在 TDengine 3.0 中,我们对流式计算、数据订阅功能都进行了再升级,帮助用户极大简化了数据架构的复杂程度,降低整体运维成本。TDengine 提供的类似消息队列产品的数据订阅、消费接口,本质上是为了帮助应用实时获取写入 TDengine 的数据,或者以事件到达顺序处理数据,与其他消息队列相比,它提供了更大的灵活性,同时有效地降低了传输的数据量与应用的复杂度。
在本篇文章中,TDengine 研发人员详细揭秘了 TDengine 数据订阅的流程和具体实现,给到有需要的人参考。此前我们还在《关于 TDengine 3.0 数据订阅,你需要知道这些》一文中汇总了部分重要的语法规则,如果你正在研究 TDengine 数据订阅功能,可以结合来看。
数据订阅的分类
TDengine 支持多种订阅类型,包括子查询结果订阅、超级表订阅以及整个数据库订阅。超级表订阅和库订阅支持参数 with meta,添加此参数后,订阅的结果将包含数据的 meta 信息,一般用于数据同步迁移。具体语法如下:
- 列订阅
CREATE TOPIC topic_name as subquery;- 库订阅
CREATE TOPIC topic_name as database db_name [with meta];- 超级表订阅
CREATE TOPIC topic_name as stable stb_name [with meta];与 Kafka 对比
一直以来,TDengine 做产品的初衷就是简单易用,因此在做数据订阅功能时,API 全部对标的都是 Kafka。如果有人深入研究过 TDengine 的模型,就会发现它的架构模型和 Kafka 的很多设计都是相对应的,Topic 和 Kafka 相似,Vnode 跟 Kafka 中的 Partition 也很接近,子表的表名跟 Kafka 中的 Event Key 对应,因此这个架构设计天然地就带有消息队列的特点,也正是基于此,TDengine 做数据订阅功能才能如此得心应手。
