目录
1. 函数库(链接)
1.1 链接
1.2 动态库与静态库
2. makefile
2.1 项目构建
2.2 Makefile的概念
2.3 Makefile的编写
2.4 .PHONY定义伪目标
ACM 时间
3.实现进度条(缓冲区)
3.1 缓冲区的概念
3.2 实现一个简易 "进度条"
4. 版本控制器Git
4.1 Git的概念和准备工作
4.2 git 三板斧
4.3 git pull和.gitignore等
5. 相关笔试题
答案及解析
本篇完。
1. 函数库(链接)
1.1 链接
在上一篇说到翻译有以下四个步骤:
- ① 预处理 ② 编译(生成汇编) ③ 汇编 ④ 链接
链接部分我们只是简单的用了一下,现在来正式讲一讲。
我们的C程序中,并没有定义 printf 的函数实现,且在预编译中包含的 stdio.h 中也只有该函数的声明,而没有定义函数的实现。那么是在哪里实 printf 函数的呢?
系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径 /usr/lib 下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数 printf 了,而这也就是链接的作用。
从我们敲下第一行代码,打印 hello world 时就已经和库有着千丝万缕的联系了。
看上去像是我们在写代码打印这个语句,实际上是调用了大佬写的 prinf 打印函数。
你自己用的C语言头文件,从库中取的所有的函数,全部都需要在头文件当中声明,在库文件当中实现,然后在编译的时候再把你的可执行程序和库文件关联起来,此时关联之后,才能形成可执行程序。
如果今天我们是在写 C++ 代码,C++ 对应的库也必须在安装 gcc 的时候都必须具备好,我们所说的装环境,实际上不仅仅在装环境。比如我们在装 VS2022 的时候我们不仅仅在装 VS2022,你也在装头文件也在装环境中所支持的语言。
头文件Header file:给我们提供了可以使用的方法,所有的开发环境,具有语法提示,本质是通过头文件帮我们搜索的。
库文件Library file:给我们提供了可以使用的方法的实现,以供链接,形成我们自己的可执行程序。
1.2 动态库与静态库
计算机存在两类库:一类库叫动态库,一类库叫静态库。
动态库:Linux (.so),Windows (.dll) —— 动态链接
动态链接:
- 优点:大家共享一个库,可以节省资源。
- 缺点:一旦库丢失,会导致几乎所有的程序失效!
静态库:Linux (.a),Windows (.lib) —— 静态链接
静态链接:将库中的相关代码,直接拷贝到自己的可执行程序中。
那 gcc 中如何体现呢?形成的可执行程序体积一定是不一样的,静态链接体积大,动态链接体积小。那么我们在 Linux 中用 gcc 编译程序,默认情况下形成的的可执行程序就是动态链接的:
如果你想进行静态链接,你需要在编译代码时在后面加上 -static 选项:(比如上一篇的加上)
gcc test.c -o mytest -static
此时如果出现了找不到的情况,那么你就需要安装一下静态库,记得切换到 root 下去安装。
安装 C语言 的静态库:
yum install -y glibc-static安装 C++ 的静态库:
yum install -y libstdc++-static动态链接和静态链接推荐使用哪个?
默认是动态链接,我们也更推荐动态链接,
因为生成体积小,无论是编译时间还是占资源的成本,一般都比静态链接要好。
但这并不是绝对的。如果你要发布一款软件是动态链接的,程序短小精悍但库相对显得累赘,如果此时你发布这款软件就不想带库了,你把它静态链接就是完全合适的。
2. makefile
写在前面:会不会写 makefile,从一个侧面说明一个人是否具备完成大型工程的能力。一个工程中的源文件不计其数,按类型、功能、模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译 ,甚至于更复杂的功能操作。
2.1 项目构建
项目构建的话题:关于你的项目和编译的话题。
对于项目构建,
VS下直接Ctrl F5就完了。编译时你需要按个键就能做到编译调试运行,
编译个项目真的轻轻松松。那是因为 VS 帮你自动维护了对应的项目结构。
你可以试着思考一下下面的问题
- 多文件 .c .h .cpp我们先编译哪一个程序?
- 链接需要哪些库?
- 库和头文件等在哪里找?
- 整个项目结构,该如何维护?
上述问题在 VS 下没关心过,你只需要在你的 VS 下需.c就创建c.,需要.h就创建.h,
需要包含头文件就 #include 头文件,因为 VS 自动帮你维护了项目的结构。
也不需要牵扯先编哪个后编哪个的话题,但是在 Linux 下这些东西该如何去弄呢?
如果你项目中存在 50个.c,50个.h个 ,你在 VS 下编译直接运行就行,各种调各种编都可以。但是如果这是在 Linux 中,有这么多的头文件和源文件,你就得把这些源文件一个个变成 ,然后再一个个把 链接起来形成可执行,头文件如果找不到的话还得自己去处理……
这些事在 Linux 中就需要我们去做了,为了能让这样的工作更方便,于是就有了 Makefile。不是集成环境也没关系,我们可以使用 Makefile 来统一解决这样的问题。
2.2 Makefile的概念
什么是 Makefile?
make 是一个命令,makefile 是一个文件。
(为了不增加学习的成本,这里只用一个头文件演示,并且会讲的浅一些)
这里我和前几篇类似,在rtx2目录下创建一个linux_6的目录,在里面写一个简单的mytest.c:

如果放到之前,我们如果想编代码会自己 gcc,但实际上写 Makefile 也要 gcc。
但 Makefile 能让你不在命令行中打 gcc 命令操作,这能避免一些比较尴尬的情况。
比如下面这种 mytest.c 和 mytest 的顺序写反了的情况:
gcc mytest -o mytest.c
如果目录下存在一个叫 mytest 的可执行,此时不小心把选项写反,后果就是源代码直接消失。还有就是在做大项目的时候gcc后面可能跟着几十几百行代码,此时就要用到Makefile了
依赖关系与依赖方法
下面我们来正式介绍一下 Makefile,Makefile 需要两个东西,我们先介绍第一个东西。
- 需要在你当前路径或代码路径下创建一个 "Makefile" 或 "makefile" 文件(首字母大小写均可)
这里用首字母大写,Makefile:是在当前路径下的一个普通文件,它会包含两个东西
- 依赖关系(Dependency Relationship)
- 依赖方法(Dependent Method)
即在这个文件中添加对应的 "依赖关系" 和 "依赖方法"。这里Makefile的依赖关系和依赖方法:

2.3 Makefile的编写
vim 写一个最基本的 Makefile:
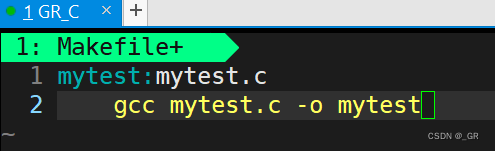
第一行是依赖关系,紧接着第二行是依赖方法。
依赖关系后面紧跟依赖方法时前面要空一个tab键(),再写依赖方法。先:wq退出
此时我们就有了一个最基本的 Makefile 了,我们编译 mytest.c 文件就可以不用再敲 gcc 命令了
直接在命令行中输入:make
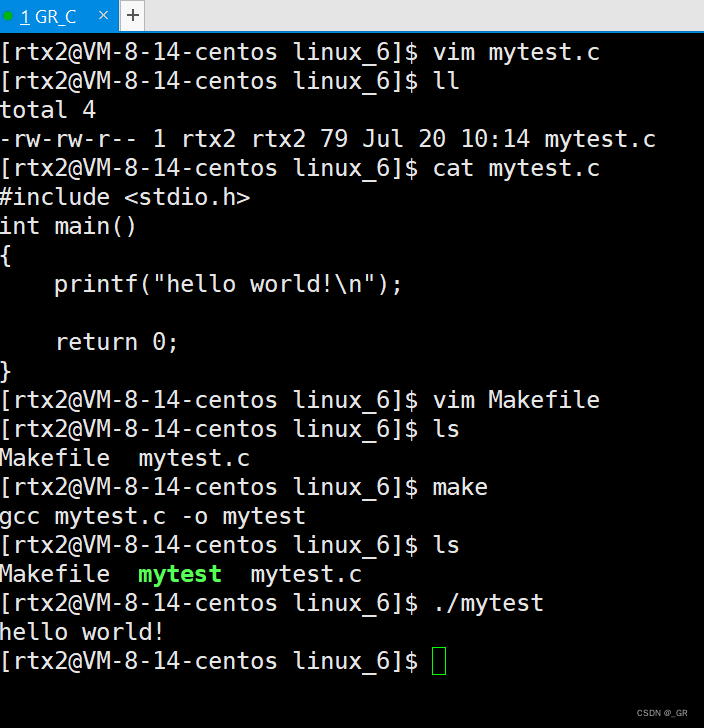
输入 make,这里就自动形成了可执行程序,会帮我们从 Makefile 去找依赖关系和依赖方法。
有童鞋就问了,这不还是要输 gcc 命令吗?这和我在命令行直接输入有什么区别?
当前让你产生这种感觉,主要是因为:
① 上面我们写的 Makefile 是最简单的 Makefile 了,自然和命令行没什么差别。
② 我们目前的项目结构简单,如果后面遇到大的项目结构你就知道 Makefile 有多方便了。
以后我们在 Linux 下编译代码就不需要敲 gcc 命令了,直接 make 就可以了。
它会给我们带来很多便捷,如果是第一次接触,现在可能还体会不到,后面慢慢就能体会到了。
Makefile项目的清理
刚才我们实现的 make 就相当于 VS 下的 "生成解决方案" :
但是 VS 下好像还有 "清理解决方案" 这样的功能,那我在 Linux 下也想拥有,怎么办?
我们现在不想要这个可执行程序了,放在之前我们会直接 rm 掉这个文件。
但是假设有这样的一个场景:一个程序生产了大量的临时文件,你岂不是要疯狂的 rm?
无脑删又很容易把源代码删掉,这个时候我们就可以在 Makefile 里实现 "清理解决方案" 的功能,看看语法:
.PHONY:clean
clean:
依赖方法
vim跟着上面写一个Makefile项目的清理


