一、简介
GNN(Graph Neural Network)和GCN(Graph Convolutional Network)都是基于图结构的神经网络模型。本文目标就是打代码基础,未用PyG,来扒一扒Graph Net两个基础算法的原理。直接上代码。
二、代码
import time
import random
import os
import numpy as np
import math
from torch.nn.parameter import Parameter
from torch.nn.modules.module import Module
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import scipy.sparse as sp
#配置项
class configs():
def __init__(self):
# Data
self.data_path = r'E:\code\Graph\data'
self.save_model_dir = r'\code\Graph'
self.model_name = r'GCN' #GNN/GCN
self.seed = 2023
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.batch_size = 64
self.epoch = 200
self.in_features = 1433 #core ~ feature:1433
self.hidden_features = 16 # 隐层数量
self.output_features = 8 # core~paper-point~ 8类
self.learning_rate = 0.01
self.dropout = 0.5
self.istrain = True
self.istest = True
cfg = configs()
def seed_everything(seed=2023):
random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
seed_everything(seed = cfg.seed)
#数据
class Graph_Data_Loader():
def __init__(self):
self.adj, self.features, self.labels, self.idx_train, self.idx_val, self.idx_test = self.load_data()
self.adj = self.adj.to(cfg.device)
self.features = self.features.to(cfg.device)
self.labels = self.labels.to(cfg.device)
self.idx_train = self.idx_train.to(cfg.device)
self.idx_val = self.idx_val.to(cfg.device)
self.idx_test = self.idx_test.to(cfg.device)
def load_data(self,path=cfg.data_path, dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt(os.path.join(path,dataset,dataset+'.content'),
dtype=np.dtype(str))
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = self.encode_onehot(idx_features_labels[:, -1])
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt(os.path.join(path,dataset,dataset+'.cites'),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = self.normalize(features)
adj = self.normalize(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = self.sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
def encode_onehot(self,labels):
classes = set(labels)
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in
enumerate(classes)}
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
return labels_onehot
def normalize(self,mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def sparse_mx_to_torch_sparse_tensor(self,sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
#精度评价指标
def accuracy(output, labels):
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
#模型
#01-GNN
class GNNLayer(nn.Module):
def __init__(self, in_features, output_features):
super(GNNLayer, self).__init__()
self.linear = nn.Linear(in_features, output_features)
def forward(self, adj_matrix, features):
hidden_features = torch.matmul(adj_matrix, features) # GNN公式:H' = A * H
hidden_features = self.linear(hidden_features) # 使用线性变换
hidden_features = F.relu(hidden_features) # 使用ReLU作为激活函数
return hidden_features
class GNN(nn.Module):
def __init__(self, in_features, hidden_features, output_features, num_layers=2):
super(GNN, self).__init__()
#输入维度in_features、隐藏层维度hidden_features、输出维度output_features、GNN的层数num_layers
self.layers = nn.ModuleList(
