文章目录
- 思想
- 避免全零初始化
- 随机权值初始化
- 权值初始化太小:
- 权值初始化太大
- Xavier初始化
- 目标
- 为什么输入和输出分布会变得不同?
- Xavier在使用Tanh时的表现好
- Xavier在使用ReLU时的表现不好
- HE初始化(MSRA)
- 权值初始化总结
思想
通过调整权值的分布使得输出与输入具有相同的分布
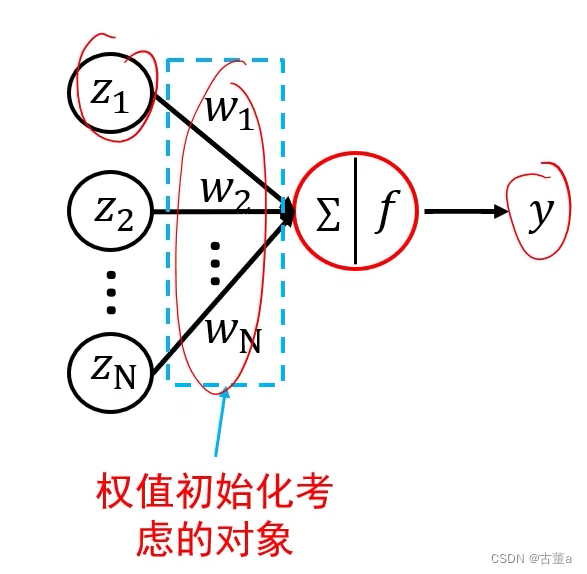
