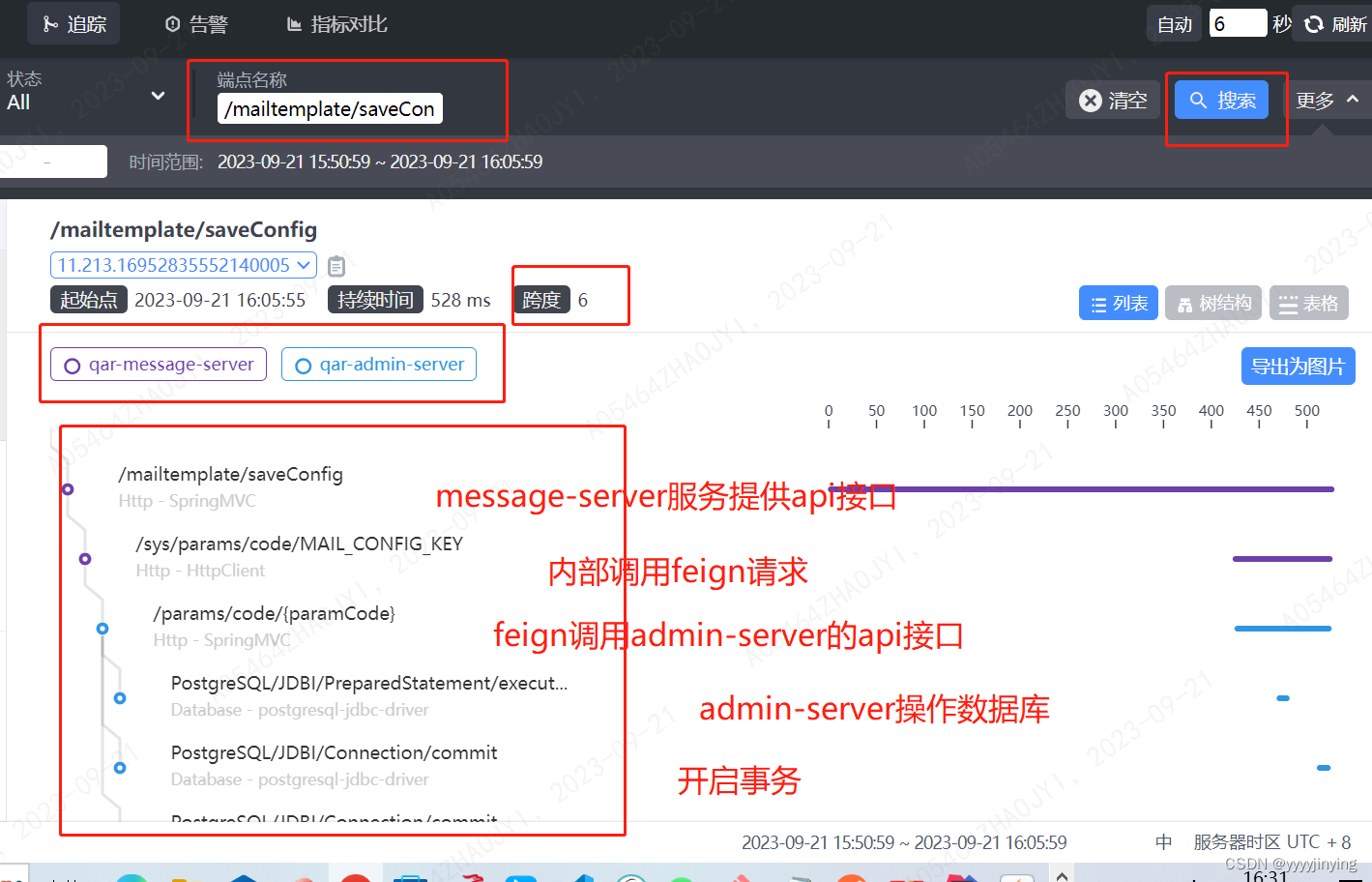
nvme I/O请求时,数据交互分析
主要函数为nvme_queue_rq:
static blk_status_t nvme_queue_rq(struct blk_mq_hw_ctx *hctx, const struct blk_mq_queue_data *bd)
{
struct nvme_ns *ns = hctx->queue->queuedata;
struct nvme_queue *nvmeq = hctx->driver_data;
struct nvme_dev *dev = nvmeq->dev;
struct request *req = bd->rq;
struct nvme_command cmnd;
blk_status_t ret;
if (unlikely(nvmeq->cq_vector < 0))
return BLK_STS_IOERR;
ret = nvme_setup_cmd(ns, req, &cmnd);
if (ret)
return ret;
ret = nvme_init_iod(req, dev);
if (ret)
goto out_free_cmd;
if (blk_rq_nr_phys_segments(req)) { //segments物理段的个数,每个物理段的长度不一定就是4096
ret = nvme_map_data(dev, req, &cmnd);
if (ret)
goto out_cleanup_iod;
}
blk_mq_start_request(req);
nvme_submit_cmd(nvmeq, &cmnd);//将命令提交到sq队列,然后写db寄存器
return BLK_STS_OK;
out_cleanup_iod:
nvme_free_iod(dev, req);
out_free_cmd:
nvme_cleanup_cmd(req);
return ret;
}
这里重点是分析nvme_map_data函数,在分析该函数之前,先看一下nvme_init_iod函数,对于后面的理解会很有帮助。
nvme_init_iod函数:
static blk_status_t nvme_init_iod(struct request *rq, struct nvme_dev *dev)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(rq);
int nseg = blk_rq_nr_phys_segments(rq);
unsigned int size = blk_rq_payload_bytes(rq);
iod->use_sgl = nvme_pci_use_sgls(dev, rq);//判断使用sgl还是prp
//nseg > 2 || size > 2 * (dev)->ctrl.page_size(假设值为4096)
if (nseg > NVME_INT_PAGES || size > NVME_INT_BYTES(dev)) {
iod->sg = mempool_alloc(dev->iod_mempool, GFP_ATOMIC);//大小是alloc_size
if (!iod->sg)
return BLK_STS_RESOURCE;
} else {
iod->sg = iod->inline_sg; //这个感觉有点奇怪,这个变量是一个指针,后面不申请内存空间直接使用了?
}
iod->aborted = 0;
iod->npages = -1;
iod->nents = 0;
iod->length = size;
return BLK_STS_OK;
}
这里我们先假设iod->sg走的是第一个分支,也就是通过内存池分配的内存,大小是alloc_size,
这个值是怎么来的呢?
在nvme_probe函数里,有这一段代码:
alloc_size = nvme_pci_iod_alloc_size(dev, NVME_MAX_KB_SZ, NVME_MAX_SEGS, true);
WARN_ON_ONCE(alloc_size > PAGE_SIZE); //只打印一次异常信息 alloc_size = 2040
