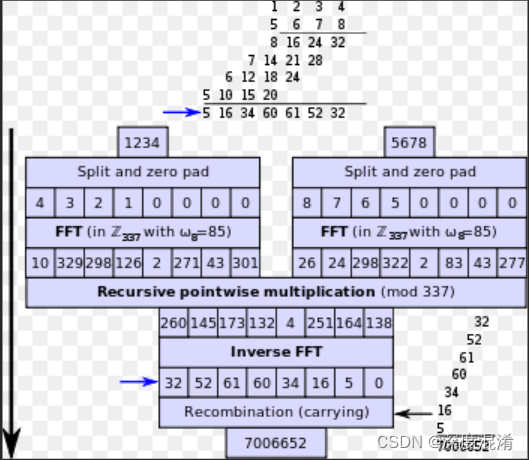
NLP简介

HuggingFace简介
hugging face在NLP领域最出名,其提供的模型大多都是基于Transformer的。为了易用性,Hugging Face还为用户提供了以下几个项目:
- Transformers(github, 官方文档): Transformers提供了上千个预训练好的模型可以用于不同的任务,例如文本领域、音频领域和CV领域。该项目是HuggingFace的核心,可以说学习HuggingFace就是在学习该项目如何使用。
- Datasets(github, 官方文档): 一个轻量级的数据集框架,主要有两个功能:①一行代码下载和预处理常用的公开数据集; ② 快速、易用的数据预处理类库。
- Accelerate(github, 官方文档): 帮助Pytorch用户很方便的实现 multi-GPU/TPU/fp16。
- Space:Space提供了许多好玩的深度学习应用,可以尝试玩一下。
Transformers

1. Pipeline流水线
将数据预处理tokenizer、模型调用model、结果后处理组装成一个流水线

Pipeline原理
pipeline(data, model, tokenizer, divece)的原理:

Pipeline使用方法
一般使用较多的方法是分别构建model和tokenizer,并指定task任务类型将其分别加入pipeline:
(每类pipeline的具体使用方法可以点进具体Pipeline类的源码中查看!!)

