⼀、回顾
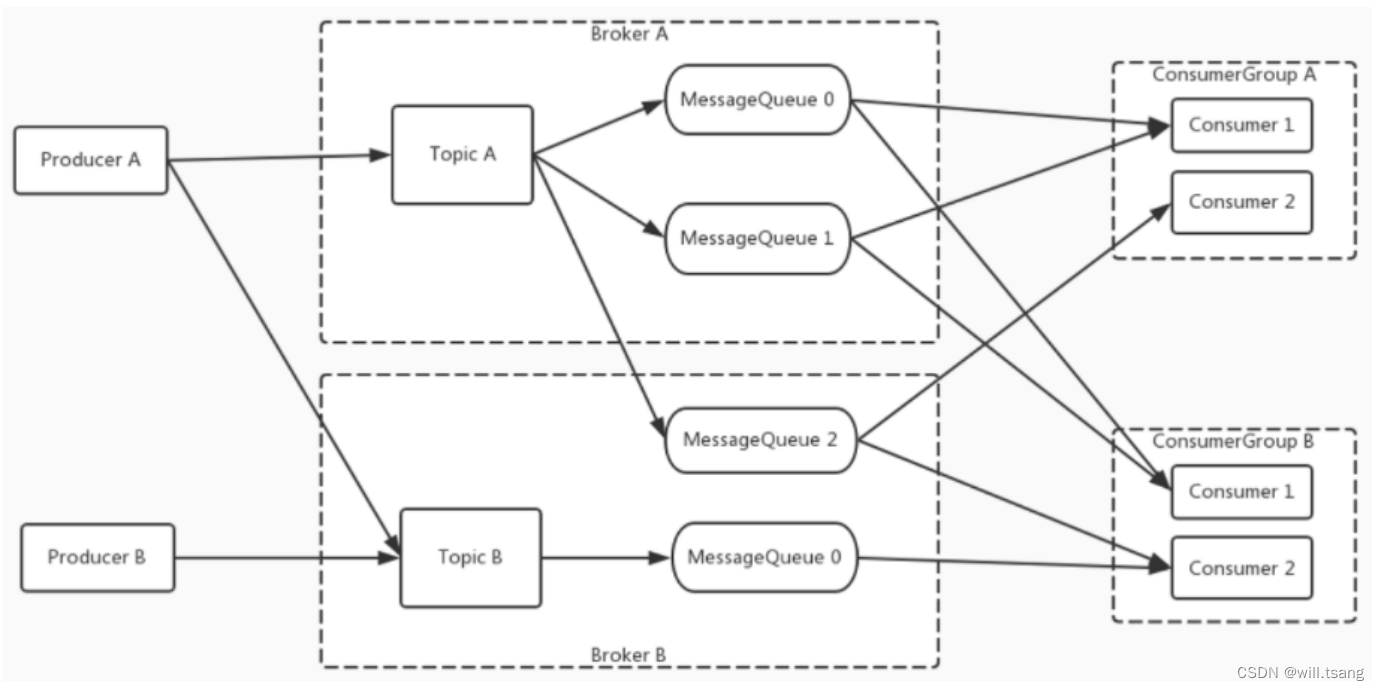
RocketMQ
的消息模型
⼆、深⼊理解
RocketMQ
的消息模型
1
、
RocketMQ
客户端基本流程
RocketMQ
基于
Maven
提供了客户端的核⼼依赖:

使⽤客户端进⾏编程时,添加这⼀个核⼼依赖就够了。 另外还有⼀个与权限控制相关的核⼼依赖也需要了解。尽量保持与服务端版⼀致。

⼀个最为简单的消息⽣产者代码如下:


⼀个简单的消息消费者代码如下:


RocketMQ
的客户端编程模型相对⽐较固定,基本都有⼀个固定的步骤。掌握这个固定步骤,对于学习其他复杂的消息模型也是很有帮助的。
· 消息⽣产者的固定步骤
1.
创建消息⽣产者
producer
,并指定⽣产者组名
2.
指定
Nameserver
地址
3.
启动
producer
。 这个步骤⽐较容易忘记。可以认为这是消息⽣产者与服务端建⽴连接的过程。
4.
创建消息对象,指定主题
Topic
、
Tag
和消息体
5.
发送消息
6.
关闭⽣产者
producer
,释放资源。
· 消息消费者的固定步骤
1.
创建消费者
Consumer
,必须指定消费者组名
2.
指定
Nameserver
地址
3.
订阅主题
Topic
和
Tag
4.
设置回调函数,处理消息
5.
启动消费者
consumer
。消费者会⼀直挂起,持续处理消息。
其中,最为关键的就是
NameServer
。从示例中可以看到,
RocketMQ
的客户端只需要指定
NameServer
地址,⽽不需要指定具体的Broker
地址。
指定
NameServer
的⽅式有两种。可以在客户端直接指定,例如consumer.setNameSrvAddr("127.0.0.1:9876")。然后,也可以通过读取系统环境变量
NAMESRV_ADDR
指定。其中第⼀种⽅式的优先级更⾼。
2
、消息确认机制
RocketMQ
要⽀持互联⽹⾦融场景,那么消息安全是必须优先保障的。⽽消息安全有两⽅⾯的要求,⼀⽅⾯是⽣产者要能确保将消息发送到Broker
上。另⼀⽅⾯是消费者要能确保从
Broker
上争取获取到消息。
1
、消息⽣产端采⽤消息确认加多次重试的机制保证消息正常发送到
RocketMQ
针对消息发送的不确定性,封装了三种发送消息的⽅式。
第⼀种称为单向发送
单向发送⽅式下,消息⽣产者只管往
Broker
发送消息,⽽全然不关⼼
Broker
端有没有成功接收到消息。这就好⽐⽣产者向Broker
发⼀封电⼦邮件,
Broker
有没有处理电⼦邮件,⽣产者并不知道。

sendOneway
⽅法没有返回值,如果发送失败,⽣产者⽆法补救。
单向发送有⼀个好处,就是发送消息的效率更⾼。适⽤于⼀些追求消息发送效率,⽽允许消息丢失的业务场景。⽐如⽇志。
第⼆种称为同步发送
同步发送⽅式下,消息⽣产者在往
Broker
端发送消息后,会阻塞当前线程,等待
Broker
端的相应结果。这就好⽐⽣产者给Broker
打了个电话。通话期间⽣产者就停下⼿头的事情,直到
Broker
明确表示消息处理成功了,⽣产者才继续做其他的事情。

SendResult
来⾃于
Broker
的反馈。
producer
在
send
发出消息,到
Broker
返回
SendResult
的过程中,⽆法做其他的事情。
在
SendResult
中有⼀个
SendStatus
属性,这个
SendStatus
是⼀个枚举类型,其中包含了
Broker
端的各种情况。
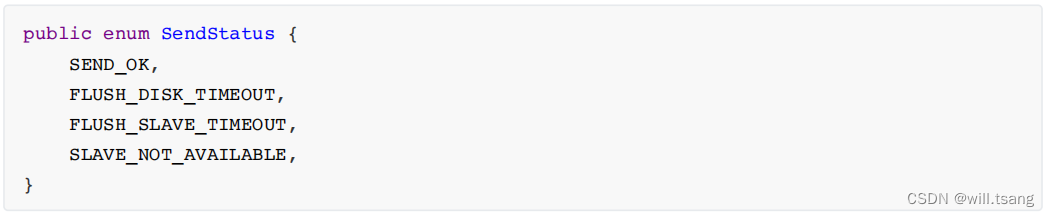
在这⼏种枚举值中,
SEND_OK
表示消息已经成功发送到
Broker
上。⾄于其他⼏种枚举值,都是表示消息在Broker端处理失败了。使⽤同步发送的机制,我们就可以在消息⽣产者发送完消息后,对发送失败的消息进⾏补救。例如重新发送。
但是此时要注意,如果
Broker
端返回的
SendStatus
不是
SEND_OK
,也并不表示消息就⼀定不会推送给下游的消费者。仅仅只是表示Broker
端并没有完全正确的处理这些消息。因此,如果要重新发送消息,最好要带上唯⼀的系统标识,这样在消费者端,才能⾃⾏做幂等判断。也就是⽤具有业务含义的OrderID
这样的字段来判断消息有没有被重复处理。
这种同步发送的机制能够很⼤程度上保证消息发送的安全性。但是,这种同步发送机制的发送效率⽐较低。毕竟,send
⽅法需要消息在⽣产者和
Broker
之间传输⼀个来回后才能结束。如果⽹速⽐较慢,同步发送的耗时就会很⻓。
第三种称为异步发送
异步发送机制下,⽣产者在向
Broker
发送消息时,会同时注册⼀个回调函数。接下来⽣产者并不等待
Broker
的响应。当Broker
端有响应数据过来时,⾃动触发回调函数进⾏对应的处理。这就好⽐⽣产者向
Broker
发电⼦邮件通知时,另外找了⼀个代理⼈专⻔等待Broker
的响应。⽽⽣产者⾃⼰则发完消息后就去做其他的事情去了。

在
SendCallback
接⼝中有两个⽅法,
onSuccess
和
onException
。当
Broker
端返回消息处理成功的响应信息SendResult时,就会调⽤
onSuccess
⽅法。当
Broker
端处理消息超时或者失败时,就会调⽤
onExcetion
⽅法,⽣产者就可以在onException
⽅法中进⾏补救措施。
此时同样有⼏个问题需要注意。⼀是与同步发送机制类似,触发了
SendCallback
的
onException
⽅法同样并不⼀定就表示消息不会向消费者推送。如果Broker
端返回响应信息太慢,超过了超时时间,也会触发
onException
⽅法。超时时间默认是3
秒,可以通过
producer.setSendMsgTimeout
⽅法定制。⽽造成超时的原因则有很多,消息太⼤造成⽹络拥堵、⽹速太慢、Broker
端处理太慢等都可能造成消息处理超时。
⼆是在
SendCallback
的对应⽅法被触发之前,⽣产者不能调⽤
shutdown()
⽅法。如果消息处理完之前,⽣产者线程就关闭了,⽣产者的SendCallback
对应⽅法就不会触发。这是因为使⽤异步发送机制后,⽣产者虽然不⽤阻塞下来等待Broker
端响应,但是
SendCallback
还是需要附属于⽣产者的主线程才能执⾏。如果
Broker
端还没有返回SendResult,⽽⽣产者主线程已经停⽌了,那么
SendCallback
的执⾏线程也就会随主线程⼀起停⽌,对应的⽅法⾃然也就⽆法执⾏了。
这种异步发送的机制能够⽐较好的兼容消息的安全性以及⽣产者的⾼吞吐需求,是很多
MQ
产品都⽀持的⽅式。RabbitMQ和
Kafka
都⽀持这种异步发送的机制。但是异步发送机制也并不是万能的,毕竟异步发送机制对消息⽣产者的主线业务是有侵⼊的。具体使⽤时还是需要根据业务场景考虑。
RocketMQ
提供的这三种发送消息的⽅式,并不存在绝对的好坏之分。我们更多的是需要根据业务场景进⾏选择。例如在电商下单这个场景,我们就应该尽量选择同步发送或异步发送,优先保证数据安全。然后,如果下单场景的并发⽐较⾼,业务⽐较繁忙,就应该尽量优先选择异步发送的机制。这时,我们就应该对下单服务的业务进⾏优化定制,尽量适应异步发送机制的要求。这样就可以尽量保证下单服务能够⽐较可靠的将⽤户的订单消息发送到RocketMQ了。
2
、消息消费者端采⽤状态确认机制保证消费者⼀定能正常处理对应的消息
我们之前分析⽣产者的可靠性问题,核⼼的解决思路就是通过确认
Broker
端的状态来保证⽣产者发送消息的可靠性。对于RocketMQ
的消费者来说,保证消息处理可靠性的思路也是类似的。只不过这次换成了
Broker
等待消费者返回消息处理状态。

这个返回值是⼀个枚举值,有两个选项
CONSUME_SUCCESS
和
RECONSUME_LATER
。如果消费者返回CONSUME_SUCCESS,那么消息⾃然就处理结束了。但是如果消费者没有处理成功,返回的是RECONSUME_LATER,
Broker
就会过⼀段时间再发起消息重试。
为了要兼容重试机制的成功率和性能,
RocketMQ
设计了⼀套⾮常完善的消息重试机制,从⽽尽可能保证消费者能够正常处理⽤户的订单信息。
1
、
Broker
不可能⽆限制的向消费失败的消费者推送消息。如果消费者⼀直没有恢复,
Broker
显然不可能⼀直⽆限制的推送,这会浪费集群很多的性能。所以,Broker
会记录每⼀个消息的重试次数。如果⼀个消息经过很多次重试后,消费者依然⽆法正常处理,那么Broker
会将这个消息推⼊到消费者组对应的死信
Topic
中。死信
Topic
相当于windows当中的垃圾桶。你可以⼈⼯介⼊对死信
Topic
中的消息进⾏补救,也可以直接彻底删除这些消息。
RocketMQ
默认的最⼤重试次数是
16
次。
2
、为了让这些重试的消息不会影响
Topic
下其他正常的消息,
Broker
会给每个消费者组设计对应的重试
Topic
。MessageQueue是⼀个具有严格
FIFO
特性的数据结构。如果需要重试的这些消息还是放在原来的
MessageQueue中,就会对当前MessageQueue
产⽣阻塞,让其他正常的消息⽆法处理。
RocketMQ
的做法是给每个消费者组⾃动⽣成⼀个对应的重试Topic
。在消息需要重试时,会先移动到对应的重试
Topic
中。后续
Broker
只要从这些重试Topic中不断拿出消息,往消费者组重新推送即可。这样,这些重试的消息有了⾃⼰单独的队列,就不会影响到Topic下的其他消息了。
3
、
RocketMQ
中设定的消费者组都是订阅主题和消费逻辑相同的服务备份,所以当消息重试时,
Broker
只要往消费者组中随意⼀个实例推送即可。这是消息重试机制能够正常运⾏的基础。但是,在客户端的具体实现时,MQDefaultMQConsumer并没有强制规定消费者组不能重复。也就是说,你完全可以实现出⼀些订阅主题和消费逻辑完全不同的消费者服务,共同组成⼀个消费组。在这种情况下,RocketMQ
不会报错,但是消息的处理逻辑就⽆法保持⼀致了。这会给业务带来很⼤的麻烦。这是在实际应⽤时需要注意的地⽅。
4
、
Broker
端最终只通过消费者组返回的状态来确定消息有没有处理成功。⾄于消费者组⾃⼰的业务执⾏是否正常,Broker
端是没有办法知道的。因此,在实现消费者的业务逻辑时,应该要尽量使⽤同步实现⽅式,保证在⾃⼰业务处理完成之后再向Broker
端返回状态。⽽应该尽量避免异步的⽅式处理业务逻辑。
3
、消费者也可以⾃⾏指定起始消费位点
Broker
端通过
Consumer
返回的状态来推进所属消费者组对应的
Offset
。但是,这⾥还是会造成⼀种分裂,消息最终是由Consumer
来处理,但是消息却是由
Broker
推送过来的,也就是说,
Consumer
⽆法确定⾃⼰将要处理的是哪些消息。这就好⽐你上班做⼀天事情,公司负责给你发⼀笔⼯资。如果⼀切正常,那么没什么问题。 但是如果出问题了呢?公司拖⽋了你的⼯资,这时,你就还是需要能到公司查账,⾄少查你⾃⼰的⼯资记录。从上⼀次发⼯资的时候计算你该拿的钱。对消息队列也⼀样。虽然
Offset
完全由
Broker
进⾏维护,但是,
RocketMQ
也允许
Consumer
⾃⼰去查账,⾃⼰指定消费位点。核⼼代码是在Consumer
中设定了⼀个属性
ConsumeFromWhere
,表示在
Consumer
启动时,从哪⼀条消息开始进⾏消费。Consumer
当然不可能精确的知道
Offset
的具体参数,所以这个
ConsumerFromWhere并不是直接传⼊Offset
位点,⽽是可以传⼊⼀个
ConsumerFromWhere
对象,这是⼀个枚举值。名字⼀⽬了然。

另外,如果指定了
ConsumerFromWhere.CONSUME_FROM_TIMESTAMP
,这就表示要从⼀个具体的时间开始。具体时间点,需要通过Consumer
的另⼀个属性
ConsumerTimestamp
。这个属性可以传⼊⼀个表示时间的字符串。

到这⾥,我们就从客户端的⻆度分析清楚了要如何保证消息的安全性。但是消息安全问题其实是⼀个⾮常体系化的问题,涉及到的不光是客户端,还需要服务端配合。关于这个问题,我们会在后⾯的分享过程当中继续带你⼀起思考。
3
、⼴播消息
应⽤场景:
⼴播模式和集群模式是
RocketMQ
的消费者端处理消息最基本的两种模式。集群模式下,⼀个消息,只会被⼀个消费者组中的多个消费者实例 共同 处理⼀次。⼴播模式下,⼀个消息,则会推送给所有消费者实例处理,不再关⼼消费者组。
示例代码:
消费者核⼼代码

启动多个消费者,⼴播模式下,这些消费者都会消费⼀次消息。
实现思路:
默认模式
(
也就是集群模式
)
下,
Broker
端会给每个
ConsumerGroup
维护⼀个统⼀的
Offset
,这个
Offset
可以保证⼀个消息,在同⼀个ConsumerGroup
内只会被消费⼀次。⽽⼴播模式的实现⽅式,是将
Offset
转移到消费者端⾃⾏保管,这样Broker
端只管向所有消费者推送消息,⽽不⽤负责维护消费进度。
注意点:
1
、
Broker
端不维护消费进度,意味着,如果消费者处理消息失败了,将⽆法进⾏消息重试。
2
、消费者端维护
Offset
的作⽤是可以在服务重启时,按照上⼀次消费的进度,处理后⾯没有消费过的消息。丢了也不影响服务稳定性。
⽐如⽣产者发送了
1~10
号消息。消费者当消费到第
6
个时宕机了。当他重启时,
Broker
端已经把第
10
个消息都推送完成了。如果消费者端维护好了⾃⼰的Offset
,那么他就可以在服务重启时,重新向
Broker
申请
6
号到
10
号的消息。但是,如果消费者端的Offset
丢失了,消费者服务依然可以正常运⾏,但是
6
到
10
号消息就⽆法再申请了。后续这个消费者就只能获取10
号以后的消息。
实际上,
Offset
的维护数据是放在${user.home}/.rocketmq_offset/${clientIp}${instanceName}/${group}/offsets.json ⽂件下的。
消费者端存储⼴播消费的本地
offsets
⽂件的默认缓存⽬录是
System.getProperty(“user.home”) +
File.separator + “.rocketmq_offsets”
,可以通过定制
rocketmq.client.localOffsetStoreDir
系统属性进⾏修改。
本地
offsets
⽂件在缓存⽬录中的具体位置与消费者的
clientIp
和
instanceName
有关。其中
instanceName
默认是DEFAULT
,可以通过定制系统属性
rocketmq.client.name
进⾏修改。另外,每个消费者对象也可以单独设定instanceName。
RocketMQ
会通过定时任务不断尝试本地
Offsets
⽂件的写⼊,但是,如果本地
Offsets
⽂件写⼊失败,RocketMQ不会进⾏任何的补救。
4
、顺序消息机制
应⽤场景:
每⼀个订单有从下单、锁库存、⽀付、下物流等⼏个业务步骤。每个业务步骤都由⼀个消息⽣产者通知给下游服务。如何保证对每个订单的业务处理顺序不乱?
示例代码:
⽣产者核⼼代码:


通过
MessageSelector
,将
orderId
相同的消息,都转发到同⼀个
MessageQueue
中。
消费者核⼼代码:

注⼊⼀个
MessageListenerOrderly
实现。
实现思路:
基础思路:只有放到⼀起的⼀批消息,才有可能保持消息的顺序。
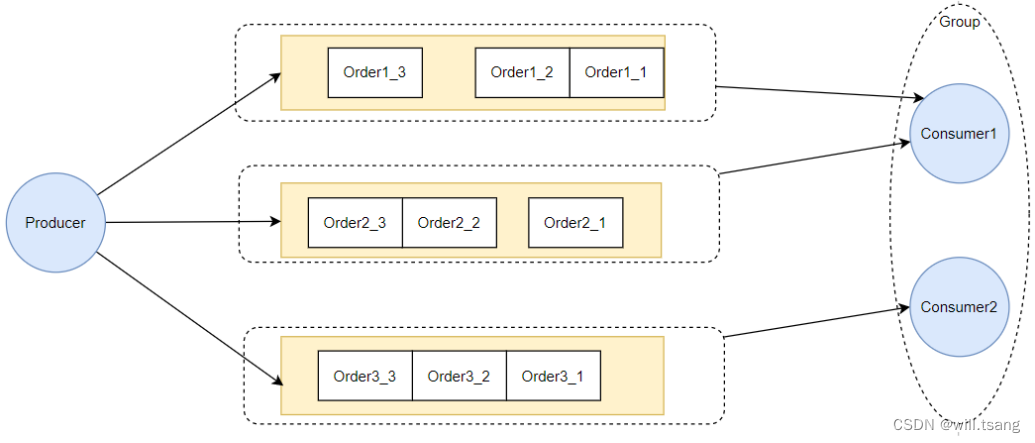
1
、⽣产者只有将⼀批有顺序要求的消息,放到同⼀个
MesasgeQueue
上,
Broker
才有可能保持这⼀批消息的顺序。
2
、消费者只有⼀次锁定⼀个
MessageQueue
,拿到
MessageQueue
上所有的消息,
注意点:
1
、理解局部有序与全局有序。⼤部分业务场景下,我们需要的其实是局部有序。如果要保持全局有序,那就只保留⼀个MessageQueue
。性能显然⾮常低。
2
、⽣产者端尽可能将有序消息打散到不同的
MessageQueue
上,避免过于⼏种导致数据热点竞争。
3
、消费者端只能⽤同步的⽅式处理消息,不要使⽤异步处理。更不能⾃⾏使⽤批量处理。
4
、消费者端只进⾏有限次数的重试。如果⼀条消息处理失败,
RocketMQ
会将后续消息阻塞住,让消费者进⾏重试。但是,如果消费者⼀直处理失败,超过最⼤重试次数,那么RocketMQ
就会跳过这⼀条消息,处理后⾯的消息,这会造成消息乱序。
5
、消费者端如果确实处理逻辑中出现问题,不建议抛出异常,可以返回
ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT
作为替代。
5
、延迟消息
应⽤场景:
延迟消息发送是指消息发送到
Apache RocketMQ
后,并不期望⽴⻢投递这条消息,⽽是延迟⼀定时间后才投递到Consumer
进⾏消费。

示例代码:
⽣产者端核⼼代码:

只要给消息设定⼀个延迟级别就⾏了,⽆⽐简单。
RocketMQ
给消息定制了
18
个默认的延迟级别,分别对应
18
个不同的预设好的延迟时间。

实现思路:
延迟消息的难点其实是性能,需要不断进⾏定时轮训。全部扫描所有消息是不可能的,
RocketMQ
的实现⽅式是预设⼀个系统Topic
,名字叫做
SCHEDULE_TOPIC_XXXX
。在这个
Topic
下,预设
18
个延迟队列。然后每次只针对这18个队列⾥的消息进⾏延迟操作,这样就不⽤⼀直扫描所有的消息了。
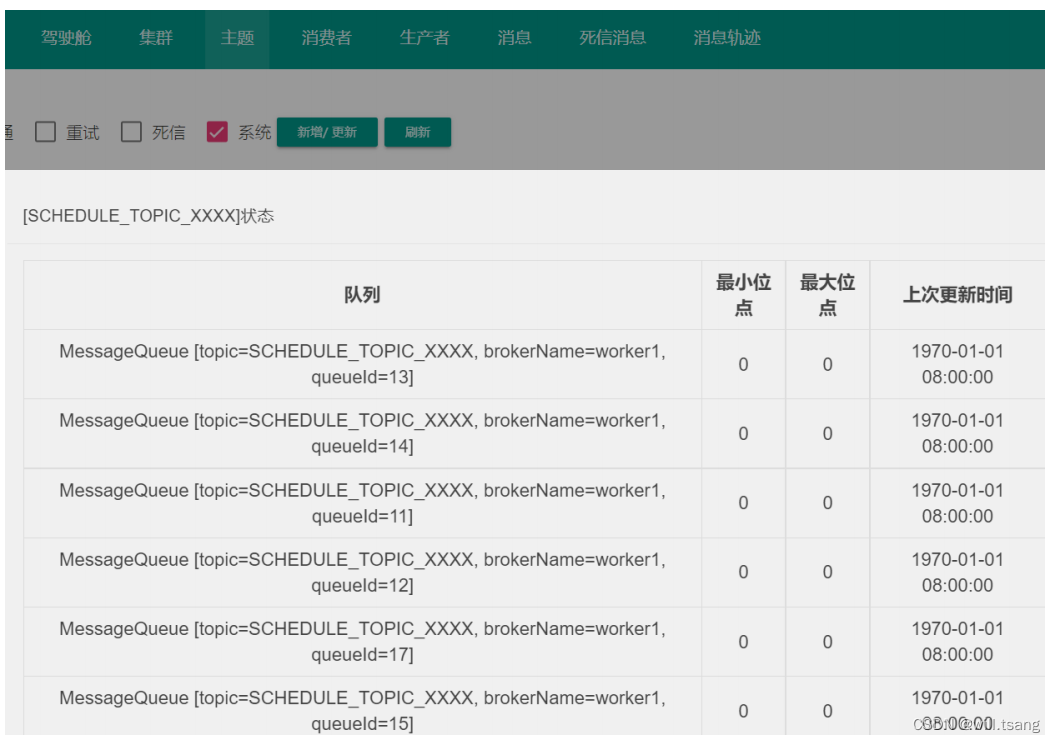
注意点:
这样预设延迟时间其实是不太灵活的。
5.x
版本已经⽀持预设⼀个具体的时间戳,按秒的精度进⾏定时发送。
但是可以看到,这18
个延迟级别虽然⽆法调整,但是每个延迟级别对应的延迟时间其实是可以调整的。只需要修改截图中的参数就⾏。不过通常不建议这么做。
6
、批量消息
应⽤场景:
⽣产者要发送的消息⽐较多时,可以将多条消息合并成⼀个批量消息,⼀次性发送出去。这样可以减少⽹络
IO
,提升消息发送的吞吐量。
示例代码:
⽣产者核⼼代码:

注意点:
批量消息的使⽤⾮常简单,但是要注意
RocketMQ
做了限制。同⼀批消息的
Topic
必须相同,另外,不⽀持延迟消息。
还有批量消息的⼤⼩不要超过
1M
,如果太⼤就需要⾃⾏分割。
7
、过滤消息
应⽤场景:
同⼀个
Topic
下有多种不同的消息,消费者只希望关注某⼀类消息。
例如,某系统中给仓储系统分配⼀个
Topic
,在
Topic
下,会传递过来⼊库、出库等不同的消息,仓储系统的不同业务消费者就需要过滤出⾃⼰感兴趣的消息,进⾏不同的业务操作。

示例代码
1
:简单过滤
⽣产者端需要在发送消息时,增加
Tag
属性。⽐如我们上⾯举例当中的⼊库、出库。核⼼代码:

消费者端就可以通过这个
Tag
属性订阅⾃⼰感兴趣的内容。核⼼代码:

这样,后续
Consumer
就只会出处理
TagA
的消息。
示例代码
2
:
SQL
过滤
通过
Tag
属性,只能进⾏简单的消息匹配。如果要进⾏更复杂的消息过滤,⽐如数字⽐较,模糊匹配等,就需要使⽤SQL
过滤⽅式。
SQL
过滤⽅式可以通过
Tag
属性以及⽤户⾃定义的属性⼀起,以标准
SQL
的⽅式进⾏消息过滤。
⽣产者端在发送消息时,出了
Tag
属性外,还可以增加⾃定义属性。核⼼代码:

消费者端在进⾏过滤时,可以指定⼀个标准的
SQL
语句,定制复杂的过滤规则。核⼼代码:

实现思路:
实际上,
Tags
和⽤户⾃定义的属性,都是随着消息⼀起传递的,所以,消费者端是可以拿到消息的
Tags
和⾃定义属性的。⽐如:

这样,剩下的就是在
Consumer
中对消息进⾏过滤了。
Broker
会在往
Consumer
推送消息时,在
Broker
端进⾏消息过滤。是Consumer
感兴趣的消息,就往
Consumer
推送。
Tag
属性的处理⽐较简单,就是直接匹配。⽽
SQL
语句的处理会⽐较麻烦⼀点。
RocketMQ
也是通过
ANLTR
引擎来解析SQL
语句,然后再进⾏消息过滤的。

