文章目录
- 引言
- 一、BufferPool缓存的作用与优势
- 1.1 BufferPool缓存的定义与作用
- 1.2 BufferPool缓存的作用
- 1.3 Change Buffer 作用
- 二、BufferPool缓存的优势
- 2.1 减少磁盘IO操作的次数
- 2.2 提高数据的读取速度
- 2.3 减轻磁盘负载,提升整体系统性能
- 三、BufferPool缓存的工作原理
- 3.1 缓存命中与缓存未命中
- 3.2 缓存置换算法
- 3.3 InnoDB缓冲池指标
- 四、redo日志的作用与优势
- 4.1 redo日志的定义与作用
- 4.2 确保事务的持久性和数据的完整性
- 五、redo日志的优势
- 5.1 减少数据的写入操作:
- 5.2 提高事务的提交速度:
- 5.3 提供数据库的故障恢复能力:
- 六、redo日志的工作原理
- 6.1 redo日志的生成与写入:
- 七、BufferPool缓存与redo日志的协同作用
- 7.1 BufferPool缓存与redo日志的数据同步:
- 7.2 BufferPool缓存与redo日志的互补作用:

引言
背景:今天看了一节某培训机构的公开课关于BufferPool缓存与Redo日志的,讲的很深入,但是太局限,所以今天抽时间来整理总结一下,方便理解消化。
在数据库系统中,事务性能的优化是一项关键任务。MySQL数据库采用了BufferPool缓存和redo日志两种重要的技术来提升事务性能。BufferPool缓存可以大大提高数据读取速度,并降低磁盘的IO负担。Redo日志则可以确保数据库在发生故障时能够恢复到一致的状态,保证数据的完整性和一致性。这两种技术的结合,可以大大提升事务性能,提高数据库的运行效率。
BufferPool缓存,是MySQL数据库中一种关键的内存管理机制。通过将经常访问的数据和索引页保存在内存中,可以大幅度提升数据读取速度,避免频繁的磁盘IO操作。这对于事务处理来说,可以大大加快事务的处理速度,并提升事务的吞吐量。
Redo日志,是MySQL数据库中一种用于保证数据完整性和一致性的恢复机制。当事务进行修改操作时,首先将修改记录写入到redo日志中,而不是直接修改磁盘上的数据。当事务提交时,再将redo日志中的修改应用到磁盘上。这样做的好处是,如果在事务提交之前系统发生故障,那么在系统恢复后,可以通过redo日志回滚未完成的事务,保证数据的一致性。
通过BufferPool缓存和redo日志,MySQL数据库能够在保证数据完整性和一致性的同时,大大提升事务处理性能,提高数据库的运行效率。这对于大规模并发访问的数据库系统来说,具有非常重要的意义。
BufferPool缓存和redo日志在数据库中相互协同工作,提供了高效的数据访问和数据安全性。BufferPool缓存通过减少磁盘访问,提高数据的读取和修改性能;redo日志通过记录事务的修改操作,确保数据的持久性和一致性。它们共同保障了数据库的高性能和数据的可靠性。
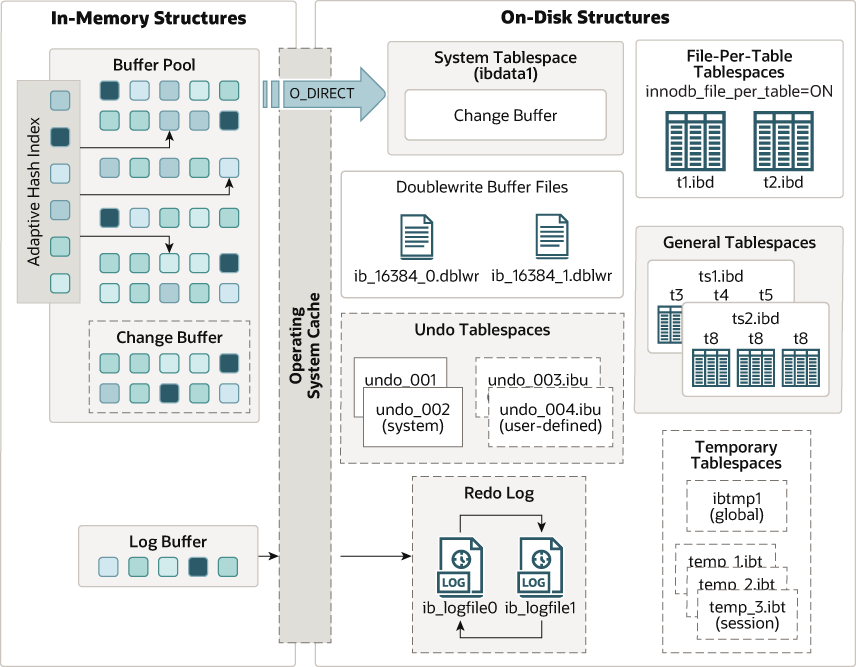
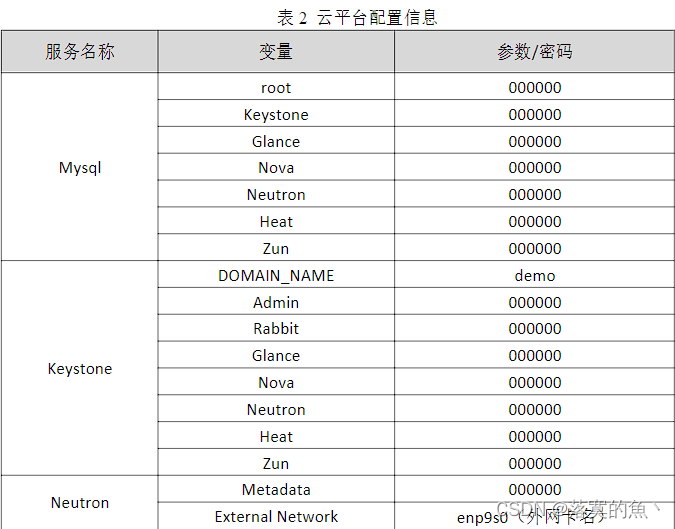
图片来源MySQL官网 《15.4 InnoDB Architecture》 https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
一、BufferPool缓存的作用与优势
1.1 BufferPool缓存的定义与作用
BufferPool是数据库管理系统中的一种内存区域,用于缓存数据库中的数据和索引页。它是数据库的核心组件之一,可以提高数据库的读取性能。BufferPool的大小可以根据系统配置进行调整,通常是数据库的一部分内存空间。
1.2 BufferPool缓存的作用
BufferPool缓存的主要作用是将磁盘上的数据和索引页加载到内存中,以减少磁盘IO访问的次数。当数据库需要读取数据时,首先会在BufferPool中查找,如果找到了所需的数据,就可以直接从内存中读取,而不需要访问磁盘。这样可以大大提高数据库的读取性能,减少了磁盘IO的开销。
BufferPool的优势还包括:
- 减少磁盘IO操作的次数:将常用的数据和索引页加载到内存中,可以减少磁盘IO的次数,提高读取数据的效率。
- 提高数据的读取速度:由于数据在内存中,读取速度较快,可以大幅度缩短数据库的响应时间。
- 减轻磁盘负载,提升整体系统性能:通过将数据和索引页缓存到内存中,可以减轻磁盘的负载,提高整体系统的性能。
1.3 Change Buffer 作用
