一、数据字典介绍
数据字典是ClickHouse提供一种非常简单且实用的存储媒介,他以键值和属性映射的形式定义数据。字典中的数据会主动或被动加载到内存并支持动态更新。由于字典数据常驻内存的特性,所以非常适合保存常量或经常使用的维度表数据,从而避免不必要的JOIN查询。
数据字典分为内置与扩展两种形式,内置字典顾名思义就是ClickHouse 默认自带的字典,而外部字典是用户通过自定义配置实现的字典,也叫扩展字典。
正常情况下,字典中的数据只能通过字典函数访问(ClickHouse设置了一类字典函数,专门用于字典数据的取用)。但是也有一种例外,那就是使用特殊的字典表引擎,在字典表引擎的帮助下,可以将数据字典挂载到一张代理的数据表下,从而实现数据表与字典数据的JOIN查询。
1.1 内置字典
ClickHouse目前只有一种内置字典:Yandex.Metrica字典,从名称上来看,这个字典是ClickHouse自家产品上的字典,而他设计目的是快速存取地理数据。较为遗憾的是,由于版权原因,Yandex并没有将geo地理数据开放出来。这意味着,ClickHouse目前的内置字典只是提供了定义机制和取数的函数,所以内置字典的现状较为尴尬,需要遵循它的规范自行导入数据,由于现实工作中使用场景很少,只做了解即可。
1.2 外部扩展字典
外部扩展字典是以插件的形式注册到ClickHouse中,由用户自定义数据模式以及数据来源,目前扩展字典支持7种类型的内存布局和4类数据来源,性比内置字典,扩展字典才是更适合更多的业务场景。
接下来,将重点介绍常用的外部扩展字典的使用。
二、 前置准备
数据准备
在clickhouse安装完成后,配置文件默认在 : /etc/clickhouse-server 目录下,进入到该目录,有一个config.xml的文件;

通过grep 命令,查找当前配置文件,找到 dictionaries_config 这样一个标签所在的位置;
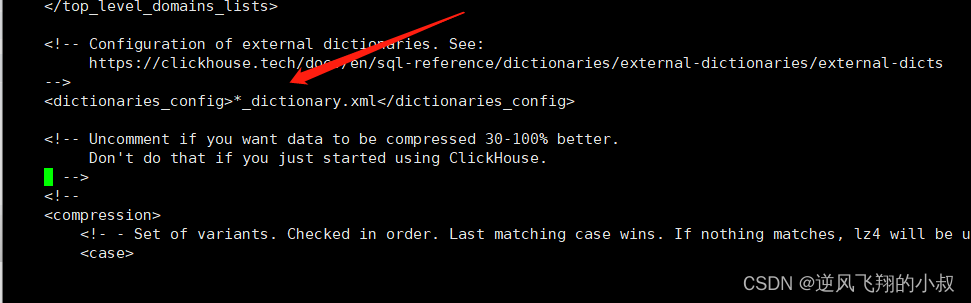
默认的情况下,ClickHouse会自动识别并加 载/etc/clickhouse-server目录下所有以_dictionary.xml结尾的配置 文件。同时ClickHouse也能够动态感知到此目录下配置文件的各种变 化,并
支持不停机在线更新配置文件
所以,接下来我们只需要将测试数据的定义放在/etc/clickhouse-server目录下即可;
准备3个csv文件

各个文件中内容如下
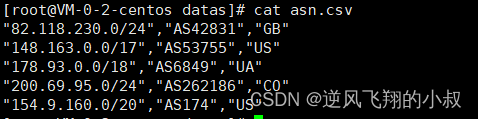
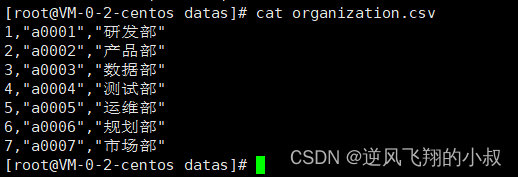

完整的配置结构如下所示
如果在/etc/clickhouse-server 目录下自定义字典,需要编写一个以dictionary.xml格式的文件,文件的格式大致遵循如下格式;
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>
dict_name
</name>
<structure>
<!—字典的数据结构 -->
</structure>
<layout>
<!—在内存中的数据格式类型 -->
</layout>
<source>
<!—数据源配置 -->
</source>
<lifetime>
<!—字典的自动更新频率 -->
</lifetime>
</dictionary>
</dictionaries>
三、外部扩展字典使用
(1)文件类型
数据字典在加载数据时,根据文件的来源不同,又可以细分为本地文件,可执行文件,和远程文件,它们是最易使用也是最直接的数据源,很适合在静态数据这类场景中使用;
本地文件
本地文件使用file这个标签元素进行定义,其中path表示数据文件的绝对路径,而format表示数据文件的格式,比如CSV格式等,完整的配置结构如下:
