目录标题
- VGG
- 参考
- VGG网络贡献
- 使用尺寸更小的$3 \times 3$卷积串联来获得更大的感受野
- 放弃使用$11 \times 11$和$5 \times 5$这样的大尺寸卷积核
- 深度更深、非线性更强,网络的参数也更少;
- 去掉了AlexNet中的局部响应归一化层(LRN)层。
- 网络结构
- 主要改进
- 输入去均值
- 小卷积核串联代替大卷积核
- 无重叠池化
- 卷积核个数逐层增加
VGG
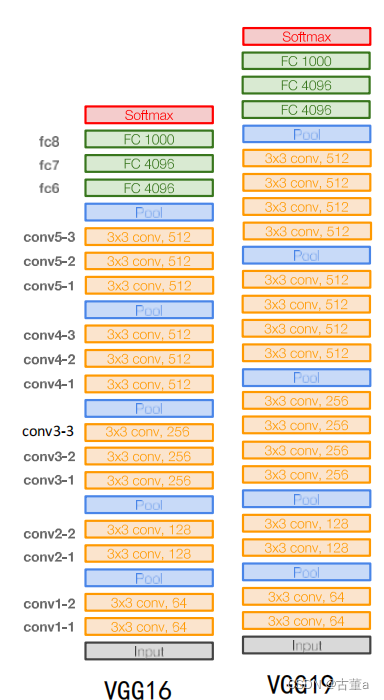
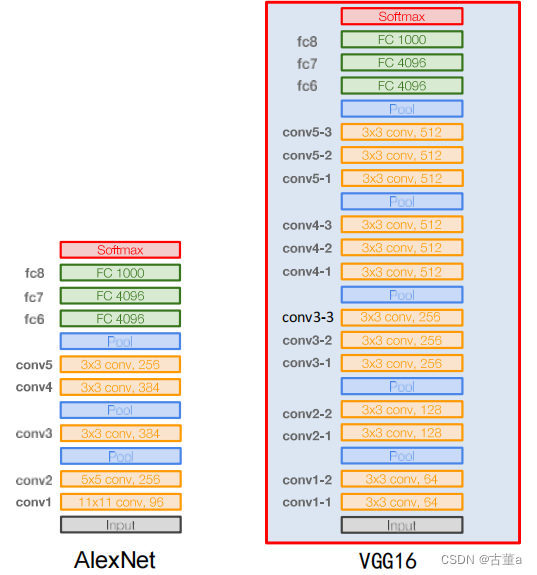
VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
参考
论文地址
一文读懂VGG网络
VGG网络贡献
使用尺寸更小的 3 × 3 3 \times 3 3×3卷积串联来获得更大的感受野
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以额增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
放弃使用 11 × 11 11 \times 11 11×11和 5 × 5 5 \times 5 5×5这样的大尺寸卷积核
使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
2个
3
×
3
3 \times 3
3×3卷积核串联,感受野为
5
×
5
5 \times 5
5×5
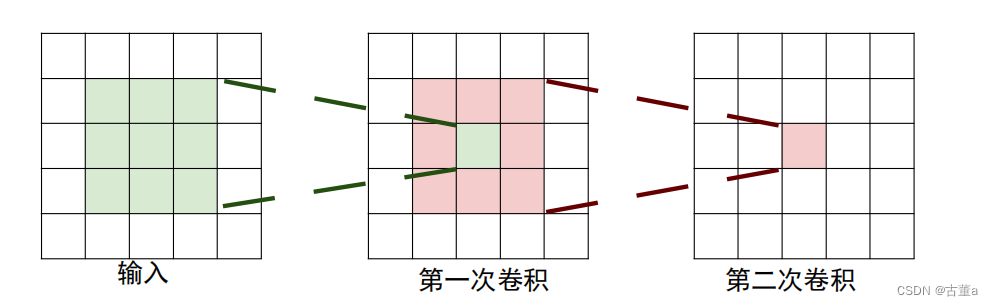
3个
3
×
3
3 \times 3
3×3卷积核串联,感受野为
7
×
7
7 \times 7
7×7
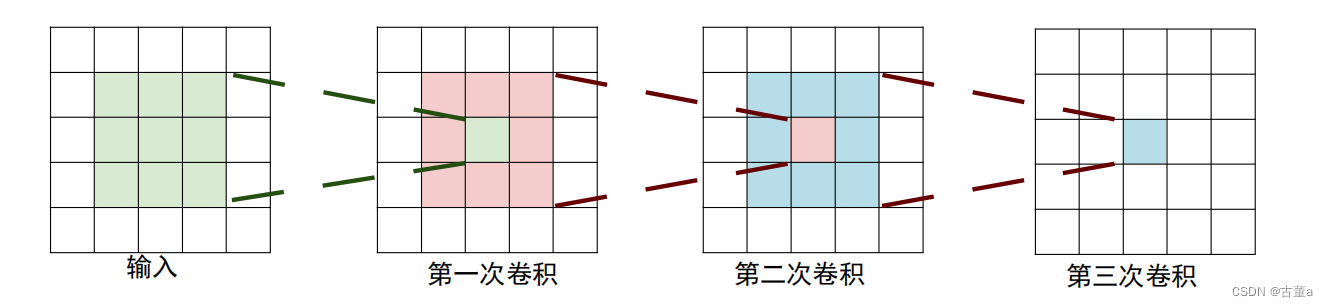
深度更深、非线性更强,网络的参数也更少;
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为
(
3
×
3
×
C
)
×
C
×
3
=
27
C
2
(3 \times 3 \times C) \times C \times 3 = 27C^2
(3×3×C)×C×3=27C2
如果直接使用7x7卷积核,其参数总量为
(
7
×
7
×
C
)
×
C
=
49
C
2
(7 \times 7 \times C) \times C = 49C^2