避免全零初始化
全零初始化:网络中不同的神经元有相同的输出,进行同样的参数更新;
因此,这些神经元学到的参数都一样,等价于一个神经元。
建议:采用随机初始化,避免全零初始化!
随机权值初始化
权值初始化太小:
前向信息流消失
权值初始化太大
反向梯度消失
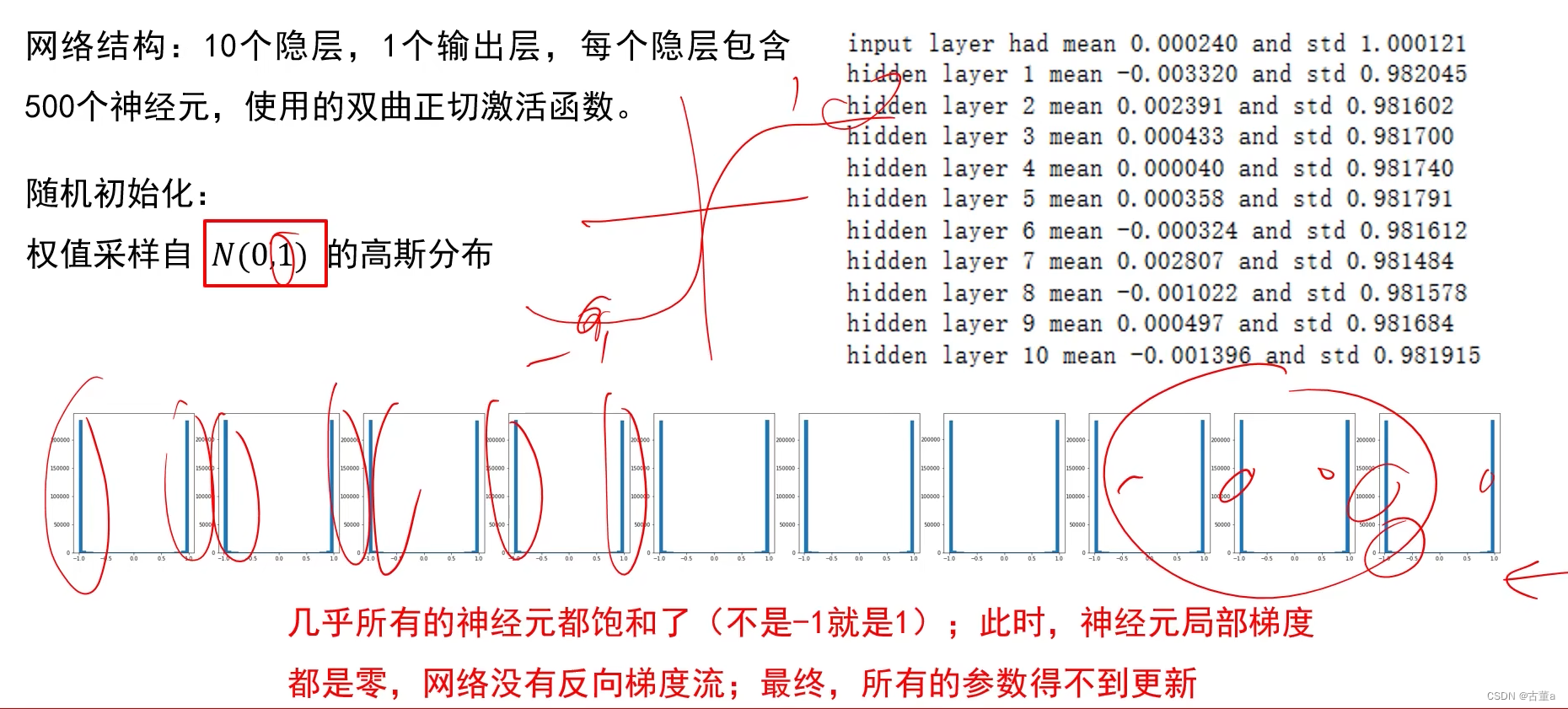
实验结论:初始化时让权值不相等,并不能保证网络能够正常的被训练。