<source>
<file>
<path>/etc/clickhouse-server/datas/organization.csv</path>
<format>CSV</format>
</file>
</source>可执行文件
可执行文件数据源属于本地文件的变种,需要通过cat 命令访问数据文件。对于cache和complex_key_cache类型的字典,必须使用此类型的文件数据源。可执行文件使用executable标签元素定义。其中,command表示数据文件的绝对路径,format表示数据格式,完整配置如下:
<source>
<executable>
<command>cat /etc/clickhouse-server/datas/organization.csv</command>
<format>CSV</format>
</executable>
</source>
远程文件
远程文件与可执行文件类似,只是将cat命令替换成了post请求,支持http与https两种协议,远程文件使用http标签元素定义,其中url表示远程数据的访问地址,format标签表示数据格式,完整配置如下:
<source>
<http>
<url>http://IP/organization.csv</command>
<format>CSV</format>
</http>
</source>
接下来,先详细说明下在clickhouse中如何加载本地文件到数据字典的;
(2)七种扩展字典类型的配置使用
扩展字典的类型使用layout元素定义,目前共有7种类型。一个字典的 类型,既决定了其数据在内存中的存储结构,也决定了该字典支持的key键 类型。根据key键类型的不同,可以将它们划分为两类:
- 单数值key类型(flat、 hashed、range_hashed和cache);
- 复合key类型(complex_key_hashed、complex_key_cache和 ip_trie);
3.1 flat类型
flat类型的字典是所有类型中性能最高的类型,它只能使用UInt64数值型 key。flat类型的字典数据在内存中使用数组结构保存。数组的初始 大小为1024,上限为500000,这意味着它最多只能保存500000行数据。如果在创建字典时数据量超出其上限,那么字典会创建失败。
在/etc/clickhouse- server 目录下创建一个flat类型的配置文件
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>flat_dict</name>
<source>
<!-- 加载上一步提前准备好的测试csv数据 -->
<file>
<path>/etc/clickhouse-server/datas/organization.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<flat/>
</layout>
<!-- 与测试csv数据的字段结构对应上 -->
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
保存之后不需要重启clickhouse服务,直接使用下面的sql查询,可以看到已经作为字典表加载进去了;
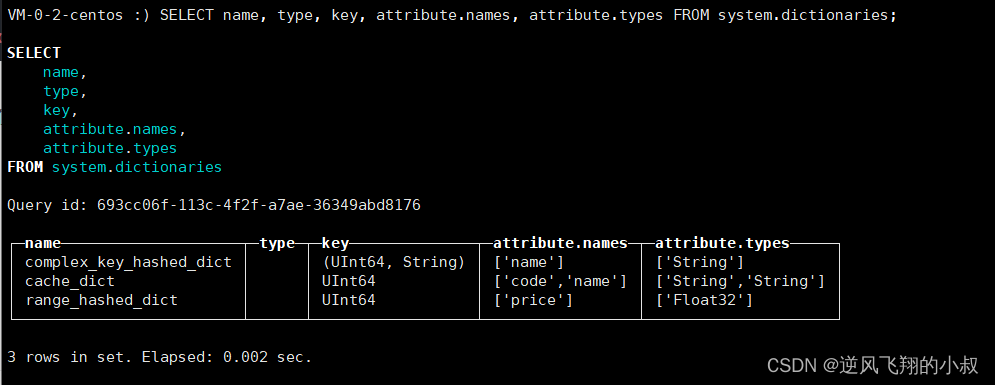
SELECT name, type, key, attribute.names, attribute.types FROM system.dictionaries;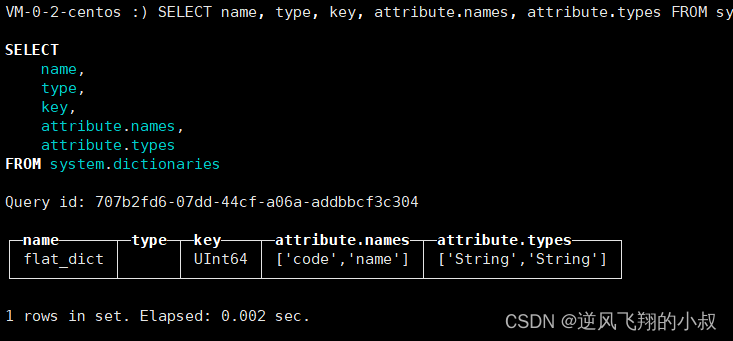
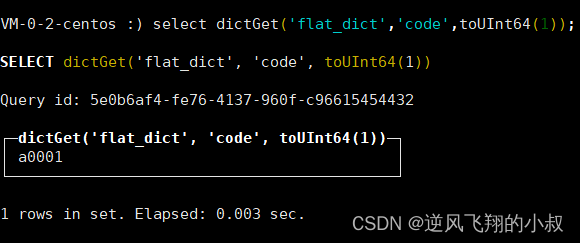
