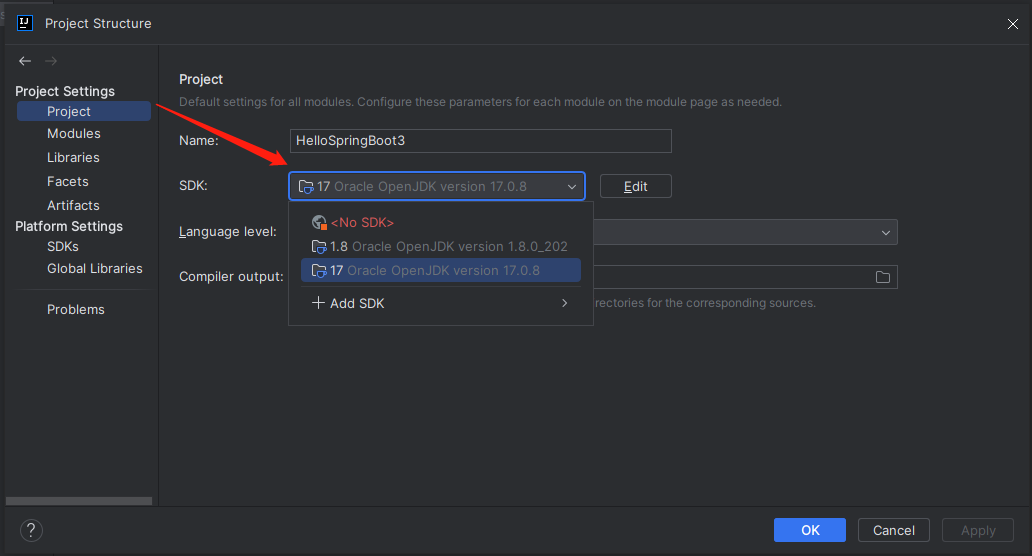
Meta荟萃分析(也称Meta分析,元分析,异质性分析等),其是一种综合各种文献结论,进而汇总综合评价的方法,Meta分析常用于医学、心理学、教育学、生态学等专业领域。通俗地看,Meta分析是将多篇类似研究的文献进行汇总,将多个文献的研究结论进行总结,并且通过一系列科学分析,从而得到科学结论的方法。
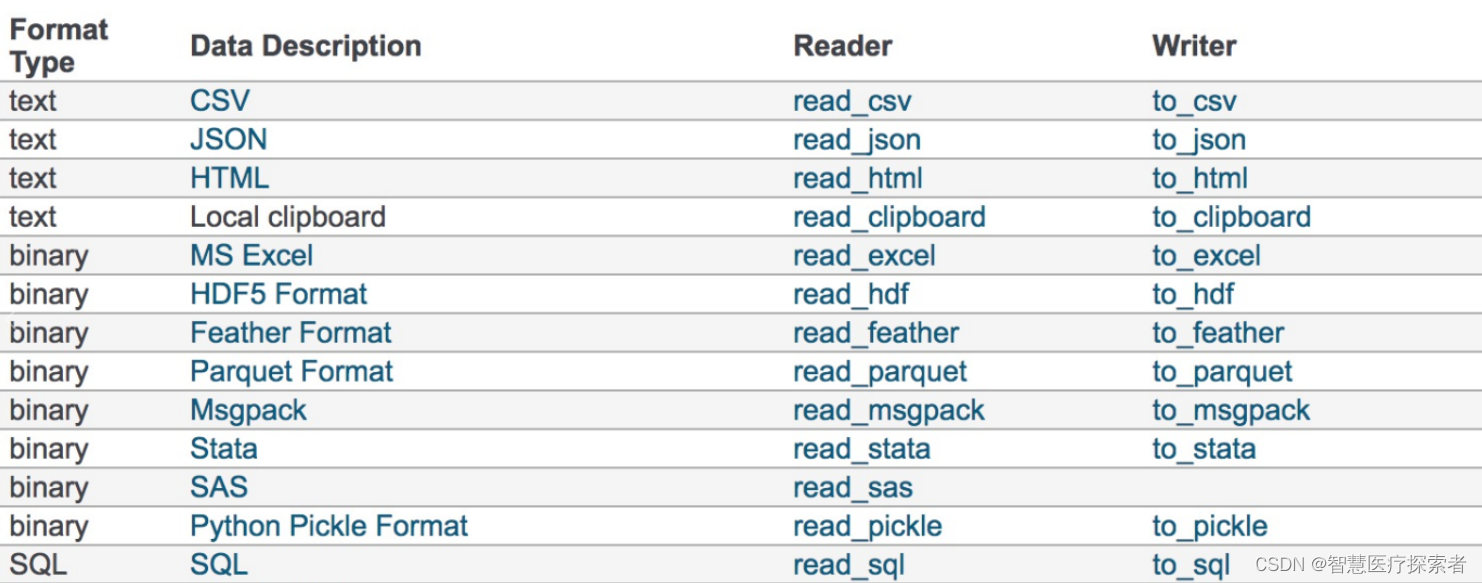
按照数据类型,Meta分析可包括多种类型,比如连续性数据进行均值差异比较,二分类数据进行比率差值对比(或计算优势比OR值,相对危险度RR值等),当然SPSSAU中还包括单个率、相关系数、平均值,或者OR值/HR值的Meta分析等,并且提供一般倒方差法时的Meta分析。Meta分析涉及专业术语和名词较多,比如效应量、效应量测量、Meta模型、估计方法、发表偏倚(Begg检验和Egger检验,Trim剪补法)、敏感性检验、累积Meta和Meta回归,森林图和漏斗图等,上述名词将在下述案例中具体说明。
连续性数据Meta荟萃分析案例
Contents
1 背景22 理论23 操作44 SPSSAU输出结果55文字分析56 剖析11疑难解惑11
1 背景
当前有五篇文献进行随机对照实验,数据如下:包括文献名称(Study)、实验组和对照组分别的平均值、标准差和样本量数据,如下图所示:

