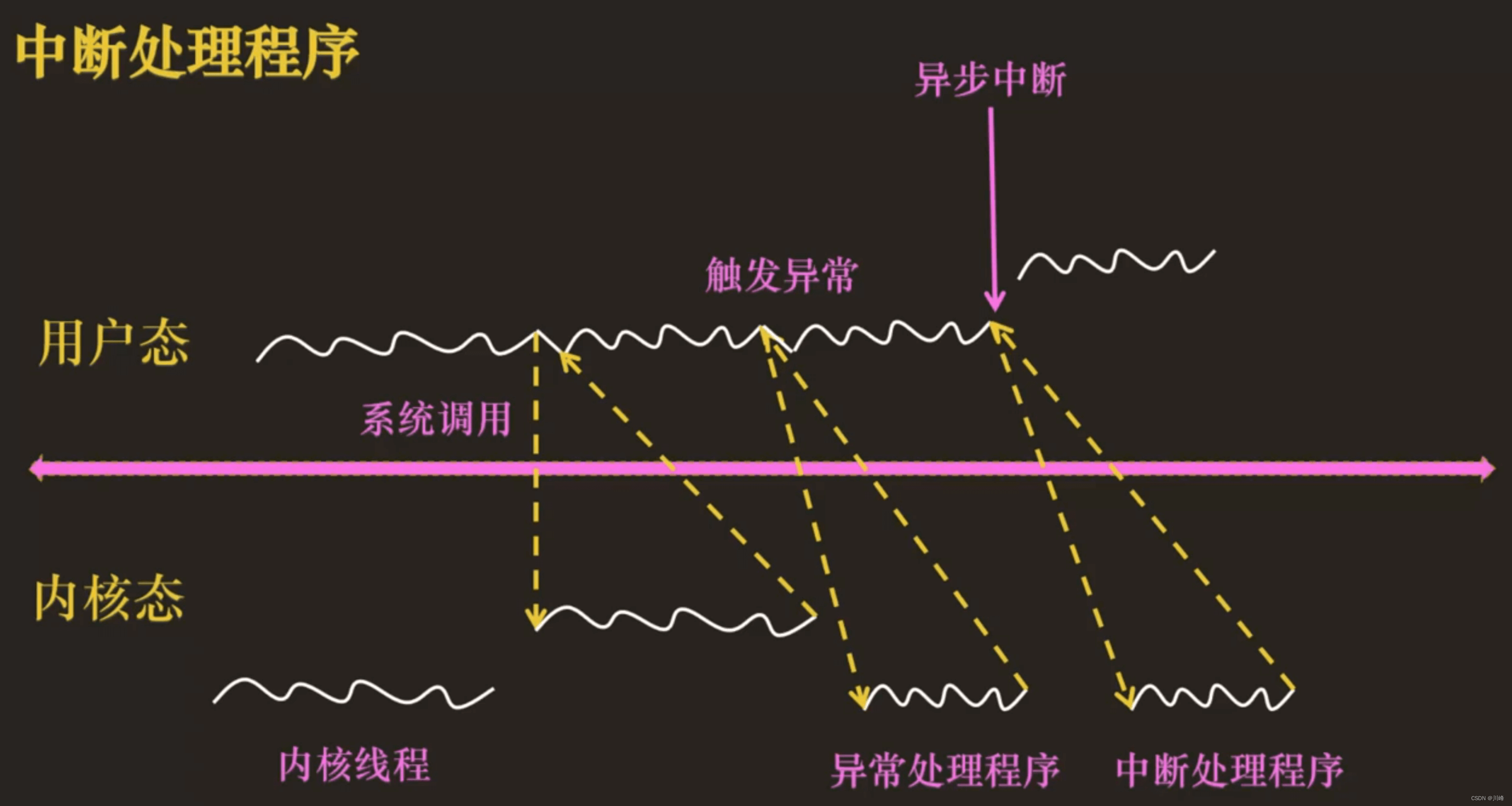
内核中可以执行以下几种程序:
- ① 当前运行的进程:陷阱程序(系统调用) 和 故障程序(page fault) ,进程运行在内核态的时候,其实就是在执行进程在用户态触发的异常对应的异常处理程序
- ② 中断处理程序
- ③ 内核线程
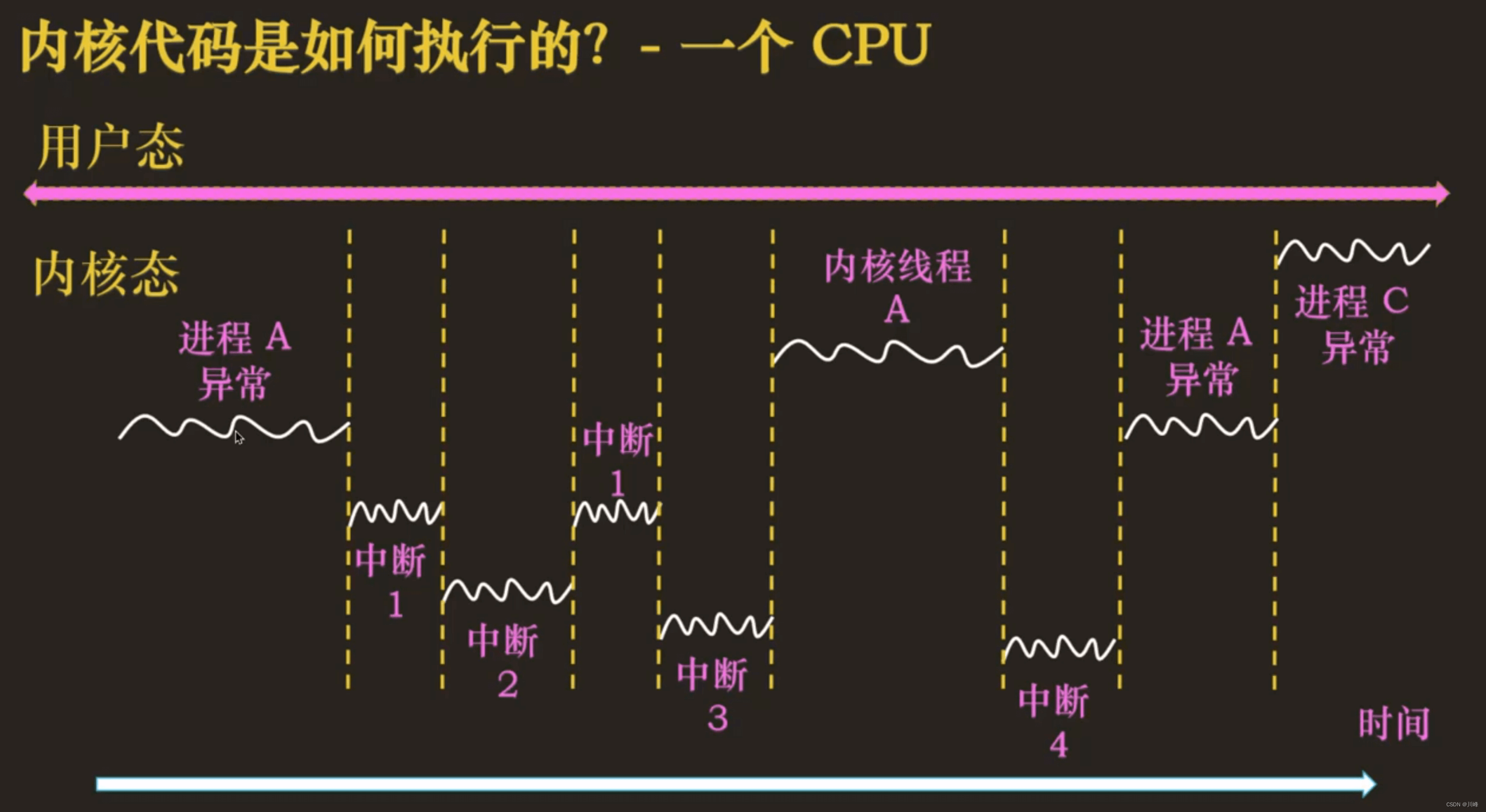

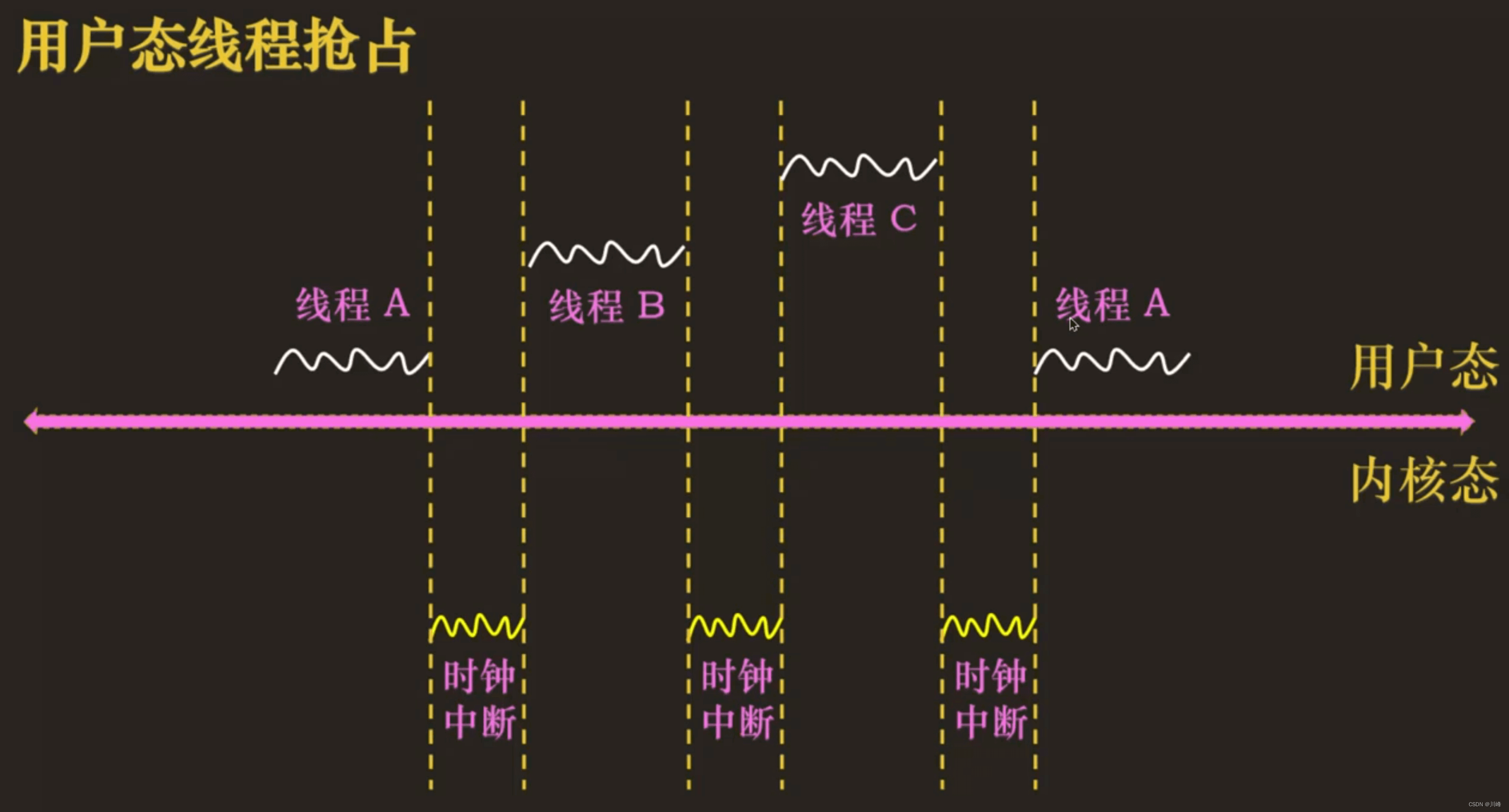
用户态线程抢占的调度时机
检查当前线程是否需要被抢占的时机点(检查点):
- 时钟中断发生,在时钟中断处理程序中判断进程实际运行的时间大于规定运行的最长时间且运行队列有优先级更高的任务
当前线程被抢占的时机点(抢占点):
- 从中断处理程序回到用户态之前
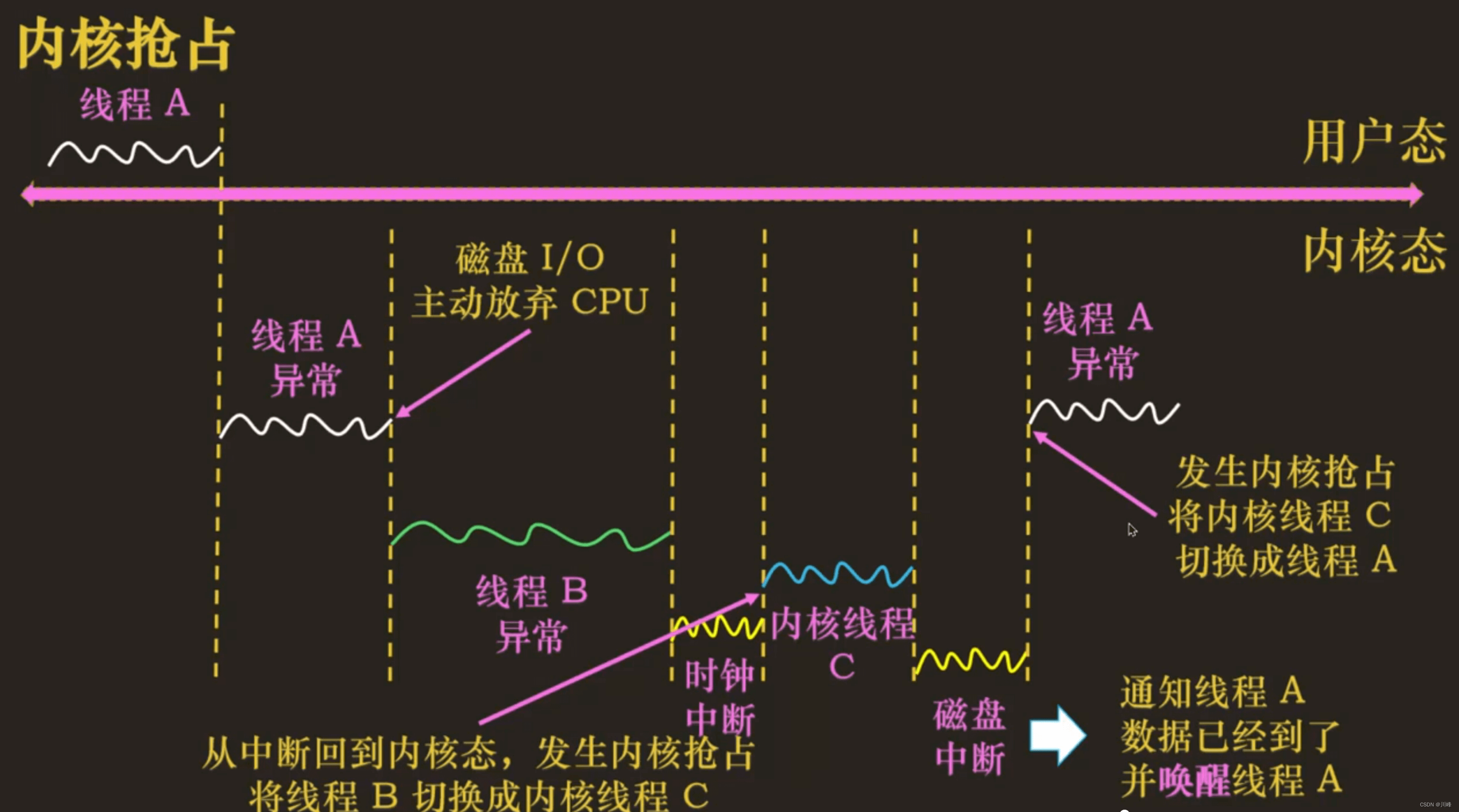
内核抢占的调度时机
检查当前线程是否需要被抢占的时机点(检查点):
-
① 时钟中断发生,在时钟中断处理程序中判断进程实际运行的时间大于规定运行的最长时间且运行队列有优先级更高的任务
-
② 线程被唤醒的时候,唤醒的任务虚拟运行时间更小(优先级高)比如,磁盘 I/O 中断唤醒正在等待数据的线程。比如,fork/ clone 创建的新进程/线程,被唤醒时。
当前线程被抢占的时机点(抢占点):
- ① 从中断处理程序回到内核态之前
- ② 开启抢占(
preemt_enable)的时候 - 条件:标记了
tlf_need_sched且抢占计数器等于 0(开启抢占)
疑问点:时钟中断发生时,当前任务被抢占的条件到底是什么呢?
其实这个是要区分任务类型的,如果当前运行的任务是普通任务的话,那么就需要根据任务运行时间和它的 vruntime 来决定要不要抢占当前进程,如下代码逻辑:

如果当前运行的任务是实时任务的话,那么就是根据 RR 调度算法来决定要不要抢占当前任务,如下图:

