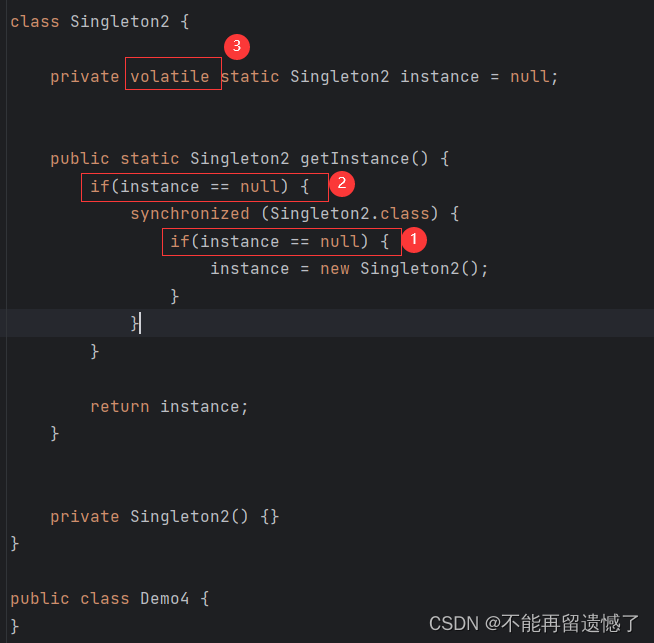
一、说明
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类是一种基于密度的聚类算法。它能够根据数据点的密度来将数据划分为不同的类别,并可以自动识别离群点。DBSCAN聚类算法的核心思想是将密度高的数据点划分为同一个簇,将密度低的数据点划分为噪声点。通过定义数据点之间的距离和密度阈值,DBSCAN可以在不需要事先确定簇的数量的情况下进行聚类。
二、DBSCAN概述
聚类应用于数据集以对相似的数据点集进行分组。它寻找数据点中的相似点和不同点,并将它们混杂在一起。聚类中没有标签。聚类是一种无监督学习,旨在发现数据集的底层结构。
2.1 聚类算法的类型:
- 基于分区的聚类
- 模糊聚类
- 层次聚类
- 基于网格的聚类
- 独家聚类
- 重叠聚类
- 基于密度的聚类
在本博客中,我们将重点介绍基于密度的聚类方法,特别是结合 scikit-learn 的 DBSCAN 算法。基于密度的算法擅长发现高密度区域和异常值。它通常用于异常检测和非线性数据集聚类。
2.2 DBSCAN性质
1)DBSCAN聚类算法的优缺点包括:
- 不需要预先指定簇的数量。
- 能够识别离群点和噪声点。
- 能够处理任意形状的簇。
- 对于密度高的簇能够表现出色。
2)DBSCAN聚类算法的缺点包括:
- 对于密度低的簇,聚类效果可能不如其他算法。
- 对于高维数据,聚类效果可能不佳。
3)DBSCAN聚类算法的应用包括:
- 图像分割
- 地理信息系统中的空间聚类
- 计算机视觉中的对象跟踪
- 社交网络分析中的社群发现
三、DBSCAN的构建
DBSCAN(基于密度的噪声应用空间聚类)是一种基于密度的无监督学习算法。它计算最近邻图以查找任意形状的簇和异常值。而 K 均值聚类会生成球形聚类。
DBSCAN 最初不需要K个簇。相反,它需要两个参数:eps 和 minPts。
- eps:它是特定邻域的半径。如果两点之间的距离小于或等于 esp,则将其视为其邻居。
- minPts:给定邻域中形成簇的最小数据点数量。
DBSCAN 使用这两个参数来定义核心点、边界点或离群点。
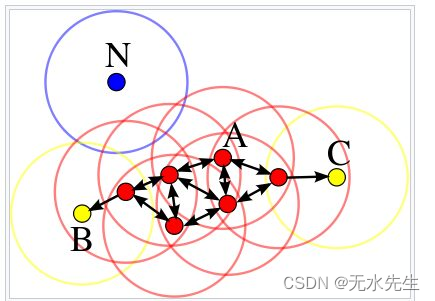
四、DBSCAN 聚类算法如何工作?