使用下面的sql查询字典表的数据,如下要查找 flat_dict这个字典中id为1的code字段的数据;
select dictGet('flat_dict','code',toUInt64(1));查询出的结果正好就是上面机构csv中的id为1的code值
查找系统中的字典表相关信息
select * from system.dictionaries;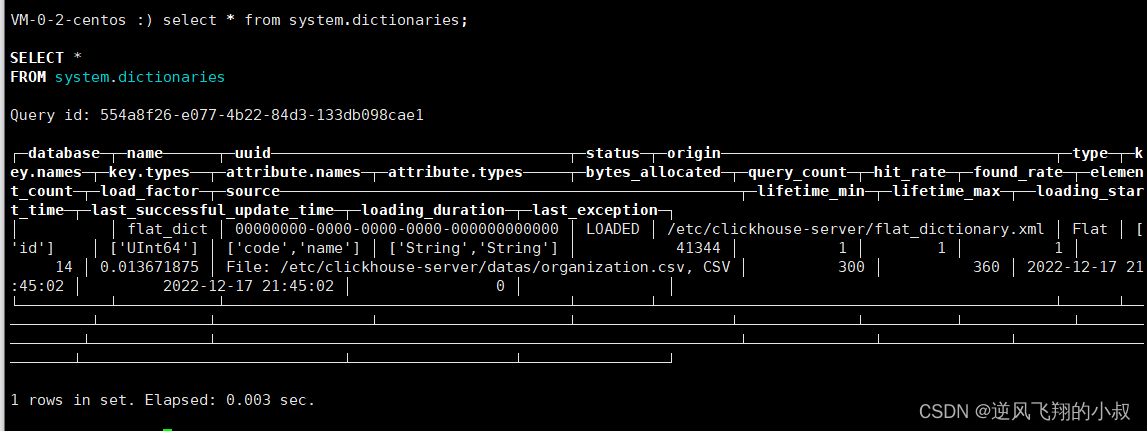
3.2 hashed类型
hashed字典同样只能够使用UInt64数值型key,但与flat字典不同的 是,hashed字典的数据在内存中通过
散列结构保存,且没有存储上限的制约。
在当前目录新增一个 org_hashed_dictionary.xml 的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>org_hashed_dictionary</name>
<source>
<file>
<path>/etc/clickhouse-server/datas/organization.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<hashed/>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
3.3 range_hashed 类型
range_hashed字典可看作hashed字典的变种,它在原有功能的基础上 增加了指定时间区间的特性,数据会以
散列结构存储并按照时间排序。时间区间通过range_min和range_max元素指定,所指定的字段必须是Date或者 DateTime类型。
在当前目录新增一个 sale_range_dictionary.xml 的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>range_hashed_dict</name>
<source>
<file>
<path>/etc/clickhouse-server/datas/sales.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<range_hashed/>
</layout>
<structure>
<id>
<name>id</name>
</id>
<range_min>
<name>start</name>
</range_min>
<range_max>
<name>end</name>
</range_max>
<attribute>
<name>price</name>
<type>Float32</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
仍然使用上面的sql可以查询到上面加载到系统中的字典表

3.4 cache类型
cache字典只能够使用UInt64数值型key,它的字典数据在内存中会通过
固定长度的向量数组保存。定长的向量数组又称cells,它的数组长度由size_in_cells指定。而size_in_cells的取值大小必须是2的整数倍,如若 不是,则会自动向上取为2的倍数的整数。
cache字典取数逻辑与其他字典有所不同,它并不会一次性将所有数 据载入内存。当从cache字典中获取数据时,首先会在cells数组中检查该数据是否已经被缓存过。如果没有被缓存,才会从源头加载数据并缓存到cells中。所以cache字典是性能最不稳定的字典,因为它的性能优劣完 全取决于缓存的命中率(缓存命中率=命中次数/查询次数),如果无法做到 99%或者更高的缓存命中率,则最好不要使用此类型。
