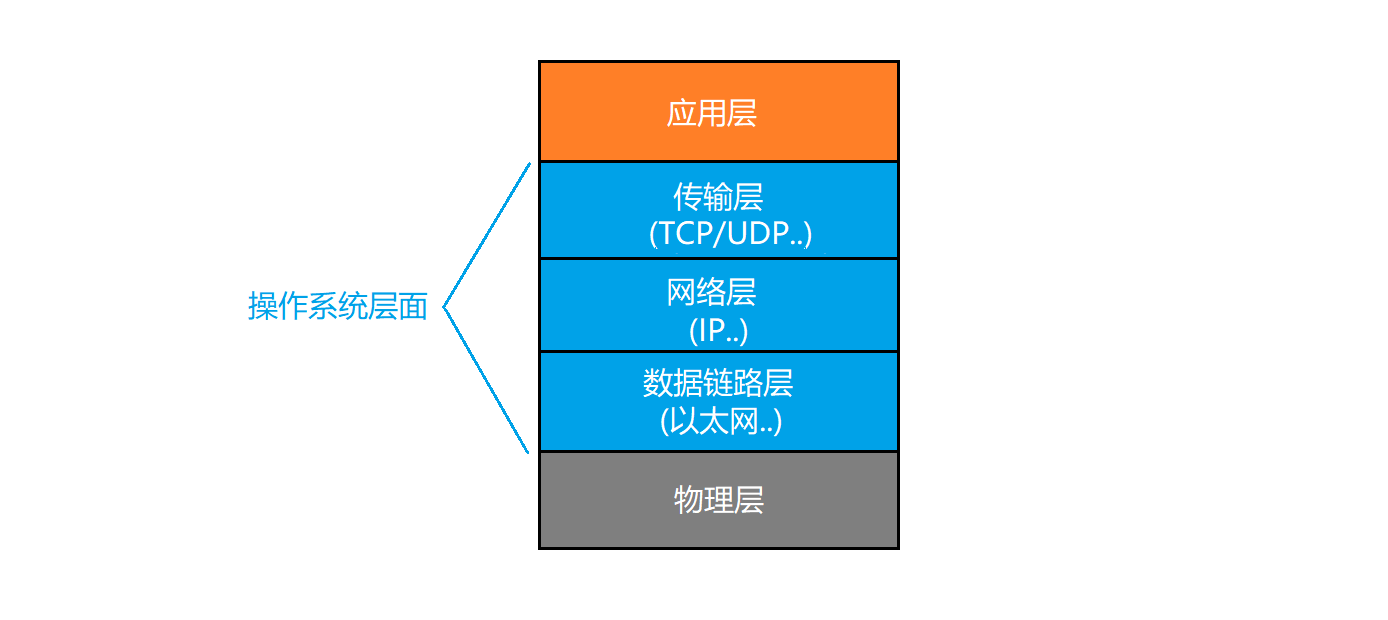
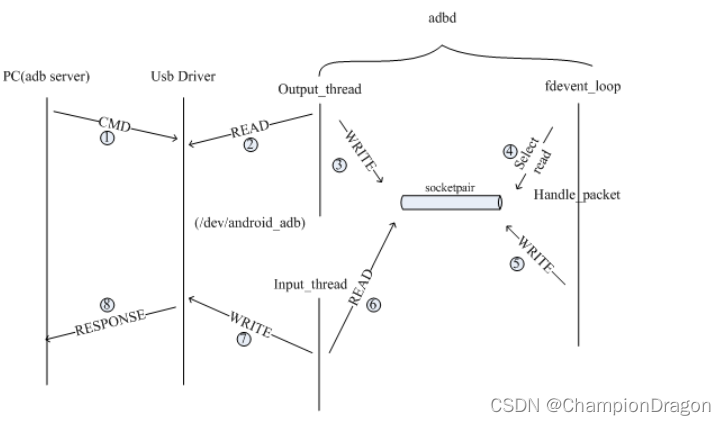
前言
PEFT 方法仅微调少量(额外)模型参数,同时冻结预训练 LLM 的大部分参数
第一部分 高效参数微调的发展史
1.1 Google之Adapter Tuning:嵌入在transformer里 原有参数不变 只微调新增的Adapter
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对 BERT 的 PEFT 微调方式,拉开了 PEFT 研究的序幕。他们指出
- 在面对特定的下游任务时,如果进行 Full-fintuning(即预训练模型中的所有参数都进行微调),太过低效
- 而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果
于是他们设计了如下图所示的 Adapter 结构
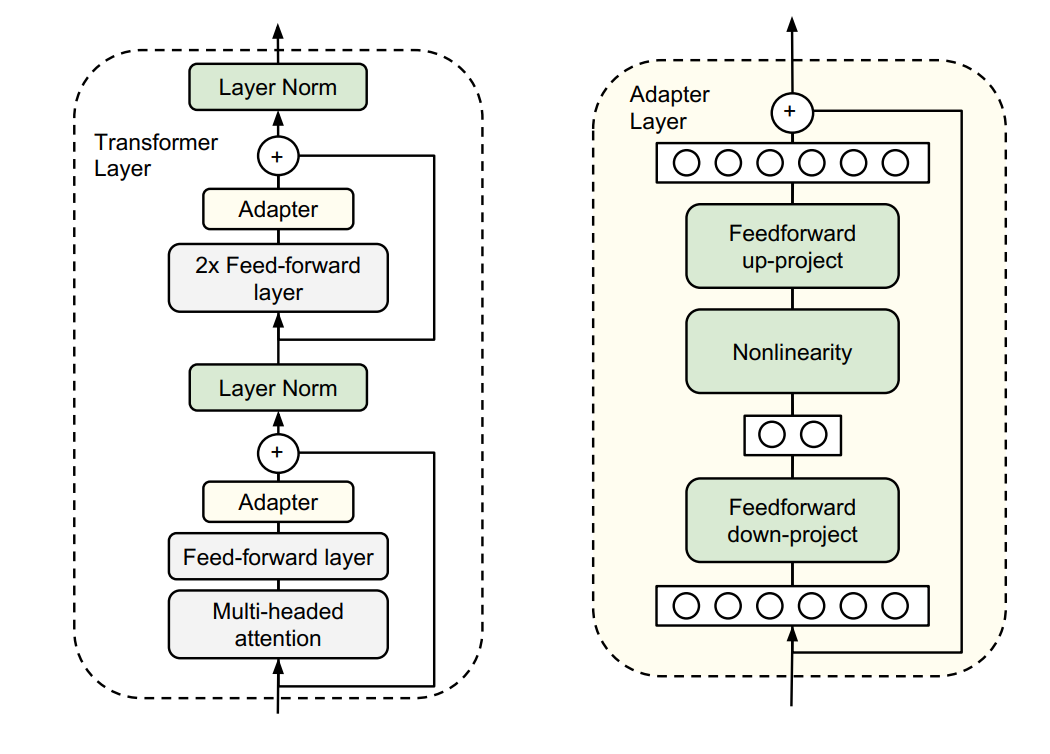
- 如上图左侧所示,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调
- 如上图右侧所示,同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:首先是一个 down-project 层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征;同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为 identity