文章目录
- 获取整个页面所有源码
- 筛选出源码中图片地址
- 将图片下载到本地
- 完整脚本
获取整个页面所有源码
该步骤可以用requests模块实现,分为下面步骤:
定义一个URL 地址;
发送HTTP 请求;
处理HTTP 响应。
下面代码定义了一个get_Html方法,用requests.get()发送get请求,并用res变量接收,然后用.content返回字符串的二进制格式(操作更方便)给get_Html方法,最后调用并把数据给html,并用print输出:
.content返回字符串的二进制格式(操作更方便)
.decode(“utf8”),二进制转码成utf8格式(显示中文)
import requests
url = "http://10.9.75.164/pythonSpider/index.html"
def get_Html(url):
res = requests.get(url = url)
return res.content
html=get_Html(url = url)
print(html.decode("utf8"))
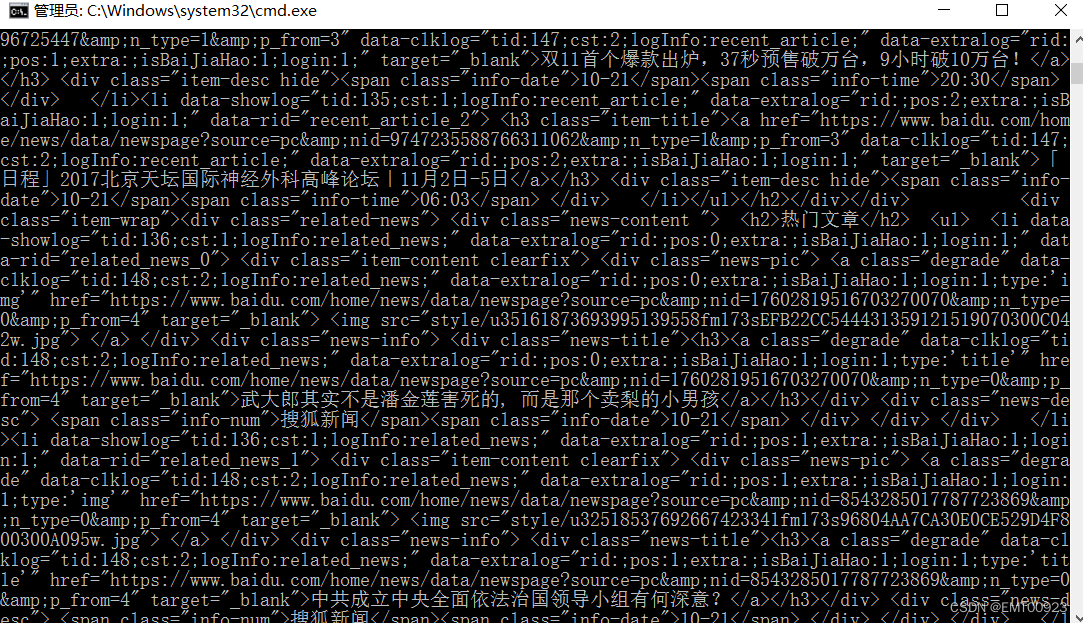
如下图,在命令行执行后获取到目标url的网页源码:
筛选出源码中图片地址
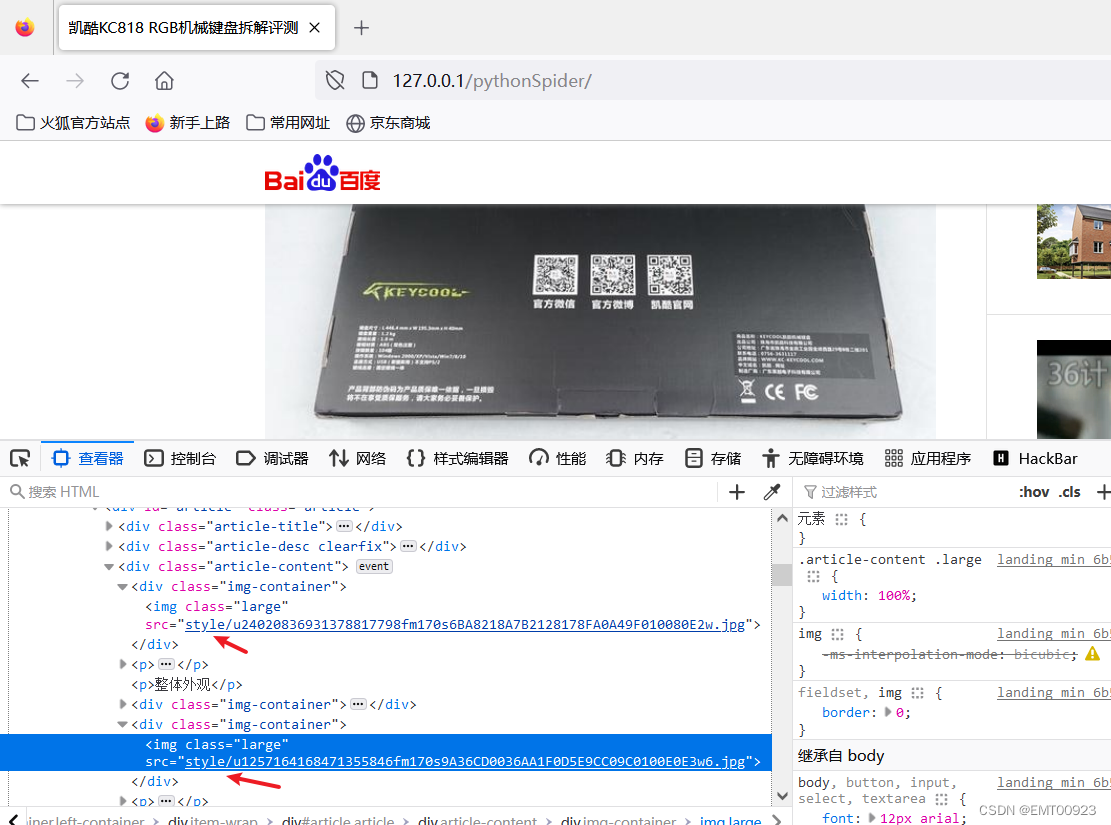
查看网页图片的地址,发现它们都是以style/u开头的URL:
这时候可以用正则来匹配图片地址,用正则匹配出的图片地址是一个列表,用for循环遍历输出:
\w*,匹配所有数字和字母
\.转义点,当做普通字符处理
.decode(),将获取到的源码从二进制转为字符串