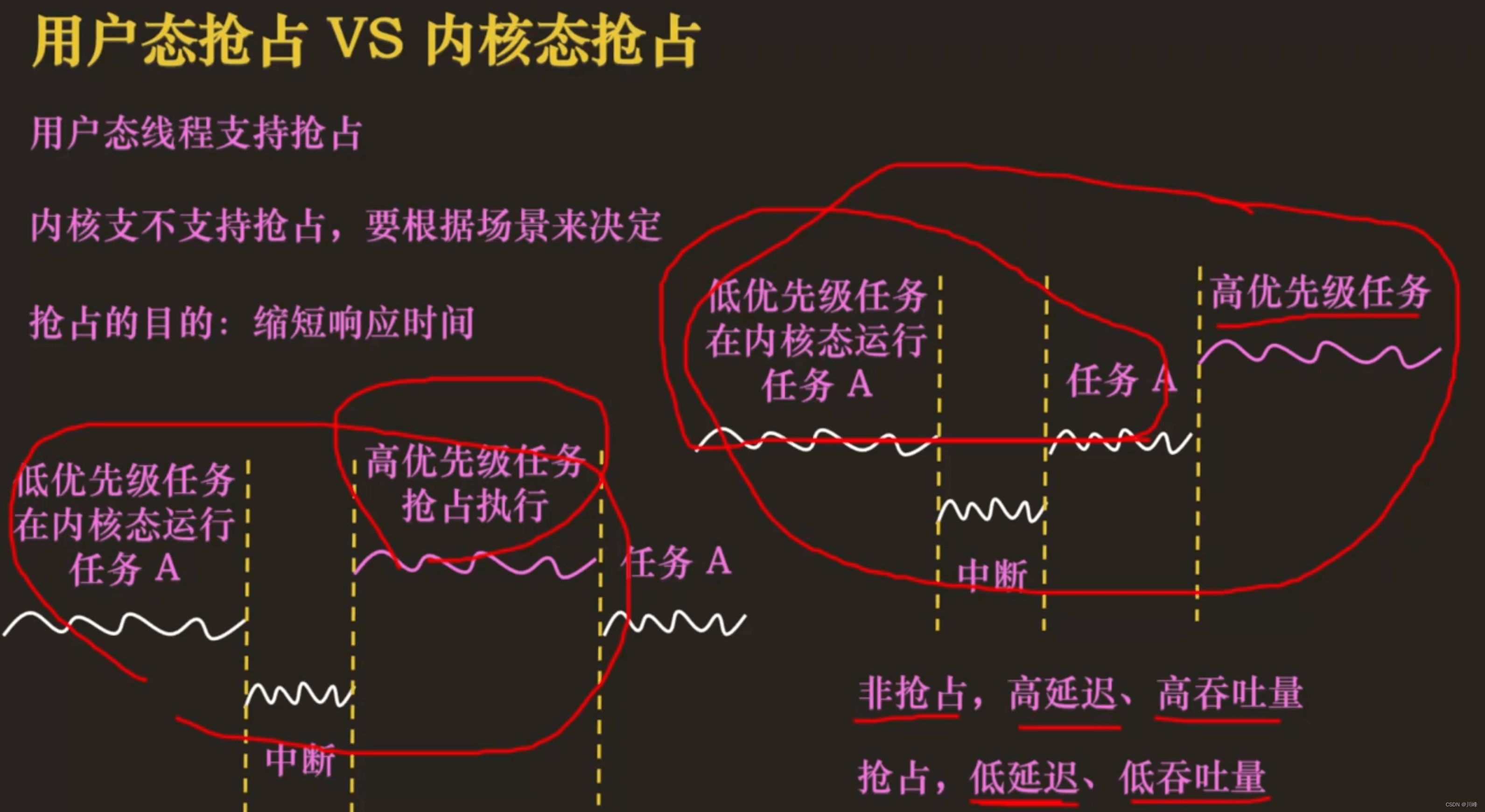
根据使用场景来决定要不要配置内核抢占:
PREEMPT_NONE:不支持抢占,吞吐量优先,后台计算场景(处理数据)PREEMPT_VOLUNTARY: 内核中放置了一些抢占点,桌面应用PREEMPT:支持内核抢占,低延迟的桌面应用、嵌入式
支持内核抢占的内核,称为抢占式内核,不支持内核抢占的内核,称为非抢占式内核。
数据并发访问安全问题
内核中:每个内核程序都可以访问所有的物理内存
-
① 两个中断处理程序同时访问一个全局数据
-
② 中断处理程序和内核态中运行的线程同时访问一个全局数据
-
③ 两个运行在内核态的线程同时访问一个全局数据
用户态:
-
① 运行在同一个进程中的多个线程,共享全局内存
-
② 进程与进程之间也可以共享内存,进程间通信
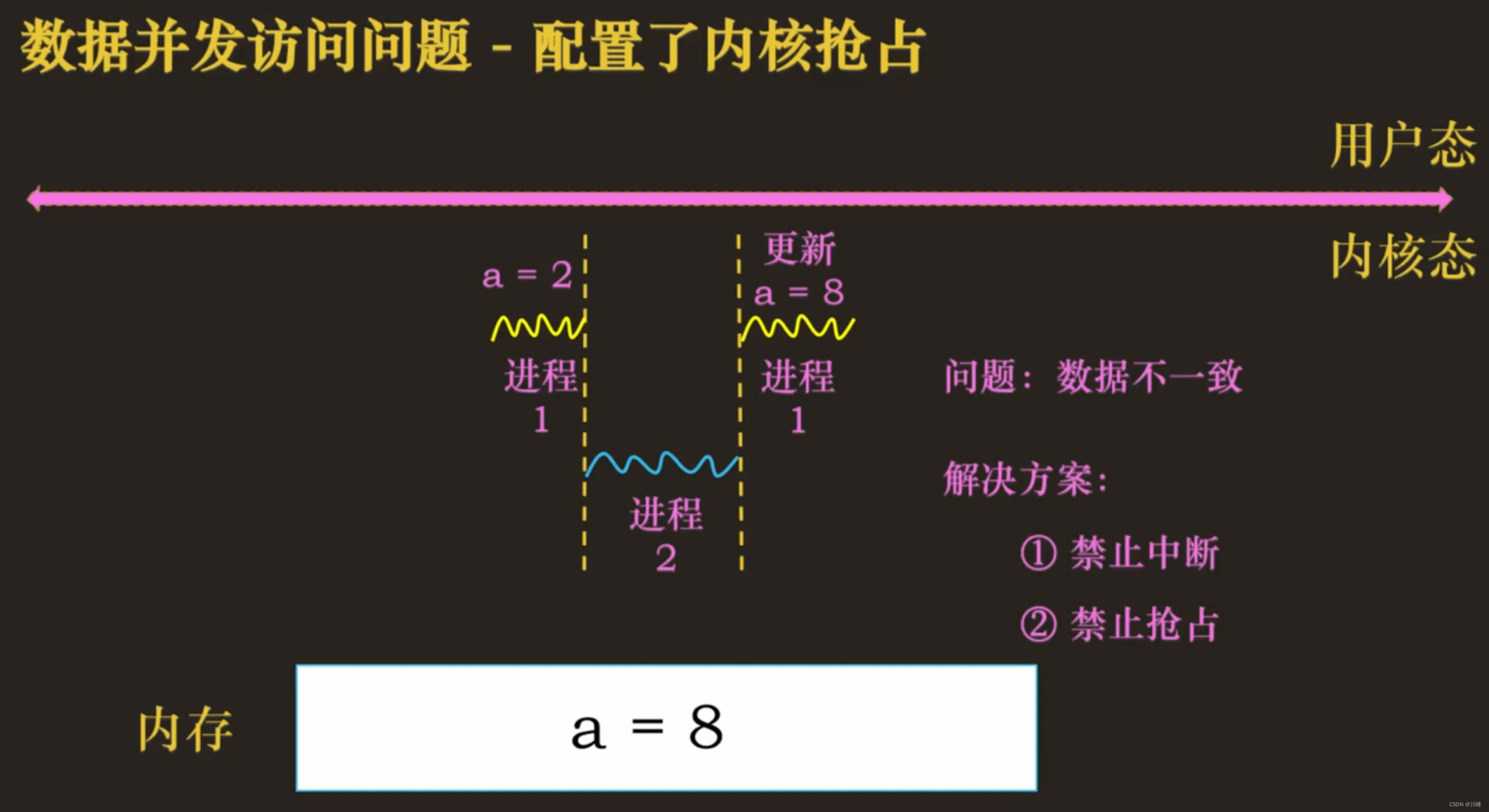
- 内核可配置为抢占和非抢占,在抢占式内核中,多个线程同时访问共享内存时,会发生并发安全问题。
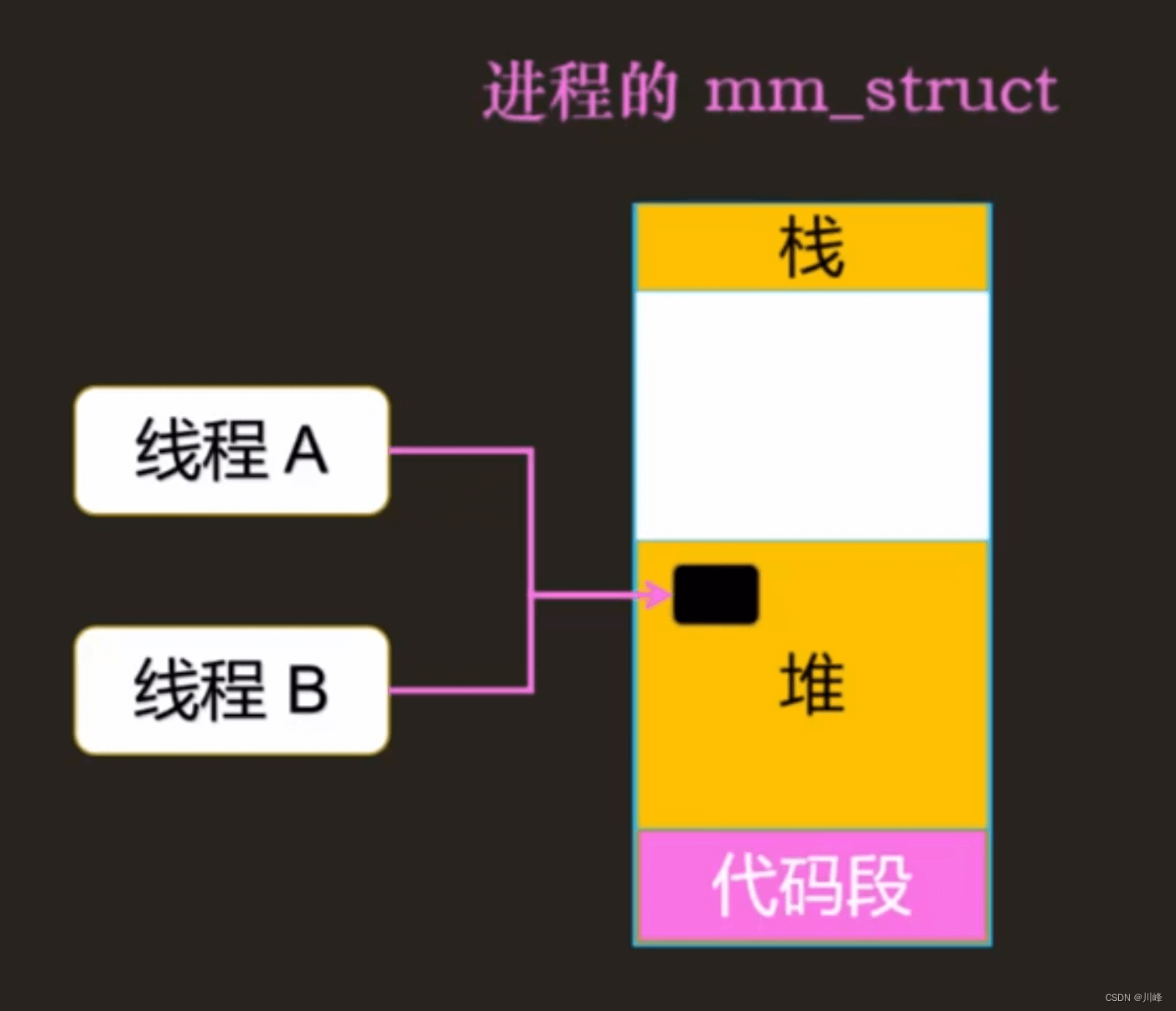
两个线程访问一个全局变量
一个进程中的所有线程共享这个进程的虚拟地址空间,多个线程可以同时访问一个全局变量。
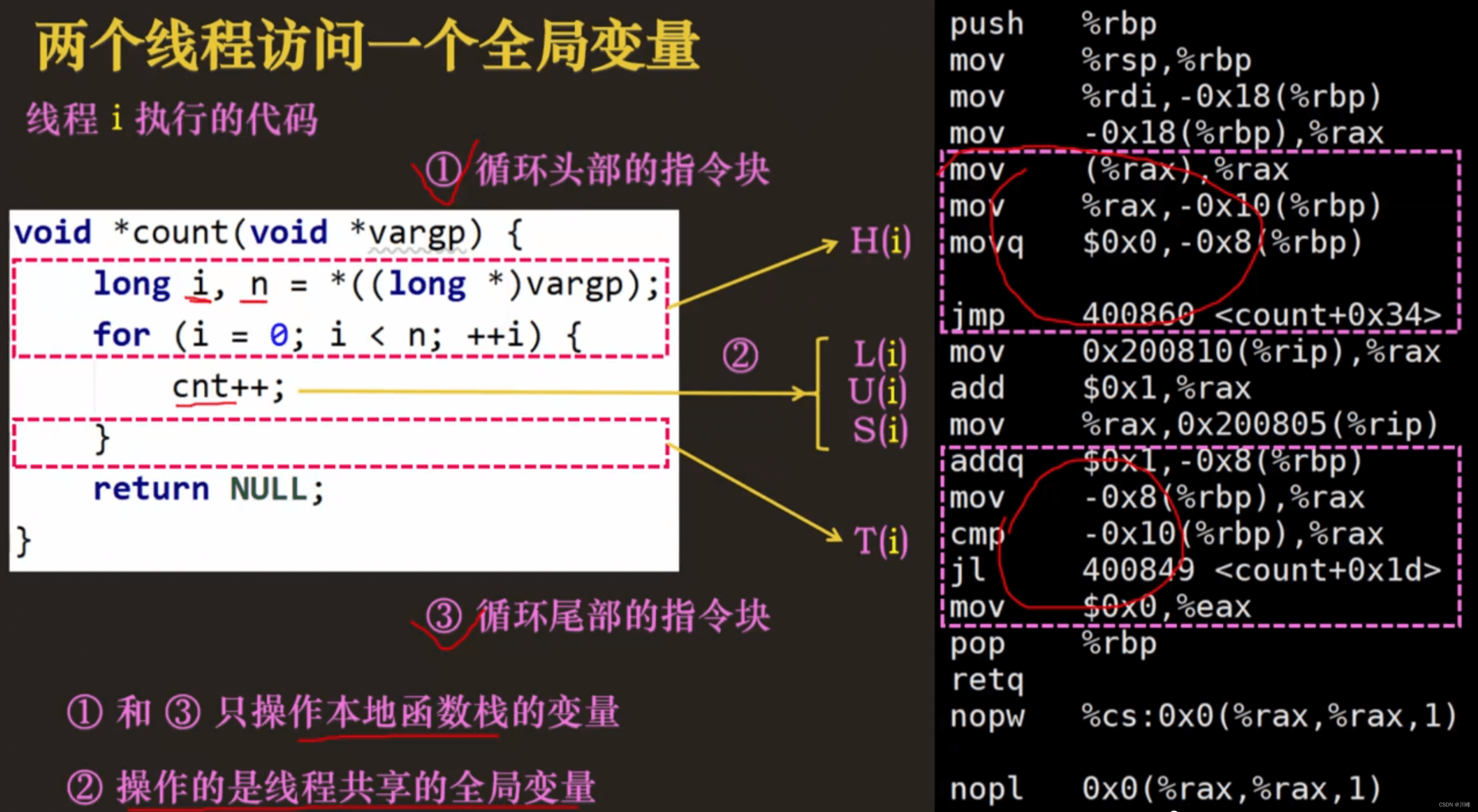
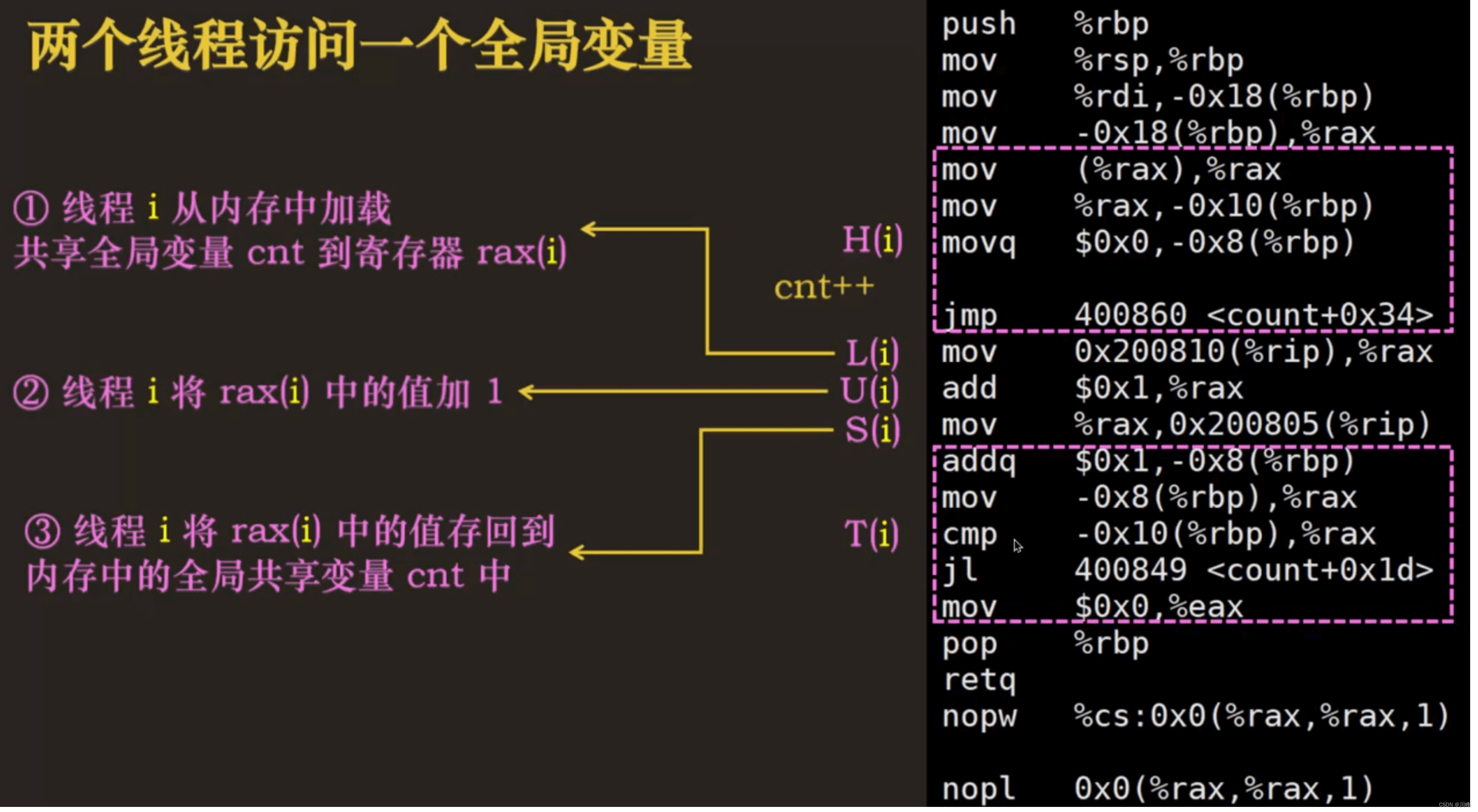
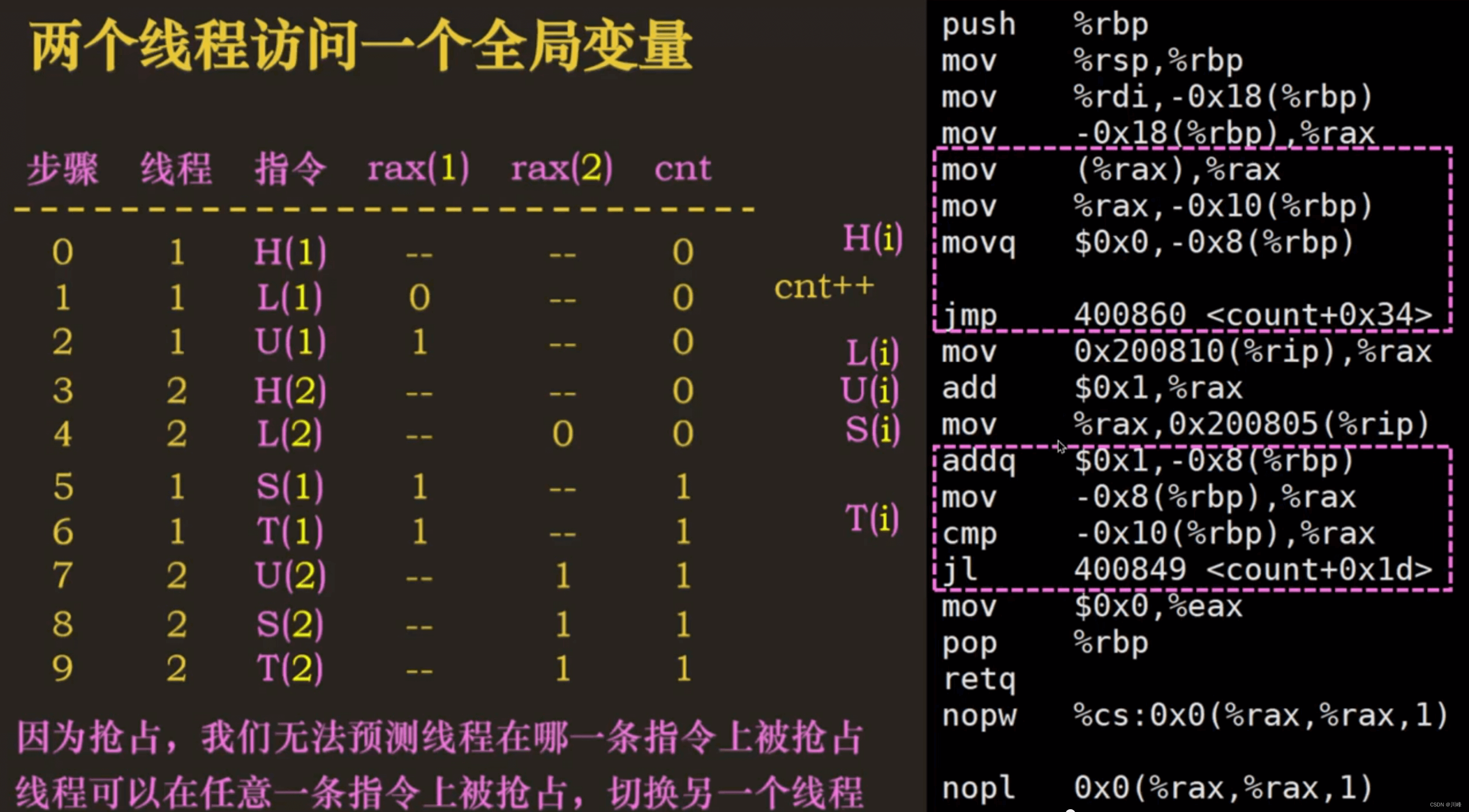
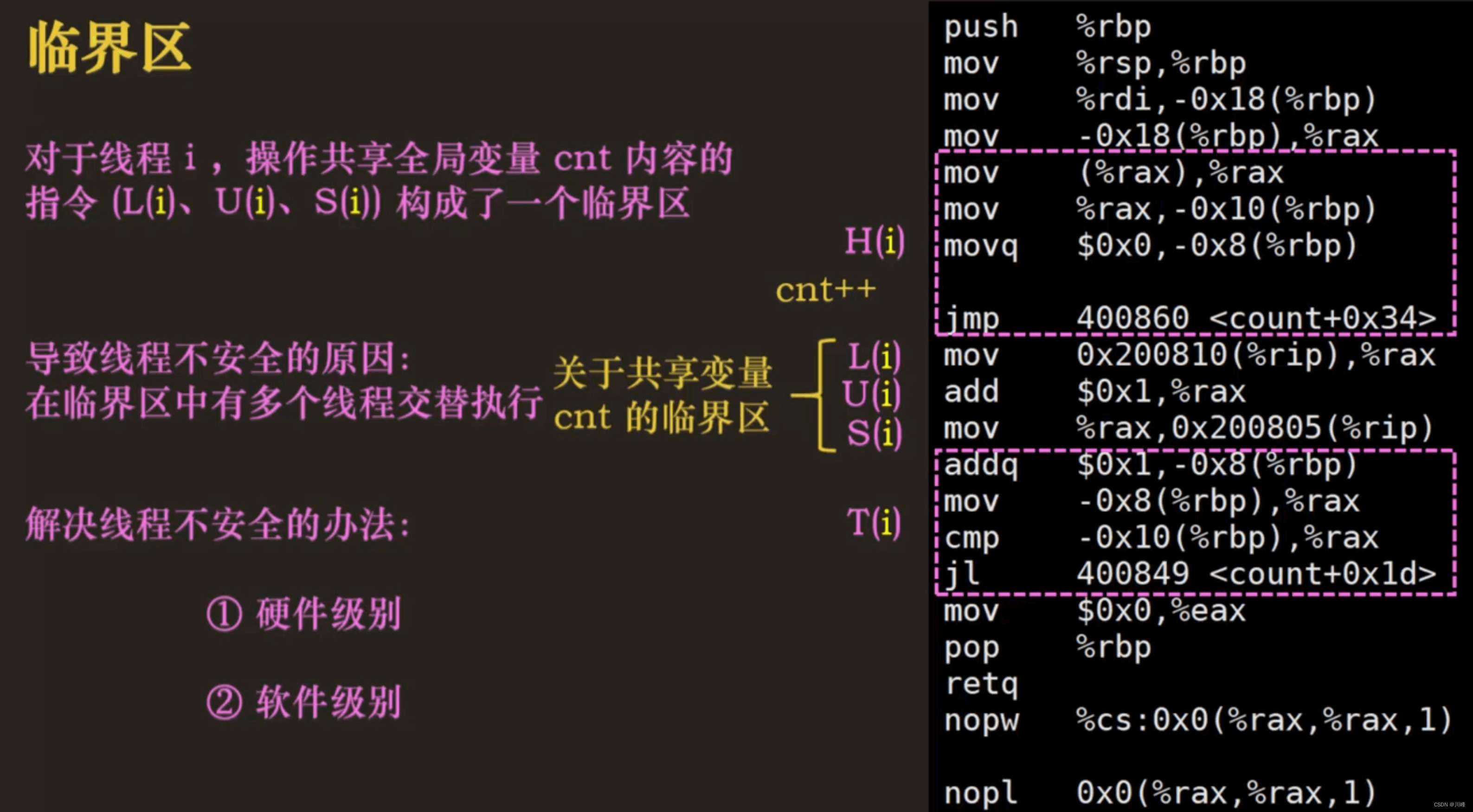
- 并发问题的根本原因是操作临界区的共享全局变量的操作不是原子操作,在高级开发语言中的一行代码可能对应多条底层汇编指令代码,如
cnt++,在底层可能对应三条汇编指令,分别是从内存读取cnt保存到寄存器、将寄存器中的cnt+1,将寄存器中的cnt写回到内存,而因为抢占,我们无法预测线程在哪一条指令上被抢占,线程可能在任意指令上被抢占后切换到另一个线程去执行。

