Seata
- 一:故事背景
- 二:使用方法
- 2.1 下载安装Seata
- 2.4 修改对应配置文件。
- 2.4.1 配置中心
- 2.4.1 注册中心
- 2.4.2 日志保存模式
- 2.3 启动Seata
- 2.4 项目中集成
- 2.5 数据库内新建undo_log 表进行日志记录
- 2.6 编写代码测试Seata提供的分布式事务功能
- 三:总结提升
一:故事背景
Seata是一个开源的分布式事务管理系统,用来解决分布式架构下的事务问题。
我们在分布式的系统中,一个业务操作可能设计多个微服务,这些微服务的数据分布在不同的数据库中,当一个操作需要跨过多个数据源执行的时候,某个服务失败了,我们该如何回滚其它已提交的部分呢?我们该如何确保数据一致性呢?
Seata的出现就是从来解决上述问题的,其提供了分布式事务的管理与协调,支持我们在分布式的系统下进行可靠的事务管理。
二:使用方法
2.1 下载安装Seata
2.4 修改对应配置文件。
2.4.1 配置中心
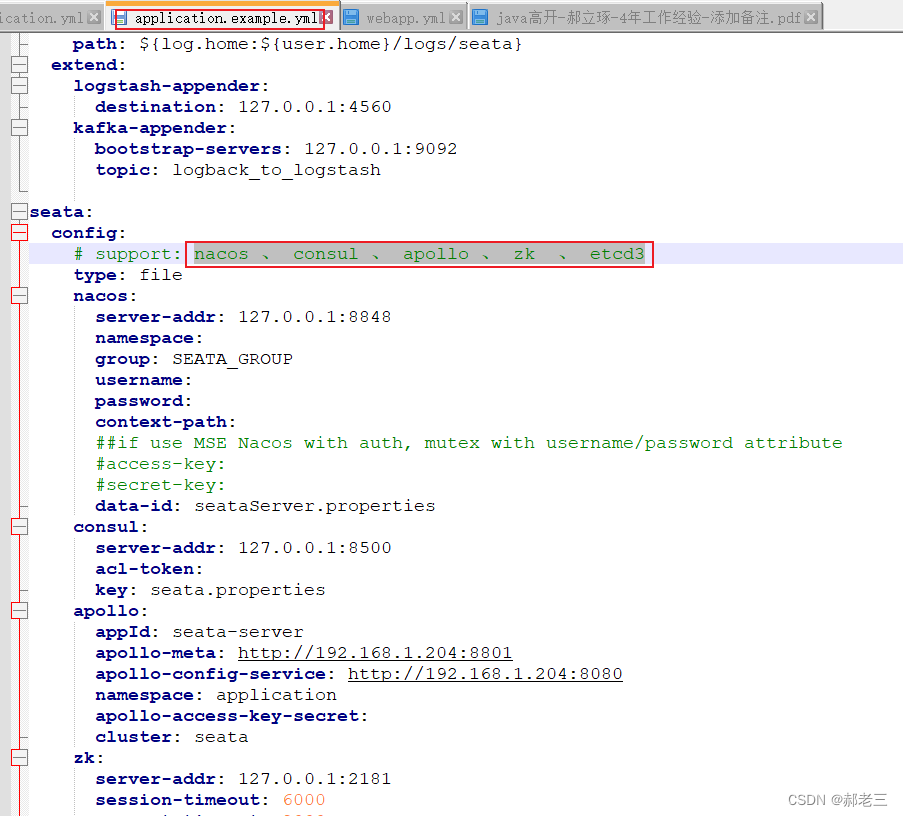
application.example.yml 里给出了Seata支持的所有配置,类似于一个模板,我们在选择配置的时候,根据此文件中给出的模板即可。
-
nacos上新建对应的配置文件
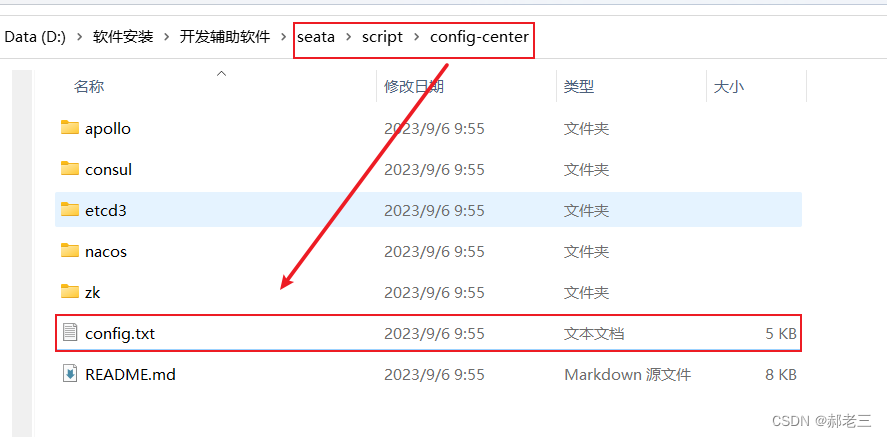
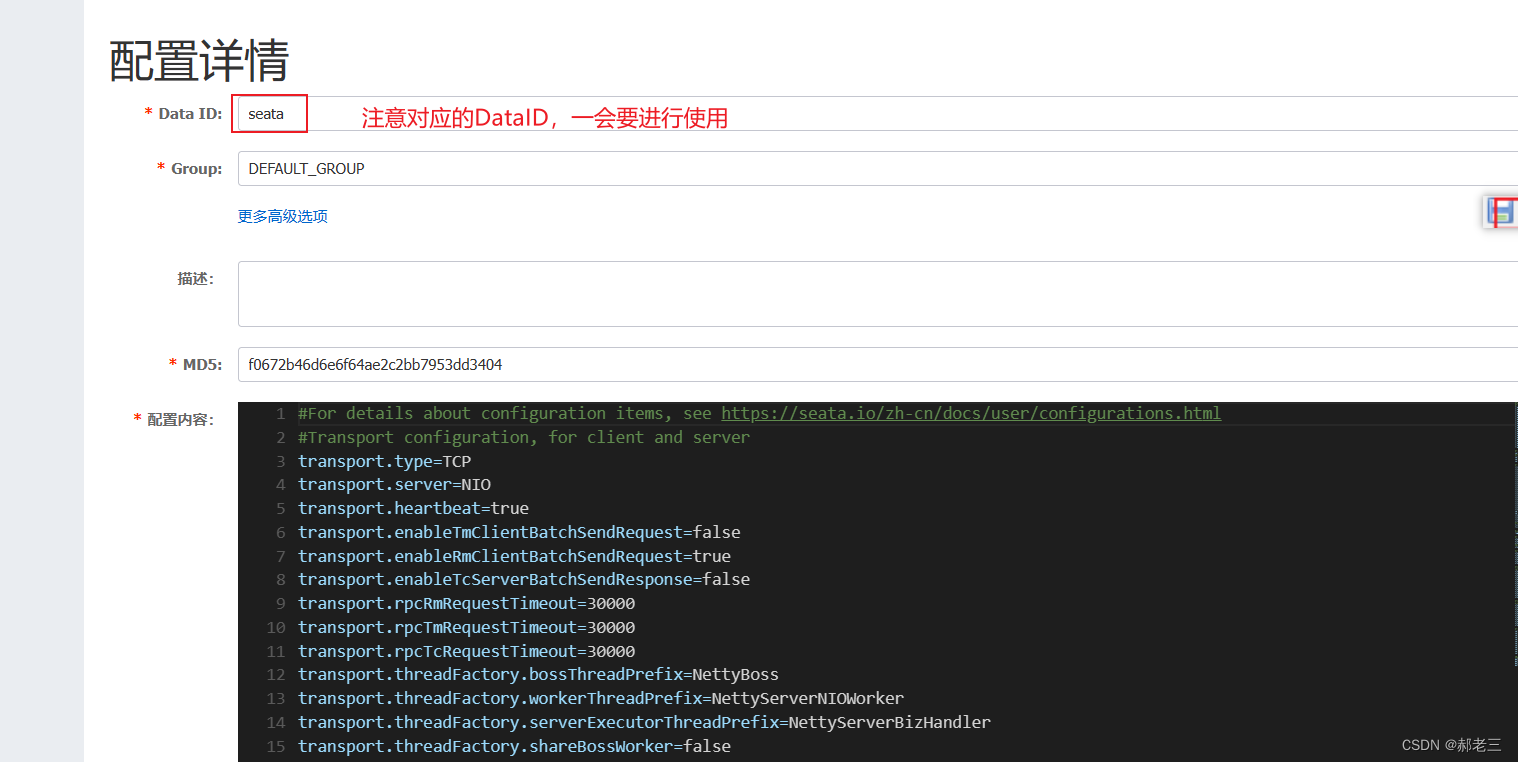
找到安装目录下的config.txt文件,将其所有内容都复制到nacos的配置中心,这里的配置都是一些对于Seata项目的配置。这里我们暂时不做修改,直接使用。
-
修改对应的application.yml 文件