import requests
import re
url = "http://10.9.75.164/pythonSpider/index.html"
def get_Html(url):
res = requests.get(url = url)
return res.content
html=get_Html(url = url)
img_path_list = re.findall(r"style/\w*\.jpg",html.decode())
for img_path in img_path_list:
print(img_path)
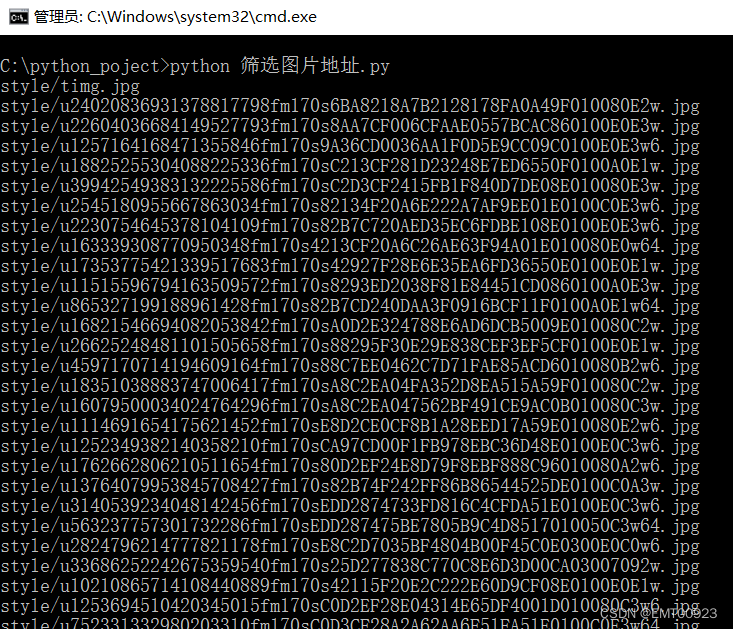
运行结果如下,成功筛选出源码中的所有图片地址:
将图片下载到本地
img_save_path=“./img/1.jpg”,指定图片文件保存的目录
with open(img_save_path,“wb”) as f,以写方式(二进制)打开文件
f.write(res.content),将接收到的GTTP源码以二进制格式写入f文件
下面定义了一个img_download方法,它将url分割子串并与img_path拼接(img_path是一个图片地址),然后用requests.get方法发送get请求并用res变量接收,然后指定了一个保存图片的路径,最后用write函数将源码的二进制写入该图片中:
import requests
url = "http://10.9.75.164/pythonSpider/index.html"