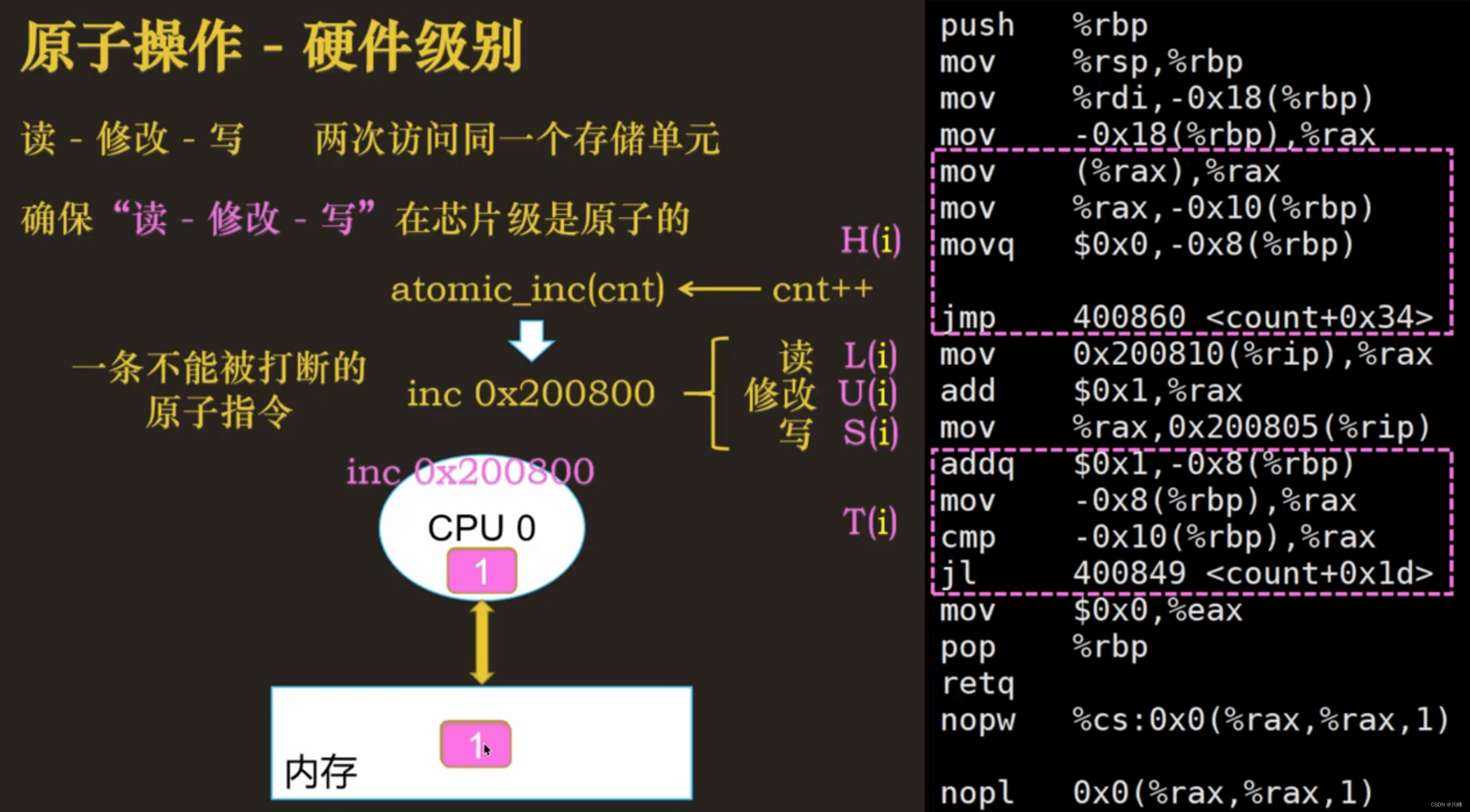
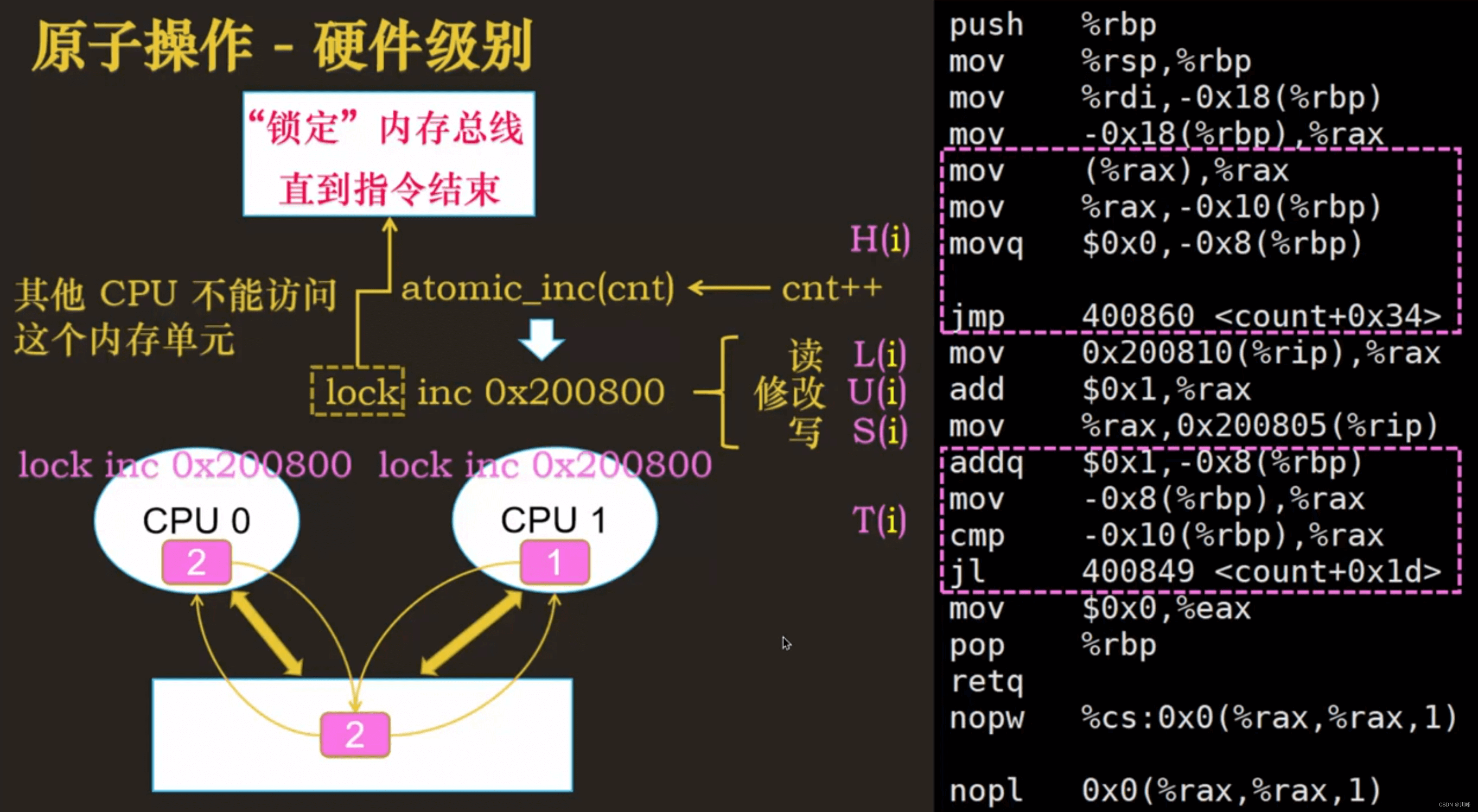


-
使用对应底层是原子操作的指令代码,如atomic一类的api,使用不能被打断的原子指令,确保指令执行时不会被中断或抢占,两次读写访问的是同一个内存单元
-
使用
lock加锁技术锁定内存总线,在指令执行结束之前,其他CPU不能访问这个内存单元 -
原子操作需要硬件级别保证,高级语言中都有对应的原子操作类
CAS 的 ABA 问题
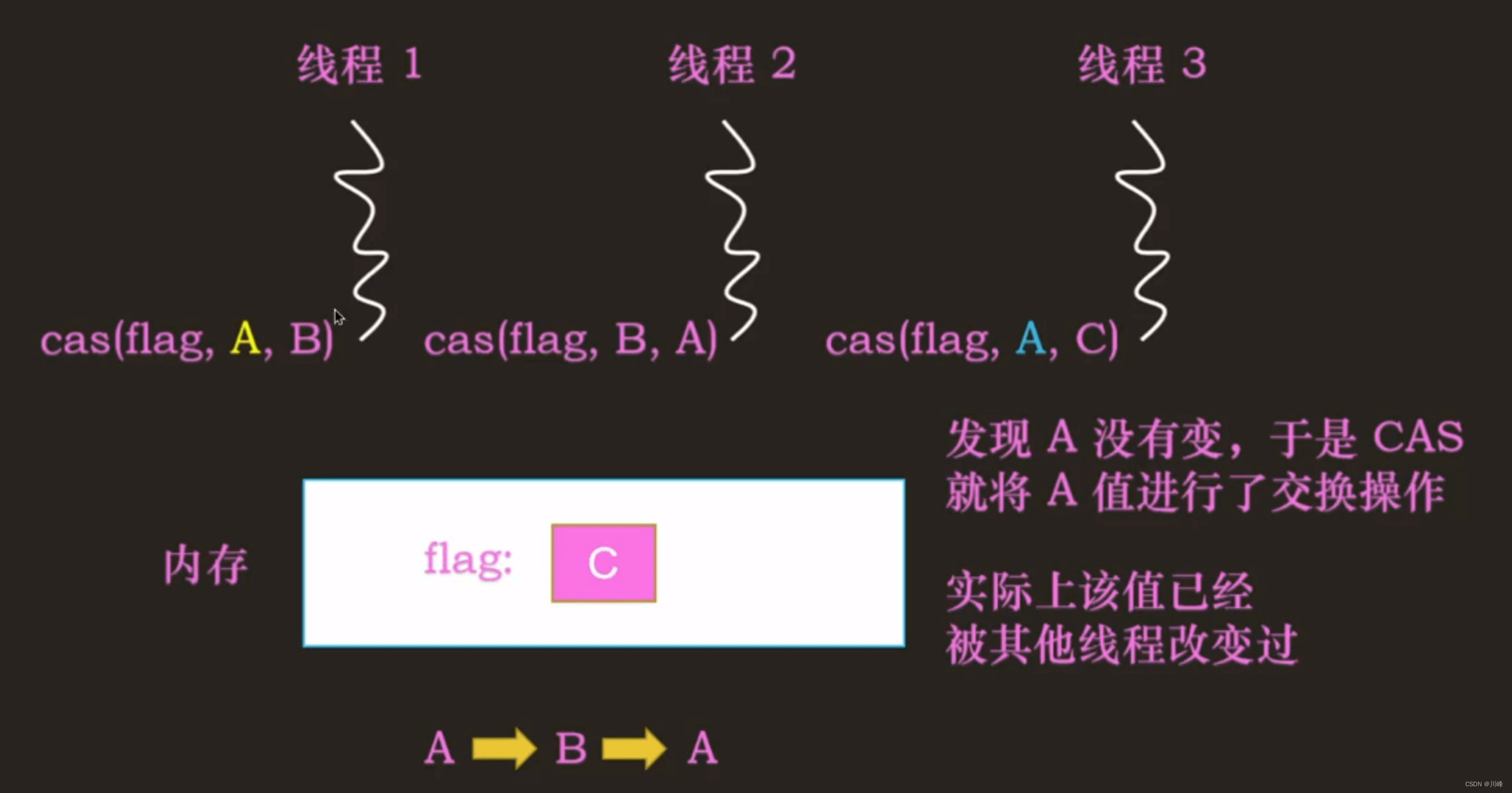