TDengine 的数据订阅功能与 Kafka 相比,基本概念都是一致的,只是具体实现方式可能有所不同,实现路径如下所示:
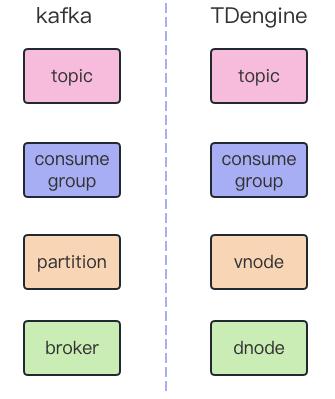
在时序数据场景下,TDengine 降低了用户对 Kafka 的依赖,其 Vnode 可以允许不同的消费者同时消费数据,用户只需要订阅自己关注的这部分数据,比如说你只想关注电流里面超限的数据,那你使用 TDengine 进行订阅时的数据传输总量是非常小的,但用 Kafka 进行数据订阅时很可能需要从服务器拉取全部的数据,然后还要在客户端中进行数据筛选,这时两者的性能就完全不在一个量级上了。
TDengine 数据订阅关键参数说明

消费示例代码
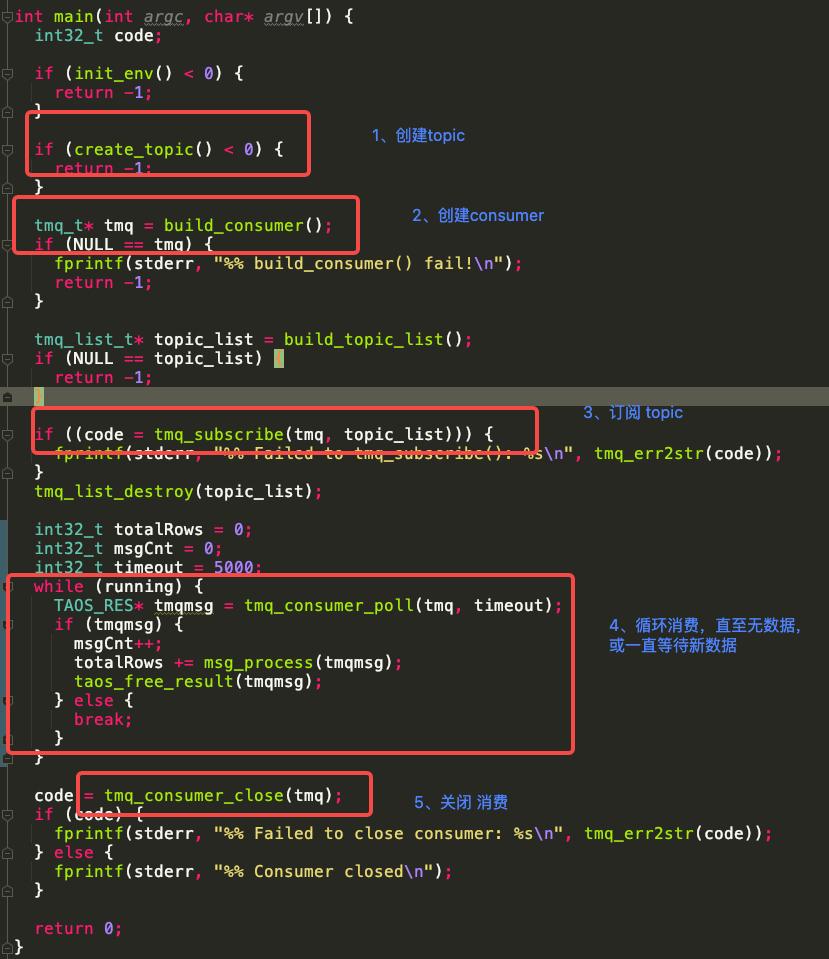
TDengine 数据订阅的流程
Client 端的功能
- 提交 commit
- 获取 endpoint
- 心跳 保活
- 消费数据
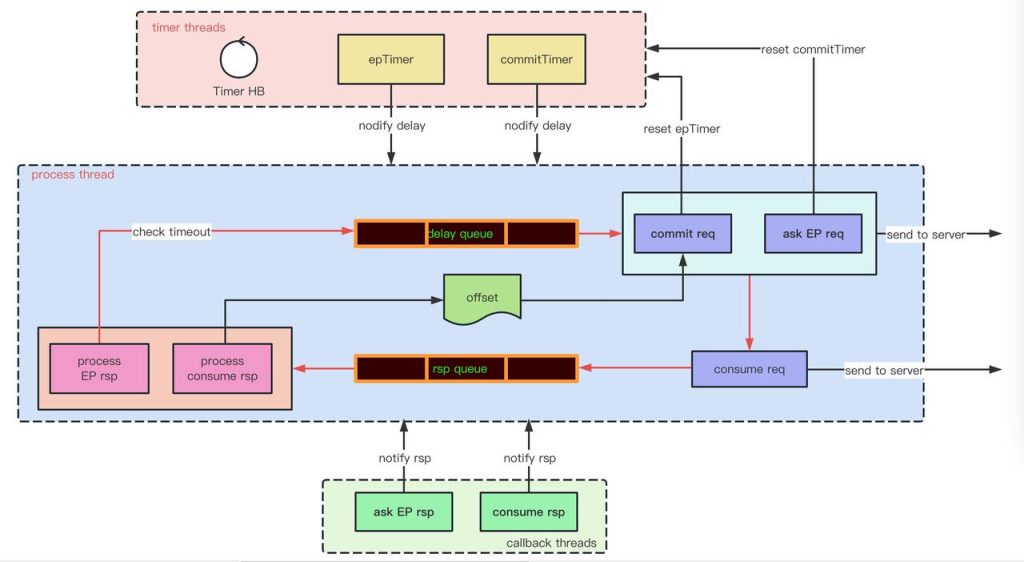
client 端在单消费线程里处理逻辑非常简单,无需对资源做并发控制。
Server 端的功能
- 消费分配控制(rebalance)(c1 表示 comsumer ID,g1 表示 group ID)
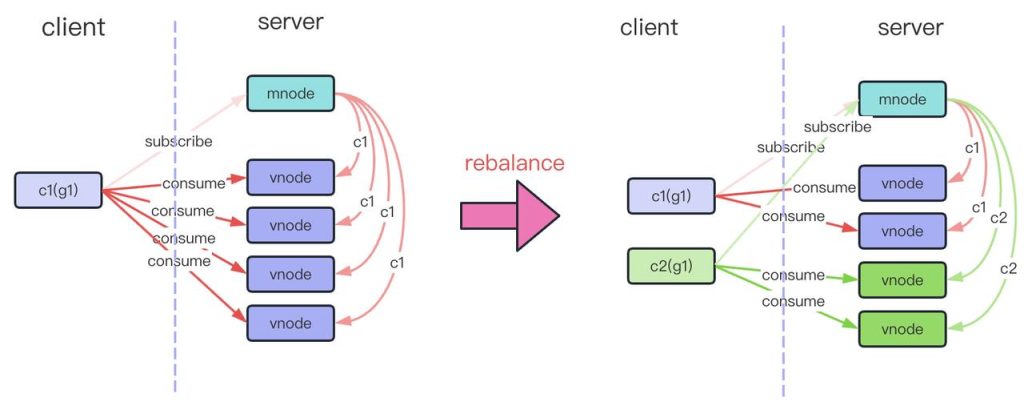
该功能通过 timer 控制,每 2s 检测一次是否需要 rebalance,rebalance 后,consumer 需要获取到新的 EP,才可正常消费,否则 consumer ID 将出现不匹配的情况,会重试。
- 消费状态控制
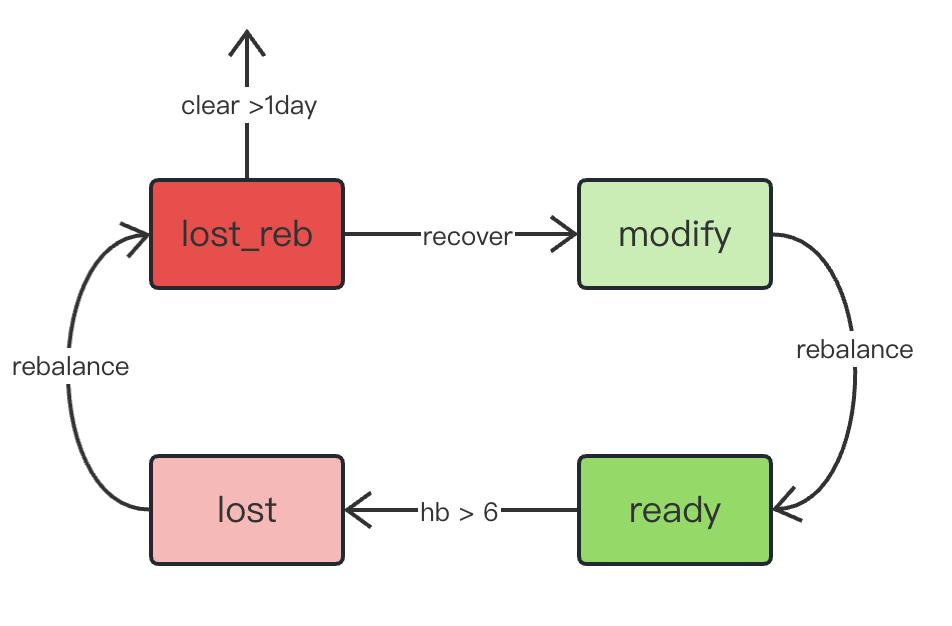