需要注意的是,Study表示文献名称,其由研究者自行处理格式即可,并无固定要求。另外,如果希望进行亚组分析,则需要在‘subgroup亚组’列中放入亚组信息(比如男/女,或A/B等),cov是协变量的意思,如果有协变量数据,那么系统会自动进行Meta回归,当前最多支持3个协变量。
2 理论
Meta分析时涉及较多的专业名词,整理如下表格所示:


针对Meta分析,其常见的分析步骤如下:

3 操作
本例子中操作截图如下:

- 关于效应量:默认情况下应该选择标准化均值差SMD,其会处理量纲问题等,即使本案例数据并无单位量纲问题;基于标准化均值差SMD时包括3种效应量计算方式,默认使用Hedges,3种方式并无特别要求,具体建议以文献为准;
- 效应量计算方法为倒方差法IV,不同文献资料时计算方法不同,比如二分类时SPSSAU会提供比如MH法;
- Meta模型:分析上默认认为有异质性问题(理论上异质性问题一定存在,只是程度而已,程度很低时则使用固定效应即可),因而默认使用随机效应;以及估计方法一般情况下使用DL法即可,SPSSAU还提供其它方式,但其结果通常基本一致;
- 出于演示需要,因而选择其余参数,包括Hartung and Knapp调整,该调整会影响合并效应的置信区间值,要求SPSSAU提供发表偏倚结果,敏感性检验结果,累积Meta分析结果和Meta回归结果(需要提示的是:如果没有协变量数据,即使用选中Meta回归也不会有对应结果);
- 发表偏倚:该参数选中后,SPSSAU会输出漏斗图、Begg检验和Egger检验和Trim剪补法结果等;
- 敏感性检验:该参数选中后,SPSSAU提供‘逐一剔除法’检验方式;
- 累积Meta:该参数选中后,SPSSAU提供逐一增加文献资料后的Meta效应结果汇总。
4 SPSSAU输出结果
Meta模型一共输出7个表格和5个图,说明如下:

另需要提示的是:
- 如果有提供‘subgroup亚组’数据,那么系统自动会进行亚组分析,其会改变森林图/效应量表格结果等;
- 如果有提供协变量数据,并且要求进行Meta回归,那么系统还会提供Meta回归结果,以及Meta回归后的异质性指标信息等。
5文字分析

上表格展示Meta分析的基本配置参数信息,上表格中研究个数k值是指研究文献数量,本案例仅为5个较少。除此之外,tau2估计方法即指Meta分析模型估计方法,在异质性检验表格中会展示tau2值。

