【运维Pro】: 由 YMatrix 售前和售后团队负责的栏目。除了介绍日常的数据库运维和使用知识,我们更希望能够通过介绍这些知识背后的原理,让大家和我们一起感知数据库的美妙。
摘要
在上一期 《时序场景实践与原理 - 1.分布与分区》中,我们围绕时间戳和设备标识列,介绍了设计关于分区、分布的设计思路和原理;在本期内容中,我们会围绕指标列的设计,比较时序场景中常用的宽表、窄表模式,用以灵活扩展的 JSON 和 YMatrix 特有的 mxkv 字段,对它们的使用场景和优缺点进行深入比较和分析。
作者:
王任远 - YMatrix MXUI 研发工程师
01 直观高效的宽表
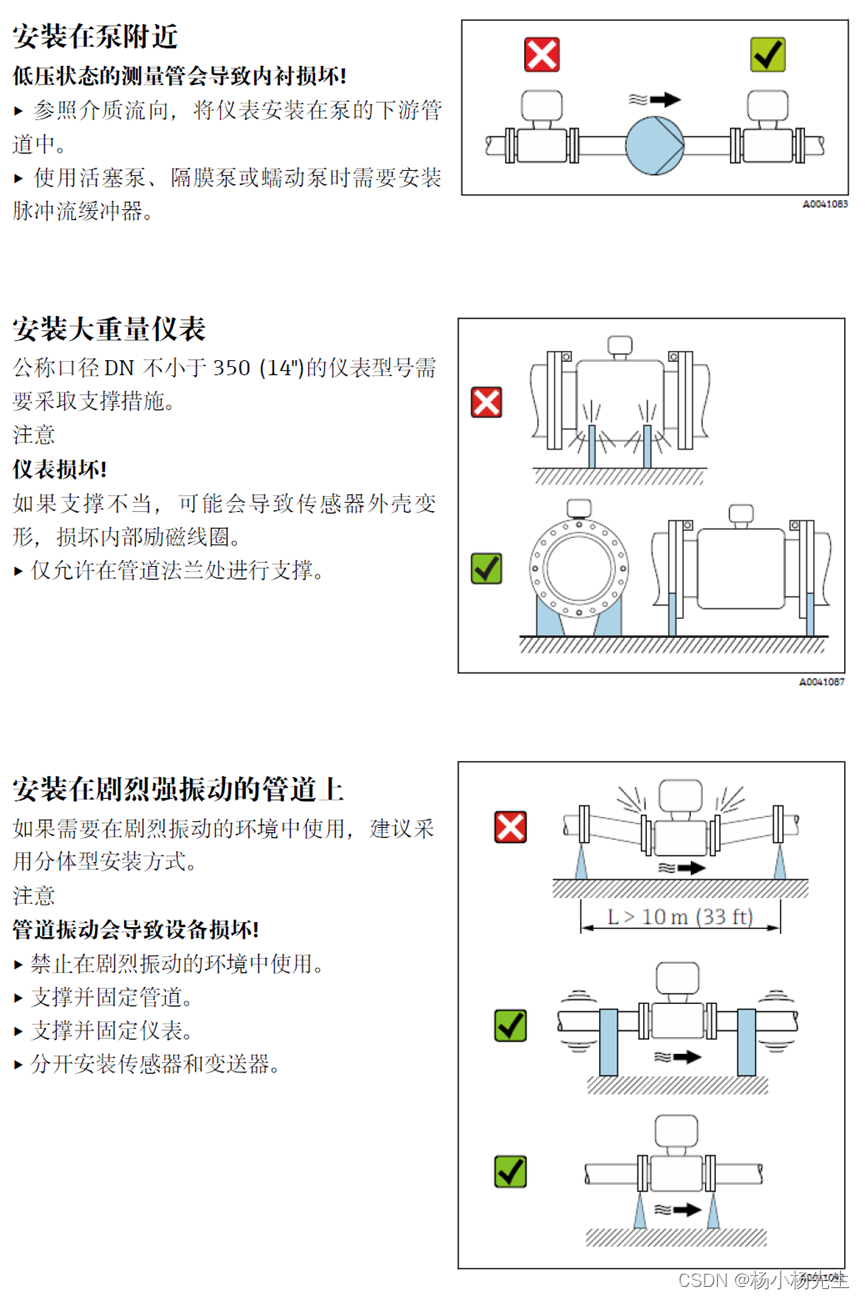
我们还是使用简单的字段传感器的例子:

根据上面的例子,我们自然而然会直接创建这样的表:
一个指标一列,有几个指标就有几列,就是宽表。
宽表是最直观的设计,所见即所得,非常容易理解;当我们查询时,使用的 SQL 也是简单直观的。
在一个真实的系统中,可能设备标识列是几列数据组成,指标也会多于一个,但基础的逻辑总是相同的。无论对于数据本身的存储还是上层应用的接入,宽表都是既简单又高效。
02 当业务发生变化?