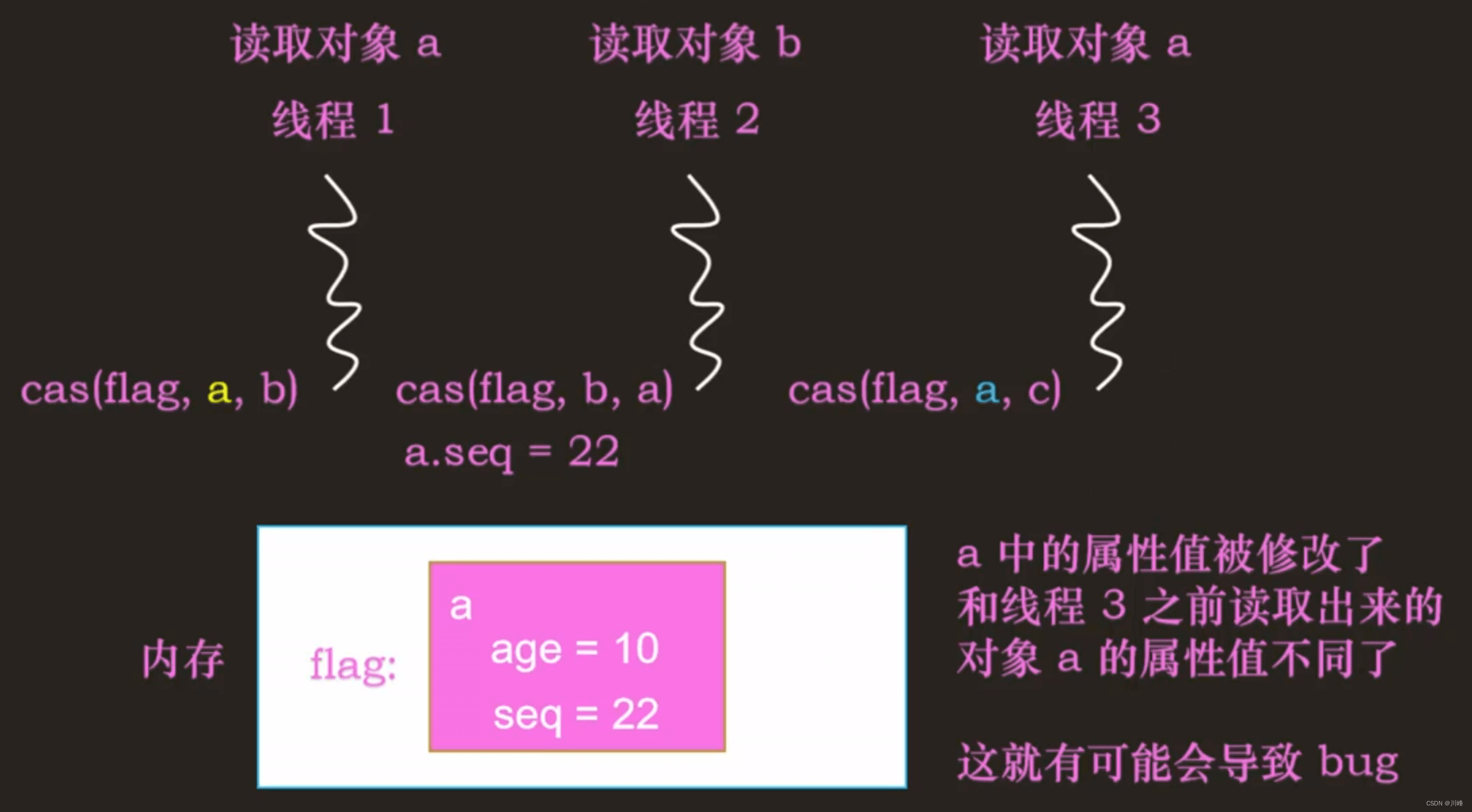

说白了,就是某个变量中间被别人改过了(A->B),但是又改回去了(B->A),但是我们不知道它中间是否被人改过,此时必须通过增加版本号,也就是添加额外标志信息,来比较是否曾经被改过,每改一次版本号就加 1,这样比较时,除了变量值一样,版本号也必须一致,才认为是没有被修改过的。否则,就是被动过的。
CAS 自旋锁


普通的自旋锁存在并发问题。

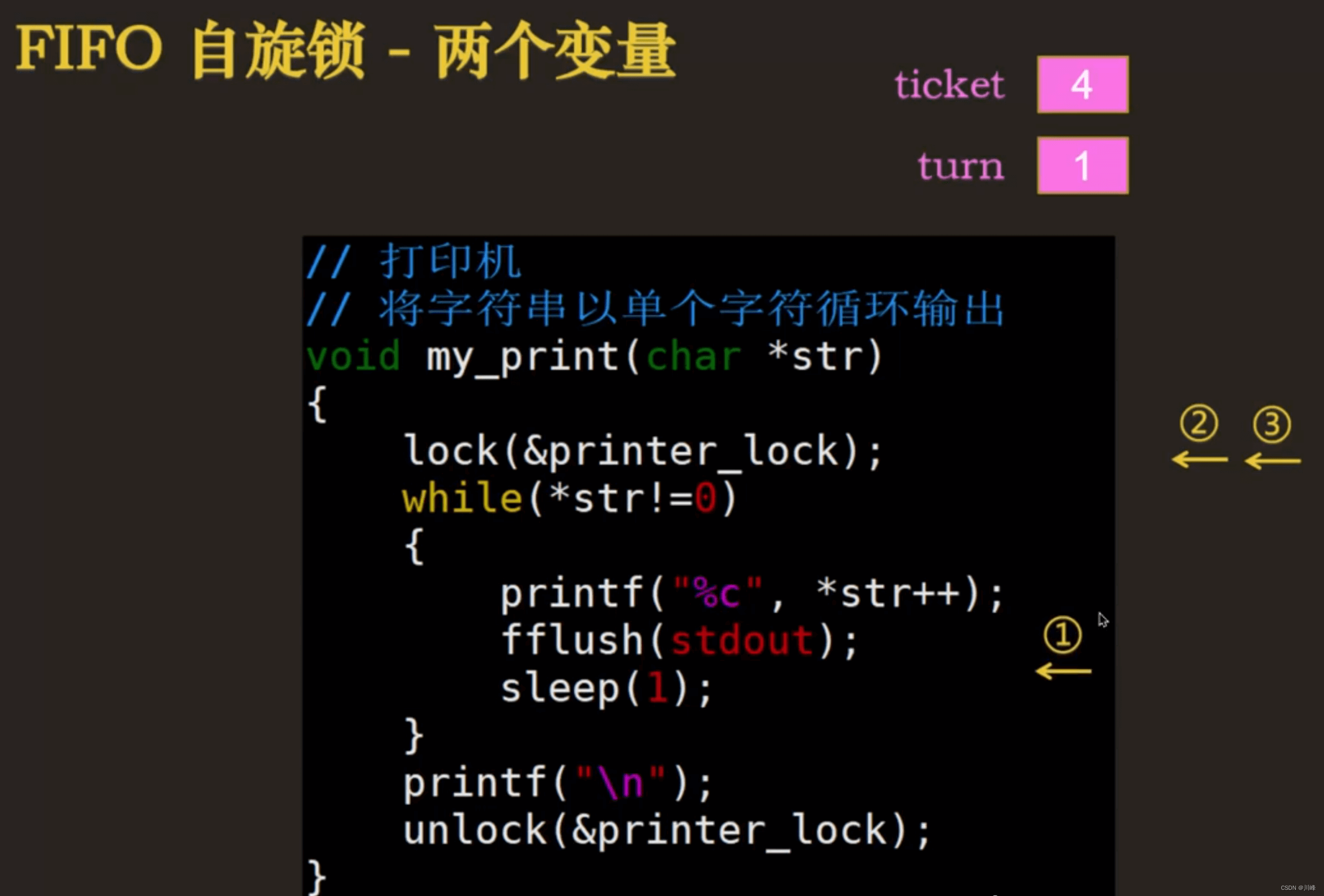
typedef struct _lock_t {
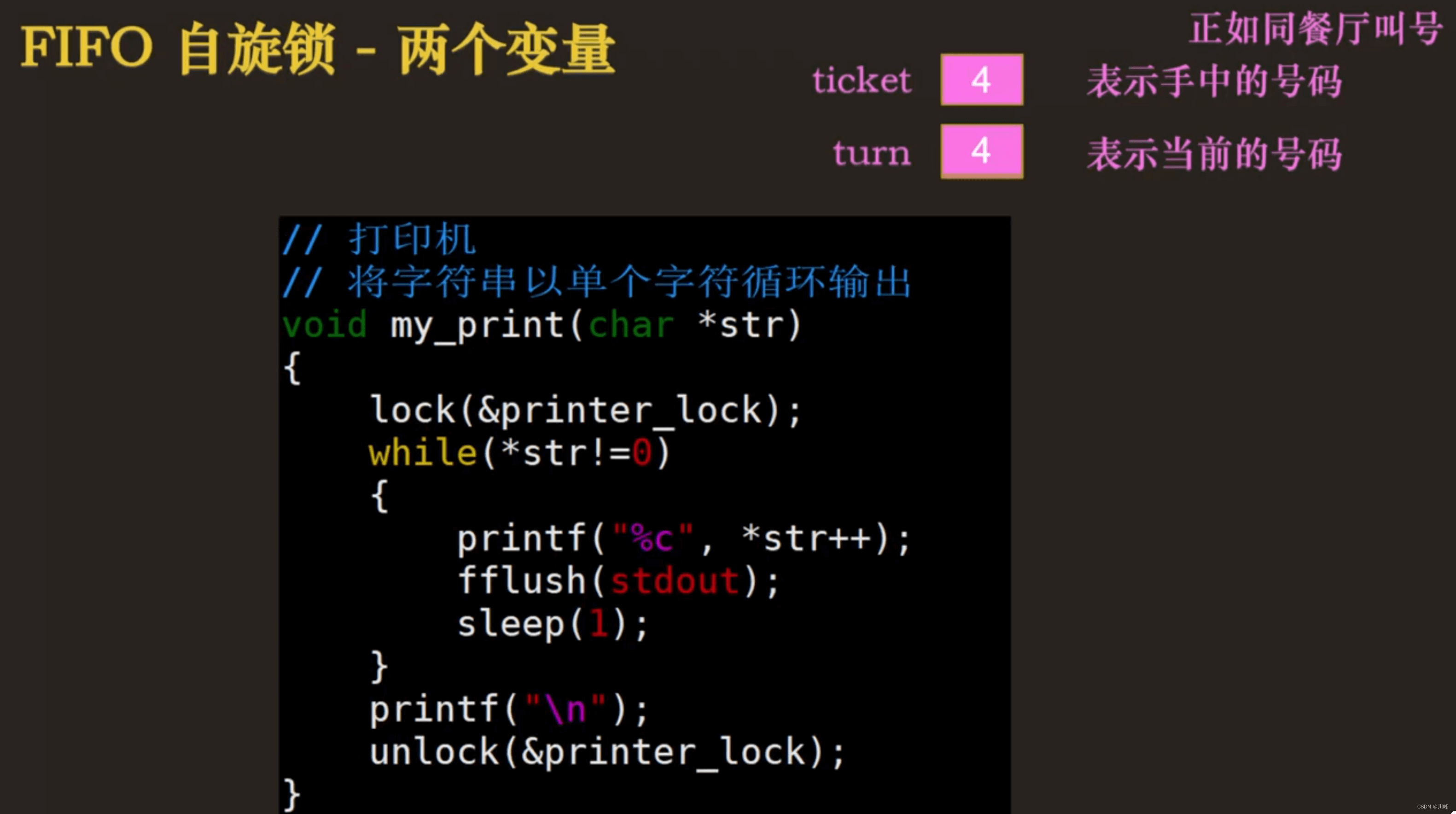
// 正如同餐厅叫号,turn表示当前的号码,ticket表示手中的号码
atomic_int ticket;
atomic_int turn;
} lock_t;
void init(lock_t *mutex) {
mutex->ticket = 0;
mutex->turn = 0;
}
void lock(lock_t *mutex) {
int my_turn = atomic_fetch_add(&mutex->ticket, 1);
while (mutex->turn != my_turn); // spin
}
void unlock(lock_t *mutex) {
// 每一个顾客(线程)用完之后就呼叫下一个号码。
mutex->turn++;
}
CAS 自旋锁的问题 — 浪费 CPU
- 由于自旋锁导致每个线程都在执行
while操作,占用 CPU 时间 - 如果进入临界区的线程执行的时间过长的话,那么等待的线程,一直占用着 CPU,导致极大的 CPU 资源浪费
解决方案:
- ① 将没有拿到锁的线程,放入到等待队列中
- ② 阻塞没有拿到锁的线程,放弃CPU执行权
- ③ 当正在执行临界区的线程,离开临界区的时候,从等待队列中唤醒一个线程

