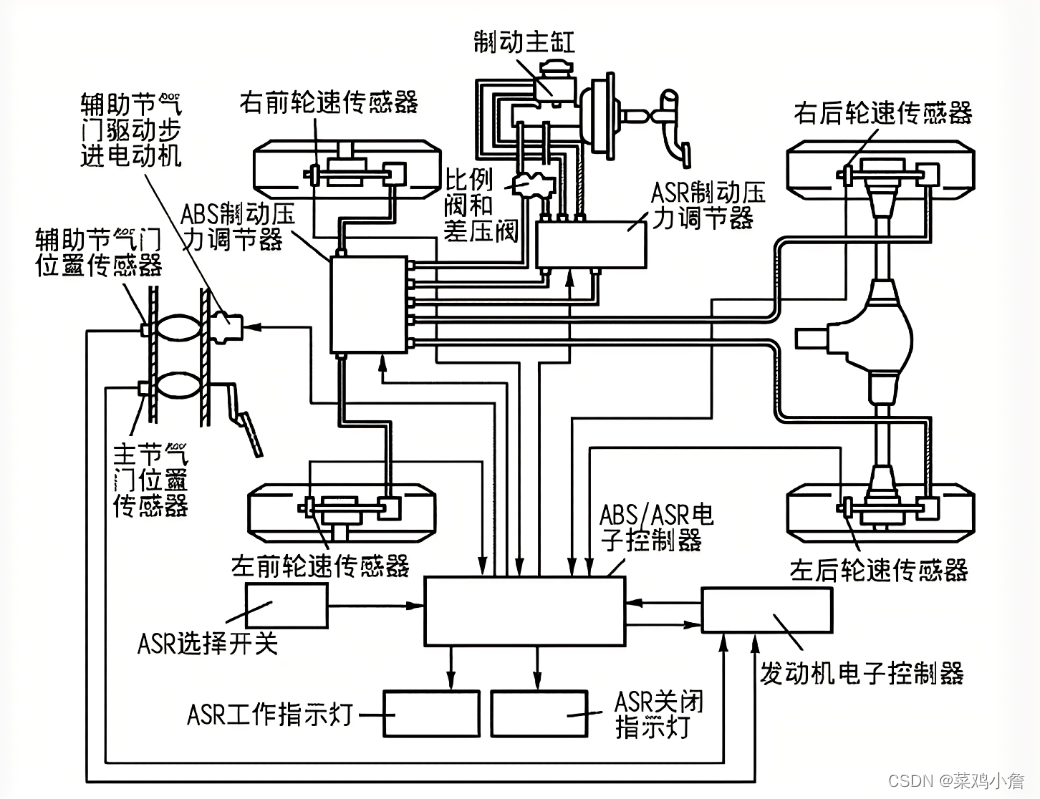
1 分片思路
打开rule.xml 文件,找到对呀的分片规则,如:sharding-by-intfile
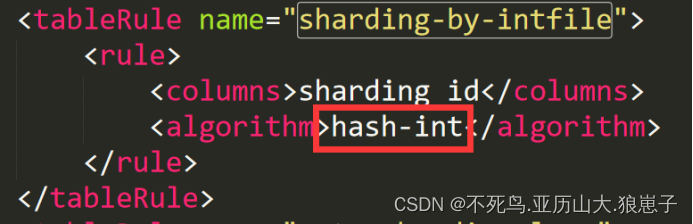
标签含义:
columns:代表数据库里面的字段名
algorithm:分片算法
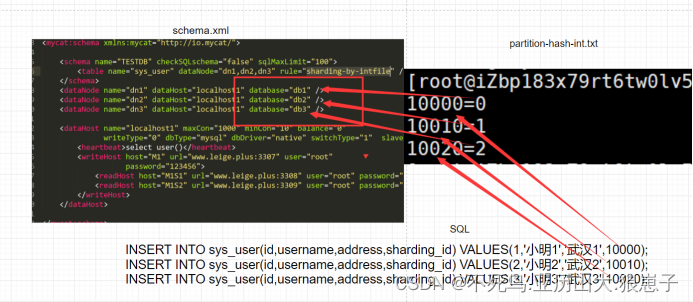
找到rule.xml文件中的hash-int分片算法地址,指向文件partition-hash-int.txt

查看conf/partition-hash-int.txt文件查看规则

整体逻辑如下:
2 枚举路由规则
通过在配置文件中配置可能的枚举id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省 份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下:
<tableRule name="sharding-by-intfile">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">1</property>
</function> 3 partition-hash-int.txt 配置
10000=0
10010=1
DEFAULT_NODE=1上面columns 标识将要分片的表字段,algorithm 分片函数, 其中分片函数配置中,mapFile标识配置文件名称,type默认值为0,0 表示Integer,非零表示String, 所有的节点配置都是从0开始,及 0代表节点1
defaultNode 默认节点:小于 0表示不设置默认节点,大于等于 0表示设置默认节点
默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点
如果不配置默认节点(defaultNode值小于0 表示不配置默认节点),碰到 不识别的枚举值就会报错, * like this:can’t find datanode for sharding
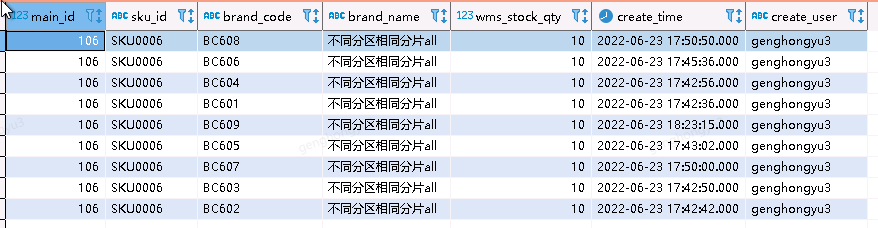
添加数据时给sharding_id字 段值为10000会插入到db1数据库 10010会到db2数据库 以此类推
该规则上一章已经演示过了,这里就不演示了。