参考文档 《MySQL 官方文档 15.5.2 Change Buffer》 https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
从本文引言里面放的官方的架构图中,我们可以看到 在Buffer Pool 里单独划分出了一块 区域命名为Change Buffer。其实在大多数数据库系统的内存模型里,Change Buffer(变更缓冲区)是Buffer Pool(缓存池)的一个重要组成部分。Change Buffer用于缓存事务提交时对索引的修改操作,以减少磁盘I/O的开销。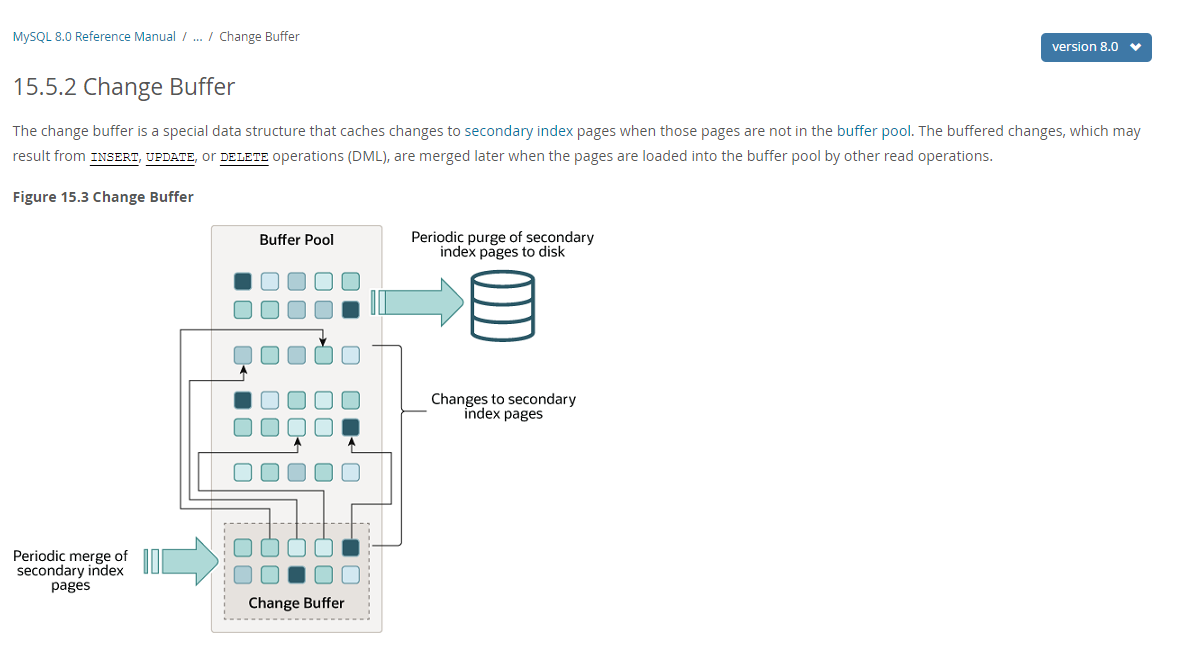
Change Buffer并不适用于所有类型的索引修改操作,它主要用于非唯一索引的插入、更新和删除操作。对于唯一索引的修改操作,仍然需要直接访问磁盘上的索引页进行处理。
当事务对数据库中的索引进行修改时,通常会涉及到磁盘上的索引页的读取和写入操作,这会导致额外的磁盘I/O消耗,并降低系统的性能。Change Buffer的引入就是为了解决这个问题。
Change Buffer的工作原理如下:
- 当事务对索引进行修改时,如果相关的索引页没有在Buffer Pool中被缓存,那么修改操作不会立即写入磁盘,而是被记录到Change Buffer中。
- Change Buffer是一个位于Buffer Pool中的专用缓冲区,用于保存事务提交时的索引修改信息。
- 当事务提交时,Change Buffer中的修改操作会被应用到磁盘上的索引页中。这个过程称为Change Buffer Merge(变更缓冲区合并)。
- Change Buffer Merge的过程会合并Change Buffer中的修改操作与磁盘上的索引页,生成最新的索引页内容,并将其写回磁盘。
- 合并后的索引页会被添加到Buffer Pool中,以供后续的查询操作使用。
Change Buffer的存在带来了几个优势:
- 减少磁盘I/O:通过将索引修改操作缓存到Change Buffer中,避免了频繁的磁盘读写操作,提高了系统的性能。
- 提高事务并发性能:当多个事务同时对相同的索引进行修改时,它们的修改操作可以被缓存到Change Buffer中,并在事务提交时一次性地进行合并,避免了锁竞争,提高了并发性能。
- 减少日志写入量:Change Buffer的修改操作在事务提交时被持久化到磁盘,可以减少写入事务日志的量,提高了日志写入性能。
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
二、BufferPool缓存的优势
BufferPool缓存的优势主要体现在减少磁盘IO操作的次数,提高数据的读取速度以及减轻磁盘负载,从而提升整体系统的性能。通过合理配置和利用BufferPool缓存,可以有效地提高数据库的读取性能和响应速度。
2.1 减少磁盘IO操作的次数
由于BufferPool缓存将常用的数据和索引页加载到内存中,当需要读取数据时,可以直接从内存中读取,而不需要进行磁盘IO操作。这样可以大大减少磁盘IO的次数,减少了磁盘访问的开销和延迟,提高了数据库的读取性能。
2.2 提高数据的读取速度
由于BufferPool缓存将数据和索引页存储在内存中,相比于磁盘,内存的读取速度要快得多。当需要读取数据时,可以直接从内存中读取,减少了磁盘IO的等待时间,加快了数据的读取速度。这对于大部分读取操作来说,可以极大地提高数据库的性能和响应速度。
2.3 减轻磁盘负载,提升整体系统性能
磁盘是数据库中相对较慢的组件,磁盘IO操作的开销较大。通过将常用的数据和索引页缓存到内存中,可以减轻磁盘的负载,降低磁盘的访问压力。这样可以提高整个系统的性能,并且减少了磁盘的机械运动,延长了磁盘的使用寿命。
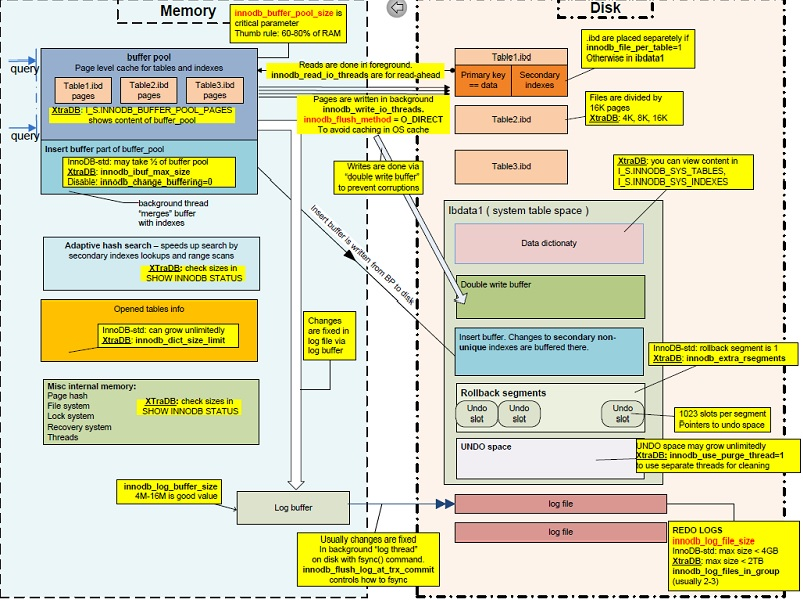
三、BufferPool缓存的工作原理
参考文档 https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
3.1 缓存命中与缓存未命中
BufferPool是MySQL数据库中的一块内存区域,用于存储数据库的数据页。当查询或修改数据时,MySQL首先会检查BufferPool中是否存在所需的数据页,这就涉及到缓存命中和缓存未命中的概念。
-
缓存命中(Cache Hit):如果所需的数据页已经在BufferPool中,则称为缓存命中。在缓存命中的情况下,MySQL可以直接从BufferPool中获取数据,避免了访问磁盘的开销,提高了数据访问的速度。
-