dev->iod_mempool = mempool_create_node(1, mempool_kmalloc, mempool_kfree, (void *) alloc_size, GFP_KERNEL, node);
if (!dev->iod_mempool) {
result = -ENOMEM;
goto release_pools;
}
其中NVME_MAX_KB_SZ为4096, NVME_MAX_SEGS为127,我们接着看nvme_pci_iod_alloc_size函数,
static int nvme_npages(unsigned size, struct nvme_dev *dev)
{
unsigned nprps = DIV_ROUND_UP(size + dev->ctrl.page_size, dev->ctrl.page_size);
return DIV_ROUND_UP(8 * nprps, PAGE_SIZE - 8); //可能会浪费一些内存
}
static int nvme_pci_npages_sgl(unsigned int num_seg) //计算SGL段所需的页面数。例如,一个4k页面可以容纳256个SGL描述符。
{
return DIV_ROUND_UP(num_seg * sizeof(struct nvme_sgl_desc), PAGE_SIZE); //int(A/B) + 1 ->int(127 * 16)/4096 + 1
}
static unsigned int nvme_pci_iod_alloc_size(struct nvme_dev *dev, unsigned int size, unsigned int nseg, bool use_sgl)
{
size_t alloc_size;
if (use_sgl)
alloc_size = sizeof(__le64 *) * nvme_pci_npages_sgl(nseg);//8 * 1
else
alloc_size = sizeof(__le64 *) * nvme_npages(size, dev);
return alloc_size + sizeof(struct scatterlist) * nseg; //alloc_size + 16 * 127 映射+记录
}
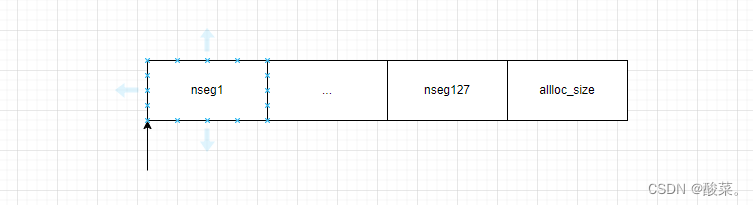
因为use_sgl传进来的是true,所以走的是上面那个分支,所以最终alloc_size 的大小是像下面这样表示的,那alloc_size = sizeof(__le64 *) * nvme_pci_npages_sgl(nseg);的表示是什么意思呢?先说结论,这个是为了后面通过pool申请内存时记录这些内存用的,因为这些内存地址是64位的所以这里要用 sizeof(__le64 *) 乘以 nvme_pci_npages_sgl(nseg),至于nvme_pci_npages_sgl(nseg)这个函数不多说了,自己看看也很容易理解,这里要说的是NVME_MAX_KB_SZ和NVME_MAX_SEGS值的大小是可以调整的。而nseg1-nseg127是为了后面映射sgl时申请的内存空间,在这里记录下来映射的sgl。
接着回来看nvme_map_data函数。
static blk_status_t nvme_map_data(struct nvme_dev *dev, struct request *req, struct nvme_command *cmnd)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct request_queue *q = req->q;
enum dma_data_direction dma_dir = rq_data_dir(req) ? DMA_TO_DEVICE : DMA_FROM_DEVICE;//数据传输方向
blk_status_t ret = BLK_STS_IOERR;
int nr_mapped;
//主要就是初始化iod->sg, blk_rq_nr_phys_segments(req)返回的时sge段的个数
sg_init_table(iod->sg, blk_rq_nr_phys_segments(req));
