【数据结构】基础:常见排序算法
摘要:本文将从排序的概念及其附属概念出发,再对排序算法进行分类,并对其思想与实现进行说明,最后对各个算法进行总结。
文章目录
- 【数据结构】基础:常见排序算法
- 一. 排序的概念
- 1.1 排序的概念
- 1.2 稳定性
- 1.3 内部排序与外部排序
- 二. 常见的排序算法
- 2.1 常见算法分类
- 2.2 插入排序
- 2.2.1 直接插入排序
- 2.2.2 希尔排序(缩小增量法)
- 2.3 选择排序
- 2.3.1 直接选择排序
- 2.3.2 堆排序
- 2.4 交换排序
- 2.4.1 冒泡排序
- 2.4.2 快速排序
- 递归实现
- 基准值选择
- 三种分裂方式详解
- 优化实现
- 非递归实现
- 优化:三路划分
- 总结
- 2.5 归并排序
- 递归实现
- 非递归实现
- 总结
- 三. 排序总结
一. 排序的概念
1.1 排序的概念
给定一个串序列R1、R2、…、Rn,键值分别为k1、k2、…、kn,将记录按任意顺序排列,使得序列Rs1、Rs2、…、Rsn的键值符合ks1≤ks2≤…≤ksn的性质。
1.2 稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
1.3 内部排序与外部排序
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
二. 常见的排序算法
2.1 常见算法分类
排序算法可以分为四大类与七小类,四大类可以分为:插入、选择、交换与归并。该四类的分类方式为排序的方法过程来区分。插入排序是通过找出适合的位置进行插入,选择排序是选择最大或最小的按照升降序进行排序,交换排序是通过对各个元素进行特定要求的交换从而达到分类的目的,归并排序则是通过不断的拆分与合并完成排序。而七小类是对每一种方法大思想的基础与优化的划分,插入排序可以分为直接插入排序与希尔排序,选择排序可以分为选择排序与堆排序,交换排序可以分为冒泡排序与快速排序,分类图如下图所示:

2.2 插入排序
插入排序的思想:把待排序的序列按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的序列插入完为止,得到一个新的有序序列。其中分为直接插入排序与希尔排序,直接插入排序为直接对插入排序思想的运用,而希尔排序则是先经过一段的预排序,最后进行插入排序,从而减少排序次数。
2.2.1 直接插入排序
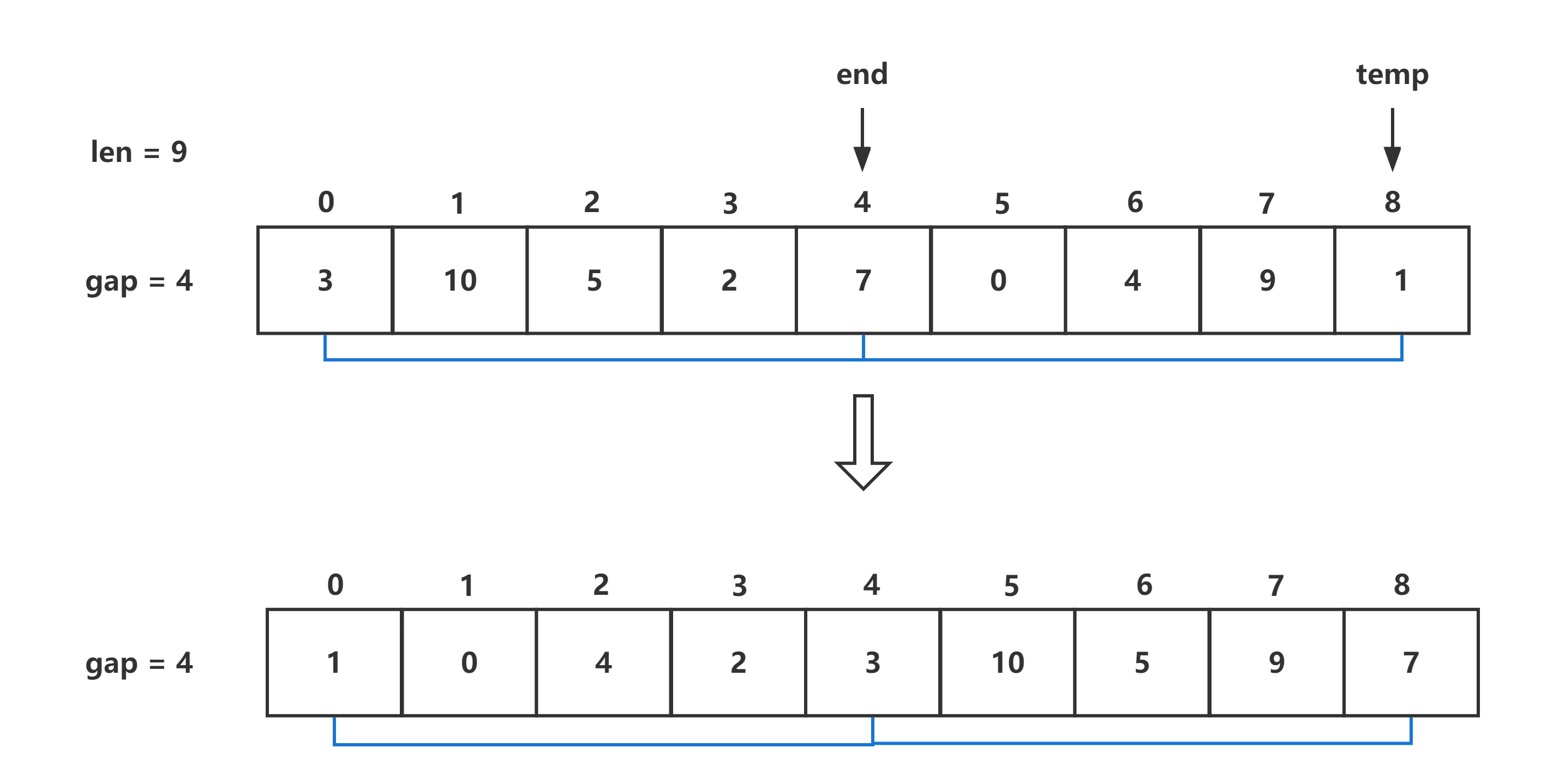
思想:当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移。

书写方法:由内到外的书写,首先书写关于一个元素插入的过程,再完成每个元素插入的过程。假设需要插入到已经排序好的序列中,该序列尾的下标为end,需要插入的值为end + 1。因为在序列进行后移的过程中,会对需要插入的值进行覆盖,因此用一个临时变量temp进行保存。当序列中的值大于temp时,将该值往后移动,直到遇到小于或者遇到序列头才结束循环,最后插入到相应位置,该段代码如下:
int end;//序列尾
int temp = arr[end + 1];//插入元素
int j = end;
// 进行遍历
while (j >= 0) {
if (arr[j] >= temp) {
arr[j + 1] = arr[j];
j--;
}
else {
break;
}
}
// 插入
arr[j + 1] = temp;
对于单步操作完成后,进行完整的排序工作,通过对每一个元素进行插入,但是需要注意越界的问题,对于插入的元素而言,是从第二个(只有一个元素序列为有序)到最后一个,因此序列尾的范围为第一个到导数第一个,完成代码如下