在当前目录新增一个 cache_dictionary.xml的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>cache_dict</name>
<source>
<!-- 本地文件需要通过 executable形式 -->
<executable>
<command>cat /etc/clickhouse-server/datas/organization.csv</command>
<format>CSV</format>
</executable>
</source>
<layout>
<cache>
<!-- 缓存大小 -->
<size_in_cells>10000</size_in_cells>
</cache>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
仍然使用上面的sql可以查询到上面加载到系统中的字典表
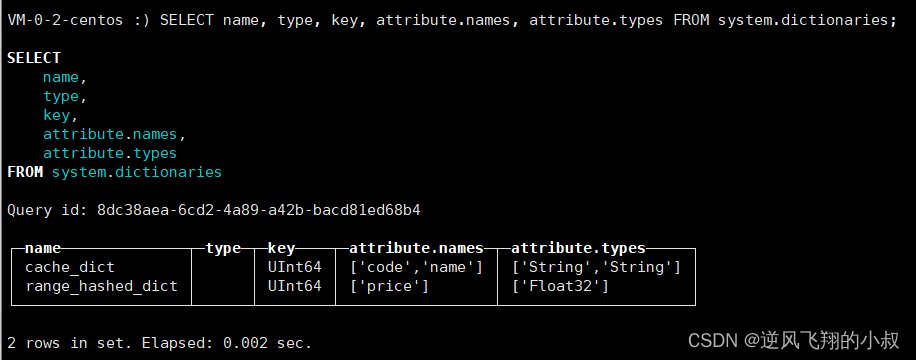
关于cells的取值可以根据实际情况考虑,在内存宽裕的情况下设 置成1000000000也是可行的。还有一点需要注意,如果cache字典使用本地 文件作为数据源,则必须使用executable的形式设置。
3.5 complex_key_hashed 类型
complex_key_hashed字典在功能方面与hashed字典完全相同,只是将单 个数值型key替换成了
复合型。
在当前目录新增一个 complex_dictionary.xml的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>complex_key_hashed_dict</name>
<source>
<file>
<path>/etc/clickhouse-server/datas/organization.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<complex_key_hashed/>
</layout>
<structure>
<!-- 复合型key -->
<key>
<attribute>
<name>id</name>
<type>UInt64</type>
</attribute>
<attribute>
<name>code</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
仍然使用上面的sql可以查询到上面加载到系统中的字典表
3.6 complex_key_cache 类型
在当前目录新增一个 complex_key_cache_dictionary.xml的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>complex_key_cache_dict</name>
<source>
<executable>
<command>cat /etc/clickhouse-server/datas/organization.csv</command>
<format>CSV</format>
</executable>
</source>
<layout>
<complex_key_cache>
<size_in_cells>10000</size_in_cells>
</complex_key_cache>
</layout>
<structure>
<!-- 复合型Key -->
<key>
<attribute>
<name>id</name>
<type>UInt64</type>
</attribute>
<attribute>