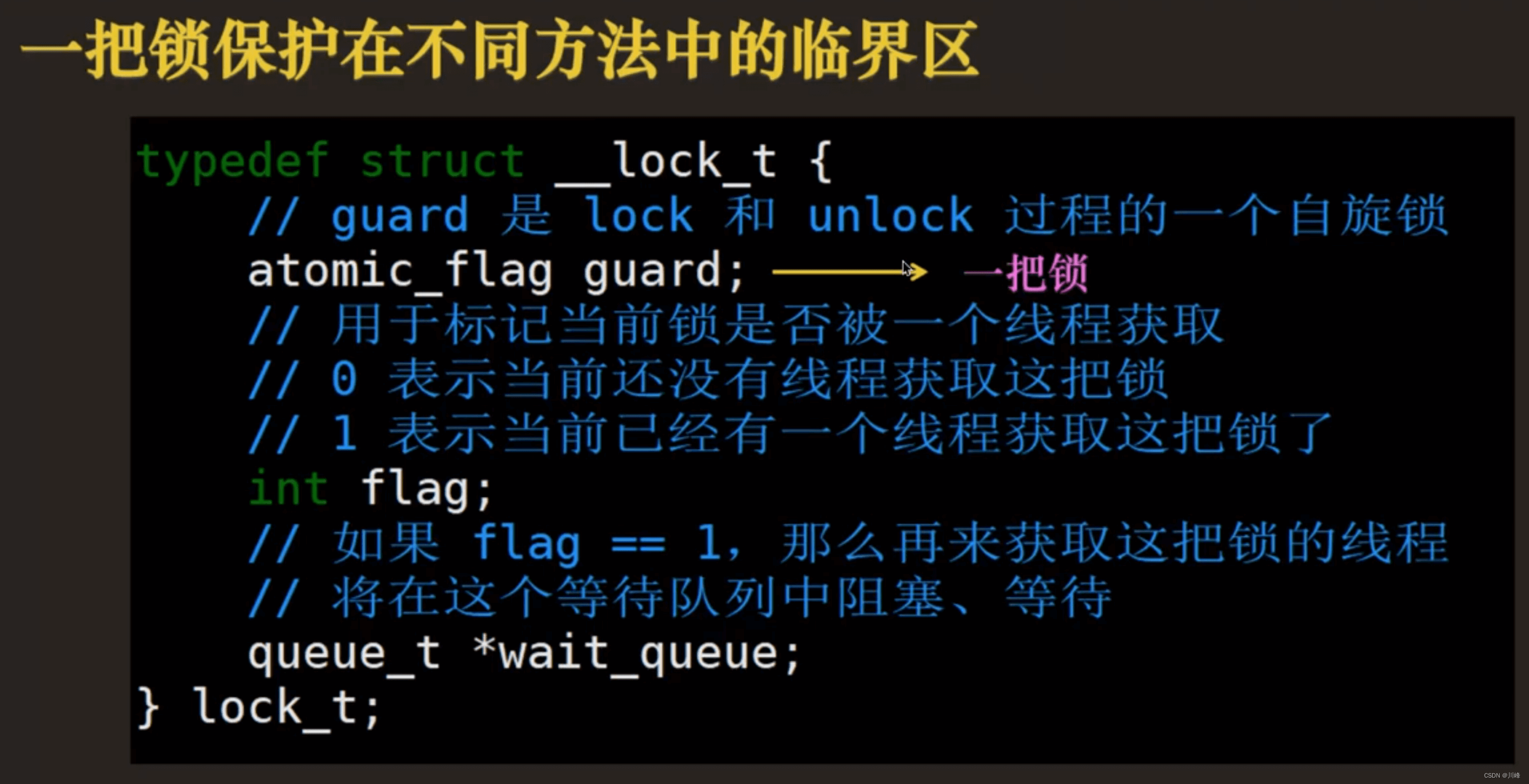
#include <stdatomic.h>
#include <sys/types.h>
#include <unistd.h>
#include "queue.c"
typedef struct _lock_t {
// guard 是 lock 和 unlock 过程的一个自旋锁
atomic_flag guard;
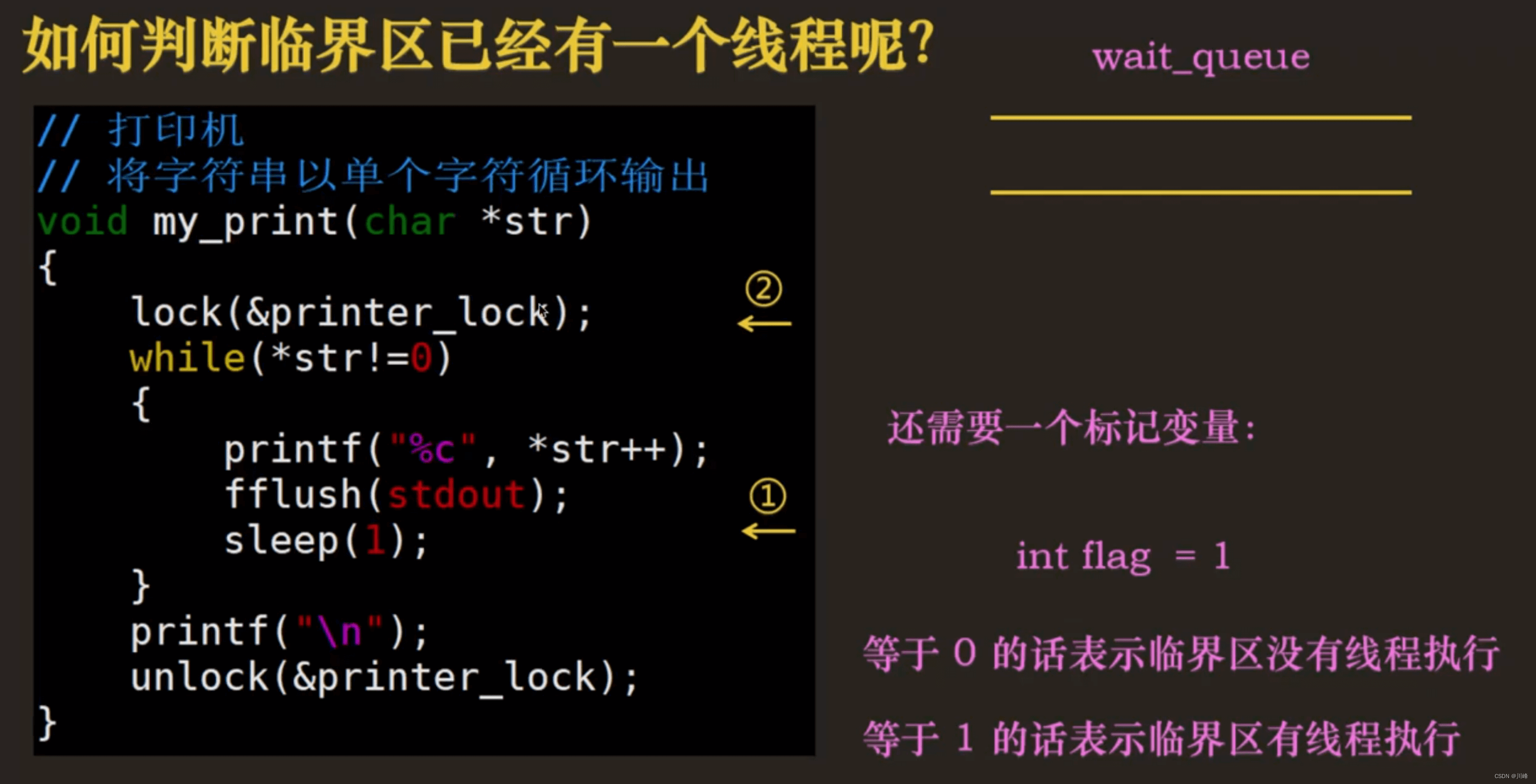
// 用于标记当前锁是否被一个线程获取
// 0表示当前还没有线程获取这把锁
// 1表示当前已经有一个线程获取这把锁了
int flag;
// 如果 flag==1,那么再来获取这把锁的线程
// 将在这个等待队列中阻塞、等待
queue_t *wait_queue;
} lock_t;
void init(lock_t *mutex) {
queue_init(mutex->wait_queue);
mutex->flag = 0;
}
void lock(lock_t *mutex) {
while(atomic_flag_test_and_set(&mutex->guard)); // spin
if (mutex->flag == 0) {
mutex->flag = 1;
atomic_flag_clear(&mutex->guard);
} else {
// 将当前线程 pid 放入到队列中
queue_add(mutex->queue, gettid());
atomic_flag_clear(&mutex->guard);
// 伪代码,阻塞当前线程,需要发起一次系统调用
park();
}
}
void unlock(lock_t *mutex) {
while(atomic_flag_test_and_set(&mutex->guard)); // spin
if (queue_empty(mutex->wait_queue)) {
mutex->flag = 0;
} else {
// 伪代码,唤醒队列中队头的线程,需要发起系统调用
unpark(queue_remove(mutex->wait_queue));
// flag 值本来就是 1,这里加不加没关系
mutex->flag = 1;
}
atomic_flag_clear(&mutex->guard);
}
相当于先用一把自旋锁来保证锁内全局共享变量的安全,这里设置flag和队列入队出队操作非常快,因此不会导致自旋锁执行while等待太久导致CPU浪费。
C语言中的互斥锁API:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
pthread_mutex_t mut;
// 打印机
// 将字符串以单个字符循环输出
void my_print(char *str)
{
pthread_mutex_lock(&mut);
while(*str!=0)
{
printf("%c", *str++);
fflush(stdout);
sleep(1);
}
printf("\n");
pthread_mutex_unlock(&mut);
}
int main(int argc, char const *argv[])
{
void *arg = NULL; // 1.初始化锁
pthread_mutex_init(&mut, NULL);
pthread_t tid, tid2, tid3, tid4;
pthread_create(&tid, NULL, print_word, "11111111");
pthread_create(&tid2, NULL-, print_word, "22222222");
pthread_create(&tid3, NULL, print_ word, "33333333");
pthread_create(&tid4, NULL, print_word, "44444444");
pthread_join(tid, &arg); // 等待,阻塞
pthread_join(tid2, &arg); // 等待,阻塞
pthread_join(tid3, &arg); // 等待,阻塞
pthread_join(tid4, &arg); // 等待,阻塞
return 0;
}
阻塞互斥锁 VS 自旋锁
阻塞互斥锁基于自旋锁实现,操作等待队列,执行的时间非常短。
-
如果临界区执行的时间非常短,选择自旋锁
-
如果临界区执行的时间比较长,选择阻塞互斥锁
阻塞时,需要发生系统调用,以及线程切换,需要开销。如果临界区执行的时间非常短,使用阻塞互斥锁,得不偿失。不管用什么锁,都需要系统开销,安全和性能需要权衡。
真实的互斥锁实现:先使用自旋锁,过了一段时间还没有拿到锁,此时再进行阻塞。 自旋+互斥启发式的锁。
总结:
-
CAS 实现自旋锁:使用一个
atomic类型的全局变量flag表示临界区是否有线程在执行,① 当
flag==1时,说明临界区有一个线程在执行,此时while执行空转等待;
② 若flag==0时,说明临界区没有线程在执行,跳出while继续往下执行,并将flag设置为1,在退出临界区时解锁将flag置为0 -
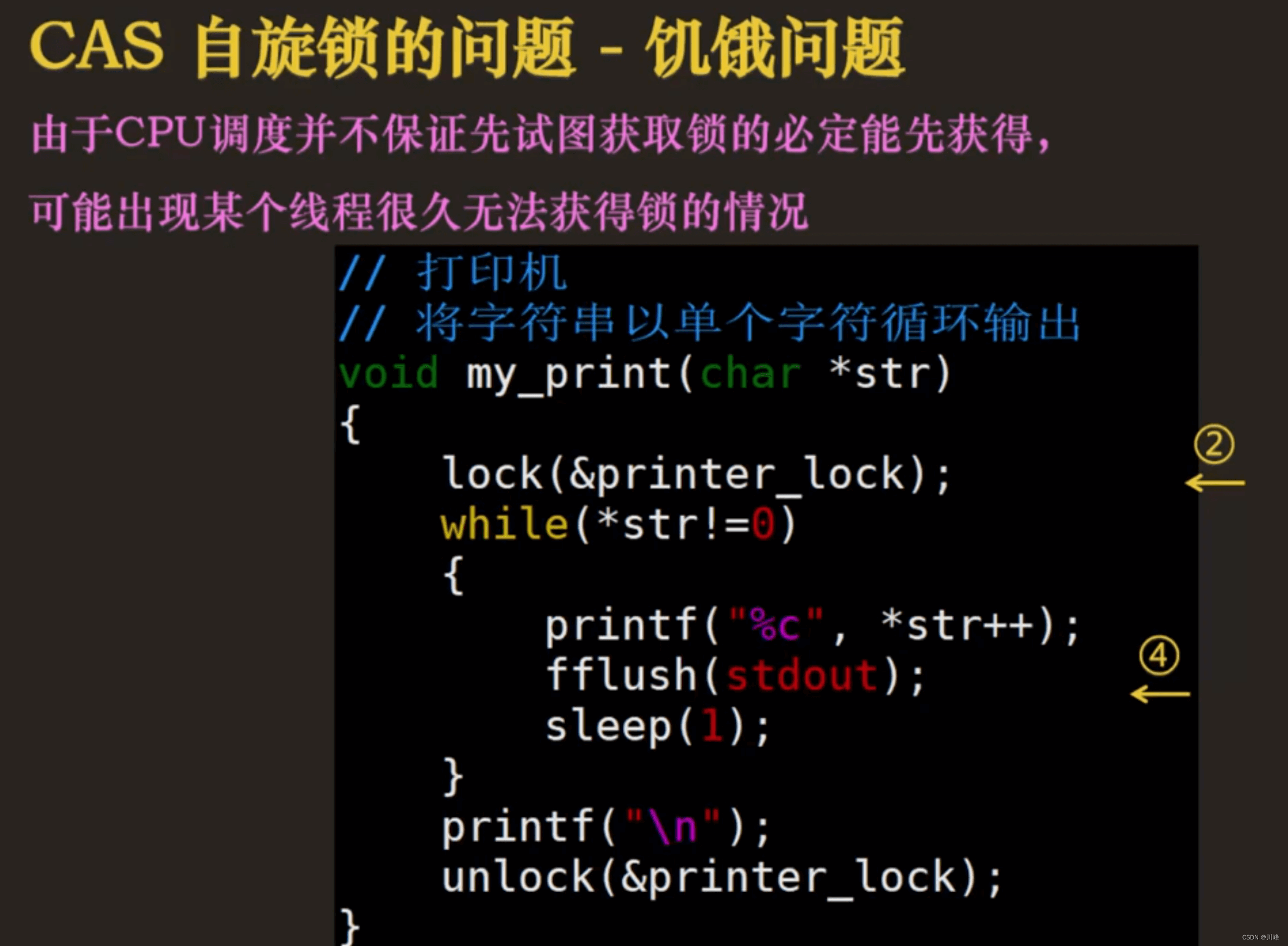
CAS 自旋锁的饥饿问题:由于 CPU 调度不能保证先申请锁的一定先获得执行权,可能存在某个线程很久无法获得锁。
解决方法:使用 FIFO 自旋锁,给每个线程编号,先叫到号的先执行
-
CAS 自旋锁的浪费 CPU 问题:由于自旋锁会导致每个线程都在不停的执行
while空转操作,会占用 CPU,假如临界区的线程执行时间过长,那么其他等待的线程将会一直占用着 CPU,导致浪费。解决方法:基于自旋锁实现阻塞互斥锁,将没有拿到锁的线程加入等待队列中阻塞等待,让出 CPU 执行权,在临界区的线程执行完后,从等待队列中唤醒一个线程来执行。在实现时,需要一个标志位来标识临界区是否有 1 个线程在执行以及一个队列数据结构,另外需要一把自旋锁来保证锁内这两个全局变量的安全性。
-
自旋锁 和 阻塞互斥锁该如何选择:根据临界区的执行时间长短来决定,时间短的使用自旋锁,时间长的使用阻塞互斥锁,因为阻塞时,需要发生系统调用 CPU 上下文切换需要开销,时间短的话再用阻塞得不偿失。
-
真实的锁实现:先使用自旋锁,过了一段时间还没有拿到锁,此时再进行阻塞。
公平锁、非公平锁以及读写锁
公平锁 VS 非公平锁
-
公平锁:多个线程按照顺序去申请锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
优点:所有的线程都有机会得到资源,不会饿死在队列中
缺点:吞吐量会下降很多,只有队首的线程会执行,其他的线程排队阻塞,CPU 唤醒阻塞线程的开销会很大。 -
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到进入等待队列,如果能获取到就执行。
优点:减少了唤起线程的数量,从而可以减少 CPU 唤醒线程的开销,CPU 不必取唤醒所有线程,整体的吞吐效率会高点。
缺点:可能某个线程一直获取不到锁,导致饿死。
读写锁(read-write lock)
主要是针对读多写少的场景:
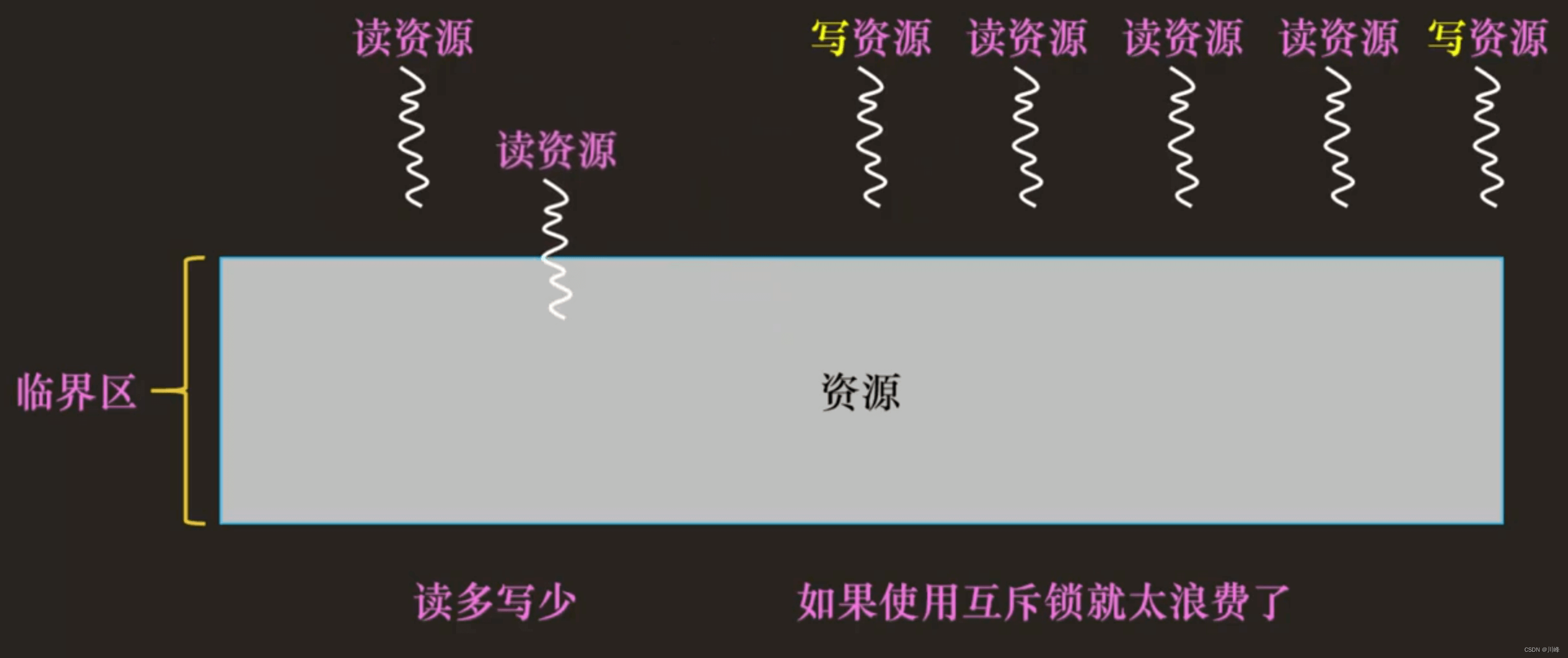

