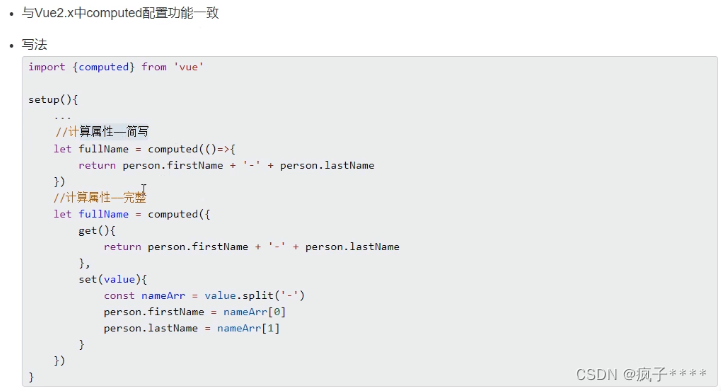
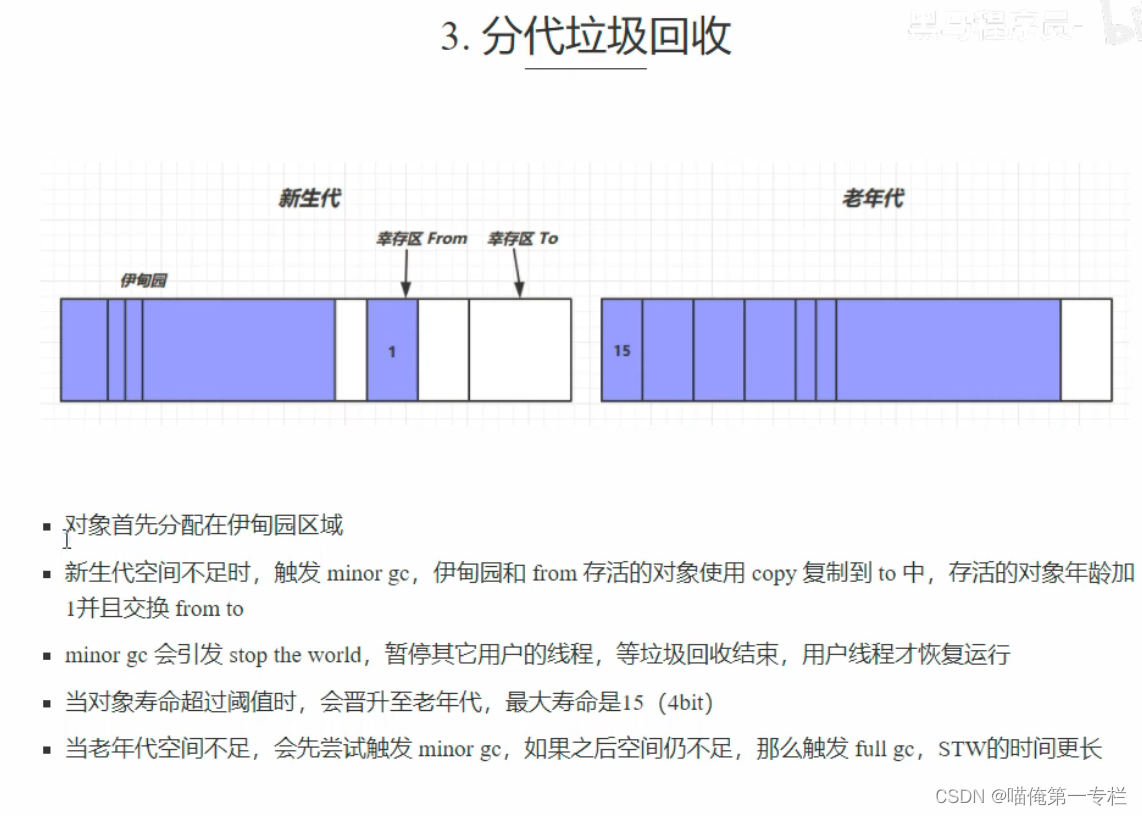
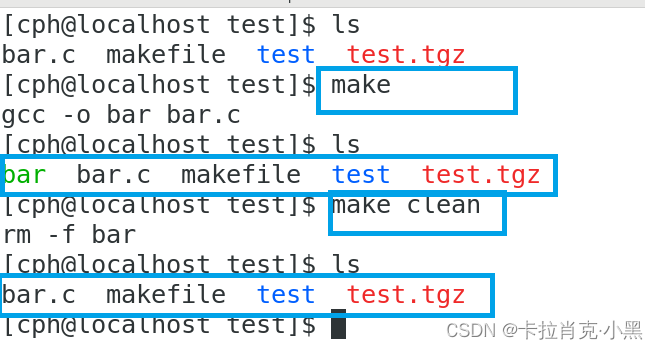
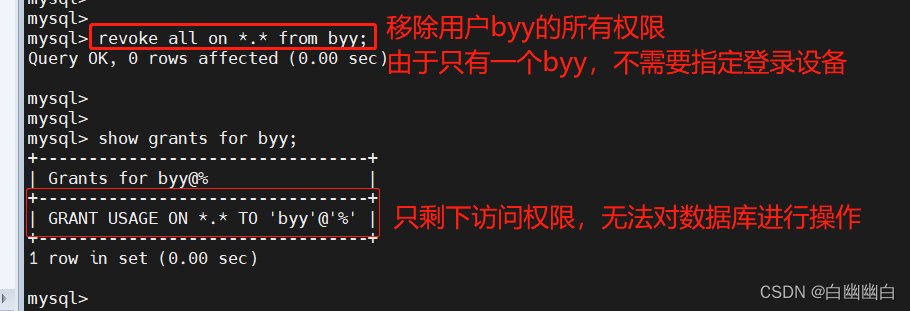
自然语言处理包含自然语言理解和自然语言生成两个方面, 常见任务包括文本分类, 结构分析 (词法分析, 分词, 词性标注, 句法分析, 篇章分析), 语义分析, 知识图谱, 信息提取, 情感计算, 文本生成, 自动文摘, 机器翻译, 对话系统, 信息检索和自动问答等. 在神经网络方法出现之前, 因为缺乏行之有效的语义建模和语言生成手段, 自然语言处理的主流方法是基于机器学习的方法, 采用有监督分类, 将自然语言处理任务转化为某种分类任务. 在神经网络时代, Word2Vec 词嵌入模型, BERT 等上下文相关语言模型为词语, 句子乃至篇章的分布式语义提供了有效的建模手段; 编码器-解码器架构和注意力机制提升了文本生成的能力; 相比传统自然语言处理所遵循的词法-句法-语义-语篇-语用分析级联式处理架构, 端到端的神经网络训练方法减少了错误传播, 极大提升了下游任务的性能. 不过, 神经网络方法仍然遵循监督学习范式, 需要针对特定任务, 给定监督数据, 设计深度学习模型, 通 过最小化损失函数来学习模型参数. 由于深度学习也是一种机器学习方法, 因此从某种程度上, 基于神经网络的方法和基于机器学习的方法并无本质区别.
然而, 不同于通常的深度学习方法, 以 ChatGPT 为代表的生成式大模型, 除了能高质量完成自然语言生成类任务之外, 还具备以生成式框架完成各种开放域自然语言理解任务的能力. 只需要将模型输出转换为任务特定的输出格式, 无需针对特定任务标注大量的训练数据, ChatGPT 即可在少样本乃至零样本上, 达到令人满意的性能, 甚至可在某些任务上超过了特别设计并使用监督数据进行训练的模型. 因此, ChatGPT 对各种自然语言处理核心任务带来了巨大的, 不可避免的冲击和影响, 也酝酿着新的研究机遇.
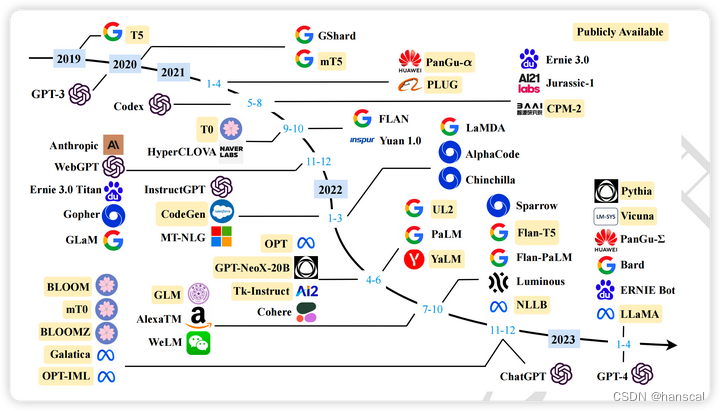
机遇
