在前面的文章中我们讲述了锁的理解、原理、用户级线程库的内容,以及对Linux中的锁和线程进行了封装,本文中将继续对多线程的内容进行讲解。
可重入与线程安全
概念
- 线程安全:多个线程并发同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现该问题。
- 重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
常见的线程不安全的情况
- 不保护共享变量的函数
- 函数状态随着被调用,状态发生变化的函数
- 返回指向静态变量指针的函数
- 调用线程不安全函数的函数
常见的线程安全的情况
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的
- 类或者接口对于线程来说都是原子操作
- 多个线程之间的切换不会导致该接口的执行结果存在二义性
常见不可重入的情况
- 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的
- 调用了标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构
- 可重入函数体内使用了静态的数据结构
常见可重入的情况
- 不使用全局变量或静态变量
- 不使用用malloc或者new开辟出的空间
- 不调用不可重入函数
- 不返回静态或全局数据,所有数据都有函数的调用者提供
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据
可重入与线程安全联系
- 函数是可重入的,那就是线程安全的(多执行流调用这个可重入函数就是线程安全的)
- 函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题
- 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的。
可重入与线程安全区别
- 可重入函数是线程安全函数的一种
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个重入函数若锁还未释放则会产生死锁,因此是不可重入的。
总的来说,线程安全与不安全之间有好坏之分,我们需要选择线程安全的线程,可重入与不可重入函数描述的是一个函数的特征,这没有好坏的区别。
死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
死锁的四个必要条件(只产生死锁四个条件都要有)
- 互斥条件:一个资源每次只能被一个执行流使用
- 请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放
- 不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺
- 循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
多线程代码 -> 并发访问临界资源 -> 加锁 -> 可能导致死锁 -> 解决死锁问题
避免死锁
核心思想:破坏死锁四个必要条件中的任意一个。
- 不加锁
- 主动释放锁
- 我们按照顺序申请锁
- 控制线程统一释放锁
下面我们就来看一段简单的程序说明死锁的问题:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *threadRoutine(void *args) {
cout << "I am a new thread " << endl;
