可变参数列表
- 一、可变参数列表的使用
- 1、可变参数列表的形式
- 2、可变参数列表的提取
- 3、使用演示
- 4、利用可变参数实现一个简单的日志打印功能
- 二、可变参数列表的原理
- 1、原理的讲解
- 2、原理的证明
一、可变参数列表的使用
1、可变参数列表的形式
有时我们在使用C语言时可能会碰到这样的情况,希望函数带有可变数量的参数,而不是预定义数量的参数。
为此C 语言为这种情况提供了一个解决方案,它允许您定义一个函数,能根据具体的需求接受可变数量的参数。
使用方式为:
int func(int arg1, ...);
其中,省略号...表示可变参数列表,需要注意的是:如果你想使用可变参数列表,则至少有一个固定参数,即不存在下面的函数:
int func(...);
我们C语言常用的printf和scanf函数就是使用了可变参数列表的函数:

2、可变参数列表的提取
对于可变参数列表,我们最关心的还是怎么将可变参数提取出来,关于可变参数的提取主要依赖一个类型和四个宏函数:va_list,va_start,va_arg,va_copy,va_end,而这些类型和宏函数在C语言的头文件stdarg.h中。
- 类型
va_list本质是一个char*类型,我们要使用可变参数列表,必须首先定义一个va_list类型的变量。
va_list ap;

- 给
va_list类型的变量初始化的函数是va_start函数,初始化以后va_list类型的变量指向第一个可变参数的首地址,该函数的函数原型如下:
void va_start(va_list ap, last);
ap: 这是一个va_list类型的对象。last是最后一个传递给函数的已知的固定参数,即省略号之前的参数。
- 用来提取可变参数列表中的参数的函数是
va_arg,使用一次提取一个,每次提取的参数是直接返回的并且该函数提取的同时会自动将ap指向下一个参数。
type va_arg(va_list ap, type);
ap: 这是一个va_list类型的对象。type:要提取的参数的类型,如int , double,如果当前参数类型和type不统一,就会发生不可预知的错误
- 这个函数不是必须使用的函数,这时一个拷贝函数,初始化dest作为src(当前状态)的副本。
void va_copy(va_list dest, va_list src);
dest: 要作为副本的对象。src: 原始值
- 销毁
va_list类型变量的函数是va_end,其本质就是将指针置为NULL。
void va_end(va_list ap);
ap: 要销毁的变量。
3、使用演示
①打印每一个参数
#include <stdio.h>
#include <stdarg.h>
void PrintArg(int num, ...)
{
va_list ap;
// 1.进行初始化
va_start(ap, num);
for (int i = 0; i < num; i++)
{
// 不断取出可变参数
int a = va_arg(ap, int);
printf("%d ", a);
}
// 销毁
va_end(ap);
}
int main()
{
PrintArg(4, 1, 3, 4, 5);
return 0;
}
输出结果:

4、利用可变参数实现一个简单的日志打印功能
日志虽然很简单,但是在实际开发中,日志信息是很重要的,下面我们就来实现一个简单的日志打印函数,这里我们为了方便使用了C++的string来存储字符串,如果你没有学习过C++可以将它简单理解为char数组。
首先我们以后的消息都是要按照这种方式来进行结构化输出:
日志格式: [错误等级] [时间] :消息体
首先日志的左边是固定的,所以我们很容易实现,对于错误等级我们可以使用枚举变量的方式进行定义每一个错误等级,对于时间,我们可以使用C语言的time.h库中的函数time()和localtime()函数配合使用得到。
实现日志的关键是在于对消息体的处理,因为消息体中的数据个数的不固定的而且类型也都是不一致的,对于它们的处理我们可以将它们转换为一个长的字符串,这就需要我们使用vsnprintf函数来将不同的参数进行格式化为字符串了。
vsnprintf函数可以将可变参数,按照一定的格式,格式化为一个字符串。
int vsnprintf(char *str, size_t size, const char *format, va_list ap);
参数:
str: 缓冲区的起始地址。size: 缓冲区的大小。format: 格式化字符串。ap:可变参数。
返回值:
- 写入到缓冲区的字节数(不包括
\0),如果返回值大于等于size意味着输出被截断了。
代码实现:
#include <iostream>
#include <cstdio>
#include <cstdarg>
#include <cstring>
#include <ctime>
// 日志等级
enum { Debuge = 0, Info, Warning, Error, Fatal, Unkonw };
// 将日志等级转换为字符串
static std::string toLevelString(int level)
{
switch (level)
{
case Debuge:
return "Debuge";
case Info:
return "Info";
case Warning:
return "Warning";
case Error:
return "Error";
case Fatal:
return "Fatal";
default:
return "Unkonw";
}
}
// 获取当前时间
static std::string getTime()
{
char buf[128];
time_t timep = time(nullptr);
struct tm stdtm;
localtime_s(&stdtm, &timep);
snprintf(buf, sizeof(buf), "%d-%d-%d %d:%d:%d", stdtm.tm_year + 1900, stdtm.tm_mon + 1, stdtm.tm_mday,
stdtm.tm_hour, stdtm.tm_min, stdtm.tm_sec);
return buf;
}
// 日志打印函数
// 日志格式: [等级] [时间] :消息体
void logMessage(int level, const char* format, ...)
