Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
impala介绍
Impala集群包含一个Catalog Server (Catalogd)、一个Statestore Server (Statestored) 和若干个Impala Daemon (Impalad)。Catalogd主要负责元数据的获取和DDL的执行,Statestored主要负责消息/元数据的广播,Impalad主要负责查询的接收和执行。
Impalad又可配置为coordinator only、 executor only 或coordinator and executor(默认)三种模式。Coordinator角色的Impalad负责查询的接收、计划生成、查询的调度等,Executor角色的Impalad负责数据的读取和计算。默认配置下每个Impalad既是Coordinator又是Executor。生产环境建议做好角色分离,即每个Impalad要么是Coordinator要么是Executor。

Impala集群内部的元数据同步的机制 是从catalog批量收集一批表的元数据,通过statestore广播到coordinator。catalog在收集元数据的时候需要为每个表加一个读锁,如果这时候某一个表有跑批的任务,或者因为其他原因加了写锁,那么收集线程加读锁的逻辑就会被阻塞住,这就导致对应的 coordinator上的这些查询得不到执行(处于created状态)。
集群规划
| 节点名称 | impala-catalogd | impala-statestored | impala-server |
|---|---|---|---|
| node01 | √ | √ | √ |
| node02 | × | × | √ |
| node03 | × | × | √ |
配置本地yum源
1. 在node01节点上安装httpd服务器
#yum方式安装httpds服务器
[root@node01 ~]# yum install -y httpd
#启动httpd服务器
[root@node01 ~]# systemctl start httpd
#查看httpd转态是否启动
[root@node01 ~]# systemctl status httpd
2. 配置yum源
- 上传下载好的impala的压缩包cdh5.14.0-centos7.tar.gz到/var/www/html/目录
- 解压 tar -zxvf cdh5.14.0-centos7.tar.gz
- 配置yum源:cd /etc/yum.repo/
- vim local.repo
#需要与文件名保持一致
[local]
name=local_yum
#访问当前源的地址信息
baseurl=http://node01/cdh/5.14.0/
#为0不做gpg校验
gpgcheck=0
#当前源是否可用,为1则可用,为0则禁用
enabled=1

- 导入秘钥认证
-
防止后边安装失败(这里有个小坑),每个节点都执行
-
rpm --import /var/www/html/cdh/RPM-GPG-KEY-cloudera
-
安装impala
- node01节点安装 impala-catalogd、impala-statestored、 impala-server(impala-Deamon)
[root@node01 ~]# yum install -y impala impala-server impala-state-store impala-catalog impala-shell

- node02节点安装impala-server(impala-Deamon)
yum install -y impala-server impala-shell
3.node03节点安装impala-server(impala-Deamon)
yum install -y impala-server impala-shell

修改hive的配置
1.修改hive-site.xml配置
-
cd /opt/yjx/apache-hive-3.1.2-bin/
-
vim hive-site.xml
<!--指定metastore地址,之前添加过可以不用添加 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
2.分发hive安装目录到集群中其它节点
-
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
修改hadoop的配置
-
在所有节点创建一下这个目录mkdir -p /var/lib/hadoop-hdfs
-
cd /opt/yjx/hadoop-3.1.2/etc/hadoop/
-
vim hdfs-site.xml
-
<!--添加如下内容 --> <!--打开短路读取开关 --> <!-- 打开短路读取配置--> <property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <!--这是一个UNIX域套接字的路路径,将⽤用于DataNode和本地HDFS客户机之间的通信 --> <property> <name>dfs.domain.socket.path</name> <value>/var/lib/hadoop-hdfs/dn_socket</value> </property> <!--block存储元数据信息开发开关 --> <property> <name>dfs.datanode.hdfs-blocks-metadata.enabled</name> <value>true</value> </property> <property> <name>dfs.client.file-block-storage-locations.timeout</name> <value>30000</value> </property> -
分发到其他节点
-
scp hdfs-site.xml node02:$PWD scp hdfs-site.xml node03:$PWD
创建impala配置的软连接
impala中跟Hadoop,Hive相关的配置使用Yum方式安装Impala时默认的Impala配置文件目录为/etc/impala/conf目录,Impala的使用要依赖Hadoop,Hive框架,所以需要把HDFS,Hive的配置文件告知Impala,执行下面的命令,把HDFS和Hive的配置文件软链接到/etc/impala/conf下(所有节点执行)
-
所有节点均执行
-
ln -s /opt/yjx/hadoop-3.1.2/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml ln -s /opt/yjx/hadoop-3.1.2/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml ln -s /opt/yjx/apache-hive-3.1.2-bin/conf/hive-site.xml /etc/impala/conf/hive-site.xml
impala的自身配置(所有节点)
-
创建日志目录mkdir -p /var/logs/impala/
-
chown impala:impala /var/logs/impala/
修改配置

