今天有朋友聊起来,机器学习算法繁多,各个算法有各个算法的特点。以及在不同场景下,不同算法模型能够发挥各自的优点。
今天呢,我把常见的、常用的算法模型进行了一个大概的总结。包括其分支以及各分支的优缺点。
涉及到的算法有:
-
回归
-
正则化算法
-
集成算法
-
决策树算法
-
支持向量机
-
降维算法
-
聚类算法
-
贝叶斯算法
-
人工神经网络
-
深度学习
感兴趣的朋友可以点赞、转发起来,让更多的朋友看到。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文文章由粉丝的分享、推荐,面试资料、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
回归
回归算法是一类用于预测连续数值输出的监督学习算法。
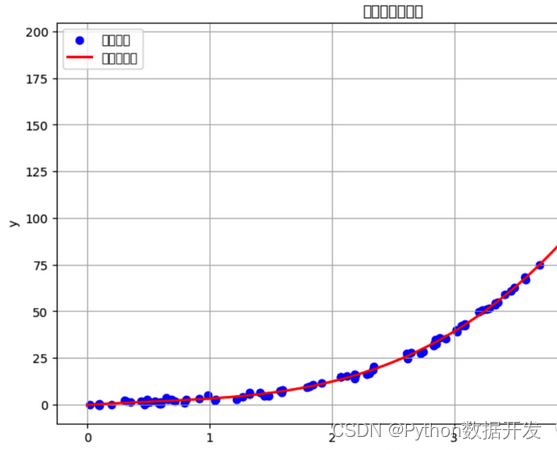
根据输入特征预测一个或多个目标变量。回归算法有多个分支和变种,每个分支都有其独特的优缺点。
1、线性回归(Linear Regression)
-
优点:
-
简单且易于解释。
-
计算效率高,适用于大规模数据集。
-
在特征与目标之间存在线性关系时效果良好。
-
缺点:
-
无法处理非线性关系。
-
对异常值敏感。
-
需要满足线性回归假设(如线性关系、残差正态分布等)。
2、多项式回归(Polynomial Regression)
-
优点:
-
可以捕捉特征和目标之间的非线性关系。
-
相对简单实现。
-
缺点:
-
可能会过度拟合数据,特别是高阶多项式。
-
需要选择适当的多项式阶数。
3、岭回归(Ridge Regression)
-
优点:
-
可以解决多重共线性问题。
-
对异常值不敏感。
-
缺点:
-
不适用于特征选择,所有特征都会被考虑。
-
参数需要调整。
4、Lasso回归(Lasso Regression)
-
优点:
-
可以用于特征选择,趋向于将不重要的特征的系数推到零。
-
可以解决多重共线性问题。
-
缺点:
-
对于高维数据,可能会选择较少的特征。
-
需要调整正则化参数。
5、弹性网络回归(Elastic Net Regression)
-
优点:
-
综合了岭回归和Lasso回归的优点。
-
可以应对多重共线性和特征选择。
-
缺点:
-
需要调整两个正则化参数。
6、逻辑斯蒂回归(Logistic Regression):
-
优点:
-
用于二分类问题,广泛应用于分类任务。
-
输出结果可以解释为概率。
-
缺点:
-
仅适用于二分类问题。
-
对于复杂的非线性问题效果可能不佳。
7、决策树回归(Decision Tree Regression)
-
优点:
-
能够处理非线性关系。
-
不需要对数据进行特征缩放。
-
结果易于可视化和解释。
-
缺点:
-
容易过拟合。
-
对数据中的噪声敏感。
-
不稳定,小的数据变化可能导致不同的树结构。
8、随机森林回归(Random Forest Regression)
-
优点:
-
降低了决策树回归的过拟合风险。
-
能够处理高维数据。
-
缺点:
-
失去了部分可解释性。
