MySQL数据库基本操作与简单管理
- 1、数据库的基本概述
- 1.1数据库背景
- 1.2数据库组成
- 1.3数据库发展
- 1.4数据库组成
- 1.5数据库的数据流向
- 1.6数据库功能
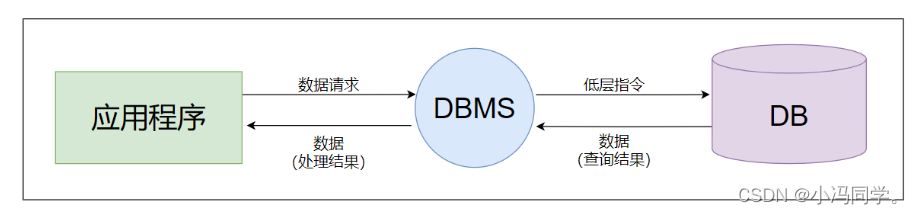
- 1.7DBMS的工作模式
- 2、关系性数据库和非关系性数据库
- 2.1关系型数据库
- 2.2非关系型数据库
- 2.3关系型数据库和非关系型数据库的区别
- 3、编译安装部署数据库
1、数据库的基本概述
1.1数据库背景
数据库(Database)是用于存储和管理数据的软件系统。它们被广泛应用于各种领域,包括企业、科学、医疗、教育、政府等。数据库系统可以帮助组织和管理大量数据,从而提高数据的可靠性、安全性和可用性。
1.2数据库组成
数据库系统由两个主要组成部分组成:数据库管理系统(DBMS)和数据库。
(1)数据库管理系统是一种软件,用于管理数据库的创建、维护和访问。它提供了一种标准化的方式,让用户可以方便地访问和操作数据库中的数据。
(2)数据库是一个存储数据的容器,可以包含多个表、索引、视图和其他对象。
1.3数据库发展
数据库的历史可以追溯到20世纪60年代。下面是数据库的一些重要发展历程:
1960年代:最早的数据库系统是针对IBM的主机系统的。最初的关系型数据库管理系统(RDBMS)是英国计算机科学家Edgar F. Codd在1969年提出的。
1970年代:在这个时期,出现了第一批商业数据库管理系统,例如IBM的IMS和Oracle的Oracle。SQL语言也在这个时期被标准化。1980年代:在这个时期,关系型数据库开始流行起来。甲骨文、IBM、Microsoft等公司
1990年代:面向对象数据库(OODB)开始受到关注,它是一种允许对象之间相互关联的数据库。同时,也出现了大量的关系型数据库管理系统和数据仓库系统。
2000年代:随着互联网的发展,非关系型数据库(NoSQL)开始流行起来。这种数据库不使用传统的关系模型,而是使用不同的数据模型,例如文档、键值对、图形等。
2010年代:云计算和大数据技术的发展推动了数据库的发展。云数据库和分布式数据库系统变得越来越流行。
1.4数据库组成
数据库是一种用于存储、组织和管理数据的系统。它可以让用户方便地访问和操作数据,并确保数据的安全性、一致性和完整性。下面是一些数据库的基本概念:
- 数据库管理系统(DBMS):它是一种软件系统,可以管理数据库的创建、维护和使用。常见的数据库管理系统有MySQL、Oracle、SQL Server等。