-
cd /etc/default/ scp impala node02:$PWD scp impala node03:$PWD
-
创建目录用于存放mysql的连接驱动mkdir -p /usr/share/java/
-
创建软连接
ln -s /opt/yjx/apache-hive-3.1.2-bin/lib/mysql-connector-java-5.1.32-bin.jar /usr/share/java/mysql-connector-java.jar
修改bigtop的JAVA_HOME路径
#修改bigtop的JAVA_HOME路径
[root@node01 ~]# vim /etc/default/bigtop-utils
[root@node02 ~]# vim /etc/default/bigtop-utils
[root@node03 ~]# vim /etc/default/bigtop-utils
#添加JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
启动集群
-
启动zookeeper
-
zkServer.sh start -
启动Hadoop
-
start-all.sh -
启动Hive
-
# 启动元数据服务 nohup hive --service metastore > /dev/null 2>&1 & #启动hiveServer2 nohup hiveserver2 > /dev/null 2>&1 & #客户端测试 -
启动impala
-
[root@node01 ~]# service impala-state-store start [root@node01 ~]# service impala-catalog start [root@node01 ~]# service impala-server start -
[root@node02 ~]# service impala-catalog start -
[root@node03 ~]# service impala-server start -
验证Impala是否启动
-
ps -ef | grep impala -
浏览器Web界面验证
-
#访问impalad管理界面
http://node01:25000/

说明: 如果进程数启动不对,web页面打不开,去指定的日志目录。
-
jps时出现空白的进程或者process information unavailable
-
解决办法
-
#解决办法(注意只删除后缀为impala的即可) [root@node01 bin]# rm -rf /tmp/hsperfdata_impala* [root@node02 bin]# rm -rf /tmp/hsperfdata_impala* [root@node03 bin]# rm -rf /tmp/hsperfdata_impala*
-
Impala的负载均衡
Impala主要有三个组件,分别是statestore,catalog和impalad,对于Impalad节点,每一个节点都可以接收客户端的查询请求,并且对于连接到该Impalad的查询还要作为Coordinator节点(需要消耗一定的内存和CPU)存在,为了保证每一个节点的资源开销的平衡需要对于集群中Impalad节点做一下负载均衡。
Cloudera官方推荐的代理方案是HAProxy,这里我们也使用这种方式实现负载均衡。实际生产中建议选择一个非Impala节点作为HAProxy安装节点。
1.选择一台机器安装haProxy,这里选择node01安装
-
yum install -y haproxy
- 修改haproxy.cfg配置文件,在配置文件中增加如下内容
-
vim /etc/haproxy/haproxy.cfg
-
#--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # # 1) configure syslog to accept network log events. This is done # by adding the '-r' option to the SYSLOGD_OPTIONS in # /etc/sysconfig/syslog # # 2) configure local2 events to go to the /var/log/haproxy.log # file. A line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 3m timeout connect 5000s timeout client 3600s timeout server 3600s timeout http-keep-alive 10s #健康检查时间 timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # main frontend which proxys to the backends #--------------------------------------------------------------------- frontend main *:5000 acl url_static path_beg -i /static /images /javascript /stylesheets acl url_static path_end -i .jpg .gif .png .css .js use_backend static if url_static default_backend app #--------------------------------------------------------------------- # static backend for serving up images, stylesheets and such #--------------------------------------------------------------------- backend static balance roundrobin server static 127.0.0.1:4331 check #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend app balance roundrobin server app1 127.0.0.1:5001 check server app1 127.0.0.1:5002 check #--------------配置 impala-jdbc ------------------------------------------------------- listen impala :25001 balance roundrobin option tcplog mode tcp #bind 0.0.0.0:21051 #listen impalajdbc server impala_jdbc_01 node02:21050 check server impala_jdbc_02 node03:21050 check #--------------配置impala-shell------------------------------------------------------- listen impala :25002 balance leastconn option tcplog mode tcp #listen impalashell server impala_shell_01 node01:21000 check server impala_shell_02 node02:21000 check server impala_shell_03 node03:21000 check #--------------配置 impala-hue ------------------------------------------------------- #listen impala :25003 #balance source #option tcplog #mode tcp #server impala_hue_01 host01:21050 check #server impala_hue_02 host02:21050 check #-----web ui---------------------------------------------------------------- listen stats :1080 balance stats uri /stats stats refresh 30s #管理界面访问IP和端口 #bind 0.0.0.0:1080 mode http #定义管理界面 #listen status
3.检查配置是否正确
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
-
开启HAProxy代理服务
开启: systemctl start haproxy.service 查看状态: systemctl status haproxy.service 关闭: systemctl stop haproxy.service 重启: systemctl restart haproxy.service 开机自启动: chkconfig haproxy on -
访问监控页面
http://node01:1080/stats