<name>code</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
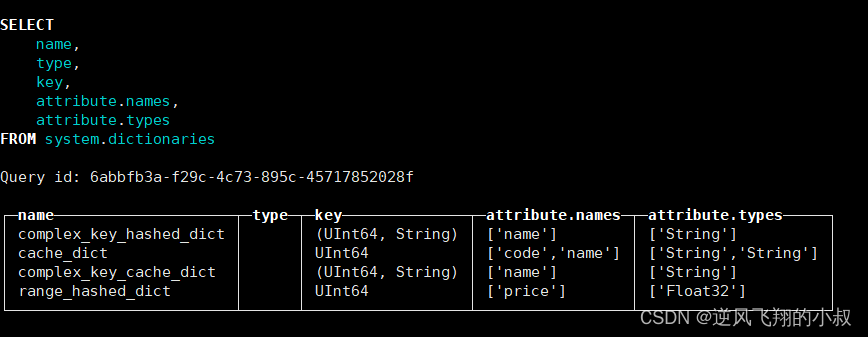
3.7 ip_trie类型
虽然同为复合型key的字典,但ip_trie字典却较为特殊,因为它只能
指定单个String类型的字段,用于指代IP前缀。ip_trie字典的数据在内存中使用trie树结构保存,且专门用于IP前缀查询的场景,例如通过IP前缀查询对应的ASN信息。
在当前目录新增一个 ip_trie_dictionary.xml的文件,配置如下内容:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>ip_trie_dict</name>
<source>
<file>
<path>/etc/clickhouse-server/datas/asn.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<ip_trie/>
</layout>
<structure>
<!-- 虽然是复合类型,但是只能设置单个String类型的字段 -->
<key>
<attribute>
<name>prefix</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>asn</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>country</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
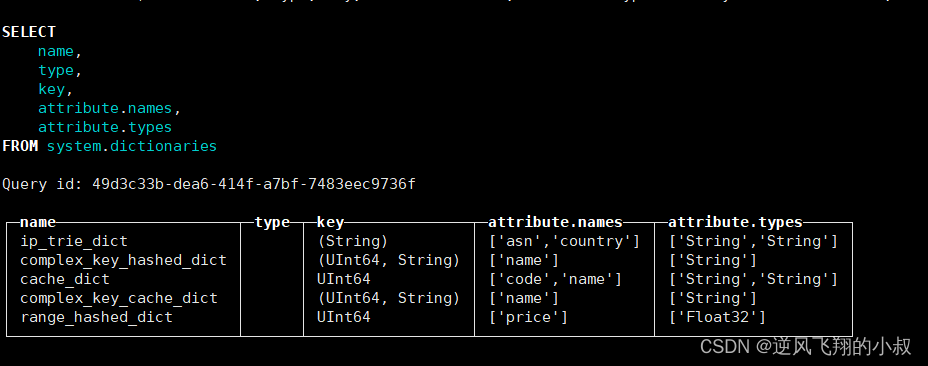
在上面列举的这些字典中,flat、hashed和range_hashed依次拥有最高的性能,因此优先推荐使用,而cache性能最不稳定,不推荐使用
以上详细介绍了如何使用本地文件作为数据源字典加载数据的过程
(3)使用数据库的表数据作为字典数据源
相比文件类型,数据库类型的数据源更适合在正式的生产环境中使用。目前扩展字典支持MySQL、 ClickHouse本身及MongoDB三种数据库。
从mysql作为数据源操作
创建测试表
create table t_organization(
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` varchar(64) DEFAULT NULL,
`name` varchar(64) DEFAULT NULL,
`updatetime` datetime DEFAULT NULL,
PRIMARY KEY(`id`)
) ENGINE=INNODB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;导入两条测试数据
INSERT INTO `db_test`.`t_organization`(`id`, `code`, `name`, `updatetime`) VALUES (1, 'a001', '研发部', '2022-12-18 10:23:39');
INSERT INTO `db_test`.`t_organization`(`id`, `code`, `name`, `updatetime`) VALUES (2, 'a001', '产品部', '2022-12-17 10:24:05');
完成上面的准备之后,在当前的目录下,创建一个mysql_dictionary.xml的配置文件,内容如下:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>mysql_dict</name>
<source>
<mysql>