iod->nents = blk_rq_map_sg(q, req, iod->sg);//这个函数主要将bio里的数据转到iod->sg里
if (!iod->nents)
goto out;
ret = BLK_STS_RESOURCE;
//这里有了数据以后可以做dma mapping了
nr_mapped = dma_map_sg_attrs(dev->dev, iod->sg, iod->nents, dma_dir, DMA_ATTR_NO_WARN);//iod->sg dma mapping
if (!nr_mapped)
goto out;
if (iod->use_sgl)
ret = nvme_pci_setup_sgls(dev, req, &cmnd->rw, nr_mapped);
else
ret = nvme_pci_setup_prps(dev, req, &cmnd->rw);
if (ret != BLK_STS_OK)
goto out_unmap;
ret = BLK_STS_IOERR;
//这个if语句是为metadata做map操作,然后把dma地址给到cmnd->rw.metadata成员 看起来数据量应该不是太大
if (blk_integrity_rq(req)) {
if (blk_rq_count_integrity_sg(q, req->bio) != 1)
goto out_unmap;
sg_init_table(&iod->meta_sg, 1);
if (blk_rq_map_integrity_sg(q, req->bio, &iod->meta_sg) != 1)
goto out_unmap;
if (!dma_map_sg(dev->dev, &iod->meta_sg, 1, dma_dir))
goto out_unmap;
}
if (blk_integrity_rq(req))
cmnd->rw.metadata = cpu_to_le64(sg_dma_address(&iod->meta_sg));
return BLK_STS_OK;
out_unmap:
dma_unmap_sg(dev->dev, iod->sg, iod->nents, dma_dir);
out:
return ret;
}
接着先看nvme_pci_setup_sgls函数,然后在看nvme_pci_setup_prps函数。
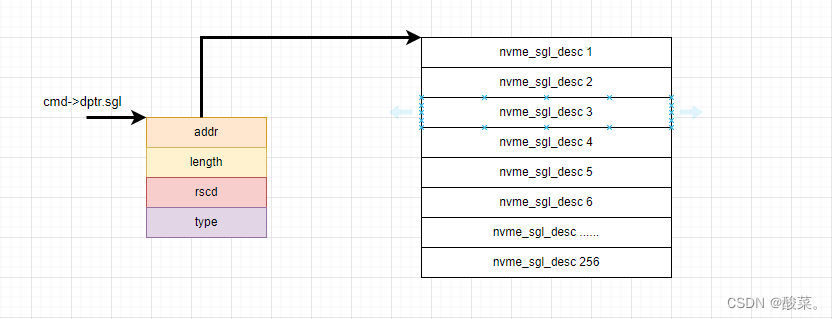
static blk_status_t nvme_pci_setup_sgls(struct nvme_dev *dev, struct request *req, struct nvme_rw_command *cmd, int entries)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
struct dma_pool *pool;
struct nvme_sgl_desc *sg_list;
struct scatterlist *sg = iod->sg;
dma_addr_t sgl_dma;
int i = 0;
cmd->flags = NVME_CMD_SGL_METABUF; //setting the transfer type as SGL
if (entries == 1) {
nvme_pci_sgl_set_data(&cmd->dptr.sgl, sg); //使用sgl,则使用struct nvme_sgl_desc 结构体
return BLK_STS_OK;
}
//这里是根据sge的个数来指定 走那个分支的,避免内存的浪费
if (entries <= (256 / sizeof(struct nvme_sgl_desc))) { //256 / 16 = 16 总的大小是256,除以16表示可以放几个struct nvme_sgl_desc
pool = dev->prp_small_pool; //大小256(如果走这个分支,pool的大小是256,可以表示16个struct nvme_sgl_desc)
iod->npages = 0;
} else {
pool = dev->prp_page_pool; //大小4096/16 = 256 所以可以表示 256个struct nvme_sgl_desc