上表格展示效应量结果,包括各研究文献的效应量及其98%置信区间,并且展示各文献对于‘合并效应’的贡献情况即权重值,权重越大意味着该文献对于Meta合并效应的贡献越大,即该文献对于合并效应的影响力度越大。本案例共5篇文献,各篇文献的权重值基本均在在20%左右。以及最后1行展示最关键的‘合并效应’信息,本案例为-0.027(-0.263 ~ 0.210),95%置信区间不包括数字0,即意味着合并效应值并不会明显偏离数字0,那么意味着实验组和对照组并无明显的差异。除此之外,还可通过z检验查看合并效应是否明显偏离数字0,检查显示z = -0.312, p = 0.770>0.1,也即说明合并效应不会明显的偏离数字0,也即意味着实验组和对照组的均值并无明显差异。
合并效应是最终关键结果,但需要说明的是,Meta分析还需要确保‘异质性问题’,‘发表偏倚问题’等均通过科学论证之后,才能认为该结果具有科学性,即还需要有下要这的异质性检验和发表偏倚检验等,并且一般还需要通过敏感性检验。

森林图直观展示Meta分析结果,森林图中包括信息为:各文献的效应量及其95%置信区间,各文献的权重信息,以及异值性检验关键指标结果(tau2值,I2值,Q检验),并且展示z检验结果(检验合并效应是否为0的检验)。森林图中中间部分可视化展示效应量及其置信区间,以及中间部分黑色矩阵的大小表示权重相对大小。菱形为合并效应及其95%置信区间的展示,如果菱形越小,则意味着合并效应的置信区间越小。中间竖着虚线表示合并效应大小。
从森林图可以看到,‘Hartman 2008’和‘Weins 2015’这两篇文献的效应量会大于‘合并效应’,另外3篇文献的效应量小于‘合并效应’。以及‘Hartman 2008’这篇文献的Hedges效应量为0.28,95%置信区间不包括数字0,但是其余4篇文献的效应量95%置信区间均包括数字0,意味着该4篇文献时,实验组和对照组本身并无均值差异。
至于森林图中的异质性检验结果等,其在‘异质性检验’表格中也有呈现。并且从森林图整体来看,5篇文献的效应量有一定的偏差但并不是特别大,意味着可能存在不严重的异质性问题。

异质性检验有多种方式,包括:Q检验,I2值判断,H值判断等。通常情况下Q检验时p值>0.1,即说明无异质性(即同质性);I2指标衡量组间异质性的占比情况,通常I2大于50%时认为异质性较高,I2大于75%时认为异质性过高;通常H值大于1.5则说明存在异质性,H值小于1.2说明不存在异质性问题,如果H介于1.2 ~ 1.5之间时,如果95%区间包括1说明没有异质性,反之说明具有异质性。
从上表格可以看到:Q检验显示p值=0.033<0.05,即拒绝无异质性问题的假定,说明资料具有异质性问题。另外,I2为61.89%>50%,说明具有较高的异质性。而且H值=1.62>1.5,且其95%置信区间介于1 ~ 2.64之间。综合来说,本次Meta分析时资料具有一定的异质性问题。当出现异质性问题时,处理方式有两种,最常见是使用随机效应(本次案例直接就使用随机效应),与此同时,还可以进一步深入探索和分析具体异质性问题所在,处理掉导致出现异质性的文献后,再次进行分析等。进一步深入探索异质性问题,则需要使用亚组Subgroup分析和Meta回归分析等,本案例不进一步深究。当然如果没有异质性问题可直接使用固定效应就好。
上表格中还包括tau2值 和H2值,tau2表示效应量的离散异质程度,其一般使用D-L法或REML法进行估计,其为随机效应时输出指标值,该值越大表示组间异质性越大,该值涉及随机效应计算的底层方式,但该值无法进行相对大小对比,通常在森林图中进行展示即可。与此同时,H2值表示总变异除以组内变异,其为H的平方,H和H2越大意味着异质性越高。

Meta分析时还有个关键问题是发表偏倚。有较多的方式可进行发表偏倚的查看和检验等,SPSSAU提供Egger检验和Begg检验,漏斗图和Trim剪补法。
Egger检验时p值大于0.05,则认为不存在发表偏倚,反之说明可能存在发表偏倚;Begg检验时p值大于0.05,则认为不存在发表偏倚,反之说明可能存在发表偏倚。通常情况下,研究文献数量较少时可能更偏向于使用Begg检验,以及当研究数量较少时(通常小于10时认为较少),使用Egger检验或Begg检验均不能很好地对发表偏倚进行检验,因而可使用漏斗图这种直观式方式进行查看发表偏倚问题。