-
难以调整模型参数。
在选择回归算法时,需要根据数据的性质以及问题的要求来决定哪种算法最适合。通常,需要进行实验和模型调优来确定最佳的回归模型。
正则化算法
正则化算法是用于降低机器学习模型的过拟合风险的技术。
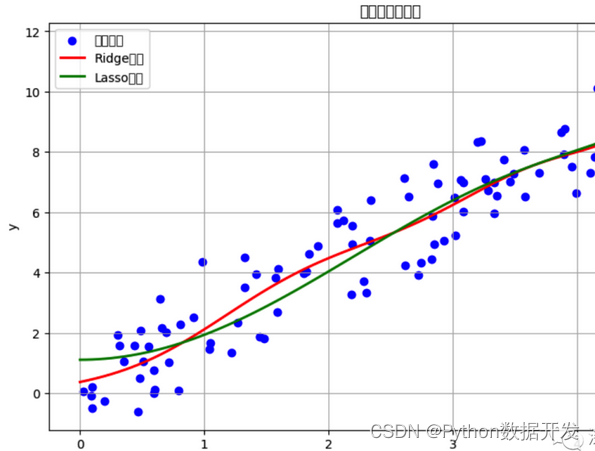
通过在模型的损失函数中引入额外的惩罚项来限制模型参数的大小。正则化有多个分支和变种,以下是一些常见的正则化算法分支以及它们的优缺点:
1、L1 正则化(Lasso 正则化)
-
优点:
-
可以用于特征选择,将不重要的特征的系数推到零。
-
可以解决多重共线性问题。
-
缺点:
-
对于高维数据,可能会选择较少的特征。
-
需要调整正则化参数。
2、L2 正则化(岭正则化)
-
优点:
-
可以解决多重共线性问题。
-
对异常值不敏感。
-
缺点:
-
不适用于特征选择,所有特征都会被考虑。
-
参数需要调整。
3、弹性网络正则化(Elastic Net 正则化)
-
优点:
-
综合了 L1 和 L2 正则化的优点,可以应对多重共线性和特征选择。
-
可以调整两个正则化参数来平衡 L1 和 L2 正则化的影响。
-
缺点:
-
需要调整两个正则化参数。
4、Dropout 正则化(用于神经网络)
-
优点:
-
通过在训练过程中随机禁用神经元,可以减少神经网络的过拟合。
-
不需要额外的参数调整。
-
缺点:
-
在推断时,需要考虑丢失的神经元,增加了计算成本。
-
可能需要更多的训练迭代。
5、贝叶斯Ridge和Lasso回归
-
优点:
-
引入了贝叶斯思想,可以提供参数的不确定性估计。
-
可以自动确定正则化参数。
-
缺点:
-
计算成本较高,尤其是对于大型数据集。
-
不适用于所有类型的问题。
6、早停法(Early Stopping)
-
优点:
-
可以通过监测验证集上的性能来减少神经网络的过拟合。
-
简单易用,不需要额外的参数调整。
-
缺点:
-
需要精心选择停止训练的时机,过早停止可能导致欠拟合。
7、数据增强
-
优点:
-
通过增加训练数据的多样性,可以降低模型的过拟合风险。
-
适用于图像分类等领域。
-
缺点:
-
增加了训练数据的生成和管理成本。
选择哪种正则化方法通常取决于数据的性质、问题的要求以及算法的复杂性。在实际应用中,通常需要通过实验和调参来确定最合适的正则化策略。
集成算法
集成算法是一种将多个弱学习器(通常是基础模型)组合成一个强学习器的技术。
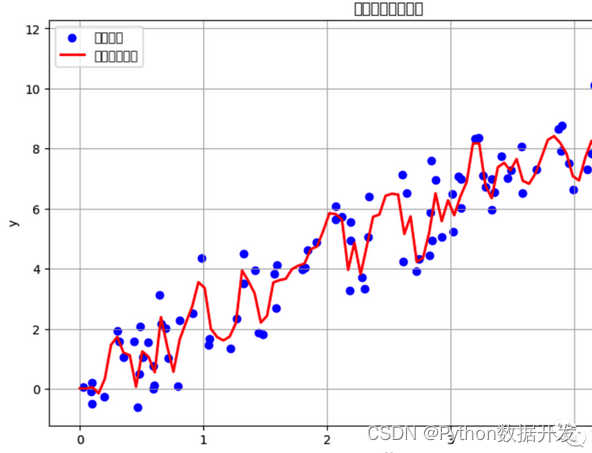
通过结合多个模型的预测,集成算法可以提高模型的性能和鲁棒性。
1、Bagging(Bootstrap Aggregating)
-
优点:
-
降低了模型的方差,减少了过拟合风险。
-
并行化处理,适用于大规模数据。
-
缺点:
-
不适用于处理高度偏斜的类别分布。
-
难以解释组合模型的预测结果。
2、随机森林(Random Forest)
-
优点:
-
基于 Bagging,降低了方差。
-
能够处理高维数据和大规模特征。
-
提供特征重要性评估。
-
缺点:
-
难以调整大量的超参数。