如果是读多写少的情况下,使用互斥锁就太浪费了。因为读的话,可以多线程同时读取资源,没有线程安全问题。
- 线程读的时候,获取【读锁】,这个时候写线程不能进临界区。
- 线程写的时候,获取【写锁】,这个时候读/写线程都不能进临界区。
读锁是共享的,写锁是独占互斥的,如果是读,可以多个读线程同时读,如果是写,只能一个线程写,其他的读写线程都不能访问。
各个语言都会有自己实现的读写锁:
pthread_rwlock_t rwlock; // 声明一个读写锁
pthread_rwlock_rdlock(&rwlock); // 在读之前加读锁
...共享资源的读操作
pthread_rwlock_unlock(&rwlock); // 读完释放锁
pthread_rwlock_wrlock(&rwlock); // 在写之前加写锁
...共享资源的写操作
pthread_rwlock_unlock(&rwlock); // 写完释放锁
pthread_rwlock_destroy(&rwlock); // 销毁读写锁
细化锁的粒度
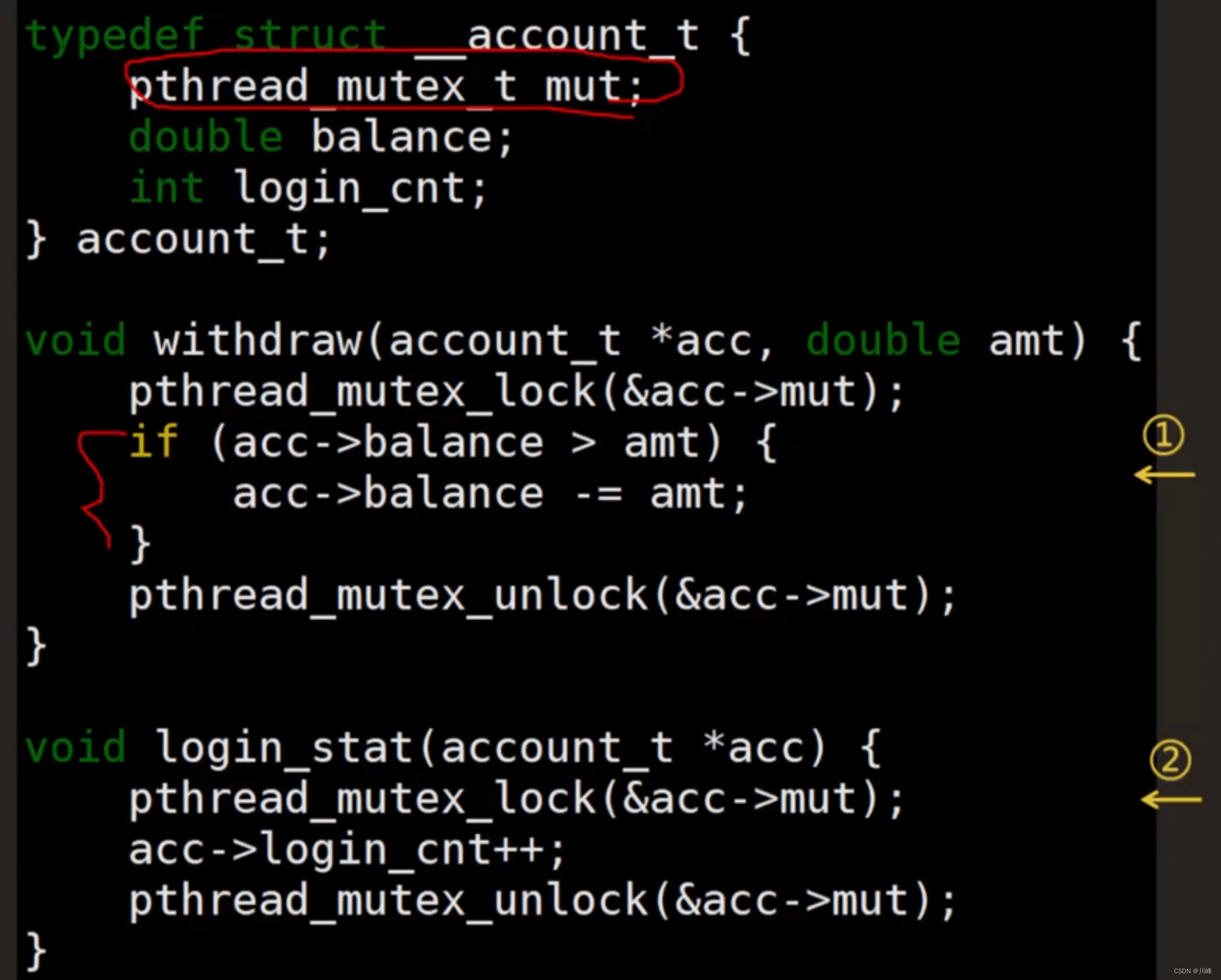
上面代码中使用一把锁来保护两个资源,一个线程在取钱,而另一个线程却不能登录。说明锁的粒度太大,可以并发的两个操作变成串行了。
其实这两个操作可以并发执行,细化锁的粒度,可以提高并发能力:
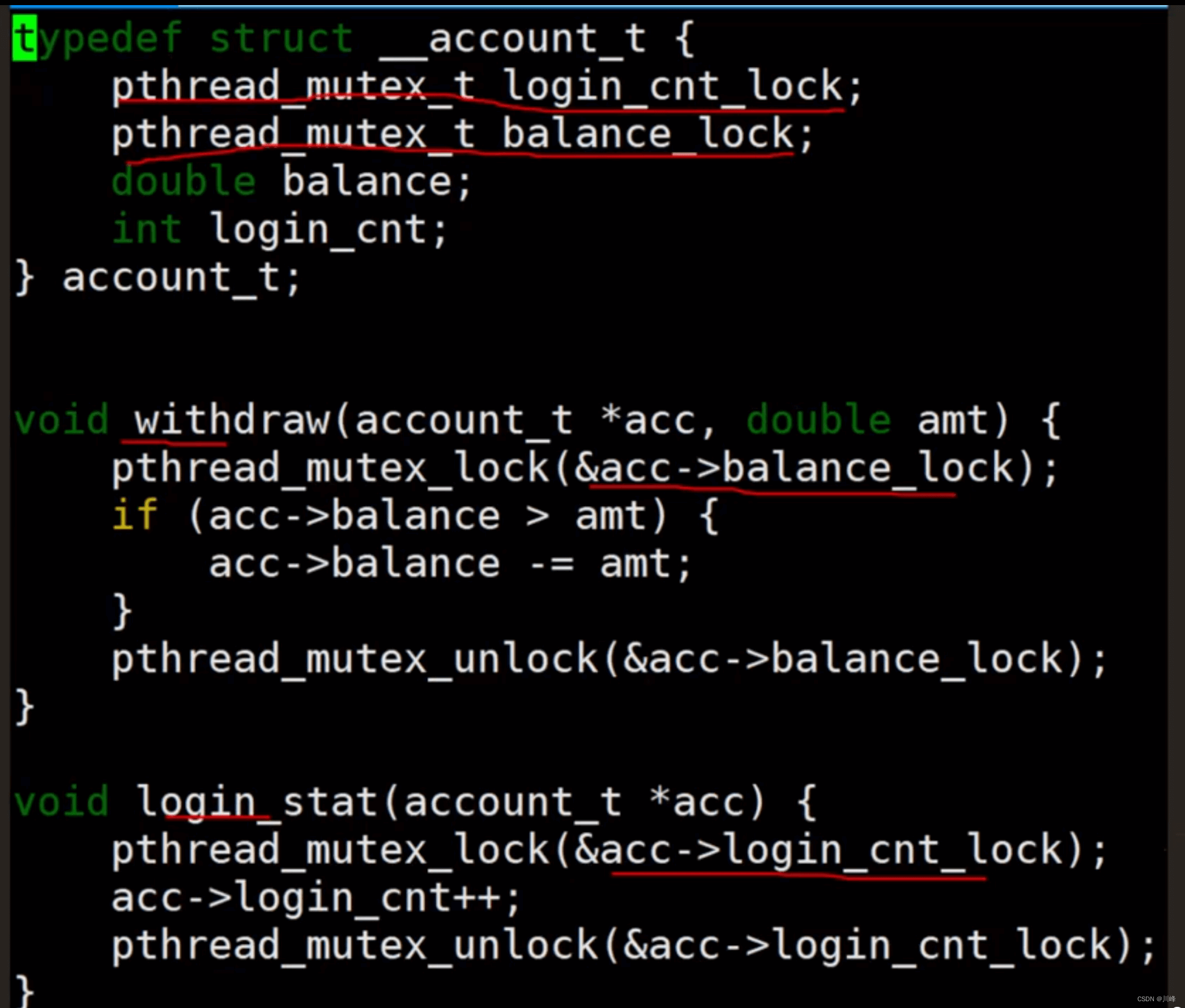
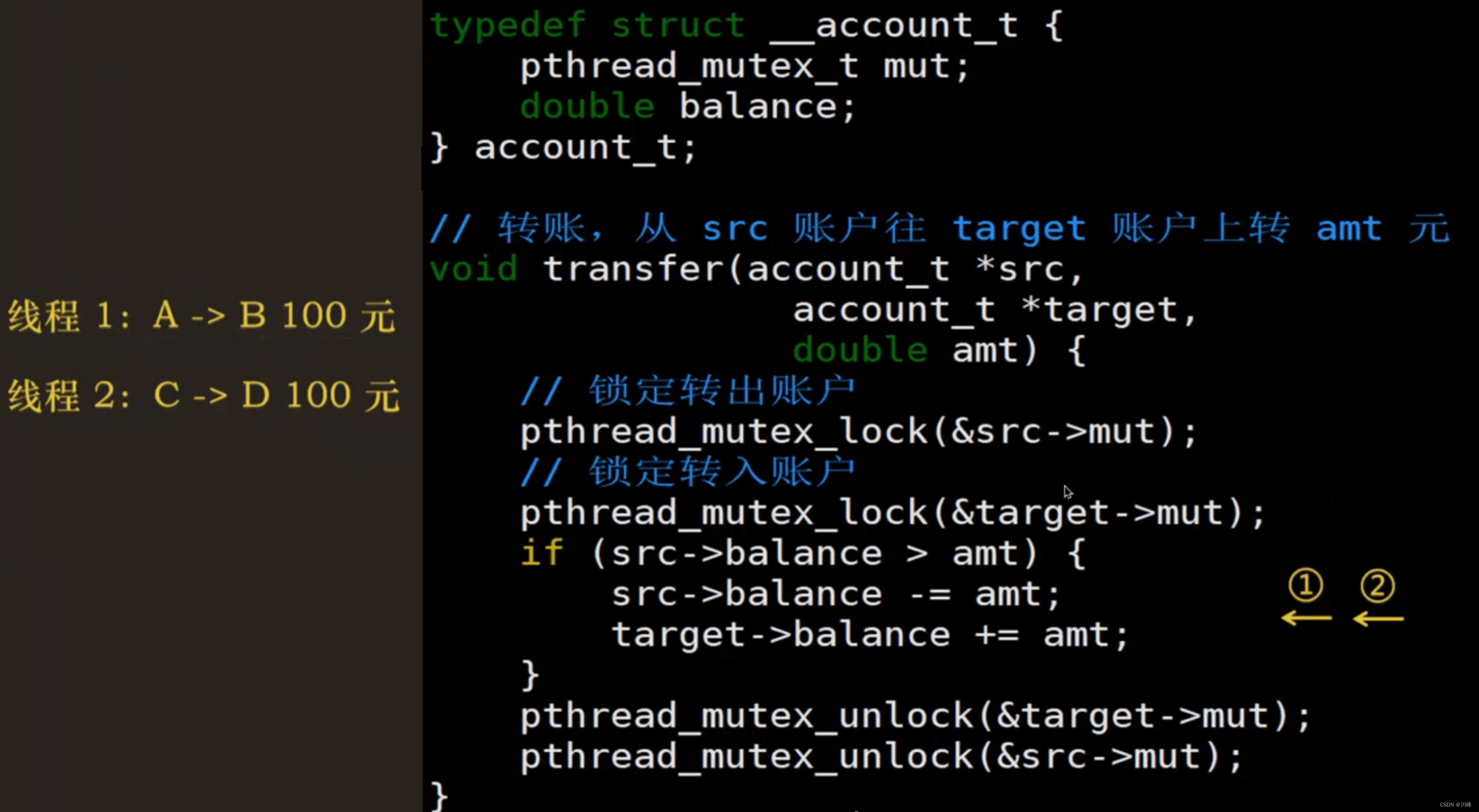
例如下面代码,两个账户需要转账的时候,要拿到两个账户的锁后,才可以开始转账,提高了并发能力
死锁
发生死锁的四个条件:
-
① 互斥:在一个时间点上,需要保证一个线程访问共享资源
-
② 占有且等待:线程 1 已经取得共享资源 A 的锁,在等待另一个共享资源 B 的锁的时候,不会释放共享资源 A 的锁
-
③ 不可抢占:如果线程 1 已经取得共享资源 A 的锁,其他的线程不能强行抢占线程 1 已经取得的锁
-
④ 循环等待:线程 1 等待线程 2 占用的资源的锁,线程 2 等待线程 1 占有的资源的锁,这就是循环等待了
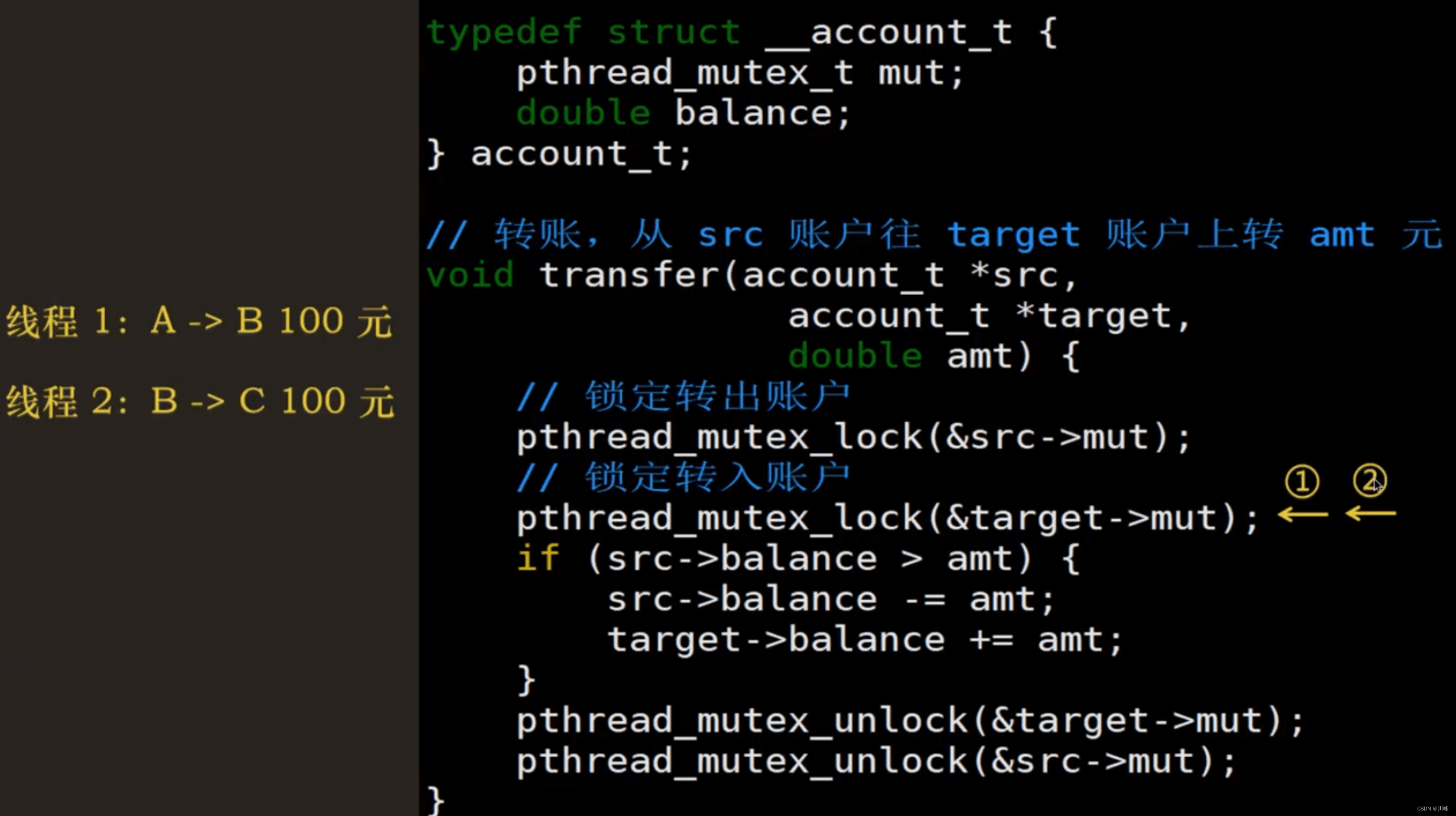
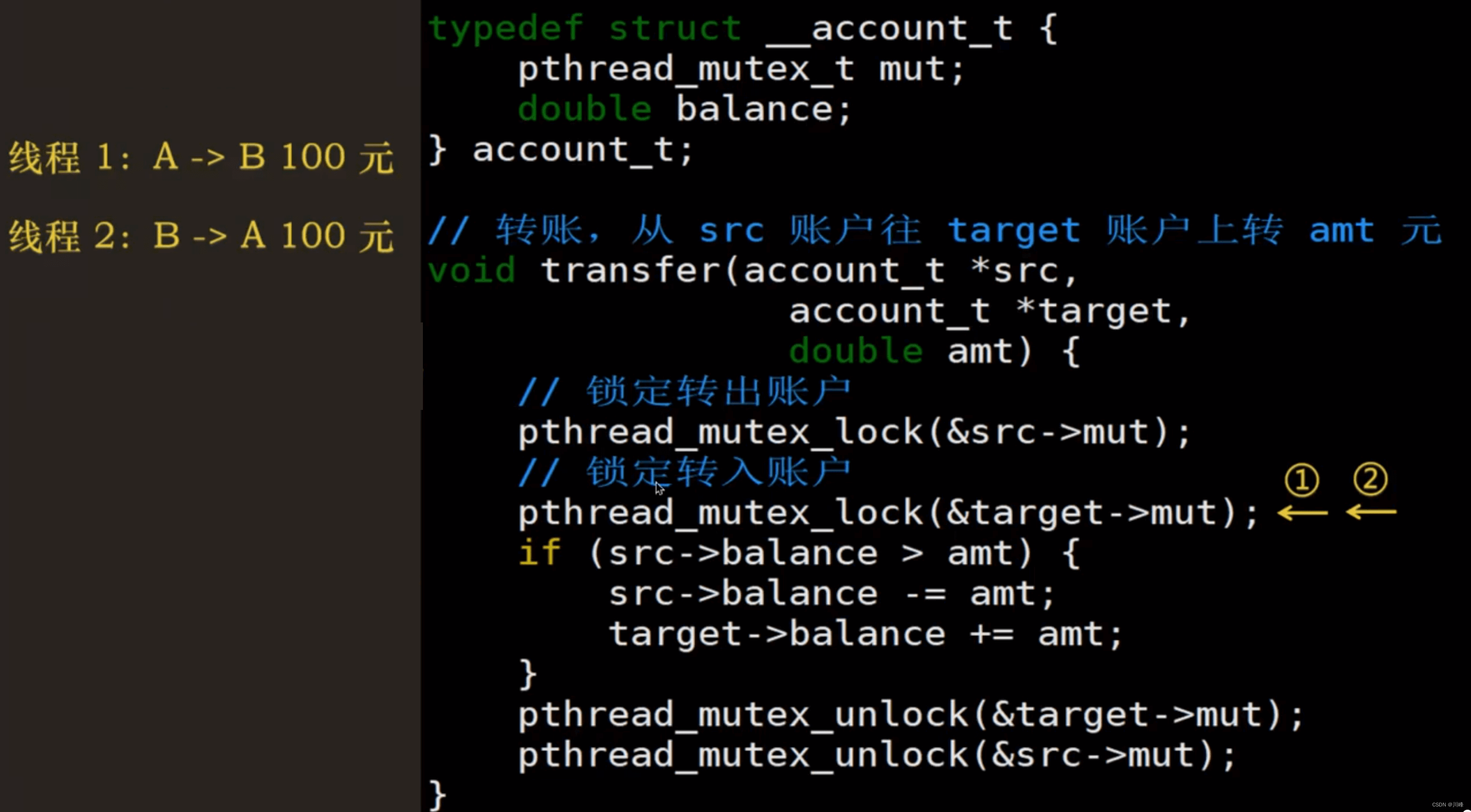
例如下面代码展示了出现死锁的情况,其中:
- 线程 1 拿到了 A 账户的转账锁,现在需要 B 账户的转账锁
- 线程 2 已经拿到了 B 账户的转账锁,现在需要 A 账户的转账锁
破坏【占有且等待】