大语言模型 ChatGPT 和 GPT4 的出现使得人们重新思考通用人工智能(AGI)的可能性。OpenAI 发表技术文章题为“AGI 及以后的规划”,其中讨论了接近 AGI 的短期和长期计划,最近的一篇论文指出GPT-4 可能是被认为是 AGI 系统的早期版本。
随着 LLMs 快速发展,人工智能的研究领域正在发生变革。在自然语言处理领域,LLM 可以作为通用语言任务解决器,其研究范式已经转向怎么使用 LLM;在信息检索领域,传统的搜索引擎已经受到 AI 聊天机器人(如ChatGPT)这种新信息查询方式的挑战;在计算机视觉领域,研究人员尝试开发类似ChatGPT的多模态的视觉语言模型来服务多模态对话交互,如 GPT-4通过整合视觉信息支持多模态输入。这个新的技术浪潮可能会给基于LLM 的实际应用生态系统带来繁荣,如LLM 赋能Microsoft 365 进行自动化办公,ChatGPT 中支持使用插件来实现特殊功能。可能会带来如下一下变革机遇:
自然语言处理的改进
大规模语言模型提供了更高水平的自然语言处理能力,能够理解和生成人类语言的 内容。这为自动化翻译、文本摘要、问答系统等任务提供了更好的解决方案。
个性化用户体验
语言模型可以根据用户的输入和上下文生成个性化的回应,从而提供更好的用户体验。 这在虚拟助手、客户服务聊天机器人和个性化推荐系统等领域具有广泛应用。
创造内容和创意
大规模语言模型可以生成各种类型的内容,如文章、故事、诗歌等。这为作家、创作者 和艺术家提供了灵感和创作支持。
教育和学习辅助
语言模型可以作为教育工具,为学生提供问题解答、解释和学习资源。它们可以生成教 育内容、编写教材,并提供个性化的学习建议和指导。
自动化和提高效率
语言模型可以自动完成各种语言相关任务,例如自动生成报告、处理文件、编写代码 等。这有助于提高工作效率和减少人工工作量,从而为企业和个人节省时间和资源。
知识获取和信息检索
大规模语言模型具有强大的文本理解和检索能力,可以帮助人们从庞大的信息中快 速获取所需的知识。这对于学术研究、专业领域的信息检索以及解决现实世界的问题都具有重要意义。
新兴应用领域
大规模语言模型不断拓展其应用领域,例如医疗保健、法律、金融和市场营销等。它们可 以提供专业意见、分析数据、自动化流程等,从而推动创新和提供更好的解决方案。
挑战