iod->npages = 1;
}
sg_list = dma_pool_alloc(pool, GFP_ATOMIC, &sgl_dma);
if (!sg_list) {
iod->npages = -1;
return BLK_STS_RESOURCE;
}
//这两个操作是为了后面的释放?看起来是的
/*
记录下这个值,类似于*(iod->sg + blk_rq_nr_phys_segments) = sg_list
使用二级指针可以记录的范围更多,如果使用一级指针记录的值范围不全
*/
nvme_pci_iod_list(req)[0] = sg_list;
iod->first_dma = sgl_dma;
nvme_pci_sgl_set_seg(&cmd->dptr.sgl, sgl_dma, entries); //给rw command sgl设置链的起始地址
do {
if (i == SGES_PER_PAGE) { //256 pool = dev->prp_page_pool; 才会走这个分支
struct nvme_sgl_desc *old_sg_desc = sg_list;
struct nvme_sgl_desc *link = &old_sg_desc[i - 1];
sg_list = dma_pool_alloc(pool, GFP_ATOMIC, &sgl_dma);
if (!sg_list)
return BLK_STS_RESOURCE;
i = 0;
nvme_pci_iod_list(req)[iod->npages++] = sg_list;//记录申请的dma addr 方便后面释放
/*因为上一个sg_list的最后一个sg_desc用来记录链表了,所以将*link这个上一个list的最后一个记录数据
的地方,换到下一个list的第一个位置。
*/
sg_list[i++] = *link;
nvme_pci_sgl_set_seg(link, sgl_dma, entries);
}
nvme_pci_sgl_set_data(&sg_list[i++], sg);
sg = sg_next(sg);
} while (--entries > 0);
return BLK_STS_OK;
}
先看读写命令时的数据结构,NVME的命令都是64个字节的。
struct nvme_sgl_desc {
__le64 addr;
__le32 length;
__u8 rsvd[3];
__u8 type;
};
struct nvme_keyed_sgl_desc {
__le64 addr;
__u8 length[3];
__u8 key[4];
__u8 type;
};
union nvme_data_ptr {
struct {
__le64 prp1;
__le64 prp2;
};
struct nvme_sgl_desc sgl;
struct nvme_keyed_sgl_desc ksgl;
};
struct nvme_rw_command {
__u8 opcode;
__u8 flags;
__u16 command_id;
__le32 nsid;
__u64 rsvd2;
__le64 metadata;
union nvme_data_ptr dptr;
__le64 slba;
__le16 length;
__le16 control;
__le32 dsmgmt;
__le32 reftag;
__le16 apptag;
__le16 appmask;
};
类似这样来表示数据,所以,如果用sgl的话,addr记录地址,length记录一个sge的长度,二prp的就只有两个64位prp指针,要用它来表示地址和要传输的长度,处理起来就麻烦一些。
static void nvme_pci_sgl_set_data(struct nvme_sgl_desc *sge, struct scatterlist *sg)
{
sge->addr = cpu_to_le64(sg_dma_address(sg));
sge->length = cpu_to_le32(sg_dma_len(sg));
sge->type = NVME_SGL_FMT_DATA_DESC << 4;
}
