《c专家编程》
- 第一章 C:穿越时空的迷雾
- 第二章 这不是Bug,而是语言特性
- gets实验
- 第三章 分析C语言的声明
- const实验
- 第四章 令人震惊的事实:数组和指针并不相同
- 指针与数组实验
- 第五章 对链接的思考
- 简单静态库动态库实验
- 第六章 运动的诗章:运行时数据结构
- 第七章 对内存的思考
- 悬挂指针实验
- 第八章 为什么程序员无法分清万圣节和圣诞节
- 第九章 再论数组
- 第十章: 再论指针
- 第十一章:你懂得C,所以C++不在话下
第一章 C:穿越时空的迷雾
这也是为什么C++语言令人失望的原因:它对C语言中存在的一些最基本的问题没有什么改进,而它对C语言最重要的扩展(类)却是建立在脆弱的C类型模型上。
C–K&R C 与 ANSI C的区别
1.10 安静的改变——无符号整数与有符号比较
/*
一个微妙的Bug,利用了sizeof返回值为无符号整数long unsigned int及表达式同时存在有符号整数与无符号整数时,所有操作将转换为无符号整数这两个特性
*/
#include <stdio.h>
#define len(array) (sizeof(array) / sizeof(array[0])) // 获取数组长度
int main() {
int test[] = {23, 34, 17, 204, 58};
int d = -1, x;
printf("%d %ld\n", d, len(test) - 2);
if (d <= len(test) - 2) {
x = test[d + 1];
printf("%d\n", x);
} else {
printf("no assignment\n");
printf("d:%u len(test) - 2:%lu\n", d, len(test) - 2);
}
}
/*
output:
-1 3
no assignment
d:4294967295 len(test) - 2:3
*/
// 更为清晰地展示有符号整数与无符号整数测试相等性
#include <stdio.h>
int main() {
unsigned int a = 1;
int b = -1;
if (a > b) {
printf("right answer\n");
} else {
printf("wrong answer\n");
}
printf("%d\n", (int)a);
printf("%u %x\n", (unsigned int)b, (unsigned int)b);
unsigned int c = 0xffffffff;
printf("%d\n", (int)c);
}
/*
output:
wrong answer
1
4294967295 ffffffff
-1
*/
无符号整数和有符号整数之间进行强制类型转换时,位模式不改变。
有符号数转换为无符号数时,负数转换为大的正数,相当于在原值上加上2的n次方,而正数保持不变。
无符号数转换为有符号数时,对于小的数将保持原值,对于大的数将转换为负数,相当于原值减去2的n次方。
当表达式中存在有符号数和无符号数类型时,所有的操作都自动转换为无符号类型。可见无符号数的运算优先级高于有符号数。
C++有符号与无符号之间的转换问题
对于无符号类型的建议:
尽量不要在代码中使用无符号类型,以免增加不必要的复杂性。尤其是不要仅仅因为无符号数不存在负值就用它来表示数量。
只有在使用位段和二进制掩码时,才可以用无符号数。应该在表达式中使用强制类型转换,使操作数均为有符号数或者无符号数,这样就不必由编译器来选择结果的类型。
第二章 这不是Bug,而是语言特性
2.2 多做之过
一:由于存在fall through,switch语句会带来麻烦
fall through:如果case语句后面不加break,就依次执行下去,以满足某些特殊情况的要求。
二:粉笔也成了可用的硬件
相邻的字符串常量将会自动合并成一个字符串
/*
如果字符串中间漏了一个逗号,则会自动合并成一个字符串。正如test数组看似有4个元素,但字符串合并,实际上只有3个元素
*/
#include <stdio.h>
#define len(array) (int)(sizeof(array) / sizeof(array[0]))
int main() {
char *test[] = {
"123"
"456",
"789",
"000"};
printf("str len:%d\n", len(test)); // 输出字符指针数组的长度
for (int i = 0; i < len(test); i++) {
printf("%s\n", test[i]);
}
}
/*
output:
str len:3
123456
789
000
*/
三:太多的缺省可见性
定义C函数时,在缺省情况下函数的名字是全局可见的。可以在函数的名字前加个冗余的extern关键字,也可以不加,效果是一样的。
interposition:用户编写和库函数同名的函数并取而代之的行为
2.3 误做之过
一:骆驼峰上的重载
static:
①在函数内部,表示该变量的值在各个调用间一直保持延续性
②在函数这一级,表示该函数只对本文件可见
extern:
①用于函数定义。表示全局可见(属于冗余的)
②用于变量,表示它在其他地方定义
void:
①作为函数的返回类型,表示不返回任何值
②在指针声明中,表示通用指针的类型
③位于参数列表中,表示没有参数
*:
①乘法运算符
②用于指针,间接引用
③在声明中,表示指针
():
①在函数定义中,包围形式参数表
②调用一个函数
③改变表达式的运算次序
④将值转换为其他类型(强制类型转换)
⑤定义带参数的宏
⑥包围sizeof操作符的操作数
二有些运算符的优先级是错误的
表达式与其实际结果
*p.f <==> *(p.f)
int* ap[] <==> int* (ap[])
int*fp() <==> int* (fp())
val& mask != 0 <==> val & (mask != 0)
c=getchar() != EOF <==> c = (getchar() != EOF)
msb<<4+lsb <==> msb << (4+lsb)
i = 1,2 <==> (i = 1),2

&运算符的优先级本应该比==高,只是最开始&同时表示&和&&(布尔运算与位运算),当&起&&作用时
if(a==b & c==d) 等同于 if(a==b && c==d)
如果提升&的优先级,则以上代码便会出错
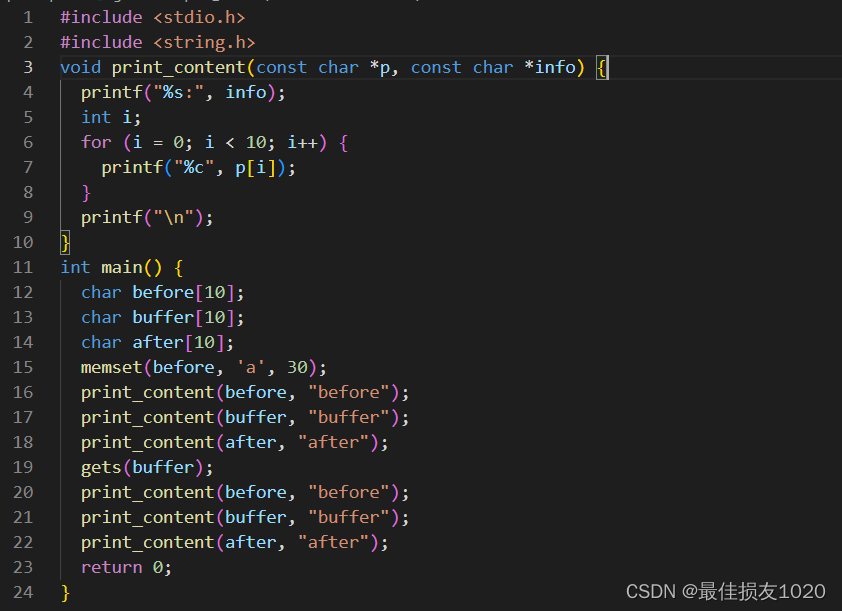
三:早期gets函数中的Bug导致了Internet蠕虫
gets实验
/*
使用gets函数违规地覆盖掉之后地址的值
*/
#include <stdio.h>
#include <string.h>
void print_content(const char *p, const char *info) {
printf("%s:", info);
for (int i = 0; i < 10; i++) {
printf("%c", p[i]);
}
printf("\n");
}
int main() {
char before[10];
char buffer[10];
char after[10];
memset(before, 'a', 30);
print_content(before, "before");
print_content(buffer, "buffer");
print_content(after, "after"); // 函数调用前的值
gets(buffer);
print_content(before, "before");
print_content(buffer, "buffer");
print_content(after, "after"); // 函数调用后的值
return 0;
}
# 编译输出
gcc gets.c -Wall -g -o gets
gets.c: In function ‘main’:
gets.c:18:3: warning: implicit declaration of function ‘gets’; did you mean ‘fgets’? [-Wimplicit-function-declaration]
18 | gets(buffer);
| ^~~~
| fgets
/usr/bin/ld: /tmp/ccUUhP2R.o: in function `main':
/root/tianchi/codebase/expr/expert/gets.c:18: warning: the `gets' function is dangerous and should not be used.
# 结果(输入1234567890123)
before:aaaaaaaaaa
buffer:aaaaaaaaaa
after:aaaaaaaaaa
1234567890123
before:aaaaaaaaaa
buffer:1234567890
after:123aaaaaa
# 使用gdb显示各变量的地址
gdb
Breakpoint 1, main () at gets.c:10
10 int main() {
(gdb) p &before
$1 = (char (*)[10]) 0x7fffffffde8a
(gdb) p &buffer
$2 = (char (*)[10]) 0x7fffffffde94
(gdb) p &after
$3 = (char (*)[10]) 0x7fffffffde9e
(gdb)
gets函数破坏了after数组的数据
2.4 少做之过
一:用户名中若有字母f,便不能收到邮件
程序参数解析时选项与其他参数难以区分问题
二:空格——最后的领域
三:C++的另一种注释形式
四:编译器日期被破坏——返回指向局部变量的指针
实际可行的方法:
在函数内部申请动态内存,交由数据使用者释放
在函数外部申请动态内存,并传递给函数(推荐)
// 使用示例
1:
char* func1(){
char * p = malloc(100);
...
return p;
}
void func2(){
char* q = func1();
...
free(q)
}
2:
void func1(char* p){
...