漏斗图时,横坐标为效应量,纵坐标为标准误差值(并且纵坐标进行逆向),如果说各散点介于漏斗内两侧并且基本上呈现出对称状态,那么意味着没有发表偏倚问题。上图显示5个研究文献散点均在漏斗内侧并且基本对称,因而直观上看数据并没有发表偏倚问题。与此同时,当研究资料出现发表偏倚问题时,还可使用Trim剪补法进行正‘合并效应’值。

Trim剪补法时剪去漏斗图中不对称项,并且沿漏斗图中心两侧填补上被剪切部分,并且基于剪补后数据重新进行效应量计算,以校正异质性问题带来的效应量偏差。上表格中列出的第1行为真实数据结果,第2行为填补后的校正数据结果;如果两行结果完全一致,则意味着并没有进行填补处理。
本次案例进行Trim剪补法后,并没有填补项,因而剪补前和剪补后结果完全一致,这也进一步说明并没有发表偏倚问题,与此同时,SPSSAU提供Trim剪补后的漏斗图(由于剪补前和剪补后完全一致,因而漏斗图也完全一致)。


敏感性检验表格使用逐一剔除检验法进行研究。每行表示移除该项后剩余项的meta合并效应量结果,效应量是否为0的z检验结果及I2指标值;比如第1行表示如果不纳入‘Hartman 2008’这篇文献数据,余下4篇文献进行Meta分析的合并效应结果等。另外,表格最后一行展示所有研究的合并效应结果;
综合上表格来看,各个效应量值对应的95%置信区间均包括数字0,即意味着合并效应不显著偏离数字0(实验组和对照组均值差无明显差异)这一结论,具有稳健性。与此同时,上表格还可以看到,‘Hartman 2008’这篇文献被移除后,I2值仅为13.80%,意味着该文献可能带来了明显的异质性问题(因为将其移除后I2明显由61.89%下降为13.80%)。
与此同时,还可使用森林图直观展示敏感性检验结果,如下图,图中可以看到,逐一移除单独一篇文献后,合并效应并没有发表非常明显的改变,因而也意味着本案例数据通过敏感性检验,合并效应结果具有良好的稳健性。


累积效应结果展示逐一纳入新的研究后的效应量、95%置信区间及效应是否为0的z检验结果和I2等;比如上表格第3行‘(+)AHS 2018’表示在‘Hartman 2008’基础上再加入该文献后的合并效应量结果等。SPSSAU中进行累积效应时,默认自上而下不停地纳入文献,如果需要改变顺序,那么可通过修改放入的原始数据顺序进行改变。
下面森林图是累积效应的可视化呈现结果。

6 剖析
Meta分析涉及以下几个关键点,分别如下:
- Meta分析通常关注三项内容,分别是异质性问题,发表偏倚问题和稳健性问题;异质性问题具有多个检验指标,有时候可能出现不一致结论,建议综合进行决择判断,类似地,发表偏倚也有多种检验和查看方式,通常使用漏斗图查看和分析即可,Meta敏感性检验常用逐一剔除法。
疑难解惑 - 如果不满足异质性检验时如何办?
如果基本没有异质性问题,那么建议使用固定效应即可,当然此时使用随机效应也可以;如果说异质性问题不太严重,那么直接使用随机效应模型即可;如果说异质性问题非常严重,建议进一步查看导致异质性问题的原因并且处理后分析使用。 - 如果不满足发表偏倚怎么办?
如果漏斗图发表散点不在漏斗内侧并且明显不对称,那么建议使用剪补法,并且最终使用修正后的合并效应结果。当然也可找出导致不对称的文献,并且移除该文献后再次分析。 - 如果没有通过敏感性检验怎么办?
SPSSAU中,敏感性检验使用逐一剔除法,综合对比和分析结论上的变化等。当然还可以有其它处理方法,比如一次性剔除两篇文献等,建议综合对比决择等。如果剔除某一文献后合并效应发表非常明显的变化,可考虑将该文献不纳入分析范围。