static void nvme_pci_sgl_set_seg(struct nvme_sgl_desc *sge, dma_addr_t dma_addr, int entries)
{
sge->addr = cpu_to_le64(dma_addr);
if (entries < SGES_PER_PAGE) {
sge->length = cpu_to_le32(entries * sizeof(*sge));
sge->type = NVME_SGL_FMT_LAST_SEG_DESC << 4;
} else {
sge->length = cpu_to_le32(PAGE_SIZE);
sge->type = NVME_SGL_FMT_SEG_DESC << 4;
}
}
static void **nvme_pci_iod_list(struct request *req)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
//前面是记录了映射的地址,所以是iod->sg加上blk_rq_nr_phys_segments(req)
return (void **)(iod->sg + blk_rq_nr_phys_segments(req));
}
最后再来看看释放的代码:
static void nvme_unmap_data(struct nvme_dev *dev, struct request *req)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
enum dma_data_direction dma_dir = rq_data_dir(req) ? DMA_TO_DEVICE : DMA_FROM_DEVICE;
if (iod->nents) {
dma_unmap_sg(dev->dev, iod->sg, iod->nents, dma_dir);
if (blk_integrity_rq(req))
dma_unmap_sg(dev->dev, &iod->meta_sg, 1, dma_dir);
}
nvme_cleanup_cmd(req);
nvme_free_iod(dev, req);
}
static void nvme_free_iod(struct nvme_dev *dev, struct request *req)
{
struct nvme_iod *iod = blk_mq_rq_to_pdu(req);
const int last_prp = dev->ctrl.page_size / sizeof(__le64) - 1;
dma_addr_t dma_addr = iod->first_dma, next_dma_addr;
int i;
if (iod->npages == 0)
dma_pool_free(dev->prp_small_pool, nvme_pci_iod_list(req)[0], dma_addr);
for (i = 0; i < iod->npages; i++) {
void *addr = nvme_pci_iod_list(req)[i];//这个是虚拟地址
if (iod->use_sgl) {
struct nvme_sgl_desc *sg_list = addr;
//256 - 1 最后一个描述符的addr记录的是下一个 list dma pool的起始dma地址
next_dma_addr = le64_to_cpu((sg_list[SGES_PER_PAGE - 1]).addr);
} else {
__le64 *prp_list = addr;
next_dma_addr = le64_to_cpu(prp_list[last_prp]);
}
dma_pool_free(dev->prp_page_pool, addr, dma_addr);
dma_addr = next_dma_addr;
}
//不相等说明iod->sg是通过mempool_alloc申请内存的,这里通过mempool_free进行释放
if (iod->sg != iod->inline_sg)
mempool_free(iod->sg, dev->iod_mempool);
}
下一篇文章再分析prp这块的代码。