{
// 1.形成左边的固定格式
char logLeft[1024];
char logRight[1024];
std::string logLevel = toLevelString(level);
std::string curTime = getTime();
snprintf(logLeft, sizeof(logLeft), "[%s] [%s] : ", logLevel.c_str(), curTime.c_str());
// 2.形成右边的消息体格式
va_list ap;
va_start(ap, format);
// 利用vsnprintf函数将可变参数按照一定的格式,格式化为一个字符串。
vsnprintf(logRight, sizeof(logRight), format, ap);
va_end(ap);
// 3.进行拼接,形成完整的日志 (此处可以根据需要重定向到文件中,进行持久化保存)
printf("%s%s\n", logLeft, logRight);
}
int main()
{
// 故意制造一个失败
FILE* fp = fopen("a.txt", "r");
if (!fp)
{
logMessage(Fatal, " fopen fail : exit code %d, info : %s", errno, strerror(errno));
}
return 0;
}
输出结果:

注意事项:
-
结构体
struct tm结构体的定义:
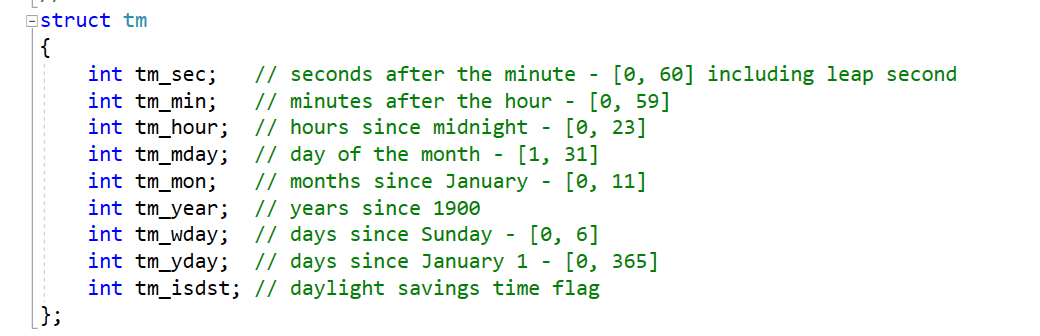
对于月数,我们要进行+1,因为其定义中包含了0月,对于年数,我们要加上1900,这样时间戳才能够正确的转换为我们想要的年数。 -
我们这里没有使用C语言的
localtime,因为其存在线程安全问题,在Linux平台下我们可以使用localtime_r代替它,在windows平台下我们可以使用localtime_s来代替它,这些代替的函数是没有线程安全的。
二、可变参数列表的原理
1、原理的讲解
这一部分涉及了函数栈帧,建议读者理解函数栈帧以后再进行观看。
首先有三个知识点:
- 对于C语言如果函数没有形式参数,也是可以给函数传递参数的。(C++是不允许的!)
- 在C语言中,只要发生了函数调用并且传递了参数,必定形成临时变量。
- 所谓的临时拷贝本质就是在栈帧内部形成的。C语言的函数参数从右向左依次形成临时变量
我们还是以这段代码为例,进行分析:
#include <stdio.h>
#include <stdarg.h>
void PrintArg(int num, ...)