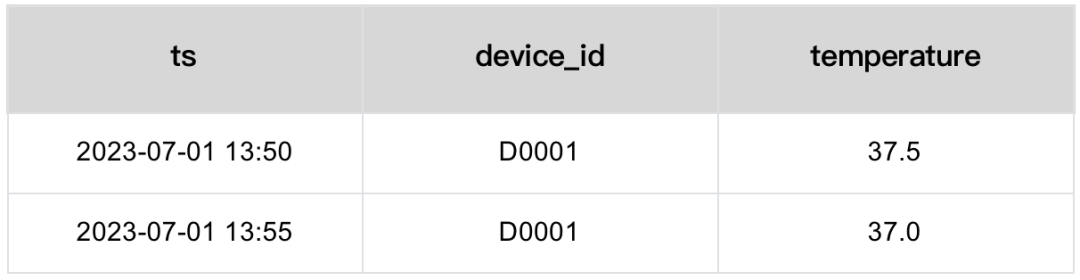
生产环境中,业务会发生变化,时序场景中最常见的业务变更就是追加字段。如果我们为业务追加了新的指标 - 湿度(humidity),就需要在表中增加新的字段。
然而,对于数据库来说,修改表结构是一件严肃的事。
1. 增加列的操作会使用排他锁 (Access Exclusive), 锁住整个表,导致操作时其他关于这个表的业务查询都会被阻塞,是需要审慎对待的。
2. 而在时序场景中,数据量巨大,甚至以 TB 计,在这时,增加列的操作可能会是分钟级甚至数十分钟,耗时难以预测。
添加列的开销:
如果添加列时不设置默认值,那么仅会修改表的元数据,不涉及数据的改变, 所以执行速度是毫秒级。
如果添加列时设置了默认值,那么已有的每一行数据均需重写,后果是当数据量大时,执行时间会长的难以接受。
3. 除此之外,增加一列也有可能使不够强壮的上层应用受到影响:例如应用中可能不严谨的使用 SELECT * FROM table这样的语句,在增加列后,返回值就会多了一列,如果缺少安全的处理,就会导致程序意外终止或者得到预期外的结果。如果我们能够对业务有 100%准确的预测,提前为未来要增加的列预留好字段,比如我已经知道了未来会增加“湿度”,只需要在项目开始时,就将这一列创建出来,问题就能得到解决。