}
void func2(){
char* q = malloc(10);
func1(q);
...
free(q);
}
五:lint程序决不应该被分离出来
先来说说什么是“静态程序分析(Static program analysis)”,静态程序分析是指使用自动化工具软件对程序源代码进行检查,以分析程序行为的技术,应用于程序的正确性检查、安全缺陷检测、程序优化等。它的特点就是不执行程序,相反,通过在真实或模拟环境中执行程序进行分析的方法称为“动态程序分析(Dynamic program analysis)”。
那在什么情况下需要进行静态程序分析呢?静态程序分析往往作为一个多人参与的项目中代码审查过程的一个阶段,因编写完一部分代码之后就可以进行静态分析,分析过程不需要执行整个程序,这有助于在项目早期发现以下问题:变量声明了但未使用、变量类型不匹配、变量在使用前未定义、不可达代码、死循环、数组越界、内存泄漏等。
代码静态分析工具——splint的学习与使用
C语言标准——C89、C99、C11、C17、C2x …
对以上的gets程序进行分析
#include <stdio.h>
#include <string.h>
void print_content(const char *p, const char *info) {
printf("%s:", info);
for (int i = 0; i < 10; i++) {
printf("%c", p[i]);
}
printf("\n");
}
int main() {
char before[10];
char buffer[10];
char after[10];
memset(before, 'a', 30);
print_content(before, "before");
print_content(buffer, "buffer");
print_content(after, "after");
gets(buffer);
print_content(before, "before");
print_content(buffer, "buffer");
print_content(after, "after");
return 0;
}
splint gets.c
Splint 3.1.2 --- 20 Feb 2018
gets.c:5:11: Parse Error. (For help on parse errors, see splint -help
parseerrors.)
*** Cannot continue.
第一次运行直接解析错误,这个的原因在于在for循环语句中定义变量
在C语言中,局部变量应该在函数的可执行语句之前定义,但在C++中变量可在任何语句位置定义,只要允许程序语句的地方,都允许定义变量。
在C99标准中C同C++一样允许在for循环语句中定义变量。并且这个变量作用域被限定在for循环中,在for循环外就成为了未定义变量(C++也是)。
※GCC下编译时需要加上std选项,例如 gcc example.c -std=c99
for语句中声明变量
c源代码检查工具splint使用问题及方案
splint不支持C99标准,将变量定义放在for语句之前重新分析
// Splint输出
Splint 3.1.2 --- 20 Feb 2018
gets.c: (in function main)
gets.c:15:18: Function memset expects arg 2 to be int gets char: 'a'
A character constant is used as an int. Use +charintliteral to allow
character constants to be used as ints. (This is safe since the actual type
of a char constant is int.)
gets.c:17:17: Passed storage buffer not completely defined (*buffer is
undefined): print_content (buffer, ...)
Storage derivable from a parameter, return value or global is not defined.
Use /*@out@*/ to denote passed or returned storage which need not be defined.
(Use -compdef to inhibit warning)
gets.c:18:17: Passed storage after not completely defined (*after is
undefined): print_content (after, ...)
gets.c:19:3: Use of gets leads to a buffer overflow vulnerability. Use fgets
instead: gets
Use of function that may lead to buffer overflow. (Use -bufferoverflowhigh to
inhibit warning)
gets.c:19:3: Return value (type char *) ignored: gets(buffer)
Result returned by function call is not used. If this is intended, can cast
result to (void) to eliminate message. (Use -retvalother to inhibit warning)
gets.c:3:6: Function exported but not used outside gets: print_content
A declaration is exported, but not used outside this module. Declaration can
use static qualifier. (Use -exportlocal to inhibit warning)
gets.c:10:1: Definition of print_content
Finished checking --- 6 code warnings
Splint Manual
第三章 分析C语言的声明
在结构体中放置数组,而后可以将数组当作第一等级的类型,用赋值语句复制整个数组,以传值调用的方式把它传递到函数,或者把它作为函数的返回类型。
在典型情况下,并不会频繁地对整个数组进行赋值传值。如果需要这样做,可以通过把它放入结构体中来实现。
示例程序:
// 将data数组置于Test结构体,以便整体赋值
#include <stdio.h>
#include <string.h>
struct Test {
int data[10];
};
int main() {
int a[10];
int b[10];
int c[10];
// 展示不同的赋值方式
for (int i = 0; i < 10; i++) {
a[i] = i;
}
for (int i = 0; i < 10; i++) {
b[i] = a[i];
}
memcpy(c, a, 10 * sizeof(int));
for (int i = 0; i < 10; i++) {
printf("a:%d b:%d c:%d\n", a[i], b[i], c[i]);
}
struct Test t1, t2, t3;
for (int i = 0; i < 10; i++) {
t1.data[i] = i;
}
t2 = t1;
memcpy(&t3, &t1, sizeof(struct Test));
for (int i = 0; i < 10; i++) {
printf("t1:%d t2:%d t3:%d\n", t1.data[i], t2.data[i], t3.data[i]);
}
}
/*
输出:
a:0 b:0 c:0
a:1 b:1 c:1
a:2 b:2 c:2
a:3 b:3 c:3
a:4 b:4 c:4
a:5 b:5 c:5
a:6 b:6 c:6
a:7 b:7 c:7
a:8 b:8 c:8
a:9 b:9 c:9
t1:0 t2:0 t3:0
t1:1 t2:1 t3:1
t1:2 t2:2 t3:2
t1:3 t2:3 t3:3
t1:4 t2:4 t3:4
t1:5 t2:5 t3:5
t1:6 t2:6 t3:6
t1:7 t2:7 t3:7
t1:8 t2:8 t3:8
t1:9 t2:9 t3:9
*/
理解C语言声明的优先级规则
A:声明从它的名字开始读取,然后按照优先级顺序依次读取。
B:优先级从高到低依次如下。
B1:声明中被括号括起来的那部分
B2:后缀操作符:括号()表示这是一个函数而方括号[]表示这是一个数组。
B3:前缀操作符:星号*表示指向…的指针
C:如果const和(或)volatile关键字的后面紧跟类型说明符(如int long等),那么它作用于类型说明符。在其他情况下,const和(或)volatile关键字作用于它左边紧邻的指针星号。
记住const表示只读,并不能因为它的意思是常量就认为它表示的就是常量。
const实验
// 使用特殊的方法覆盖掉const变量的值
#include <stdio.h>
int main() {
int a;
const int b = 10;
unsigned long long *p = (unsigned long long *)&a; // 将u64的指针变量指向变量a
printf("addr \na:%p\nb:%p\n", &a, &b); // 打印变量a b的地址关系
*p = 0x1111222233334444; // 对指向的地址空间赋值
printf("no const var value:%x\n", a); // 输出非const变量的值
printf("const var value:%x\n", b); // 输出赋值后const变量的值
}
// 输出:
addr
a:0x7fff69a8fff8
b:0x7fff69a8fffc
no const var value:33334444
const var value:11112222
// gdb打印地址与相应值
gdb:
(gdb) b const.c:8
Breakpoint 1 at 0x11c0: file const.c, line 8.