{
va_list ap;
// 1.进行初始化
va_start(ap, num);
for (int i = 0; i < num; i++)
{
// 不断取出可变参数
int a = va_arg(ap, int);
printf("%d ", a);
}
// 销毁
va_end(ap);
}
int main()
{
PrintArg(4, 1, 3, 4, 5);
return 0;
}
在调用函数PrintArg时,其参数会先从右向左依次压栈:
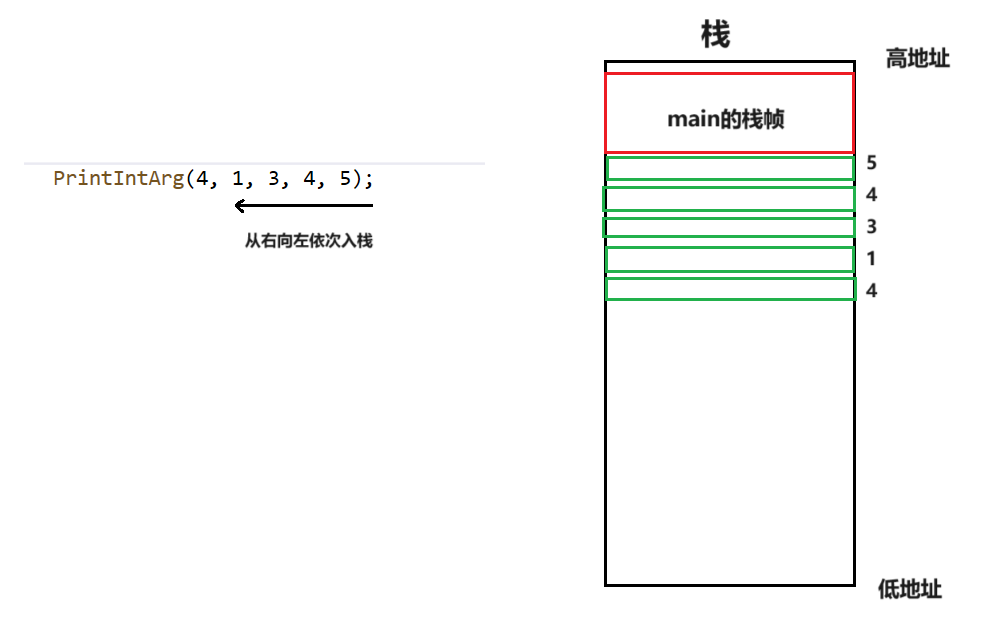
我们可以在Visual Studio中打开内存和寄存器窗口,在执行PrintArg函数时转到反汇编进行观察esp位置内存中的值的变化。
- ebp:栈底寄存器
- esp:栈顶寄存器
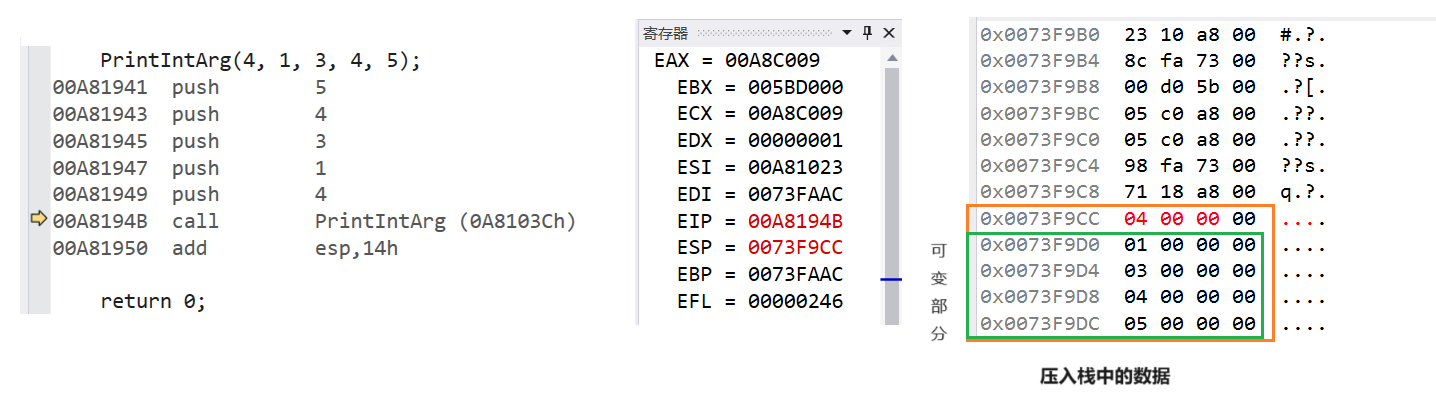
可以看到调用函数所使用的参数压入栈时数据是连续的,那么也就是说我们只要拿到第一个参数的地址,后面所有的参数我们都可以拿到,只不过需要我们在读取数据时进行一下类型转换,改变一下指针的步长,保证我们拿到完整的数据。
- 所以为什么
va_list是char *类型?