- impala安装包链接: 提取码: k877
Haproxy的下载安装包离线安装步骤
下载安装Haproxy
下载地址:
https://src.fedoraproject.org/repo/pkgs/haproxy/
http://download.openpkg.org/components/cache/haproxy/
haproxy-1.8.10.tar.gz :
haproxy安装包下载 提取码: 6evh
(1)将下载下来的Haproxy放到Linux中, 解压文件
tar -zxvf haproxy-1.7.8.tar.gz
(2)yum安装GCC
yum install gcc-c++
(3)编译与安装Haproxy
进入Haproxy文件夹,编译执行命令:make TARGET=linux26
安装特定位置:make install PREFIX=/usr/local/haproxy
(4)进入创建的文件夹cd /usr/local/haproxy,修改配置
创建一个文件夹,mkdir conf config文件夹
进入该文件夹,在文件夹中,创建 一个文件执行命令: touch haproxy.cnf
编辑配置文件haproxy.cfg
Impala的常见错误
1.Impala不能创建表,提示权限的问题
-
[node02:21000] > create table person2(id int,name string,address string) row format delimited fields terminated by ','; Query: create table person2(id int,name string,address string) row format delimited fields terminated by ',' ERROR: ImpalaRuntimeException: Error making 'createTable' RPC to Hive Metastore: CAUSED BY: MetaException: Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=impala, access=EXECUTE, inode="/hive/warehouse":root:supergroup:drwxr-x--- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:315) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:242) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:606) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkTraverse(FSDirectory.java:1801) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkTraverse(FSDirectory.java:1819) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.resolvePath(FSDirectory.java:676) at org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getFileInfo(FSDirStatAndListingOp.java:114) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3102) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1154) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:966) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:872) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:818) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2678) -
为对应的目录赋权777,我的数仓路径 /hive/warehouse/
-
hdfs dfs -chmod -R 777 /hive/warehouse/