(gdb) r
Starting program: /root/tianchi/codebase/expr/expert/const
addr
a:0x7fffffffdee8
b:0x7fffffffdeec
Breakpoint 1, main () at const.c:8
8 printf("no const var value:%x\n", a);
(gdb) x/8ab 0x7fffffffdee8
0x7fffffffdee8: 0x44 0x44 0x33 0x33 0x22 0x22 0x11 0x11
typedef关键字并不创建一个变量,而是宣称“这个名字是指定类型的同义词”。
typedef与#define的区别:typedef是一种彻底的封装类型 ,而#define只是单纯的宏文本替换。
首先,可以用其他类型说明符对宏类型名进行扩展,但对typedef所定义的类型名却不能这样做。
其次,在连续几个变量的声明中,用typedef定义的类型能够保证声明中所有的变量均为同一种类型,而用#define定义的类型则无法保证。
示例程序:
/*
使用sizeof返回的大小间接反映变量类型
*/
#include <stdio.h>
typedef char *char_ptr;
#define c_ptr char *
int main() {
char *t1, t2;
c_ptr p1, p2;
char_ptr q1, q2;
printf("t1:%ld t2:%ld\np1:%ld p2:%ld\nq1:%ld q2:%ld\n", sizeof(t1), sizeof(t2), sizeof(p1), sizeof(p2), sizeof(q1), sizeof(q2));
}
/*
输出:
t1:8 t2:1
p1:8 p2:1
q1:8 q2:8
*/
不要为了方便起见而对结构体使用typedef。这样做的唯一好处是你不必书写struct关键字,但这个关键字可以向你提示一些信息,不应该把它省掉。
第四章 令人震惊的事实:数组和指针并不相同
数组的下标应该从0开始还是从1开始?我提议的妥协方案是0.5,可惜他们未予认真考虑便一口回绝。
定义与声明
| 定义 | 只能出现在一个地方 | 确定对象的类型并分配内存,用以创建新的对象。例如:int array[10]; |
|---|---|---|
| 声明 | 可以多次出现 | 描述对象的类型,用于指代其他地方定义的对象(例如在其他文件里)。例如:extern int array[] |
指针与数组实验
先简单看一下以下c代码
// 对数组变量与指针变量指向的空间赋值
#include <stdio.h>
#include <stdlib.h>
int main() {
char array[10];
array[0] = 0x56;
array[1] = 0x78;
array[9] = 0x12;
char *p = (char *)malloc(10);
p[0] = 0x34;
p[1] = 0x12;
printf("%p\n%p\n%p\n%p\n", array, &array, p, &p);
}
生成目标文件并进行反汇编
gcc point.c -o point -g # 加上调试选项
objdump -S point > point.s -g
gcc point.c -o point -fno-stack-protector -g #关掉栈保护机制
截取主要汇编代码
0000000000001189 <main>:
#include <stdio.h>
#include <stdlib.h>
int main() {
1189: f3 0f 1e fa endbr64
118d: 55 push %rbp
118e: 48 89 e5 mov %rsp,%rbp
1191: 48 83 ec 20 sub $0x20,%rsp
1195: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
119c: 00 00
119e: 48 89 45 f8 mov %rax,-0x8(%rbp)
11a2: 31 c0 xor %eax,%eax
char array[10];
array[0] = 0x56;
11a4: c6 45 ee 56 movb $0x56,-0x12(%rbp)
array[1] = 0x78;
11a8: c6 45 ef 78 movb $0x78,-0x11(%rbp)
array[9] = 0x12;
11ac: c6 45 f7 12 movb $0x12,-0x9(%rbp)
char *p = (char *)malloc(10);
11b0: bf 0a 00 00 00 mov $0xa,%edi
11b5: e8 d6 fe ff ff callq 1090 <malloc@plt>
11ba: 48 89 45 e0 mov %rax,-0x20(%rbp)
p[0] = 0x34;
11be: 48 8b 45 e0 mov -0x20(%rbp),%rax
11c2: c6 00 34 movb $0x34,(%rax)
p[1] = 0x12;
11c5: 48 8b 45 e0 mov -0x20(%rbp),%rax
11c9: 48 83 c0 01 add $0x1,%rax
11cd: c6 00 12 movb $0x12,(%rax)
printf("%p\n%p\n%p\n%p\n", array, &array, p, &p);
11d0: 48 8b 4d e0 mov -0x20(%rbp),%rcx
11d4: 48 8d 75 e0 lea -0x20(%rbp),%rsi
11d8: 48 8d 55 ee lea -0x12(%rbp),%rdx
11dc: 48 8d 45 ee lea -0x12(%rbp),%rax
11e0: 49 89 f0 mov %rsi,%r8
11e3: 48 89 c6 mov %rax,%rsi
11e6: 48 8d 3d 17 0e 00 00 lea 0xe17(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11ed: b8 00 00 00 00 mov $0x0,%eax
11f2: e8 89 fe ff ff callq 1080 <printf@plt>
11f7: b8 00 00 00 00 mov $0x0,%eax
11fc: 48 8b 7d f8 mov -0x8(%rbp),%rdi
1200: 64 48 33 3c 25 28 00 xor %fs:0x28,%rdi
1207: 00 00
1209: 74 05 je 1210 <main+0x87>
120b: e8 60 fe ff ff callq 1070 <__stack_chk_fail@plt>
1210: c9 leaveq
1211: c3 retq
1212: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
1219: 00 00 00
121c: 0f 1f 40 00 nopl 0x0(%rax)
fs:0x28与linux的堆栈保护机制有关,为简化问题,将该机制关掉。
面试官不讲武德,居然让我讲讲蠕虫和金丝雀!
Why does this memory address %fs:0x28 ( fs[0x28] ) have a random value?
再次反汇编,并加上一些注释
# 主要关注数组变量与指针变量赋值方式的不同
0000000000001169 <main>:
#include <stdio.h>
#include <stdlib.h>
int main() {
1169: f3 0f 1e fa endbr64
116d: 55 push %rbp
116e: 48 89 e5 mov %rsp,%rbp
1171: 48 83 ec 20 sub $0x20,%rsp # 申请32字节堆栈空间
# rbp-1到rbp-10为array空间,array为rbp-10地址别名,array[9]即array+9 * sizeof(char)
# 数组赋值一步到位
char array[10];
array[0] = 0x56;
1175: c6 45 f6 56 movb $0x56,-0xa(%rbp)
array[1] = 0x78;
1179: c6 45 f7 78 movb $0x78,-0x9(%rbp)
array[9] = 0x12;
117d: c6 45 ff 12 movb $0x12,-0x1(%rbp)
char *p = (char *)malloc(10); # 指针变量也是局部变量,占8个字节 rbp-17到rbp-24
1181: bf 0a 00 00 00 mov $0xa,%edi # 申请10个字节空间
1186: e8 e5 fe ff ff callq 1070 <malloc@plt>
118b: 48 89 45 e8 mov %rax,-0x18(%rbp)
# 指针赋值需要两步/三步
p[0] = 0x34;
118f: 48 8b 45 e8 mov -0x18(%rbp),%rax # 取得指针变量中存储的地址
1193: c6 00 34 movb $0x34,(%rax) # 将值写入该地址
p[1] = 0x12;
1196: 48 8b 45 e8 mov -0x18(%rbp),%rax # 取得指针变量中存储的地址
119a: 48 83 c0 01 add $0x1,%rax # 设置偏移量
119e: c6 00 12 movb $0x12,(%rax) # 将值写入该地址
# lea: Load Effective Address,即装入有效地址的意思,它的操作数就是地址
printf("%p\n%p\n%p\n%p\n", array, &array, p, &p);
11a1: 48 8b 4d e8 mov -0x18(%rbp),%rcx # p
11a5: 48 8d 75 e8 lea -0x18(%rbp),%rsi # &p
11a9: 48 8d 55 f6 lea -0xa(%rbp),%rdx # &array
11ad: 48 8d 45 f6 lea -0xa(%rbp),%rax # array
11b1: 49 89 f0 mov %rsi,%r8
11b4: 48 89 c6 mov %rax,%rsi
11b7: 48 8d 3d 46 0e 00 00 lea 0xe46(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11be: b8 00 00 00 00 mov $0x0,%eax
11c3: e8 98 fe ff ff callq 1060 <printf@plt>
11c8: b8 00 00 00 00 mov $0x0,%eax
11cd: c9 leaveq
11ce: c3 retq
11cf: 90 nop
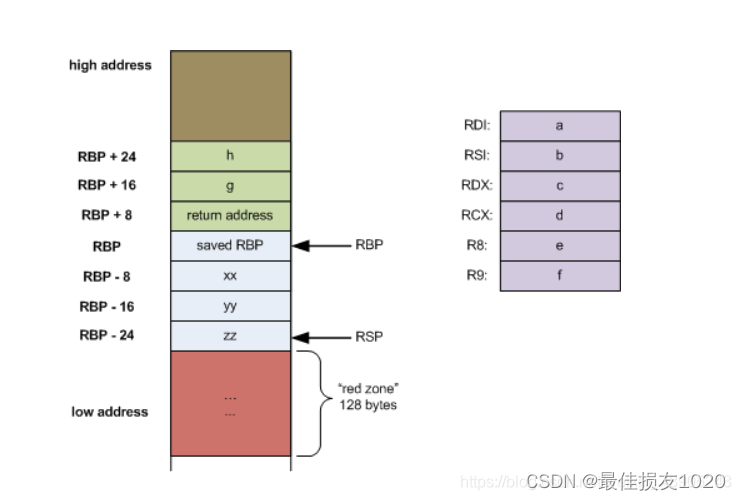
C++内存模型以及寄存器指针rsp和rbp
看完汇编代码,可以很容易猜到:p与&p结果不一样,array与&array结果一致。
0x7ffd85499f96
0x7ffd85499f96
0x55e303c302a0
0x7ffd85499f88
使用gdb显示相关数据
# examine命令介绍
可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:
x/<n/f/u> <addr>
n:是正整数,表示需要显示的内存单元的个数,即从当前地址向后显示n个内存单元的内容,
一个内存单元的大小由第三个参数u定义。
f:表示addr指向的内存内容的输出格式,s对应输出字符串,此处需特别注意输出整型数据的格式:
x 按十六进制格式显示变量.
d 按十进制格式显示变量。
u 按十进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
u:就是指以多少个字节作为一个内存单元-unit,默认为4。u还可以用被一些字符表示:
如b=1 byte, h=2 bytes,w=4 bytes,g=8 bytes.
<addr>:表示内存地址。
Reading symbols from ./point...
(gdb) b point.c:11
Breakpoint 1 at 0x11a1: file point.c, line 11.