LLM 为诸多领域提供新发展机遇的同时也带来了很多新的挑战:首先, LLM 的高性能是以高算力为代价的。OpenAI 在 2018 年发布的报告中指出, 自 2012 年以来, AI 训练的算力呈指数级增长, 这意味着 LLM 在提升性能的同时也消耗了更多算力。其次, LLM 的置信度有待提升。LLM 准确度由训练样本的数量和质量共同决定, 因此在处理一些复杂问题时准确度会降低,甚至出现一些完全错误的答案, 不恰当的使用会导致严重的损失. 也因此, LLM 难以在工业领域应用, 控制和决策类的 LLM 也很少见。再次,LLM 在创新能力方面还存在很大的上升空间。观察由 ChatGPT 生成的相应文案可以发现, 其生成的文本在格式方面都大同小异, 缺乏多样性和创新性。最后, 由于人类在此类模型中扮演了开发者和使用者的角色,LLM 在给人类带来便利的同时也带来了额外的法律和道德问题, 因此如何正确使用科技带来的便利也成为一个亟待解决的问题。可能会带来如下一下困难挑战:
偏见和不准确性
语言模型可能从训练数据中学习到偏见和错误信息,并在生成内容时反映出来。这可能导致误导和不准确的结果,特别是对于敏感话题和社会问题。解决这个问题需要更加精心的数据处理和模 型调整。
隐私和安全问题
语言模型可以存储和生成大量个人信息,可能引发隐私和安全风险。滥用这些模型可能 导致虚假信息传播、社交工程攻击和个人隐私泄露。需要采取有效的安全措施来保护用户和数据的安全。
能源和环境影响
大规模语言模型需要庞大的计算资源和能源消耗,这可能对环境产生不利影响。为了减 少对能源的依赖和减少碳足迹,需要寻找更加高效和可持续的模型训练和推理方法。
深度技术理解和应用挑战
要有效地使用大规模语言模型,需要对其底层技术有一定的理解和专业知识。 这可能对一些领域的从业人员和使用者构成技术门槛。
训练数据和样本偏差
大规模语言模型的训练需要大量的数据,但这些数据可能存在偏差,反映了现实世 界中的不平等和歧视。这可能导致模型在生成内容时重复这些偏差,进一步加剧社会不平等和偏见。应该 采取措施来解决这些问题,例如数据清洗、多样化数据集和公平性评估等。
伦理和道德问题
随着语言模型变得更加强大和逼真,出现了一些伦理和道德问题。例如,如何处理生成 的虚假信息、遵守隐私和知识产权法律、以及维护透明度和责任等问题。这需要进行广泛的讨论和制定相 应的政策和准则。
可解释性和透明度
大规模语言模型通常被认为是黑盒模型,难以解释其生成内容的具体原因和依据。这 对于关键决策和敏感领域的应用可能带来问题,因为无法确定其可靠性和可信度。研究人员和开发者需要 努力提高模型的可解释性和透明度。
ps: 欢迎扫码关注微信公众号^-^.