- 消费进度控制
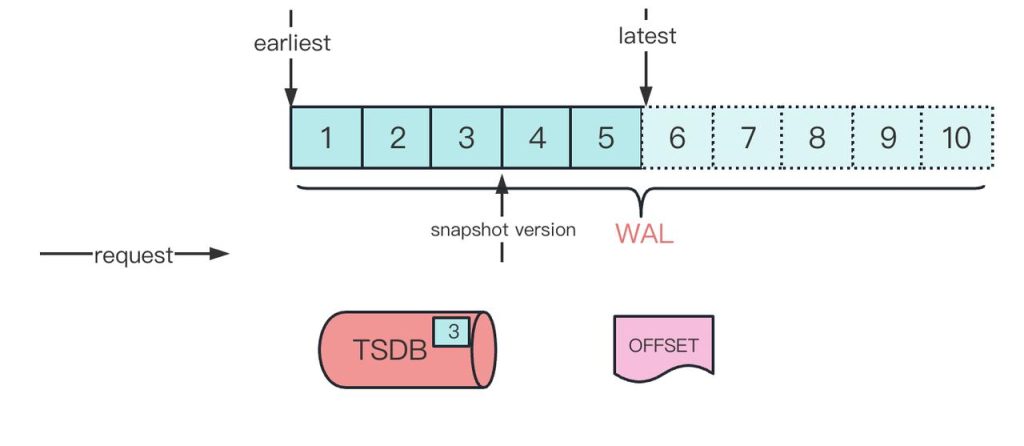
结语
TDengine 的数据订阅、流式计算功能优势也体现在企业的具体实践上,以西门子的数字化解决方案改造项目为例,TDengine 帮助其 SIMICAS® OEM 2.0 版本移除了 Flink、Kafka 以及 Redis,大大简化了系统架构,节约了运维成本;在狮桥集团的网货平台与金融 GPS 系统数据架构改造中,部署了 TDengine 之后,直接下线了一整套的末次位置 Redis 集群、轨迹查询的 Hbase 集群也被集体下掉。
如果你也面临着性能和成本难以两全的数据处理难题,亟需升级数据架构,欢迎添加小T vx:tdengine,和更专业的解决方案架构师点对点沟通。
关于 TDengine
TDengine 核心是一款高性能、集群开源、云原生的时序数据库(Time Series Database,TSDB),专为物联网、工业互联网、电力、IT 运维等场景设计并优化,具有极强的弹性伸缩能力。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一个高性能、分布式的物联网、工业大数据平台。当前 TDengine 主要提供两大版本,分别是支持私有化部署的 TDengine Enterprise 以及全托管的物联网、工业互联网云服务平台 TDengine Cloud,两者在开源时序数据库 TDengine OSS 的功能基础上有更多加强,用户可根据自身业务体量和需求进行版本选择。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。

![[git] rebase 合并多个commit](https://img-blog.csdnimg.cn/198305990cf2445883dd6d7897494d88.png)