- 数据库:它是一个包含一系列相关数据的集合,通常包括表、视图、索引、存储过程等。
- 表:数据库中的一个基本组成部分,由多个行和列组成,每个列都有一个唯一的名称和数据类型,每个行则包含了一组相关的数据。
- 字段:表中的列,它们定义了每行所包含的数据类型和数据值。
- 记录:表中的行,它们包含了一组相关的数据。
- 主键:表中用来唯一标识每个记录的字段或字段组合,通常是一个唯一的标识符。
- 外键:表中用来关联另一个表的字段,它引用了另一个表的主键。
- 视图:它是一个虚拟表,由一个或多个表的数据按照特定的条件组合而成,可以简化数据访问和查询。
- 索引:它是一种数据结构,用于快速查找和访问表中的数据。常见的索引类型包括B-树索引和哈希索引。
- 存储过程:它是一组预编译的SQL语句,可以在数据库中执行,通常用于实现复杂的数据操作、数据验证和数据访问控制等功能。
1.5数据库的数据流向
数据库的数据流向通常包括以下三个方向:
1、数据的输入:用户通过各种方式向数据库中输入数据,例如通过应用程序、网页、API等方式。
2、数据的处理:数据库管理系统对输入的数据进行处理和存储,例如通过SQL语句执行数据的增、删、改、查等操作,并将数据存储到表中。
3、数据的输出:用户可以通过各种方式从数据库中获取所需的数据,例如通过应用程序、网页、API等方式获取数据,并进行显示、分析、处理等操作。
在这个过程中,数据库管理系统扮演着非常重要的角色,它负责管理和维护数据库中的数据,保证数据的安全性、一致性和完整性。
数据库管理系统还提供了各种功能和工具,例如备份、恢复、性能监测、访问控制等,以方便用户管理和维护数据库。
同时,数据库管理系统还可以通过数据的复制、同步等方式,将数据流向扩展到多个系统、多个地点,以满足不同的业务需求。
1.6数据库功能
数据库的建立和维护功能:这些功能包括创建数据库、定义表结构、设定字段类型、规定主键和外键等。在数据录入时,需要进行数据转换和数据清洗等操作。数据库转储和恢复功能用于备份和恢复数据。数据库重组和性能监视功能则用于优化数据库性能,例如重新组织表、索引等以提高查询效率,以及监视数据库运行情况以及性能瓶颈等。
1、数据定义功能:这些功能包括定义全局数据结构、局部逻辑数据结构、存储结构、保密模式及信息格式等。数据定义功能是指对数据库中的各种对象进行定义,例如表、字段、视图、索引、存储过程等,以及定义各种数据类型、数据格式、数据约束等。这些定义保证了存储在数据库中的数据正确、有效和相容,以防止不合语义的错误数据被输入或输出。