void InsertSort(int *arr, int len) {
//越界问题:对于插入的元素而言,是从第二个(只有一个元素序列为有序)到最后一个,因此序列尾的范围为第一个到导数第一个
for (int i = 0; i < len - 1; i++) {
int end = i;
int temp = arr[end + 1];
int j = end;
while (j >= 0) {
if (arr[j] >= temp) {
arr[j + 1] = arr[j];
j--;
}
else {
break;
}
}
arr[j + 1] = temp;
}
}
总结
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:稳定
注意:元素集合越接近有序,直接插入排序算法的时间效率越高
2.2.2 希尔排序(缩小增量法)
思想:将插入排序进行预排序与直接插入排序,在直接插入排序前,先选择一个间隔,通过该间隔数将序列分组,并对每一个组进行排序,当对一定间隔的组排序完成后,通过不同的间隔继续排序,最后再对序列进行直接插入排序。示意图如下:
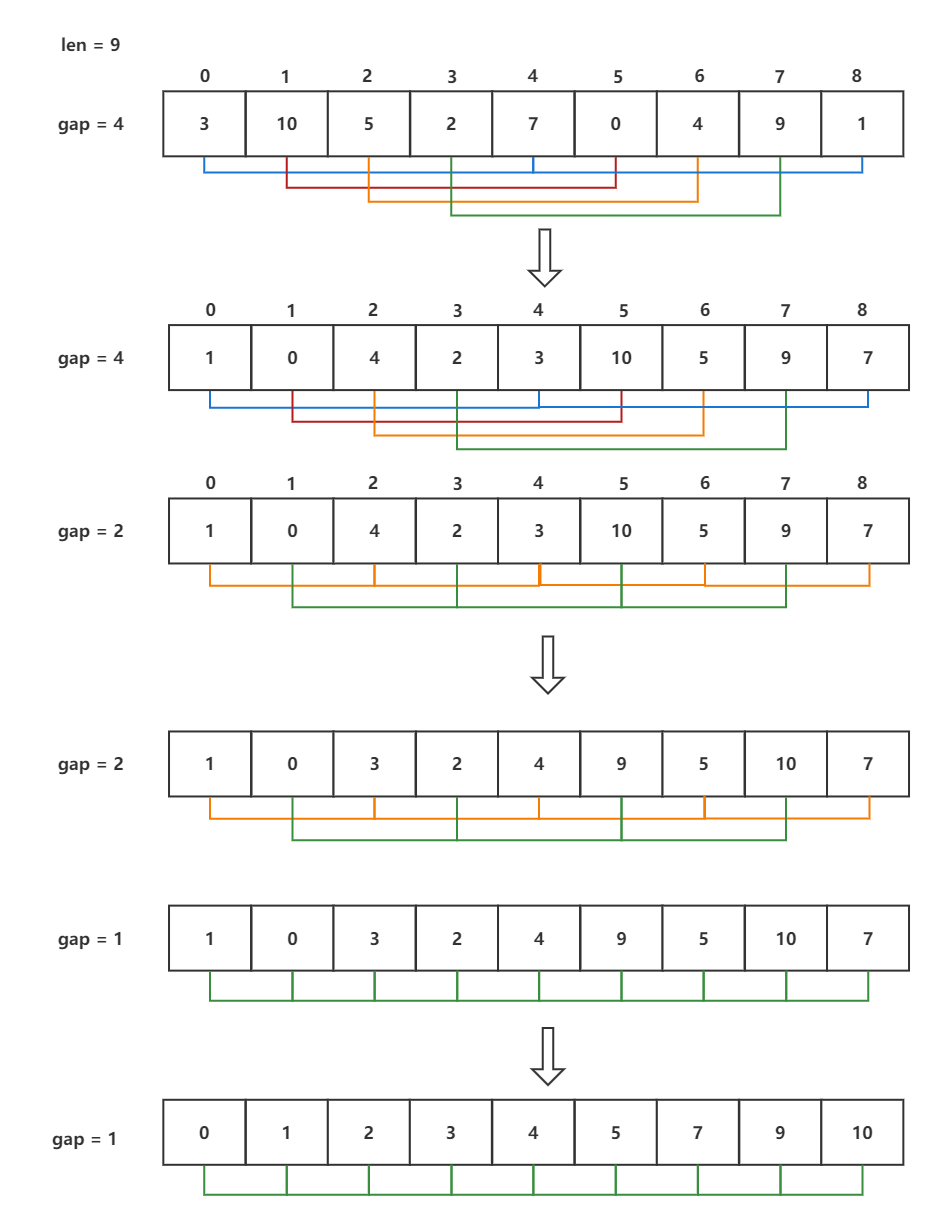
书写方法:用内向外进行书写,首先书写预排序中每组的数据插入,再将每组的数据进行间隔插入排序,然后对每一组进行排序,最后根据不同的间隔重复该排序过程。完成预排序后进行直接插入排序。
首先对每组的单个元素进行插入排序,这一步很像直接插入排序中对单个元素的插入排序,只不过对于需要插入的元素和插入组的间隔需要修改。在此需要插入的元素为序列尾的后间隔数位的元素,对于后移过程与遍历序列的过程,间隔数需要修改,代码示例如下:
//每组的单个元素进行插入排序
int end = i; // 序列尾
int temp = arr[end + gap]; // 需要插入的元素
while (end >= 0) {
// 插入后移的过程
if (arr[end] >= temp) {
arr[end + gap] = arr[end];
end -= gap;
}
else
break;
}
arr[end + gap] = temp;
其次对于每组的每个数据进行间隔插入排序,该步与插入排序的全过程类似,不过是对于组间隔数不为1的组进行的,而尾序列的终止条件为序列长度减去间隔数,该位置的意义为第一组的序列末尾,这样可以有效的防止越界,代码示例如下:
for (int i = j; i < len - gap; i += gap) {
//每组的单个元素进行插入排序
int end = i; // 序列尾
int temp = arr[end + gap]; // 需要插入的元素
while (end >= 0) {
// 插入后移的过程
if (arr[end] >= temp) {
arr[end + gap] = arr[end];
end -= gap;
}
else
break;
}
arr[end + gap] = temp;
}
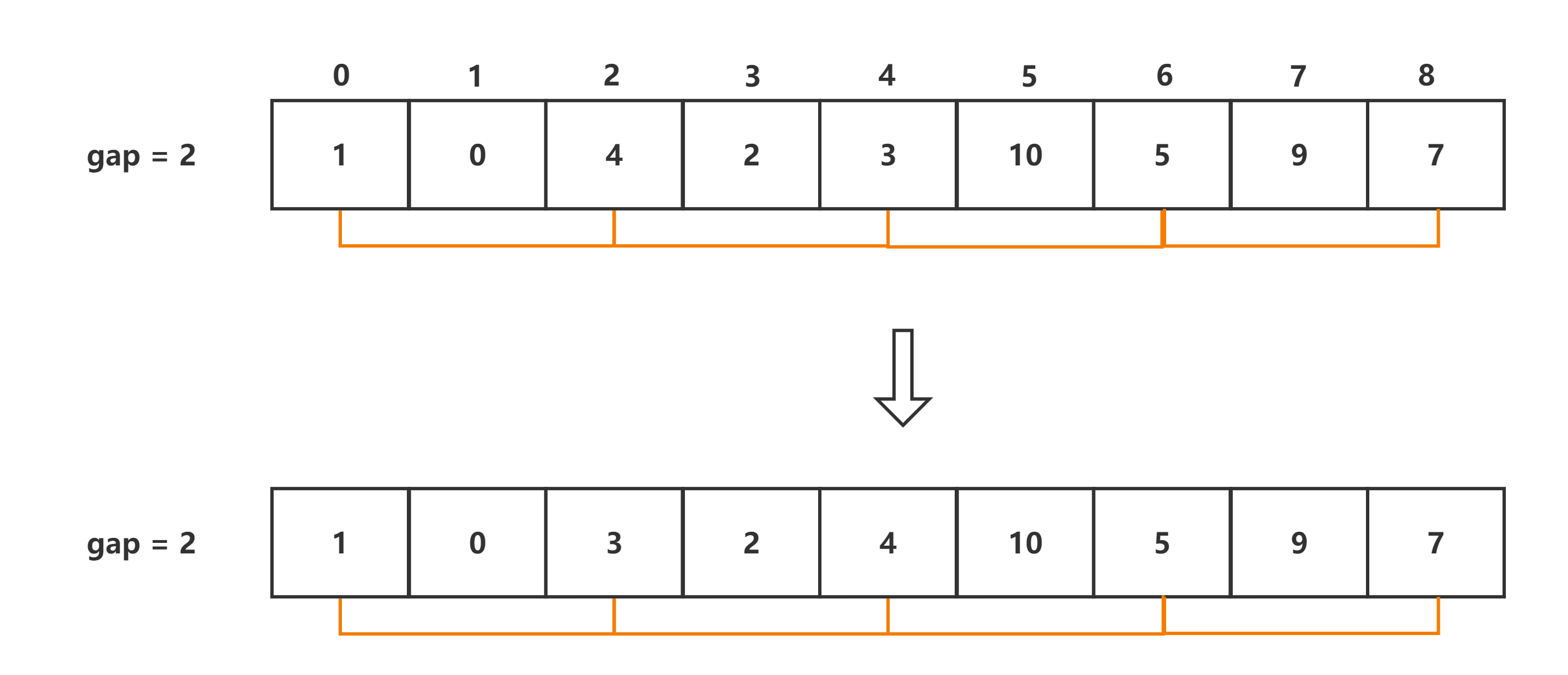
但是可能会有疑问就是为什么不是每组的末尾,实际上并不是每组的元素数量都是相等的,对于少的组来说,使用了多的组的序列末尾数将会发生越界的问题,示意图如下:

完成后对于一组的循环书写后,进行对于每组的循环书写,由于分组的策略,组数就是间隔数,代码示例如下:
for (int j = 0; j < gap; j++) { // 对每一组进行排序
for (int i = j; i < len - gap; i += gap) {
// 每一组进行插入排序但是间隔为gap
// 起点是j 终点为什么不是 len-gap+j 呢?