-
对噪声和异常值敏感。
3、Boosting
-
优点:
-
增强了模型的准确性。
-
能够自动调整弱学习器的权重。
-
适用于不平衡类别分布。
-
缺点:
-
对噪声数据敏感。
-
训练时间可能较长。
-
AdaBoost(自适应Boosting):
-
优点:能够处理高维数据和大规模特征,对异常值敏感性较低。
-
缺点:对噪声和异常值敏感。
-
Gradient Boosting(梯度提升):
-
优点:提供了很高的预测性能,对噪声和异常值相对较稳定。
-
缺点:需要调整多个超参数。
-
XGBoost(极端梯度提升)和LightGBM(轻量级梯度提升机):都是梯度提升算法的变种,具有高效性和可扩展性。
4、Stacking
-
优点:
-
可以组合多个不同类型的模型。
-
提供更高的预测性能。
-
缺点:
-
需要更多的计算资源和数据。
-
复杂性较高,超参数的调整较困难。
5、Voting(投票)
-
优点:
-
简单易用,易于实现。
-
能够组合多个不同类型的模型。
-
缺点:
-
对于弱学习器的性能要求较高。
-
不考虑各个模型的权重。
6、深度学习集成
-
优点:
-
可以利用神经网络模型的强大表示能力。
-
提供了各种集成方法,如投票、堆叠等。
-
缺点:
-
训练时间长,需要大量的计算资源。
-
超参数调整更加复杂。
选择合适的集成算法通常取决于数据的性质、问题的要求以及计算资源的可用性。在实际应用中,通常需要进行实验和模型调优,以确定最适合特定问题的集成方法。
决策树算法
决策树算法是一种基于树状结构的监督学习算法,用于分类和回归任务。
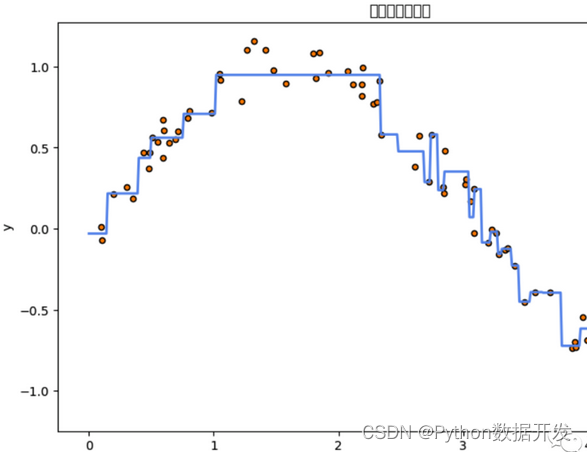
它通过一系列的分割来建立一个树形结构,每个内部节点表示一个特征测试,每个叶节点表示一个类别或数值输出。
1、ID3 (Iterative Dichotomiser 3)
-
优点:
-
简单易懂,生成的树易于解释。
-
能够处理分类任务。
-
缺点:
-
对数值属性和缺失值的处理有限。
-
容易过拟合,生成的树可能很深。
2、C4.5
-
优点:
-
可以处理分类和回归任务。
-
能够处理数值属性和缺失值。
-
在生成树时使用信息增益进行特征选择,更健壮。
-
缺点:
-
对噪声和异常值敏感。
-
生成的树可能过于复杂,需要剪枝来降低过拟合风险。
3、CART (Classification and Regression Trees)
-
优点:
-
可以处理分类和回归任务。
-
对数值属性和缺失值有很好的支持。
-
使用基尼不纯度或均方误差进行特征选择,更灵活。
-
缺点:
-
生成的树可能较深,需要剪枝来避免过拟合。
4、随机森林(Random Forest)
-
优点:
-
基于决策树,降低了决策树的过拟合风险。
-
能够处理高维数据和大规模特征。
-
提供特征重要性评估。
-
缺点:
-
难以调整大量的超参数。
-
对噪声和异常值敏感。
5、梯度提升树(Gradient Boosting Trees)
-
优点:
-
提供了很高的预测性能,对噪声和异常值相对较稳定。
-
适用于回归和分类任务。
-