因为
char*的指针读取数据时是按照1字节进行读取的,1字节读取方便我们读取数据。
- 为什么
va_list类型的变量需要进行初始化,可变参数列表必须至少要有一个固定参数,而且va_start()函数的第二个参数必须是最后一个固定参数?
这是因为初始化的工作就是将
va_list类型的变量根据第一个固定参数,让其指向第一个可变参数。如果没有一个固定参数,就会导致va_list类型的变量不能指向第一个可变参数的地址。
- 为什么我们使用
va_arg()函数提取参数时第二个参数需要一个类型?
因为只有根据这个类型,
va_list类型的变量才知道接下来要提取的参数的大小是多少字节。
这里我们再来看下面的一个特例:
我们传入char类型的变量,然后使用int类型进行提取,故意让其不匹配。
#include <stdio.h>
#include <stdarg.h>
void PrintIntArg(int num, ...)
{
va_list ap;
// 1.进行初始化
va_start(ap, num);
for (int i = 0; i < num; i++)
{
// 注意这里我们使用int类型提取char类型的变量
int a = va_arg(ap, int);
printf("%c ", a);
}
// 销毁
va_end(ap);
}
int main()
{
char a = 'a';
char b = 'b';
char c = 'c';
char d = 'd';
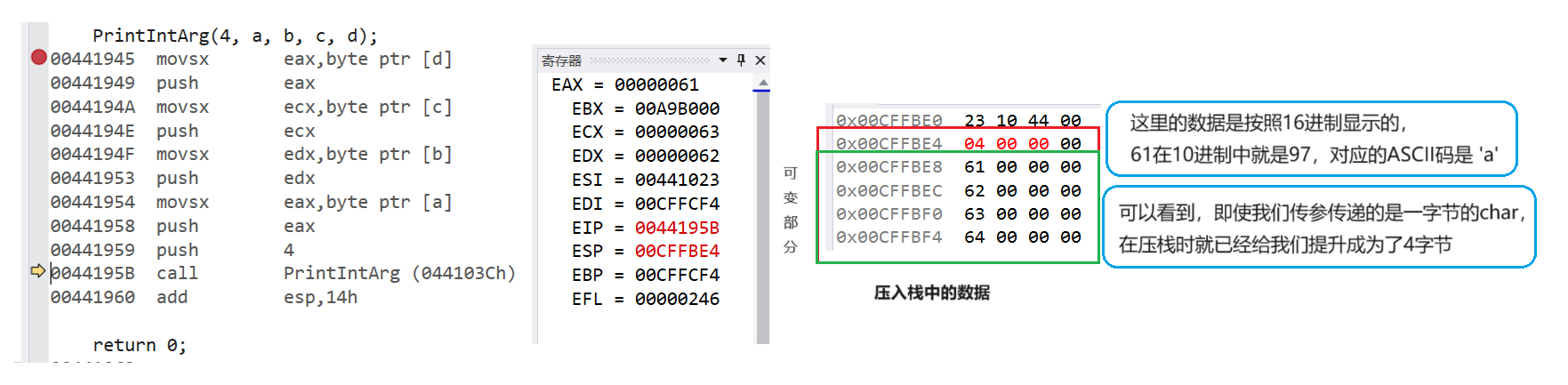
PrintIntArg(4, a, b, c, d);
return 0;
}
输出结果:

程序没有崩溃,正确的提取了我们想要的参数,为什么没有出现数据不匹配呢?