img_path="style/u24020836931378817798fm170s6BA8218A7B2128178FA0A49F010080E2w.jpg"
def img_download(img_path):
img_url=url[0:url.rfind('/')+1]+ img_path
res=requests.get(url= img_url)
img_save_path="./img/1.jpg"
with open(img_save_path,"wb") as f:
f.write(res.content)
img_download(img_path)
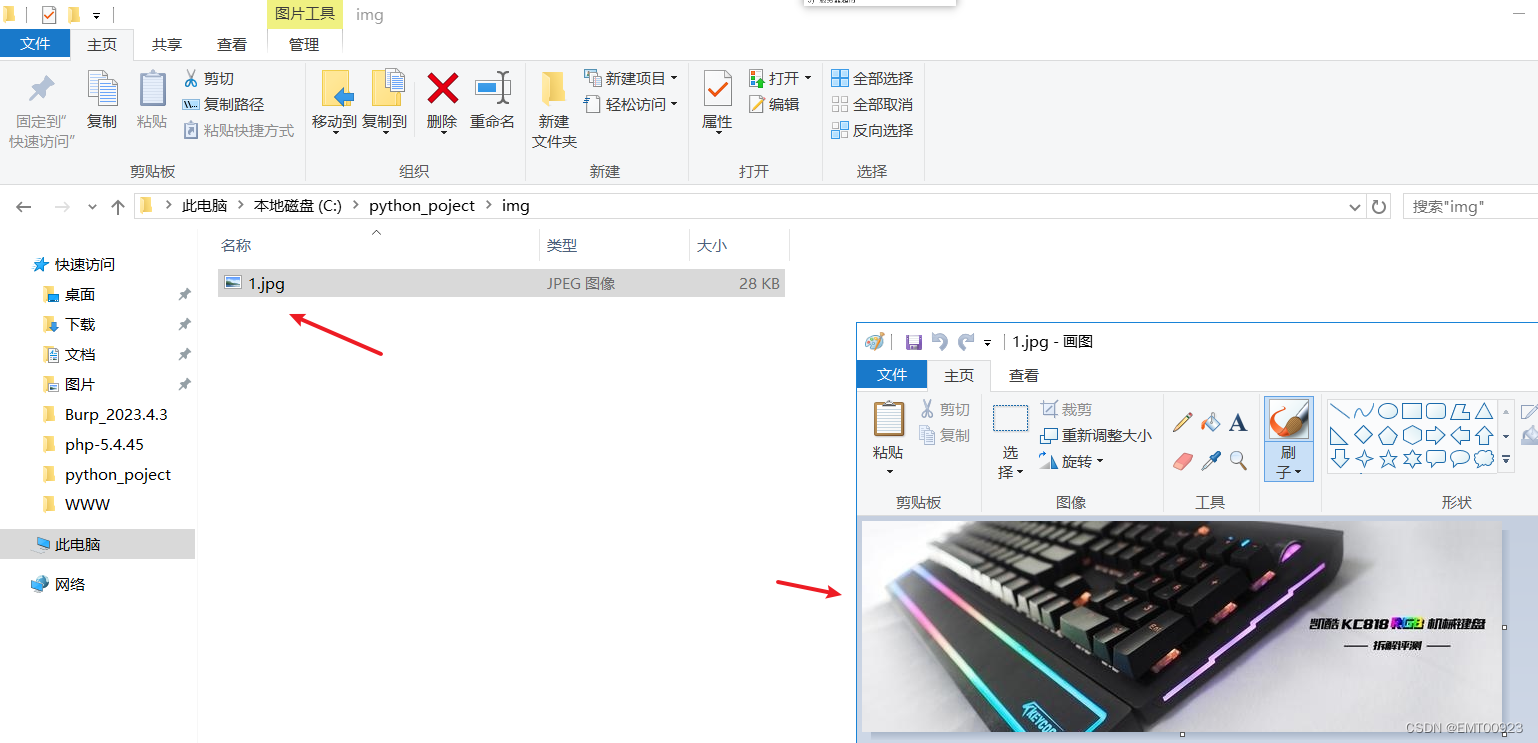
执行成功后结果如下:

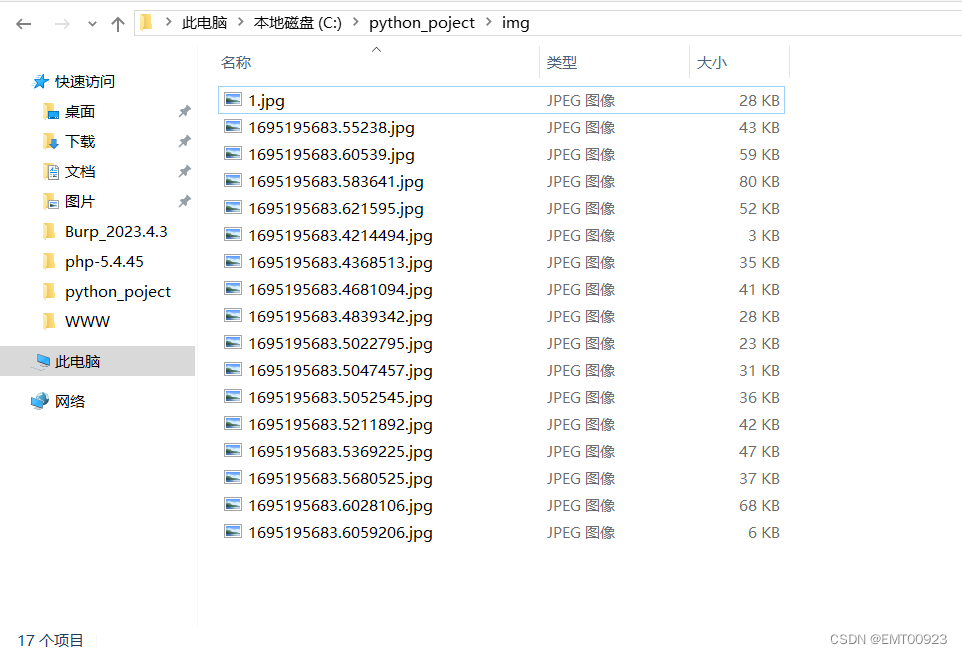
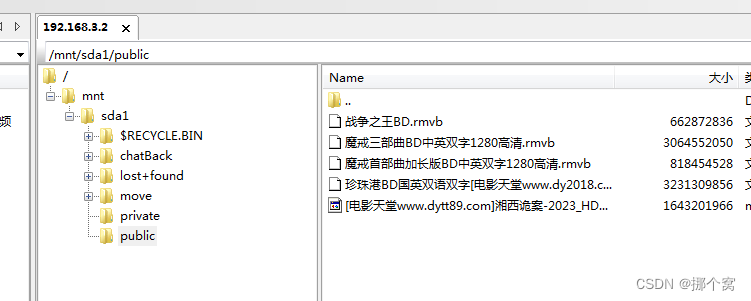
成功爬取图片到本地:
完整脚本
下面是完整脚本,定义了上述的三个方法, get_html方法获取页面源码,get_img_path_list方法筛选出源码中的图片地址并组成一个列表,img_download将文件下载到本地,其中用时间戳命名每个图片文件。
这段代码调用了三个方法,前两个方法的结果给变量html和img_path_list,然后用for循环将列表遍历,每一次遍历都调用img_download方法:
html = get_html(url = url).decode()
img_path_list = get_img_path_list(html = html)
for img_path in img_path_list:
print(img_path)