pthread_mutex_lock(&mutex);
cout << "I got a mutex!" << endl;
pthread_mutex_lock(&mutex); // 申请锁的问题,它会停下来
cout << "I alive again" << endl;
return nullptr;
}
int main() {
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, nullptr);
sleep(3);
cout << "main thread run begin" << endl;
pthread_mutex_unlock(&mutex);
cout << "main thread unlock..." << endl;
sleep(3);
return 0;
}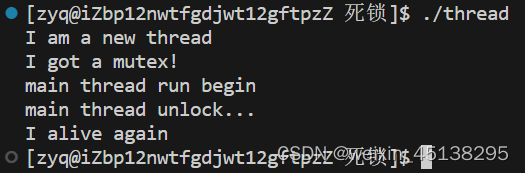
通过上述的图片可以看出我们在新线程中进行了死锁的操作,然后主线程中进行了解锁,可以正常的运行,说明一个线程可以控制另一个线程的解锁,加锁与解锁不必写在同一个函数中。
线程同步
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。以之前编写的抢票为例子,对于ticket的判断是放在临界区的,那么假设票数小于了0,对于票数来说就不会进行--的操作,此时又有新的票生成,但是ticket的大小此时还是==0的,那么就会陷入一种情况,加锁 - 条件不满足 - 解锁,这三种状态的循环,那么该线程就会在ticket的大小改变之前什么都无法操作,这样就会造成资源的浪费。
例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。
上述的这两种情况可能就会让一个线程长期的占用资源 -- 引起饥饿问题,这件事情没什么错,但是不是很合理,在安全的规则下,多线程的访问资源具有一定的顺序,为了合理的解决饥饿问题,此时就需要线程同步,让多线程进行协同工作。
条件变量
条件变量的概念与接口
在上述的这种情况下,就引入了条件变量,条件变量用于衡量需要访问的资源的状态。
条件变量函数初始化
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);
参数:
cond:要初始化的条件变量
attr:NULL
等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
参数:
cond:要在这个条件变量上等待
mutex:互斥量
唤醒等待
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
销毁
int pthread_cond_destroy(pthread_cond_t *cond)
demo代码
#include <iostream>
#include <pthread.h>
#include <string>
#include <unistd.h>
using namespace std;
const int num = 5;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void* active(void* args) {
string name = static_cast<const char*>(args);
while (true)
{
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond, &mutex); // pthread_cond_wait 调用的时候会自动释放锁