2.hdfs进入安全模式
- hdfs dfsadmin -safemode leave
3.启动datanode时日志发现如下报错信息
- 启动日志
023-09-17 03:04:54,358 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Starting DataNode with maxLockedMemory = 0
2023-09-17 03:04:54,435 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Opened streaming server at /0.0.0.0:9866
2023-09-17 03:04:54,461 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Balancing bandwidth is 10485760 bytes/s
2023-09-17 03:04:54,461 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Number threads for balancing is 50
2023-09-17 03:04:54,476 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Shutdown complete.
2023-09-17 03:04:54,477 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.io.IOException: The path component: '/var/lib/hadoop-hdfs' in '/var/lib/hadoop-hdfs/dn_socket' has permissions 0755 uid 993 and gid 991. It is not protected because it is owned by a user who is not root and not the effective user: '0'. This might help: 'chown root /var/lib/hadoop-hdfs' or 'chown 0 /var/lib/hadoop-hdfs'. For more information: https://wiki.apache.org/hadoop/SocketPathSecurity
at org.apache.hadoop.net.unix.DomainSocket.validateSocketPathSecurity0(Native Method)
at org.apache.hadoop.net.unix.DomainSocket.bindAndListen(DomainSocket.java:193)
at org.apache.hadoop.hdfs.net.DomainPeerServer.<init>(DomainPeerServer.java:40)
at org.apache.hadoop.hdfs.server.datanode.DataNode.getDomainPeerServer(DataNode.java:1195)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:1162)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1417)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:501)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:2783)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:2691)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:2733)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:2877)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2901)
2023-09-17 03:04:54,483 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.io.IOException: The path component: '/var/lib/hadoop-hdfs' in '/var/lib/hadoop-hdfs/dn_socket' has permissions 0755 uid 993 and gid 991. It is not protected because it is owned by a user who is not root and not the effective user: '0'. This might help: 'chown root /var/lib/hadoop-hdfs' or 'chown 0 /var/lib/hadoop-hdfs'. For more information: https://wiki.apache.org/hadoop/SocketPathSecurity
-
解决办法: 由于前面的/var/lib/hadoop-hdfs的问题,需将其用户修改为root
-
# 三个节点都执行这个操作 [root@node01 ~]#chown root /var/lib/hadoop-hdfs/ [root@node02 ~]#chown root /var/lib/hadoop-hdfs/ [root@node03 ~]#chown root /var/lib/hadoop-hdfs/
4.namenode启动异常,日志显示
aused by: org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream$PrematureEOFException: got premature end-of-file at txid 27027; expected file to go up to 27152
at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.nextOp(RedundantEditLogInputStream.java:197)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.readOp(EditLogInputStream.java:85)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.skipUntil(EditLogInputStream.java:151)
at org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream.nextOp(RedundantEditLogInputStream.java:179)
at org.apache.hadoop.hdfs.server.namenode.EditLogInputStream.readOp(EditLogInputStream.java:85)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:213)
... 12 more
这个错误表明在处理 HDFS(Hadoop分布式文件系统)的编辑日志时遇到了意外的文件结尾。
要解决这个问题,您可以尝试以下方法:
-
检查文件完整性:检查导致错误的编辑日志文件是否完整。可能是由于文件损坏或丢失导致了预期范围之外的文件结尾。您可以尝试从备份中恢复丢失的文件或使用其他副本。
-
恢复缺失的日志段:如果确定存在缺失的日志段,您可以尝试使用辅助工具(如
hdfs oiv命令)来恢复缺失的事务日志。具体步骤可以参考 HDFS 文档和社区支持资源。 -
恢复备份:如果有可用的完整备份,您可以尝试将备份数据还原到新的文件系统中,并确保整个过程符合数据一致性和正确性的要求。
-
寻求专业支持:如果以上方法无法解决问题,建议您咨询 Hadoop 或 HDFS 的专业支持团队,他们可以提供更具体和针对性的解决方案。
请注意,在进行任何更改或修复操作之前,请务必备份重要数据,并确保在测试环境中进行验证,以避免进一步数据丢失或其他潜在问题。
-
经测试这个命令
hdfs oiv不行 -
看日志似乎是无法正常写入日志,namenode的元数据可能异常
-
# 使用这个命令修复元数据:hadoop namenode -recover,在出错的机器执行如下命令,一路按c或者y -
参考文章链接
5.impala启动出现空进程
-
说明: 如果进程数启动不对,web页面打不开,去指定的日志目录.
-
jps时出现空白的进程或者process information unavailable
-
#解决办法(注意只删除后缀为impala的即可) [root@node01 bin]# rm -rf /tmp/hsperfdata_impala* [root@node02 bin]# rm -rf /tmp/hsperfdata_impala* [root@node03 bin]# rm -rf /tmp/hsperfdata_impala*
-
Haproxy负载均衡测试
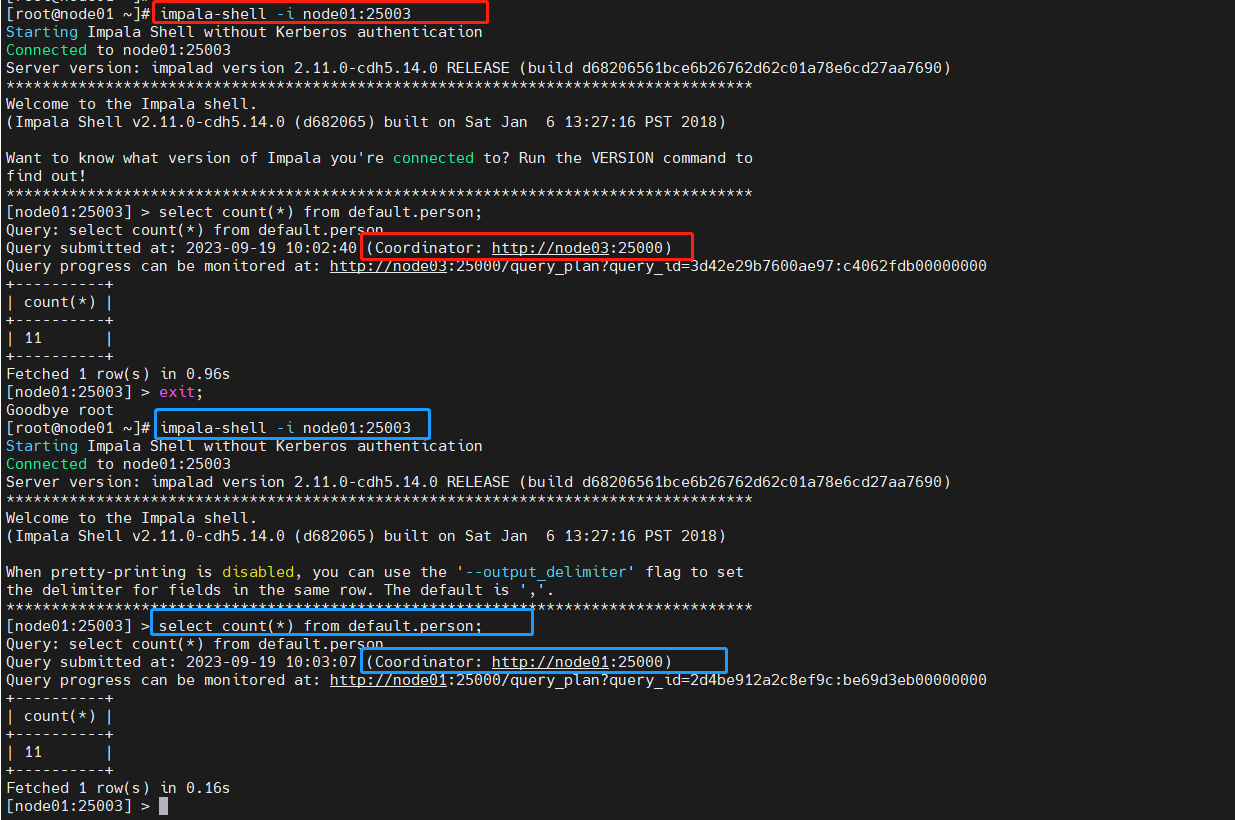
impala-shell测试
-
在安装了Haproxy服务的节点执行命令:注意端口
25003是配置中绑定的路由端口 -
impala-shell -i node01:25003 -
看到我们指定的node01 节点,Haproxy转发至node02执行SQL

