EasyNLP带你玩转CLIP图文检索 - 知乎作者:熊兮、章捷、岑鸣、临在导读随着自媒体的不断发展,多种模态数据例如图像、文本、语音、视频等不断增长,创造了互联网上丰富多彩的世界。为了准确建模用户的多模态内容,跨模态检索是跨模态理解的重要任务,…![]() https://zhuanlan.zhihu.com/p/528476134
https://zhuanlan.zhihu.com/p/528476134
initialize_easynlp()->
train_dataset = CLIPDataset(pretrained_model_name_or_path=get_pretrain_model_path("alibaba-pai/clip_chinese_roberta_base_vit_base"),
data_file="MUGE_MR_train_base64_part.tsv",
max_seq_length=32,
input_schema="text:str:1,image:str:1",
first_sequence="text",
second_sequence="image",
is_training=True)
valid_dataset = CLIPDataset()
model = get_application_model(app_name='clip',...)
- easynlp.appzoo.api.ModelMapping->CLIPApp
- easynlp.appzoo.clip.model.py->CLIPApp
- CHINESE_CLIP->
- self.visual = VisualTransformer()
- self.bert = BertModel()
trainer = Trainer(model,train_dataset,user_defined_parameters,
evaluator=get_application_evaluator(app_name="clip",valid_dataset=valid_dataset,user_defined_parameters=user_defined_parameters,eval_batch_size=32))
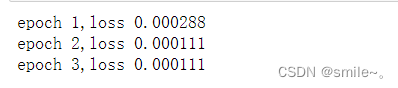
trainer.train()
- for _epoch in range(self._first_epoch,int(args.epoch_num)):
for _step,batch in enumerate(self._train_loader):
label_ids = batch.pop()
forward_outputs = self._model(batch)
loss_dict = self.model_module.compute_loss(forward_outputs,label_ids)
_loss = loss_dict('loss')
_loss.backward()
model = get_application_model_evaluation()
evaluator = get_application_evaluator()
evaluator.evaluate(model)数据处理:
import os
import base64
import multiprocessing
from tqdm import tqdm
def process_image(image_path):
# 从图片路径中提取中文描述
image_name = os.path.basename(image_path)
description = os.path.splitext(image_name)[0]
# 将图片转换为 Base64 编码
with open(image_path, 'rb') as f:
image_data = f.read()
base64_data = base64.b64encode(image_data).decode('utf-8')
return description, base64_data
def generate_tsv(directory):
image_paths = [os.path.join(directory, filename) for filename in os.listdir(directory) if
filename.endswith(('.jpg', '.png'))]
with multiprocessing.Pool() as pool, tqdm(total=len(image_paths), desc='Processing Images') as pbar:
results = []
for result in pool.imap_unordered(process_image, image_paths):
results.append(result)
pbar.update(1)
with open(
'/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/vcg_furnitures_text_image/vcg_furnitures_train.tsv',
'w', encoding='utf-8') as f:
for description, base64_data in results:
line = f"{description}\t{base64_data}\n"
f.write(line)
if __name__ == '__main__':
target_directory = "/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/vcg_furnitures_text_image/vcg_furnitures_train/img_download/"
# import pdb;pdb.set_trace()
generate_tsv(target_directory)
训练代码:
import torch.cuda
from easynlp.appzoo import CLIPDataset
from easynlp.appzoo import get_application_predictor, get_application_model, get_application_evaluator, \
get_application_model_for_evaluation
from easynlp.core import Trainer, PredictorManager
from easynlp.utils import initialize_easynlp, get_args, get_pretrain_model_path
from easynlp.utils.global_vars import parse_user_defined_parameters
def main():
# /root/.easynlp/modelzoo中
train_dataset = CLIPDataset(
pretrained_model_name_or_path=get_pretrain_model_path(args.pretrained_model_name_or_path),
data_file=args.tables.split(",")[0],
max_seq_length=args.sequence_length,
input_schema=args.input_schema,
first_sequence=args.first_sequence,
second_sequence=args.second_sequence,