(gdb) r
Starting program: /root/tianchi/codebase/expr/point/point
Breakpoint 1, main () at point.c:11
11 printf("%p\n%p\n%p\n%p\n", array, &array, p, &p);
(gdb) p &array
$1 = (char (*)[10]) 0x7fffffffdef6
(gdb) p &p
$2 = (char **) 0x7fffffffdee8
(gdb) p p
$3 = 0x5555555592a0 "4\022"
(gdb) x/10ab 0x5555555592a0 # 查看指针变量指向区域内容
0x5555555592a0: 0x34 0x12 0x0 0x0 0x0 0x0 0x0 0x0
0x5555555592a8: 0x0 0x0
(gdb) x/32tb 0x7fffffffdee8 # 打印该地址之上32字节的内容,二进制
0x7fffffffdee8: 10100000 10010010 01010101 01010101 01010101 01010101 00000000 00000000
0x7fffffffdef0: 11110000 11011111 11111111 11111111 11111111 01111111 01010110 01111000
0x7fffffffdef8: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00010010
0x7fffffffdf00: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
(gdb) x/32ab 0x7fffffffdee8 # 打印该地址之上32字节的内容,十六进制,有些前面有fff是符号位补全的原因(符号位为1),小端方式,低位在低地址
0x7fffffffdee8: 0xffffffffffffffa0 0xffffffffffffff92 0x55 0x55 0x55 0x55 0x0 0x0
0x7fffffffdef0: 0xfffffffffffffff0 0xffffffffffffffdf 0xffffffffffffffff 0xffffffffffffffff 0xffffffffffffffff 0x7f 0x56 0x78
0x7fffffffdef8: 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x12
0x7fffffffdf00: 0x0 0x0 0x0 0x0 0x0 0x0 0x0 0x0
(gdb) x/1tg 0x7fffffffdee8 # 打印指针变量内容 二进制
0x7fffffffdee8: 0000000000000000010101010101010101010101010101011001001010100000
(gdb) x/1ag 0x7fffffffdee8 # 打印指针变量内容 十六进制
0x7fffffffdee8: 0x5555555592a0
(gdb)
注意区分“地址y”和“地址y的内容”之间的区别
| 指针 | 数组 |
|---|---|
| 保存数据的地址 | 保存数据 |
| 间接访问数据,首先取得指针的内容,把它作为地址,然后从这个地址提取数据。 如果指针有一个下标[i],就把指针的内容加上i为地址,从中提取数据 | 直接访问数据,a[i]只是简单地以a+i为地址取得数据 |
| 通常用于动态结果 | 通常用于存储固定数目且数据类型相同的元素 |
| 相关的函数为malloc,free | 隐式分配和删除 |
| 通常指向匿名数据 | 自身即为变量名 |
第五章 对链接的思考
如果函数库的一份副本是可执行文件的物理组成部分,那么我们称之为静态链接;如果可执行文件只是包含了文件名,让载入器在运行时能够寻找程序所需要的函数库,那么我们称之为动态链接。收集模块准备执行的三个阶段的规范名称是链接编辑(link editing)、载入(loading)和运行时链接(runtime linking)。 静态链接的模块被链接编辑并载入以便运行。动态链接的模块被链接编辑后载入,并在运行时进行链接以便运行。程序执行时,在main函数被调用前,运行时载入器把共享的数据对象载入到进程的地址空间。外部函数被真正调用之前,运行时载入器并不解析它们。所以即使链接了函数库,如果并没有实际调用,也不会带来额外开销。
动态链接的主要目的就是把程序与它们使用的特定的函数库版本中分离开来。动态链接必须保证四个特定的函数库:libc(c运行时函数库),libsys(其他系统函数),libX(X windowing)和libnsl(网络服务)
简单静态库动态库实验
// 编写两个文件,一个用于生成静态库/动态库,一个用于调用库函数
// func.c
#include <stdio.h>
int func(int a, int b) {
printf("%d %d\n", a, b);
return a + b;
}
// test.c
#include <stdio.h>
int func(int a, int b); // 函数声明
int main() {
int c = func(1, 2);
printf("%d\n", c);
}
gcc func.c -c # 生成obj文件
gcc -shared func.o -o libfunc.so # 生成动态库
ar rcs libfunc.a func.o # 生成静态库
gcc libfunc.a test.c -o static # 生成目标文件失败,函数库顺序问题
/usr/bin/ld: /tmp/ccRkOXTX.o: in function `main':
test.c:(.text+0x17): undefined reference to `func'
collect2: error: ld returned 1 exit status
gcc test.c libfunc.a -o static # 生成目标文件成功
./static
1 2
3
gcc test.c -lfunc -L. -o shared # 未指定运行时动态库路径
/shared
./shared: error while loading shared libraries: libfunc.so: cannot open shared object file: No such file or directory
gcc test.c -lfunc -L. -Wl,-rpath=. -o shared # 指定运行时动态库路径
./shared
1 2
3
静态库动态库大小比较(由于func较为简单,故差别不大)
4 -rw-r--r-- 1 root root 89 Nov 16 05:58 func.c
4 -rw-r--r-- 1 root root 1712 Nov 16 06:12 func.o
4 -rw-r--r-- 1 root root 1854 Nov 16 06:12 libfunc.a
16 -rwxr-xr-x 1 root root 16200 Nov 16 06:12 libfunc.so*
20 -rwxr-xr-x 1 root root 16728 Nov 16 06:17 shared*
20 -rwxr-xr-x 1 root root 16760 Nov 16 06:14 static*
4 -rw-r--r-- 1 root root 120 Nov 16 06:11 test.c
# 使用ldd打印程序或者库文件所依赖的共享库列表
ldd shared
linux-vdso.so.1 (0x00007fff78daa000)
libfunc.so => ./libfunc.so (0x00007f3deb144000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f3deaf3f000)
/lib64/ld-linux-x86-64.so.2 (0x00007f3deb150000)
ldd wrong_shared # 不指定运行时动态库路径
linux-vdso.so.1 (0x00007ffd35ce6000)
libfunc.so => not found
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f9f504a0000)
/lib64/ld-linux-x86-64.so.2 (0x00007f9f506ac000)
ldd static
linux-vdso.so.1 (0x00007fffcf1ea000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fb6a0667000)
/lib64/ld-linux-x86-64.so.2 (0x00007fb6a0873000)
# 使用nm列出符号
nm shared
0000000000004010 B __bss_start
0000000000004010 b completed.8061
w __cxa_finalize@@GLIBC_2.2.5
0000000000004000 D __data_start
0000000000004000 W data_start
00000000000010b0 t deregister_tm_clones
0000000000001120 t __do_global_dtors_aux
0000000000003d98 d __do_global_dtors_aux_fini_array_entry
0000000000004008 D __dso_handle
0000000000003da0 d _DYNAMIC
0000000000004010 D _edata
0000000000004018 B _end
0000000000001228 T _fini
0000000000001160 t frame_dummy
0000000000003d90 d __frame_dummy_init_array_entry
0000000000002154 r __FRAME_END__
U func # U:符号在当前文件中是未定义的,即该符号的定义在别的文件中。
0000000000003fb0 d _GLOBAL_OFFSET_TABLE_
w __gmon_start__
0000000000002008 r __GNU_EH_FRAME_HDR
0000000000001000 t _init
0000000000003d98 d __init_array_end
0000000000003d90 d __init_array_start
0000000000002000 R _IO_stdin_used
w _ITM_deregisterTMCloneTable
w _ITM_registerTMCloneTable
0000000000001220 T __libc_csu_fini
00000000000011b0 T __libc_csu_init
U __libc_start_main@@GLIBC_2.2.5
0000000000001169 T main
U printf@@GLIBC_2.2.5
00000000000010e0 t register_tm_clones
0000000000001080 T _start
0000000000004010 D __TMC_END__
nm static
0000000000004010 B __bss_start
0000000000004010 b completed.8061
w __cxa_finalize@@GLIBC_2.2.5
0000000000004000 D __data_start
0000000000004000 W data_start
0000000000001090 t deregister_tm_clones
0000000000001100 t __do_global_dtors_aux
0000000000003dc0 d __do_global_dtors_aux_fini_array_entry
0000000000004008 D __dso_handle
0000000000003dc8 d _DYNAMIC
0000000000004010 D _edata
0000000000004018 B _end
0000000000001238 T _fini
0000000000001140 t frame_dummy
0000000000003db8 d __frame_dummy_init_array_entry
0000000000002184 r __FRAME_END__
0000000000001184 T func # T:符号位于代码区 text section
0000000000003fb8 d _GLOBAL_OFFSET_TABLE_
w __gmon_start__
0000000000002010 r __GNU_EH_FRAME_HDR
0000000000001000 t _init