<port>3312</port>
<user>root</user>
<password>XXX<password/>
<replica>
<host>你的数据库连接IP地址</host>
<priority>1</priority>
</replica>
<db>db_test</db>
<table>t_organization</table>
<!--
<where>id=1</where>-->
<invalidate_query>select updatetime from t_organization where id = 8</invalidate_query>
</mysql>
</source>
<layout>
<flat/>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>updatetime</name>
<type>DateTime</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
当然,这里也提供下面这种方式,以供参考,有兴趣的同学可以操作一下;
-- clickhouse 使用mysql作为dict字典表
-- mysql
CREATE TABLE ch_dict.dict_demo(
id bigint(20)PRIMARY KEY,
value_1 varchar(400),
value_2 varchar(400)
);
insert into dict_demo values (1,'v1','v2');
insert into dict_demo values (2,'vv1','vv2');
-- clickhouse
CREATE DICTIONARY dict.dict_demo (
id UInt64,
value_1 String DEFAULT '',
value_2 String DEFAULT ''
)
PRIMARY KEY id
SOURCE(MYSQL(
port 3306
user 'root'
password 'xxx'
replica(host 'mysql_host_address' priority 1)
db 'ch_dict'
table 'dict_demo'
invalidate_query 'select id from ch_dict.dict_demo where 1=0'
fail_on_connection_loss 'true'
))
LAYOUT(HASHED())
LIFETIME(MIN 1 MAX 10);
SELECT * FROM dict_demo;
SELECT dictGet('dict_demo', 'value_1', 2);
从clickhouse作为数据源操作
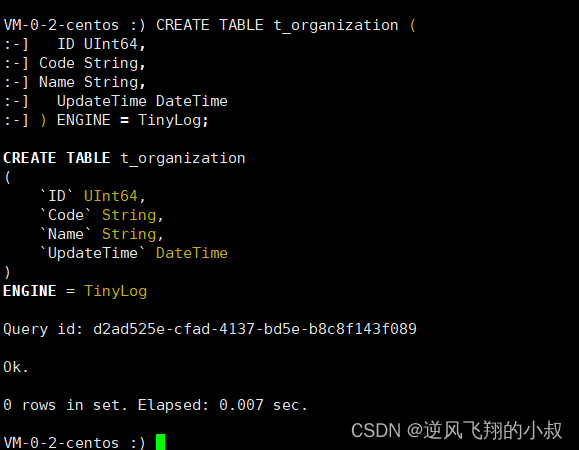
顾名思义,数据字典中的数据来源于clickhouse自身的表,在当前目录下创建clickhouse_dictionary.xml的配置文件,首先需要创建一张数据表作为字典的数据来源;
创建测试表并写入测试数据
CREATE TABLE t_organization (
ID UInt64,
Code String,
Name String,
UpdateTime DateTime
) ENGINE = TinyLog;
--写入测试数据
INSERT INTO t_organization VALUES
(1,'a0001','研发部',NOW()),
(2,'a0002','产品部' ,NOW()),
(3,'a0003','数据部',NOW());

配置clickhouse_dictionary.xml