clean是存在依赖关系的,只不过这个clean没有依赖列表。(下面讲PHONY时讲)
后面的 rm -f mytest 为依赖方法,再次强调,依赖方法前面必以 tab 键开头。
我们现在来用一下看看效果如何,
:wq保存退出,刚才我们编译用的是 make,清理我们用 make clean:

make 就相当于 VS 中的构建项目,而 make clean 就相当于是清理项目。
2.4 .PHONY定义伪目标
这里的第1行就是目标文件,第4行就是伪目标
目标文件和伪目标,给我的一种感觉就是好像都是目标文件啊?这就像正规军和伪军,都是军队。不管是目标文件还是伪目标,最终目的都是要根据自己的依赖关系执行依赖方法。
不知道你有没有观察到,我们的 makefile 有两个目标文件:
我们在 make 的时候,默认只帮我们生成 makefile 中的 mytest.c 目标文件。
而 make clean 是制作指定名称的目标文件,做清理的工作,我们首先来思考一个问题:
为什么 make 的时候它总是执行第一个呢?
makefile 在自顶而下进行形成目标文件时,它可以根据你的需求形成多个目标文件。
我们这里有两个目标文件,一个是 mytest 一个是 clean,凭什么我 make 执行的是 mytest 而不是 clean?答案很简单,就凭我 mytest 是在前面写的。
makefile 在形成文件时会自顶而下扫描,默认只会形式第一个目标文件,执行该依赖关系的依赖方法。 我们一般还是喜欢把形成可执行程序放在前面,也就是让 makefile 默认去形成。
.PHONY 是 makefile 语法格式的一个关键字,表明 "总是被执行的" 。
- 比如 clean 被.PHONY修饰时,表明 clean 是总是被执行的。
"总是被执行" 就意味着还有 "总是不被执行" ,我们先来看看什么是 "不总是被执行" ?

我们多次 make 之后它仍然是会提示 “make: `mytest` is up to date.” 这段话。
貌似只有第一次 make 的时候才会才会帮我们形成一个全新的 mytest ,再之后多次进行 make,就会告知你 mytest 已经是一个可执行程序了,不能再生成了。
如果自己的源代码已经用最新的源代码编译链接形成可执行文件了,那么编译器就不会再帮我们再重新根据你的 makefile 再重新给你生成了。因为既然变都没变,还给你生成那岂不是既浪费时间又浪费资源?它是怎么知道要不要再生成的?
它是通过比较Makefile的ACM和mytest.c的ACM之类的操作实现的。(下面讲)
现在来看看 clean 被.PHONY修饰时,表明 clean 是总是被执行的:
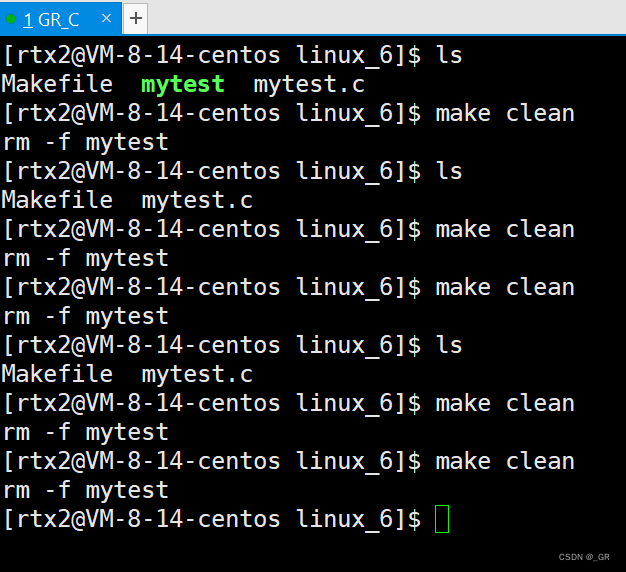
总是被执行:无论目标时间是否新旧,照样执行依赖关系。
而我们一般不太建议把我们形成的目标文件定义成伪目标,而是喜欢把清理定义成伪目标。
这也正是为什么我们每次 make clean 都能帮我们执行清理的根本原因。
前面提到:那 makefile 是如何识别我的 exe/bin 文件是新的还是旧的呢?
ACM 时间
Access是最后访问时间时间、Modify是文件内容最后修改时间,Change是属性最后修改时间。
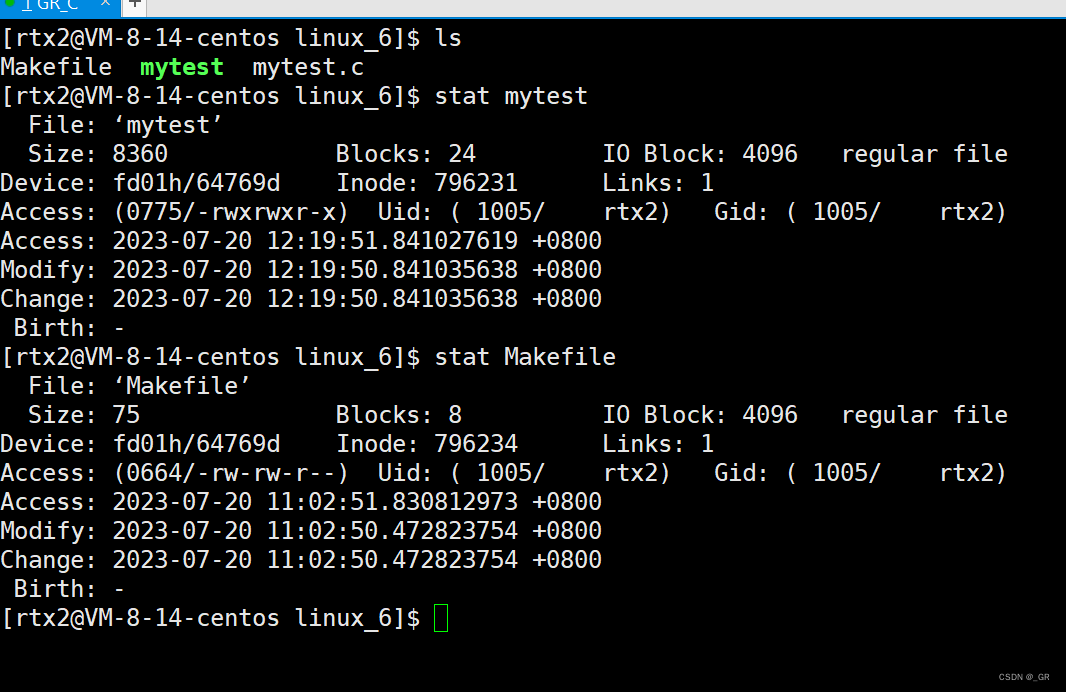
这个 Modify 和 Change 有什么区别呢?
我们知道,"文件 = 内容 + 属性"
如果是内容发生改变,就是 Modify;如果是属性发生改变,就是 Change。
修改内容也有可能引发 Change 的改变,因为修改内容可能会引起 change time 的变化
我们打开文件修改,Access 应不应该改变呢?我们读取 Access 变不变?
要变的,但是现在不会变。因为访问文件的频率是最高的,Modify 和 Change 是不得不变的,不变的化文件就不对了。但是我们大多数情况修改文件属性和修改文件内容是很低频的事情,但打开文件是非常高平的事情,Linux 后期内核对 Access 进行了优化,将文件打开访问,打开时间不会变化,累计一段时间后他才会变化。如果不这样,打开文件这种高频率的事情,一旦更新 Access 时间,就要将数据刷新到磁盘上,这实际上一个很没效率的事情。
具体 Access 的调整策略取决于 Linux 的版本。
总结:
通过对比你的源文件和可执行程序的更改时间 (modify time) 识别的新旧。 根据原文件和可执行程序的最近修改时间,评估要不要重新生成。
现在我们再回头看刚才的问题:什么是 "总是被执行呢" ?
"总是被执行" 就是 忽略对比时间 (modify time),不看新旧,我让你执行你就给我执行。
还有就是写Makefile和文件代码时,应该先写Makefile,后写其他具体代码的实现。
3.实现进度条(缓冲区)
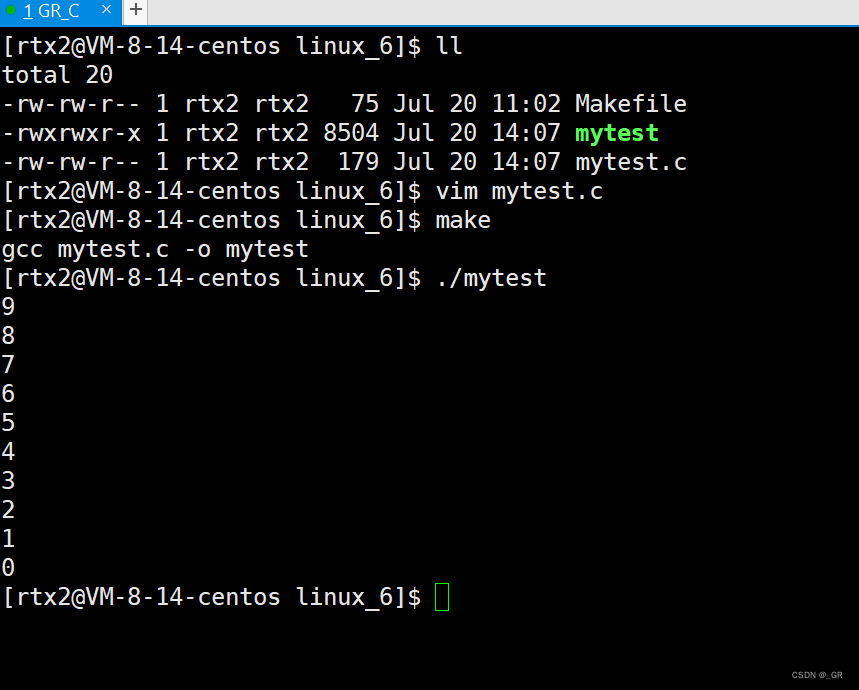
先说一下 unistd.h 库中的 sleep 函数,它可以按照秒去休眠:

代码演示: (改一下上面写的mytest.c)

首先运行的是第6行的代码还是第7行的代码?
按照以往来说应该是先输出hello word!,然后再睡眠两秒,事实也是这样:
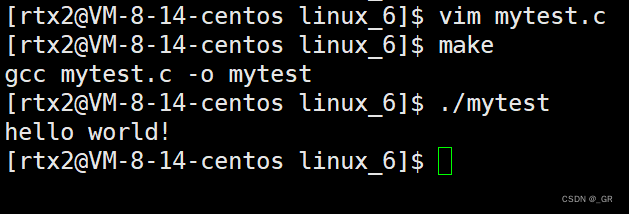
虽然这里图片看不出来,但是我看到了事实就是这样,/傲娇。

此时把\n去掉,还是不是和上面一样先输出hello word!,然后再睡眠两秒呢?
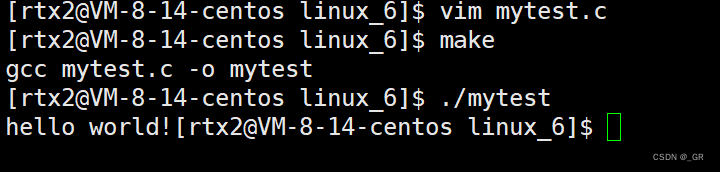
自己去运行就发现此时是先睡眠两秒,然后再输出hello word!
然而实际上,无论你加不加 \n,代码都是从上往下先运行的,即先执行 printf 再执行 sleep,
代码没有任何的循环判断跳转什么的操作,那一定是 从上到下按顺序执行的,要坚信自己,
这就是所谓的 "顺序结构",也是我们的默认结构。既然是从上到下按顺序执行,可是我们运行代码观察到的现象就是 sleep 先休眠 然后打印啊。
实际上,printf 已经先执行了,只是这个 "hello word!" 没有立马被显示出来罢了!
当我们 sleep 时也没有显示,当我们 sleep 完甚至到程序退出后,这个 "hello word!" 才显示出来。这个时候如果打印的消息如果没有立即被显示出来,
在 sleep 执行期间它最后显示出来证明了它的存在,
但是 sleep 内它并没有显示出来,那么问题来了 —— 这个 "hello word! 在哪?
看标题就猜到,"hello word! 在缓冲区
3.1 缓冲区的概念
什么是缓冲区?这个缓冲区在哪里?缓冲区其实说白了,就是一段内存空间。
既然是内存空间,那我们就能理解刚才举的例子里的 "hello word!"数据是放在了内存空间里。只要在内存里就没有打印出来。
缓冲区的理解:就是一段内存空间。立马将内存中的空间显示出来 刷新策略
我们今天不探讨什么策略,就往显示器打印这个点来说,我们只关注一种策略:行刷新
所谓的行刷新,就是你要输出的一个行字符串当中,看它是不是一个完整行,
如果是一个完整行,就会立马刷新出来;如果不是,就不刷新,让它去到缓冲区,
等缓冲区变满了或者程序退出了,再或者碰到换行服务,再把它一块送出去。
那么,如何证明你一个文本是完整的一行呢?
这也很简单,只要你打印的内容包含 \n,包含 \n 在内的之前的所有内容成为一行。
不是直接把数据刷到我们外设上, 还是把数据先放到缓冲区里,只不过因为你有 \n,
它就立马根据刷新策略,把内容给你刷新出来,仅此而已。
如果我不想用 \n,我就想让我的数据立马刷新出去(立马显示出来)呢?
这里就说来话长了,我们不得不说一下 stdin、stdout 和 stderr 的知识。
在C语言说到过:

这篇文章也说到过关于缓冲区的概念:
C语言进阶⑲(文件下篇)(文件读写+文本文件和二进制文件+EOF+文件缓冲区)__GR的博客-CSDN博客
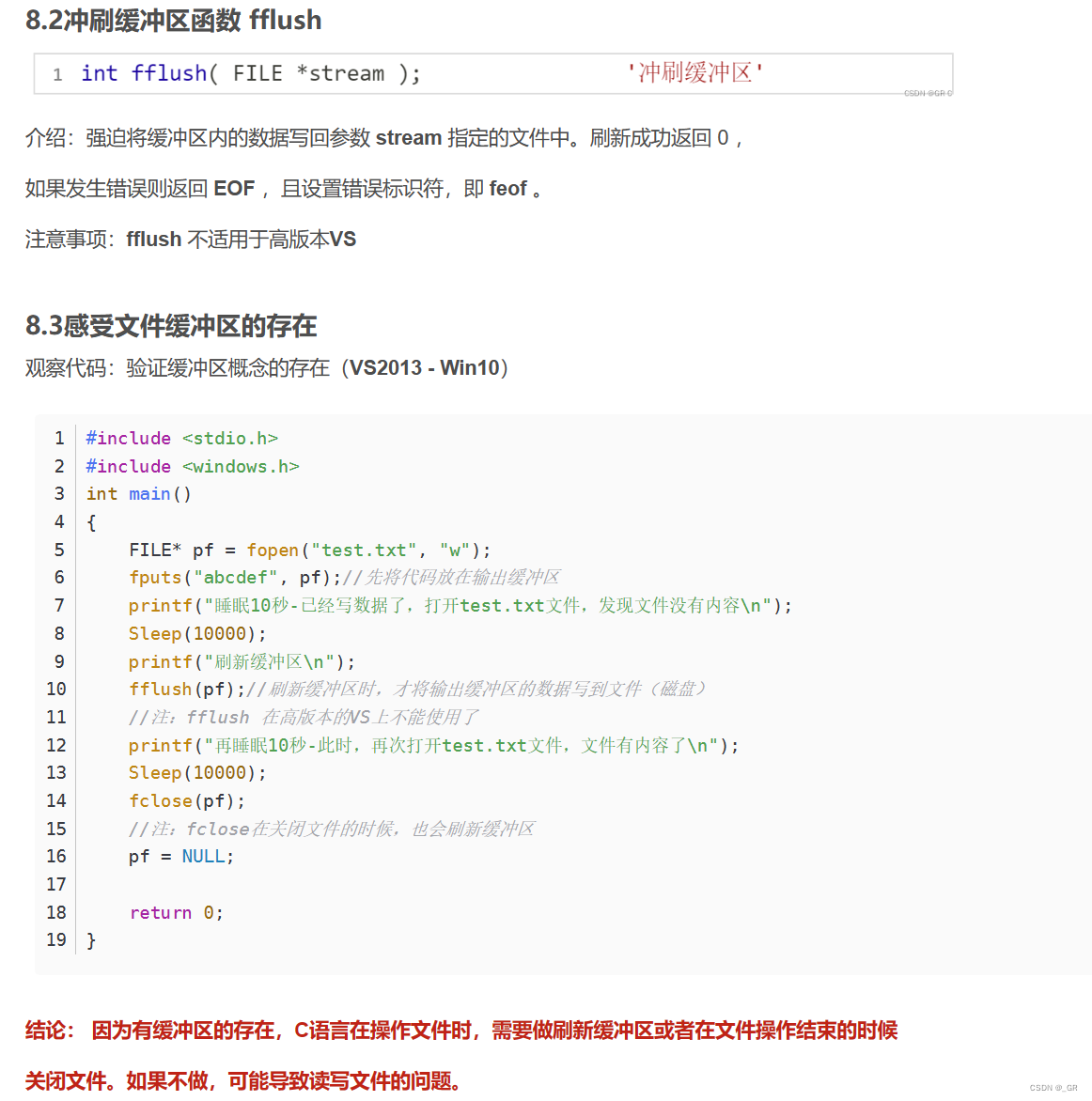
如果你仔细观察你会发现它的参数和我们 stdin、stdout 和 stderr 类型是一样的,都是 FILE*
实际上所有的 printf 底层打印的都是往 stdout 里丢的
用一下fflush解决上面问题:
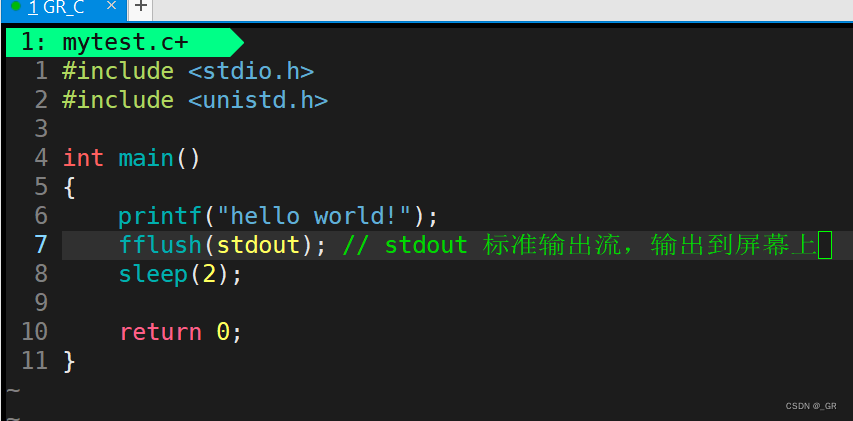
此时运行就行先打印到屏幕再睡眠两秒了。
3.2 实现一个简易 "进度条"
回车和换行的概念
在实现简易 "进度条" 之前,我们还需要讲解一下回车和换行的概念。
你认为回车和换行是一个概念吗?
回车:将光标拨回到当前行的最开始(最左侧)
换行:新起一行(并不影响光标的位置)
我们所理解的 "换行" 并不是这里的换行,想达到我们所理解的 "换行" 效果,即新起一行并将光标拨回最开始位置,就需要:回车+换行
我们在 C语言中经常使用的 \n 其实就是 "回车 + 换行",回车对应的是 \r。
为了写 "进度条",我们先来模拟一下 "倒计时",以前可能是这么写的:

输出结果:
但是我们的倒计时应该是在一个地方倒计时的,应该不需要换行,所以使用\r解决:

此时运行发现什么都没有显示出来:
10秒后程序结束:
这是因为前面讲到的:行刷新,就是你要输出的一个行字符串当中,看它是不是一个完整行,
如果是一个完整行,就会立马刷新出来;如果不是,就不刷新,让它去到缓冲区,
这里\r只是回车并没有换行所以缓冲区的内容一直没有输出,此时要加上fflush:
此时就会在一个地方倒计时直到0,然后退出程序了:



开始实现想要的简易进度条:

在这里面改的话,进度百分比应该行了,先来弄进度图:

运行:

此时进度图也差不多了,就是太慢了,这里使用usleep函数,按照微秒为单位去休眠,
我们 usleep(20000) ,能让它 2 秒内跑完。然后加上不会停的旋转效果:
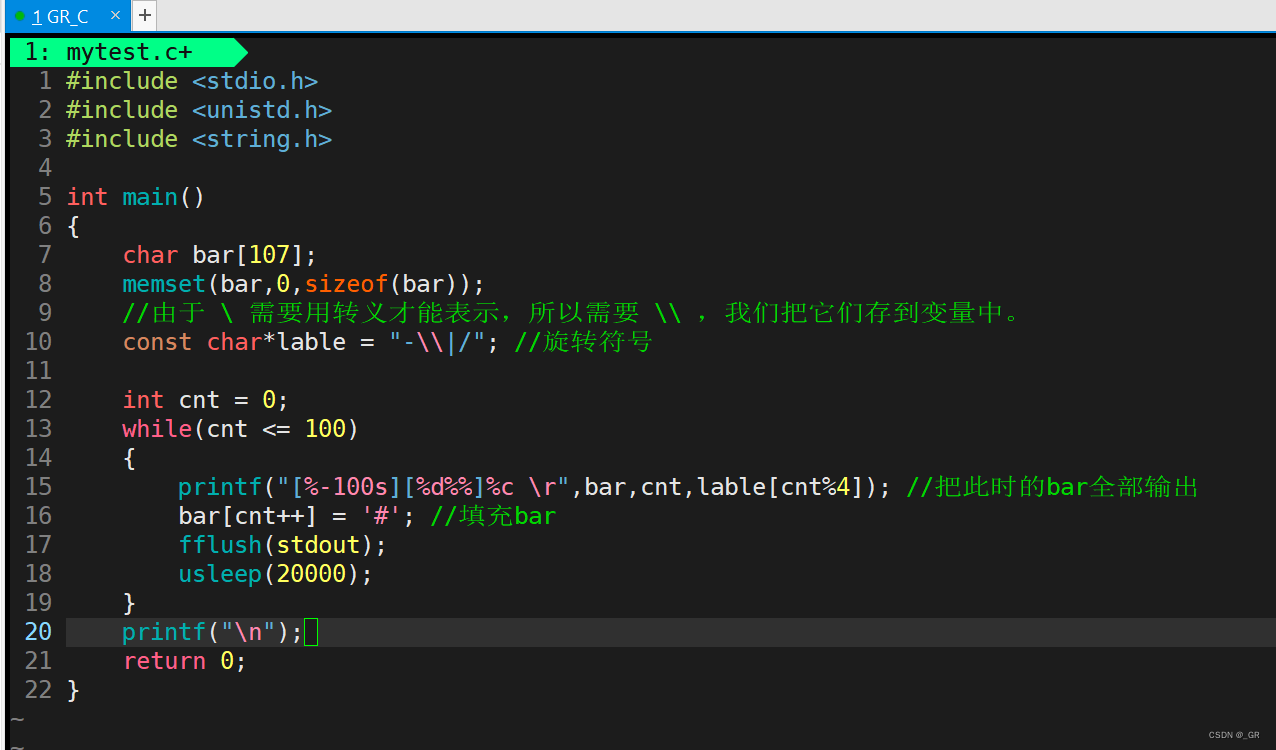
运行:

完成。我是完成了,各位去试试吧,\又傲娇。
4. 版本控制器Git
4.1 Git的概念和准备工作
(有兴趣的可以去查一查Git的起源)
Git 是一个免费的开源分布式版本控制系统,旨在快速高效地处理从小型项目到大型项目的所有内容。
Git 依赖于软件分布式开发的基础,其中不止一个开发人员可以访问特定应用程序的源代码并可以修改其他开发人员可能看到的更改。
最初由 Linus Torvalds 于 2005 年为 Linux 内核开发而设计和开发。
每个 git 工作目录都是一个成熟的存储库,具有完整的历史记录和完整的版本跟踪功能,独立于网络访问或中央服务器。
Git 允许一群人一起工作,所有人都使用相同的文件。它还可以帮助团队应对多人编辑同一文件时容易出现的混乱。Git 是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码的版本控制软件。
Git 允许用户在开发过程中跟踪文件的更改,并在需要时回滚到之前的版本。
这样可以在团队协作开发时避免冲突,并保证项目的完整性。
Git常用的两个网页是Github 和 gitee,Github是国际版的,现在网络不稳定了,所以我们用gitee演示,(没有账号的去注册账号)
这里直接在gitee主页右上角创建一个仓库,将仓库的地址复制下来。
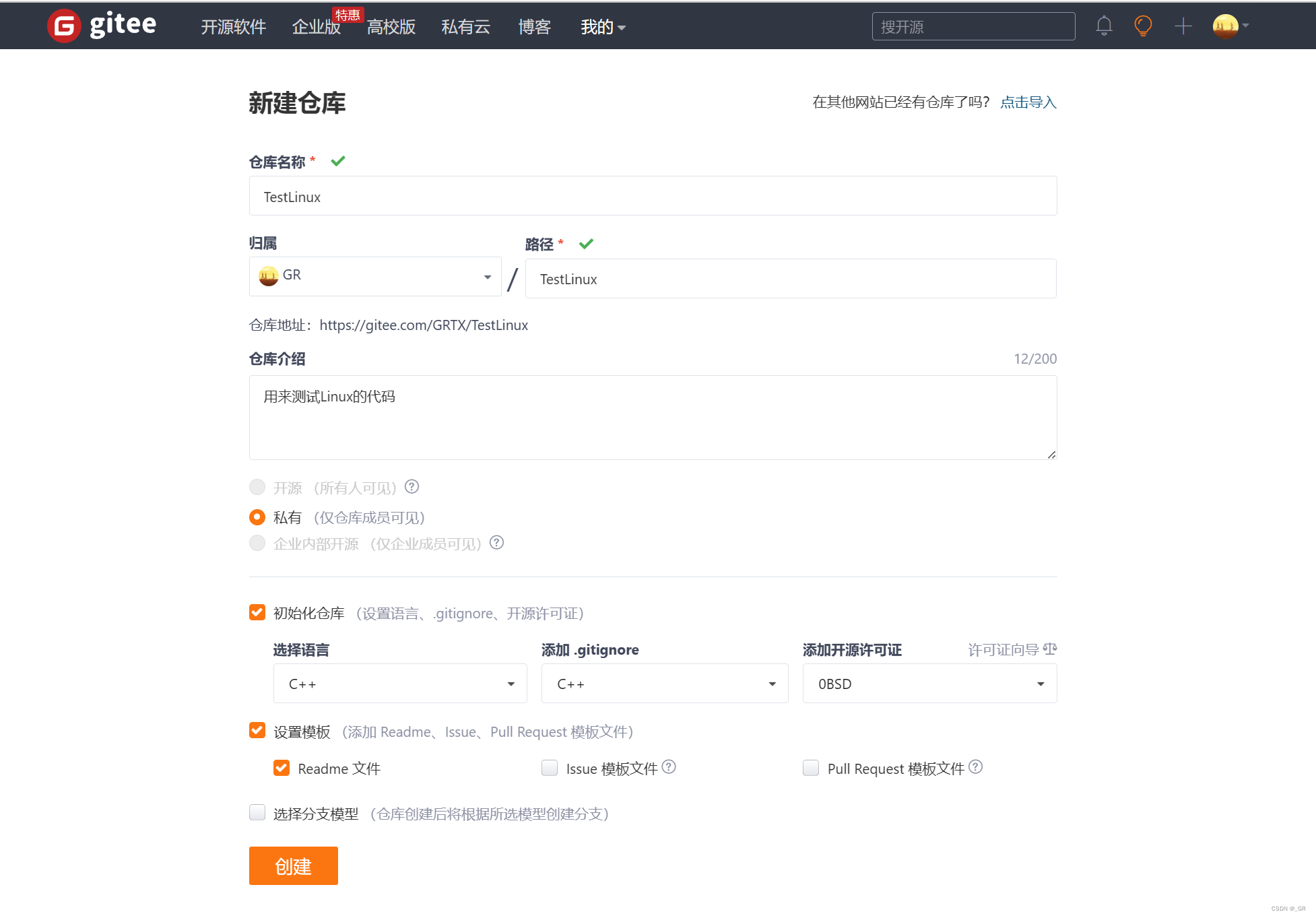
点击创建:

在命令行中输入git clone 复制的仓库地址,此时在我们的系统上就会创建一个本地仓库,这个仓库是和gitee上的远端仓库同步的,这里需要输入gitee的用户名和密码:

此时刚刚的目录下就多了一个目录,这个目录就是本地仓库,所以仓库的实质就是一个目录。

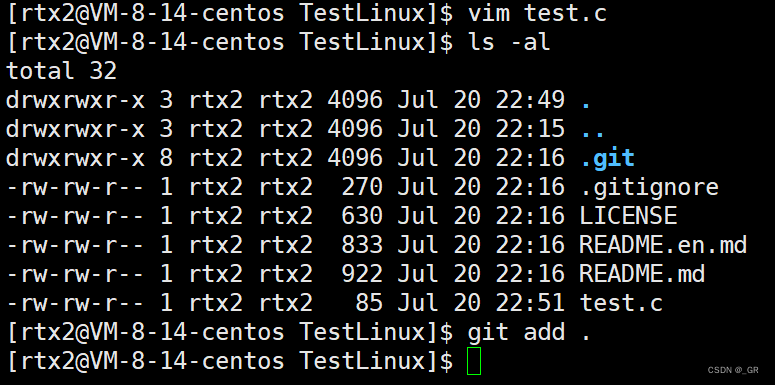
在这个目录下创建一个文件,随便写一点代码,然后使用git 三板斧:
4.2 git 三板斧
三板斧第一板斧:git add:
- 用法:git add 文件名
- 将文件放在创建好的本地仓库中

这里使用的文件名是一个点,git会自动判断,将当前目录下,并且在本地仓库中没有的文件全部放进本地仓库中。(此时也就相当于git add test.c)
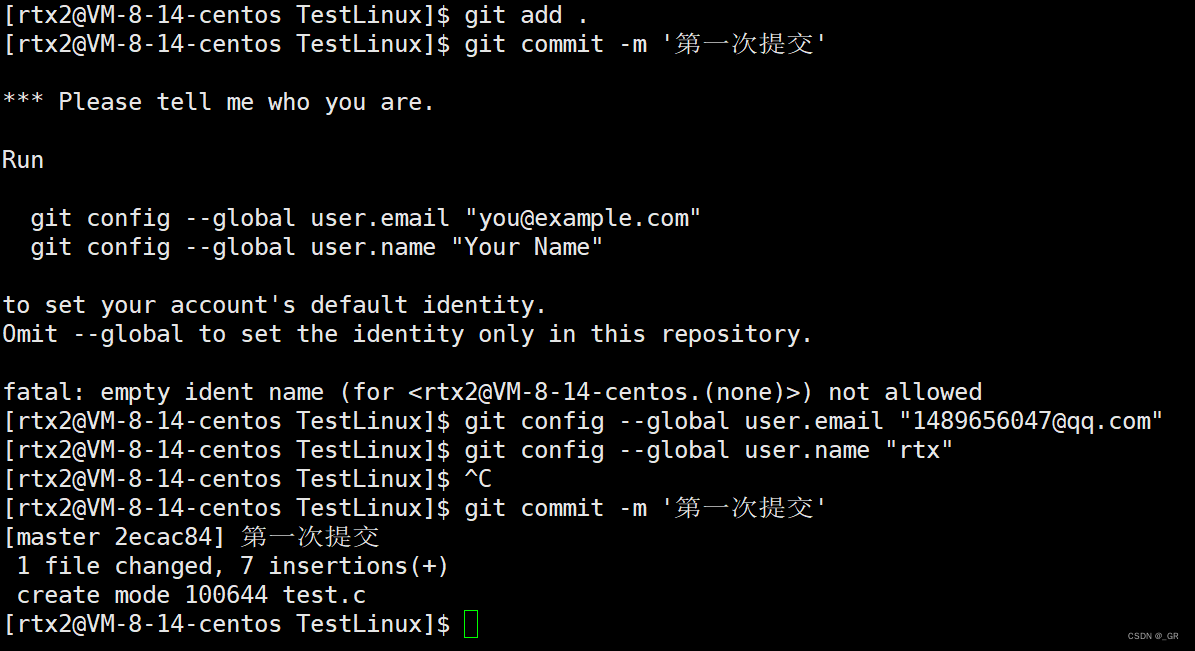
三板斧第二板斧:git commit :
- 用法:git commit -m ‘提交日志’
- 功能:将文件中的改动提交到本地仓库,会自动更新已经放在本地仓库中的内容。
- 注意:-m后的单引号中的提交日志一定不要乱写,一般写你对代码修改了什么