破坏【占有且等待】的方法:线程一次申请需要的所有资源锁,这样这可以避免发生死锁了
转账的例子,假如一个线程执行 A 账户转账 100 元给 B 账户,只有当这个线程拿到了 A 和 B 的锁,才开始进行转账操作,线程要么拿到 A 和 B 的锁,要么 A 和 B 的锁都没拿到,不会出现拿到一个锁,而等待另一个锁的情况,从而避免了死锁。
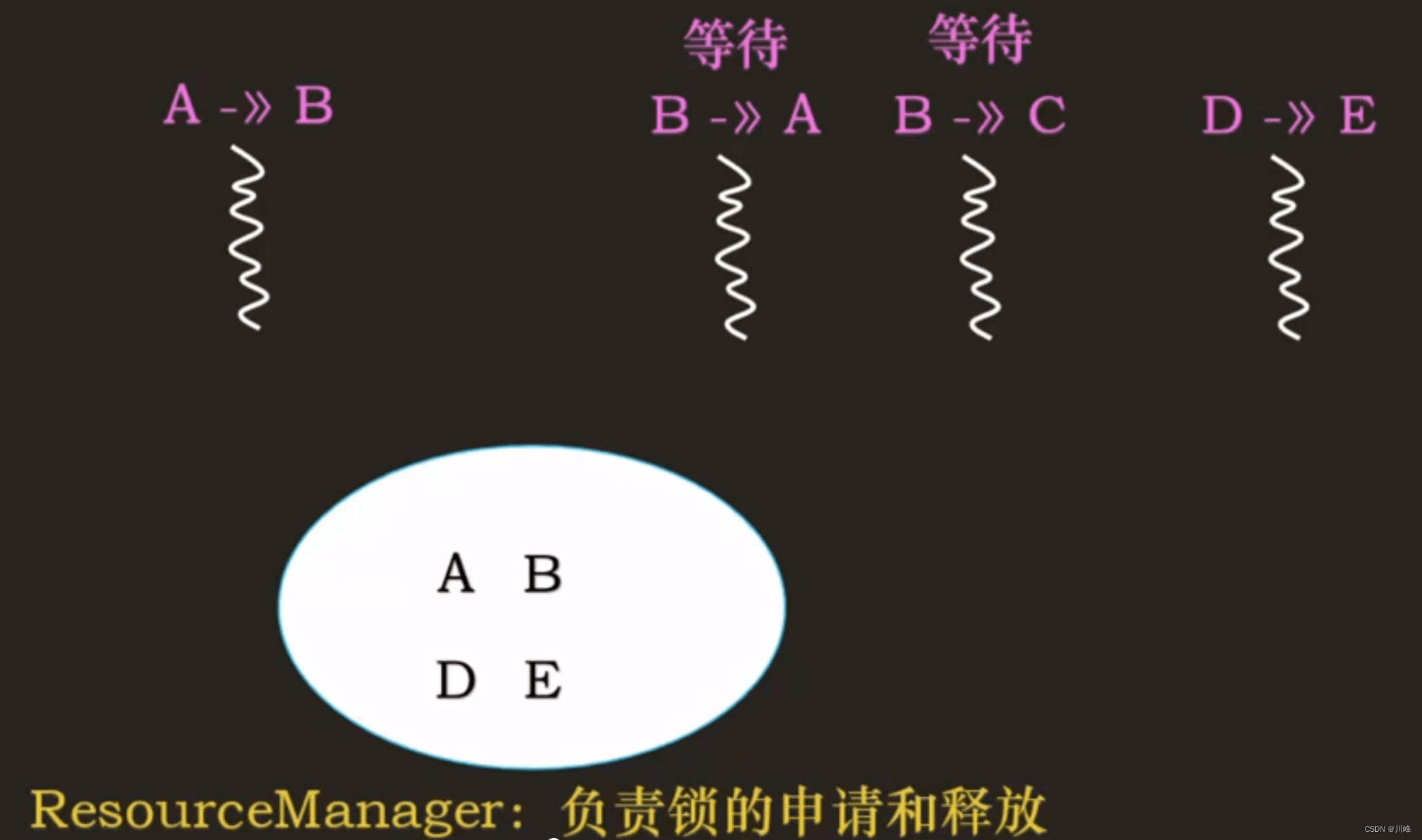
思考:在使用 ResourceManager 破坏【占用且等待】时,下面的代码 ① 和代码 ② 是否多余?
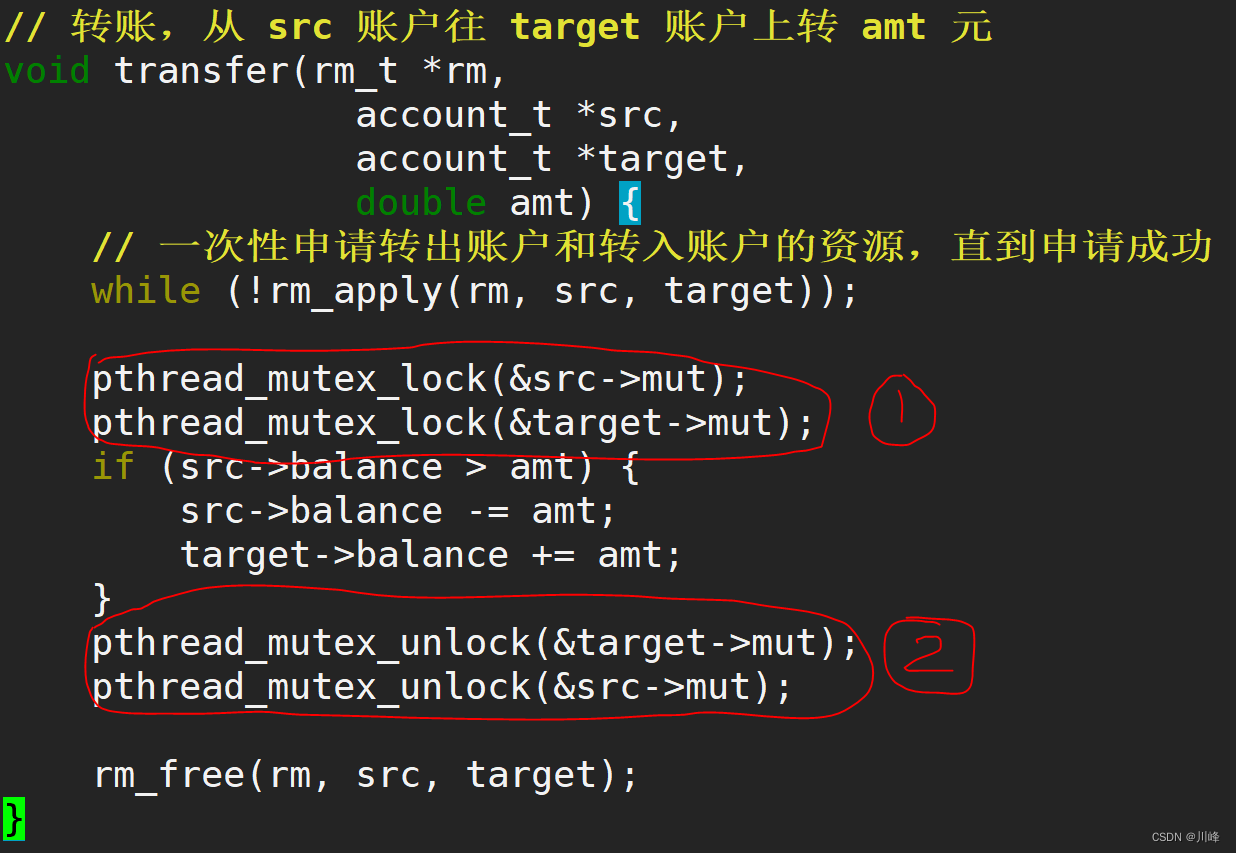
如果只有转账功能的话,那么代码 ① 和代码 ② 是多余的,可以省略的。
这是因为,当 src 和 target 有一把锁申请不到,或者两把锁都申请不到的时候,线程会在 while 代码处自旋,不会进入临界区,这样就可以保证临界区只会有一个线程执行,只有这个线程拿到了两把锁。
但是,当不仅仅只有转账功能,可能还有取钱、存钱等业务的时候,这些业务也会去操作账户中的 balance 了,那么上面的代码 ① 和代码 ② 就很有必要了,因为转账的同时,可能还会有其他的线程对转账的账户执行取钱,或者存钱。
也就是存在多线程同时更新一个账户的 balance ,所以,转账的时候还是得把两把锁锁上,才能保证 balance 的线程安全。
破坏【不可抢占】

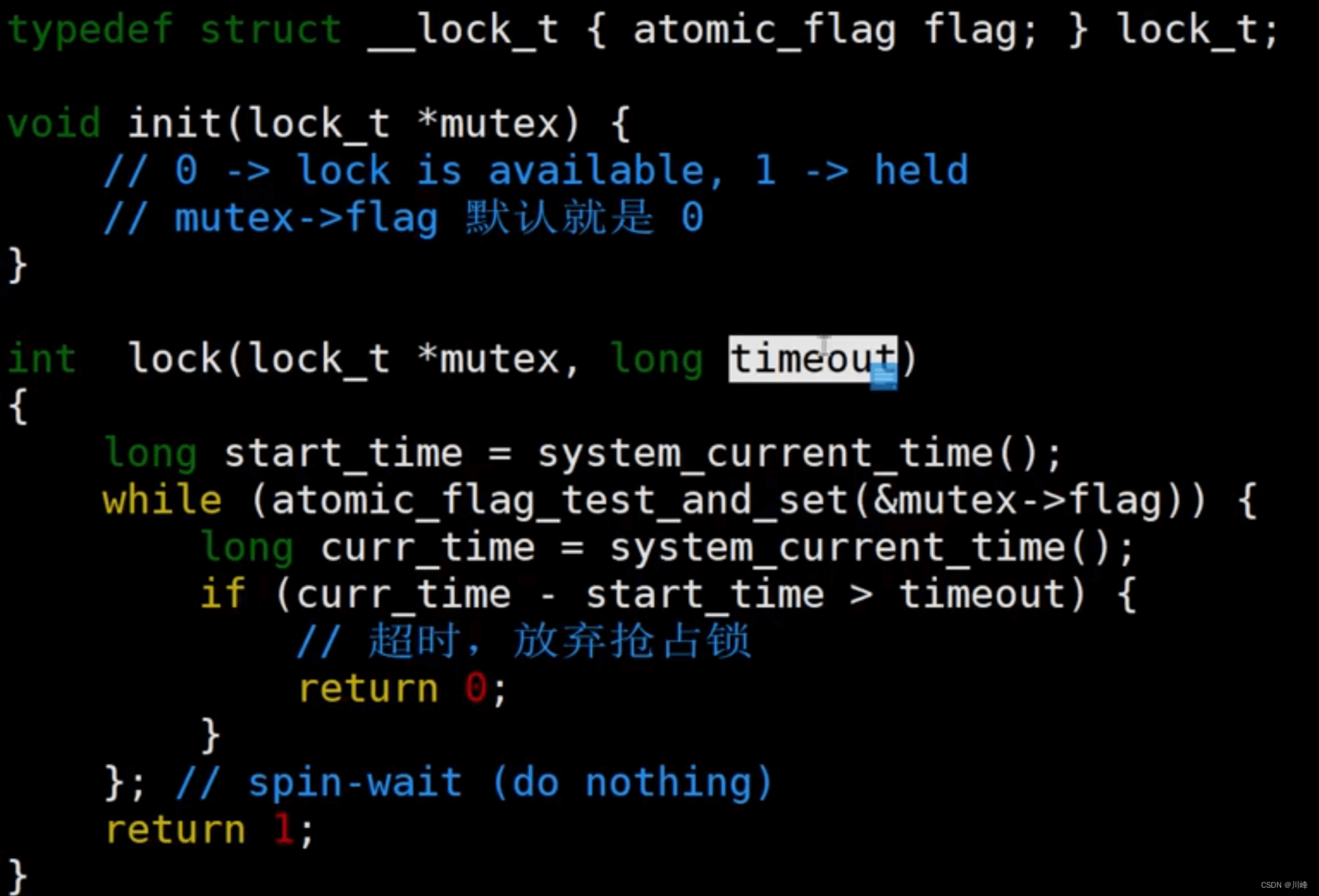
破坏【不可抢占】的方法:已经占有部分资源的线程在进一步申请其他资源时,如果申请不到的话,可以主动释放它所占有的资源,这样不可抢占这个条件就破坏掉了。
可以通过设计一个带超时的锁来实现,也就是当线程获取不到锁,如果超过了指定的时间后,就主动放弃。
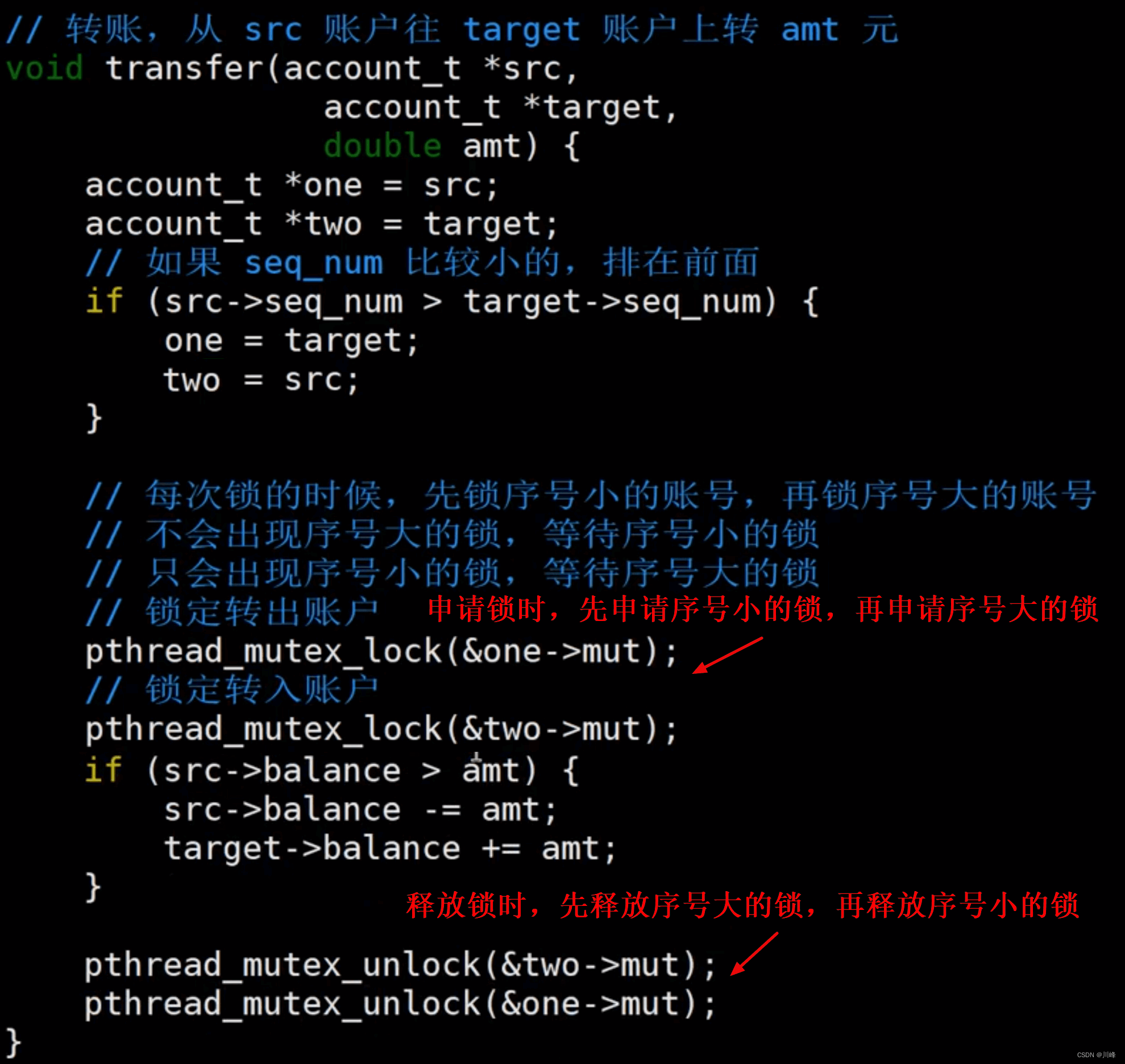
破坏【循环等待】

破坏【循环等待】的方法:如果我们先对资源排序,然后按照顺序来申请资源的话,就可以破坏【循环等待】的条件了。
假设每个账户都有一个序号,来标志唯一标志这个账号,我们可以使用 seqNo 来表示
总结
- 破坏占用且等待 —— 先一次性申请到所有需要的资源,再进行操作,线程要么都拿到了 A 和 B 的锁,要么都没有拿到,不会出现拿到一个 A 锁,而等待另一个 B 锁的情况
- 破坏不可抢占 —— 设计带超时的锁,一直获取不到锁时,超时自动放弃当前占用资源
- 破坏循环等待 —— 先对资源进行排序,然后按顺序申请资源,释放时,按顺序释放锁
信号量
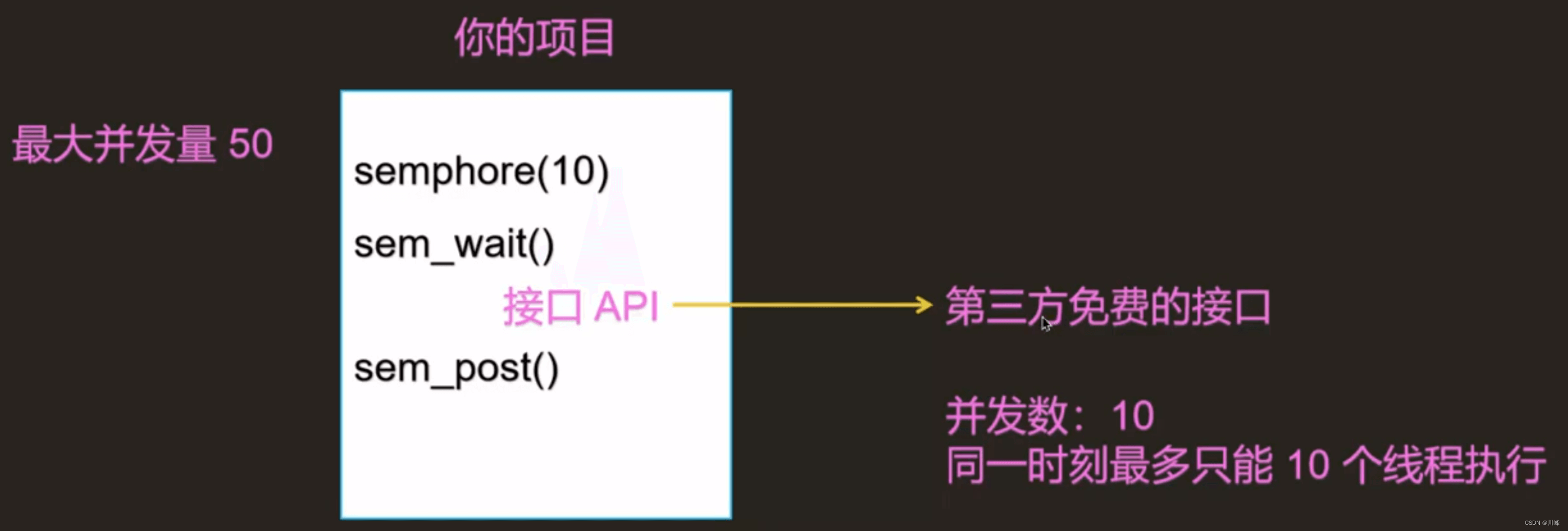
信号量的主要作用:
- 1:限流(控制并发度)
- 2:相当于互斥锁(将信号量初始值设置为1)