//每组的单个元素进行插入排序
int end = i; // 序列尾
int temp = arr[end + gap]; // 需要插入的元素
while (end >= 0) {
// 插入后移的过程
if (arr[end] >= temp) {
arr[end + gap] = arr[end];
end -= gap;
}
else
break;
}
arr[end + gap] = temp;
}
}

最后进行每一组间隔的排序,当然很容易发现,当间隔数为1时就是直接插入排序,因此可以设置gap = len / 2的策略或者gap = len/3 + 1 的策略,这样一定会进行完预排序后进行直接插入排序,在此通过gap = len / 2 距离,完成代码如下:
void ShellSort(int* arr, int len) {
int gap = len;
while (gap >= 1) { // gap >1预排序 =1 插入排序
gap /= 2;
for (int j = 0; j < gap; j++) { // 对每一组进行排序
for (int i = j; i < len - gap; i += gap) {
// 每一组进行插入排序但是间隔为gap
// 起点是j 终点为什么不是 len-gap+j 呢?
//每组的单个元素进行插入排序
int end = i; // 序列尾
int temp = arr[end + gap]; // 需要插入的元素
while (end >= 0) {
// 插入后移的过程
if (arr[end] >= temp) {
arr[end + gap] = arr[end];
end -= gap;
}
else
break;
}
arr[end + gap] = temp;
}
}
}
}
总结
时间复杂度:O(N^1.25) 到 O(1.6 * N^1.25)
空间复杂度:O(1)
稳定性:不稳定
希尔排序是对直接插入排序的优化,当gap > 1时是预排序,目的是让数组更接近于有序。当gap = 1时,数组已经接近有序,直接插插入排序速率加快。整体而言,可以达到优化的效果
希尔排序的时间复杂度难以计算,因为gap的取值方法很多,在此不做证明
2.3 选择排序
选择排序的思想是每一次从待排序的序列中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。主要分为直接选择排序与堆排序,两者都运用了这一思想,不过选择的方式存在差距。
2.3.1 直接选择排序
思路:
- 在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素
- 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
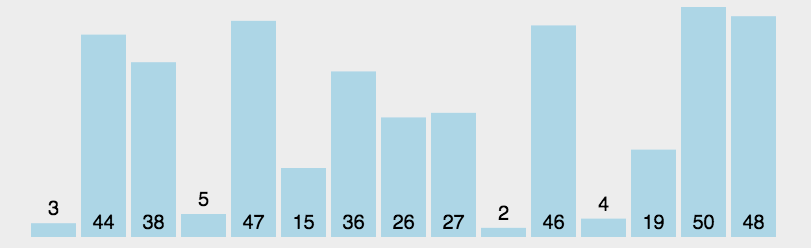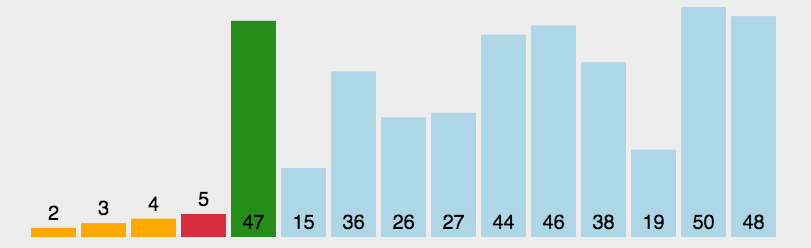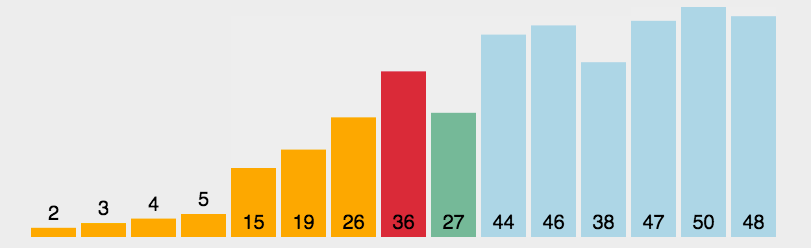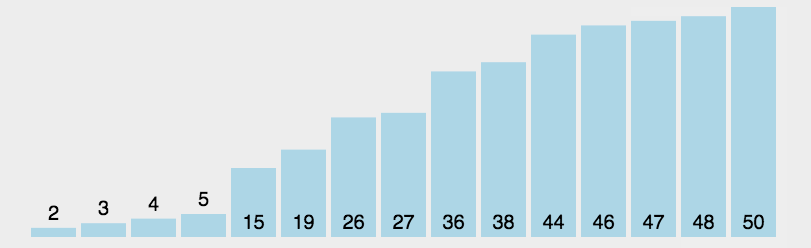
书写方法:选择排序书写方法较为简单,首先在一次循环中找出最大或最小的元素,再将其放到对应位置,对每个元素进行寻找即可完成排序,代码如下:
void SelectSort(int arr[], int size) {
for (int i = 0; i < size; i++) {
int min = arr[i];
for (int j = i + 1; j < size; j++) {
if (arr[j] < min) {
swap(&arr[j], &min);
}
}
swap(&arr[i], &min);
}
}
改进:为了提高效率,可以在一次循环中同时找到最小与最大的元素,与序列头尾进行交换,需要注意的是对于交换过程中,可能最大或者最小的位于头或尾,这样会导致交换错误,因此在面对这种特殊情况时,要对交换的位置进行修正,代码如下:
void SelectSort(int* arr, int len) {
int begin = 0;
int end = len - 1;
while (begin < end) {
int min_index = begin;
int max_index = end;
for (int i = begin ; i <= end; i++) {
if (arr[max_index] < arr[i])
max_index = i;
if (arr[min_index] > arr[i])
min_index = i;
}
swap(&arr[begin], &arr[min_index]);
if (begin == max_index) {
max_index = min_index;
}
swap(&arr[end], &arr[max_index]);
begin++;
end--;
}
}
总结:
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:不稳定
注意:直接选择排序思考非常好理解,但是效率不高,实际中很少使用。
2.3.2 堆排序