缓存未命中(Cache Miss):如果所需的数据页不在BufferPool中,则称为缓存未命中。在缓存未命中的情况下,MySQL需要从磁盘读取相应的数据页到BufferPool中,以便后续的查询或修改操作能够在BufferPool中进行。
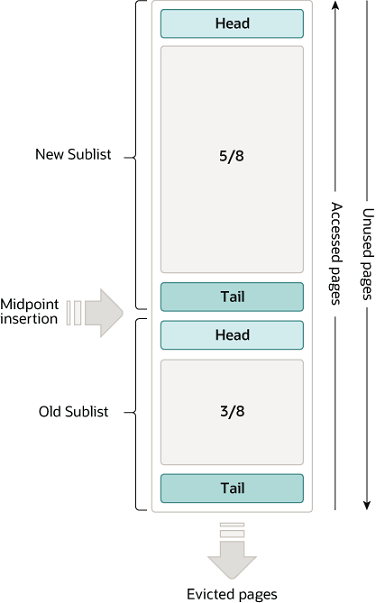
3.2 缓存置换算法
当BufferPool的空间已满时,需要使用缓存置换算法来选择要替换的数据页,以为新的数据页腾出空间。常见的缓存置换算法包括:
-
最近最少使用(Least Recently Used, LRU):LRU算法根据数据页的最近使用情况来进行置换。当需要替换数据页时,选择最近最少被使用的数据页进行替换。
-
最不经常使用(Least Frequently Used, LFU):LFU算法根据数据页被访问的频率来进行置换。当需要替换数据页时,选择被访问次数最少的数据页进行替换。
-
随机(Random):随机算法是一种简单的缓存置换算法,它随机选择一个数据页进行替换。
-
其他算法:还有其他一些缓存置换算法,如Clock算法、LRU-K算法等。
我们可以通过 SHOW ENGINE INNODB STATUS\G命令查看
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 776332
Buffer pool size 131072
Free buffers 124908
Database pages 5720
Old database pages 2071
Modified db pages 910
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not
0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read
ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2018-04-12 15:14:08 0x7f971c063700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 4 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 15 srv_active, 0 srv_shutdown, 1122 srv_idle
srv_master_thread log flush and writes: 0
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 24
OS WAIT ARRAY INFO: signal count 24
RW-shared spins 4, rounds 8, OS waits 4
RW-excl spins 2, rounds 60, OS waits 2
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 2.00 RW-shared, 30.00 RW-excl, 0.00 RW-sx
------------------------
LATEST FOREIGN KEY ERROR
------------------------
2018-04-12 14:57:24 0x7f97a9c91700 Transaction:
TRANSACTION 7717, ACTIVE 0 sec inserting
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 3
MySQL thread id 8, OS thread handle 140289365317376, query id 14 localhost root update
INSERT INTO child VALUES (NULL, 1), (NULL, 2), (NULL, 3), (NULL, 4), (NULL, 5), (NULL, 6)
Foreign key constraint fails for table `test`.`child`:
,
CONSTRAINT `child_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES `parent` (`id`) ON DELETE
CASCADE ON UPDATE CASCADE
Trying to add in child table, in index par_ind tuple:
DATA TUPLE: 2 fields;
0: len 4; hex 80000003; asc ;;
1: len 4; hex 80000003; asc ;;
But in parent table `test`.`parent`, in index PRIMARY,
the closest match we can find is record:
PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 80000004; asc ;;
1: len 6; hex 000000001e19; asc ;;
2: len 7; hex 81000001110137; asc 7;;
------------
TRANSACTIONS
------------
Trx id counter 7748
Purge done for trx's n:o < 7747 undo n:o < 0 state: running but idle
History list length 19
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421764459790000, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 7747, ACTIVE 23 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 9, OS thread handle 140286987249408, query id 51 localhost root updating
DELETE FROM t WHERE i = 1
------- TRX HAS BEEN WAITING 23 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 4 page no 4 n bits 72 index GEN_CLUST_INDEX of table `test`.`t`
trx id 7747 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000202; asc ;;
1: len 6; hex 000000001e41; asc A;;
2: len 7; hex 820000008b0110; asc ;;
3: len 4; hex 80000001; asc ;;
------------------
TABLE LOCK table `test`.`t` trx id 7747 lock mode IX
RECORD LOCKS space id 4 page no 4 n bits 72 index GEN_CLUST_INDEX of table `test`.`t`
trx id 7747 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 6; hex 000000000202; asc ;;
1: len 6; hex 000000001e41; asc A;;
2: len 7; hex 820000008b0110; asc ;;
3: len 4; hex 80000001; asc ;;
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (log thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (read thread)
I/O thread 4 state: waiting for i/o request (read thread)
I/O thread 5 state: waiting for i/o request (read thread)
I/O thread 6 state: waiting for i/o request (write thread)
I/O thread 7 state: waiting for i/o request (write thread)
I/O thread 8 state: waiting for i/o request (write thread)
I/O thread 9 state: waiting for i/o request (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