2、数据操纵功能:数据操纵功能包括数据查询和统计、数据更新、数据插入、数据删除等,用户可以通过SQL语句或其他方式对数据库中的数据进行操作。数据查询和统计功能包括选择数据、排序、分组、聚合等操作,以便用户快速获取所需的数据。数据更新包括插入、修改、删除等操作,以便用户对数据进行更新和维护。
3、数据库的运行管理功能:这些功能是数据库管理系统的核心部分,包括并发控制、存取控制、数据库内部维护等功能。并发控制功能用于控制多个用户同时访问数据库时的冲突和互斥,以保证数据的一致性和完整性。存取控制功能用于控制用户对数据库的访问权限,以保证数据的安全性。数据库内部维护功能用于保证数据库的稳定性和可靠性,例如垃圾回收、空间管理、日志管理等。
4、通信功能:数据库管理系统需要与其他系统和应用程序进行通信,例如与Web应用、移动应用、第三方服务等的集成和交互。通信功能包括数据的导入和导出、数据的转换和格式化、数据的传输和同步等。例如,Access可以与其他Office组件进行数据交换,以便用户更方便地管理和使用数据。
1.7DBMS的工作模式
1、接受应用程序的数据请求和处理请求:应用程序通过DBMS的API(应用程序接口)向DBMS发送数据请求,例如查询、插入、更新、删除等操作。DBMS负责解析这些请求,并将它们转换为执行数据库操作的底层指令。
2、将用户的数据请求(高级指令)转换为复杂机器代码(底层指令):DBMS将用户的高级指令(例如SQL语句)转换为底层指令,这些底层指令是DBMS能够理解和执行的机器代码。这个过程通常涉及到语法分析、语义分析、优化等操作,以确保生成的底层指令能够高效地执行数据库操作。
3、实现对数据库的操作:DBMS使用底层指令直接操作数据库,例如读取、修改、删除、插入等操作。这些操作通常涉及到文件I/O、索引查找、锁定、并发控制等复杂的操作,以确保数据的一致性、可靠性和安全性。
4、从数据库的操作中接受查询结果:如果用户的请求是查询操作,DBMS会从数据库中检索出符合查询条件的数据,并将这些数据返回给用户。这个过程涉及到数据的读取、过滤、排序、分组等操作。
5、对查询结果进行处理(格式转换):DBMS通常会将查询结果转换为用户需要的格式,例如XML、JSON、CSV等格式。这个过程通常涉及到数据的格式转换、编码转换、数据加工等操作。
6、将处理结果返回给用户:DBMS将处理后的结果返回给用户,用户可以通过应用程序或其他方式展示和使用这些数据。
2、关系性数据库和非关系性数据库
2.1关系型数据库
概述:
关系型数据库是指采用关系模型的数据库管理系统(DBMS),以表格(也称为关系)的形式来组织和管理数据。关系型数据库的核心思想是将数据组织成一组表格,每个表格包含多个行和列,行表示记录,列表示字段。
特点:
1、数据表格化:关系型数据库采用表格的形式来组织和管理数据,每个表格包含多个行和列。
2、数据结构化:关系型数据库要求数据具有结构化的特点,即每个表格都有一个预定义的数据结构,包括字段名、数据类型、长度、约束条件等。
3、数据关联性:关系型数据库通过主键和外键等关联机制,将不同的数据表格连接起来,以满足复杂的业务需求。
4、数据一致性:关系型数据库采用事务机制来保证数据的一致性,事务是一组相关操作的集合,要么全部执行成功,要么全部回滚。
5、数据安全性:关系型数据库提供了访问控制、数据加密、审计等安全机制,以保护数据免受未经授权的访问和使用。
6、数据查询语言:关系型数据库采用结构化查询语言(SQL)作为查询语言,用户可以通过SQL语句来查询和修改数据。
7、数据扩展性:关系型数据库可以通过添加新的表格、字段等方式来扩展数据。
应用场景:
关系型数据库被广泛应用于企业应用系统、电子商务平台、金融交易系统、医疗信息管理系统等领域,例如MySQL、Oracle、SQL
Server等都是常见的关系型数据库管理系统。虽然关系型数据库具有很多优点,但也存在一些局限性,例如数据结构的限制、性能瓶颈等问题。为了解决这些问题,出现了一些非关系型数据库(NoSQL数据库),例如文档型数据库、列族数据库、图数据库等。
2.2非关系型数据库
概述:
非关系型数据库(NoSQL数据库)是指不使用传统的关系型数据表格来组织和管理数据的数据库管理系统。与关系型数据库不同,非关系型数据库采用不同的数据模型,例如文档、键值、列族、图等模型,以适应不同的应用场景和数据类型
特点:
1、数据模型多样性:非关系型数据库采用不同的数据模型,例如文档、键值、列族、图等模型,以适应不同的应用场景和数据类型。
2、数据结构灵活性:非关系型数据库不要求数据具有固定的结构,例如文档型数据库可以存储不同结构的文档。
3、数据可扩展性:非关系型数据库可以轻松地扩展数据,例如通过添加新的节点、分片等方式来扩展数据。
4、数据高可用性:非关系型数据库采用分布式架构,可以实现数据的高可用性和容错性。
5、数据高性能:非关系型数据库通常采用内存计算、索引优化、分布式计算等技术,可以实现高性能的数据访问和查询。
6、数据分布式处理:非关系型数据库采用分布式架构,可以将数据分布在多个节点上并进行并行处理,以实现高效的数据处理和查询。