思想:通过堆得性质,不断从堆顶进行取值出堆,并保持堆的性质不变。通过升序排序为例,具体思路为,初始化时通过建堆的思路将需要排序的数组建成一个大堆(每次出堆最大值,将其放在末尾),建立好后,将最大值与末尾交换,进行下移算法,保持堆的性质,重复此过程知道所有元素排序完成。
堆排序的第一个细节是思考建立大堆还是小堆,如果为升序,那就是需要大堆,建立大堆可以将堆顶元素与末尾交换,并将数组长度减一,这样对于数组来说,堆的性质不变的,而如果是小堆则无法达成该目的。
书写方法:首先对于数组自下而上的构建堆,再不断将最后一个元素与第一个元素进行交换,向下调整,直到堆为空。
void HeapSorted(HeapDataType arr[], int len) {
// 升序
// 变成一个大堆
// 最小子树的根节点
int parent = (len - 1) / 2;
while (parent >= 0) {
AjustDown(arr, len, parent);
parent--;
}
// 将最后一个与第一个互换,向下调整
int length = len;
for (int i = 0; i < len; i++) {
swap(&arr[0], &arr[length - 1]);
AjustDown(arr, --length, 0);
}
return 0;
}
总结
时间复杂度:O(N*logN)
空间复杂度:O(1)
稳定性:不稳定
补充:关于堆与堆排序的更详细内容可访问数据结构:堆及其应用
2.4 交换排序
思想:根据序列中两个记录键值的比较结果来交换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
主要包括两种方式分别为冒泡排序与快速排序,冒泡排序是每次循环将最大的元素往上冒泡,直到所有元素冒泡完毕,较为简单。而快速排序则是通过交换,每次使得元素达到正确位置,同时以此分裂,将选定元素为之比较,分成两组,不断重复该过程。
2.4.1 冒泡排序
思想:每次循环将最大的元素往上冒泡,直到所有元素冒泡完毕。
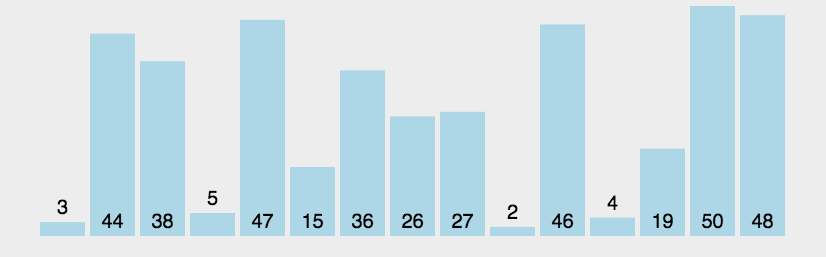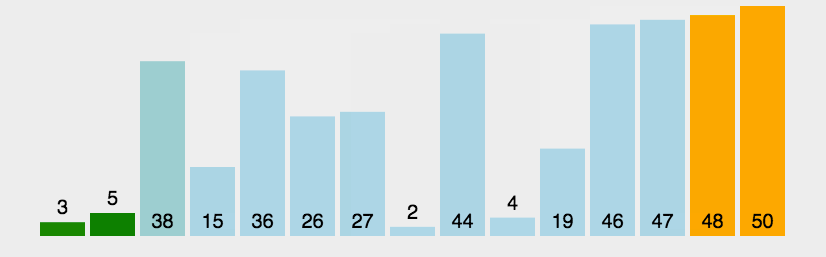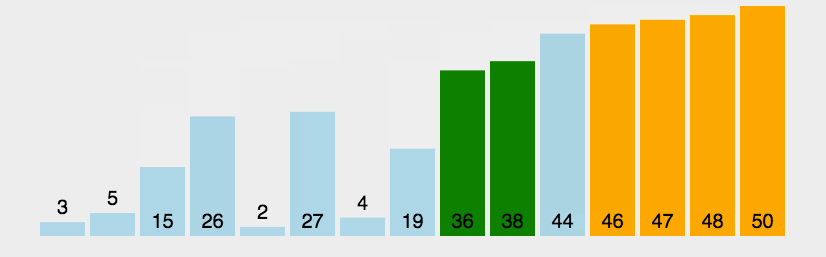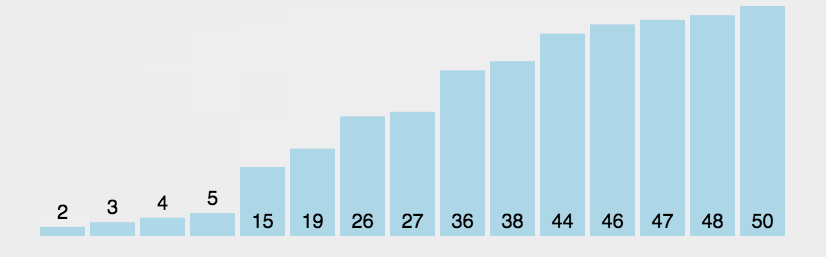
书写方法:类似于冒泡的过程,从第一个元素起与下一个元素进行比较,如果较大就要进行冒泡,即交换操作,直到为序列尾。为此可以进行优化,当不再有冒泡过程产生,说明各个元素比较大小的结果相同,即有序,因此不再需要进行循环,退出循环即可,代码如下:
void BubbleSort(int* arr, int len) {
int flag = 0;
for (int i = 0; i < len - 1; i++) {
flag = 0;
for (int j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
swap(&arr[j], &arr[j + 1]);
flag = 1;
}
}
if (flag == 0)
break;
}
}
总结
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:稳定
2.4.2 快速排序
思想:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
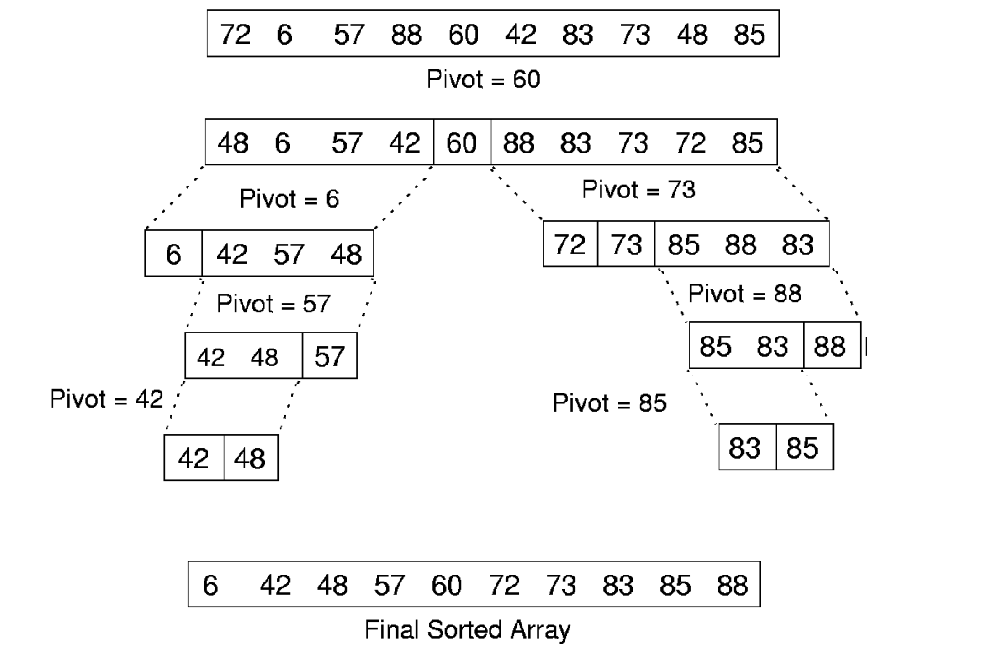
递归实现
通过递归来书写,需要掌握递归的基本方法,即明确分治思想,其中包括终止条件,如何分治为小问题,如何合并。对于快速排序,我们通过区间两端检索值来划分排序范围,当检索值为小于等于1时需要停止递归。将其分治为更小的问题的过程为,进行分裂,通过分裂后的新区间进行递归,而合并过程无需考虑,因为已经合并完成了,因此可以完成对快速排序的递归方法的代码框架书写。完成框架书写后,可以思考一下递归的过程,是类似于二叉树中的先序遍历。示例如下:
void QucikSort(int arr[], int left, int right) {
if (left >= right)
return;
// 分裂:三种方式
int key_index = partiton(arr, left, right);
//int key_index = partitonByHole(arr, left, right);
//int key_index = partitonByDoublePoint(arr, left, right);
// 递归
QucikSort(arr, left, key_index - 1);
QucikSort(arr, key_index + 1, right);
}
以下再对三种分裂方式进行介绍,三种分裂方式分别为Hoare版本、挖坑法和双指针法。在实现三种方法前,需要对基准值进行查找。基准值的查找方式主要有三种,分别为取最左端、三数取中以及随机选值。
基准值选择
取最左端数是直接获取需要分裂的序列的最左值即可,非常简单。但是当该值时刻为最小时,这样会增加快速排序分裂的次数,从而导致性能的降低。
因此人们对此改进为三数取中的方法,即选择最左键最右键与中间键进行比较,选择对应值的中位数,将其中的键返回,这样可以对有序的数据进行分裂次数的减少。