此时因为是第一次使用,需要Run一下那两个命令,其中两个双引号里面分别是你的邮箱和你的名字。因为这是多人合作的,别人可能想看这次修改是谁修改的,可以找到你。
三板斧第三板斧:git push:
- 用法:git push
- 功能:将本地仓库中的内容和gitee上远端仓库的内容保持一致。
执行该指令以后,会让你输入用户名和密码,然后就成功将本地仓库中的文件提交到了远端仓库。
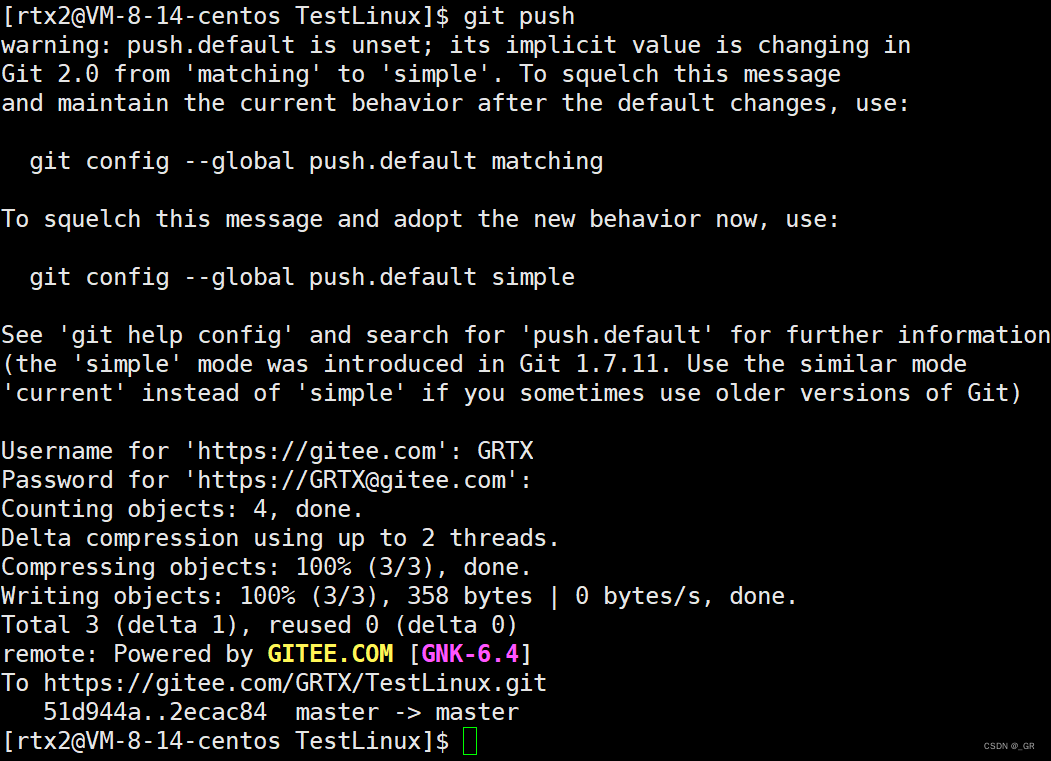
此时在远端的仓库就可以看到我们的文件:
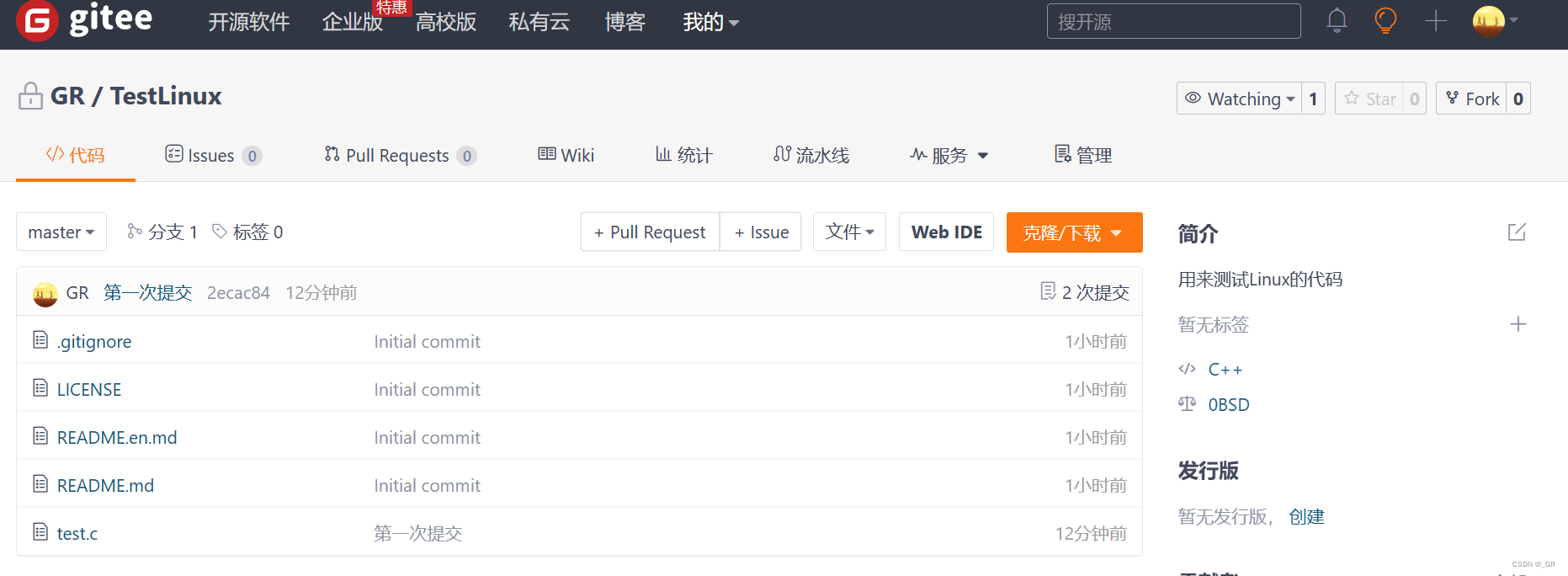
点进去:
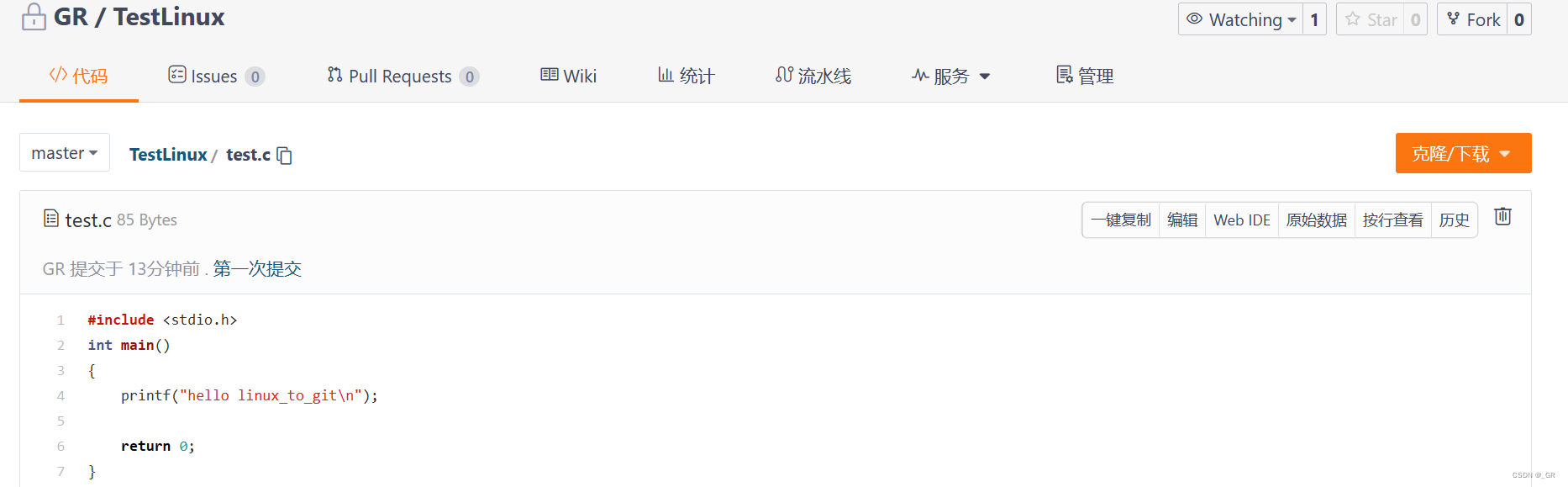
还有查看提交记录:git log:

4.3 git pull和.gitignore等
还有多人做项目时需要用到的git pull:将远端仓库内容拉到本地仓库(更新,同步)
这个情况是一个新的文件使用三板斧上传到远端仓库的时候,提示有冲突,无法上传,这是因为,远端仓库中有修改的内容,本地仓库还没有和远端同步,所以需要先同步,也就是将远端仓库中的改动拉到本地仓库。
还有删除,重命名:git rm/mv 文件名,等等这里就不演示了
另外,在本地仓库中,有一个.gitignore的隐藏文件。
在上传一个文件的时候,这个文件中有各种类型的文件,而我们上传的只是源代码之类的有用的文件,如果一个文件一个文件上传的话又非常的繁琐,而.gitignore文件就是用来解决这个问题的。
用vim打开看看:
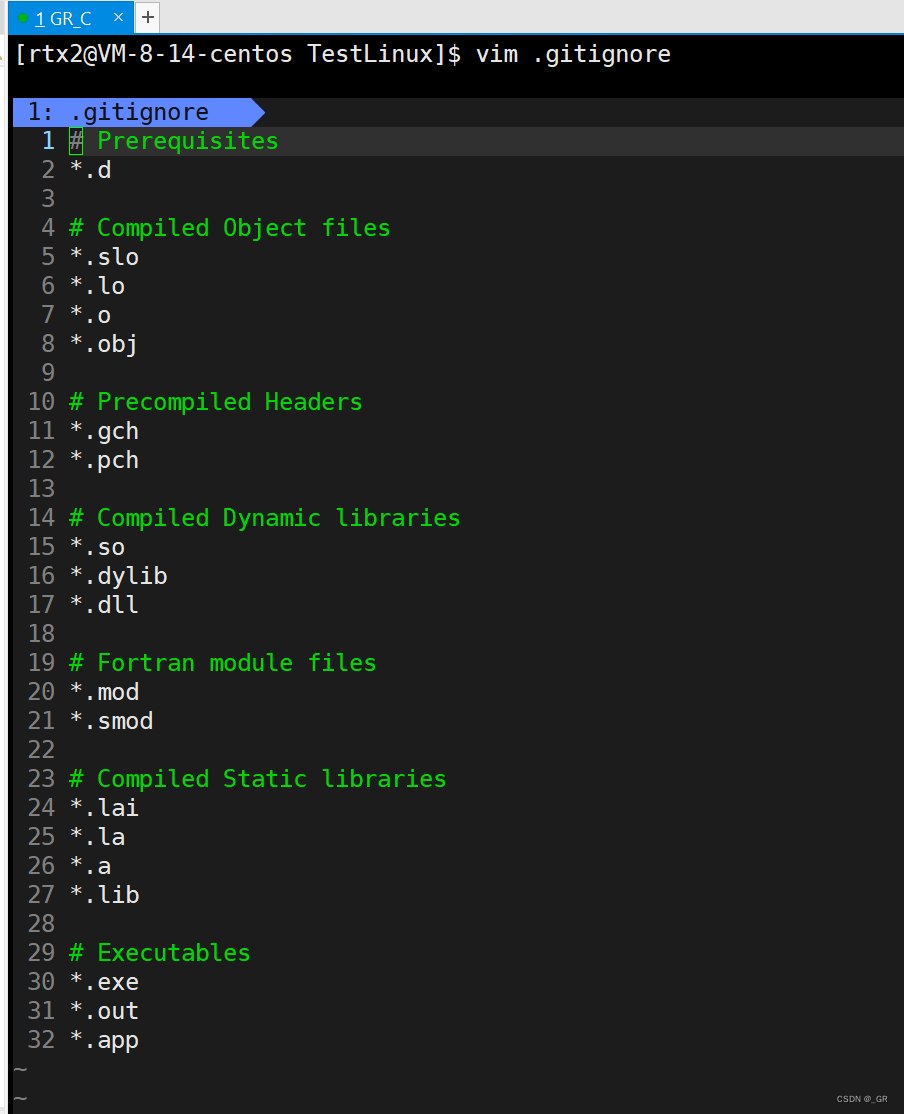
此时以这里面的任何一个为后缀的文件都不会上传到远端仓库。
为了演示一下和使用一下三板斧,这里我们写上一些东西:

然后:wq保存退出,创建四个后缀不一样的文件,用三git板斧上传:
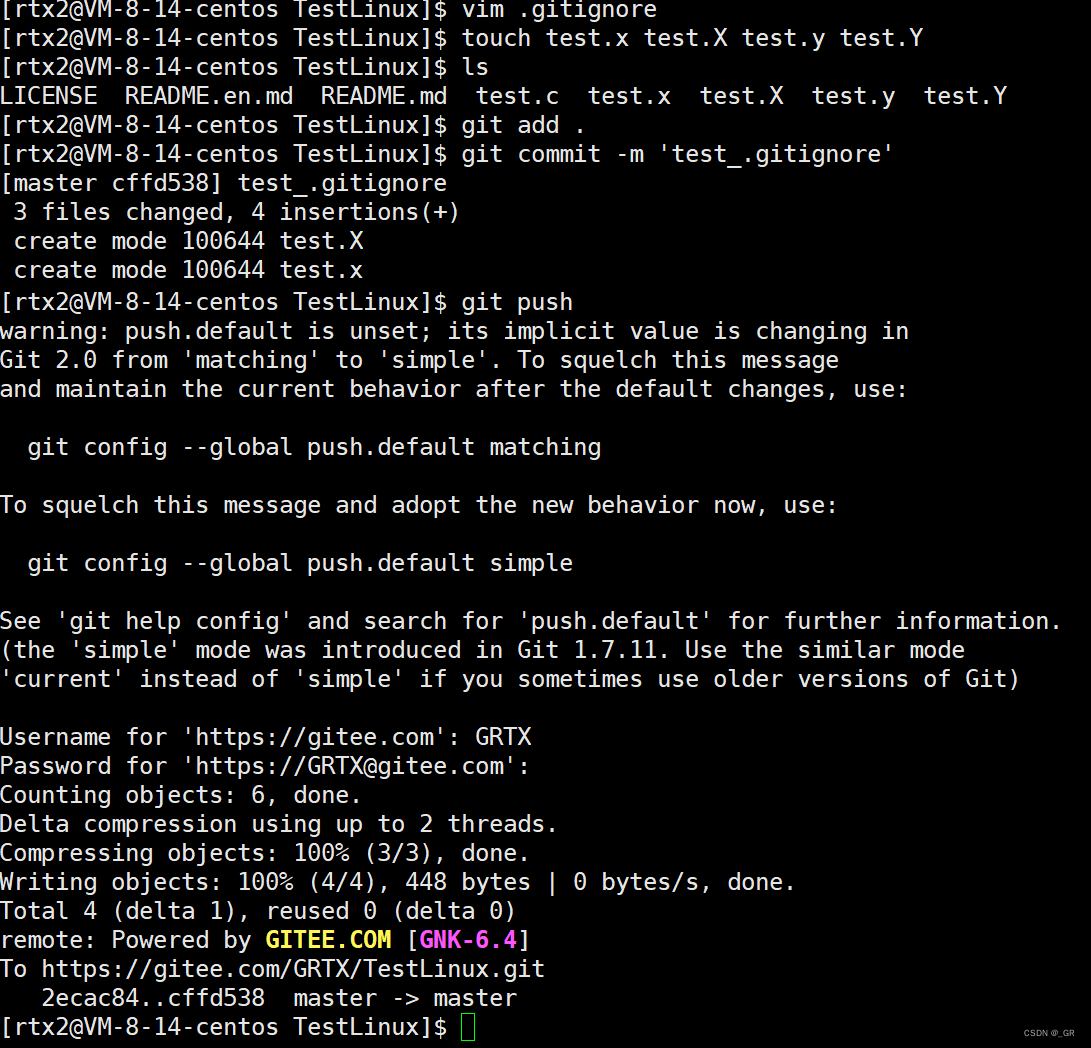
此时分别以大小写X为后缀的文件就上传到远端了,而分别以大小写Y为后缀的就没有上传:

所以.gitignore的作用就是用来配置哪些文件类型是上传的,哪些文件类型是不上传的。gitee中一般只上传源代码,一些没必要的文件就不要上传了,VS默认上传了很多没必要的文件,也可以去改一改。
5. 相关笔试题
(想对着答案看可以开两个网页)
1. vim编辑器中,删除一行的命令是( )
A.rm
B.dd
C.yy
D.pp
2. 以下描述正确的是( )[多选]
A.在Centos中可以使用yum install 命令安装软件包
B.在Centos中可以使用yum uninstall 命令卸载软件包
C.在Centos中可以使用yum list 查看所有可安装软件包
D.在Centos中可以使用yum show查看所有可安装软件包
3. 以下命令正确的是( )[多选]
A.yum makecache命令的功能是将服务器的软件包信息缓存到本地
B.yum search命令可以在所有软件包中搜索包含有指定关键字的软件包
C.yum clean all 命令可以清除缓存中老旧的头文件和软件包
D.yum upgrade命令可以更新所有的rpm软件包
4. vim编辑器中,怎样将字符AAA全部替换成yyy( )
A.p/AAA/yyy/
B.s/AAA/yyy/g
C.i/AAA/yyy/
D.p/AAA/yyy/h
5. 你使用命令”vi/etc/inittab”查看该文件的内容,你不小心改动了一些内容,为了防止系统出为,你不想保存所修改的内容,你应该如何操作()
A.在末行模式下,键入:wq
B.在末行模式下,键入:q!
C.在末行模式下,键入:x!
D.在编辑模式下,键入”ESC”键直接退出vi
6. 将一个test.c文件仅仅进行汇编而不生成可执行程序的命令是( )
A.gcc -S test.c
B.gcc -E test.c
C.gcc -c test.c
D.gcc test.c
7. 在编译过程中,产生parse tree的过程是哪个阶段( )
A.语法分析
B.语义分析阶段
C.词法分析
D.目标代码生成阶段
8. 程序的完整编译过程分为是:预处理,编译,汇编等,如下关于编译阶段的编译优化的说法中不正确的是( )
A.死代码删除指的是编译过程直接抛弃掉被注释的代码
B.函数内联可以避免函数调用中压栈和退栈的开销
C.for循环的循环控制变量通常很适合调度到寄存器访问
D.强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令
9. 若基于Linux操作系统所开发的源文件名为test.c,生成该程序代码的调试信息,编译时使用的GCC命令正确的是( )
A.gcc -c -o test.o test.c
B.gcc -S -o test.o test.c
C.gcc -o test test.c
D.gcc -g -o test test.c
10. 下列关于makefile描述正确的有( )[多选]
A.makefile文件保存了编译器和连接器的参数选项
B.主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释
C.默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件, 找到了解释这个文件
D.在Makefile不可以使用include关键字把别的Makefile包含进来
11. 下列关于make/Makefile描述正确的有( )[多选]
A.make会生成Makefile中定义的所有目标对象
B.make会自动根据依赖对象检测目标对象是否需要重新生成
C.Makefile中伪对象的功能是目标对象存在则不需要生成
D.Makefile中声明伪对象使用 .PHONY
12. 以下哪项命令可以完成, 在gdb调试中,查看断点信息的功能( )
A.bt
B.show break
C.set scheduler-locking off
D.info break
答案及解析
1. B
A rm 没有这个指令
B dd 删除光标所在行内容
C yy 复制光标所在行内容
D pp 没有这个指令
2. AC
yum工具的常用选项有:
install 表示安装软件包
list 列出所有可供安装的软件包
search 搜索包含指定关键字的软件包
remove 卸载指定的软件包
根据常用操作的选项可排除出B和D是错误的。yum不具备这两个操作选项
3. ABC
yum工具在每次安装指定软件包的时候,都会检测源服务器上的软件包信息,为了便捷不用每次都去搜索软件包信息,因此使用 yum makecache将软件包信息缓存到本地,使用 yum clean all 清理老旧的缓存信息。因此A和C是正确的
yum search 用于在搜索包含有指定关键字的软件包,B也是正确的
D选项:yum -y update:升级所有包同时,也升级软件和系统内核;
yum -y upgrade:只升级所有包,不升级软件和系统内核,软件和内核保持原样。
4. B
在vim的底行模式中,
:s 表示substitute,也就是替换, 格式为以下
:[range]s[ubstitute]/{pattern}/{string}/[flags] [count]
range 表示区间 % 用于表示全文, 2,3 表示从第2行开始到第3行
{pattern} 表示字符串匹配规则,要匹配什么样的字符串 , 比如^a 表示以a字符起始的字符串
{string} 表示要将匹配到的字符串替换为的新的string字符串
[flags] s_flags中,g比较常用,通常使用g表示全部替换,默认如果不给的话,表示只替换一次
[count] 表示在一行中匹配多少次,很少会用到....
如果想要将文件中所有 nihao 替换为 hello 则命令为: %s/nihao/hello/g
:p 用于打印指定区间的行
:[range]p[rint] [flags]
:i 在指定行上方添加文本
:{range}i[nsert][!]
5. B
A 在末行模式下,键入:wq 保存并退出编辑,就算没有修改也会写入,并修改文件时间属性
B 在末行模式下,键入:q! 强制退出编辑,但并不保存当前修改
C 在末行模式下,键入:x! 保存并退出编辑,仅当文件有修改时会保存,并修改文件时间属性
D 在编辑模式下,键入”ESC”键并非直接退出vi编辑,而是用于返回普通模式
6. C
gcc常见选项:
-c 汇编完成后停止,不进行链接
-E 预处理完成后停止,不进行编译
-S 编译完成后停止,不进行汇编
-o 用于指定目标文件名称
-g 生成debug程序。向程序中添加调试符号信息
题目要求为仅执行到汇编就结束,而不生成可执行程序,因此选择C选项。
7. A
- 编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化;
- 扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型
- 语法分析是根据语法规则,将输入的语句构建出分析树,或者语法树,也就是我们答案中提到的分析树parse tree或者语法树syntax tree
- 语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的
- 目标代码生成指的是,把中间代码变换成为特定机器上的低级语言代码。
8. A
- 死代码删除是编译最优化技术,指的是移除根本执行不到的代码,或者对程序运行结果没有影响的代码,而并不是删除被注释的代码,因此A选项错误
- 内联函数,也叫编译时期展开函数, 指的是建议编译器将内联函数体插入并取代每一处调用函数的地方,从而节省函数调用带来的成本,使用方式类似于宏,但是与宏不同的是内联函数拥有参数类型的校验,以及调试信息,而宏只是文本替换而已。因此B选项正确
- for循环的循环控制变量,通常被cpu访问频繁,因此如果调度到寄存器中进行访问则不用每次从内存中取出数据,可以提高访问效率,因此C选项正确
- 强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令,比如 num % 128 与 num & 127 相较,则明显&127更加轻量, 故D也是正确的
9. D
- gcc常见选项:
- -c 汇编完成后停止,不进行链接
- -E 预处理完成后停止,不进行编译
- -S 编译完成后停止,不进行汇编
- -o 用于指定目标文件名称
- -g 生成debug程序。向程序中添加调试符号信息
10. ABC
- makefile文件中,保存了编译器和链接器的参数选项,并且描述了所有源文件之间的关系。make程序会读取makefile文件中的数据,然后根据规则调用编译器,汇编器,链接器产生最后的输出。根据makefile的功能理解,A选项是正确的
- Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释, B选项是正确的
- 显式规则说明了,如何生成一个或多个目标文件。
- make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写makefile,比如源文件与目标文件之间的时间关系判断之类
- 在makefile中可以定义变量,当makefile被执行时,其中的变量都会被扩展到相应的引用位置上,通常使用 $(var) 表示引用变量
- 文件指示。包含在一个makefile中引用另一个makefile,类似C语言中的include; 根据这一项可以推导D选项是错误的。
- 注释,makefile中可以使用 # 在行首表示行注释
- 默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件,C选项也正确
11. BD
- make的执行规则是,只生成所有目标对象中的第一个,当然make会根据语法规则,递归生成第一个目标对象的所有依赖对象后再回头生成第一个目标对象,生成后退出。因此A选项错误。
- make在执行makefile规则中,根据语法规则,会分析目标对象与依赖对象的时间信息,判断是否在上一次生成后,源文件发生了修改,若发生了修改才需要重新生成。因此B选项正确
- makefile中的伪对象表示对象名称并不代表真正的文件名,与实际存在的同名文件没有相互关系,因此伪对象不管同名目标文件是否存在都会执行对应的生成指令。伪对象的作用有两个,1. 使目标对象无论如何都要重新生成。2. 并不生成目标文件,而是为了执行一些指令。 根据对伪对象的理解,C选项错误
- makefile中使用 .PHONY 来声明伪对象, .PHONY: clean。 D选项正确
12. D
- A bt 查看函数调用栈
- B show break info break 用于查看断点信息
- C set scheduler-locking off 用于后期多线程调试,关闭调度锁(所有线程同步执行)
- D info break 查看断点信息
本篇完。
下一篇:零基础Linux_7(进程)冯诺依曼结构+操作系统原理+进程的概念和基本操作。