我们的例子中,将会使用nacos作为配置中心。我们需要将对应的application.example.yml的关于配置中心的配置复制到application.yml,并且进行修改即可。
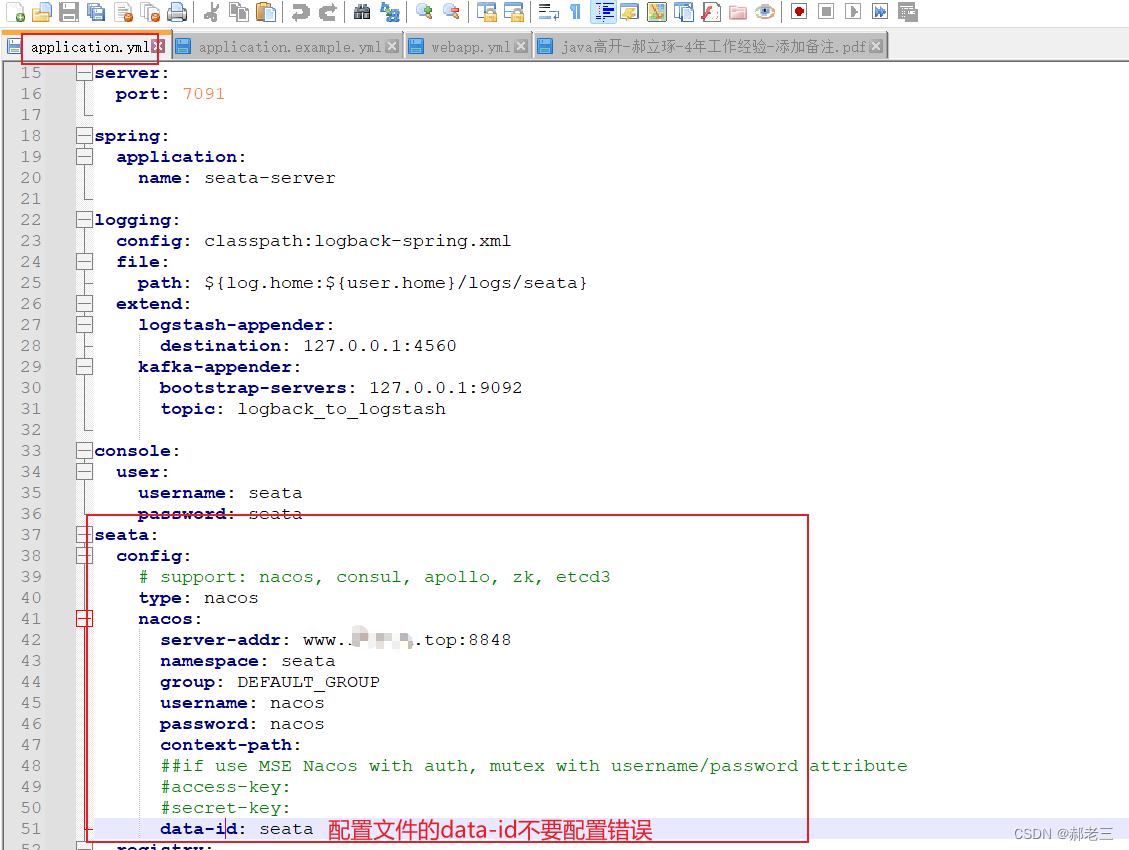
到这里,对应配置中心我们就设置好了。
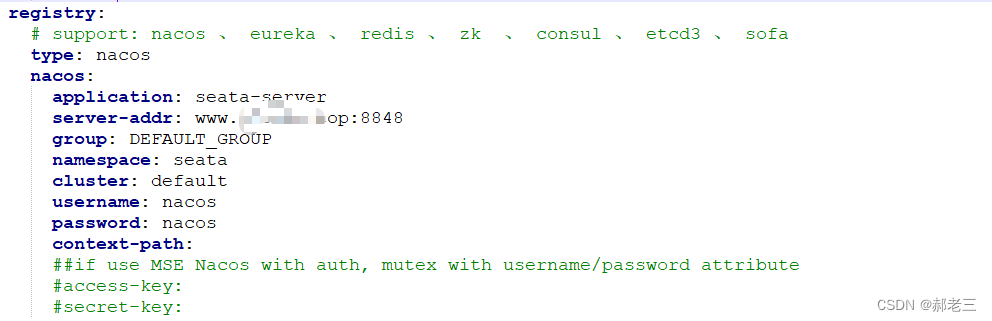
2.4.1 注册中心
注册中心的配置流程与配置中心的配置流程相同,我们同样使用nacos作为配置中心。
2.4.2 日志保存模式
Seata进行分布式事务日志保存的时候,可以使用多种模式,这里我们使用mysql数据库的方式,保存对应的日志.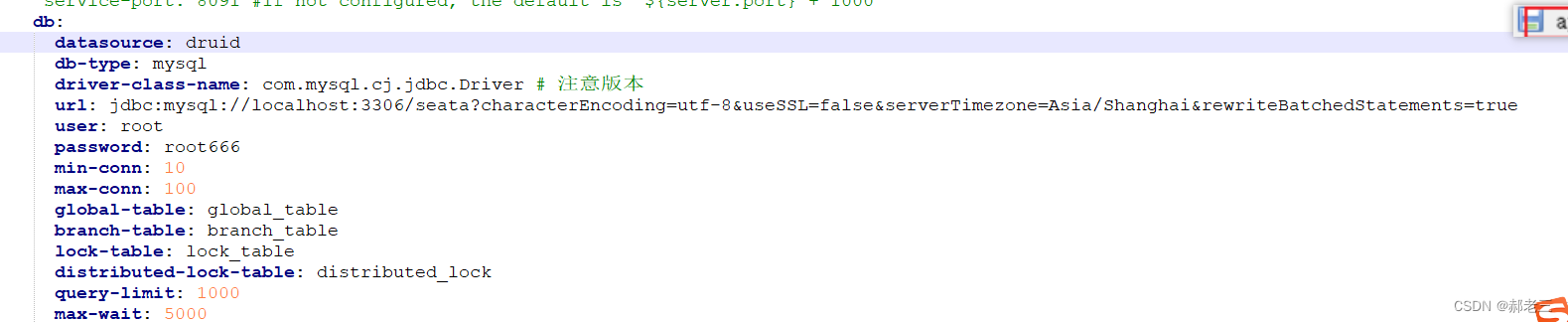
将对应的配置文件修改好之后,我们就可以启动Seata了
2.3 启动Seata
- 找到安装目录,并且进入控制台,然后通过命令启动
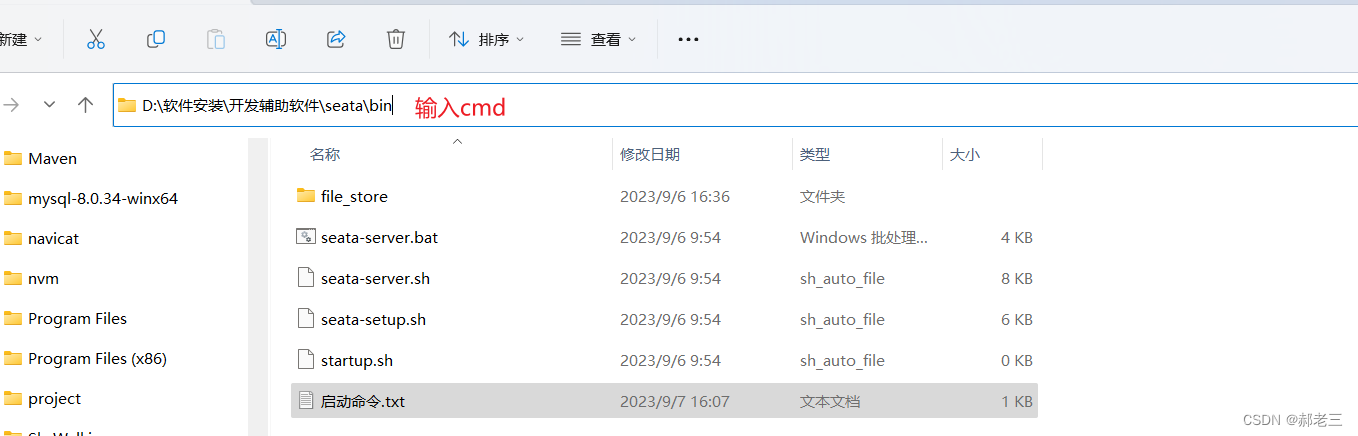
- 启动命令
seata-server.bat -h 127.0.0.1 -p 8091 -m db
-
seata-server.bat: 这是启动 Seata 服务器的脚本文件,通常以 .bat 结尾,表示它是一个 Windows 平台上的批处理文件。在 Linux 或 macOS 等 Unix 类操作系统上可能会使用不同的脚本文件,如 seata-server.sh。
-
-h 127.0.0.1: 这是指定 Seata 服务器的主机地址的参数。在这里,-h 表示主机地址,127.0.0.1 是 IP 地址,表示将 Seata 服务器绑定到本地主机(localhost),只允许本地访问。如果需要允许远程访问,可以指定服务器的公共 IP 地址或主机名。