7、数据复制和同步:非关系型数据库可以将数据复制到多个节点,以实现数据的备份和同步。
应用场景:
非关系型数据库在大数据、云计算、物联网等领域得到广泛应用,例如MongoDB、Redis、Cassandra、HBase等都是常见的非关系型数据库管理系统。虽然非关系型数据库具有很多优点,但也存在一些局限性,例如数据一致性、数据完整性、查询语言的限制等问题。因此,在选择数据库时,需要根据实际业务需求和数据特点来选择适合的数据库管理系统。
2.3关系型数据库和非关系型数据库的区别
1、数据模型不同:关系型数据库采用二维表格的数据模型,表格之间通过关系建立联系;而非关系型数据库采用各种数据模型,例如文档、键值、列族、图等模型。
2、数据结构不同:关系型数据库要求数据具有固定的结构,每个表格都有一组预定义的字段;而非关系型数据库不要求数据具有固定的结构,可以存储不同结构的数据。
3、数据操作语言不同:关系型数据库使用结构化查询语言(SQL)作为操作语言,非关系型数据库则使用不同的操作语言或API。
4、数据扩展性不同:关系型数据库在扩展数据时需要添加新的表格或字段,而非关系型数据库可以轻松地扩展数据,例如通过添加新的节点、分片等方式来扩展数据。
5、数据一致性不同:关系型数据库采用ACID事务来保证数据的一致性,而非关系型数据库通常采用BASE模型,强调基于可用性、最终一致性和灵活性来保证数据的一致性。
6、性能和可扩展性不同:非关系型数据库通常具有更好的可扩展性和性能,可以处理海量数据和高并发请求,而关系型数据库在某些情况下可能会受到性能瓶颈的限制。
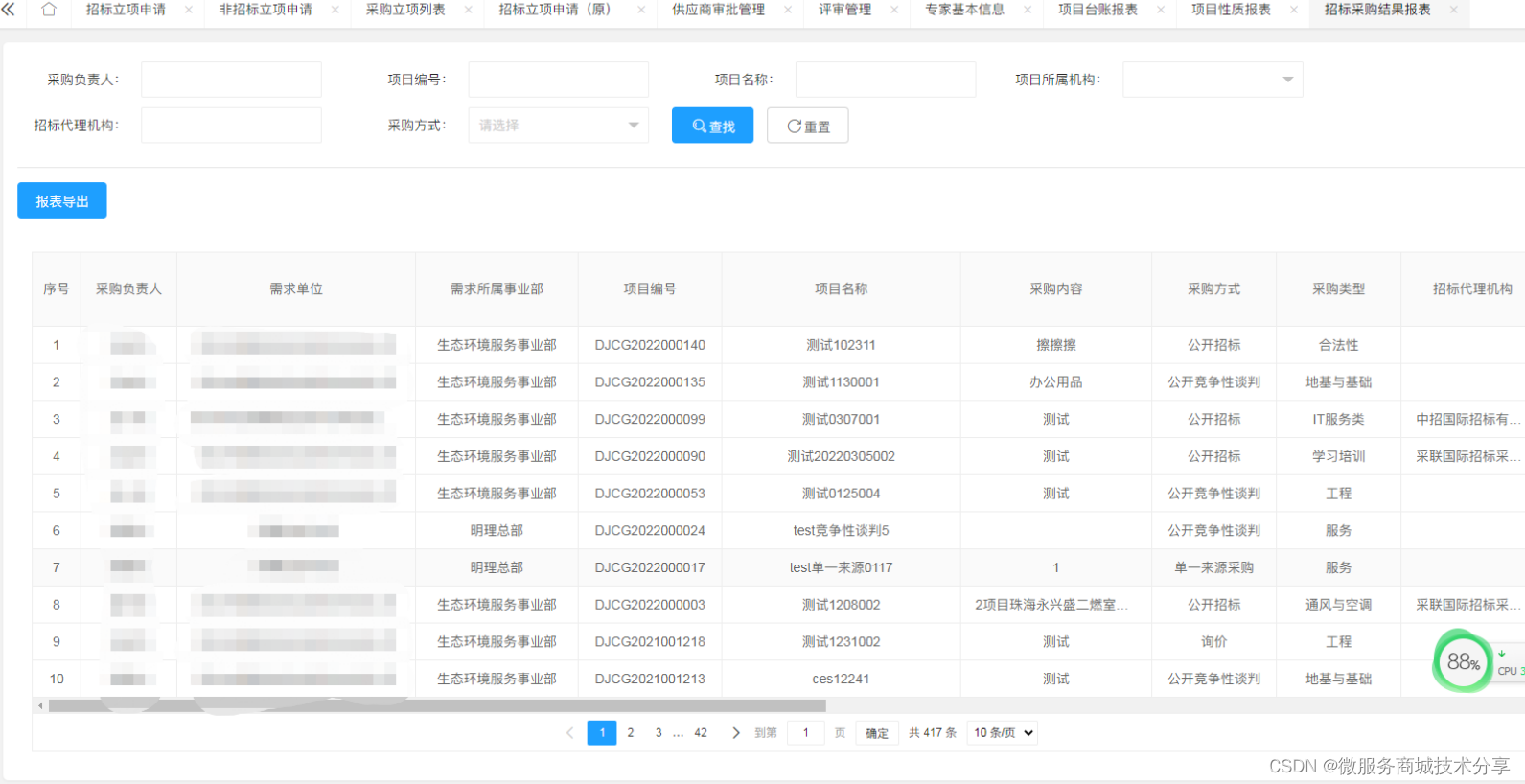
3、编译安装部署数据库
安装Mysql环境依赖包
yum -y install gcc gcc-c++ cmake bison bison-devel zlib-devel libcurl-devel libarchive-devel boost-devel ncurses-devel gnutls-devel libxml2-devel openssl-devel
libevent-devel libaio-devel
//安装依赖环境包
创建运行用户
编译安装

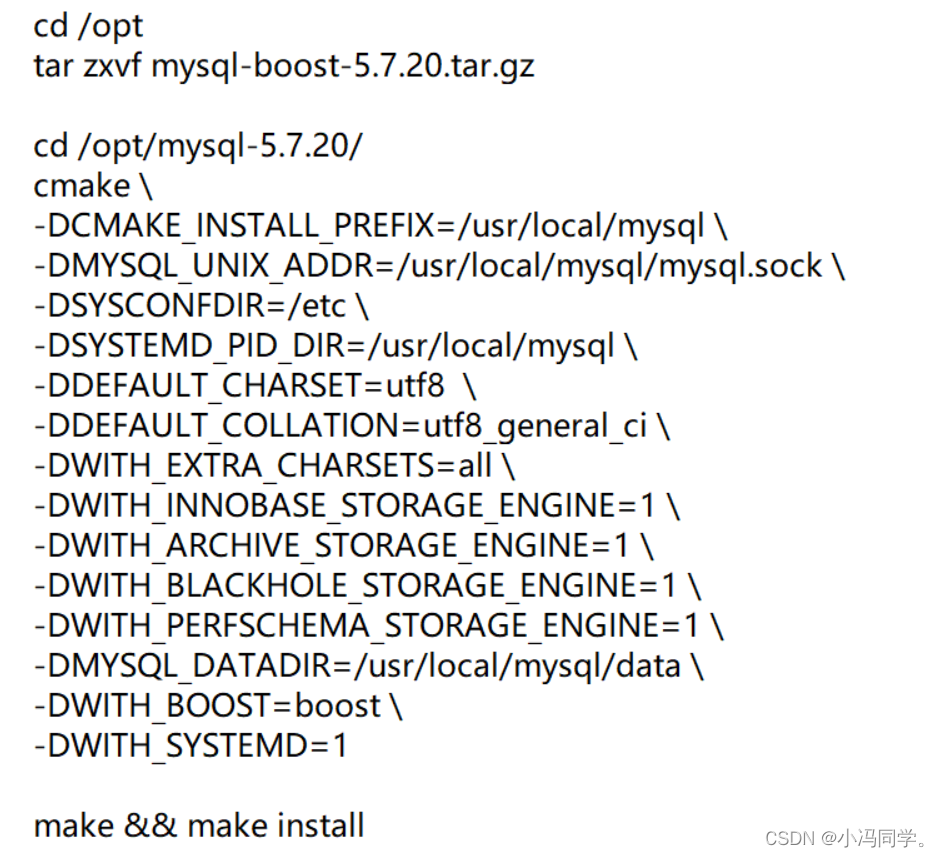
修改mysql 配置文件

更改mysql安装目录和配置文件的属主属组

设置路径环境变量

初始化数据库

添加systemctl系统服务

设置mysql用户的登录密码