可以使用不同的损失函数。
-
缺点:
-
需要调整多个超参数。
-
训练时间可能较长。
6、XGBoost(极端梯度提升)和LightGBM(轻量级梯度提升机)
- 这些是梯度提升树的高效实现,具有高度可扩展性和性能。
7、多输出树(Multi-output Trees)
-
优点:
-
能够处理多输出(多目标)问题。
-
可以预测多个相关的目标变量。
-
缺点:
-
需要大量的数据来训练有效的多输出树。
选择合适的决策树算法通常取决于数据的性质、问题的要求以及模型的复杂性。在实际应用中,通常需要通过实验和模型调优来确定最合适的决策树算法。决策树算法的优点之一是它们产生的模型易于可视化和解释。
支持向量机
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,用于分类和回归任务。
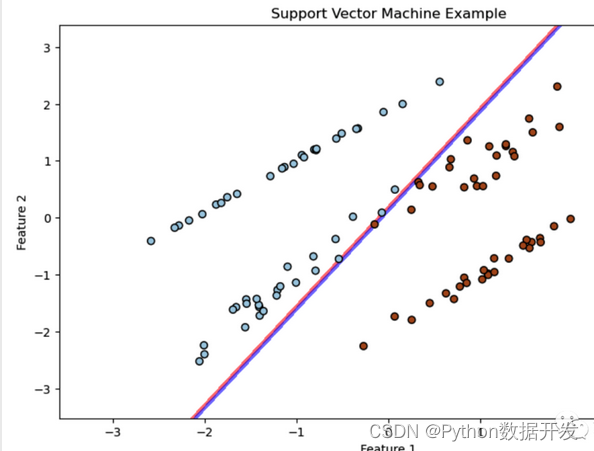
通过找到最佳的超平面来将数据分隔成不同的类别或拟合回归函数。
1、线性支持向量机
-
优点:
-
在高维空间中有效,适用于高维数据。
-
可以通过选择不同的核函数扩展到非线性问题。
-
具有较强的泛化能力。
-
缺点:
-
对大规模数据集和特征数目敏感。
-
对噪声和异常值敏感。
2、非线性支持向量机
-
优点:
-
可以处理非线性问题。
-
通过选择合适的核函数,可以适应不同类型的数据。
-
缺点:
-
对于复杂的非线性关系,可能需要选择合适的核函数和参数。
-
计算复杂性较高,特别是对于大型数据集。
3、多类别支持向量机
-
优点:
-
可以处理多类别分类问题。
-
常用的方法包括一对一(One-vs-One)和一对多(One-vs-Rest)策略。
-
缺点:
-
在一对一策略中,需要构建多个分类器。
-
在一对多策略中,类别不平衡问题可能出现。
4、核函数支持向量机
-
优点:
-
能够处理非线性问题。
-
通常使用径向基函数(RBF)作为核函数。
-
适用于复杂数据分布。
-
缺点:
-
需要选择适当的核函数和相关参数。
-
对于高维数据,可能存在过拟合风险。
5、稀疏支持向量机
-
优点:
-
引入了稀疏性,只有少数支持向量对模型有贡献。
-
可以提高模型的训练和推断速度。
-
缺点:
-
不适用于所有类型的数据,对于某些数据分布效果可能不佳。
6、核贝叶斯支持向量机
-
优点:
-
结合了核方法和贝叶斯方法,具有概率推断能力。
-
适用于小样本和高维数据。
-
缺点:
-
计算复杂性较高,对于大规模数据集可能不适用。
7、不平衡类别支持向量机
-
优点:
-
专门设计用于处理类别不平衡问题。
-
通过调整类别权重来平衡不同类别的影响。
-
缺点:
-
需要调整权重参数。
-
对于极不平衡的数据集,可能需要其他方法来处理。
选择适当的支持向量机算法通常取决于数据的性质、问题的要求以及计算资源的可用性。SVM通常在小到中等规模的数据集上表现出色,但在大规模数据集上可能需要更多的计算资源。此外,需要注意调整超参数以获得最佳性能。
降维算法
降维算法是一类用于减少数据维度的技术。
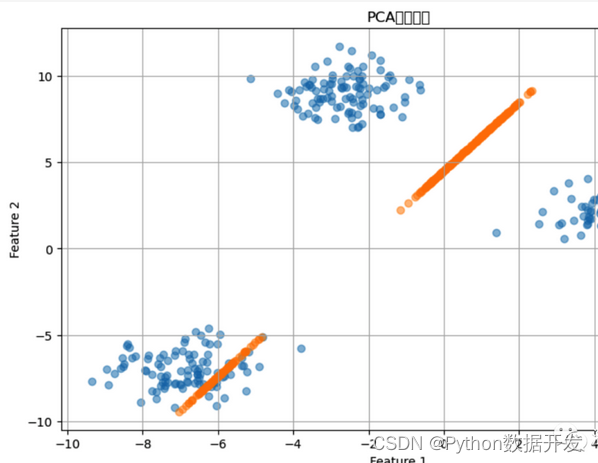