cout << name << " 活动 " << endl;
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main() {
pthread_t tids[num];
for (int i = 0; i < num; ++i) {
char* name = new char[32];
snprintf(name, 32, "thread-%d", i+1);
pthread_create(tids+i, nullptr, active, name);
}
sleep(3);
while(true) {
cout << " main thread wake up thread... " << endl;
pthread_cond_signal(&cond);
sleep(1);
}
for (int i = 0; i < num; ++i) {
pthread_join(tids[i], nullptr);
}
}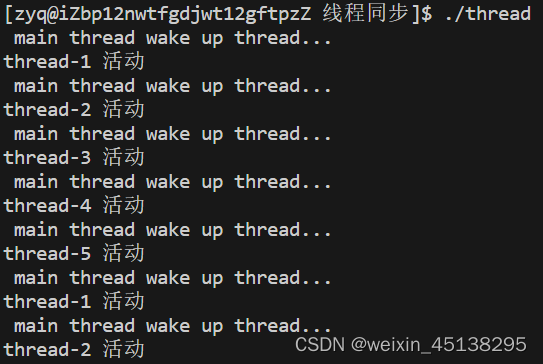 从图中就可以看出通过pthread_cond_signal唤醒的线程都已经实现了在条件变量下的自动排队。如果我们使用了pthread_cond_broadcast那么我们就会唤醒全部的线程。条件变量就是允许多线程在cond进行队列式的等待。
从图中就可以看出通过pthread_cond_signal唤醒的线程都已经实现了在条件变量下的自动排队。如果我们使用了pthread_cond_broadcast那么我们就会唤醒全部的线程。条件变量就是允许多线程在cond进行队列式的等待。
生产者消费者模型 - 使用条件变量与互斥锁实现一个CP
为何要使用生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
生产者消费者模型优点
解耦
支持并发(效率高)
支持忙闲不均(允许生产消费的步调可以不一致)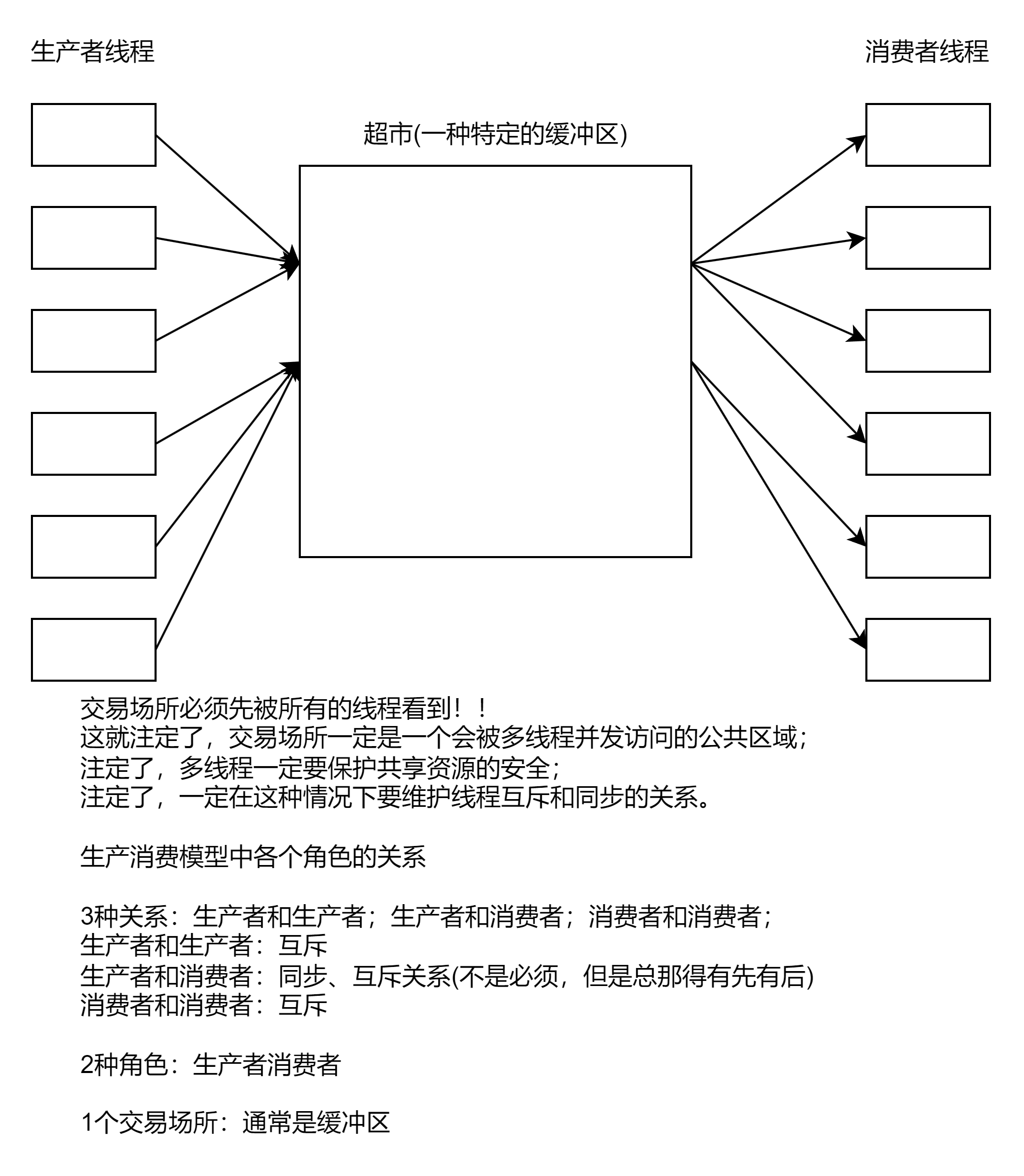
基于BlockingQueue的生产者消费者模型
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
下面我们就来编写一下demo代码,首先我们以单生产,单消费为例子,中间的交易场所设置为阻塞队列,那么在阻塞队列中需要有push和pop的接口,对于生产者线程首先需要获得数据,然后将数据推送至阻塞队列中,完成生产过程。对于消费者线程需要做的就是将数据从阻塞队列中获取,然后再结合某种业务,处理获得的数据。上面说了阻塞队列与普通队列的不同之处,那么就需要我们有条件变量来确定某种顺序,当队列为空时消费者阻塞,当队列为满时生产者阻塞,那么说明我们需要有两个条件变量。
void push(const T& in)
{
pthread_mutex_lock(&_mutex);
// 细节1:一定要保证在任何时候都是符合条件,才进行生产
while(isFull()) // 1. 我们只能在临界区内部判断临街资源是否就绪!注定了我们在当前一定是持有锁的
{
// 2. 要让线程进行休眠等待,不能持有锁等待!
// 3. 注定了,pthread_cond_wait要有持有锁的释放的能力
pthread_cond_wait(&_productorCond, &_mutex); // 我休眠(切换)了,我醒来的时候,在哪里往后执行
// 4. 当线程醒来的时候,注定了继续从临界区内部继续运行,应为是从临界区被切走的!