833 OS file reads, 605 OS file writes, 208 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 1 buffer(s)
Hash table size 553253, node heap has 3 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
Hash table size 553253, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 19643450
Log buffer assigned up to 19643450
Log buffer completed up to 19643450
Log written up to 19643450
Log flushed up to 19643450
Added dirty pages up to 19643450
Pages flushed up to 19643450
Last checkpoint at 19643450
129 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 409606
Buffer pool size 131072
Free buffers 130095
Database pages 973
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 810, created 163, written 404
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 973, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
----------------------
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 65536
Free buffers 65043
Database pages 491
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 411, created 80, written 210
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 491, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
---BUFFER POOL 1
Buffer pool size 65536
Free buffers 65052
Database pages 482
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 399, created 83, written 194
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 482, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=5772, Main thread ID=140286437054208 , state=sleeping
Number of rows inserted 57, updated 354, deleted 4, read 4421
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
3.3 InnoDB缓冲池指标
这些指标提供了关于InnoDB缓冲池的各个方面的信息,包括内存分配、页面管理、IO操作等。
| 名称 | 描述 |
|---|---|
| 分配的总内存 | 为缓冲池分配的总内存(字节)。 |
| 分配的字典内存 | InnoDB数据字典分配的总内存(字节)。 |
| 缓冲池大小 | 分配给缓冲池的总页面大小。 |
| 空闲缓冲区 | 缓冲池空闲列表的总页面大小。 |
| 数据库页面 | 缓冲池LRU列表的总页面大小。 |
| 旧数据库页面 | 缓冲池旧LRU子列表的总页面大小。 |
| 修改的数据库页面 | 当前在缓冲池中修改的页面数量。 |
| 待处理的读取 | 等待读入缓冲池的缓冲池页面数。 |
| 待处理的LRU写入 | 来自LRU列表底部的旧脏页数待在缓冲池中写入。 |
| 待处理的刷新列表写入 | 在检查点期间需要刷新的缓冲池页面数。 |