主要目标是在保留数据关键特征的同时减少特征的数量。
1、主成分分析(PCA,Principal Component Analysis)
-
优点:
-
最常用的降维方法之一,易于理解和实现。
-
能够捕捉数据中的主要变化方向。
-
通过线性变换可以减少特征的数量。
-
缺点:
-
对于非线性关系的数据降维效果可能不佳。
-
不考虑类别信息。
2、线性判别分析(LDA,Linear Discriminant Analysis)
-
优点:
-
与PCA相似,但考虑了类别信息,适用于分类问题。
-
可以通过线性变换减少特征的数量并提高分类性能。
-
缺点:
-
对于非线性问题的降维效果可能有限。
-
只适用于分类问题。
3、t-分布随机邻域嵌入(t-SNE,t-Distributed Stochastic Neighbor Embedding)
-
优点:
-
非线性降维方法,能够捕捉数据中的复杂结构。
-
适用于可视化高维数据。
-
缺点:
-
计算复杂度较高,不适用于大规模数据。
-
可能导致不同运行之间的结果不稳定。
4、自编码器(Autoencoder)
-
优点:
-
非线性降维方法,可以学习数据的非线性特征。
-
适用于无监督学习任务。
-
缺点:
-
训练复杂性高,需要大量数据。
-
对于超参数的选择敏感。
5、独立成分分析(ICA,Independent Component Analysis)
-
优点:
-
适用于源信号相互独立的问题,如信号处理。
-
可以用于盲源分离。
-
缺点:
-
对于数据的假设要求较高,需要满足独立性假设。
6、特征选择(Feature Selection)
-
优点:
-
不是降维,而是选择最重要的特征。
-
保留了原始特征的可解释性。
-
缺点:
-
可能丢失了部分信息。
-
需要谨慎选择特征选择方法。
7、核方法降维
-
优点:
-
能够处理非线性数据。
-
通过核技巧将数据映射到高维空间,然后在该空间中进行降维。
-
缺点:
-
计算复杂性高,特别是对于大规模数据。
-
需要谨慎选择核函数。
选择适当的降维方法通常取决于数据的性质、问题的要求以及计算资源的可用性。降维有助于减少数据维度和去除冗余特征,但需要权衡维度减少和信息损失之间的关系。不同的降维方法适用于不同的问题和数据类型。
聚类算法
聚类算法是一类无监督学习算法,用于将数据分组成具有相似性的簇或群体。
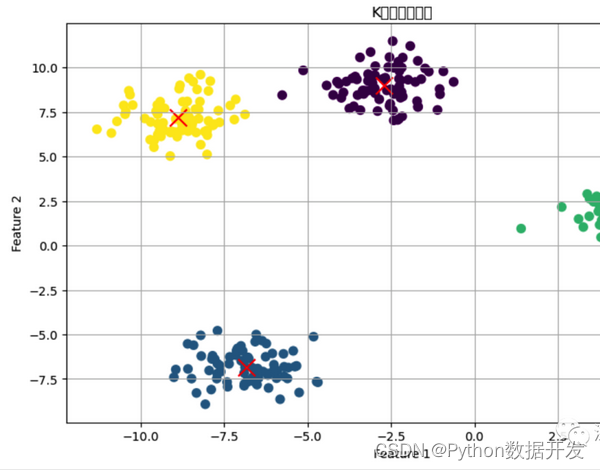
聚类有多个分支和变种,以下是一些常见的聚类算法分支以及它们的优缺点:
1、K均值聚类(K-Means Clustering)
-
优点:
-
简单易懂,容易实现。
-
适用于大规模数据。
-
速度较快,适用于许多应用。
-
缺点:
-
需要预先指定簇的数量K。
-
对初始簇中心的选择敏感。
-
对异常值和噪声敏感。
-
适用于凸形簇。
2、层次聚类(Hierarchical Clustering)
-
优点:
-
不需要预先指定簇的数量。
-
可以生成层次化的簇结构。
-
适用于不规则形状的簇。
-
缺点:
-
计算复杂性较高,不适用于大规模数据。
-
