知识图谱搭建最重要的核心在于对业务的理解以及对知识图谱本身的设计,这就类似于对于一个业务系统,数据库表的设计是至关重要的,而这种设计师根据业务及未来场景的变化预估不断探索得出的。
一个完整的知识图谱的构建包含以下几个步骤:
1. 定义业务问题
2. 数据收集 & 预处理
3. 知识图谱设计
4. 知识图谱数据存入
5. 上层应用的开发及系统的评估。
一、定义具体的业务问题
在P2P网贷环境下,最核心的问题是风控,也就是怎么去评估一个借款人的风险。在线上的环境下,欺诈风险尤其为严重,而且很多这种风险隐藏在复杂的关系网络之中,而且知识图谱正好是为这类问题所设计的,所以我们“有可能”期待它能在欺诈,这个问题上带来一些价值。
在进入下一个话题的讨论之前,要明确的一点是,对于自身的业务问题到底需不需要知识图谱系统的支持。因为在很多的实际场景,即使对关系的分析有一定的需求,实际上也可以利用传统数据库来完成分析的。所以为了避免使用知识图谱而选择知识图谱,以及更好的技术选型,以下给出了几点总结,供参考。

白牛数据公司企业下的产品,通过对业务的深入研究,鉴于拥有大数据下的支撑,选择知识图谱来展示多场景多需求的问题,便于客户更迅速准确的定位企业问题。
二、数据收集 & 预处理
下一步就是要确定数据源以及做必要的数据预处理。针对于数据源,我们需要考虑以下几点:1. 我们已经有哪些数据? 2. 虽然现在没有,但有可能拿到哪些数据? 3. 其中哪部分数据可以用来降低风险? 4. 哪部分数据可以用来构建知识图谱?在这里需要说明的一点是,并不是所有跟反欺诈相关的数据都必须要进入知识图谱。
对于反欺诈,有几个数据源是我们很容易想得到的,包括用户的基本信息、行为数据、运营商数据、网络上的公开信息等等。假设我们已经有了一个数据源的列表清单,则下一步就要看哪些数据需要进一步的处理,比如对于非结构化数据我们或多或少都需要用到跟自然语言处理相关的技术。用户填写的基本信息基本上会存储在业务表里,除了个别字段需要进一步处理,很多字段则直接可以用于建模或者添加到知识图谱系统里。对于行为数据来说,我们则需要通过一些简单的处理,并从中提取有效的信息比如“用户在某个页面停留时长”等等。 对于网络上公开的网页数据,则需要一些信息抽取相关的技术。
举个例子,对于用户的基本信息,我们很可能需要如下的操作。一方面,用户信息比如姓名、年龄、学历等字段可以直接从结构化数据库中提取并使用。但另一方面,对于填写的公司名来说,我们有可能需要做进一步的处理。比如部分用户填写“北京京东有限公司”,另外一部分用户填写“北京京东世纪贸易有限公司”,其实指向的都是同一家公司。所以,这时候我们需要做公司名的对齐,用到的技术细节可以参考前面讲到的实体对齐技术。
三、知识图谱的设计
图谱的设计是一门艺术,不仅要对业务有很深的理解、也需要对未来业务可能的变化有一定预估,从而设计出最贴近现状并且性能高效的系统。在知识图谱设计的问题上,我们肯定会面临以下几个常见的问题:1. 需要哪些实体、关系和属性? 2. 哪些属性可以做为实体,哪些实体可以作为属性? 3. 哪些信息不需要放在知识图谱中?
基于这些常见的问题,我们从以往的设计经验中抽象出了一系列的设计原则。这些设计原则就类似于传统数据库设计中的范式,来引导相关人员设计出更合理的知识图谱系统,同时保证系统的高效性。
业务原则(BusinessPrinciple),它的含义是 “一切要从业务逻辑出发,并且通过观察知识图谱的设计也很容易推测其背后业务的逻辑,而且设计时也要想好未来业务可能的变化”。
举个例子,可以观察一下下面这个图谱,并试问自己背后的业务逻辑是什么。通过一番观察,其实也很难看出到底业务流程是什么样的。做个简单的解释,这里的实体-“申请”意思就是application,如果对这个领域有所了解,其实就是进件实体。在下面的图中,申请和电话实体之间的“has_phone”,“parent phone”是什么意思呢?