// 5. 注定了当线程被唤醒的时候,继续在pthread_cond_wait函数出向后运行,又要重新申请锁,申请成功才会彻底返回
}
// 没有满的
_q.push(in);
// 加策略唤醒
pthread_cond_signal(&_consumerCond); // 放在解锁前或者解锁后都可以
pthread_mutex_unlock(&_mutex);
// pthread_cond_signal(_consumerCond);
}
void pop(T *out)
{
pthread_mutex_lock(&_mutex);
while(isEmpty())
{
pthread_cond_wait(&_consumerCond, &_mutex);
}
// 不是空的
*out = _q.front();
_q.pop();
// 加策略唤醒
pthread_cond_signal(&_productorCond);
pthread_mutex_unlock(&_mutex);
}首先对与push和pop需要先加锁,然后进行判断如果处于队列满或者队列空的情况,满足条件的不同的线程就需要进行阻塞,等到条件满足之后再将其进行唤醒。
同样对于多生产与多消费的模型也是一样的,只需要多加几个线程即可,因为这里不同的生产者个不同的消费者使用的是同一把锁,那么就不会有冲突的可能性,可以正常的运行。
信号量
信号量(信号灯):本质上就是一个计数器,用来衡量临界资源的数量,信号量需要进行pv操作,p == --,v == ++,原子的。二元信号量:信号量的变化是1 -> 0 -> 1这就与之前学习过的互斥锁是一致的。
每一个线程,在访问对应资源的时候,先申请信号量申请成功,表示该线程允许使用该资源,申请不成功,目前无法使用该资源。信号量的工作机制就类似于我们看电影买票,是一种资源的预定机制。信号量已经是资源的计数器,申请信号量的成功,本身就表明资源可用,申请信号量失败本身就表明资源不可用 -- 本质就是把判断转化成信号量的申请行为。
接口
初始化信号量
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数:
pshared:0表示线程间共享,非零表示进程间共享
value:信号量初始值
销毁信号量
int sem_destroy(sem_t *sem);
等待信号量
功能:等待信号量,会将信号量的值减1
int sem_wait(sem_t *sem); // P()sem_post函数(函数原型 int sem_post(sem_t *sem);)
作用:是从信号量的值减去一个“1”,但它永远会先等待该信号量为一个非零值才开始做减法。
发布信号量
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。