有效的初始化方法:是网络各层的激活值和局部梯度的方差在传播过程中尽量保持一致;以保证网络中正向和反向数据流动。
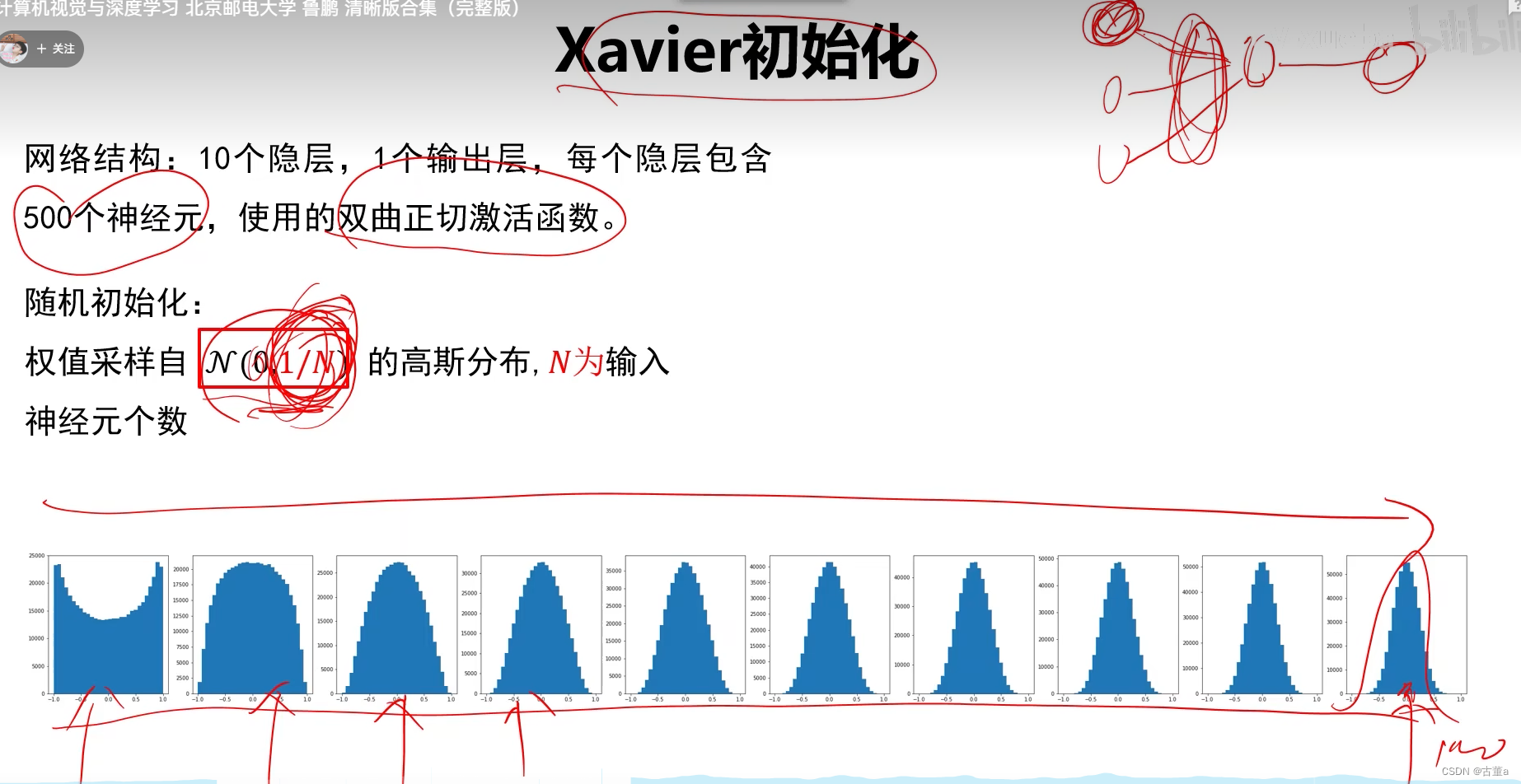
Xavier初始化
Xavier初始化是一种用于初始化神经网络权重的方法,旨在使网络的前向传播时保持信号的方差不变。该方法根据每一层的输入和输出神经元的数量来确定权重的初始范围。
目标
