上一篇文章《深度干货 | 揭秘YashanDB融合存储引擎》
https://mp.weixin.qq.com/s/yipJcEAH3fVA-_hnUvOiKA从存储结构、事务引擎、高可用等方面介绍了YashanDB存储引擎的整体架构。本篇为大家详细解读YashanDB行式存储技术。
数据库底层组织数据的方式主要分为行式存储和列式存储两大类。YashanDB在存储引擎设计上采用融合架构,基于统一存储底座构建了不同的存储结构,支持In-place Update行式存储,适应在线事务处理场景(OLTP);支持原位更新(In-place Update)和追加式(Append-only)两种列式存储,具备原生混合负载处理能力(HTAP)和海量数据分析能力(OLAP)。
YashanDB的堆表(Heap Table)在结构上采用的是行式存储,以行为粒度将数据随机存储在最小存储单元数据块上。行式存储的优势是数据以行汇聚,随机增删改查操作效率高,通常配合Btree等类型索引使用,提供高效的事务处理能力。缺点是查询时需要整行读出,如果只需要部分列的数据,就会扫描不必要的数据,同时很难利用向量化计算来进行加速,压缩率也没有列式存储高。
行式存储关键技术
在线事务处理(OLTP)是最常见的业务模型之一,通常具有以下特点:
要保证实时性,对数据库的响应时延要求很高;
要保证数据一致性,要求数据库提供强一致事务保证;
并发量高,要求数据库并发能力强。
YashanDB行式存储主要用于在线事务处理场景,在设计上根据其场景特点进行了针对性优化,本文将重点介绍其中的几个关键技术实践:
事务并发控制:优化传统MVCC机制,采用In-place Update的块级MVCC,提供事务高并发处理能力;
插入性能优化:通过提升并发性、批量化处理、减少日志产生等优化,降低事务处理过程中插入响应时延;
行存储结构:尽管In-place Update原位更新带来了性能的显著提升,但是宽行的存储设计成为了面临的关键挑战之一。因此,我们针对宽行设计行链接和行迁移机制,以确保对宽行的处理性能不受影响。
事务并发控制
YashanDB使用业内主流的MVCC机制(Multi-version Concurrency Control,多版本并发控制)实现事务并发控制,但MVCC的实现在不同的数据库差异较大,主要包含以下两种:
Append-only行级MVCC:更新数据时新增一条数据。这种方式的缺点是,历史版本数据与最新版本存储在一个空间,导致空间膨胀,最新版本的查询代价高,历史版本垃圾回收开销大,修改时需要拷贝整行。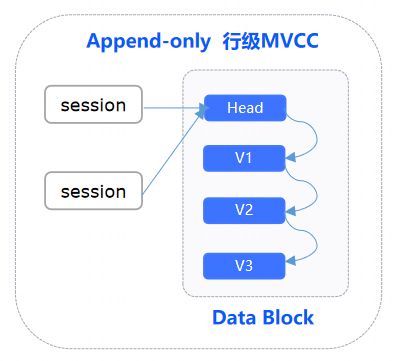
图1 Append Only的行级MVCC
In-place Update 行级MVCC:更新记录时对原始数据进行覆盖。这种有独立的Undo空间存储历史数据,最新数据的更新是In-Place Update(原位更新),但由于每一行都要关联对应的历史版本记录,存储开销大。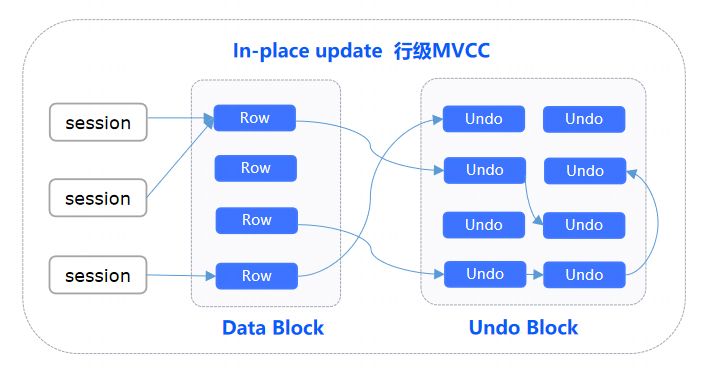
图2 In-place Update的行级MVCC
YashanDB针对主流MVCC机制存在的问题,在设计上采用了In-place Update的块级MVCC。块级MVCC与行级MVCC最大的差别是,与历史版本(undo数据)关联的是事务而不是行,当需要查询行的历史版本(一致性版本)时,不再按行构建,而是通过数据块上的事务信息,构建整个数据块级别的历史版本,通常称之为一致性数据块(Consistent Read Block)。
块级MVCC优化了数据块内行的Undo空间开销,同一事务在同一数据块中修改不同行时产生的Undo可以进行合并,有效节省了存储空间开销。 按块构建一致性版本提升了历史数据访问效率,同时在全局对一致性数据块进行缓存之后,可以跨会话共享,避免不同会话之间重复构建。
图3 In Place update的块级MVCC
基于MVCC机制,我们实现了行式存储的行级事务并发控制,主要分为三种场景:
写写并发:写操作之间不会产生冲突,可以并发执行;
读写并发:读操作不会被写操作所阻塞,读操作可以读取到之前的数据版本,保证了读的一致性;
DDL和查询并发:多个读操作或者DDL操作之间不会产生冲突,可以并发执行。
1
写写并发
行存的并发控制单元就在行上,通过行与事务绑定,实现行数据的写写并发控制。行数据被事务修改,事务提交之前,其他事务不能修改该行。
2
读写并发
事务修改了一行数据,未提交之前,其他会话都不能修改这行数据,但是可以查询这行数据,查询的版本是本次查询时间对应的数据快照。查询通过最新数据块以及关联的历史版本(Undo),构建一致性数据块,作为本次查询可见的历史版本快照。
对于索引过滤之后再回表查询的场景,如果每行数据都构建一致性数据块,代价比价大。因此我们通过引入行级可见性判断对这个场景进行了优化,使得大多数索引回表的查询都不需要构建一致性数据块。
针对Nest Loop Join这种外表驱动内表,对内表进行多次查询的场景,我们将内表构建的一致性数据块缓存在全局数据缓存中,以供下一轮内表查询的时候直接使用,这种方式在数据量较大时可以大大减少查询时间。
3
DDL和查询并发
YashanDB实现的是无锁查询,即查询表数据时不加表锁,可以在查询期间并发地对表做Drop/Truncate/Shrink等DDL操作。查询需要保证:要么查到的是一致的数据集,要么在查询过程中检测到对象的数据块被复用而报错。
YashanDB能精准识别数据块是否已经被复用,全方位保证了单个表查询的一致性,以及分区表各个分区之间的一致性。
今天我们讲述了行式存储中事务并发控制的关键设计和优化。YashanDB采用了In-place Update 的块级 MVCC,能极大提高事务并发处理能力。在下一篇,我们将会详解插入性能优化和宽行存储的设计,敬请期待。