int sem_post(sem_t *sem);// V()作用:给信号量的值加上一个“1”。 当有线程阻塞在这个信号量上时,调用这个函数会使其中一个线程不在阻塞,选择机制是有线程的调度策略决定的。
基于环形队列的生产消费模型
构建CP问题:
1. 生产者和消费者关心的资源是一样的吗?不一样,生产者关心空间,消费者关心数据
2. 只要信号量不为0,表示资源可用,表示线程可访问
3. 环形队列只要我们访问不同的区域生产和消费就可以同时进行
4. 生产和消费什么时候会访问同一个区域?只有为空和为满的时候cp才会指向同一个位置,存在竞争关系;其他情况,cp可以并发运行。
刚开始没有数据的时候 -- 空;让生产者先运行
数据全满的时候 -- 满;让消费者先运行
因此这个基于环形队列的生产消费模型就需要满足这几个条件:
1. 刚开始没有数据的时候,指向同一个位置,存在竞争关系,让生产者先运行
· 2. 数据全满的时候,指向同一个位置,让消费者先运行
3. 不能让消费者超过生产者
4. 不能让生产者套圈消费者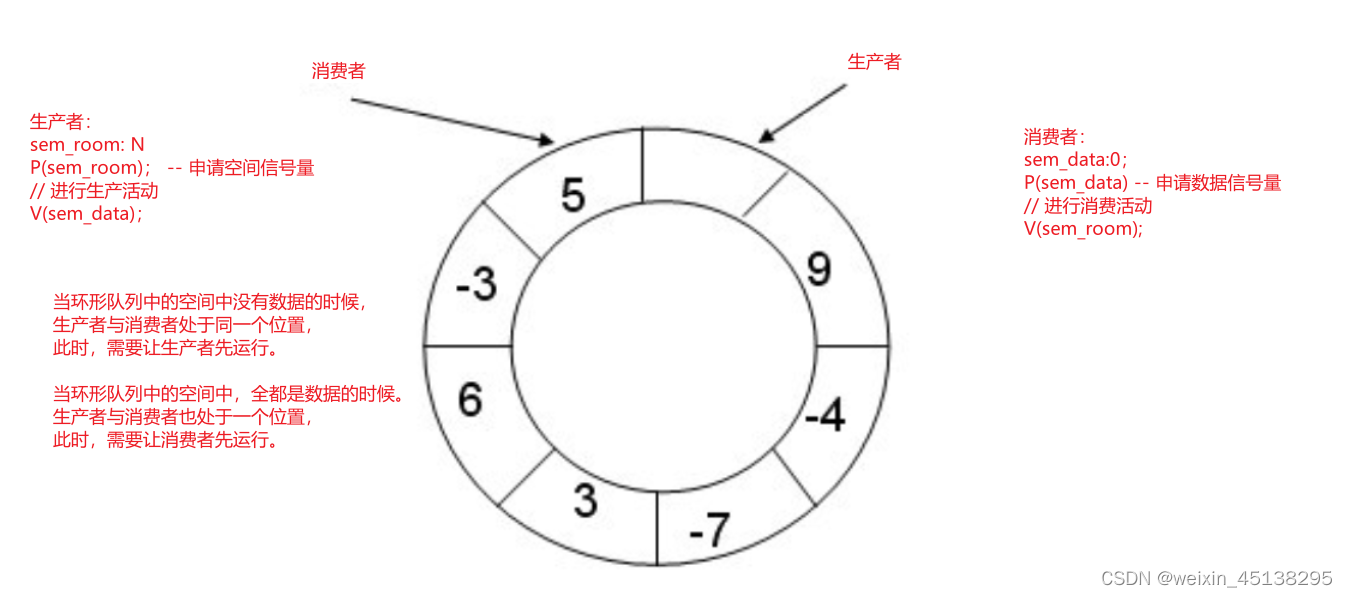
#pragma once
#include <semaphore.h>
#include <mutex>
static const int N = 5;
template <class T>
class RingQueue
{
private:
void P(sem_t &s)
{
sem_wait(&s);
}
void V(sem_t &s)
{
sem_post(&s);
}
void Lock(pthread_mutex_t &m)
{
pthread_mutex_lock(&m);
}
void Unlock(pthread_mutex_t &m)
{
pthread_mutex_unlock(&m);
}
public:
RingQueue(int num = N) : _ring(num), _cap(num)
{
sem_init(&_data_sem, 0, 0); // 消费者关心的信号量,应该被初始化为0
sem_init(&_space_sem, 0, num); // 生产者者关心的信号量,应该被初始化为num
_c_step = _p_step = 0;
pthread_mutex_init(&_c_mutex, nullptr);
pthread_mutex_init(&_p_mutex, nullptr);
}
// 生产
void push(const T &in)
{
// 信号量
// 1. 可以不用在临界区内部做判断,就可以知道临界资源的使用情况
// 2. 什么时候用锁,什么时候用sem?你对应的临界资源,是否被整体使用!