(7×7×C)×C=49C2 ,这里 C 指的是输入和输出的通道数。
很明显, 27 C 2 27C^2 27C2小于 49 C 2 49C^2 49C2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
去掉了AlexNet中的局部响应归一化层(LRN)层。
网络结构

1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
主要改进
输入去均值
AlexNet和ZFNet的输入去均值:求所有图像向量的均值,最后得出一个与原始图像大小相同维度的均值向量。
VGG输入去均值:求所有图像向量的RGB均值,最后得到的是一个3×1的向量 [R,G,B]
小卷积核串联代替大卷积核
增加了非线性能力。
多个小尺寸卷积核串联可以得到与大尺寸卷积核相同的感受野。
与高斯核不同,高斯核中两个小卷积核组合卷积核大卷积核卷积结果相同。但是卷积神经网络中的卷积核,多个小卷积核组合和大卷积核结果不同,但是感受野相同。
无重叠池化
窗口大小为2×2,步长为2。
卷积核个数逐层增加
前层卷积核少,是因为前层学习到的是图像的基元(点、线、边),基元很少,所以不需要很多的神经元学习,又前层的图像都比较大,若神经元很多,计算量会很大(K×m×m×D×K×n×n)。到后面的层时,包含很多的语义结构,需要更多的卷积核学习。
为什么在VGG网络前四段里,每经过一次池化操作,卷积核个数就增加一倍?
1、池化操作可以减少特征图尺寸,降低显存占用
2、增加卷积核个数有助于学习更多的结构特诊,但会增加网络参数数量以及内存消耗
3、一减一增的设计平衡了识别精度与存储、计算开销
最终提升了网络性能
为什么卷积核个数增加到512后就不再增加了?
1、第一个全连接层含102M参数,占总参数个数的74%
2、这一层的参数个数是特征图的尺寸与个数的乘积
3、参数过多容易过拟合,且不易被训练
如果将最后一层卷积核个数增加至1024,这一层参数个数为: 7 × 7 × 1024 × 4096 = 205520896 ≈ 200 M 7 \times 7 \times 1024 \times 4096 = 205520896 \approx 200M 7×7×1024×4096=205520896≈200M






![计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-卷积-[北邮鲁鹏]](https://img-blog.csdnimg.cn/053b4862d7574c61876343a6cf7460fc.png)