| 待处理的单页写入 | 在缓冲池中待处理的独立页面写入数量。 |
| 使数据库页面年轻 | 在缓冲池LRU列表中使页面年轻的总数(移到“新”页面子列表的头部)。 |
| 未使数据库页面年轻 | 在缓冲池LRU列表中未使页面年轻的总数(页面在“旧”子列表中保持不变,没有变为年轻)。 |
| 每秒年轻化率 | 每秒访问缓冲池LRU列表中旧页面的平均次数,这些访问使页面年轻化。 |
| 每秒未年轻化率 | 每秒访问缓冲池LRU列表中旧页面的平均次数,这些访问没有使页面年轻化。 |
| 读取的页面 | 从缓冲池读取的页面的总数。 |
| 创建的页面 | 在缓冲池中创建的页面的总数。 |
| 写入的页面 | 从缓冲池写入的页面的总数。 |
| 每秒读取率 | 每秒缓冲池页面读取的平均数。 |
| 每秒创建率 | 每秒创建的缓冲池页面的平均数。 |
| 每秒写入率 | 每秒从缓冲池写入页面的平均数。 |
| 缓冲池命中率 | 从缓冲池读取页面与从磁盘存储读取页面的缓冲池页面命中率。 |
| 年轻化命中率 | 页面访问导致页面年轻化的平均命中率。 |
| 未年轻化命中率 | 页面访问未导致页面年轻化的平均命中率。 |
| 读取预读 | 预读操作的每秒平均数。 |
| 无访问驱逐的页面 | 未从缓冲池访问的页面的每秒平均驱逐数。 |
| 随机预读 | 随机预读操作的每秒平均数。 |
| LRU长度 | 缓冲池LRU列表的总页面大小。 |
| 解压LRU长度 | 缓冲池解压LRU列表的长度(页面)。 |
| I/O总量 | 访问的缓冲池LRU列表页面的总数。 |
| I/O当前 | 很抱歉,我的回答被截断了。以下是表格中剩余的内容: |
| 名称 | 描述 |
|---|---|
| I/O当前 | 在当前间隔中访问的缓冲池LRU列表页面的总数。 |
| 解压I/O总量 | 解压的缓冲池解压LRU列表页面的总数。 |
| 解压I/O当前 | 在当前间隔中解压的缓冲池解压LRU列表页面的总数。 |
四、redo日志的作用与优势
参考文档 《MySQL 8.0版本文档 15.6.5 Redo Log》 https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log.html
设置Redo log 大小
SET GLOBAL innodb_redo_log_capacity = 8589934592;
redo日志文件使用“#ib_redoN”命名约定,其中N是重做日志文件的编号。多余的重做日志文件以“_tmp”后缀表示。以下示例显示了一个#innodb_redo目录中的重做日志文件,其中有21个活动的重做日志文件和11个备用的重做日志文件,按顺序编号。
'#ib_redo582' '#ib_redo590' '#ib_redo598' '#ib_redo606_tmp'
'#ib_redo583' '#ib_redo591' '#ib_redo599' '#ib_redo607_tmp'
'#ib_redo584' '#ib_redo592' '#ib_redo600' '#ib_redo608_tmp'
'#ib_redo585' '#ib_redo593' '#ib_redo601' '#ib_redo609_tmp'
'#ib_redo586' '#ib_redo594' '#ib_redo602' '#ib_redo610_tmp'
'#ib_redo587' '#ib_redo595' '#ib_redo603_tmp' '#ib_redo611_tmp'
'#ib_redo588' '#ib_redo596' '#ib_redo604_tmp' '#ib_redo612_tmp'
'#ib_redo589' '#ib_redo597' '#ib_redo605_tmp' '#ib_redo613_tmp'
每个普通的重做日志文件与特定范围的LSN值关联;例如,以下查询显示了上述示例中列出的活动重做日志文件的START_LSN和END_LSN值:
mysql> SELECT FILE_NAME, START_LSN, END_LSN FROM performance_schema.innodb_redo_log_files;
+----------------------------+--------------+--------------+
| FILE_NAME | START_LSN | END_LSN |
+----------------------------+--------------+--------------+