P(_space_sem); // 信号量在前,锁在后 生产线程只要持有锁了,其他线程就只能在外部进行等待,本来可以先分配资源再申请锁进行生产消费
Lock(_p_mutex);
_ring[_p_step++] = in;
_p_step %= _cap;
Unlock(_p_mutex);
V(_data_sem);
}
// 消费
void pop(T *out)
{
P(_data_sem);
Lock(_c_mutex);
*out = _ring[_c_step++];
_c_step %= _cap;
Unlock(_c_mutex);
V(_space_sem);
}
~RingQueue()
{
sem_destroy(&_data_sem);
sem_destroy(&_space_sem);
pthread_mutex_destroy(&_c_mutex);
pthread_mutex_destroy(&_p_mutex);
}
private:
vector<T> _ring;
int _cap; // 环形队列
sem_t _data_sem; // 只有消费者关心
sem_t _space_sem; // 只有生产者关心
int _c_step; // 消费位置
int _p_step; // 生产位置
pthread_mutex_t _c_mutex;
pthread_mutex_t _p_mutex;
};然后下面既可以给这个人基于环形队列的生产消费模型设置对应的任务并多线程来执行,首先封装一个人任务类:
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
class Task
{
public:
Task(){}
Task(int x, int y, char op) : _x(x), _y(y), _op(op), _result(0), _exitCode(0){}
void operator()()
{
switch (_op)
{
case '+':
_result = _x + _y;
break;
case '-':
_result = _x - _y;
break;
case '*':
_result = _x * _y;
break;
case '/':
{
if (_y == 0)
_exitCode = -1;
else
_result = _x / _y;
}
break;
case '%':
{
if (_y == 0)
_exitCode = -2;
else
_result = _x % _y;
}
break;
default:
break;
}
usleep(100000); // 模拟消费者处理数据的时间
}
std::string formatArg()
{
return std::to_string(_x) + _op + std::to_string(_y) + "= ?";
}
std::string formatRes()
{
return std::to_string(_result) + "(" + std::to_string(_exitCode) + ")";
}
~Task()
{}
private:
int _x;
int _y;
char _op;
int _result;
int _exitCode;
};最后我们就可以进行单生产单消费与多生产多消费的模拟实现:
对于生产者与消费者模型我们要建立正确的认知,不一定多生产多消费效率就高。那么多生产多消费的意义在哪里呢?意义绝对不在从缓冲区冲放入和拿去,意义在于,放前并发构建Task,获取后多线程可以并发处理task,因为这些操作没有加锁!
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <time.h>
#include <vector>
#include <cstring>
using namespace std;
#include "Task.hpp"
#include "RingQueue.hpp"
const char *ops = "+-*/%";
void* consumerRoutine(void* args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task>*>(args);
while (true)
{
// sleep(1);
Task t;
rq->pop(&t);
t();
cout << pthread_self() << " " << "consumer done, 处理完成的任务是:" << t.formatRes() << endl;
}
}
void* productorRoutine(void* args)
{
RingQueue<Task> *rq = static_cast<RingQueue<Task>*>(args);
while (true)
{
int x = rand() % 100;
int y = rand() % 100;
char op = ops[(x + y) % strlen(ops)];
Task t(x, y, op);
rq->push(t);
cout << pthread_self() << " " << "productor done, 生产的任务是: " << t.formatArg() << endl;
sleep(1);
}
}
int main()
{
srand(time(nullptr) ^ getpid());
RingQueue<Task> *rq = new RingQueue<Task>();
pthread_t c[3], p[2];
for (int i = 0; i < 3; i++)
pthread_create(c + i, nullptr, consumerRoutine, rq);
for (int i = 0; i < 2; i++)
pthread_create(p + i, nullptr, productorRoutine, rq);
for (int i = 0; i < 3; i++)
pthread_join(c[i], nullptr);
for (int i = 0; i < 2; i++)
pthread_join(p[i], nullptr);
// // 单生产单消费
// pthread_t c, p;
// pthread_create(&c, nullptr, consumerRoutine, rq);
// pthread_create(&p, nullptr, productorRoutine, rq);
// pthread_join(c, nullptr);
// pthread_join(p, nullptr);
delete rq;
return 0;
}
// void* consumerRoutine(void* args)
// {
// RingQueue<int> *rq = static_cast<RingQueue<int>*>(args);
// while (true)
// {
// int data;
// rq->pop(&data);
// cout << "consumer done:" << data << endl;
// }
// }
// void* productorRoutine(void* args)
// {
// RingQueue<int> *rq = static_cast<RingQueue<int>*>(args);
// while (true)
// {
// int data = rand() % 10 + 1;
// rq->push(data);
// cout << "productor done:" << data << endl;
// sleep(1);
// }
// }
// int main()
// {
// srand(time(nullptr) ^ getpid());
// RingQueue<int> *rq = new RingQueue<int>();
// // 单生产单消费
// pthread_t c, p;
// pthread_create(&c, nullptr, consumerRoutine, rq);
// pthread_create(&p, nullptr, productorRoutine, rq);
// pthread_join(c, nullptr);
// pthread_join(p, nullptr);
// delete rq;
// return 0;
// }