img_download(img_path = img_path)
完整脚本:
import requests
import re
import time
url = "http://10.9.75.164/pythonSpider/index.html"
def get_html(url):
res = requests.get(url = url)
return res.content
def get_img_path_list(html):
img_path_list = re.findall(r"style/\w*\.jpg", html)
return img_path_list
def img_download(img_path):
img_url=url[0:url.rfind('/')+1]+ img_path
res=requests.get(url= img_url)
img_save_path=f"./img/{time.time()}.jpg"
with open(img_save_path,"wb") as f:
f.write(res.content)
html = get_html(url = url).decode()
img_path_list = get_img_path_list(html = html)
for img_path in img_path_list:
print(img_path)
img_download(img_path = img_path)
脚本执行成功:
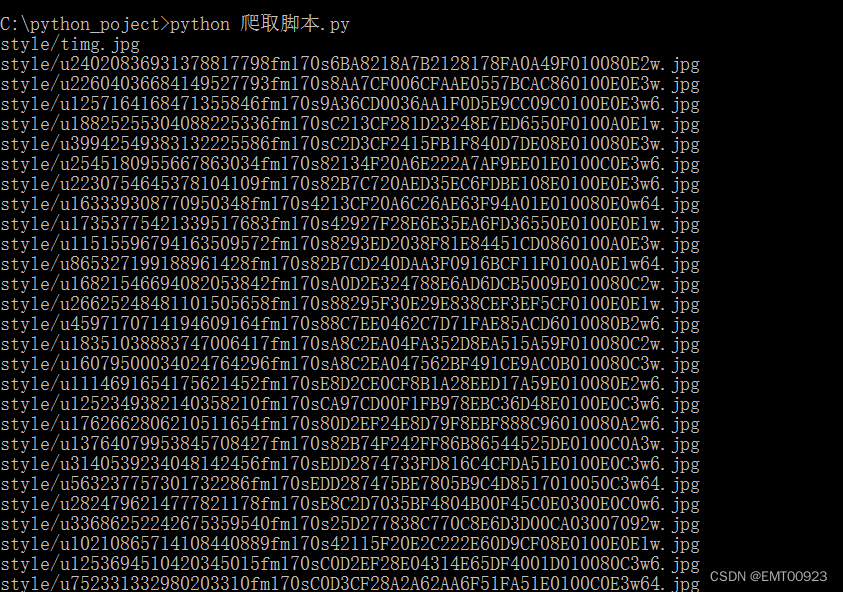
下载图片到本地成功: