目录
1.数据收集及处理
2.数据提取及可视化
3.逻辑回归训练样本并且测试
4.绘制散点决策边界
逻辑回归的方法已经在数学建模里面讲过了,这里就不多讲了。
本篇我们主要是利用逻辑回归的方法来求解分类问题。
1.数据获取及处理
import pandas as pd
from sklearn.linear_model import LogisticRegression
import numpy as np
# 从Excel读取数据
data = pd.read_excel('classification_data_2.xlsx')
data.head()2.数据提取及可视化
# 提取特征和标签
X = data[['Feature1', 'Feature2']].values
y = data['Label'].values
#绘制X的可视化图片
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
X1=X[0:,0]
X2=X[0:,1]
#绘制可视化图片
plt.scatter(X1,X2,s=25)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("数据特征散点分布图")
plt.savefig(".\数据特征散点分布图.png",dpi=500)
plt.show()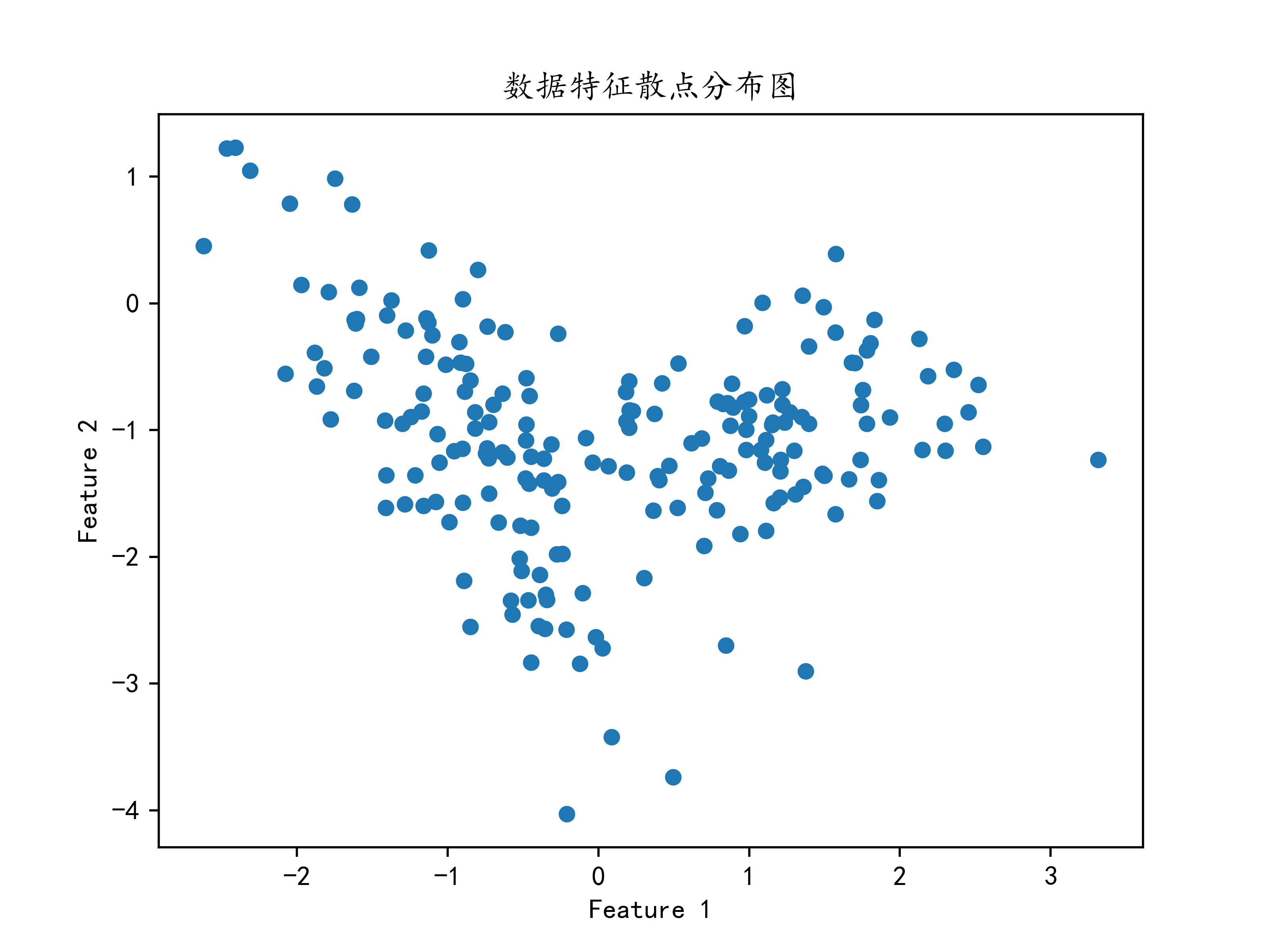
3.逻辑回归训练样本及测试
#导入新样本
test_data=[[0.8,-3.5],[2,-2.1],[3.1,-1.4]]
test_data=np.array(test_data)
test_data
#预测样本
predicted_data=model.predict(test_data)
predicted_data测试样本所返回的结果还算不错,大致能看出正确与否。
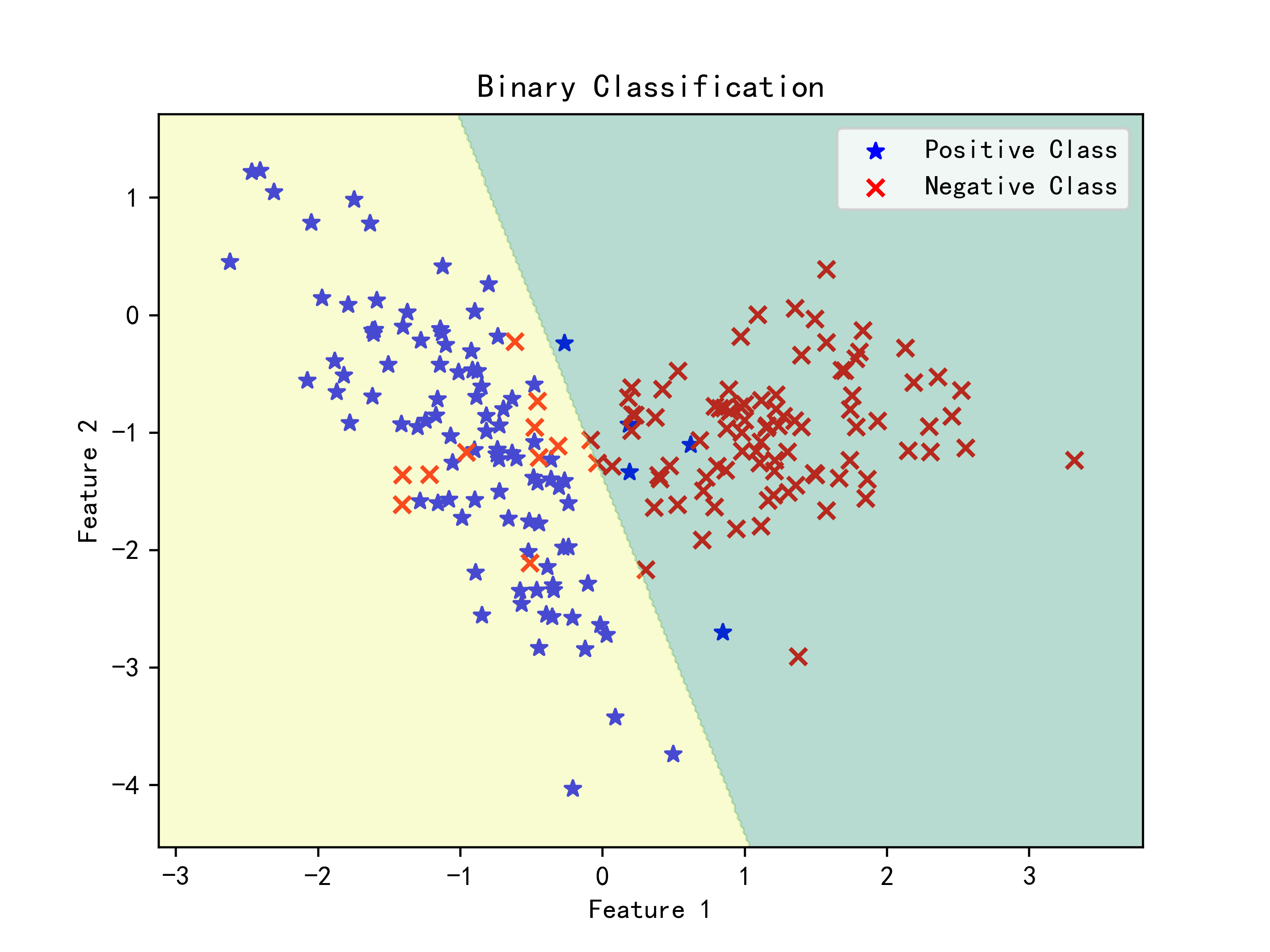
4.绘制散点决策边界
# 绘制散点图
#这个时候散点图的和原先的散点图有些区别
#根据类别标签绘制不一样的图
#先绘制label==1的图
X1=X[y==1,0]
X2=X[y==1,1]
plt.scatter(X1, X2, color='b', marker='*', label='Positive Class')
#再绘制label==2的图
X3=X[y==0,0]
X4=X[y==0,1]
plt.scatter(X3, X4, color='r', marker='x', label='Negative Class')
#
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Binary Classification')
plt.legend()
# 绘制对应的决策边界
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3,cmap='summer')
plt.show()