注意点:
1
、使⽤
Tag
过滤时,如果希望匹配多个
Tag
,可以使⽤两个竖线
(||)
连接多个
Tag
值。另外,也可以使⽤星号
(*)匹配所有。
2
、使⽤
SQL
顾虑时,
SQL
语句是按照
SQL92
标准来执⾏的。
SQL
语句中⽀持⼀些常⻅的基本操作:
· 数值⽐较,⽐如:
>
,
>=
,
<
,
<=
,
BETWEEN
,
=
;
· 字符⽐较,⽐如:
=
,
<>
,
IN
;
· IS NULL
或者
IS NOT NULL
;
· 逻辑符号
AND
,
OR
,
NOT
;
2
、消息过滤,其实在
Broker
端和在
Consumer
端都可以做。
Consumer
端也可以⾃⾏获取⽤户属性,不感兴趣的消息,直接返回不成功的状态,跳过该消息就⾏了。但是RocketMQ
会在
Broker
端完成过滤条件的判断,只将Consumer感兴趣的消息推送给
Consumer
。这样的好处是减少了不必要的⽹络
IO
,但是缺点是加⼤了服务端的压⼒。不过在RocketMQ
的良好设计下,更建议使⽤消息过滤机制。
3
、
Consumer
不感兴趣的消息并不表示直接丢弃。通常是需要在同⼀个消费者组,定制另外的消费者实例,消费那些剩下的消息。但是,如果⼀直没有另外的Consumer
,那么,
Broker
端还是会推进
Offset
。
8
、事务消息
应⽤场景:
事务消息是
RocketMQ
⾮常有特⾊的⼀个⾼级功能。他的基础诉求是通过
RocketMQ
的事务机制,来保证上下游的数据⼀致性。
以电商为例,⽤户⽀付订单这⼀核⼼操作的同时会涉及到下游物流发货、积分变更、购物⻋状态清空等多个⼦系统的变更。这种场景,⾮常适合使⽤RocketMQ
的解耦功能来进⾏串联。
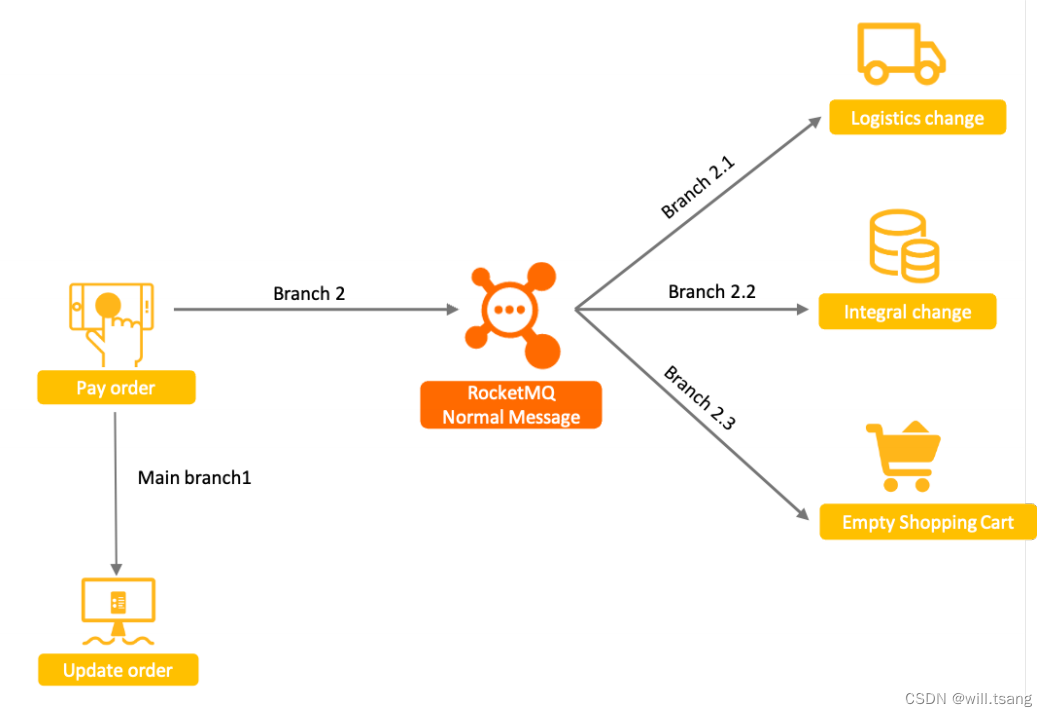
考虑到事务的安全性,即要保证相关联的这⼏个业务⼀定是同时成功或者同时失败的。如果要将四个服务⼀起作为⼀个分布式事务来控制,可以做到,但是会⾮常麻烦。⽽使⽤RocketMQ
在中间串联了之后,事情可以得到⼀定程度的简化。由于RocketMQ
与消费者端有失败重试机制,所以,只要消息成功发送到
RocketMQ
了,那么可以认为Branch2.1
,
Branch2.2
,
Branch2.3
这⼏个分⽀步骤,是可以保证最终的数据⼀致性的。这样,⼀个复杂的分布式事务问题,就变成了MinBranch1
和
Branch2
两个步骤的分布式事务问题。
然后,在此基础上,
RocketMQ
提出了事务消息机制,采⽤两阶段提交的思路,保证
Main Branch1
和
Branch2
之间的事务⼀致性。
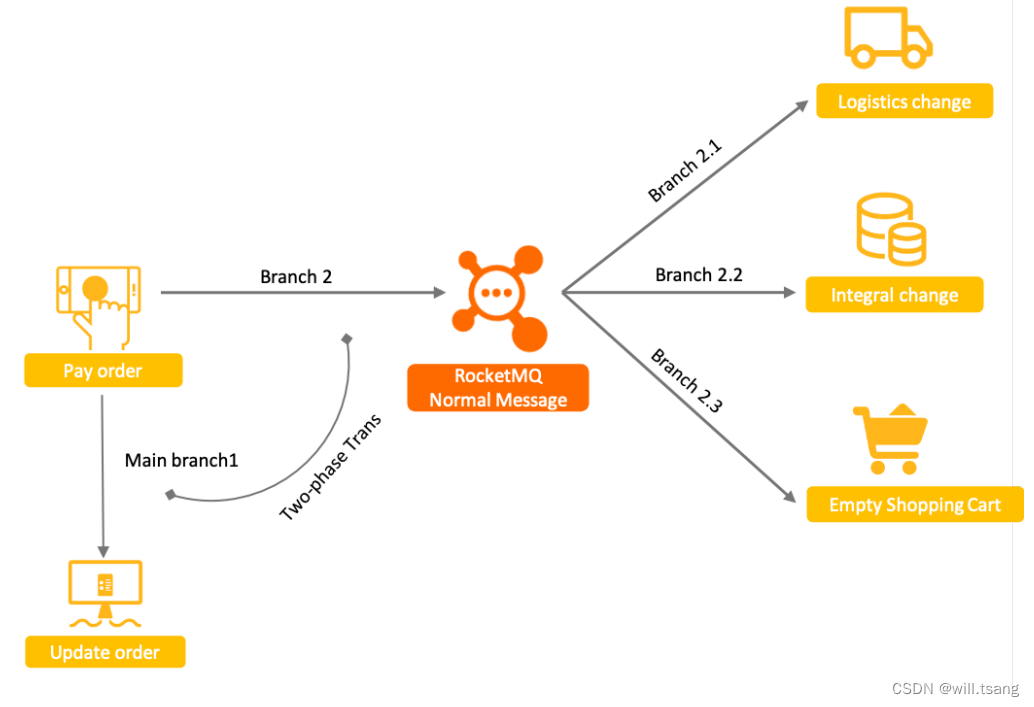
具体的实现思路是这样的:
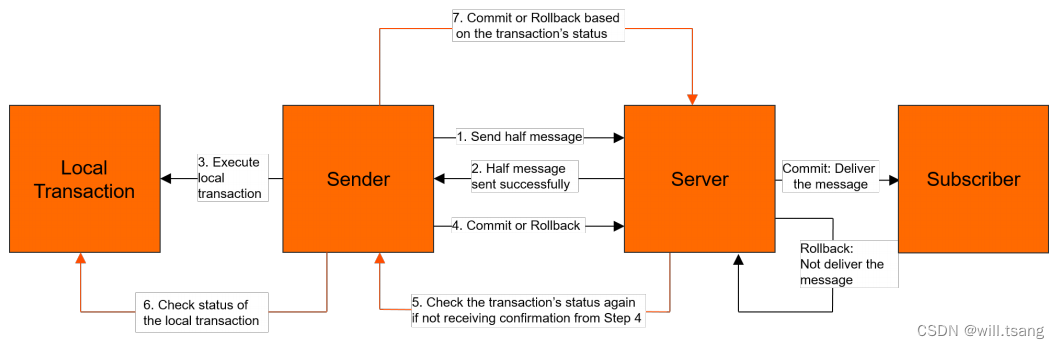
1.
⽣产者将消息发送⾄
Apache RocketMQ
服务端。
2. Apache RocketMQ
服务端将消息持久化成功之后,向⽣产者返回
Ack
确认消息已经发送成功,此时消息被标记为"
暂不能投递
"
,这种状态下的消息即为半事务消息。
3.
⽣产者开始执⾏本地事务逻辑。
4.
⽣产者根据本地事务执⾏结果向服务端提交⼆次确认结果(
Commit
或是
Rollback
),服务端收到确认结果后
处理逻辑如下:
· ⼆次确认结果为
Commit
:服务端将半事务消息标记为可投递,并投递给消费者。
· ⼆次确认结果为
Rollback
:服务端将回滚事务,不会将半事务消息投递给消费者。
5.
在断⽹或者是⽣产者应⽤重启的特殊情况下,若服务端未收到发送者提交的⼆次确认结果,或服务端收到的⼆次确认结果为Unknown
未知状态,经过固定时间后,服务端将对消息⽣产者即⽣产者集群中任⼀⽣产者实例发起消息回查。
6.
⽣产者收到消息回查后,需要检查对应消息的本地事务执⾏的最终结果。
7.
⽣产者根据检查到的本地事务的最终状态再次提交⼆次确认,服务端仍按照步骤
4
对半事务消息进⾏处理。
示例代码:
实现时的重点是使⽤
RocketMQ
提供的
TransactionMQProducer
事务⽣产者,在
TransactionMQProducer
中注⼊⼀个TransactionListener
事务监听器来执⾏本地事务,以及后续对本地事务的检查。
注意点:
1
、半消息是对消费者不可⻅的⼀种消息。实际上,
RocketMQ
的做法是将消息转到了⼀个系统
Topic
,RMQ_SYS_TRANS_HALF_TOPIC。
2
、事务消息中,本地事务回查次数通过参数
transactionCheckMax
设定,默认
15
次。本地事务回查的间隔通过参数transactionCheckInterval
设定,默认
60
秒。超过回查次数后,消息将会被丢弃。
3
、其实,了解了事务消息的机制后,在具体执⾏时,可以对事务流程进⾏适当的调整。
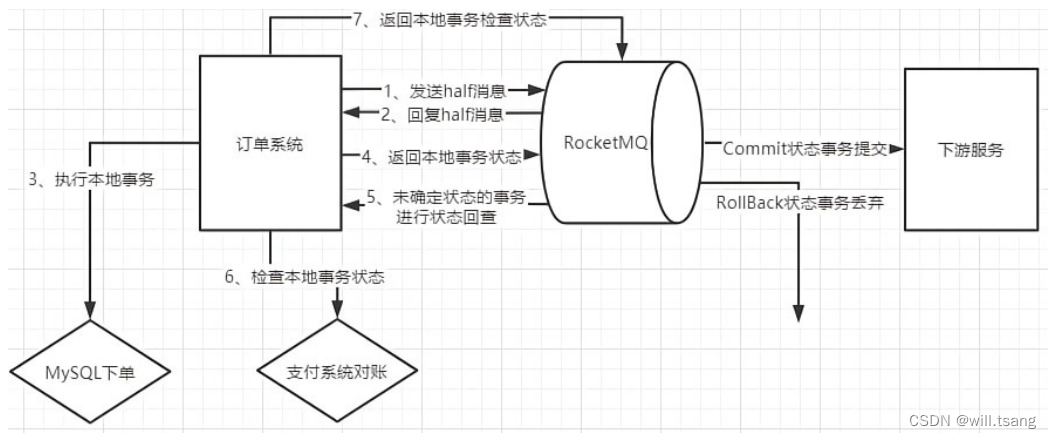
4
、如果你还是感觉不到
RocketMQ
事务消息机制的作⽤,那么可以看看下⾯这个⾯试题:

9
、
ACL
权限控制机制
应⽤场景:
RocketMQ
提供了针对队列、⽤户等不同维度的⾮常全⾯的权限管理机制。通常来说,
RocketMQ
作为⼀个内部服务,是不需要进⾏权限控制的,但是,如果要通过RocketMQ
进⾏跨部⻔甚⾄跨公司的合作,权限控制的重要性就显现出来了。
权限控制体系:
1
、
RocketMQ
针对每个
Topic
,就有完整的权限控制。⽐如,在控制平台中,就可以很⽅便的给每个
Topic
配置权限。
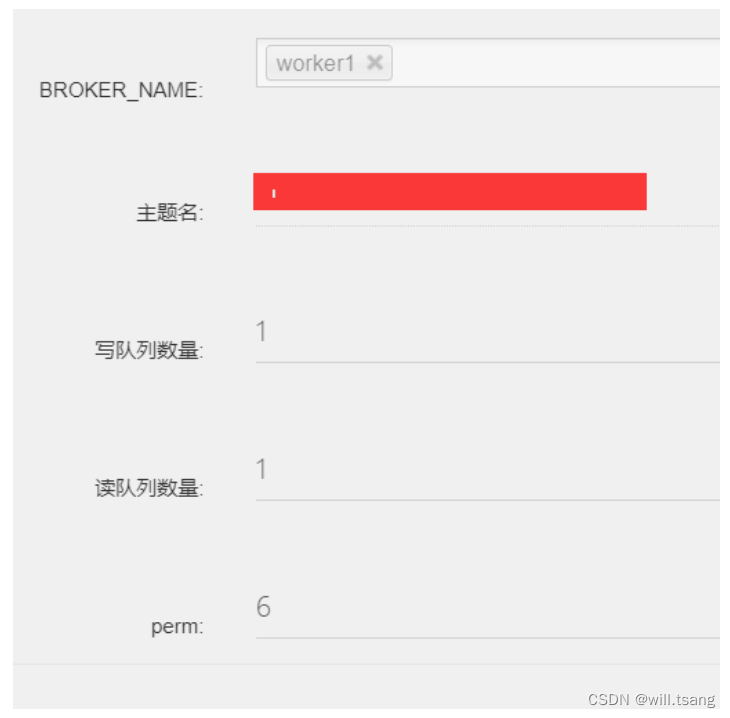
perm
字段表示
Topic
的权限。有三个可选项。
2
:禁写禁订阅,
4
:可订阅,不能写,
6
:可写可订阅
2
、在
Broker
端还提供了更详细的权限控制机制。主要是在
broker.conf
中打开
acl
的标志:
aclEnable=true
。然后就可以⽤他提供的plain_acl.yml
来进⾏权限配置了。并且这个配置⽂件是热加载的,也就是说要修改配置时,只要修改配置⽂件就可以了,不⽤重启Broker
服务。⽂件的配置⽅式,也⾮常简单,⼀⽬了然。

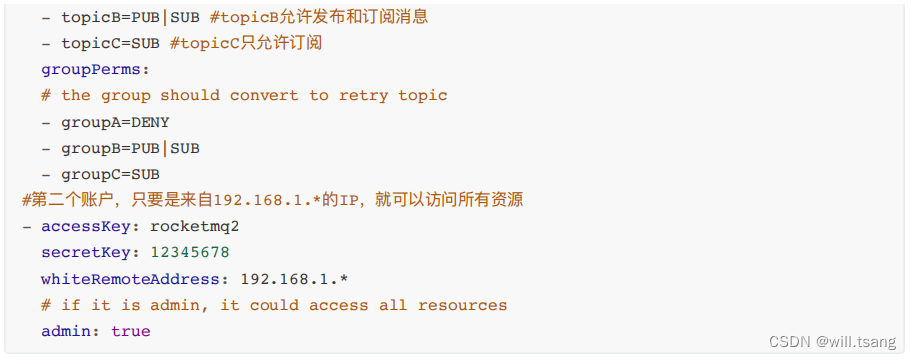
接下来,在客户端就可以通过
accessKey
和
secretKey
提交身份信息了。客户端在使⽤时,需要先引⼊⼀个Maven依赖包。

然后在声明客户端时,传⼊⼀个
RPCHook
。

三、
SpringBoot
整合
RocketMQ
1
、快速实战
按照
SpringBoot
三板斧,快速创建
RocketMQ
的客户端。创建
Maven
⼯程,引⼊关键依赖:


启动类

配置⽂件:

接下来就可以声明⽣产者,直接使⽤
RocketMQTemplate
进⾏消息发送。
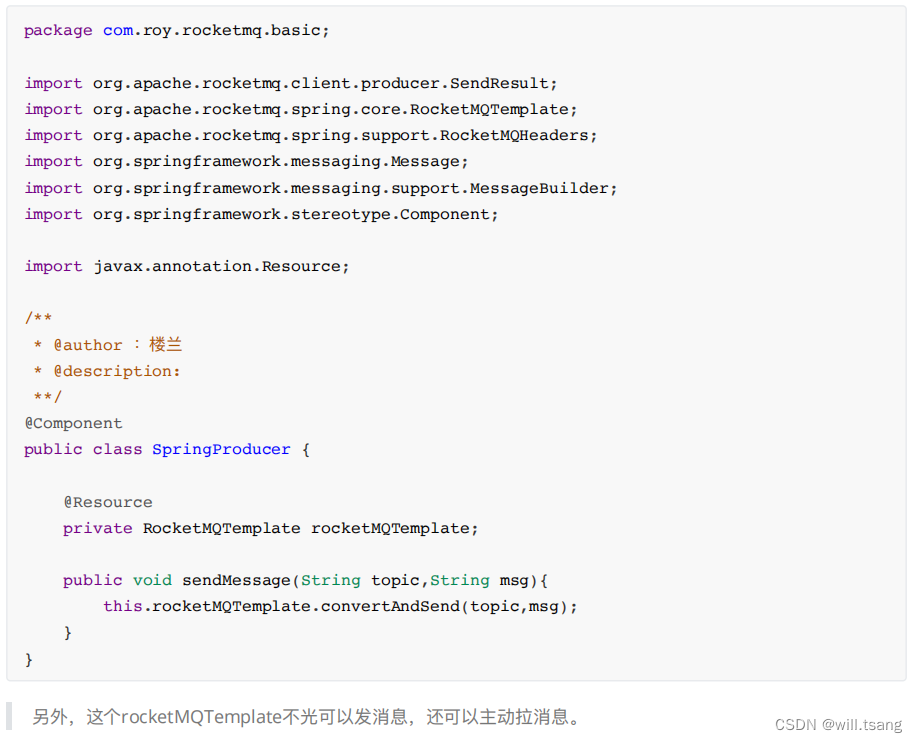
消费者的声明也很简单。所有属性通过
@RocketMQMessageListener
注解声明。

这⾥唯⼀需要注意下的,就是消息了。
SpringBoot
框架中对消息的封装与原⽣
API
的消息封装是不⼀样的。
2
、如何处理各种消息类型
1
、各种基础的消息发送机制参⻅单元测试类:
com.roy.rocketmq.SpringRocketTest
2
、⼀个
RocketMQTemplate
实例只能包含⼀个⽣产者,也就只能往⼀个
Topic
下发送消息。如果需要往另外⼀个Topic
下发送消息,就需要通过
@ExtRocketMQTemplateConfiguration()
注解另外声明⼀个⼦类实例。
3
、对于事务消息机制,最关键的事务监听器需要通过
@RocketMQTransactionListener
注解注⼊到
Spring
容器当中。在这个注解当中可以通过rocketMQTemplateBeanName
属性,指向具体的
RocketMQTemplate
⼦类。
3
、实现原理
1
、
Push
模式
Push
模式对于
@RocketMQMessageListener
注解的处理⽅式,⼊⼝在
rocketmq-spring-boot-2.2.2.jar
中的org.apache.rocketmq.spring.autoconfigure.ListenerContainerConfiguration类中。
这个
ListenerContainerConfiguration
类继承了
Spring
当中的
SmartInitializingSingleton
接⼝,当
Spring
容器当中所有⾮懒加载的实例加载完成后,就会触发他的afterSingletonsInstantiated
⽅法进⾏初始化。在这个⽅法中会去扫描所有带有注解@RocketMQMessageListener
注解的类,将他注册到内部⼀个
Container
容器当中。

这⾥这个
Container
可以认为是客户端实例的⼀个容器,通过这个容器来封装
RocketMQ
的原⽣
API
。
registerContainer
的⽅法挺⻓的,我这⾥截取出跟今天的主题相关的⼏⾏重要的源码:

这其中最关注的,当然是创建容器的
createRocketMQListenerContainer
⽅法中。⽽在这个⽅法中,你基本看不到RocketMQ
的原⽣
API
,都是在创建并维护⼀个
DefaultRocketMQListenerContainer
对象。⽽这个DefaultRocketMQListenerContainer类,就是我们今天关注的重点。
DefaultRocketMQListenerContainer
类实现了
InitializingBean
接⼝,⾃然要先关注他的
afterPropertiesSet
⽅法。这是Spring
提供的对象初始化的扩展机制。

这个⽅法就是⽤来初始化
RocketMQ
消费者的。在这个⽅法⾥就会创建⼀个
RocketMQ
原⽣的
DefaultMQPushConsumer
消费者。同样,⽅法很⻓,抽取出⽐较关注的重点源码。


这整个就是在维护
RocketMQ
的原⽣消费者对象。其中的使⽤⽅式,其实有很多地⽅是很值得借鉴的,尤其是消费监听的处理。
2
、
Pull
模式
Pull
模式的实现其实是通过在
RocketMQTemplate
实例中注⼊⼀个
DefaultLitePullConsumer
实例来实现的。只要注⼊并启动了这个DefaultLitePullConsumer
示例后,后续就可以通过
template
实例的
receive
⽅法,来调⽤DefaultLitePullConsumer的
poll
⽅法,主动去
Pull
获取消息了。
初始化
DefaultLitePullConsumer
的代码依然是在
rocketmq-spring-boot-2.2.2.jar
包中。不过处理类是org.apache.rocketmq.spring.autoconfigure.RocketMQAutoConfiguration。这个配置类会配置在
jar
包中的spring.factories⽂件中,通过
SpringBoot
的⾃动装载机制加载进来。
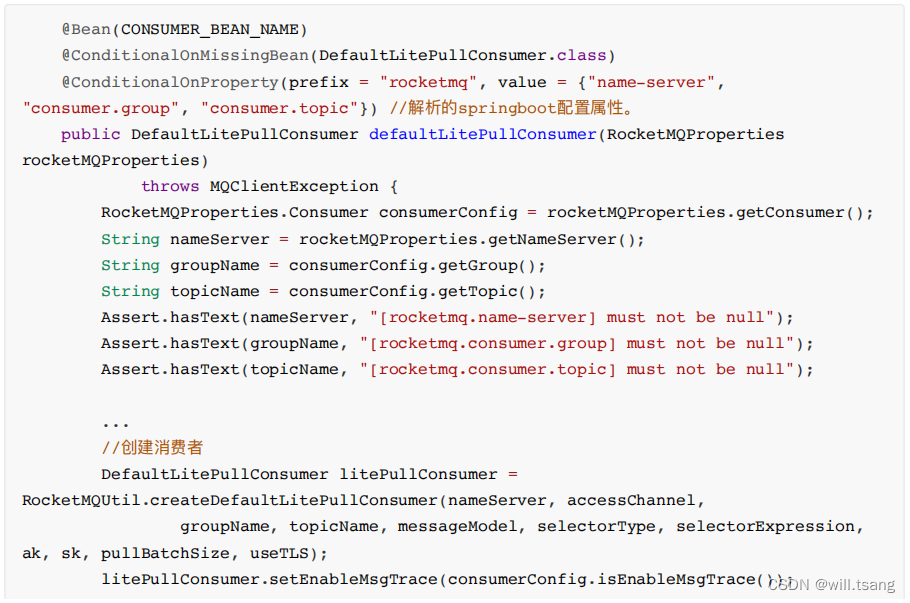

RocketMQUtil.createDefaultLitePullConsumer
⽅法中,就是在维护⼀个
DefaultLitePullConsumer
实例。这个实例就是RocketMQ
的原⽣
API
当中提供的拉模式客户端。

四、
RocketMQ
最佳实践
1
、合理分配
Topic
、
Tag
⼀个应⽤尽可能⽤⼀个
Topic
,⽽消息⼦类型则可以⽤
tags
来标识。
tags
可以由应⽤⾃由设置,只有⽣产者在发送消息设置了tags
,消费⽅在订阅消息时才可以利⽤
tags
通过
broker
做消息过滤:
message.setTags("TagA")
。

2
、使⽤
Key
加快消息索引
分配好
Topic
和
Tag
之后,⾃然就需要优化
Key
属性了,因为
Key
也可以参与消息过滤。通常建议每个消息要分配⼀个在业务层⾯的唯⼀标识码,设置到Key
属性中。这有两个⽅⾯的作⽤:
⼀是可以配合
Tag
进⾏更精确的消息过滤。
另⼀个更重要的⽅⾯是,
RocketMQ
的
Broker
端会为每个消息创建⼀个哈希索引。应⽤可以通过
topic
、
key
来查询某⼀条历史的消息内容,以及消息在集群内的处理情况。在管理控制台就可以看到。为了减少哈希索引潜在的哈希冲突问题,所有官⽅建议,客户端要尽量保证key
的唯⼀性。
3
、关注错误消息重试