结果的可解释性较差。
3、密度聚类(Density-Based Clustering)
-
优点:
-
能够发现任意形状的簇。
-
对噪声和异常值相对稳健。
-
不需要预先指定簇的数量。
-
缺点:
-
对参数的选择敏感。
-
不适用于数据密度差异很大的情况。
4、谱聚类(Spectral Clustering)
-
优点:
-
能够发现任意形状的簇。
-
适用于不规则形状的簇。
-
不受初始簇中心的选择影响。
-
缺点:
-
计算复杂性较高,对于大规模数据不适用。
-
需要谨慎选择相似度矩阵和簇数。
5、DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
-
优点:
-
能够自动发现任意形状的簇。
-
对噪声和异常值相对稳健。
-
不需要预先指定簇的数量。
-
缺点:
-
对于高维数据,需要特别注意参数的选择。
-
可能在数据密度差异较大时效果不佳。
6、EM聚类(Expectation-Maximization Clustering)
-
优点:
-
适用于混合模型,可以发现概率分布簇。
-
适用于数据有缺失值的情况。
-
缺点:
-
对初始参数的选择敏感。
-
对于高维数据,需要特别注意参数的选择。
7、模糊聚类(Fuzzy Clustering)
-
优点:
-
能够为每个数据点分配到多个簇,考虑数据的不确定性。
-
适用于模糊分类问题。
-
缺点:
-
计算复杂性较高。
-
结果的可解释性较差。
选择适当的聚类方法通常取决于数据的性质、问题的要求以及计算资源的可用性。聚类算法可以用于数据探索、模式发现、异常检测等多种应用,但需要根据具体情况进行选择和调整。
贝叶斯算法
贝叶斯算法是一类基于贝叶斯定理的统计方法,用于处理不确定性和概率推断。它有多个分支和变种,以下是一些常见的贝叶斯算法分支以及它们的优缺点:
1、朴素贝叶斯(Naive Bayes)
-
优点:
-
简单、易于理解和实现。
-
在小规模数据和高维数据上表现良好。
-
可用于分类和文本分类等任务。
-
缺点:
-
基于强烈的特征独立性假设,可能不适用于复杂关联的数据。
-
对于不平衡数据和噪声数据敏感。
2、贝叶斯网络(Bayesian Networks)
-
优点:
-
能够表示和推断复杂的概率关系和依赖关系。
-
支持处理不完整数据和缺失数据。
-
适用于领域建模和决策支持系统。
-
缺点:
-
模型结构的学习和参数估计可能很复杂。
-
对于大规模数据和高维数据,计算成本可能较高。
3、高斯过程(Gaussian Processes)
-
优点:
-
能够建模非线性关系和不确定性。
-
提供了置信区间估计。
-
适用于回归和分类任务。
-
缺点:
-
计算复杂性较高,不适用于大规模数据。
-
需要选择合适的核函数和超参数。
4、贝叶斯优化(Bayesian Optimization)
-
优点:
-
用于优化黑盒函数,例如超参数调优。
-
能够在少量迭代中找到最优解。
-
适用于复杂、昂贵的优化问题。
-
缺点:
-
计算成本相对较高。
-
需要谨慎选择先验和采样策略。
5、变分贝叶斯(Variational Bayesian Methods)