-
-p 8091: 这是指定 Seata 服务器监听的端口号的参数。在这里,-p 表示端口号,8091 是具体的端口号,表示 Seata 服务器将在 8091 端口上监听来自客户端的连接请求。
-
-m db: 这是指定 Seata 服务器的运行模式的参数。在这里,-m 表示运行模式,db 表示数据库模式。Seata 支持两种运行模式,一种是 db 模式,表示分布式事务日志将存储在数据库中,另一种是 file 模式,表示分布式事务日志将存储在文件中。这里指定的是 db 模式,意味着 Seata 将使用数据库来管理分布式事务。
- 成功启动

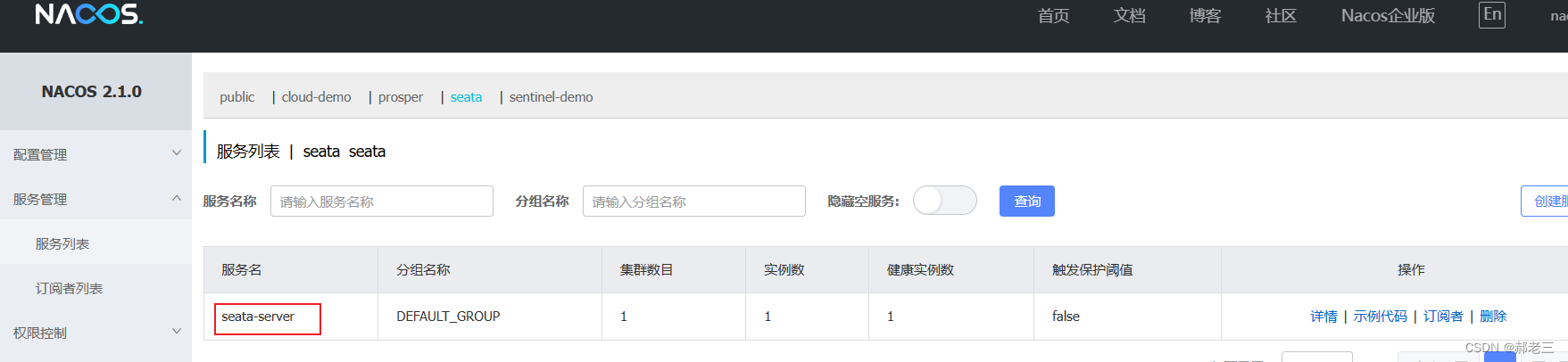
- 看一下nacos对应服务
2.4 项目中集成
因为我们是测试分布式事务,所以我们应该至少创建两个服务,并且都对Seata进行集成。
- Seata对应pom依赖
<!--seata,推荐用最新版本-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.7.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
- 其它必备依赖
我们这里选择jpa作为我们的数据交互层框架。
<!-- 数据库-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
使用nacos做服务注册与发现
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- nacos-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 项目配置文件
server:
port: 7004