通过查看汇编,我们可以看到,在可变参数场景下:
- 实际传入的参数如果是
char,short,float,编译器在编译的时候,会自动进行整形提升(通过查看汇编,我们都能看到) - 函数内部使用的时候,根据类型提取数据,更多的是通过
int或者double来进行提取。
原理总结:
- 可变参数列表对应的函数,最终调用也是函数调用,也要形成栈帧。
- 栈帧形成前,临时变量是要先入栈的,入栈的参数之间位置关系是固定的。
- 通过上面的特例我们发现了短整型在可变参数部分,会默认进行整形提升,那么函数内部在提取该数据的时候,就要考虑提升之后的值,如果不加考虑,获取数据可能会报错或者结果不正确。
注意事项 :
- 可变参数必须从头到尾逐个访问。如果你在访问了几个可变参数之后想半途终止,这是可以的,但是,如果你想一开始就访问参数列表中间的参数,那是不行的。
- 参数列表中至少有一个固定参数。如果连一个固定参数都没有,就无法使用
va_start。 - 这些宏是无法直接判断实际存在参数的数量,提取时提取的个数由你控制,或者通过其他的方式让这些宏知道参数的个数,例如
printf()的格式控制时,就是根据%来确定参数的个数的。 - 这些宏无法判断每个参数的是类型,提取时你必须显示指定类型,或者通过其他方式让这些宏知道参数的类型,例如
printf()的格式控制中,就是根据%后面的d,s,c,lf来确定参数的类型的。 - 如果在
va_arg中指定了错误的类型,那么其后果是不可预测的。
2、原理的证明
va_start宏函数的定义:

例如下面的例子:
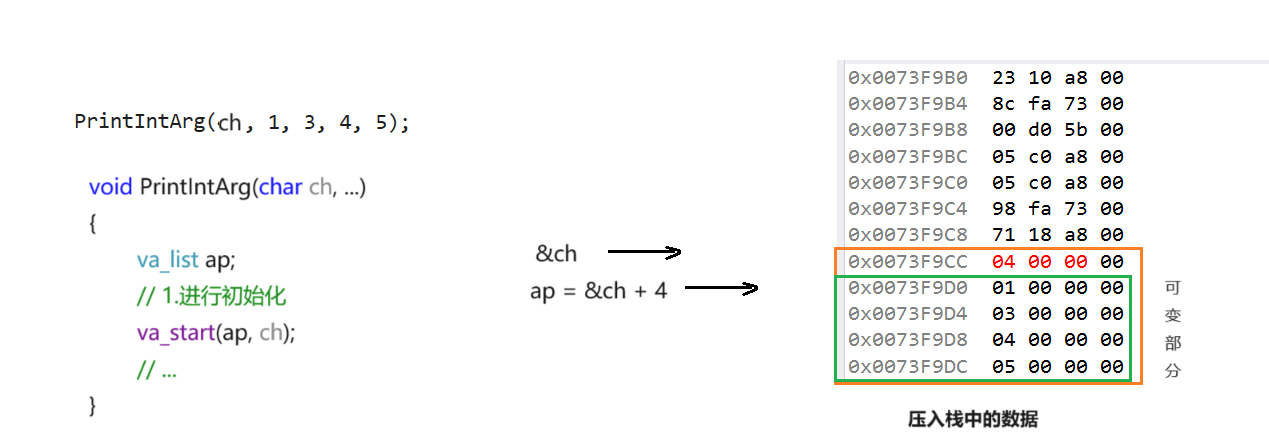
按照此宏函数的定义:我们先取出ch变量的地址,然后判断ch是否满足4字节对齐,不满足就进行提升,所以后面_INTSIZEOF(ch)的结果是4,于是ap被赋值为了第一个可变参数的地址!