接下来再看一下下面的图,跟之前的区别在于我们把申请人从原有的属性中抽取出来并设置成了一个单独的实体。在这种情况下,整个业务逻辑就变得很清晰,我们很容易看出张三申请了两个贷款,而且张三拥有两个手机号,在申请其中一个贷款的时候他填写了父母的电话号。总而言之,一个好的设计很容易让人看到业务本身的逻辑。

效率原则(Efficiency Principle)让知识图谱尽量轻量化、并决定哪些数据放在知识图谱,哪些数据不需要放在知识图谱。在经典的计算机存储系统中,我们经常会谈论到内存和硬盘,内存作为高效的访问载体,作为所有程序运行的关键。这种存储上的层次结构设计源于数据的局部性-“locality”,也就是说经常被访问到的数据集中在某一个区块上,所以这部分数据可以放到内存中来提升访问的效率。 类似的逻辑也可以应用到知识图谱的设计上:我们把常用的信息存放在知识图谱中,把那些访问频率不高,对关系分析无关紧要的信息放在传统的关系型数据库当中。 效率原则的核心在于把知识图谱设计成小而轻的存储载体。
比如在下面的知识图谱中,我们完全可以把一些信息比如“年龄”,“家乡”放到传统的关系型数据库当中,因为这些数据对于:a. 分析关系来说没有太多作用 b. 访问频率低,放在知识图谱上反而影响效率。

分析原则(Analytics Principle)中不需要把跟关系分析无关的实体放在图谱当中;
冗余原则(Redundancy Principle)把有些重复性信息、高频信息可以放到传统数据库当中。
四、把数据存入知识图谱
存储上我们要面临存储系统的选择,但由于我们设计的知识图谱带有属性,图数据库可以作为首选。但至于选择哪个图数据库也要看业务量以及对效率的要求。如果数据量特别庞大,则Neo4j很可能满足不了业务的需求,这时候不得不去选择支持准分布式的系统比如OrientDB,JanusGraph等,或者通过效率、冗余原则把信息存放在传统数据库中,从而减少知识图谱所承载的信息量。 通常来讲,对于10亿节点以下规模的图谱来说Neo4j已经足够了。
五、上层应用的开发
构建好知识图谱之后,就要使用它来解决具体的问题。对于风控知识图谱来说,首要任务就是挖掘关系网络中隐藏的欺诈风险。从算法的角度来讲,有两种不同的场景:一种是基于规则的;另一种是基于概率的。鉴于目前AI技术的现状,基于规则的方法论还是在垂直领域的应用中占据主导地位,但随着数据量的增加以及方法论的提升,基于概率的模型也将会逐步带来更大的价值。
1.基于规则的应用
接下来介绍几个基于规则的应用,包括不一致性验证、基于规则的特征提取、基于模式的判断。
不一致性验证:为了判断关系网络中存在的风险,一种简单的方法就是做不一致性验证,也就是通过一些规则去找出潜在的矛盾点。这些规则是以人为的方式提前定义好的,所以在设计规则这个事情上需要一些业务的知识。比如李明和李飞两个人都注明了同样的公司电话,但实际上从数据库中判断这俩人其实在不同的公司上班,这就是一个矛盾点。类似的规则其实可以有很多这里不一一列出。
基于规则提取特征:我们也可以基于规则从知识图谱中提取一些特征,而且这些特征一般基于深度的搜索比如2度,3度甚至更高维度。比如我们可以问一个这样的问题:“申请人二度关系里有多少个实体触碰了黑名单?”,等这些特征被提取之后,一般可以作为风险模型的输入。在此还是想说明一点,如果特征并不涉及深度的关系,其实传统的关系型数据库则足以满足需求。
基于模式的判断:这种方法比较适用于找出团体欺诈,它的核心在于通过一些模式来找到有可能存在风险的团体或者子图(sub-graph),然后对这部分子图做进一步的分析。
2.基于概率的方法
除了基于规则的方法,也可以使用概率统计的方法。 比如社区挖掘、标签传播、聚类等技术都属于这个范畴。
社区挖掘算法的目的在于从图中找出一些社区。对于社区,我们可以有多种定义,但直观上可以理解为社区内节点之间关系的密度要明显大于社区之间的关系密度。由于社区挖掘是基于概率的方法论,好处在于不需要人为地去定义规则,特别是对于一个庞大的关系网络来说,定义规则这事情本身是一件很复杂的事情。
标签传播算法的核心思想在于节点之间信息的传递。这就类似于,跟优秀的人在一起自己也会逐渐地变优秀是一个道理。因为通过这种关系会不断地吸取高质量的信息,最后使得自己也会不知不觉中变得更加优秀。
相比规则的方法论,基于概率的方法的缺点在于:需要足够多的数据。数据量少的话就造成整个图谱比较稀疏(Sparse),所以基于规则的方法可以成为我们的首选。
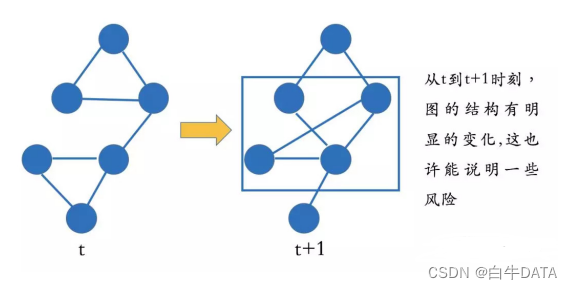
3.基于动态网络的分析
以上所有的分析都是基于静态的关系图谱。所谓的静态关系图谱,意味着我们不考虑图谱结构本身随时间的变化,只是聚焦在当前知识图谱结构上。然而,我们也知道图谱的结构是随时间变化的,而且这些变化本身也可以跟风险有所关联。