Redis介绍
Redis是单线程 + 多路IO复用技术(类似黄牛买票)
默认有16个库,用select进行切换
默认端口号为6379
Memcached:多线程 + 锁(数据类型单一,不支持持久化)
五大常用数据类型
Redis key
- 查看所有键
key *
- 判断key是否存在(返回0/1)
exist key
- 查看key的类型
type key
- 删除key
del key
- 根据value选择非阻塞删除
unlink key
- 设置key的过期时间
expire key 秒数
- 查看key还有多少秒过期,-1表示永不过期,-2表示已经过期
ttl key
- 其他命令
select 切换数据库
dbsize 查看当前数据库key的数量
flushdb 清空当前库
flushall 通杀全部库
String
是二进制安全的,即可以包含任何数据,一个字符串value最多可以是512M,是简单动态字符串,类似ArrayList。
set <key> <value> [EX | PX] [NX | XX]
*NX: key不存在时添加(存在时不覆盖原值)
*XX: key存在时可以添加
*EX: key的超时秒数
*PX: key的超时毫秒数
get <key>
append <key> <value> 追加到原value末尾
strlen <key> 获取值长度
setnx <key> <value> 只有在key不存在时设置
incr <key> 对数字值+1, 只能对数字操作,若为空则设置值为1
decr <key> 对数字值-1,只能对数字操作,若为空则设置值为-1
incrby/decrby <key> <步长> 数字值增减,自定义步长
mset <key1> <value1> <key2> <value2>... 同时设置一个或多个键值对
mget <key1> <key2> <key3>... 同时获取一个或多个value
msetnx <key1> <value1> <key2> <value2>... 同时设置,当且仅当所有key都不存在
getreange <key> <起始位置> <结束位置> 获得值的范围,前包后包
setrange <key> <起始位置> <value> 将从起始位置开始的所有值置为value(下标从0开始)
setex <key> <过期时间> <value> 设置键值的同时,设置过期时间(秒)
getset <key> <value> 设置新值同时获得旧值
List
单键多值,底层是双向链表,可以在两端添加元素(有序),对两端的操作效率较高。
数据结构是quickList,元素较少时用一块连续的内存存储,即ziplist;当数据多的时候才改成quickList(目的是节省空间)。

lpush/rpush <key> <value1> <value2> ... 从左/右插入一个或多个值
lpop/rpop <key> 从左/右弹出一个值。注意:值在键在,值光键亡。
rpoplpush <key1><key2> 从key1右弹一个值,放入key2左边
lrange <key> <start> <stop> 按照下标获得元素(从左到右)
lindex <key> <index> 按下标取元素(从左到右)
llen <key> 获取长度
linsert <key> before/after <value> <newvalue> 在<value>的前/后插入<newvalue>
lrem <key> <n> <value> 从左边删n个value(从左到右)
lset <key> <index> <value> 将列表key下标为index的值替换成value
Set
自动排重,无序。底层是hash表,增删查是O(1)。
数据结构是dict字典。
sadd <key> <value1> <value2> ... 添加元素,已存在则忽略
smembers <key> 取出所有值
sismember <key> <value> 判断是否存在,返回0/1
scard <key> 返回该集合的元素个数
srem <key> <value1> <value2> ... 删除元素
spop <key> 随机弹出集合中的一个值
srandmember <key> <n> 随机得到集合中的n个值,不会被删除
smove <source> <destination> <value> 把集合中一个值从一个集合移动到另一个 集合
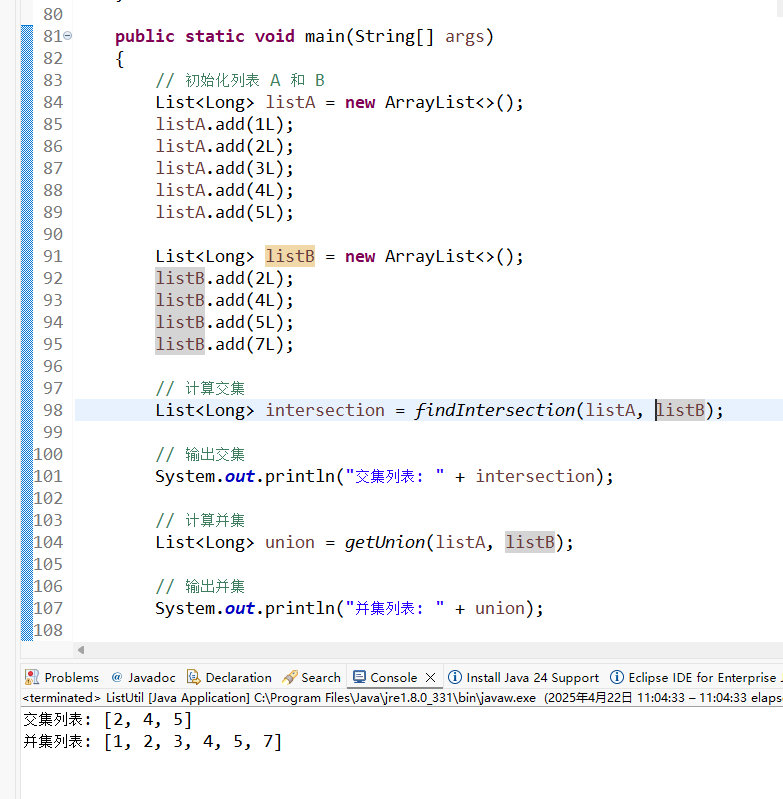
sinter <key1> <key2> 返回交集
sunion <key1> <key2> 返回并集
sdiff <key1> <key2> 返回差集(在key1但不在key2)
Hash
键值对集合,是一个string类型的field和value的映射表,特别适合存储对象。类似Map<String, Object>。
长度短且个数较少用ziplist,多了用hashtable
hset <key> <field> <value> 赋值
hget <key> <field> 取值
hmset <key> <field> <value1> <value2> <value3> 批量设置
hexists <key> <field> 是否存在
hkeys <key> 获得所有field
hvals <key> 获得所有value
hincrby <key> <field> <increment>
hsetnx <key> <field> <value>
Zset (sorted set)
没有重复元素的字符串集合(有序),每个成员关联了一个score,集合成员唯一,但score可以重复。
类似Map<String, Double>和TreeSet,底层使用两个数据结构:
- hash,关联value和score
- 跳表,给value排序,根据score范围获取元素列表
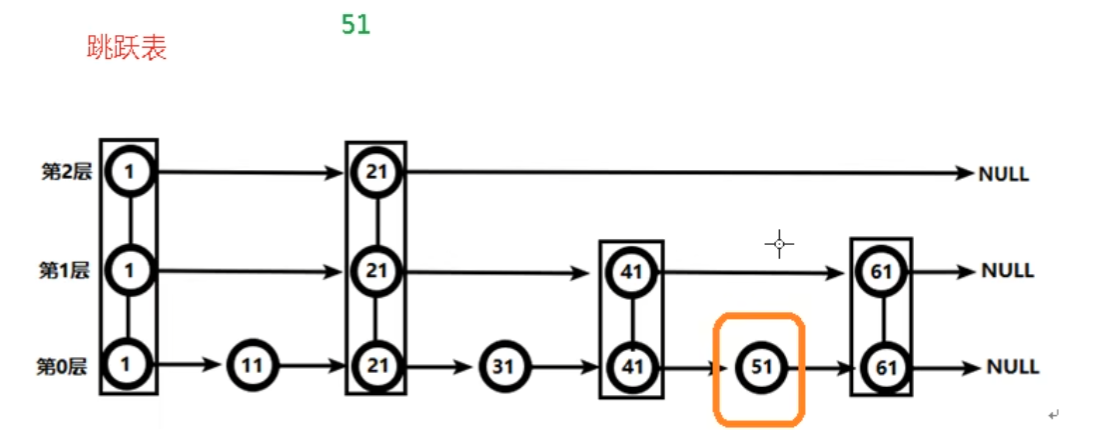
zadd <key> <score1> <value1> <score2> <value2> ... 添加
zrange <key> <start> <stop> [WITHSCORES] 返回下标在start和stop之间的元素(可以让分数和值一起返回到结果集)
zrangebyscore key minmax [withscores] [limit offset count] 返回score值在min和max之间的成员(包括两端),按score递增排列
zrevrangebyscore key maxmin [withscores] [limit offset count],同上,从大到小排列
zincrby <key> <increment> <value> 为元素的score加上增量
zrem <key> <value> 删除该集合指定值的元素
zcount <key> <min> <max> 统计分数区间内元素个数
zrank <key> <value> 返回该值在集合中的排名,从0开始
配置文件 redis.conf
Units单位
配置大小单位,开头定义了一些基本的度量单位只支持bytes,不支持bit,大小写不敏感。
Include
类似jsp中的include,多实例的情况可以把公用的配置提取出来。
网络相关配置
bind
- 默认bind = 127.0.0.1 只能接受本机的访问请求。
- 不写的话,无限制接受任何ip地址的方位。
- 生产环境就写应用服务器的地址;服务器是需要远程访问的,所以要注释掉(来支持远程访问)。
- 如果开启了protected-mode,那么在没有设定bind- ip且没有设密码的情况下,Redis只允许接受本机的响应。
port
端口号,默认6379
tcp-backlog
- backlog是一个连接队列,backlog队列总和 = 未完成三次握手队列 + 已完成三次握手队列。
- 在高并发环境下,需要一个高backlog值来避免慢客户端连接问题。
- 注意:Linux内核回把这个值缩小到 /proc/sys/net/core/somaxconn的值(128),所以要增大该值和 /proc/sys/net/ipv4/tcp_max_syn_backlog(128)来达到想要的效果。
timeout
默认是0
tcp-keepalive
心跳检测
通用
daemonize
是否为后台进程,设置为yes,守护进程,后台启动。
pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件。
loglevel
默认notice

logfile
默认输出日志文件路径
databases
默认16,数据库数量
LIMITS限制
maxclients
最大客户端连接数,默认为10000,达到限制后会拒绝新的连接请求,并回应“max number of clients reached”
maxmemory
建议必须设置,否则内存占满造成服务器宕机。
一旦达到内存使用上线,Redis会试图移除内部数据,一处规则可以通过maxmemory-policy指定。

发布和订阅
pub/sub,是一种消息通信模式,pub发送消息,sub接收消息。Redis客户端可以订阅任意数量的频道。
注意:发布的消息没有持久化,只能收到订阅后发布的消息。
SUBSCRIBE <channel> 订阅
publish <channel> <information> 给channel发布消息(返回订阅者数量)
新数据类型
Bitmaps
其实就是字符串,但只有0和1,可以对字符串的位进行操作。可以想象为一个只有0和1的数组,下标叫偏移量(从0开始)。用来存储活跃用户,会比set节约很大的空间。
setbit <key> <offset> <value> 设置
getbit <key> <offset> 取值
bitcount <key> [start end] 统计1的数量
bitop and/or/not/xor <festkey> [key...] 多个bitmaps的交、并、非、异或,并将结果存在destkey中。
HyperLogLog
是用来做基数统计的算法,优点是:在输入元素的数量或体积非常非常大的时候,计算基数需要的空间总是固定的,并且很小。
pfadd <key> <element> [element ... ] 添加指定元素到HyperLogLog中
pfcount <key> [key .. ] 计算HLL的近似基数
pfmerge <destkey> <sourcekey> [sourcekey ... ] 将一个或多个HLL合并后存在destkey中(如每月活跃用户可以用每天活跃用户来合并计算得到)
Geospatial
用来对地理信息进行操作。
geoadd <key> <经度> <维度> <member> 添加位置
geopos <key> <member> 得到位置信息
geodist <key> <member1> <member2> [m | km | ft | mi] 获得两个位置的直线距离
georadius <key> <经度> <维度> radius m | km | ft | mi 给定经纬度为中心,找出某半径内的元素
Jedis操作
- 在Maven工程中,引入Jedis依赖
- 写一个测试Demo
注意:要禁用Linux防火墙,并在Redis.conf里注释掉bind,然后protected-mode no。
public static void main(String[] args){
// ip地址和端口号
Jedis jedis = new Jedis("192.168.44.168", 6379);
String value = jedis.ping();
System.out.println(vaLue);
}
key相关
jedis.set("k1", "v1");
jedis.set("k2", "v2");
jedis.set("k3", "v3");
Set<String> keys = jedis.keys("*");
System.out.println(keys.size());
System.out.println(jedis.exists("k1"));
System.out.println(jedis.ttl("k1"));
System.out.println(jedis.get("k1"));
String相关
jedis.mset("str1", "v1", "str2", "v2", "str3", "v3");
List<String> mget = jedis.mget("str1", "str2", "str3");
list相关
List<String<> list = jedis.lrange("mylist", 0, -1);
set相关
jedis.sadd("orders", "order1");
jedis.sadd("orders", "order2");
jedis.sadd("orders", "order3");
Set<String> smembers = jedis.smembers("orders");
jedis.srem("orders", "order1");
hash相关
jedis.hset("hash1", "username", "lisi");
Map<String, String> map = new HashMap<>();
map.put("tel", "13800009999");
map.put("address", "atguigu");
map.put("email", "abc@163.com");
jedis.hmset("hash2", map);
List<String> result = jedis.hmget("hash2", "tel", "email");
Zset相关
jedis.zadd("zset1", 100d, "z3");
jedis.zadd("zset1", 90d, "l4");
jedis.zadd("zset1", 80d, "w5");
实例:手机验证码


public class PhoneCode{
public static void main(String[] args){
// 测试逻辑懒得写了,主要是方法
}
// 生成6位数字验证码
public static String getCode(){
Random random = new Random();
String code = "";
for (int i = 0; i < 6; i++){
int rand = random.nextInt(10);
code += rand;
}
return code;
}
// 每个手机每天只能发送三次,验证码放到redis中,设置过期时间
public static void verifyCode(String phone){
Jedis jedis = new Jedis("192.168.44.168", 6379);
String countKey = "VerifyCode" + phone + ":count";
String codeKey = "VerifyCode" + phone + ":code";
String count = jedis.get(countKey);
if (count == null){
jedis.setex(countKey, 24*60*60, "1");
} else if(Integer.parseInt(count) <= 2){
jedis.incr(countKey);
} else if (Integer.parseInt(count) > 3){
System.out.println("今天发送次数已经超过三次");
jedis.close();
return ;
}
String vcode = getCode();
jedis.setex(codeKey, 120, vcode);
jedis.close();
}
// 验证码校验
public static void getRedisCode(String phone, String code){
Jedis jedis = new Jedis("192.168.44.168", 6379);
String codeKey = "VerifyCode" + phone + ":code";
String redisCode = jedis.get(codeKey);
if (redisCode.equals(code){
System.out.println("成功");
} else{
System.out.println("失败");
}
jedis.close ();
}
}
Sprint Boot 整合 Redis
- 建立Spring Boot工程,引入相关依赖
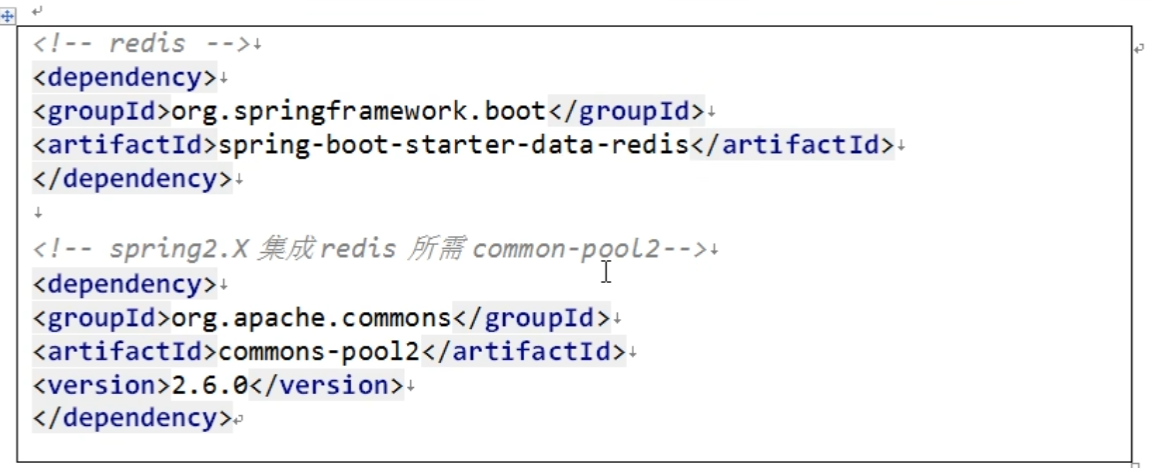
- application.properties 配置 redis
- 添加redis配置类 (固定的,现查一个复制粘贴就行)
Redis事务、锁机制、秒杀案例
Redis事务定义
Multi, Exec, discard

事务的错误处理
组队中某个命令报错,执行时整个队列都会被取消;执行时某个命令报错,只有报错的不执行,其他都执行,不会回滚。
事务冲突的问题
悲观锁
操作前上锁,解锁后其他人才能操作。安全,但效率比较低。
乐观锁
加入版本号,所有人都可以得到数据,但操作之后要同步更新版本号,check-and-set机制。适合于多读的应用类型,提高吞吐量。
watch key [key … ]
在执行multi之前,先执行watch,监视一个或多个key,如果在事务执行之前key被其他命令改动,则事务被打断。
使用unwatch可以解除监视。
Redis事务三特性

秒杀案例
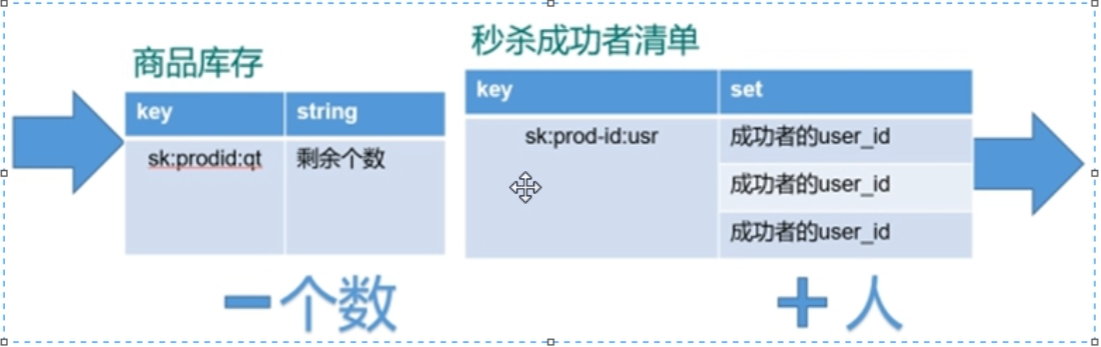
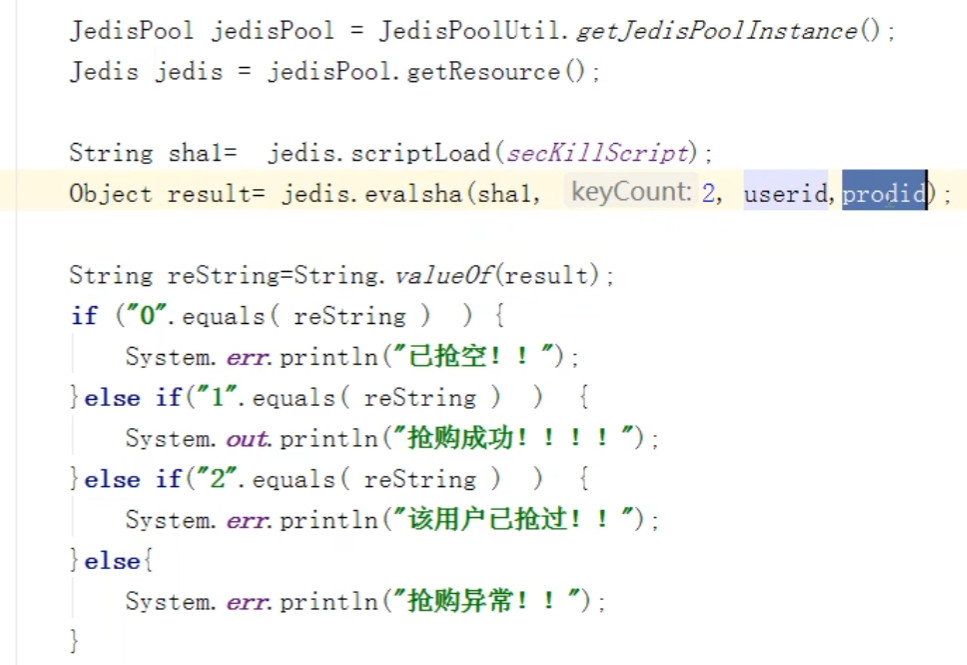
public static boolean do SecKill(String uid, String prodid) throws IOException{
if (uid == null || prodid == null){
return false;
}
Jedis jedis = new Jedis("192.168.44.168", 6379);
String kcKey = "sk:" + prodid + ":qt";
String userKey = "sk" + prodid + ":user";
// 乐观锁
jedis.watch(kcKey);
String kc = jedis.get(kcKey);
if (kc == null){
System.out.println("秒杀还没开始,请等待");
jedis.close();
return false;
}
if (jedis.sismember(userKey, uid)){
System.out.println("已经秒杀成功,不能重复秒杀");
jedis.close();
return false;
}
if (Integer.parseInt(kc) <= 0){
System.out.println("秒杀已经结束了");
jedis.close();
return false;
}
Transaction multi = jedis.multi();
multi.decr(kcKey);
multi.sadd(userKey, uid);
List<Object> results = multi.exec();
if (results == null || results.size() == 0){
System.out.println("秒杀失败了");
jedis.close();
return false;
}
// jedis.decr(kcKey);
// jedis.sadd(userKey, uid);
System.out.println("秒杀成功了");
jedis.close();
return true;
}
并发时存在的问题
- 库存为负(超卖问题)——增加乐观锁
- 可能出现连接超时问题——使用连接池解决(直接粘就行)
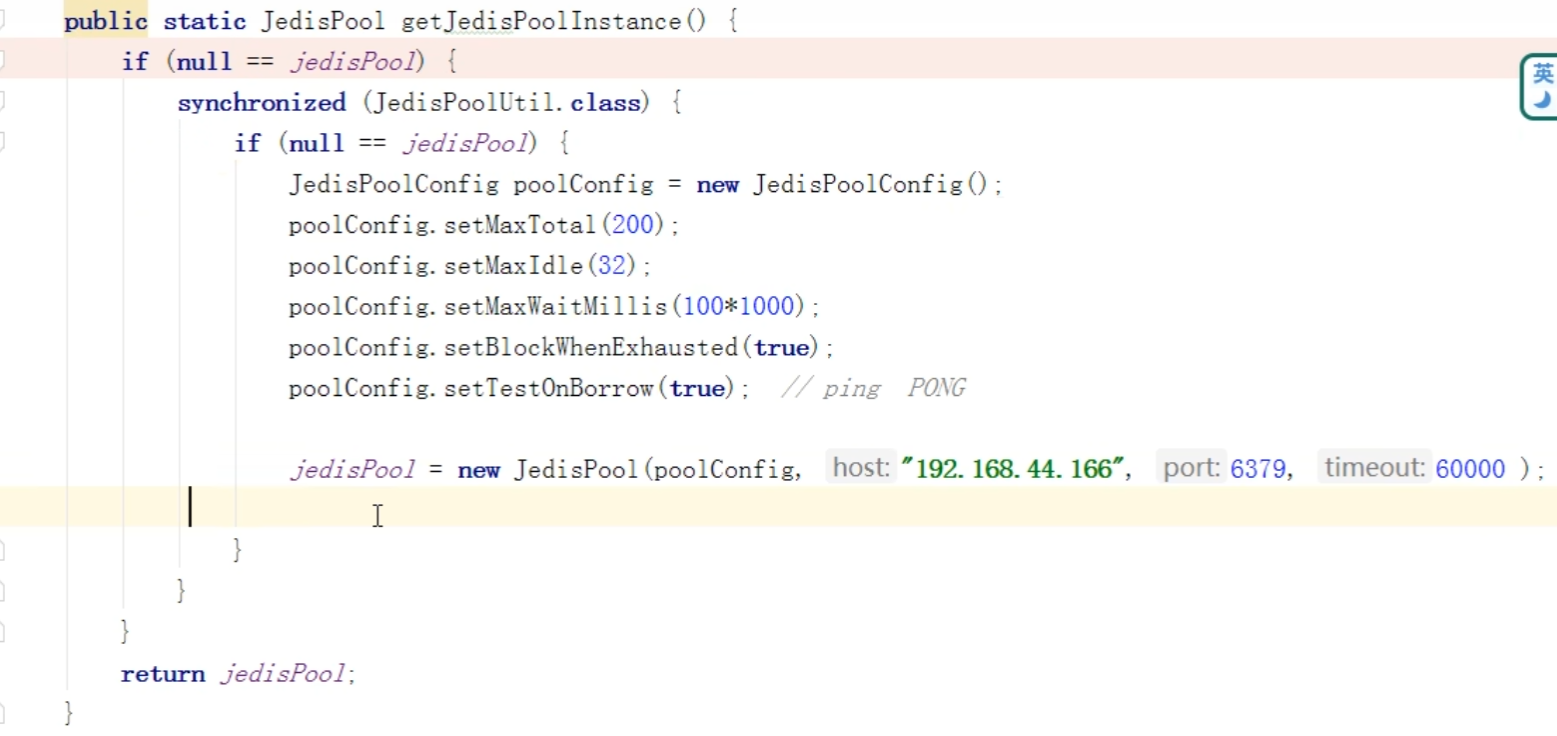

- 库存遗留问题(乐观锁造成的)——使用LUA脚本

LUA脚本的优势:

连接池 + lua脚本
Redis 持久化
RDB (Redis DataBase)
是什么
在指定时间间隔内将内存中的数据库快照写入磁盘,即snapshot快照,它恢复时时将快照文件直接读到内存里。
执行过程(保证数据完整性)

Fork

一些配置
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
save 时间 改变条数 (手动)
bgsave 是自动的
优势
- 适合大数据的数据恢复
- 对数据完整性和一致性要求不高,更适合使用
- 节省磁盘空间
- 恢复速度快
劣势
- Fork导致内存要2倍
- 写时复制如果数据量大,其实还是很耗性能的
- Redis意外挂了,最后一次持久化后的数据可能丢失
AOF (Append Of File)
- 写命令append到AOF缓冲区
- 根据AOF持久化策略将缓冲区内容同步到磁盘AOF文件中
- AOF文件大小超过重写策略或手动重写时,会rewrite压缩
- Redis重启时根据AOF文件恢复数据
是什么

AOF默认不开启
appendonly yes
AOF和RDB同时开启,默认读取AOF的数据(数据不会存在丢失)
AOF异常恢复

AOF同步频率设置
appendfsync always 始终同步,每次写入都记录,性能差但数据完整性好
appendfsync everysec 每秒记录一次,如果宕机,本秒数据可能丢失
appendfsync no 不主动同步,把同步时机交给操作系统
Rewrite压缩
set a a1
set b b1
会被压缩为:
set a a1 b b1


重写时和RDB是类似的,即写时复制技术。
优势
- 备份机制更稳健,丢失数据概率低
- 可读的日志文本,通过操作AOF文件,可以处理误操作
劣势
- 比RDB占用更多磁盘空间
- 恢复备份速度慢
- 每次读写都同步的话,有一定性能压力
- 存在个别bug造成恢复不能
用哪个好?

主从复制
是什么
主机数据更新后,根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
能干嘛
- 读写分离,性能扩展
- 容灾快速恢复
搭建主从复制
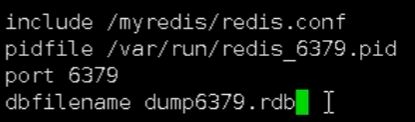
- 创建/myredis文件夹
- 复制redis.conf到文件夹中
- 配置一主两从,创建三个配置文件
- redis6379.conf
- redis6380.conf
- redis6381.conf
- 写入内容
- 使用命令启动三个服务
redis-server redis6379.conf
- 查看三台主机运行情况
info replication
- 配从不配主
slaveof <ip> <port> 成为某个实例的从服务器
一主两仆
从服务器挂了,重启后变成普通服务器,不再是从服务器,需要再次配置猜能变成从服务器;
主服务器挂了,重启后仍然是主服务器。
复制原理(有全量和增量)
- 当从连上主服务器之后,从服务器向主服务器发送进行数据同步消息(从服务器主动);
- 主服务器接到消息后,进行数据持久化得到rdb文件,把rdb文件发送给从服务器,从服务器拿到rdb文件后进行读取;
- 每次主服务器进行写操作之后,和从服务器进行数据同步(主服务器主动);
薪火相传
从服务器向下边的从服务器传数据,缺点是上边的从服务器挂了,下边就收不到数据了。
反客为主
一个master宕机后,后边的slave可以立刻升为master,其后边的slave不用做任何修改。
缺点:手动完成,没法自动完成。
slaveof no one 从机变主机
哨兵模式(sentinel)
是什么
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从转换为主。
怎么玩
- 调整为一主二仆,6379带着6380、6381
- 自定义的 /myredis 目录下新建sentinel.conf文件,名字绝对不能错
- 配置哨兵,填写内容
sentinel monitor mymaster 127.0.0.1 6379 1
mymaster为监控对象起的服务器名称,1为至少有多少个哨兵同意迁移的数量
- 启动哨兵
redis-sentinel /myredis/sentinel.conf
- 主机挂掉,从机选举产生新主机
根据 slave-priority 选择从机,原主机重启后会变成从机。
选择条件依次为:- 选择优先级靠前的(在redis.conf里默认:replica-priority 100,值越小优先级越高)
- 选择偏移量最大的(原主机数据最全的)
- 选择runid最小的(每个redis实例启动后都会随机生成一个40位的runid)
复制延时
所有写操作都是在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
注:Jedis里有相关配置代码,上网找一个粘就行。
集群
问题
容量不够如何扩容?——用集群
并发写操作,如何分摊?——用集群
主从模式、薪火相传模式,主机挂了导致ip地址发生变化,应用程序的配置需要修改对应的主机地址、端口等信息。——无中心化集群配置(任何一台服务器都可以作为集群的入口,所有服务器互相连通状态)
特点
- Redis集群实现了对Redis的水平扩容,即启动 N 个Redis节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数居的 1 / N;
- Redis集群通过分区(partition)来提供一定程度的可用性(availability),即使集群中有一部分节点失效或者无法通讯,集群也可以继续处理命令请求。
删除持久化数据
rdb 和 aof 文件都删掉就行
搭建集群玩玩
- 制作6个实例:6379、6380、6381、6389、6390、6391
- 配置基本信息
开启 daemonize yes
Pid 文件名字
指定端口
Log 文件名字
Dump.rdb 名字
Appendonly 关掉或换名字
- redis cluster 配置修改
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进入主从切换
- 启动6个redis服务
- 将6个节点合成一个集群
注意:需要确保所有redis实例启动后,nodes-xxxx.conf文件都正常生成。
cd /opt/redis-6.2.1/src 进入redis安装目录
redis-cli --cluster create --cluster-replicas 1 192.168.11.101:6379 192.168.11.101:6380 192.168.11.101:6381 192.168.11.101:6389 192.168.11.101:6390 192.168.11.101:6391
–replicas 1 采用最简单的方式配置集群,一台主机一台从机,刚好三组
注意:这里要使用真实ip地址,不要用127.0.0.1
- -c 采用集群策略连接,设置数据会自动切换到相应的写主机
redis-cli -c -p 6379
- 通过命令查看集群信息
cluster nodes
- redis cluster如何分配这6个节点?
一个集群至少要有三个主节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
什么是slots(插槽)
就是哈希槽,数据库中的每个键都属于这些插槽中的一个,集群使用CRC16(key) % 插槽数量来计算key属于哪个槽(计算CRC16校验和)。集群中的每个节点负责处理一部分插槽。
**注意:**不在一个slot的键值,不能使用 mset 和 mget 等多键操作!
解决方法:通过{}定义组,从而使key中{}内相同内容的键值对放到一个slot中去。
mset k1{cust} v1 k2{cust} v2
查询集群中的值
注意:只能看自己的插槽啊,看不到别人的
cluster keyslot cust
cluster countkeysinslot xxxx
cluster getkeysinslot xxxx
故障恢复
如果主节点挂了,从节点能否自动升为主节点?注意:15s超时
主节点恢复后,主从关系会如何?主节点回来变成从机。
如果拥有某一段插槽的主从节点都挂了,redis服务还能继续吗?
- 如果 cluster-require-full-converage 为yes,则整个集群挂掉;
- 为no,该插槽数据全部不能使用,也无法存储;
注:该参数在redis.conf中
集群的Jedis开发
public class JedisClusterTest{
public static void main(String[] args){
HostAndPort hostAndPort = new HostAndPort("192.168.31.211", 6379);
JedisCluster jedisCluster = new JedisCluster(hostAndPort);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