0000000000003dc0 d __init_array_end
0000000000003db8 d __init_array_start
0000000000002000 R _IO_stdin_used
w _ITM_deregisterTMCloneTable
w _ITM_registerTMCloneTable
0000000000001230 T __libc_csu_fini
00000000000011c0 T __libc_csu_init
U __libc_start_main@@GLIBC_2.2.5
0000000000001149 T main
U printf@@GLIBC_2.2.5
00000000000010c0 t register_tm_clones
0000000000001060 T _start
0000000000004010 D __TMC_END__
5.3 函数库链接的5个特殊秘密
- 动态库文件的扩展名是.so,而静态库文件的扩展名是.a
- 通过-lthread选项,告诉编译链接到libthread.so
- 编译器期望在确定目录下找到库
动态库的搜索路径搜索的先后顺序是:- 编译目标代码时指定的动态库搜索路径;
- 环境变量 LD_LIBRARY_PATH 指定的动态库搜索路径;
- 配置文件 /etc/ld.so.conf 中指定的动态库搜索路径;
- 默认的动态库搜索路径 /lib ;
- 默认的动态库搜索路径 /usr/lib
- 观察头文件,确认所使用的函数库
#include文件名 库路径名 所用的编译器选项
<math.h> /usr/lib/libm.so -lm
<math.h> /usr/lib/libm.a -dn -lm
<stdio.h> /usr/lib/libc.so 自动链接
<thread.h> /usr/lib/libthread.so -lthread
<curses.h> /usr/lib/libcurses.so -lcurses
<sys/socket.h> /usr/lib/libsocket.so -lsocket
<stdio.h> <string.h> <time.h> ---> libc.so
许多常见的头文件的函数定义均为运行时库提供
- 与提取动态库中的符号相比,静态库中的符号提取的方法限制更严
简而言之,在编译器命令行中各个静态链接库出现的顺序是非常重要的。为了能从静态链接库中提取所需的符号,首先需要让文件包含未解析的引用。始终应该将-l函数库选项/静态库/动态库 放在编译命令行的最右边。
参考:
gcc 指定运行时动态库路径
nm命令详解](https://www.cnblogs.com/zuofaqi/p/12026482.html)
gcc 指定动态连接路编译时路径和运行时路径
5.4 警惕interpositioning
interpositioning就是编写与库函数同名的函数来取代该库函数的行为。当编译器注意到库函数被另外一个定义覆盖时,它通常不会给出错误信息。这也是遵循C语言的设计哲学,即程序员所做的都是对的。
准则:不要让程序中任何符号成为全局的,除非有意把它们作为程序的接口之一
第六章 运动的诗章:运行时数据结构
编程语言理论的经典对立之一就是代码和数据的区别,有些语言(lisp)把两者视为一体。其他语言(如C语言)通常维持两者的区别。Internet蠕虫之所以难以理解,是因为它的攻击方法的原理是把数据转换为代码。代码和数据的区别也可以认为是编译时和运行时的分界线。编译器的绝大部分工作与翻译代码有关;必要的数据存储管理的绝大部分在运行时进行。
a.out: assembler output
文件系统超级块(super block):
#define FS_MAGIC 0x011954
在SVr4中,可执行文件用文件的第一个字节来标注,文件以十六进制7F打头,紧跟在后面的第二至第四个字节为ELF。
ELF:Extensible Linker Format(可扩展链接器格式)/Executable and Linking Format(可执行文件和链接格式)
#include <stdio.h>
#include <stdlib.h>
char pear[40];
static double peach;
int mango = 13;
static long melo = 2001;
int main() {
int i = 3, j, *ip;
ip = malloc(sizeof(i));
pear[5] = i;
peach = 2.0 * mango;
}
gcc seg.c -g
objdump -S a.out >seg.s
file a.out
a.out: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=efe0b3aa5ce851a149c89be3e48b6a0fed34a56e, for GNU/Linux 3.2.0, with debug_info, not stripped
size a.out
text data bss dec hex filename
1587 616 72 2275 8e3 a.out
0000000000001149 <main>:
#include <stdlib.h>
char pear[40];
static double peach;
int mango = 13;
static long melo = 2001;
int main() {
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 83 ec 10 sub $0x10,%rsp # 16字节空间
int i = 3, j, *ip;
1155: c7 45 f4 03 00 00 00 movl $0x3,-0xc(%rbp) # 9-12为i
ip = malloc(sizeof(i));
115c: bf 04 00 00 00 mov $0x4,%edi # 申请4字节空间
1161: e8 ea fe ff ff callq 1050 <malloc@plt>
1166: 48 89 45 f8 mov %rax,-0x8(%rbp) # 1-8为ip指针变量
pear[5] = i;
116a: 8b 45 f4 mov -0xc(%rbp),%eax
116d: 88 05 d2 2e 00 00 mov %al,0x2ed2(%rip) # 4045 <pear+0x5>
peach = 2.0 * mango;
1173: 8b 05 97 2e 00 00 mov 0x2e97(%rip),%eax # 4010 <mango>
1179: f2 0f 2a c0 cvtsi2sd %eax,%xmm0 # 取出最低位的64位整型,并将其转换为一个浮点值
117d: f2 0f 58 c0 addsd %xmm0,%xmm0 # 相加一次
1181: f2 0f 11 05 9f 2e 00 movsd %xmm0,0x2e9f(%rip) # 4028 <peach>
1188: 00
1189: b8 00 00 00 00 mov $0x0,%eax
118e: c9 leaveq
118f: c3 retq

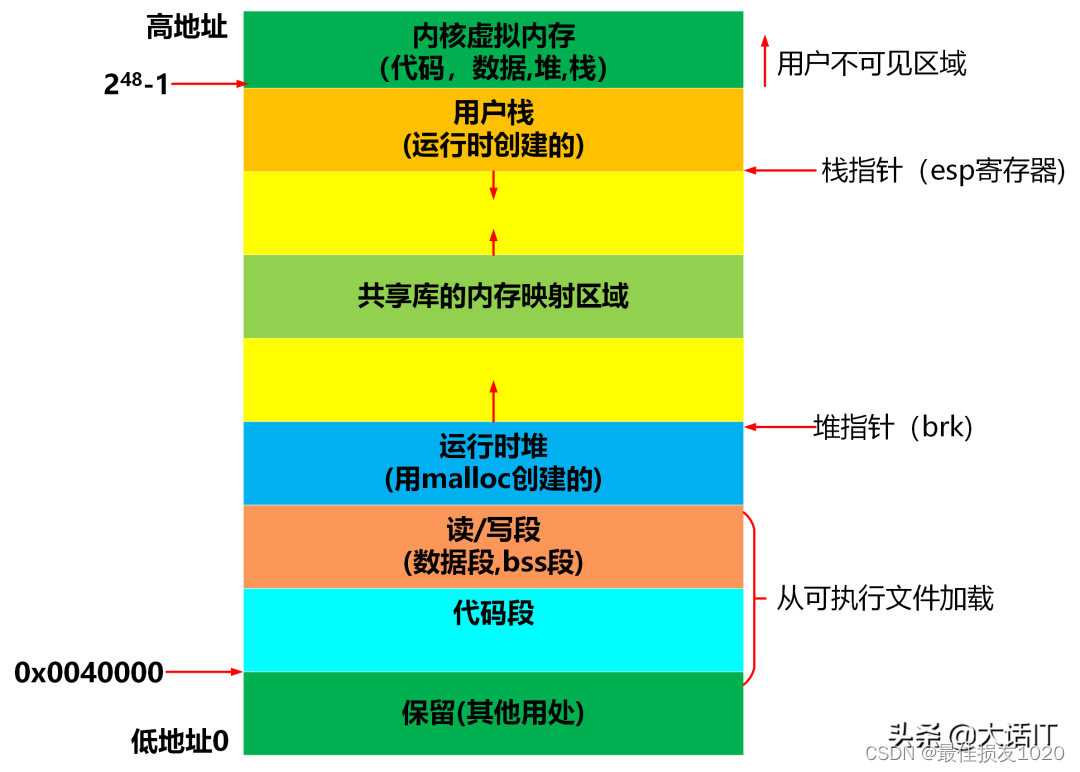
第0页未映射,故访问空指针就会引发段错误。
用grep来调试操作系统是一个非同寻常的概念。有时候甚至连源代码工具都可以帮忙解决运行时问题!
第七章 对内存的思考
如果它存在,而且你能看见它——它是真实的(real)
如果它不存在,但你能看见它——它是虚拟的(virtual)
如果它存在,但你看不见它——它是透明的(transparent)
如果它不存在,而且你也看不见它——那肯定是你把它擦掉了
进程只能操作位于物理内存中的页面。当进程引用一个不在物理内存中的页面上时,内存管理单元(MMU)就会产生一个页错误。内核对此事件作出响应,并判断该引用是否有效。如果无效,那么内核向进程发出一个segmentation violation(段违规)的信号。如果有效,内核从磁盘取回该页,换入到内存中。一旦页面进入内存,进程便被解锁,可以重新运行——进程本身不知道它曾经因为页面换入事件等待了一会。
堆经常会出现两种类型的问题:
1 释放或改写仍在使用的内存(内存损坏)
2 未释放不再使用的内存(内存泄漏)
总线错误与段错误
bus error(core dump)
segmentation fault(core dump)
core dump来源于很早的过去,那时所有的内存都是由铁氧化物圆环(也就是core,磁心)制造的。半导体作为内存的主要制造材料的时间已经超过15年,但core这个词仍然被用作“内存”的同义词。
总线错误:
事实上,总线错误几乎都是未对齐的读或写引起的。它之所以称之为总线错误,是因为出现未对齐的内存访问请求时,被堵塞的组件就是地址总线。对齐(alignment)的意思就是数据项只能存储在地址是数据项大小的整数倍的内存位置上。
示例代码:
// 试图访问非对齐的地址引发总线错误
#include <stdio.h>
int main() {
union bus {
char a[10];
int i;
} u;
int *p = (int *)&(u.a[1]);
*p = 0x12345678;
for (int i = 0; i < 10; i++) {
printf("%llx %x\n", &(u.a[i]), u.a[i] & 0xff);
}
unsigned long long addr = (unsigned long long)&(u.a[1]);
printf("addr:%lld remainder:%lld\n", addr, addr - addr / 4 * 4);
}
/*
./bus
7fff95028d9c 6a
7fff95028d9d 78
7fff95028d9e 56
7fff95028d9f 34
7fff95028da0 12
7fff95028da1 8e
7fff95028da2 2
7fff95028da3 95
7fff95028da4 ff
7fff95028da5 7f
addr:140735693360541 remainder:1
*/
在x86的机器上运行,并不会发生书中所说的总线错误问题,参考《c专家编程》笔记–bus error(总线错误)加入汇编代码打开对齐检查功能。
#include <stdio.h>
int main() {
__asm__("pushf\norl $0x40000,(%rsp)\npopf");
union bus {
char a[10];
int i;
} u;
int *p = (int *)&(u.a[1]);
*p = 0x12345678;
for (int i = 0; i < 10; i++) {
printf("%llx %x\n", &(u.a[i]), u.a[i] & 0xff);
}
unsigned long long addr = (unsigned long long)&(u.a[1]);
printf("addr:%lld remainder:%lld\n", addr, addr - addr / 4 * 4);
}
/*
./bus
fish: “./bus” terminated by signal SIGBUS (Misaligned address error)
*/
x86都支持地址非对齐访问,arm部分支持非对齐访问,有些则可能会触发HardFault exception,即死机;为代码移植性考虑,建议内存访问数据时对齐访问(不用#pragma pack)
推荐博客:
内存访问为什么需要地址对齐
段错误
段错误由内存管理单元(负责支持虚拟内存的硬件)的异常所致,而该异常通常是解除引用一个未初始化或非法值的指针引起的 。如果指针引用一个并不位于你的地址空间中的地址,操作系统便会对此进行干涉。
// 段错误 访问非法地址
#include <stdio.h>
int main() {
int *p = (int *)0x12345678;
*p = 1;
}
// 段错误 访问非法地址(空指针)
#include <stdio.h>
int main() {
int *p = (int *)0x0;
*p = 1;
}
// 不报错才倒霉 释放后仍在使用
int main() {
int *p = malloc(16);
printf("addr:0x%p\n", p);
free(p);
printf("addr:0x%p\n", p);
*p = 0;
}
addr:0x0x55f41bfc22a0
addr:0x0x55f41bfc22a0
// 双重释放
#include <stdio.h>
#include <stdlib.h>
int main() {
int *p = malloc(16);
printf("addr:0x%p\n", p);
free(p);
printf("addr:0x%p\n", p);
free(p);
*p = 0;
}
addr:0x0x563b2b7852a0
addr:0x0x563b2b7852a0
free(): double free detected in tcache 2