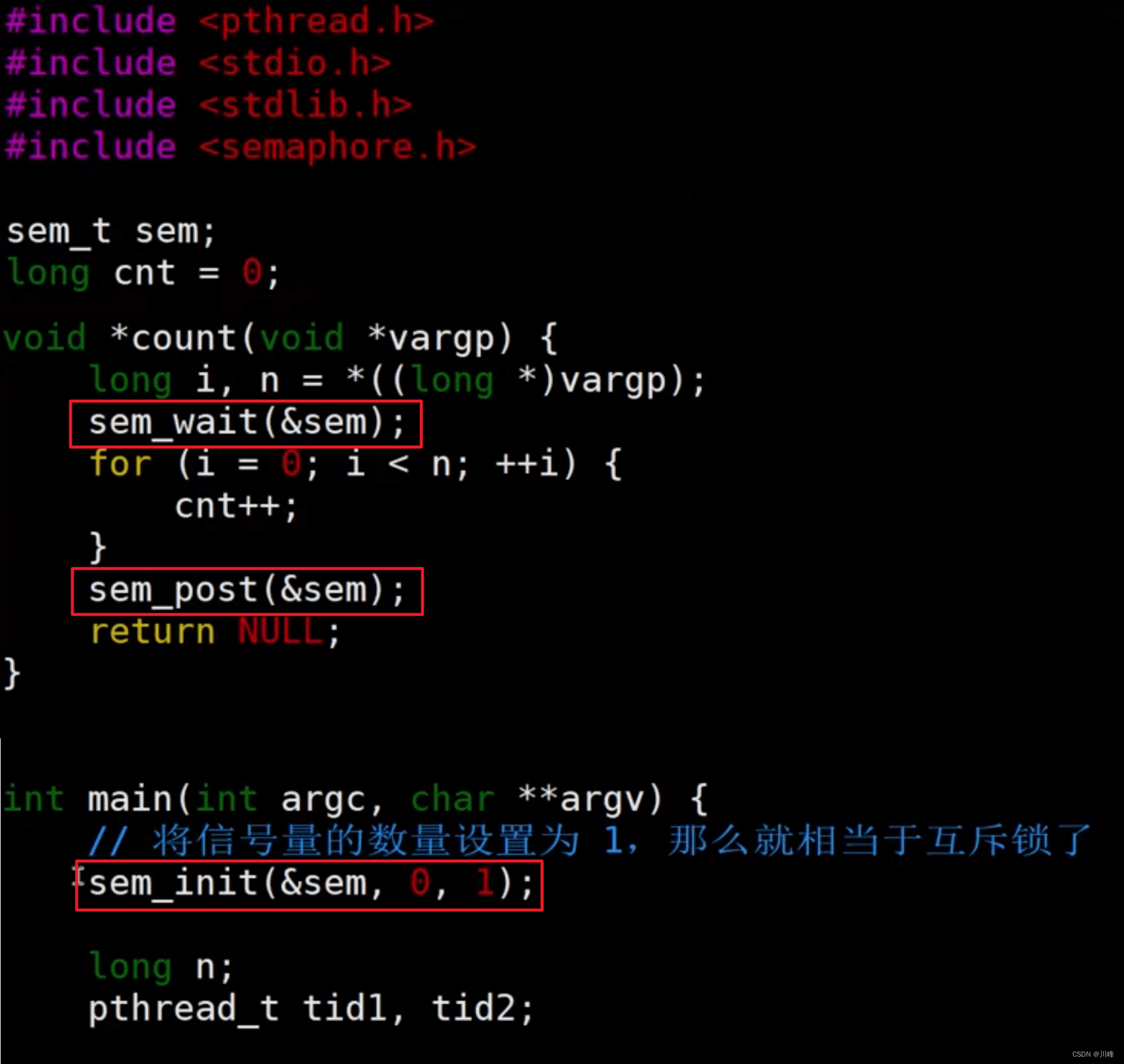
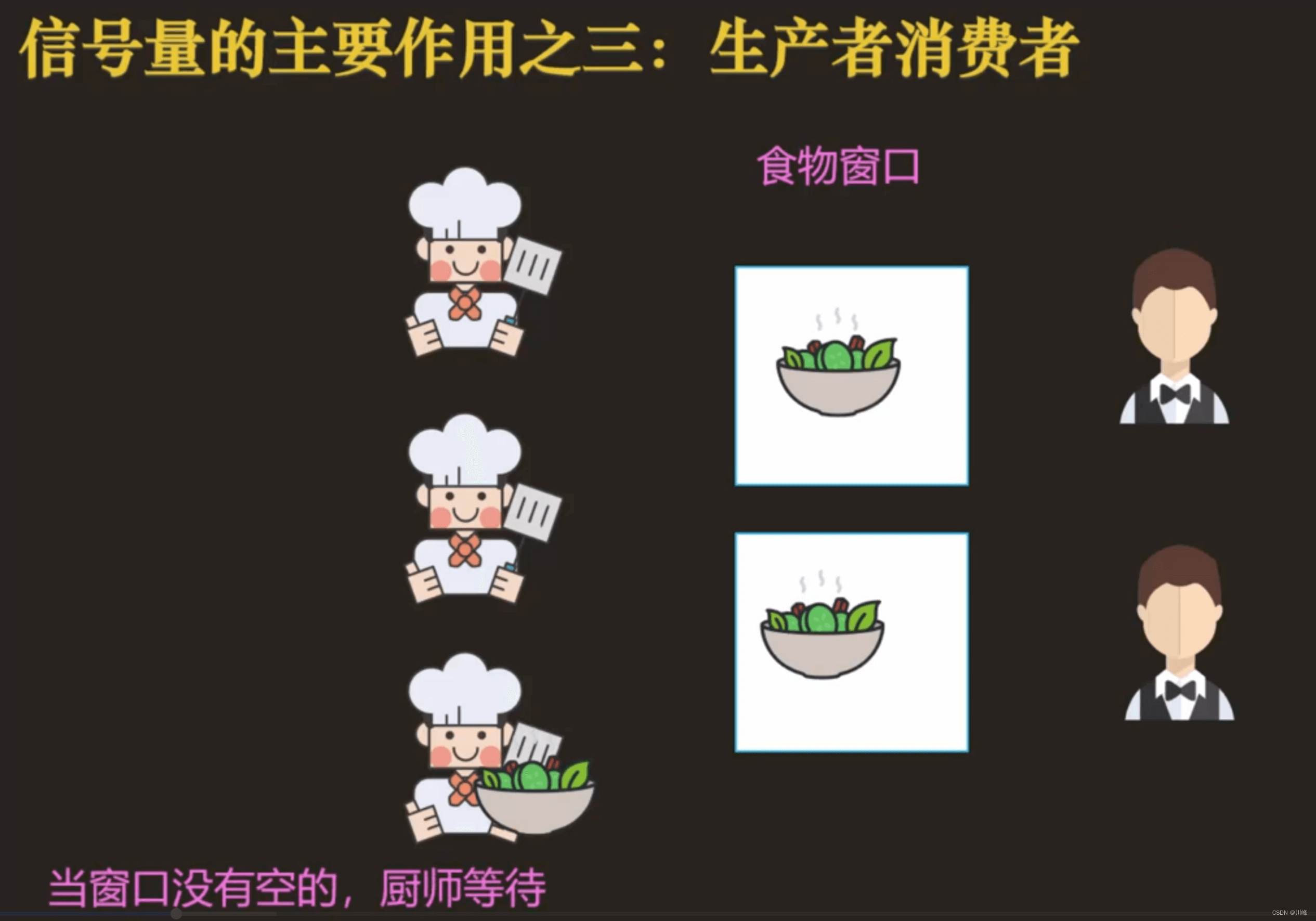

信号量实现生产者消费者模型的参考代码:
int main() {
sem_init(&empty, 0,2); // 有两个食物窗口
sem_init(&full, 0, 0); // 一开始食物窗口中没有任何菜,所以这里初始化为 0
pthread_t chefs[3];
pthread_t waiters[2];
// 3个厨师
for (int i = 0; i< 3; i++) {
pthread_create(&chefs[i], NULL, chef_thread, &i);
}
// 2个服务员
for (int i = 0; i<2; i++) {
pthread_create(&waiters[i], NULL, waiter_thread, &i);
}
sleep(30);
sem_destroy(&empty);
sem_destroy(&full);
}
void *chef_thread(void *args) {
int chef id = *((int *)args);
while (1) {
// 模拟做菜
sleep(rand() % 5);
produce(chef_id);
}
}
void *waiter_thread(void *args) {
int waiter id = *((int *)args);
while (1) {
sleep(rand( ) % 3);
consume(waiter_id);
}
}
sem_t empty;
sem_t full;
// 厨师这个线程通过这个函数,不断的往食物窗口放置菜
void produce(int chef_id) {
// 这里会判断窗口是否为空,如果不为空则等待
sem_wait(&empty);
// 临界区
printf("chef %d add food to food window\n", chef_id);
fflush(stdout);
// 厨师将菜放入窗口,则通知服务员来取菜
sem_post (&full);
}
// 服务员这个线程通过这个函数,不断的从食物窗口中取菜
void consume(int waiter_id) {
// 这里服务员判断窗口是否满的,如果不满,也就是没有食物,则等待
sem_wait(&full);
// 临界区
printf("waiter %d remove food from food winddow\n", waiter_id);
fflush(stdout);
// 当服务员拿完菜,则通知厨师往窗口中放菜
sem_post(&empty);
}
生产者用一个信号量empty表示队列是否满的资源,消费者用一个信号量full表示队列是否空的资源。empty==0时,表示没有空的资源可用,则表示队列已满,生产者等待消费者消费,消费者消费后通知信号量empty, 若empty > 0时,表示队列有空位,生产者继续,生产者生产之后,通知信号量full。full == 0时,表示队列为空,消费者等待生产者生产,full > 0时,表示队列有资源,消费者从队列中取出资源消费,然后通知信号量empty。
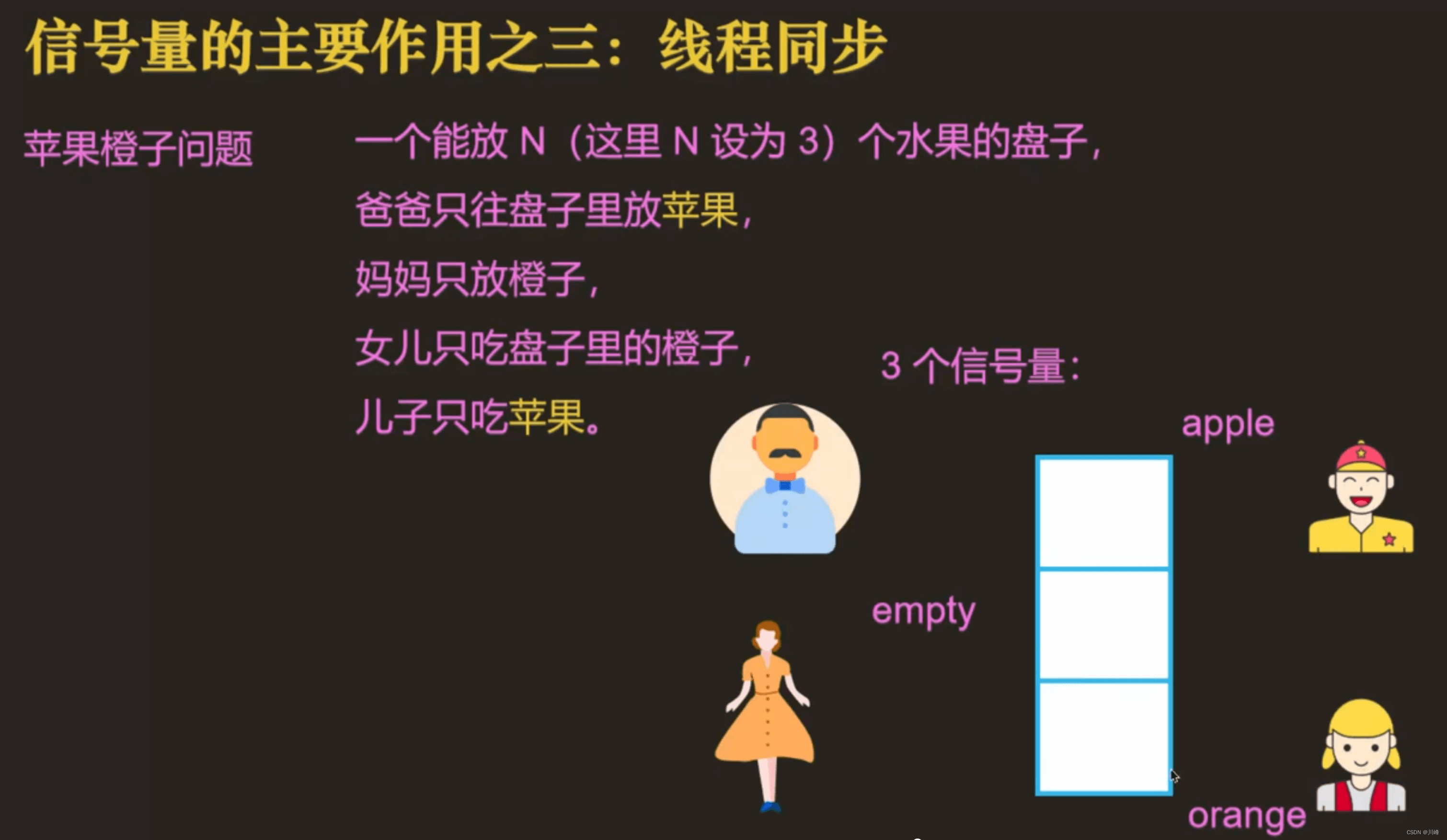
苹果橙子问题参考代码:
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
sem_t empty;
sem_t apple;
sem_t orange;
void *father_thread(void *args) {
while (1) {
// 如果盘子不是空的就等待
sem_wait(&empty);
sleep(rand() % 3);
printf("爸爸放入一个苹果!\n");
// 通知儿子可以吃苹果了
sem_post(&apple);
}
}
void *mother_thread(void *args) {
while (1) {
// 如果盘子不是空的就等待
sem_wait(&empty) ;
sleep(rand() % 3);
printf("妈妈放入一个橙子!\n");
// 通知女儿可以吃橙子了
sem_post(&orange);
}
}
void *son_thread(void *args) {
while (1) {
// 如果没有苹果,则等待
sem_wait(&apple);
sleep(rand() % 5);
printf("儿子吃了一个苹果!\n");
// 通知爸爸妈妈可以放水果了
sem_post(&empty);
}
}
void *daughter_thread(void *args) {
while (1) {
// 如果没有橙子,则等待
sem_wait(&orange);
sleep(rand() % 5);
printf("女儿吃了一个橙子!\n");
// 通知爸爸妈妈可以放水果了
sem_post(&empty) ;
}
}
int main() {
pthread_t father; // 定义线程
pthread_t mother;
pthread_t son;
pthread_t daughter;
sem_init(&empty, 0, 3); //信号量初始化
sem_init(&apple, 0, 0);
sem_init(&orange, 0, 0);
pthread_create(&father, NULL, father_thread, NULL); // 创建线程
pthread_create(&mother, NULL, mother_thread, NULL);
pthread_create(&daughter, NULL, daughter_thread, NULL);
pthread_create(&son, NULL, son_thread, NULL);
sleep(100);
return 1;
}
信号量总结:
-
信号量:表示临界区的可用资源数量,进入临界区可用资源数量 - 1,退出临界区可用资源数量 + 1,临界区可以同时有多个线程执行,只要能获取到资源。可用资源数量
≤ 0时,线程等待,直到可用资源数量≥ 0时,才能进入。 -
信号量的值设置为
> 0时,可以用于限流,控制并发数,信号量的值设置为1时,可以当成互斥锁来使用。 -
信号量可以用于线程同步控制,如生产者消费者模型。
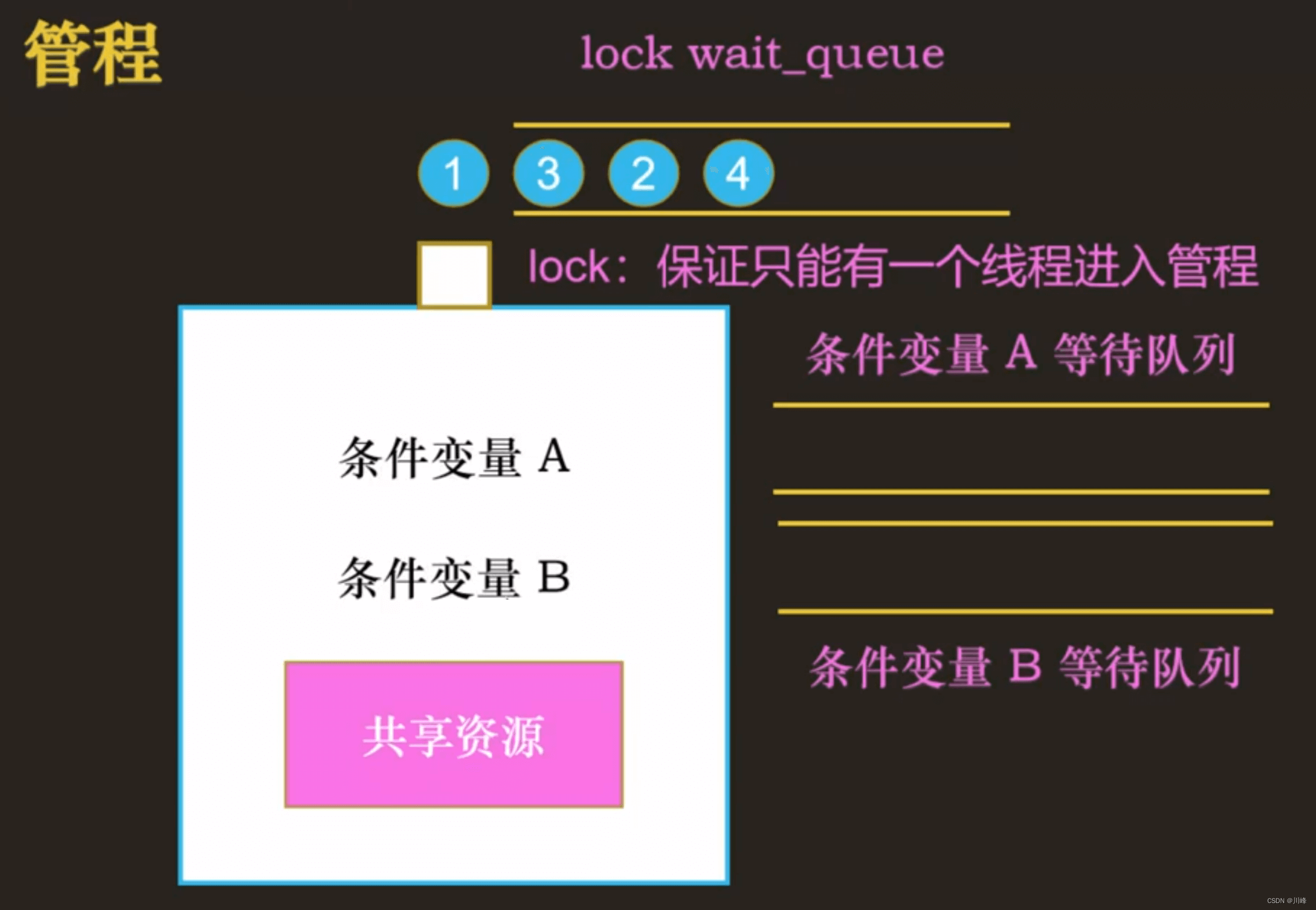
管程 (monitor)
管程和信号量是等价的,一般信号量能实现的功能,也是可以使用管程来实现的。信号量一开始提出来的时候,就是应用于操作系统中多线程同步互斥的实现。管程一开始提出来的时候,是用在编程语言这个层面上的,比如 Java 语言、C++ 语言等,这些语言通过设计实现的管程机制,可以简化它们实现多线程同步互斥的操作。
管程是包含一系列的共享变量,以及针对这些变量的操作函数的一个组合,在具体的设计中,管程包含:
- ① 一个锁,这个锁是用来确保互斥的,也就是确保只能有一个线程可以进入管程执行操作
- ② 0 个或者多个条件变量,用于实现条件同步