然而,由于实际生产环境中,业务不断发展,最终一个业务有几个指标,每个指标都是什么名字,分别对应什么类型,是难以预测的,所以我们总是无法做到 100%的未雨绸缪。
03 灵活不太好用的窄表
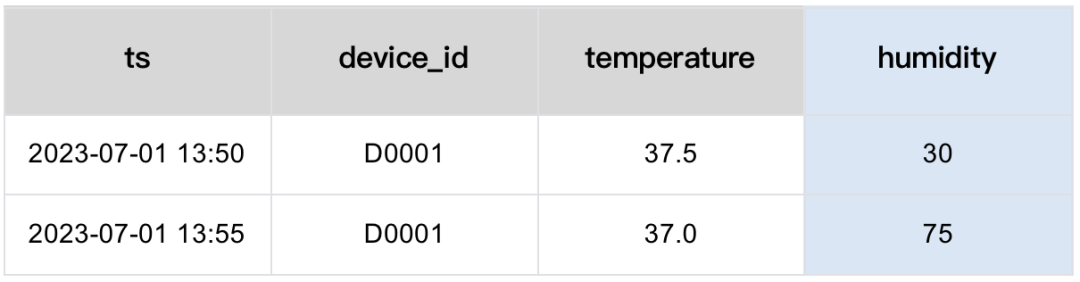
如果不能改表,那么有没有办法在一个表中存储所有的数据呢?如果我们每种必要的数据类型都创建一列,然后额外增添一个指标名列,那么多个指标就可以对应为多行数据,那么就做到了用有限的列记录所有的指标。
如上表所示,无论有多少个不同指标,都能存储在有限的列中。与其使用灵活的优点相比,其缺点同样突出:
1. 随着指标增多,表的行数会显著多于宽表的实现。
2. 当数据量大时,由于每一行包含多个空字段,会导致额外的存储开销。
3. 当需要针对多个指标进行过滤和计算时,需要复杂的 JOIN,导致相应 SQL 的开发和维护成本都明显变高。
04让宽表变得灵活
我们还有另一种选择:在创建宽表时,为后续的修改留足空间。

我们创建了 4 个冗余列,这样未来增加新的列时,只需要把对应的列改名即可。比如我们把 int_1 列征召为新的湿度列。
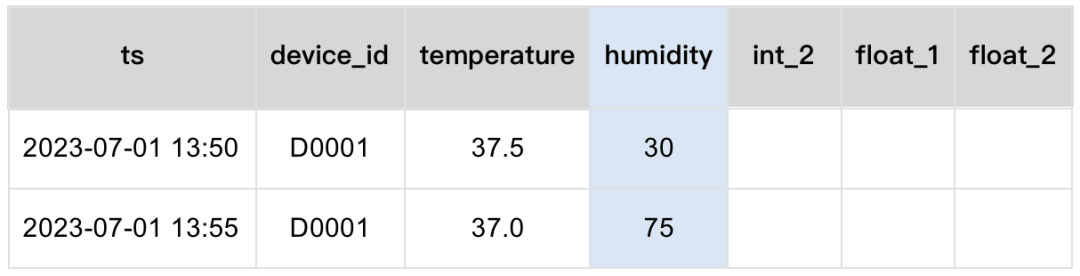
此外,我们也可以选择不更换列名,相应的我们需要额外的用另一张表存储指标名和列名的映射关系。
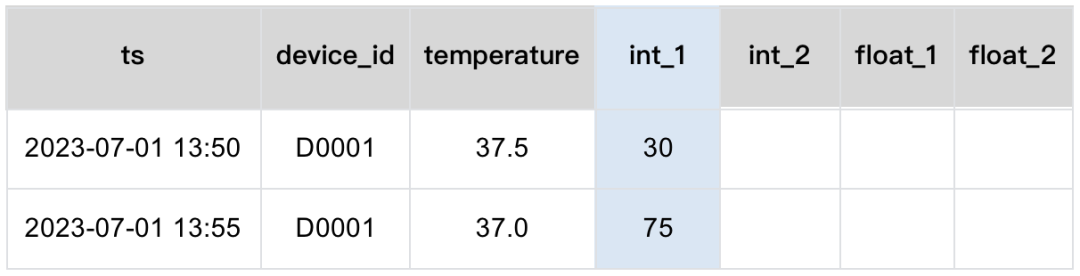

YMatrix 中,一张表最多可以支持 1600列。
这样的表有什么缺陷呢?