fish: “./segment” terminated by signal SIGABRT (Abort)
悬挂指针实验
// 悬挂指针
#include <stdio.h>
int *func() {
int array[10] = {1, 2, 3, 4};
return array;
}
int main() {
int *p = func();
printf("val:%d %d %d %d\n", p[0], p[1], p[2], p[3]);
}
// 编译输出
segment.c: In function ‘func’:
segment.c:5:10: warning: function returns address of local variable [-Wreturn-local-addr]
5 | return array;
// 运行结果
fish: “./segment” terminated by signal SIGSEGV (Address boundary error)
// 增加打印
#include <stdio.h>
int *func() {
int array[10] = {1, 2, 3, 4};
printf("addr:0x%p", array);
return array;
}
int main() {
int *p = func();
printf("addr:0x%p", p);
printf("val:%d %d %d %d\n", p[0], p[1], p[2], p[3]);
}
// 运行输出
./segment
fish: “./segment” terminated by signal SIGSEGV (Address boundary error)
// 未打印任何数据,并不是没有执行printf函数就段错误了,只是因为printf是行缓冲函数,先写到缓冲区,满足条件后,才将缓冲区刷到对应文件中。
// 修改printf内容
#include <stdio.h>
int *func() {
int array[10] = {1, 2, 3, 4};
printf("addr:0x%p\n", array);
return array;
}
int main() {
int *p = func();
printf("addr:0x%p\n", p);
printf("val:%d %d %d %d\n", p[0], p[1], p[2], p[3]);
}
// 运行结果
./segment
addr:0x0x7ffeff3f5a00
addr:0x(nil)
fish: “./segment” terminated by signal SIGSEGV (Address boundary error)
// 进行反汇编,重点关注func返回值
gcc segment.c -o segment -g -fno-stack-protector
objdump -S segment > segment.s
0000000000001149 <func>:
#include <stdio.h>
int *func() {
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 83 ec 30 sub $0x30,%rsp
int array[10] = {1, 2, 3, 4};
1155: 48 c7 45 d0 00 00 00 movq $0x0,-0x30(%rbp) # movq 传送四字
115c: 00
115d: 48 c7 45 d8 00 00 00 movq $0x0,-0x28(%rbp)
1164: 00
1165: 48 c7 45 e0 00 00 00 movq $0x0,-0x20(%rbp)
116c: 00
116d: 48 c7 45 e8 00 00 00 movq $0x0,-0x18(%rbp)
1174: 00
1175: 48 c7 45 f0 00 00 00 movq $0x0,-0x10(%rbp)
117c: 00
117d: c7 45 d0 01 00 00 00 movl $0x1,-0x30(%rbp) # movl 传送双字
1184: c7 45 d4 02 00 00 00 movl $0x2,-0x2c(%rbp)
118b: c7 45 d8 03 00 00 00 movl $0x3,-0x28(%rbp)
1192: c7 45 dc 04 00 00 00 movl $0x4,-0x24(%rbp)
printf("addr:0x%p\n", array);
1199: 48 8d 45 d0 lea -0x30(%rbp),%rax # 传送地址
119d: 48 89 c6 mov %rax,%rsi
11a0: 48 8d 3d 5d 0e 00 00 lea 0xe5d(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11a7: b8 00 00 00 00 mov $0x0,%eax
11ac: e8 9f fe ff ff callq 1050 <printf@plt>
return array;
11b1: b8 00 00 00 00 mov $0x0,%eax # 返回值为0
}
11b6: c9 leaveq
11b7: c3 retq
00000000000011b8 <main>:
int main() {
11b8: f3 0f 1e fa endbr64
11bc: 55 push %rbp
11bd: 48 89 e5 mov %rsp,%rbp
11c0: 48 83 ec 10 sub $0x10,%rsp
int *p = func();
11c4: b8 00 00 00 00 mov $0x0,%eax
11c9: e8 7b ff ff ff callq 1149 <func>
11ce: 48 89 45 f8 mov %rax,-0x8(%rbp) # 返回值写入栈中(指针变量)
printf("addr:0x%p\n", p);
11d2: 48 8b 45 f8 mov -0x8(%rbp),%rax
11d6: 48 89 c6 mov %rax,%rsi
11d9: 48 8d 3d 24 0e 00 00 lea 0xe24(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11e0: b8 00 00 00 00 mov $0x0,%eax
11e5: e8 66 fe ff ff callq 1050 <printf@plt>
printf("val:%d %d %d %d\n", p[0], p[1], p[2], p[3]);
11ea: 48 8b 45 f8 mov -0x8(%rbp),%rax
11ee: 48 83 c0 0c add $0xc,%rax
11f2: 8b 30 mov (%rax),%esi
11f4: 48 8b 45 f8 mov -0x8(%rbp),%rax
11f8: 48 83 c0 08 add $0x8,%rax
11fc: 8b 08 mov (%rax),%ecx
11fe: 48 8b 45 f8 mov -0x8(%rbp),%rax
1202: 48 83 c0 04 add $0x4,%rax
1206: 8b 10 mov (%rax),%edx
1208: 48 8b 45 f8 mov -0x8(%rbp),%rax
120c: 8b 00 mov (%rax),%eax
120e: 41 89 f0 mov %esi,%r8d
1211: 89 c6 mov %eax,%esi
1213: 48 8d 3d f5 0d 00 00 lea 0xdf5(%rip),%rdi # 200f <_IO_stdin_used+0xf>
121a: b8 00 00 00 00 mov $0x0,%eax
121f: e8 2c fe ff ff callq 1050 <printf@plt>
1224: b8 00 00 00 00 mov $0x0,%eax
1229: c9 leaveq
122a: c3 retq
122b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
// 不知道为啥func直接返回0了,修改实现,返回指针
#include <stdio.h>
int *func() {
int a = 1;
int *p = &a;
printf("addr:0x%p\n", p);
return p;
}
int main() {
int *p = func();
printf("addr:0x%p\n", p);
*p = 0x12345678;
printf("val:%x\n", *p);
}
// 运行结果
./segment
addr:0x0x7ffcf5a7e3c4
addr:0x0x7ffcf5a7e3c4
val:12345678
// 进行反汇编,重点关注func返回值
0000000000001149 <func>:
#include <stdio.h>
int *func() {
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 83 ec 10 sub $0x10,%rsp
int a = 1;
1155: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp)
int *p = &a;
115c: 48 8d 45 f4 lea -0xc(%rbp),%rax
1160: 48 89 45 f8 mov %rax,-0x8(%rbp) # 将变量a地址写入p中
printf("addr:0x%p\n", p);
1164: 48 8b 45 f8 mov -0x8(%rbp),%rax
1168: 48 89 c6 mov %rax,%rsi
116b: 48 8d 3d 92 0e 00 00 lea 0xe92(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
1172: b8 00 00 00 00 mov $0x0,%eax
1177: e8 d4 fe ff ff callq 1050 <printf@plt>
return p;
117c: 48 8b 45 f8 mov -0x8(%rbp),%rax # 返回指针地址
}
1180: c9 leaveq
1181: c3 retq
0000000000001182 <main>:
int main() {
1182: f3 0f 1e fa endbr64
1186: 55 push %rbp
1187: 48 89 e5 mov %rsp,%rbp
118a: 48 83 ec 10 sub $0x10,%rsp
int *p = func();
118e: b8 00 00 00 00 mov $0x0,%eax
1193: e8 b1 ff ff ff callq 1149 <func>
1198: 48 89 45 f8 mov %rax,-0x8(%rbp)
printf("addr:0x%p\n", p);
119c: 48 8b 45 f8 mov -0x8(%rbp),%rax
11a0: 48 89 c6 mov %rax,%rsi
11a3: 48 8d 3d 5a 0e 00 00 lea 0xe5a(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11aa: b8 00 00 00 00 mov $0x0,%eax
11af: e8 9c fe ff ff callq 1050 <printf@plt>
*p = 0x12345678;
11b4: 48 8b 45 f8 mov -0x8(%rbp),%rax
11b8: c7 00 78 56 34 12 movl $0x12345678,(%rax)
printf("val:%x\n", *p);
11be: 48 8b 45 f8 mov -0x8(%rbp),%rax
11c2: 8b 00 mov (%rax),%eax
11c4: 89 c6 mov %eax,%esi
11c6: 48 8d 3d 42 0e 00 00 lea 0xe42(%rip),%rdi # 200f <_IO_stdin_used+0xf>
11cd: b8 00 00 00 00 mov $0x0,%eax
11d2: e8 79 fe ff ff callq 1050 <printf@plt>
11d7: b8 00 00 00 00 mov $0x0,%eax
11dc: c9 leaveq
11dd: c3 retq
11de: 66 90 xchg %ax,%ax
基本的观察结果为:返回数组地址,编译器直接返回0,一定报错,返回指针地址,编译器返回原值,不会报错。编译器这样干或许是因为返回局部数组的地址是一定错的,指针有可能指向动态分配的内存,有可能是对的。不过返回执行局部变量的指针危害更大。

Thing King万岁!