-
优点:
-
用于概率模型的参数估计和推断。
-
可以用于处理大规模数据集。
-
提供了一种近似推断的框架。
-
缺点:
-
近似推断可能会引入估计误差。
-
模型选择和参数选择需要谨慎。
6、贝叶斯深度学习(Bayesian Deep Learning)
-
优点:
-
结合了深度学习和贝叶斯方法,提供了不确定性估计。
-
适用于小样本学习和模型不确定性建模。
-
缺点:
-
计算复杂性较高,训练时间长。
-
超参数调整复杂。
贝叶斯方法在处理不确定性、概率建模、优化和模式识别等方面具有广泛的应用,但不同的分支适用于不同类型的问题和数据。选择适当的贝叶斯方法通常取决于问题的要求和计算资源的可用性。
人工神经网络
人工神经网络(Artificial Neural Networks,ANNs)是受到人类大脑结构启发而设计的机器学习模型。
用于处理各种任务,包括分类、回归、图像处理和自然语言处理等。
1、前馈神经网络(Feedforward Neural Networks,FNNs)
-
优点:
-
适用于各种任务,包括分类和回归。
-
具有很强的表示能力,可以捕捉复杂的非线性关系。
-
针对深度学习问题提供了基础。
-
缺点:
-
对于小样本数据,容易出现过拟合。
-
需要大量的标记数据进行训练。
2、卷积神经网络(Convolutional Neural Networks,CNNs)
-
优点:
-
专门用于图像处理和计算机视觉任务。
-
通过卷积层有效捕捉图像中的局部特征。
-
具有平移不变性。
-
缺点:
-
需要大规模的标记图像数据进行训练。
-
在其他领域的任务上性能可能不如前馈神经网络。
3、循环神经网络(Recurrent Neural Networks,RNNs)
-
优点:
-
适用于序列数据,如自然语言处理和时间序列分析。
-
具有循环连接,可以处理不定长的序列数据。
-
具有记忆能力,可以捕捉时间依赖性。
-
缺点:
-
梯度消失问题,导致长序列的性能下降。
-
计算复杂性较高,不适用于大规模数据和深度网络。
4、长短时记忆网络(Long Short-Term Memory,LSTM)
-
优点:
-
解决了RNN的梯度消失问题。
-
适用于长序列的建模。
-
在自然语言处理等领域取得了显著的成功。
-
缺点:
-
计算复杂性较高。
-
需要大量的数据来训练深层LSTM网络。
5、门控循环单元(Gated Recurrent Unit,GRU)
-
优点:
-
类似于LSTM,但参数较少,计算复杂性较低。
-
在某些任务上性能与LSTM相媲美。
-
缺点:
-
对于某些复杂任务,性能可能不如LSTM。
6、自注意力模型(Transformer)
-
优点:
-
适用于自然语言处理和序列建模等任务。
-
可并行化,计算效率高。
-
在大规模数据和深度模型上表现出色。
-
缺点:
-
需要大规模的数据来训练。
-
相对较新的模型,可能不适用于所有任务。
7、生成对抗网络(Generative Adversarial Networks,GANs)
-
优点:
-
用于生成数据和图像,以及进行无监督学习。
-
生成高质量的样本。