servlet:
encoding:
force: true # 强制使用
charset: UTF-8 # 编码格式
spring:
application:
name: module-four
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/cloud-demo?autoReconnect=true&useSSL=false&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&allowMultiQueries=true
username: root
password: root666
cloud:
nacos:
discovery:
server-addr: www.xxxx.top:8848
namespace: cloud-demo
sentinel:
transport:
port: 9856
dashboard: localhost:8849
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: nacos
nacos:
server-addr: www.zlovem.top:8848
namespace: seata
group: DEFAULT_GROUP
username: nacos
password: nacos
context-path:
##if use MSE Nacos with auth, mutex with username/password attribute
#access-key:
#secret-key:
data-id: seata
registry:
type: nacos
nacos:
application: seata-server
server-addr: www.zlovem.top:8848
group : "DEFAULT_GROUP"
namespace: "seata"
通过上述两种方式新建两个对应服务。
2.5 数据库内新建undo_log 表进行日志记录
我们需要在我们项目连接的数据库中新建一张对应的undo_log 表来记录日志。这个表的作用是记录一次事务过程中,不同的服务,对数据库的操作。
实际上集成了Seata之后,不同的微服务之间并不是等所有调用完所有的微服务之后在进行事务提交,将数据持久化,实际上其是会将数据先进行提交,然后再出现异常的时候,才会将对应的数据回滚回去。
CREATE TABLE `undo_log` (
`id` bigint NOT NULL AUTO_INCREMENT,
`branch_id` bigint NOT NULL,
`xid` varchar(100) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`context` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8mb3 ROW_FORMAT=DYNAMIC;
2.6 编写代码测试Seata提供的分布式事务功能
- 项目A代码
@GetMapping("/seata")
@GlobalTransactional//全局事务控制注解
public void seata(){
System.out.println("测试测试seata");
User user = new User();
user.setName("郝");
userDao.save(user);
moduleFourFegin.testStata();