va_arg宏函数的定义:


ap指针先被赋值为指向下一个参数的位置(ap已经改变了),然后再回退过去(此时ap不变),再然后利用回退过去的值进行指针类型转换,然后解引用进行提取,拿到参数。
va_end宏函数的定义:

可以看到ap指针被置空了,最前面的(void)是不想让此函数有返回值。
理解_INITSIZEOF

为了后面方便表述,我们假设sizeof(n)的值是n(char 1,short 2, int 4)我们在32位平台,vs2013下测试,sizeof(int)大小是4,其他情况我们不考虑。
_INTSIZEOF(n)的意思:计算一个最小数字x,满足 x>=n && x%4==0,其实就是一种4字节对齐的方式。
比如n是:1,2,3,4 对n进行向 sizeof(int) 的最小整数倍取整的问题 就是 4
比如n是:5,6,7,8 对n进行向 sizeof(int) 的最小整数倍取整的问题 就是 8
为什么有这个4字节对齐是因为短整型参数传递时会进行整形提升。
怎么办到的:
第一步理解:4的倍数
既然是4的最小整数倍取整,那么本质是:
x
=
4
∗
m
x=4*m
x=4∗m,m是具体几倍。对
x
=
7
x=7
x=7来讲,m就是2,对齐的结果就是8,而m具体是多少,取决于n是多少。
- 如果n能整除4,那么m就是 n / 4 n/4 n/4。
- 如果n不能整除4,那么m就是 n / 4 + 1 n/4+1 n/4+1。
上面是两种情况,如何合并成为一种写法呢?
常见做法是 : ( n + s i z e o f ( i n t ) − 1 ) ) / s i z e o f ( i n t ) − > ( n + 4 − 1 ) / 4 ( n+sizeof(int)-1) )/sizeof(int) -> (n+4-1)/4 (n+sizeof(int)−1))/sizeof(int)−>(n+4−1)/4
- 如果n能整除4,那么m就是 ( n + 4 − 1 ) / 4 − > ( n + 3 ) / 4 (n+4-1)/4->(n+3)/4 (n+4−1)/4−>(n+3)/4,+3的值无意义,会因取整自动消除,等价于 n / 4 n/4 n/4。
- 如果n不能整除4,那么
n
=
最大能整除
4
部分
+
r
,
1
<
=
r
<
4
n=最大能整除4部分+r,1<=r<4
n=最大能整除4部分+r,1<=r<4那么m就是
(
n
+
4
−
1
)
/
4
−
>
(
能整除
4
部分
+
r
+
3
)
/
4
(n+4-1)/4->(能整除4部分+r+3)/4
(n+4−1)/4−>(能整除4部分+r+3)/4,其中
4 < = r + 3 < 7 − > 能整除 4 部分 / 4 + ( r + 3 ) / 4 − > n / 4 + 1 4<=r+3<7 -> 能整除4部分/4 + (r+3)/4 -> n/4+1 4<=r+3<7−>能整除4部分/4+(r+3)/4−>n/4+1
第二步理解:最小4字节对齐数
搞清楚了满足条件最小是几倍问题,那么,计算一个最小数字x,满足 x>=n && x%4==0,就变成了
(
(
n
+
s
i
z
e
o
f
(
i
n
t
)
−
1
)
/
s
i
z
e
o
f
(
i
n
t
)
)
[
最小几倍
]
∗
s
i
z
e
o
f
(
i
n
t
)
[
单位大小
]
−
>
(
(
n
+
4
−
1
)
/
4
)
∗
4
((n+sizeof(int)-1)/sizeof(int))[最小几倍] * sizeof(int)[单位大小] -> ((n+4-1)/4)*4
((n+sizeof(int)−1)/sizeof(int))[最小几倍]∗sizeof(int)[单位大小]−>((n+4−1)/4)∗4
这样就能求出来4字节对齐的数据了,其实上面的写法,在功能上,已经和源代码中的宏等价了。
第三步理解:理解源代码中的宏
简洁写法: ( ( n + 4 − 1 ) / 4 ) ((n+4-1)/4) ((n+4−1)/4)* 4,设 w = n + 4 − 1 w=n+4-1 w=n+4−1, 那么表达式可以变化成为 ( w / 4 ) ∗ 4 (w/4)*4 (w/4)∗4,而4就是 2 2 2^2 22, w / 4 w/4 w/4,不就相当于右移两位吗?再次 ∗ 4 *4 ∗4不就相当左移两位吗?先右移两位,在左移两位,最终结果就是,最后2个比特位被清空为0!
这就相当于w & ~3 ,所以,简洁版:(n+4-1) & ~(4-1)
原码版:((sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )



![计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-卷积-[北邮鲁鹏]](https://img-blog.csdnimg.cn/053b4862d7574c61876343a6cf7460fc.png)