is_training=True)
valid_dataset = CLIPDataset(
# 预训练模型名称路径,这里我们使用封装好的get_pretrain_model_path函数,来处理模型名称"alibaba-pai/clip_chinese_roberta_base_vit_base"以得到其路径,并自动下载模型
pretrained_model_name_or_path=get_pretrain_model_path(args.pretrained_model_name_or_path),
data_file=args.tables.split(",")[-1],
# "data/pai/MUGE_MR_valid_base64_part.tsv"
max_seq_length=args.sequence_length, # 文本最大长度,超过将截断,不足将padding
input_schema=args.input_schema, # 输入tsv数据的格式,逗号分隔的每一项对应数据文件中每行以\t分隔的一项,每项开头为其字段标识,如label、sent1等
first_sequence=args.first_sequence, # 用于说明input_schema中哪些字段作为第一/第二列输入数据
second_sequence=args.second_sequence,
is_training=False) # 是否为训练过程,train_dataset为True,valid_dataset为False
model = get_application_model(
app_name=args.app_name, # 任务名称,这里选择文本分类"clip"
pretrained_model_name_or_path=get_pretrain_model_path(
args.pretrained_model_name_or_path),
user_defined_parameters=user_defined_parameters
# user_defined_parameters:用户自定义参数,直接填入刚刚处理好的自定义参数user_defined_parameters
)
trainer = Trainer(model=model,
train_dataset=train_dataset,
user_defined_parameters=user_defined_parameters,
evaluator=get_application_evaluator(app_name=args.app_name,
valid_dataset=valid_dataset,
user_defined_parameters=user_defined_parameters,
eval_batch_size=32))
trainer.train()
# 模型评估
model = get_application_model_for_evaluation(app_name=args.app_name,
pretrained_model_name_or_path=args.checkpoint_dir,
user_defined_parameters=user_defined_parameters)
evaluator = get_application_evaluator(app_name=args.app_name,
valid_dataset=valid_dataset,
user_defined_parameters=user_defined_parameters,
eval_batch_size=32)
model.to(torch.cuda.current_device())
evaluator.evaluate(model=model)
# 模型预测
if test:
predictor = get_application_predictor(app_name="clip",
model_dir="./outputs/clip_model/",
first_sequence="text",
second_sequence="image",
sequence_length=32,
user_defined_parameters=user_defined_parameters)
predictor_manager = PredictorManager(predictor=predictor,
input_file="data/vcg_furnitures_text_image/vcg_furnitures_test.tsv",
input_schema="text:str:1",
output_file="text_feat.tsv",
output_schema="text_feat",
append_cols="text",
batch_size=2)
predictor_manager.run()
if __name__ == "__main__":
initialize_easynlp()
args = get_args()
user_defined_parameters = parse_user_defined_parameters(
'pretrain_model_name_or_path=alibaba-pai/clip_chinese_roberta_base_vit_base')
args.checkpoint_dir = "./outputs/clip_model/"
args.pretrained_model_name_or_path = "alibaba-pai/clip_chinese_roberta_base_vit_base"
# args.n_gpu = 3
# args.worker_gpu = "1,2,3"
args.app_name = "clip"
args.tables = "data/pai/MUGE_MR_train_base64_part.tsv,data/pai/MUGE_MR_valid_base64_part.tsv"
# "data/vcg_furnitures_text_image/vcg_furnitures_train.tsv," \
# "data/vcg_furnitures_text_image/vcg_furnitures_test.tsv"
# "data/pai/MUGE_MR_train_base64_part.tsv,data/pai/MUGE_MR_valid_base64_part.tsv"
args.input_schema = "text:str:1,image:str:1"
args.first_sequence = "text"
args.second_sequence = "image"
args.learning_rate = 1e-4
args.epoch_num = 1000
args.random_seed = 42
args.save_checkpoint_steps = 200
args.sequence_length = 32
# args.train_batch_size = 2
args.micro_batch_size = 32
test = False
main()
# python -m torch.distributed.launch --nproc_per_node 4 tools/train_pai_chinese_clip.py
说一点自己的想法,在我自己工作之初,我很喜欢去拆解一些框架,例如openmm系列,但其实大部分在训练过程上都是相似的,大可不必,在改动上,也没有必要对其进行流程上的大改动,兼具百家之长,了解整体pipeline,更加专注在pipeline实现和效果导向型的结果提交更加有效。