}
- 项目B代码
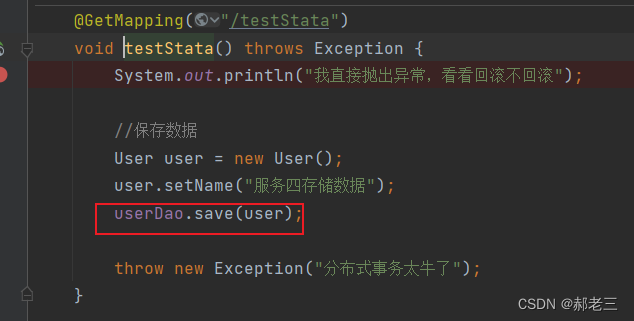
@GetMapping("/testStata")
void testStata() throws Exception {
System.out.println("我直接抛出异常,看看回滚不回滚");
//保存数据
User user = new User();
user.setName("服务四存储数据");
userDao.save(user);
throw new Exception("分布式事务太牛了");
}
在上述给出的代码中,我们在服务A中使用了Seata提供的 @GlobalTransactional 全局事务注解,并且在服务B中,直接将对应的异常抛出,看看其会不会实现回滚的效果。
3. 启动项目并且进行测试
当代码走到以下位置:
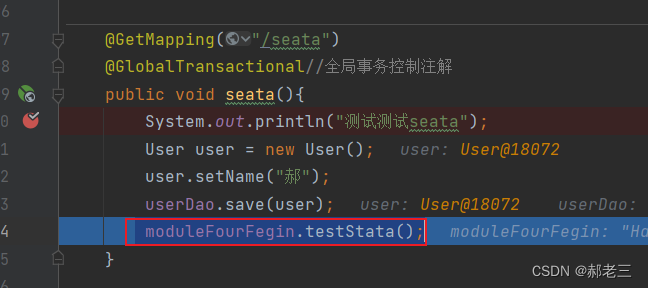
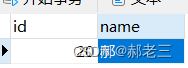
数据库中对应的数据:
当用户走到以下位置:
数据库数据:
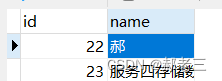
用户抛出异常后,数据库数据:
通过上述结果,我们可以观察到,分布式事务生效了,跨服务之间出现错误之后,可以实现数据的回滚,实现了跨服务之间的数据控制。
三:总结提升
本文只是一篇基础介绍,介绍如何使用Seata,关于Seata的的原理,进阶,我们会在接下来的博客中持续更新~



![心法利器[101] | 从大模型到大模型系统](https://img-blog.csdnimg.cn/img_convert/d0356c910177d771b655b0e61dad44a1.png)