-
在图像生成、风格迁移等领域取得了显著的成功。
-
缺点:
-
训练复杂性高,稳定性差,需要谨慎调整超参数。
-
对于某些任务,可能存在模式崩溃问题。
选择适当的神经网络架构通常取决于问题的性质、数据类型和计算资源的可用性。神经网络在各种领域取得了显著的成功,但在训练和调优方面也存在挑战。
深度学习
深度学习是机器学习的一个分支,以深层神经网络为基础,用于解决各种复杂任务。
1、卷积神经网络(Convolutional Neural Networks,CNNs)
-
优点:
-
用于图像处理和计算机视觉任务,包括图像分类、物体检测和图像分割。
-
通过卷积层有效捕捉图像中的局部特征。
-
具有平移不变性。
-
缺点:
-
需要大规模的标记图像数据进行训练。
-
在其他领域的任务上性能可能不如前馈神经网络。
2、循环神经网络(Recurrent Neural Networks,RNNs)
-
优点:
-
适用于序列数据,如自然语言处理和时间序列分析。
-
具有循环连接,可以处理不定长的序列数据。
-
具有记忆能力,可以捕捉时间依赖性。
-
缺点:
-
梯度消失问题,导致长序列的性能下降。
-
计算复杂性较高,不适用于大规模数据和深度网络。
3、长短时记忆网络(Long Short-Term Memory,LSTM)
-
优点:
-
解决了RNN的梯度消失问题。
-
适用于长序列的建模。
-
在自然语言处理等领域取得了显著的成功。
-
缺点:
-
计算复杂性较高。
-
需要大量的数据来训练深层LSTM网络。
4、门控循环单元(Gated Recurrent Unit,GRU)
-
优点:
-
类似于LSTM,但参数较少,计算复杂性较低。
-
在某些任务上性能与LSTM相媲美。
-
缺点:
-
对于某些复杂任务,性能可能不如LSTM。
5、自注意力模型(Transformer)
-
优点:
-
适用于自然语言处理和序列建模等任务。
-
可并行化,计算效率高。
-
在大规模数据和深度模型上表现出色。
-
缺点:
-
需要大规模的数据来训练。
-
相对较新的模型,可能不适用于所有任务。
6、生成对抗网络(Generative Adversarial Networks,GANs)
-
优点:
-
用于生成数据和图像,以及进行无监督学习。
-
生成高质量的样本。
-
在图像生成、风格迁移等领域取得了显著的成功。
-
缺点:
-
训练复杂性高,稳定性差,需要谨慎调整超参数。
-
对于某些任务,可能存在模式崩溃问题。
7、自编码器(Autoencoder)
-
优点:
-
用于特征学习、降维和去噪。
-
适用于无监督学习任务。
-
缺点:
-
训练复杂性高,需要大量数据。
-
对于超参数的选择敏感。
深度学习在各种领域取得了显著的成功,但训练和调优深度神经网络通常需要大规模的数据和计算资源。选择适当的深度学习算法通常取决于问题的性质、数据类型和计算资源的可用性。深度学习模型的设计和调整是一个复杂的任务,需要谨慎处理。
最后
今天介绍了 算法 的一些核心的优缺点。
另外,更多展现方式以及使用技巧可以从官方文档获取以及实战中领略!
喜欢的朋友可以收藏、点赞、转发起来!