第八章 为什么程序员无法分清万圣节和圣诞节
在表达式中,char转换为int,float转换为double。由于函数参数也是一个表达式,在参数传递时也会发生类型转换。
C语言中的类型转换比一般人想象中的要广泛得多。在涉及类型小于int或double的表达式中,都有可能出现类型转换。
#include <stdio.h>
int main() { printf("char const:%d\n", sizeof('a')); }
// char const:4
原类型 提升后类型
char 位段 枚举 unsigned char short unsigned short int
float double
任何数组 相应类型指针
每次在使用系统调用之后,检查一下全局变量errno是一种好的做法,errno隶属于ANSI C标准。当确有错误发生时,库函数perror可以打印错误信息。
debugging hook
#include <stdio.h>
void func() { printf("call function\n"); }
int add(int a, int b) { return a + b; }
int main() { printf("test\n"); }
// gdb执行函数,可以使用“ call ”或“ print ”命令直接调用函数执行。
Breakpoint 1, main () at hook.c:5
5 int main() { printf("test\n"); }
(gdb) call func()
call function
(gdb) p func()
call function
$1 = void
(gdb) call add(1,2)
$2 = 3
(gdb) p add(1,2)
$3 = 3
可调试性编码意味着把系统分成几个部分,先让程序总体结构运行。只有基本的程序能够运行之后,你才为那些复杂的细节完善,性能调整和算法优化进行编码。
int hash_filename(char* s){
return 0;
}
有时候,花点时间把编程问题分解为几个部分往往是解决它的最快方法。
第九章 再论数组
软件信条
什么时候数组和指针是相同的
C语言标准对此做了如下说明:
规则1. 表达式中的数组名(与声明不同)被编译器当作一个指向该数组第一个元素的指针
规则2. 下标总是与指针的偏移量相同
规则3. 在函数参数的声明中,数组名被编译器当作指向该数组第一个元素的指针
另一种表述为:
- “表达式中的数组名”就是指针
- C语言把数组下标作为指针的偏移量
- “作为函数参数的数组名”等于指针
C语言把数组下标改写成指针偏移量的根本原因是指针和偏移量是底层硬件所使用的基本模型。
// 不同的数组赋值方式对比
#include <stdio.h>
int main() {
int a[10], *p; // 局部变量
int i = 0;
for (i = 0; i < 10; i++) {
a[i] = 0;
}
p = a;
for (i = 0; i < 10; i++) {
p[i] = 0;
}
p = a;
for (i = 0; i < 10; i++) {
*(p + i) = 0;
}
for (i = 0; i < 10; i++) {
*p++ = 0;
}
}
进行反汇编:
0000000000001129 <main>:
#include <stdio.h>
int main() {
1129: f3 0f 1e fa endbr64
112d: 55 push %rbp
112e: 48 89 e5 mov %rsp,%rbp
int a[10], *p;
int i = 0;
1131: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp) # 变量i赋值(9-12)
for (i = 0; i < 10; i++) {
1138: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp)
113f: eb 11 jmp 1152 <main+0x29> # 与10作比较
a[i] = 0;
1141: 8b 45 f4 mov -0xc(%rbp),%eax
1144: 48 98 cltq
1146: c7 44 85 c0 00 00 00 movl $0x0,-0x40(%rbp,%rax,4) # 数组地址为25-64,64-4*i即为a[i]
114d: 00
for (i = 0; i < 10; i++) {
114e: 83 45 f4 01 addl $0x1,-0xc(%rbp) # i++
1152: 83 7d f4 09 cmpl $0x9,-0xc(%rbp) # 实际上是与9作比较
1156: 7e e9 jle 1141 <main+0x18> # 小于或等于则执行语句块语句
}
p = a;
1158: 48 8d 45 c0 lea -0x40(%rbp),%rax
115c: 48 89 45 f8 mov %rax,-0x8(%rbp) # 指针变量赋值(1-8)
for (i = 0; i < 10; i++) {
1160: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp)
1167: eb 1e jmp 1187 <main+0x5e>
p[i] = 0;
1169: 8b 45 f4 mov -0xc(%rbp),%eax
116c: 48 98 cltq
116e: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx # 4*i
1175: 00
1176: 48 8b 45 f8 mov -0x8(%rbp),%rax
117a: 48 01 d0 add %rdx,%rax # p+4*i
117d: c7 00 00 00 00 00 movl $0x0,(%rax) # *(p+4*i) = 0
for (i = 0; i < 10; i++) {
1183: 83 45 f4 01 addl $0x1,-0xc(%rbp)
1187: 83 7d f4 09 cmpl $0x9,-0xc(%rbp)
118b: 7e dc jle 1169 <main+0x40>
}
# 下面一模一样
p = a;
118d: 48 8d 45 c0 lea -0x40(%rbp),%rax
1191: 48 89 45 f8 mov %rax,-0x8(%rbp)
for (i = 0; i < 10; i++) {
1195: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp)
119c: eb 1e jmp 11bc <main+0x93>
*(p + i) = 0;
119e: 8b 45 f4 mov -0xc(%rbp),%eax
11a1: 48 98 cltq
11a3: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx
11aa: 00
11ab: 48 8b 45 f8 mov -0x8(%rbp),%rax
11af: 48 01 d0 add %rdx,%rax
11b2: c7 00 00 00 00 00 movl $0x0,(%rax)
for (i = 0; i < 10; i++) {
11b8: 83 45 f4 01 addl $0x1,-0xc(%rbp)
11bc: 83 7d f4 09 cmpl $0x9,-0xc(%rbp)
11c0: 7e dc jle 119e <main+0x75>
}
for (i = 0; i < 10; i++) {
11c2: c7 45 f4 00 00 00 00 movl $0x0,-0xc(%rbp)
11c9: eb 16 jmp 11e1 <main+0xb8>
*p++ = 0;
11cb: 48 8b 45 f8 mov -0x8(%rbp),%rax # p值存于rax
11cf: 48 8d 50 04 lea 0x4(%rax),%rdx
11d3: 48 89 55 f8 mov %rdx,-0x8(%rbp) # p+4
11d7: c7 00 00 00 00 00 movl $0x0,(%rax) # *p = 0
for (i = 0; i < 10; i++) {
11dd: 83 45 f4 01 addl $0x1,-0xc(%rbp)
11e1: 83 7d f4 09 cmpl $0x9,-0xc(%rbp)
11e5: 7e e4 jle 11cb <main+0xa2>
11e7: b8 00 00 00 00 mov $0x0,%eax
}
11ec: 5d pop %rbp
11ed: c3 retq
11ee: 66 90 xchg %ax,%ax
# 关键的赋值代码为:
a[i] = 0;
1141: 8b 45 f4 mov -0xc(%rbp),%eax
1144: 48 98 cltq
1146: c7 44 85 c0 00 00 00 movl $0x0,-0x40(%rbp,%rax,4) # 数组地址为25-64,64-4*i即为a[i]
p[i] = 0;
1169: 8b 45 f4 mov -0xc(%rbp),%eax
116c: 48 98 cltq
116e: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx # 4*i
1175: 00
1176: 48 8b 45 f8 mov -0x8(%rbp),%rax
117a: 48 01 d0 add %rdx,%rax # p+4*i
117d: c7 00 00 00 00 00 movl $0x0,(%rax) # *(p+4*i) = 0
*(p + i) = 0;
119e: 8b 45 f4 mov -0xc(%rbp),%eax
11a1: 48 98 cltq
11a3: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx
11aa: 00
11ab: 48 8b 45 f8 mov -0x8(%rbp),%rax
11af: 48 01 d0 add %rdx,%rax
11b2: c7 00 00 00 00 00 movl $0x0,(%rax)
*p++ = 0;
11cb: 48 8b 45 f8 mov -0x8(%rbp),%rax # p值存于rax
11cf: 48 8d 50 04 lea 0x4(%rax),%rdx
11d3: 48 89 55 f8 mov %rdx,-0x8(%rbp) # p+4
11d7: c7 00 00 00 00 00 movl $0x0,(%rax) # *p = 0
好像4种方法的效果并不是完全一样,①>④>②=③
不过如果变量定义在main函数之外,情况就不一样了
#include <stdio.h>
int a[10], *p; // 全局变量
int main() {
int i = 0;
for (i = 0; i < 10; i++) {
a[i] = 0;
}
p = a;
for (i = 0; i < 10; i++) {
p[i] = 0;
}
p = a;
for (i = 0; i < 10; i++) {
*(p + i) = 0;
}
for (i = 0; i < 10; i++) {
*p++ = 0;
}
}
a[i] = 0;
1141: 8b 45 fc mov -0x4(%rbp),%eax
1144: 48 98 cltq
1146: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx # 4*i
114d: 00
114e: 48 8d 05 0b 2f 00 00 lea 0x2f0b(%rip),%rax # 数组a地址 # 4060 <a>
1155: c7 04 02 00 00 00 00 movl $0x0,(%rdx,%rax,1) # *(a+4*i) = 0