-
每次提交SQL任务协调节点都不一样,自动轮询
HDFS高可用集群中standBy 的NameNode无法启动—解决方案
在日常操作中发现自己的高可用hadoop集群,发现存在一台NamNode节点无法启动,但该节点上的DataNode仍可正常运行。其它的NameNode在正常运行。
- 启动日志如下:
Error: Gap in transactions. Expected to be able to read up until at least txid 27896 but unable to find any edit logs containing txid 27711
java.io.IOException: Gap in transactions. Expected to be able to read up until at least txid 27896 but unable to find any edit logs containing txid 27711
问题可能是由多个NameNode上的元数据信息不一致,解决方法如下:
1、停止HDFS集群。
2、删除每个NameNode节点上的data、logs。(我是在刚搭好HDFS集群遇到的这个问题,所有data和logs中的数据可直接删除。如果data和logs中存在重要的不能删除的数据,还请将数据迁移保存至别处,或使用其它方法进行解决)。
3、在每一个JournalNode节点上,输入以下命令启动journalnode服务。(我是在每一台NameNode上启动的)。
hdfs --daemon start journalnode
4、在一个NameNode节点上,对其元数据进行修复
hadoop namenode -recover
# 如果hdfs上没有重要数据可以直接格式化namenode
//格式化
hdfs namenode -format
//启动namenode
hdfs --daemon start namenode
5、在其它每一个NameNode节点上执行下面这句话,同步<第4步那个NameNode节点>的元数据信息。
hdfs namenode -bootstrapStandby
6、其它NameNode节点都去执行下面这句话启动NameNode——除<第4步那个NameNode节点>。
hdfs --daemon start namenode
然后通过jps就可以查看NameNode已经启动了。
参考博客
- https://blog.csdn.net/qq_42385284/article/details/88960678