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_dict</name>
<source>
<clickhouse>
<host>你的clickhouse所在IP</host>
<port>9000</port>
<user>default</user>
<password>密码<password/>
<db>datasets</db>
<table>t_organization</table>
<!--
<where>id=10</where>-->
<!-- 指定一条SQL语句,用于在数据更新时判断是否需要更新,非必填项 -->
<invalidate_query>SELECT UpdateTime FROM t_organization WHERE ID = 1</invalidate_query>
</clickhouse>
</source>
<layout>
<flat/>
</layout>
<!--大小写敏感,需要与数据表字段对应-->
<structure>
<id>
<name>ID</name>
</id>
<attribute>
<name>Code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>Name</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>UpdateTime</name>
<type>DateTime</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
从mongodb作为数据源操作
clickhouse也提供了从mongodb作为数据源将数据导入到clickhouse的字典表中,在当前目录下创建mongodb_dictionary.xml文件,配置如下:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>mongodb_dict</name>
<source>
<mongodb>
<host>你的mongoIP</host>
<port>27017</port>
<user>用户名<user/>
<password密码><password/>
<db>test_db</db>
<collection>t_organization</collection>
</mongodb>
</source>
<layout>
<flat/>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
四、扩展字典的常用操作
当数据集字典数据加载完成后,接下来就是针对数据字典表的各种操作和使用了
数据查询
正常情况下,字典数据只能通过字典函数获取,例如下面的语句就使用到了
dictGet('dict_name','attr_name',key)函数
SELECT dictGet('flat_dict', 'name', toUInt64(1));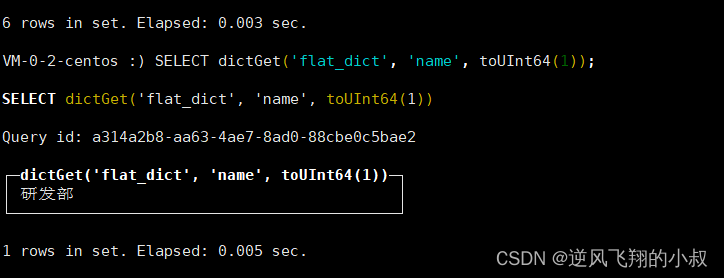
如果字典使用了复合型key,则需要使用元组作为参数传入:
SELECT dictGet('ip_trie_dict', 'asn', tuple(IPv4StringToNum('82.118.230.0')));
除了dictGet函数之外,ClickHouse还提供了一系列以dictGet为前缀的字典函 数,如下所示:
- 获取整型数据的函数:
dictGetUInt8、dictGetUInt16、dictGetUInt32、 dictGetUInt64、dictGetInt8、dictGetInt16、dictGetInt32、dictGetInt64; - 获取浮点数据的函数:
dictGetFloat32、dictGetFloat64; - 获取日期数据的函数:
dictGetDate、dictGetDateTime; - 获取字符串数据的函数:
dictGetString、dictGetUUID;
字典表操作
除了通过字典函数读取数据之外,ClickHouse还提供了另外一种
借助字典表的形式来读取数据。字典表是使用Dictionary表引擎的数据表(即上文中创建的那个字典表)
建表语句如下
CREATE TABLE test_flat_dict (
id UInt64,
code String,
name String
) ENGINE = Dictionary(flat_dict);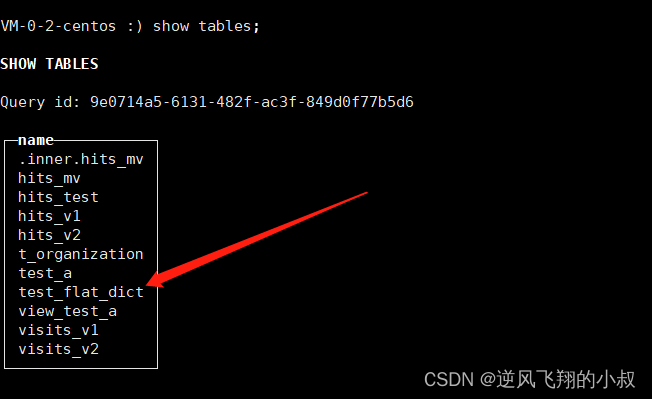
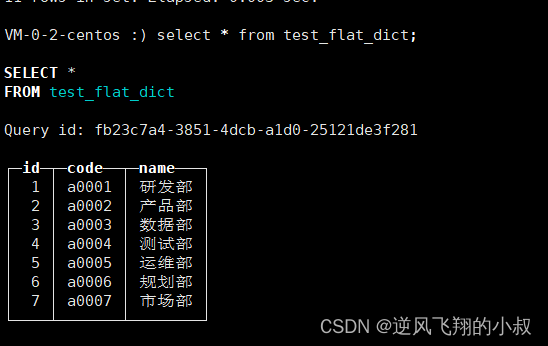
那么通过这张表,就能查询到字典中的数据
使用DDL查询创建字典
从19.17.4.11版本开始,clickhouse开始支持使用DDL查询创建数据字典,如下:
CREATE DICTIONARY test_dict(
id UInt64,
value String
)
PRIMARY KEY id
LAYOUT(FLAT())
SOURCE(FILE(PATH '/usr/bin/cat' FORMAT TabSeparated))
LIFETIME(1);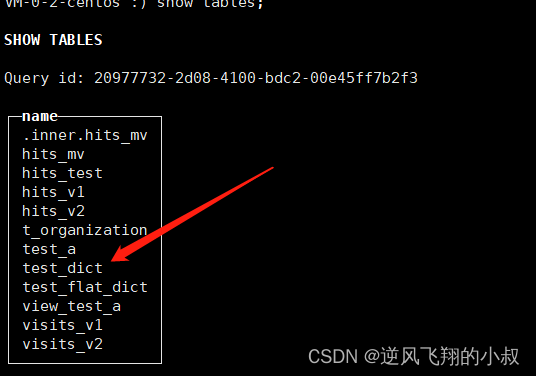
字典引擎 Dictionary
Dictionary表引擎是数据字典的一层代理封装,它可以取代字典函数,让用户通过数据表查询字典。字典内的数据被加载后,会全部保存到内存中,所以使用 Dictionary表对字典性能不会有任何影响。
test_flat_dict等同于数据字典flat_dict的代理表,现在对它使用 SELECT语句进行查询
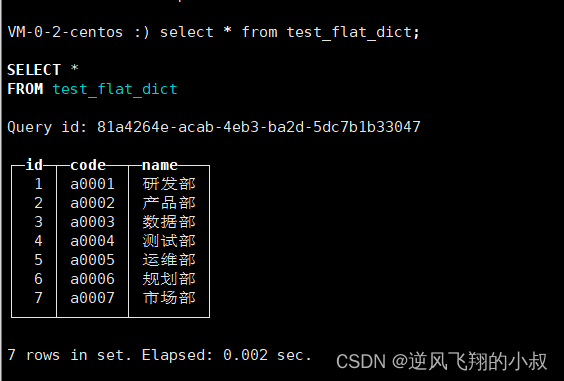
如果字典数量很多,逐一为它们创建各自的Dictionary表就过于烦琐。这时可以使用Dictionary引擎类型的数据库来解决这个问题,例如:
CREATE DATABASE my_test_dictionaries ENGINE = Dictionary;


上述语句创建了一个名为my_test_dictionaries的数据库,它使用了Dictionary 类型的引擎。在这个数据库中,ClickHouse会自动为每个字典分别创建它们的 Dictionary表,这时候如果使用下面的sql进行查询,可以看到之前已经创建的那些字典表都被纳入到当前的这个数据字典所在的库下了;
SELECT
database,
name,
engine_full
FROM system.tables
WHERE database = 'my_test_dictionaries';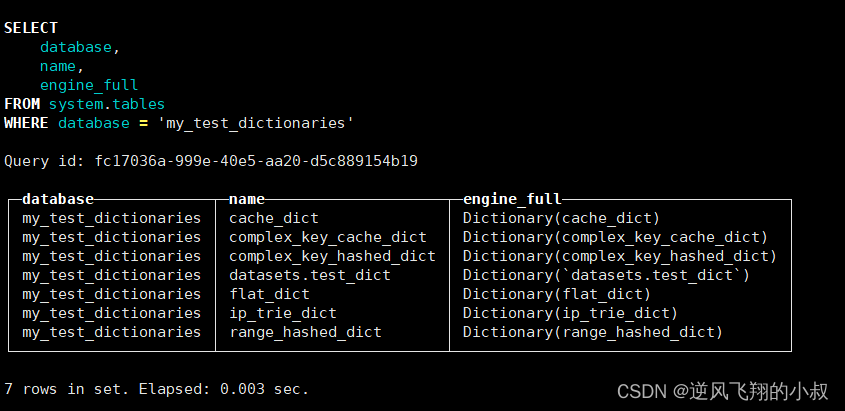

![[附源码]计算机毕业设计Python公共台账管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/b0f0bbfcae3844dfb75711984db40b1e.png)







![[附源码]计算机毕业设计Python贵港高铁站志愿者服务平台(程序+源码+LW文档)](https://img-blog.csdnimg.cn/6c37b894c26b44028fb8c8627dee4848.png)

![[附源码]Nodejs计算机毕业设计江西婺源旅游文化推广系统Express(程序+LW)](https://img-blog.csdnimg.cn/c7fc02a05e294ea3bf22c62dcc3fd35f.png)