可是对于特定设计的序列,三数取中会选择到较小的或者较大的数,这样分裂次数还是较多,因此只能对其进行随机选择从而优化选择过程。
三种基准值选择法的代码如下:
int findpivotByLeft(int arr[], int left, int right) {
//getLeftIndex
return left;
}
int findpivotByMid(int arr[], int left, int right) {
//getMidIndex
int mid = left + right / 2;
if (arr[left] > arr[mid]) {
if (arr[mid] > arr[right])
return mid;
else if (arr[left] < arr[right])
return left;
else
return right;
}
else {
if (arr[right] > arr[mid])
return mid;
else if (arr[left] > arr[right])
return left;
else
return right;
}
}
int findpivotByRandom(int arr[], int left, int right) {
//getRandomIndex
int mid = (rand() % (right - left + 1)) + left;
if (arr[left] > arr[mid]) {
if (arr[mid] > arr[right])
return mid;
else if (arr[left] < arr[right])
return left;
else
return right;
}
else {
if (arr[right] > arr[mid])
return mid;
else if (arr[left] > arr[right])
return left;
else
return right;
}
}
三种分裂方式详解
Hoare版本:从序列右端往左检索,当遇到比基准值小的元素停止,让序列左端向右寻址,当遇到比基准值大的元素停止,两者进行交换并重复该过程。当左右端检索相遇,该位置为基准值的排序后位置,进行与基准值交换。
图示如下:
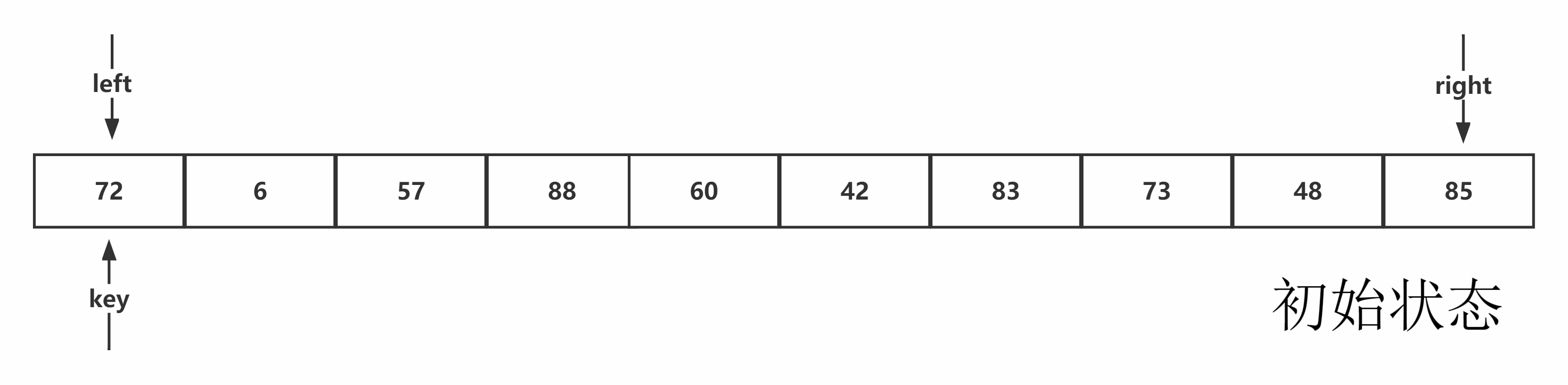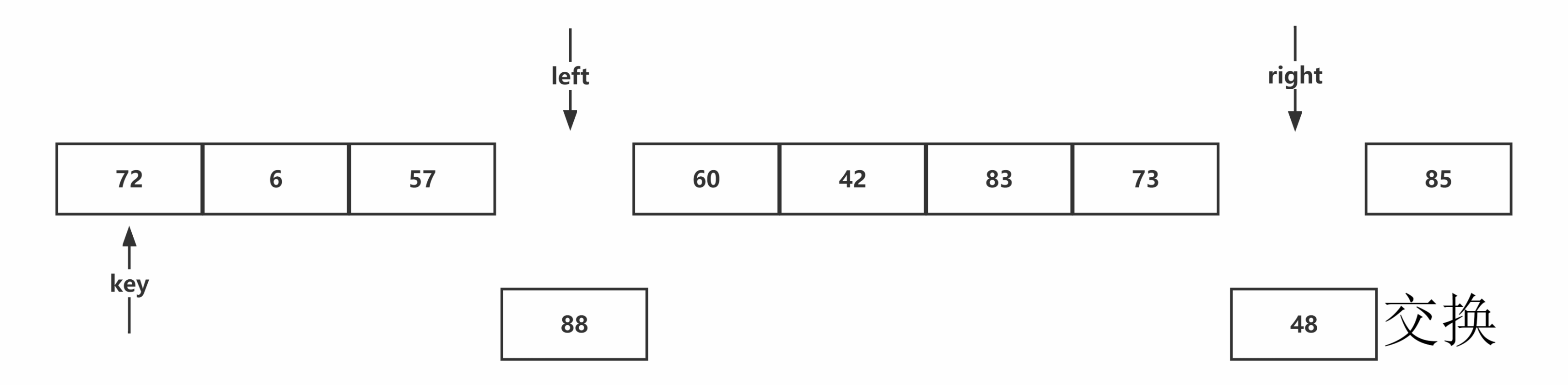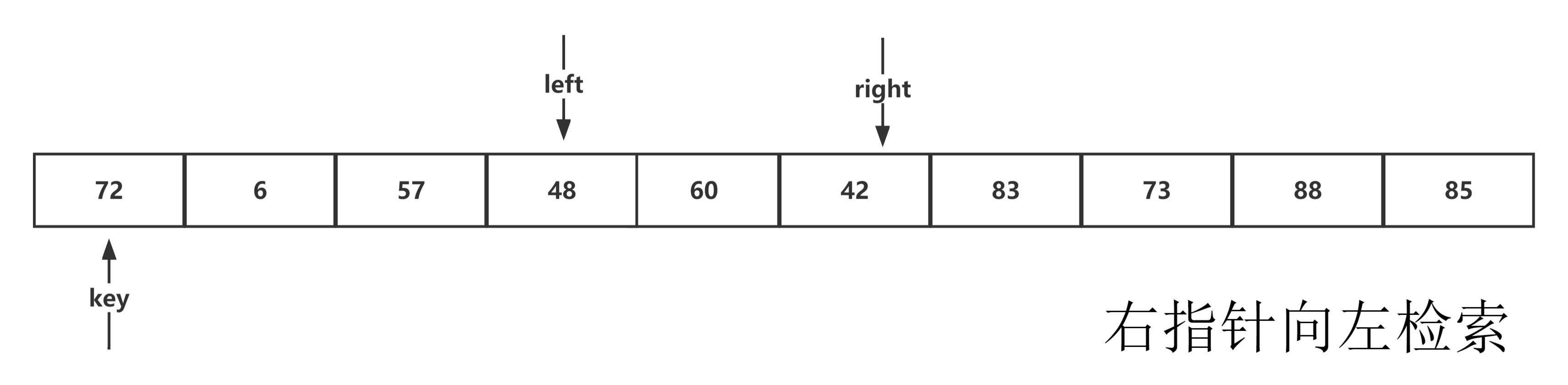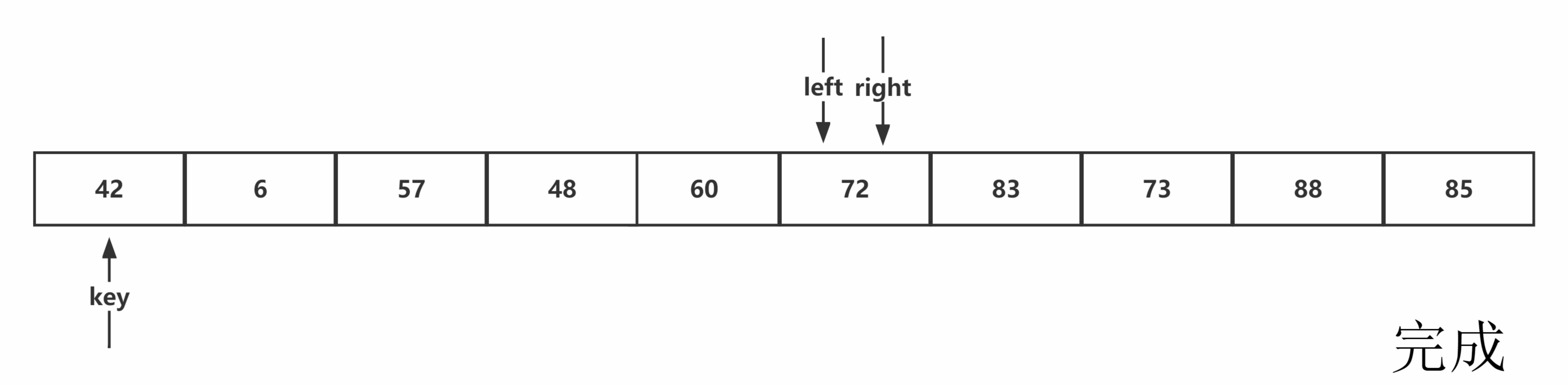
代码书写:首先找出相应的基准值,进行交换到最左侧,按照hoare方法的思路,分别定义左右指针,由先右后左的顺序,进行检索,完成检索与交换后,将基准值交换到正确排序位置,最后进行返回,其中细节有每一次都需要检查是否左右指针相遇,当与基准值相等时,也需要移动,否则无法到达边界。代码示例如下:
int partation(int *arr, int left, int right) {
int key_index = findpivot(arr, left, right);
//int key_index = left;
swap(&arr[left], &arr[key_index]);
key_index = left;
while (left < right) {
while (left < right && arr[right] >= arr[key_index])
right--;
while (left < right && arr[left] <= arr[key_index])
left++;
swap(&arr[left], &arr[right]);
}
swap(&arr[right], &arr[key_index]);
key_index = right;
return key_index;
}
注意:从右端开始查询的原因:当右端开始查询时,所有经过的元素都是大于基准值的,当相遇左检索或者遇到序列头时,所指向的元素都为小于或等于基准值的元素,与基准值交换符合排序要求。而后出发的左检索,一定会遇到右检索,此时的右检索一定小于或等于基准值。若从左开始检索相遇或者遇到序列尾时,都为大元素,不符合排序要求。
挖坑法:首先寻找基准值,并通过临时变量保存,将基准值的位置设为坑。从右开始遍历,当遇到较小值时,进行填坑,并且将当前位置作为新的坑位,再从左开始检索,当遇到较大值时,进行填坑,并将当前位置作为新的坑位,重复该过程,直至两个指针相遇。将基准值填入坑中。
图示如下:
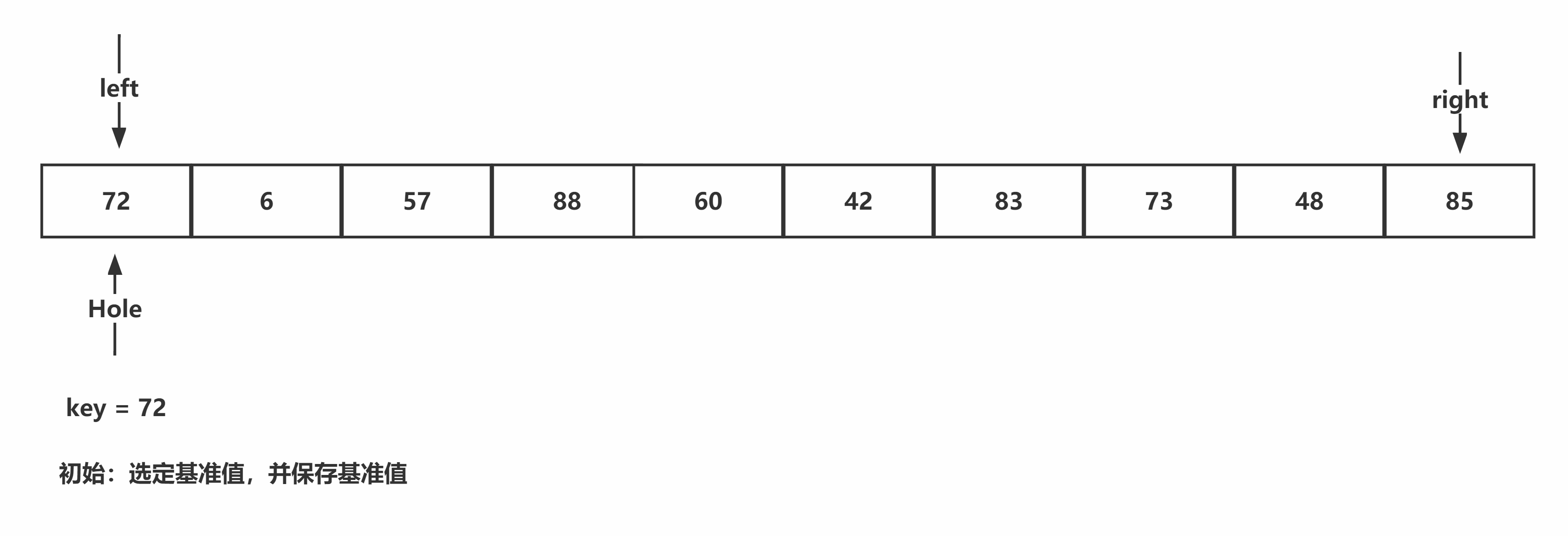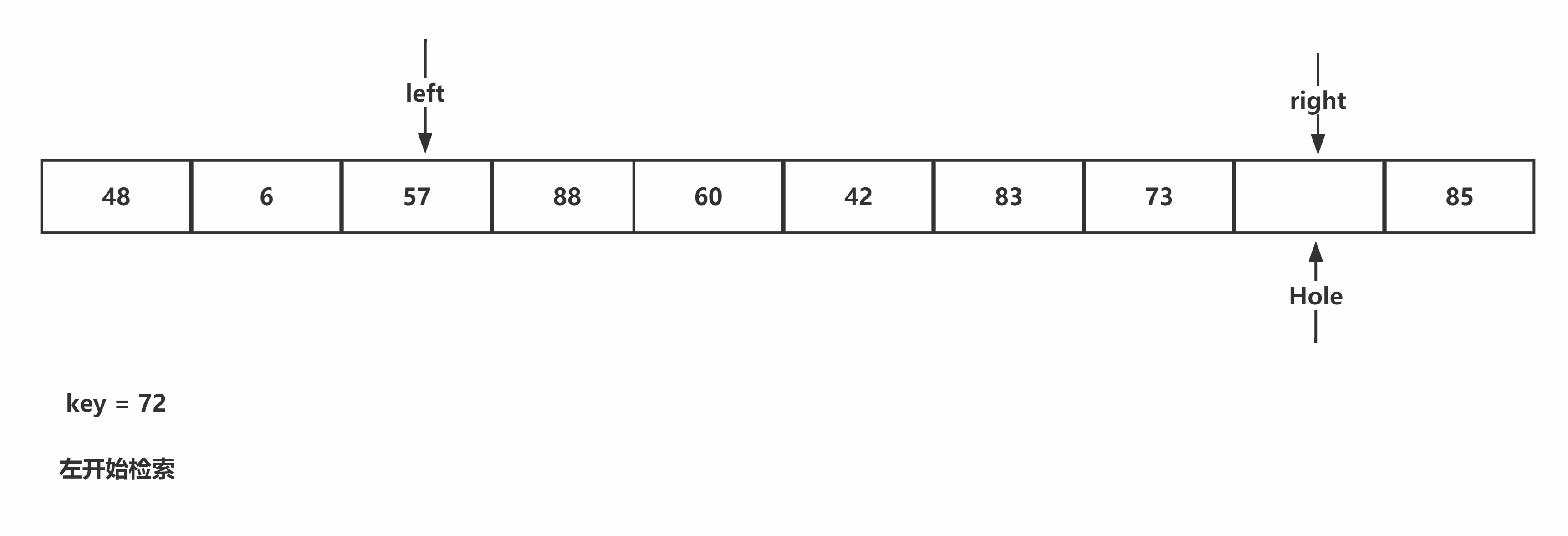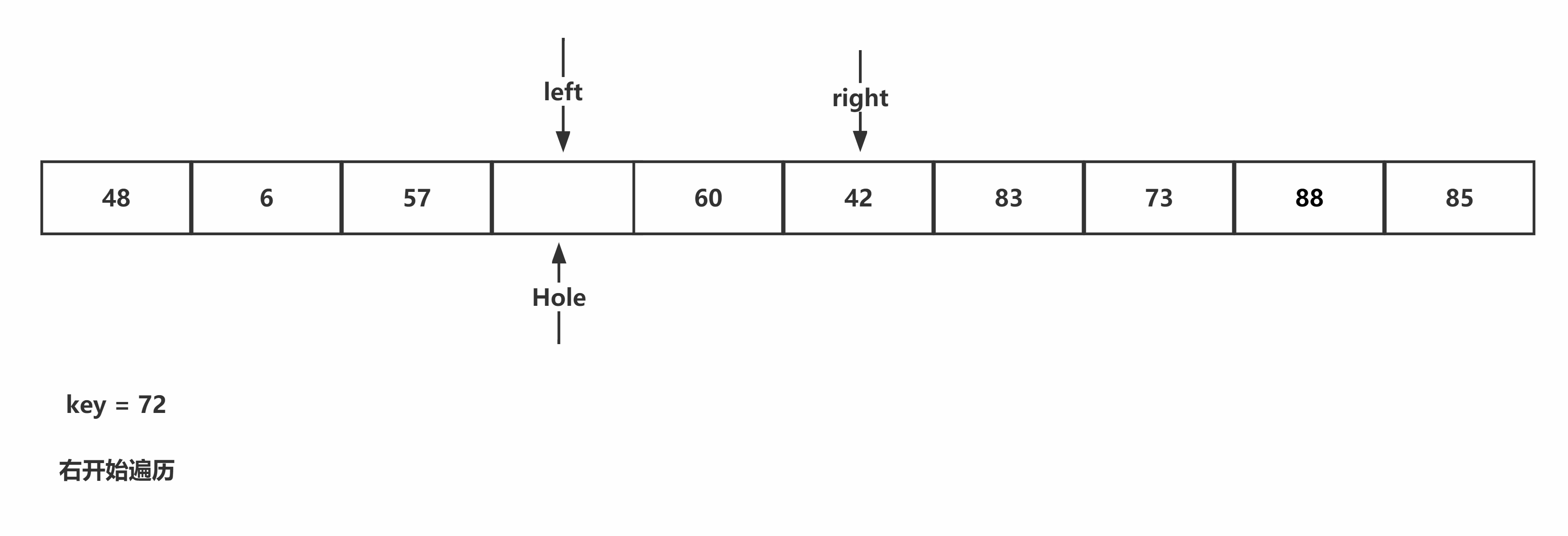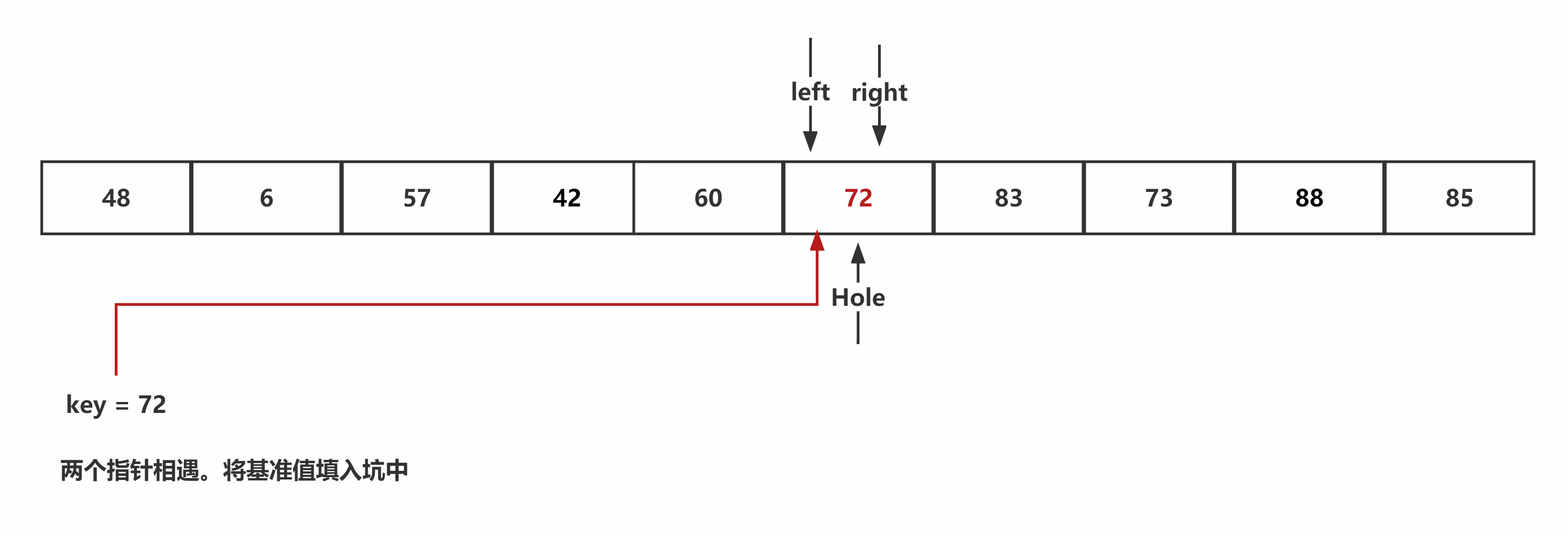
代码书写:首先找出基准值,并作为键保存下来,开始从右指针到左指针的填坑挖坑操作,直至二者相遇,将保存下来的键值填入坑中。
int partationByHole(int* arr, int left, int right) {