使网络各层的激活值和局部梯度的方差在传播过程中保持一致,即寻找w的分布使得输出y与输入z的方差一致

为什么输入和输出分布会变得不同?
因为输入在经过隐藏层时发生衰变。
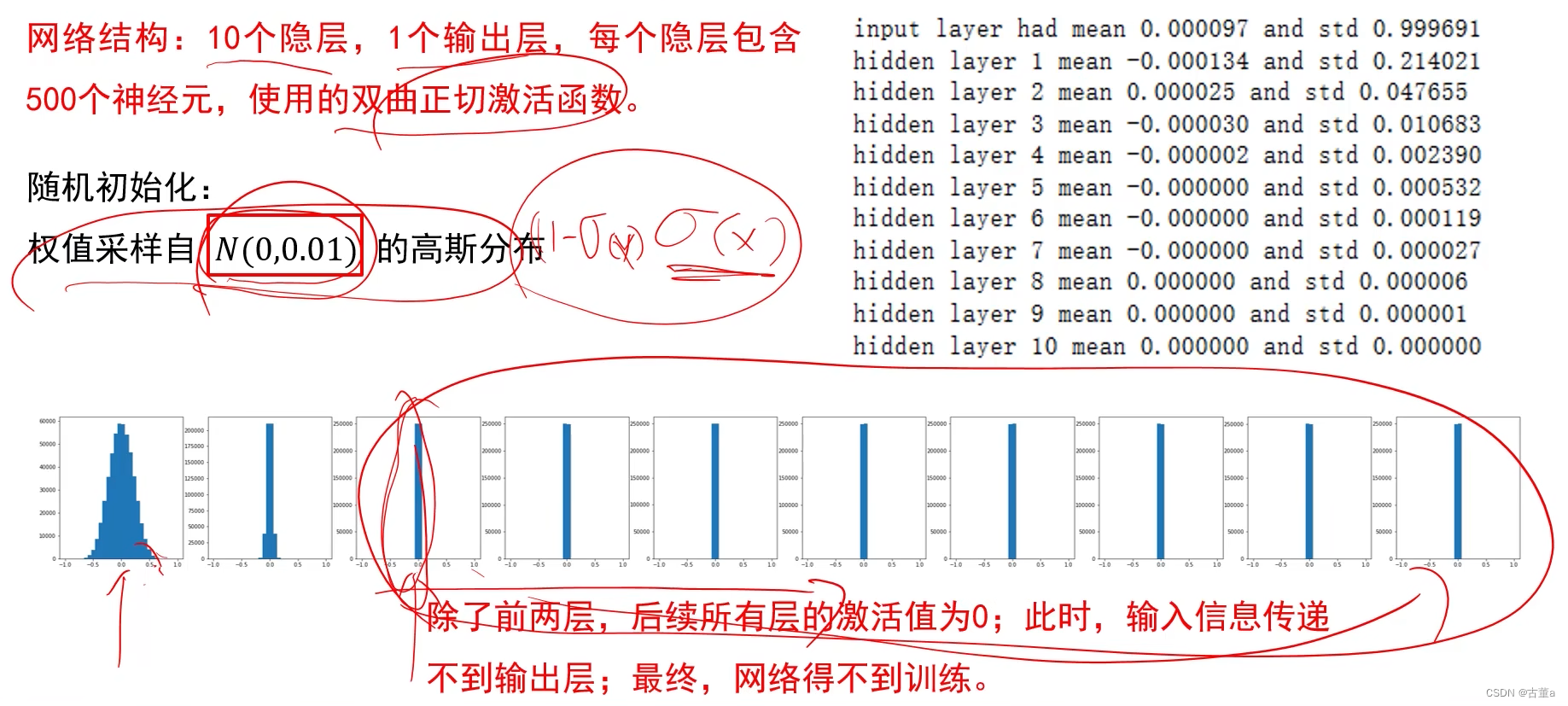
Xavier在使用Tanh时的表现好
Xavier在使用ReLU时的表现不好
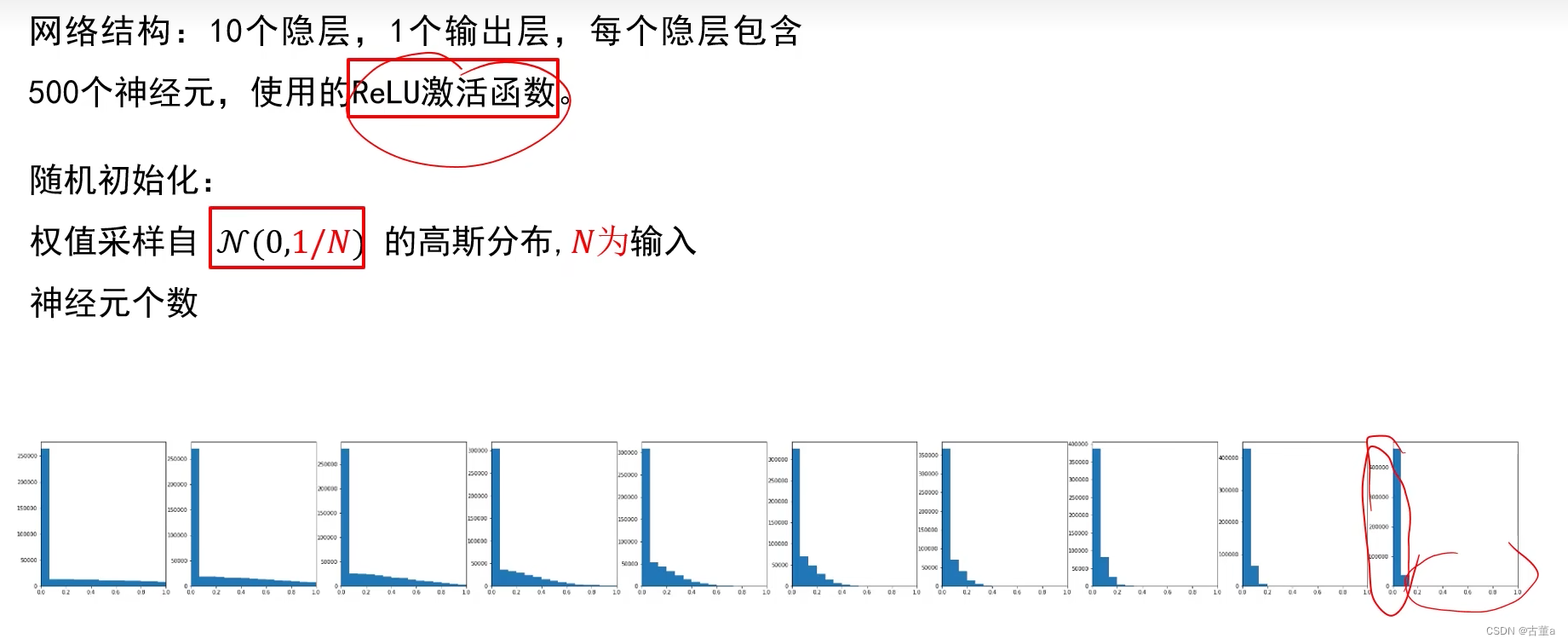
在多次迭代后结果集中在0附近