p[i] = 0;
117d: 48 8b 05 bc 2e 00 00 mov 0x2ebc(%rip),%rax # p变量的值 # 4040 <p>
1184: 8b 55 fc mov -0x4(%rbp),%edx
1187: 48 63 d2 movslq %edx,%rdx
118a: 48 c1 e2 02 shl $0x2,%rdx # 4*i
118e: 48 01 d0 add %rdx,%rax # p+4*i
1191: c7 00 00 00 00 00 movl $0x0,(%rax) # *(p+4*i)=0
*(p + i) = 0;
11b8: 48 8b 05 81 2e 00 00 mov 0x2e81(%rip),%rax # 4040 <p>
11bf: 8b 55 fc mov -0x4(%rbp),%edx
11c2: 48 63 d2 movslq %edx,%rdx
11c5: 48 c1 e2 02 shl $0x2,%rdx
11c9: 48 01 d0 add %rdx,%rax
11cc: c7 00 00 00 00 00 movl $0x0,(%rax)
*p++ = 0;
11e5: 48 8b 05 54 2e 00 00 mov 0x2e54(%rip),%rax # 4040 <p>
11ec: 48 8d 50 04 lea 0x4(%rax),%rdx # p+4
11f0: 48 89 15 49 2e 00 00 mov %rdx,0x2e49(%rip) # 4040 <p>
11f7: c7 00 00 00 00 00 movl $0x0,(%rax) # *p=0
此时各个方式的效果就类似了。
聊一聊基础的CPU寄存器~
第十章: 再论指针
我认为本章只需要快速浏览一编即可,指针数组,数组指针之类的东西会让第九章本来比较清晰的概念再次混淆,反正多维数组本就不怎么常用,与其认真研究这章,不如回过头再看几遍第四章与第九章。
第十一章:你懂得C,所以C++不在话下
构造函数与析构函数违反了C语言中“一切工作自己负责”的原则。它们可以使大量的工作在程序运行时被隐式地完成,减轻了程序员的负担。这也违背了C语言的哲学,即语言中的任何部分都不应该通过隐藏的运行时程序来实现。
C语言很容易让你在开枪时伤着自己的脚,C++使这种情况很少发生。但是,一旦发生这种情况,它很可能轰掉你整条腿。
class Base {
public:
virtual void PrintMsg() { std::cout << "Base class msg" << std::endl; }
};
class Derive : public Base {
public:
void PrintMsg() { std::cout << "Derive class msg" << std::endl; }
};
int main() {
Base base_object;
Derive derive_object;
// 使用基类指针实现多态
Base *base_pointer;
base_pointer = &base_object;
base_pointer->PrintMsg();
base_pointer = &derive_object;
base_pointer->PrintMsg();
// 使用基类引用实现多态
Base &ref1 = base_object;
ref1.PrintMsg();
Base &ref2 = derive_object;
ref2.PrintMsg();
// 使用基类对象无法实现多态
Base base_object2 = derive_object;
base_object2.PrintMsg();
}
/*
Base class msg
Derive class msg
Base class msg
Derive class msg
Base class msg
*/
c++ 多态相关的virtual关键词:
从当前这个上下文的角度来说,virtual(虚拟)这个词多少显得有些用词不当。在计算机科学的其他领域中,virtual的意思是用户所看到的东西事实上并不存在,它只是用某种方法支撑的幻觉罢了。这里,它的意思是不让用户看到事实上存在的东西(基类的成员函数)。换用一个更有意义的关键字(虽然长得不切实际):
choose_the_appropriate_method_at_runtime_for_whatever_object_this_is
(在运行时时根据对象的类型选择合适的成员函数)
也可以用一个更简单的词,就是placeholder
new和delete操作符:用于取代malloc和free函数。这两个操作符用起来方便一些(如能够自动完成sizeof的计算工作),并自动调用合适的构造函数和析构函数)。new能够真正地建立一个对象,malloc则只是分配内存。
编程语言的主要目标是提供一个框架,用计算机能够处理的方式表达问题的解决方法。编程语言越是能够体现这个原则,就越成功。C语言向系统程序员提供了许多由硬件直接支持的操作,它并不使用许多的抽象层来挡路。
C++对C语言的改进:
- 在C语言中,初始化一个字符数组的方式很容易产生这样一个错误,即数组很可能没有足够的空间存放结尾的NULL字符。C++对此作了一些改进,像char b[3]="Bob"这样的表达式被认为是一个错误,但它在C语言中却是合法的。
- C++允许一个常量整数来定义数组的大小,但C语言中不允许
示例代码:
字符串结尾
// 字符串初始化数组时自动在末尾填充结束字符
#include <stdio.h>
#include <string.h>
int main() {
char test[] = "1234";
printf("strlen: %ld sizeof:%ld\n", strlen(test), sizeof(test));
for (int i = 0; i < 5; i++) {
printf("%x ", test[i] & 0xff);
}
}
/*
strlen: 4 sizeof:5
31 32 33 34 0
*/
C语言初始化错误示例
#include <stdio.h>
#include <string.h>
int main() {
char test[4] = "1234"; // 数组大小比字符串+结束符长度小一
char after[] = "5678"; // 在其后申请其他非零变量
printf("strlen: %ld sizeof:%ld\n", strlen(test), sizeof(test));
for (int i = 0; i < strlen(test); i++) {
printf("%c ", test[i]);
}
}
/*
strlen: 8 sizeof:4
1 2 3 4 5 6 7 8 ⏎
*/
使用g++编译,显示错误
g++ c3.c -o c3pp
c3.c: In function ‘int main()’:
c3.c:5:18: error: initializer-string for array of chars is too long [-fpermissive]
5 | char test[4] = "1234"; // 数组大小比字符串+结束符长度小一
C

C++

实际上只要修改后缀名,vscode会自动显示其大小
常量定义
C语言
// 定义局部数组
#include <stdio.h>
void func() {
const int TEST_SIZE = 10;
int test_data[TEST_SIZE]; // 在func函数中使用常量整数定义数组大小
for (int i = 0; i < TEST_SIZE; i++) {
test_data[i] = i + 10;
}
for (int i = 0; i < TEST_SIZE; i++) {
printf("%d ", test_data[i]);
}
}
int main() {
const int SIZE = 10;
int data[SIZE]; // 在main函数中使用常量整数定义数组大小
for (int i = 0; i < SIZE; i++) {
data[i] = i;
}
for (int i = 0; i < SIZE; i++) {
printf("%d ", data[i]);
}
printf("\n");
func();
}
/*
运行成功
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
*/
// 定义全局数组
#include <stdio.h>
const int SIZE = 10;
int data[SIZE];
int main() {
for (int i = 0; i < SIZE; i++) {
data[i] = i;
}
for (int i = 0; i < SIZE; i++) {
printf("%d ", data[i]);
}
}
/*
编译输出
c2.c:3:5: error: variably modified ‘data’ at file scope
3 | int data[SIZE];
*/
// 使用define替代const
#include <stdio.h>
#define SIZE (10)
int data[SIZE];
int main() {
for (int i = 0; i < SIZE; i++) {
data[i] = i;
}
for (int i = 0; i < SIZE; i++) {
printf("%d ", data[i]);
}
}
/*
0 1 2 3 4 5 6 7 8 9
*/
c++语言
同样的代码,使用g++编译就能通过
#include <stdio.h>
const int SIZE = 10;
int data[SIZE];
int main() {
for (int i = 0; i < SIZE; i++) {
data[i] = i;
}
for (int i = 0; i < SIZE; i++) {
printf("%d ", data[i]);
}
}
// 编译运行
gcc cpp1.c -o cpp1
cpp1.c:4:5: error: variably modified ‘data’ at file scope
4 | int data[SIZE];
| ^~~~
g++ cpp1.c -o cpp1
./cpp1
0 1 2 3 4 5 6 7 8 9 ⏎
// 修改后缀名为cpp也能编译通过
gcc cpp1.cpp -o cpp1
C语言编译错误:Variably modified array at file scope
gcc 自动识别的文件扩展名,gcc/g++ -x 选项指定语言,不同 gcc 版本 -std 编译选项支持列表
据说当你两眼深深的凝视深渊是,深渊也同样凝视着你。但是,如果你深深凝视本书,显然并不十分优雅,另外你很可能患有头痛或其他疾患。
我无法想象,除了计算机编程以外,我还能做些什么工作。在所有的日子里,你从虚幻中创建模式与结构,并顺便解决数十个小问题。人脑的聪明与天才被栓在计算机的高速度和准确性上。
事实就是如此。人类的最高目标是奋斗,寻求,创造。每位程序员都应该寻找并抓住每一次机会,使自己…哇!写得太多了。《C专家编程》尾页

![[附源码]计算机毕业设计Python飞越青少儿兴趣培训机构管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/1d1f69b756ed4c2aa8dcef5988c91f87.png)



![[附源码]计算机毕业设计Node.js仓库管理系统(程序+LW)](https://img-blog.csdnimg.cn/bb730bdd36244a46b7a7327ef3f9d82c.png)



![[附源码]计算机毕业设计Python高校流浪动物领养网站(程序+源码+LW文档)](https://img-blog.csdnimg.cn/dab16938f48740fe91edb45d2ca3db9b.png)