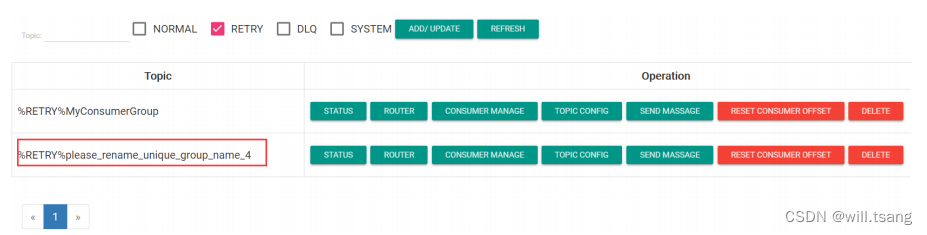
多关注重试队列,可以及时了解消费者端的运⾏情况。这个队列中出现了⼤量的消息,就意味着消费者的运⾏出现了问题,要及时跟踪进⾏⼲预。
然后
RocketMQ
默认允许每条消息最多重试
16
次,每次重试的间隔时间如下:
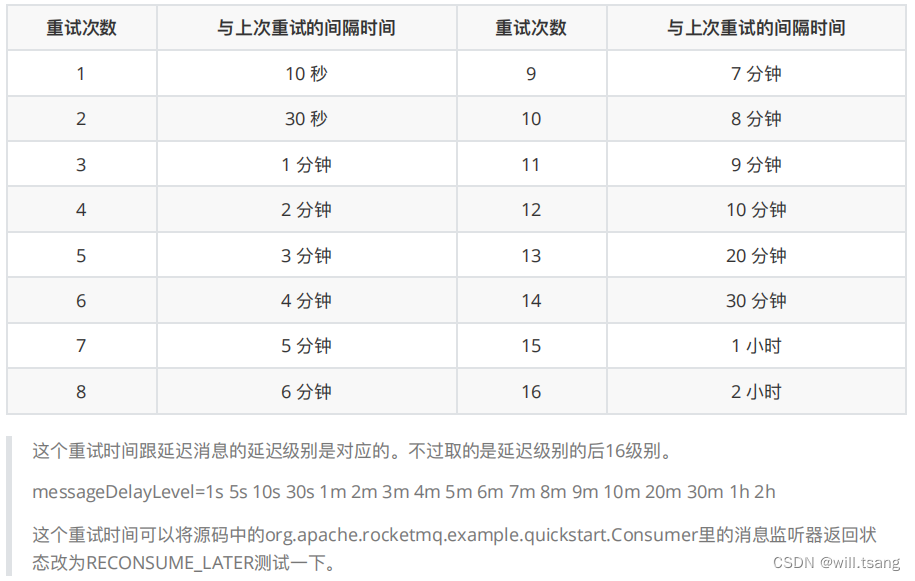
重试次数:
如果消息重试
16
次后仍然失败,消息将不再投递。转为进⼊死信队列。
然后关于这个重试次数,
RocketMQ
可以进⾏定制。例如通过
consumer.setMaxReconsumeTimes(20);
将重试次数设定为20
次。当定制的重试次数超过
16
次后,消息的重试时间间隔均为
2
⼩时。
配置覆盖:
消息最⼤重试次数的设置对相同
GroupID
下的所有
Consumer
实例有效。并且最后启动的
Consumer
会覆盖之前启动的Consumer
的配置。
4
、⼿动处理死信队列
当⼀条消息消费失败,
RocketMQ
就会⾃动进⾏消息重试。⽽如果消息超过最⼤重试次数,
RocketMQ
就会认为这个消息有问题。但是此时,RocketMQ
不会⽴刻将这个有问题的消息丢弃,⽽会将其发送到这个消费者组对应的⼀种特殊队列:死信队列。
通常,⼀条消息进⼊了死信队列,意味着消息在消费处理的过程中出现了⽐较严重的错误,并且⽆法⾃⾏恢复。此时,⼀般需要⼈⼯去查看死信队列中的消息,对错误原因进⾏排查。然后对死信消息进⾏处理,⽐如转发到正常的Topic
重新进⾏消费,或者丢弃。
死信队列的名称是
%DLQ%+ConsumGroup

死信队列的特征:
· ⼀个死信队列对应⼀个
ConsumGroup
,⽽不是对应某个消费者实例。
· 如果⼀个
ConsumeGroup
没有产⽣死信队列,
RocketMQ
就不会为其创建相应的死信队列。
· ⼀个死信队列包含了这个
ConsumeGroup
⾥的所有死信消息,⽽不区分该消息属于哪个
Topic
。
· 死信队列中的消息不会再被消费者正常消费。
· 死信队列的有效期跟正常消息相同。默认
3
天,对应
broker.conf
中的
fileReservedTime
属性。超过这个最⻓时间的消息都会被删除,⽽不管消息是否消费过。

5
、消费者端进⾏幂等控制
在
MQ
系统中,对于消息幂等有三种实现语义:
· at most once
最多⼀次:每条消息最多只会被消费⼀次
· at least once
⾄少⼀次:每条消息⾄少会被消费⼀次
· exactly once
刚刚好⼀次:每条消息都只会确定的消费⼀次
这三种语义都有他适⽤的业务场景。
其中,
at most once
是最好保证的。
RocketMQ
中可以直接⽤异步发送、
sendOneWay
等⽅式就可以保证。
⽽
at least once
这个语义,
RocketMQ
也有同步发送、事务消息等很多⽅式能够保证。
⽽这个
exactly once
是
MQ
中最理想也是最难保证的⼀种语义,需要有⾮常精细的设计才⾏。
RocketMQ
只能保证
at least once,保证不了
exactly once
。所以,使⽤
RocketMQ
时,需要由业务系统⾃⾏保证消息的幂等性。


但是,对于
exactly once
语义,阿⾥云上的商业版
RocketMQ
是明确有
API
⽀持的,⾄于如何实现的,就不得⽽知了。
消息幂等的必要性
在互联⽹应⽤中,尤其在⽹络不稳定的情况下,消息队列
RocketMQ
的消息有可能会出现重复,这个重复简单可以概括为以下情况:
· 发送时消息重复
当⼀条消息已被成功发送到服务端并完成持久化,此时出现了⽹络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时⽣产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且Message ID 也相同的消息。
· 投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候⽹络闪断。 为了保证消息⾄少被消费⼀次,消息队列 RocketMQ
的服务端将在⽹络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID
也相同的消息。
· 负载均衡时消息重复(包括但不限于⽹络抖动、
Broker
重启以及订阅⽅应⽤重启)
当消息队列
RocketMQ
的
Broker
或客户端重启、扩容或缩容时,会触发
Rebalance
,此时消费者可能会收到重复消息。
处理⽅式
从上⾯的分析中,我们知道,在
RocketMQ
中,是⽆法保证每个消息只被投递⼀次的,所以要在业务上⾃⾏来保证消息消费的幂等性。
⽽要处理这个问题,
RocketMQ
的每条消息都有⼀个唯⼀的
MessageId
,这个参数在多次投递的过程中是不会改变的,所以业务上可以⽤这个MessageId
来作为判断幂等的关键依据。
但是,这个
MessageId
是⽆法保证全局唯⼀的,也会有冲突的情况。所以在⼀些对幂等性要求严格的场景,最好是使⽤业务上唯⼀的⼀个标识⽐较靠谱。例如订单ID
。⽽这个业务标识可以使⽤
Message
的
Key
来进⾏传递。










![[MySQL]基本介绍及安装使用详细讲解](https://img-blog.csdnimg.cn/5f58de15a1274d59a75b5ffcab695221.png)