HE初始化(MSRA)
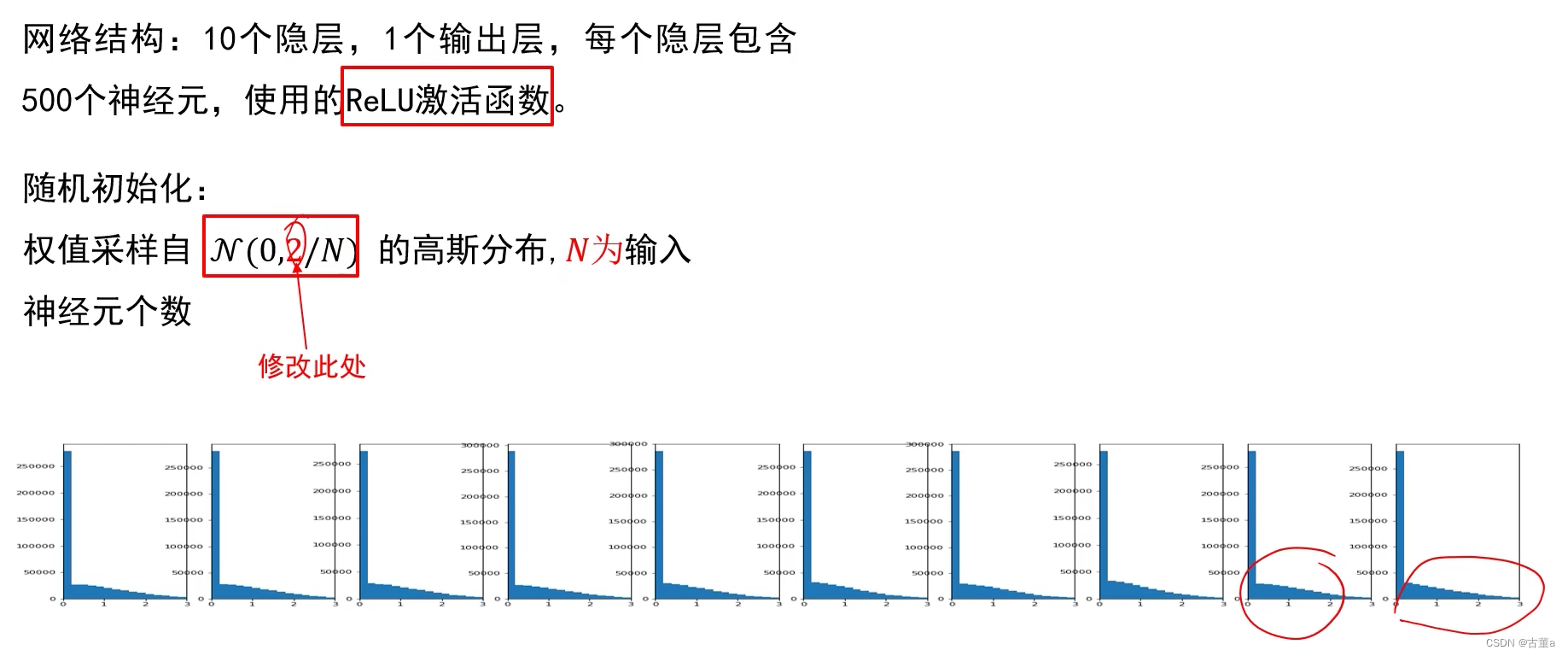
适用于ReLU函数
权值初始化总结
- 好的初始化方法可以防止前向传播过程中的信息消失,也可以解决反向传递过程中的梯度消失。
- 激活函数选择双曲正切(ReLU)或者Sigmoid时,建议使用Xaizer初始化方法;
- 激活函数选择ReLY或Leakly ReLU时,推荐使用He初始化方法。