| ./#innodb_redo/#ib_redo582 | 117654982144 | 117658256896 |
| ./#innodb_redo/#ib_redo583 | 117658256896 | 117661531648 |
| ./#innodb_redo/#ib_redo584 | 117661531648 | 117664806400 |
| ./#innodb_redo/#ib_redo585 | 117664806400 | 117668081152 |
| ./#innodb_redo/#ib_redo586 | 117668081152 | 117671355904 |
| ./#innodb_redo/#ib_redo587 | 117671355904 | 117674630656 |
| ./#innodb_redo/#ib_redo588 | 117674630656 | 117677905408 |
| ./#innodb_redo/#ib_redo589 | 117677905408 | 117681180160 |
| ./#innodb_redo/#ib_redo590 | 117681180160 | 117684454912 |
| ./#innodb_redo/#ib_redo591 | 117684454912 | 117687729664 |
| ./#innodb_redo/#ib_redo592 | 117687729664 | 117691004416 |
| ./#innodb_redo/#ib_redo593 | 117691004416 | 117694279168 |
| ./#innodb_redo/#ib_redo594 | 117694279168 | 117697553920 |
| ./#innodb_redo/#ib_redo595 | 117697553920 | 117700828672 |
| ./#innodb_redo/#ib_redo596 | 117700828672 | 117704103424 |
| ./#innodb_redo/#ib_redo597 | 117704103424 | 117707378176 |
| ./#innodb_redo/#ib_redo598 | 117707378176 | 117710652928 |
| ./#innodb_redo/#ib_redo599 | 117710652928 | 117713927680 |
| ./#innodb_redo/#ib_redo600 | 117713927680 | 117717202432 |
| ./#innodb_redo/#ib_redo601 | 117717202432 | 117720477184 |
| ./#innodb_redo/#ib_redo602 | 117720477184 | 117723751936 |
+----------------------------+--------------+--------------+
4.1 redo日志的定义与作用
在MySQL中,redo日志(Redo Log)是一种事务日志,用于记录数据库中的修改操作。它起到了保障事务的持久性和数据的完整性的重要作用。
4.2 确保事务的持久性和数据的完整性
-
持久性(Durability):redo日志的主要作用之一是确保事务的持久性。当事务提交时,相关的修改操作将首先被写入redo日志中,然后才会被应用到数据库的数据文件中。这样即使系统在事务提交后发生故障或崩溃,通过redo日志的恢复机制,可以将未持久化到数据文件的修改操作重新应用,从而保证了事务的持久性。
-
数据完整性:redo日志还起到了保障数据完整性的作用。当数据库执行修改操作时,相关的修改信息会先被写入redo日志,然后才会被应用到实际的数据文件中。如果在这个过程中发生了故障,数据库可以利用redo日志重新应用这些修改,确保数据的完整性。在数据库恢复的过程中,redo日志是非常重要的,它能够将未完成的事务完成,并将数据库恢复到故障发生之前的状态,避免了数据的不一致性。
- 高性能:由于redo日志是以顺序方式写入的,相比于随机写入数据文件,顺序写入日志文件的性能更高。这是因为磁盘的顺序写入速度通常比随机写入速度更快,从而提高了数据库的整体性能。
- 数据恢复:通过redo日志,数据库可以在崩溃或故障中恢复到事务提交之前的状态。redo日志中的修改操作可以被重放,确保数据的完整性和一致性。
- 并发控制:通过redo日志,数据库可以实现并发控制。多个事务可以并发地进行修改操作,并将这些操作记录在redo日志中。数据库可以根据事务的隔离级别和锁机制来协调并发访问,并保证数据的一致性。
五、redo日志的优势
通过redo日志,数据库可以在故障恢复过程中实现数据的持久性和一致性。即使在异常情况下,如系统崩溃或断电,数据库可以通过重放redo日志中的操作来恢复数据,并确保数据的完整性。
5.1 减少数据的写入操作:
redo日志的一大优势是减少了对数据文件的直接写入操作。当事务执行修改操作时,相关的修改信息首先被写入redo日志中,而不是立即写入到实际的数据文件中。这样可以减少磁盘的随机写入操作,提高了数据库的写入性能。
5.2 提高事务的提交速度:
由于redo日志的写入是以顺序方式进行的,相比于随机写入数据文件,顺序写入日志文件的速度更快。因此,事务的提交速度可以得到提升。当事务提交时,只需要将redo日志写入到磁盘中,而不需要等待所有的修改操作直接写入到数据文件中。
5.3 提供数据库的故障恢复能力:
redo日志在数据库的故障恢复过程中起着关键的作用。当数据库发生崩溃或故障时,通过redo日志可以将未持久化到数据文件中的修改操作重新应用,从而将数据库恢复到故障发生之前的状态。redo日志记录了事务的修改信息,可以用于将未完成的事务完成,并确保数据的一致性和完整性。
六、redo日志的工作原理
redo日志的工作原理包括生成与写入过程,以及重做和回滚的操作。它记录了事务的修改操作,并通过重做操作将修改应用到数据库的数据文件中,以确保数据的持久性和一致性;同时,通过回滚操作可以撤销事务的修改操作,将数据库回滚到事务开始之前的状态。
6.1 redo日志的生成与写入:
当事务执行修改操作时,相关的修改信息会生成并写入redo日志。具体的工作原理如下:
- 在事务开始时,会为该事务分配一个唯一的事务ID。
- 在事务执行过程中,对数据库的修改操作(如插入、更新、删除)会生成对应的redo日志记录,记录了修改前和修改后的数据值。
- 生成的redo日志记录会被写入到redo日志缓冲区中,同时也会被异步刷写到磁盘上的redo日志文件中。
6.2 redo日志的重做与回滚:
-
重做(Redo):当事务提交时,redo日志中的修改操作将被应用到数据库的数据文件中,以确保事务的持久性。重做操作会按照redo日志的顺序进行,将修改操作重新执行,将数据的物理状态更新到磁盘上的数据文件中。这样可以保证事务的修改操作在数据库的崩溃或故障后能够得到恢复。
-
回滚(Rollback):在事务回滚的情况下,redo日志也发挥了作用。当事务被回滚时,相关的redo日志记录会被撤销,即将对应的修改操作反向执行。这样可以将事务的修改操作从数据库中撤销,使数据库回滚到事务开始之前的状态。
通过redo日志的重做和回滚机制,数据库可以实现数据的持久性和一致性。重做操作确保了数据的修改操作在事务提交后持久化到数据文件中,而回滚操作确保了在事务回滚时能够撤销相关的修改操作。
七、BufferPool缓存与redo日志的协同作用
7.1 BufferPool缓存与redo日志的数据同步:
BufferPool缓存和redo日志在数据库中扮演着不同的角色,但它们之间存在着一定的协同作用,主要体现在数据的同步方面。
- 当事务执行修改操作时,相关的数据页会被加载到BufferPool缓存中,以提高数据的访问性能。同时,对于修改操作,相关的修改信息也会被写入redo日志中,以确保数据的持久性。
- BufferPool缓存中的数据页在修改时,会在相应的数据页中进行数据的修改,并将修改后的数据更新到BufferPool中。此时,相关的redo日志记录也会被写入redo日志缓冲区。
- 当事务提交时,BufferPool缓存中的数据页的修改会被写回到磁盘的数据文件中,同时相关的redo日志记录会被刷写到磁盘的redo日志文件中。这样可以保证数据的一致性和持久性,确保数据在数据库故障后能够恢复。
7.2 BufferPool缓存与redo日志的互补作用:
BufferPool缓存和redo日志在数据库的运行过程中具有互补的作用,主要体现在数据访问性能和数据安全性方面。
- BufferPool缓存提供了高效的数据访问方式,通过将热点数据加载到内存中,避免了频繁的磁盘访问操作,提高了数据的读取和修改性能。
- redo日志记录了事务的修改操作,确保了数据的持久性和一致性。即使在数据库发生故障或崩溃的情况下,通过redo日志可以将未持久化的修改操作重新应用,恢复数据的一致状态。

大家好,我是冰点,今天的MySQL BufferPool缓存与Redo日志是如何提升事务性能的 内容就是这些了。如果你有疑问或见解可以在评论区留言。