jedisCluster.close();
}
}
优点
实现扩容、分摊压力、无中心配置相对简单
不足
- 多键操作不支持
- 多键的Redis事务不被支持,lua脚本不被支持
- 出现时间较晚,已经采用其他集群方案的公司想要迁移到redis cluster,需要整体迁移而不是逐步过渡,复杂度较高
应用问题解决
缓存穿透
观察到的现象:
- 应用服务器压力变大了
- redis命中率降低
- 一直查询数据库,然后数据库崩溃了
发生什么事
- redis查询不到数据库
- 出现很多非正常url访问
原因
遭到攻击
解决方案
- 对空值缓存:如果一个查询返回的数据为空(无论数据是否存在),我们扔把空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过5min
- 设置可访问的名单(白名单):用 bitmaps 类型定义一个可以访问的名单,名单 id 作为 bitmaps 的偏移量,每次访问和 bitmaps 里的 id 进行比较,如果访问 id 不在 bitmaps 里,进行拦截,不允许访问
- 采用布隆过滤器(Bloom Filter):1970年由布隆提出的。实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否存在一个集合中。它的优点是空间效率和查询时间都远远超过一般算法,缺点是有一定的误识别率和删除困难
- 进行实时监控:当发现 Redis 的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
缓存击穿
现象
- 数据库访问压力瞬时增加
- redis 里面没有出现大量的 key 过期
- redis 正常运行
原因
- redis 某个 key 过期了,大量访问使用这个 key
解决方案
- 预先设置热门数据:在 redis 高峰访问之前,把一些热门数据提前存入到 redis里面,加大这些热门数据 key 的时长
- 实时调整:现场监控哪些数据热门,实时调整 key 的过期时长
- 使用锁:
1)在缓存失效的时候(判断拿出来的值为空),不是立即去 load db
2)先使用缓存工具的某些带成功返回值的操作(如 Redis 的 SETNX)去 set 一个 mutex key
3)当操作返回成功时,再进行 load db操作,并回设缓存,最后删除 mutex key
4)当操作返回失败,证明有线程在 load db,当前线程睡眠一段时间再重试整个 get 缓存的方法
缓存雪崩
现象
- 数据库压力变大
- 服务器崩溃
原因
- 在极少时间内,查询大量 key 的集中过期情况
解决方法
- 构建多级缓存架构:nginx 缓存 + redis 缓存 + 其他缓存(ehcache等)
- 使用锁或队列:用加锁或队列的方式保证不会有大量线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
- 设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际 key 的缓存
- 将缓存失效时间分散开:比如我们可以在原有的失效时间上加一个随机值,比如 1-5 min 随机,这样每一个缓存过期时间的重复率就会降低,很难引发集体失效的事件
分布式锁
单纯 Java API 不能提供分布式锁的能力,需要一种跨 JVM 的互斥机制来控制共享资源的访问。
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis等)
- 基于Zookeeper
性能上 redis 最高,可靠性上 zookeeper 最高。
使用redis实现分布式锁
- setnx + del 实现上锁和释放锁
- 锁一直没有释放,设置 key 过期时间,自动释放
- 上锁后突然出现异常,无法设置过期时间——上锁时同时设置过期时间
set users 10 nx ex 12
UUID防止误删
@GetMapping("testLock")
public void testLock(){
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111", 3, TimeUnit.SECONDS);
if (lock){
Object value = redisTemplate.opsForValue().get("num");
if (StringUtils.isEmpty(value)){
return ;
}
int num = Integer.parseInt(value + " ");
redisTemplate.opsForValue().set("num", ++num);
redisTemplate.delete("lock");
} else{
try{
Thread.sleep(100);
testLock();
} catch (InterruptedException){
e.printStackTrace();
}
}
}
问题:可能释放其他服务器的锁
@GetMapping("testLock")
public void testLock(){
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS);
if (lock){
Object value = redisTemplate.opsForValue().get("num");
if (StringUtils.isEmpty(value)){
return ;
}
int num = Integer.parseInt(value + " ");
redisTemplate.opsForValue().set("num", ++num);
String lockUuid = (String) redisTemplate.opsForValue().get("lock");
if (lockUuid.equals(uuid)) {
redisTemplate.delete("lock");
}
} else{
try{
Thread.sleep(100);
testLock();
} catch (InterruptedException){
e.printStackTrace();
}
}
}
LUA保证删除原子性
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEY[1]) else return 0 end";
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
redisScript.setResultType(Long.class);
redisTemplate.execute(redisScript, Arrays.asList(lockKey), uuid);
确保分布式锁满足以下4个条件:
- 互斥。任意时刻,只有一个客户端能持有锁;
- 不会发生死锁。即使有一个客户端在持有锁期间挂了而没有主动解锁,也能保证后续其他金额护短能加锁;
- 加锁和解锁必须是同一个客户端,并且不能把别人加的锁释放;
- 加锁和解锁必须具有原子性。