[GNNLayer(in_features, hidden_features) if i == 0 else GNNLayer(hidden_features, hidden_features) for i in
range(num_layers)])
self.output_layer = nn.Linear(hidden_features, output_features)
def forward(self, adj_matrix, features):
hidden_features = features
for layer in self.layers:
hidden_features = layer(adj_matrix, hidden_features)
output = self.output_layer(hidden_features)
return F.log_softmax(output,dim=1)
#02-GCN
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
class GCN(nn.Module):
def __init__(self, in_features, hidden_features, output_features, dropout=cfg.dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(in_features, hidden_features)
self.gc2 = GraphConvolution(hidden_features, output_features)
self.dropout = dropout
def forward(self, adj_matrix, features):
x = F.relu(self.gc1(features, adj_matrix))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj_matrix)
return F.log_softmax(x, dim=1)
class graph_run():
def train(self):
t = time.time()
#Create Train Processing
all_data = Graph_Data_Loader()
#创建一个模型
model = eval(cfg.model_name)(in_features=cfg.in_features,
hidden_features=cfg.hidden_features,
output_features=cfg.output_features).to(cfg.device)
optimizer = optim.Adam(model.parameters(),
lr=cfg.learning_rate, weight_decay=5e-4)
#Train
model.train()
for epoch in range(cfg.epoch):
optimizer.zero_grad()
output = model(all_data.adj, all_data.features)
loss_train = F.nll_loss(output[all_data.idx_train], all_data.labels[all_data.idx_train])
acc_train = accuracy(output[all_data.idx_train], all_data.labels[all_data.idx_train])
loss_train.backward()
optimizer.step()
loss_val = F.nll_loss(output[all_data.idx_val], all_data.labels[all_data.idx_val])
acc_val = accuracy(output[all_data.idx_val], all_data.labels[all_data.idx_val])
print('Epoch: {:04d}'.format(epoch + 1),
'loss_train: {:.4f}'.format(loss_train.item()),
'acc_train: {:.4f}'.format(acc_train.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}s'.format(time.time() - t))
torch.save(model, os.path.join(cfg.save_model_dir, 'latest.pth')) # 模型保存
def infer(self):
#Create Test Processing
all_data = Graph_Data_Loader()
model_path = os.path.join(cfg.save_model_dir, 'latest.pth')
model = torch.load(model_path, map_location=torch.device(cfg.device))
model.eval()
output = model(all_data.adj,all_data.features)
loss_test = F.nll_loss(output[all_data.idx_test], all_data.labels[all_data.idx_test])
acc_test = accuracy(output[all_data.idx_test], all_data.labels[all_data.idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
if __name__ == '__main__':
mygraph = graph_run()
if cfg.istrain == True:
mygraph.train()
if cfg.istest == True:
mygraph.infer()
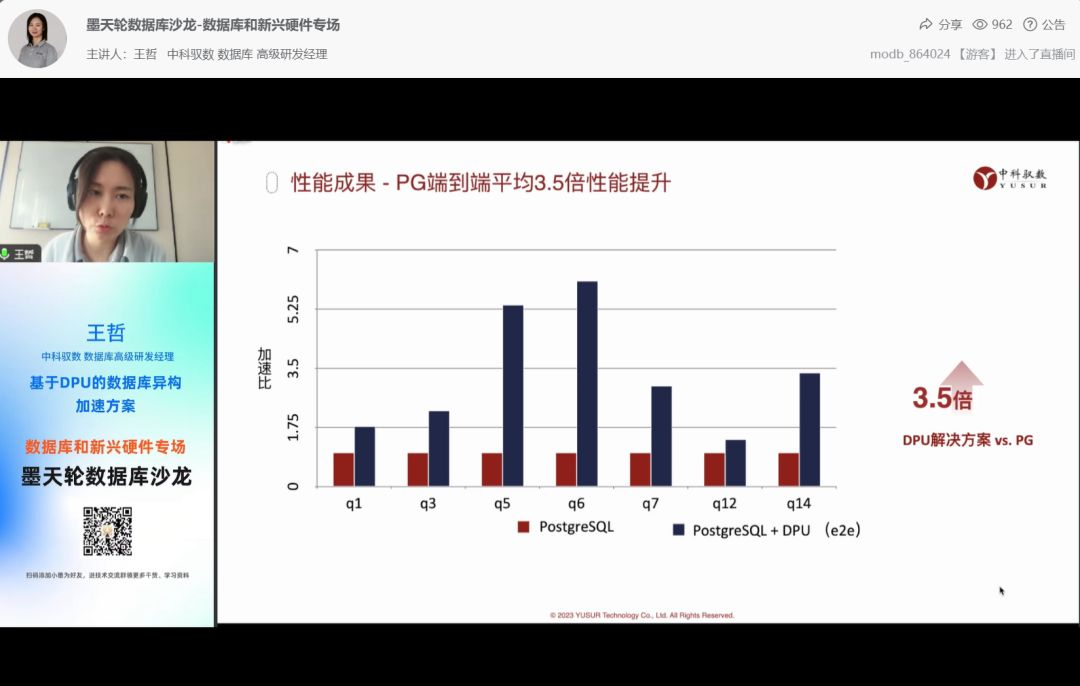
三、结果与讨论
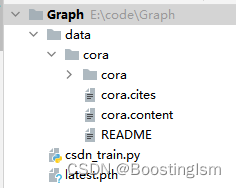
需要从网上下载cora数据集,数据组织形式如下图。
测了下Params和GFLOPs,还是比较大的,发现若作为一个Net的Block还是需要优化的哈哈~
| Model | Params | GFLOPs |
| GNN | 23.352K | 126.258M |
| Model | Cora(/train/val/test) |
| GNN | 1.0000/0.7800/0.7620 |
| GCN | 0.9714/0.7767/0.8290 |
四、展望
未来可以考虑用PyG(PyTorch Geometric),毕竟PyG实现GAT等图网络、图的数据组织、加载会更加方便。Graph Net通常用可以用于属性数据的embedding模式,将属性数据可以作为一种补充特征加入Net去训练,看能不能发挥效能。