int hole_index = findpivot(arr, left, right);
swap(&arr[left], &arr[hole_index]);
hole_index = left;
int key = arr[hole_index];
while (left < right) {
while (left < right && arr[right] >= key)
right--;
arr[hole_index] = arr[right];
hole_index = right;
while (left < right && arr[left] <= key)
left++;
arr[hole_index] = arr[left];
hole_index = left;
}
arr[hole_index] = key;
return hole_index;
}
双指针法:双指针法中一个指针用于遍历序列,一个指针指向比基准值小的序列,当遍历指针遇到比基准值小或者等于的元素时,就会将该元素进行交换,并小序列指针后移,从而通过双指针完成对序列的遍历与对序列的分割。最后需要将基准值交换到正确的排序位置。
图示如下:

代码书写:首先找出基准值,定义双指针,在此定义了cur作为遍历指针,定义了leftPoint作为小序列指针。对cur进行遍历,当遇到小于基准值的检索,进行交换,并将leftPoint完成后移操作,直到遍历完成。完成遍历后,将基准值写入正确的位置,示例代码如下:
int partitonByDoublePoint(int arr[], int left, int right) {
int key_index = findpivot(arr, left, right);
swap(&arr[key_index], &arr[left]);
key_index = left;
int cur = 0;
int leftPoint = left;
for (cur = left; cur <= right; cur++) {
if (arr[cur] <= arr[key_index]) {
swap(&arr[cur], &arr[leftPoint]);
leftPoint++;
}
}
swap(&arr[key_index], &arr[leftPoint - 1]);
key_index = leftPoint - 1;
return key_index;
}
优化实现
由于是递归实现,会占用栈帧的空间,在分裂到较短序列时,插入排序和快速排序的时间复杂度类似,而插入排序不需要进行递归占用函数栈帧,因此在较短区间中,采取插入排序,代码示例如下:
void QuickSort(int* arr, int head, int end) {
if(head >= end)
return;
int left = head;
int right = end;
if ((right - left + 1) > 5) {
int key_index = partation(arr, head, end);
//int key_index = partationByHole(arr, head, end);
//int key_index = partationByDoublePoint(arr, head, end);
QuickSort(arr, head, key_index - 1);
QuickSort(arr, key_index + 1, end);
}
else {
InsertSort(arr + left, right - left + 1);
}
}
非递归实现
思路:非递归的实现可以从递归实现中获取思路,实际上快排是将每个基准值放到正确的排序位置,并完成分裂过程,而这一过程的核心参数就是区间的范围。因此可以考虑使用数据结构来存储相应的区间范围,从而完成对于递归实现的模拟过程,最后完成非递归实现。
代码书写:在此通过建立一个栈来储存相应的区间范围,在初始化过程中,将头尾插入栈中。进入循环,当栈不为空时,获取区间范围,并进行分裂,将分裂后的区间范围插入栈中,当然在插入前需要判断是否区间范围已经足够的小,不需要继续排列,重复该过程,直到栈为空。代码示例如下:
// qsort non-recursion
void QuickSort_NonRecursion(int* arr, int head, int end) {
// 创建一个 栈
Stack* stack = (Stack*)malloc(sizeof(Stack));
StackInit(stack);
StackPush(stack, head);
StackPush(stack, end);
while (!isStackEmpty(stack)) {
int right = StackTop(stack);
StackPop(stack);
int left = StackTop(stack);
StackPop(stack);
int key_index = partation(arr, left, right);
if (key_index - 1 - left + 1 > 1) {
StackPush(stack, left);
StackPush(stack, key_index - 1);
}
if (right - key_index - 1 + 1 > 1) {