对于典型的列式存储,比如 AOCO 存储,可以理解为每一个列对一个文件。如果我们真的预留了 1600 列,只用了其中 100 列,那么插入一条数据时,即便其中仅有 100 列有数据,也可能会需要操作 1600 个文件,其写入性能可想而知。因此,这种方式虽然方便,但是具体创建表时需要留下多少列,也是需要根据实际情况权衡的。
除此之外,由于列名的变更,也可能造成对上层应用产生额外的风险。
而如果我们选择不更换列名,则查询时需要和指标映射表进行 JOIN, 会增加额外的复杂度。
05 平衡性能与灵活性的 JSON 字段
针对宽表,我们还有另一个解决方案:在固定字段之外,追加一个额外的 JSON 列。
1. 我们将高频查询的指标单独设置为列,
2. 追加 JSON 列,用以存储所有低频查询的指标。
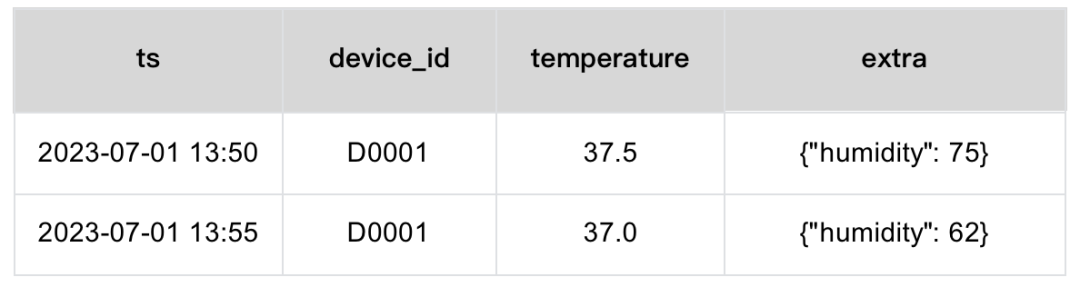
不足:
1. 查询 JSON 列中的数据时性能逊于独立的列。
2. 查询 JSON 列中的数据时,需要使用一些高级的语法。
-- 查询湿度(humidity)
SELECT extra::json->'humidity' FROM demo;好处:
1. 独立的列会被独立存储和处理,可以提供更佳的性能,且使用直观方便。
2. JSON 列则负责提供足够的灵活性,可以随意往里面增加新指标,无需考虑类型,字段数量。
3. 虽然 JSON 列的查询涉及一些稍微复杂的语法,但其直观性,复杂度,都远远好于窄表。
06 更高性能的 mxkv 字段
JSON 列提供了良好的灵活性,然而其性能并不尽如人意。当我们同时要求很高的灵活性和性能时, YMatrix 企业版专有的 mxkv 类型字段就是非常合适的选择。
mxkv 是一种单层的 JSON,读写时语法与 JSON 相同,但 mxkv 要求限定 JSON 中值字段的类型。
如上一张示例中的 extra 字段,我们可以指定其类型为 mxkv_int4,这样 extra 就可以用以灵活的存储多个 int4 类型的指标。
CREATE TABLE data(
time timestamp with time zone,
device_id text,
temperature float,
extra mxkv_int4 -- 新增 extra 字段
)
DISTRIBUTED BY (device_id);除此之外,还需要通过函数 mxkv_import_keys 预先指定 extra 中的字段名(humidity),才可以向其中写入。
mxadmin=# SELECT mxkv_import_keys('demo'::regclass, '{"humidity": 75}');
mxkv_import_keys
------------------
humiditymxkv 类型虽然使用相对复杂,但是其性能相较 JSON 字段仍然有着明显的优势。在一些字段数量较多,查询复杂的时序场景中,仍然有着独特的优势。目前 YMatrix 研发团队仍在对 mxkv 类型进行持续优化,在未来版本中,我们会进一步提升其使用便利性和性能。
关于 mxkv 更详细的介绍,可以参阅官方文档 《可扩展数据类型:mxkv》:
https://ymatrix.cn/doc/5.1/datamodel/mxkv
Reference:
1. 时序数据模型是什么:
https://ymatrix.cn/doc/5.1/datamodel/what_is_time-Series_datamodel
2. 时序建模思路:
https://ymatrix.cn/doc/5.1/datamodel/guidebook
3. YMatrix 数据建模视频教程:
https://www.bilibili.com/video/BV133411r7WH
本文为 YMatrix 原创内容,未经允许不得转载。
欲了解更多超融合时序数据库相关信息,请访问 “YMatrix 超融合数据库” 官方网站




![计算机视觉与深度学习-全连接神经网络-训练过程-模型正则与超参数调优- [北邮鲁鹏]](https://img-blog.csdnimg.cn/a9e2d73ad52c4b94a751d208e1c4a9ce.png)