- 随机选择任意点p。如果邻域中的 数据点多于minPts,则也称为核心点。
- 它将使用eps和minPts来识别所有密度可达点。
- 如果p是核心点, 它将使用eps和minPts创建一个簇。
- 如果p是边界点,它将移动到下一个数据点。如果一个数据点的邻域内 点数少于minPts ,则该数据点称为边界点。
- 该算法将继续下去,直到访问完所有点。
五、Python 中的 DBSCAN 聚类
我们将使用 Deepnote 笔记本来运行该示例。它预装了 Python 包,因此我们只需导入 NumPy、pandas、seaborn、matplotlib 和 sklearn 即可。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN我们正在使用来自 Kaggle 的商城客户细分数据。它包含客户的年龄、性别、收入和支出分数。我们将使用这些功能来创建各种集群。
首先,我们将使用 pandas `read_csv` 加载数据集。然后,我们将选择三列(“年龄”、“年收入 (k$)”、“支出分数 (1-100)”)来创建X_train数据框。
df = pd.read_csv('Mall_Customers.csv')
X_train = df[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]我们将使用eps 12.5 和min_sample 4 将X_train拟合到 DBSCAN 算法上。之后,我们将从 X_train 创建一个DBSCAN_dataset并使用clustering.labels_创建一个“Cluster”列。
clustering = DBSCAN(eps=12.5, min_samples=4).fit(X_train)
DBSCAN_dataset = X_train.copy()
DBSCAN_dataset.loc[:,'Cluster'] = clustering.labels_为了可视化集群的分布,我们将使用 value_counts() 并将其转换为数据帧。
如您所见,我们有 5 个聚类和 1 个异常值。“0”簇的大小最大,有 112 行。
DBSCAN_dataset.Cluster.value_counts().to_frame()
在本节中,我们将使用上述信息并可视化散点图。
有两个图:“年收入与支出分数”和“年收入与年龄”。簇由颜色定义,异常值被定义为小黑点。
可视化清楚地显示了每个客户如何属于 5 个集群之一,我们可以使用此信息为紫色集群的客户提供高端优惠,为深绿色集群的客户提供更便宜的优惠。
outliers = DBSCAN_dataset[DBSCAN_dataset['Cluster']==-1]
fig2, (axes) = plt.subplots(1,2,figsize=(12,5))
sns.scatterplot('Annual Income (k$)', 'Spending Score (1-100)',
data=DBSCAN_dataset[DBSCAN_dataset['Cluster']!=-1],
hue='Cluster', ax=axes[0], palette='Set2', legend='full', s=200)
sns.scatterplot('Age', 'Spending Score (1-100)',
data=DBSCAN_dataset[DBSCAN_dataset['Cluster']!=-1],
hue='Cluster', palette='Set2', ax=axes[1], legend='full', s=200)
axes[0].scatter(outliers['Annual Income (k$)'], outliers['Spending Score (1-100)'], s=10, label='outliers', c="k")
axes[1].scatter(outliers['Age'], outliers['Spending Score (1-100)'], s=10, label='outliers', c="k")
axes[0].legend()
axes[1].legend()
plt.setp(axes[0].get_legend().get_texts(), fontsize='12')
plt.setp(axes[1].get_legend().get_texts(), fontsize='12')
plt.show()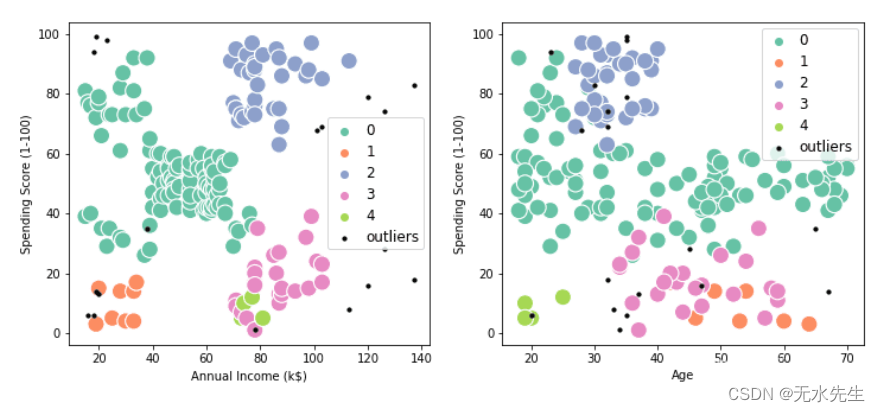
六、结论
DBSCAN 是用于客户细分的众多算法之一。您可以使用 K 均值或分层聚类来获得更好的结果。聚类算法通常用于推荐引擎、市场和客户细分、社交网络分析和文档分析。
在本博客中,我们学习了基于密度的算法 DBCAN 的基础知识,以及如何使用它通过 scikit-learn 创建客户细分。您可以通过使用轮廓得分和热图查找最佳eps和min_samples来改进算法。