StackPush(stack, key_index + 1);
StackPush(stack, right);
}
}
}
优化:三路划分
思路:在快速排序的过程中,可能会出现大量重复数据的情况,面对这些情况,可能会将基准值放在较前的位置,从而使得大量的递归过程,降低效率,因此进行三路划分,分别划分为比基准值小的区间,与基准值相等的区间和比基准值大的区间。
代码书写:对于三路划分,采取与用双指针分裂类似的思想,不过采取了三指针的方式。命名cur指针作为遍历指针,遍历所有数据,命名left指针为小序列指针指向序列头,当遍历指针遇到较小值时,将会与其进行位置互换,对其后移,同时需要对cur后移,因为交换后肯定是基准值,通过以上操作使小序列增加元素,命名right指针为大序列指针指向序列尾,当遍历指针遇到较大值时,将会与其进行位置互换,对其前移,从而使大序列增加元素。当遇到与基准数相同的值时,只需要将cur后移即可,图示如下:

代码示例如下:
void QuickSortThreePartation(int arr[], int head, int end) {
if (head >= end)
return;
if ((end - head + 1) <= 5)
InsertSort(arr + head, end - head + 1);
else {
int pivot_index = findpivotByRandom(arr, head, end);
swap(&arr[head], &arr[pivot_index]);
int pivot = arr[head];
int left = head;
int right = end;
int cur = left + 1;
while (cur <= right) {
if (arr[cur] < pivot) {
swap(&arr[cur], &arr[left]);
cur++;
left++;
}
else if (arr[cur] > pivot) {
swap(&arr[cur], &arr[right]);
right--;
}
else
cur++;
}
QuickSortThreePartation(arr, head, left - 1);
QuickSortThreePartation(arr, right + 1, end);
}
}
总结
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)
- 稳定性:不稳定
2.5 归并排序
思路:归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer),将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。

书写方法:同样分为递归与非递归两种方式书写 。
递归实现
序列进行不断分组,到最小组后进行不断合并。采用递归的方法,主要是使用了分治的策略,主要考虑到如何将其分解为更小的子问题,如何进行子问题解决,最后完成合并,以及终止条件。
- 分解:将序列拆为两组,作为子序列;
- 解决:使用归并排序继续为子序列分组排序;
- 合并:将排序好的数组合并即可
- 一个条件:但分解为只有子序列长度为1时,就可以结束递的过程;
图示如下:
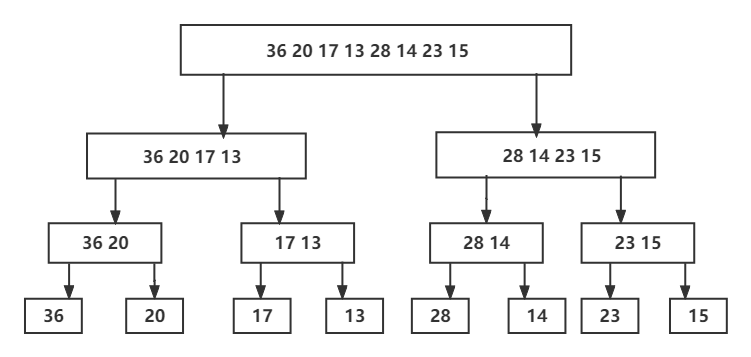
上图表示的就是递归排序的递的过程,也就是分解的过程,就是将序列分为两个子序列,再进行递归排序,当只有子序列长度为1时是无需排序的,这是终止条件,所以将其返回并开始合并操作。这里的归的部分就是整合,整合后的部分通过字体标红,通过不断的整合,得到原问题,即得到一个排序好的数组。
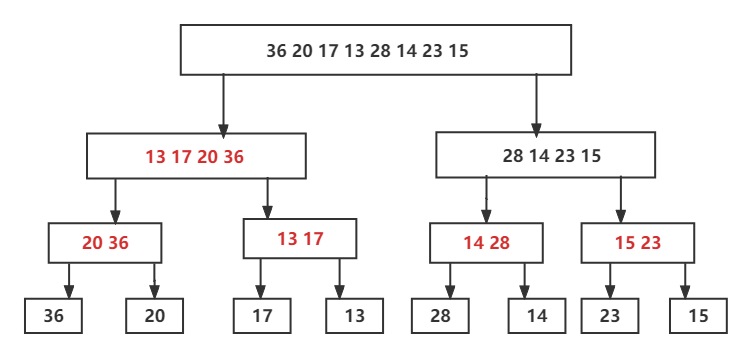
按照以上思路可以写出伪代码:
List mergesort(List inlist) {
//终止条件:长度为 1 就返回子序列
if (inlist.length() <= 1) return inlist;
//分解过程:分为两个子序列
List l1 = half of the items from inlist;
List l2 = other half of items from inlist;
// 合并过程(其中包含解决过程)
return merge(mergesort(l1), mergesort(l2));
}
具体代码实现为:
void MergeSort(int arr[], int left, int right,int temp[]) {
// 终止条件
if (left >= right)
return;
// 分解子问题
int mid = (left + right) / 2;
MergeSort(arr, left, mid,temp);
MergeSort(arr, mid + 1, right, temp);
// 复制到临时数组,用于合并
memmove(temp + left, arr + left, sizeof(int) * (right - left + 1));
int begin_1 = left;
int begin_2 = mid + 1;
for (int i = left; i <= right; i++) {
if (begin_1 > mid) {
arr[i] = temp[begin_2];
begin_2++;
}
else if (begin_2 > right) {
arr[i] = temp[begin_1];
begin_1++;
}
else if (temp[begin_1] < temp[begin_2]) {
arr[i] = temp[begin_1];
begin_1++;
}
else {
arr[i] = temp[begin_2];
begin_2++;
}
}
}
非递归实现
非递归实现是模仿递归实现的,但是并不需要占用函数栈帧。可能有读者会仿照快速排序的非递归实现思路,通过一个数据结构进行存储需要归并的区间,实际上这样做是不正确的,因为快速排序递归的过程是类似于先序遍历的方式 ,而归并排序是逐层归并,因此并不适用。
因此再仔细观察归并的过程,实际上是从最后一层开始合并,每层的区间逐渐增大,因此只需要对区间大小进行掌控,在通过对区间起点与终点进行修正,完成归并操作即可。
为此通过创建一个临时变量rangeN来表示区间大小,从1开始,不断乘以2递增,直到大于序列长度为止。对于每个归并层,都可以通过循环来算出归并的范围,需要注意的是归并的rangeN不是每组的序列元素个数是相同的,为了防止越界,因此需要对其进行判断与修正。代码示例如下:
void MergeSort_NonRecursion(int arr[], int size) {
int* temp = (int*)malloc(sizeof(int) * size);
if (temp == NULL) {
perror("malloc");
return;
}
int rangeN = 1;
for (rangeN = 1; rangeN < size; rangeN *= 2) {
for (int i = 0; i < size; i = i + 2 * rangeN ) {
int begin_1 = i;
int end_1 = i + rangeN - 1;
int begin_2 = i + rangeN;
int end_2 = i + rangeN + rangeN - 1;
if (end_1 >= size) {
end_1 = size - 1;
begin_2 = size - 1;
end_2 = size - 1;
}
if (begin_2 >= size) {
begin_2 = size - 1;
end_2 = size - 1;
}
if (end_2 >= size) {
end_2 = size - 1;
}
memmove(temp + i, arr + i, sizeof(int) * (end_2 - begin_1 + 1));
for (int j = begin_1; j <= end_2; j++) {
if (begin_1 > end_1) {
arr[j] = temp[begin_2];
begin_2++;
}
else if (begin_2 > end_2) {
arr[j] = temp[begin_1];
begin_1++;
}
else if (temp[begin_1] < temp[begin_2]) {
arr[j] = temp[begin_1];
begin_1++;
}
else{
arr[j] = temp[begin_2];
begin_2++;
}
}
}
}
}
总结
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
- 注意:归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
三. 排序总结
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 直接插入排序 | O(N^2) | O(1) | √ |
| 希尔排序 | O(N^1.25) ~ O(1.6 * N^1.25) | O(1) | × |
| 选择排序 | O(N^2) | O(1) | × |
| 堆排序 | O(NlogN) | O(1) | × |
| 冒泡排序 | O(N^2) | O(1) | √ |
| 快速排序 | O(NlogN) | O(logN) | × |
| 归并排序 | O(NlogN) | O(N) | √ |
补充:
- 代码将会放到:C++/C/数据结构代码链接 ,欢迎查看!
- 欢迎各位点赞、评论、收藏与关注,大家的支持是我更新的动力,我会继续不断地分享更多的知识!

![[附源码]计算机毕业设计Node.js宠物店网站(程序+LW)](https://img-blog.csdnimg.cn/abbd6602e38647009010277142d0c373.png)

![[附源码]计算机毕业设计Python的实验填报管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/b13180771b17464381c1bffb7df33d2b.png)



![[附源码]Python计算机毕业设计Django校园二手交易平台](https://img-blog.csdnimg.cn/8a38b79a04c645d8bbdab7c0bdb3c2bf.png)