Pipeline的Task类型
audio-classification{‘impl’: <class ‘transformers.pipelines.audio_classification.AudioClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForAudioClassification’>,), ‘default’: {‘model’: {‘pt’: (‘superb/wav2vec2-base-superb-ks’, ‘372e048’)}}, ‘type’: ‘audio’}automatic-speech-recognition{‘impl’: <class ‘transformers.pipelines.automatic_speech_recognition.AutomaticSpeechRecognitionPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForCTC’>, <class ‘transformers.models.auto.modeling_auto.AutoModelForSpeechSeq2Seq’>), ‘default’: {‘model’: {‘pt’: (‘facebook/wav2vec2-base-960h’, ‘55bb623’)}}, ‘type’: ‘multimodal’}feature-extraction{‘impl’: <class ‘transformers.pipelines.feature_extraction.FeatureExtractionPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModel’>,), ‘default’: {‘model’: {‘pt’: (‘distilbert-base-cased’, ‘935ac13’), ‘tf’: (‘distilbert-base-cased’, ‘935ac13’)}}, ‘type’: ‘multimodal’}text-classification{‘impl’: <class ‘transformers.pipelines.text_classification.TextClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSequenceClassification’>,), ‘default’: {‘model’: {‘pt’: (‘distilbert-base-uncased-finetuned-sst-2-english’, ‘af0f99b’), ‘tf’: (‘distilbert-base-uncased-finetuned-sst-2-english’, ‘af0f99b’)}}, ‘type’: ‘text’}token-classification{‘impl’: <class ‘transformers.pipelines.token_classification.TokenClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForTokenClassification’>,), ‘default’: {‘model’: {‘pt’: (‘dbmdz/bert-large-cased-finetuned-conll03-english’, ‘f2482bf’), ‘tf’: (‘dbmdz/bert-large-cased-finetuned-conll03-english’, ‘f2482bf’)}}, ‘type’: ‘text’}question-answering{‘impl’: <class ‘transformers.pipelines.question_answering.QuestionAnsweringPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForQuestionAnswering’>,), ‘default’: {‘model’: {‘pt’: (‘distilbert-base-cased-distilled-squad’, ‘626af31’), ‘tf’: (‘distilbert-base-cased-distilled-squad’, ‘626af31’)}}, ‘type’: ‘text’}table-question-answering{‘impl’: <class ‘transformers.pipelines.table_question_answering.TableQuestionAnsweringPipeline’>, ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForTableQuestionAnswering’>,), ‘tf’: (), ‘default’: {‘model’: {‘pt’: (‘google/tapas-base-finetuned-wtq’, ‘69ceee2’), ‘tf’: (‘google/tapas-base-finetuned-wtq’, ‘69ceee2’)}}, ‘type’: ‘text’}visual-question-answering{‘impl’: <class ‘transformers.pipelines.visual_question_answering.VisualQuestionAnsweringPipeline’>, ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForVisualQuestionAnswering’>,), ‘tf’: (), ‘default’: {‘model’: {‘pt’: (‘dandelin/vilt-b32-finetuned-vqa’, ‘4355f59’)}}, ‘type’: ‘multimodal’}document-question-answering{‘impl’: <class ‘transformers.pipelines.document_question_answering.DocumentQuestionAnsweringPipeline’>, ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForDocumentQuestionAnswering’>,), ‘tf’: (), ‘default’: {‘model’: {‘pt’: (‘impira/layoutlm-document-qa’, ‘52e01b3’)}}, ‘type’: ‘multimodal’}fill-mask{‘impl’: <class ‘transformers.pipelines.fill_mask.FillMaskPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForMaskedLM’>,), ‘default’: {‘model’: {‘pt’: (‘distilroberta-base’, ‘ec58a5b’), ‘tf’: (‘distilroberta-base’, ‘ec58a5b’)}}, ‘type’: ‘text’}summarization{‘impl’: <class ‘transformers.pipelines.text2text_generation.SummarizationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM’>,), ‘default’: {‘model’: {‘pt’: (‘sshleifer/distilbart-cnn-12-6’, ‘a4f8f3e’), ‘tf’: (‘t5-small’, ‘d769bba’)}}, ‘type’: ‘text’}translation{‘impl’: <class ‘transformers.pipelines.text2text_generation.TranslationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM’>,), ‘default’: {(‘en’, ‘fr’): {‘model’: {‘pt’: (‘t5-base’, ‘686f1db’), ‘tf’: (‘t5-base’, ‘686f1db’)}}, (‘en’, ‘de’): {‘model’: {‘pt’: (‘t5-base’, ‘686f1db’), ‘tf’: (‘t5-base’, ‘686f1db’)}}, (‘en’, ‘ro’): {‘model’: {‘pt’: (‘t5-base’, ‘686f1db’), ‘tf’: (‘t5-base’, ‘686f1db’)}}}, ‘type’: ‘text’}text2text-generation{‘impl’: <class ‘transformers.pipelines.text2text_generation.Text2TextGenerationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM’>,), ‘default’: {‘model’: {‘pt’: (‘t5-base’, ‘686f1db’), ‘tf’: (‘t5-base’, ‘686f1db’)}}, ‘type’: ‘text’}text-generation{‘impl’: <class ‘transformers.pipelines.text_generation.TextGenerationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForCausalLM’>,), ‘default’: {‘model’: {‘pt’: (‘gpt2’, ‘6c0e608’), ‘tf’: (‘gpt2’, ‘6c0e608’)}}, ‘type’: ‘text’}zero-shot-classification{‘impl’: <class ‘transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSequenceClassification’>,), ‘default’: {‘model’: {‘pt’: (‘facebook/bart-large-mnli’, ‘c626438’), ‘tf’: (‘roberta-large-mnli’, ‘130fb28’)}, ‘config’: {‘pt’: (‘facebook/bart-large-mnli’, ‘c626438’), ‘tf’: (‘roberta-large-mnli’, ‘130fb28’)}}, ‘type’: ‘text’}zero-shot-image-classification{‘impl’: <class ‘transformers.pipelines.zero_shot_image_classification.ZeroShotImageClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForZeroShotImageClassification’>,), ‘default’: {‘model’: {‘pt’: (‘openai/clip-vit-base-patch32’, ‘f4881ba’), ‘tf’: (‘openai/clip-vit-base-patch32’, ‘f4881ba’)}}, ‘type’: ‘multimodal’}zero-shot-audio-classification{‘impl’: <class ‘transformers.pipelines.zero_shot_audio_classification.ZeroShotAudioClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModel’>,), ‘default’: {‘model’: {‘pt’: (‘laion/clap-htsat-fused’, ‘973b6e5’)}}, ‘type’: ‘multimodal’}conversational{‘impl’: <class ‘transformers.pipelines.conversational.ConversationalPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM’>, <class ‘transformers.models.auto.modeling_auto.AutoModelForCausalLM’>), ‘default’: {‘model’: {‘pt’: (‘microsoft/DialoGPT-medium’, ‘8bada3b’), ‘tf’: (‘microsoft/DialoGPT-medium’, ‘8bada3b’)}}, ‘type’: ‘text’}image-classification{‘impl’: <class ‘transformers.pipelines.image_classification.ImageClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForImageClassification’>,), ‘default’: {‘model’: {‘pt’: (‘google/vit-base-patch16-224’, ‘5dca96d’), ‘tf’: (‘google/vit-base-patch16-224’, ‘5dca96d’)}}, ‘type’: ‘image’}image-segmentation{‘impl’: <class ‘transformers.pipelines.image_segmentation.ImageSegmentationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForImageSegmentation’>, <class ‘transformers.models.auto.modeling_auto.AutoModelForSemanticSegmentation’>), ‘default’: {‘model’: {‘pt’: (‘facebook/detr-resnet-50-panoptic’, ‘fc15262’)}}, ‘type’: ‘multimodal’}image-to-text{‘impl’: <class ‘transformers.pipelines.image_to_text.ImageToTextPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForVision2Seq’>,), ‘default’: {‘model’: {‘pt’: (‘ydshieh/vit-gpt2-coco-en’, ‘65636df’), ‘tf’: (‘ydshieh/vit-gpt2-coco-en’, ‘65636df’)}}, ‘type’: ‘multimodal’}object-detection{‘impl’: <class ‘transformers.pipelines.object_detection.ObjectDetectionPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForObjectDetection’>,), ‘default’: {‘model’: {‘pt’: (‘facebook/detr-resnet-50’, ‘2729413’)}}, ‘type’: ‘multimodal’}zero-shot-object-detection{‘impl’: <class ‘transformers.pipelines.zero_shot_object_detection.ZeroShotObjectDetectionPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForZeroShotObjectDetection’>,), ‘default’: {‘model’: {‘pt’: (‘google/owlvit-base-patch32’, ‘17740e1’)}}, ‘type’: ‘multimodal’}depth-estimation{‘impl’: <class ‘transformers.pipelines.depth_estimation.DepthEstimationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForDepthEstimation’>,), ‘default’: {‘model’: {‘pt’: (‘Intel/dpt-large’, ‘e93beec’)}}, ‘type’: ‘image’}video-classification{‘impl’: <class ‘transformers.pipelines.video_classification.VideoClassificationPipeline’>, ‘tf’: (), ‘pt’: (<class ‘transformers.models.auto.modeling_auto.AutoModelForVideoClassification’>,), ‘default’: {‘model’: {‘pt’: (‘MCG-NJU/videomae-base-finetuned-kinetics’, ‘4800870’)}}, ‘type’: ‘video’}
2. Tokenizer分词器
Tokenizer将过去繁琐的text-to-token的过程进行简化:

2.1 Tokenizer的使用方法

Step1 加载与保存
from transformers import AutoTokenizer
# 从HuggingFace加载,输入模型名称,即可加载对应的分词器
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
"""
BertTokenizerFast(name_or_path='uer/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
"""
# tokenizer 保存到本地
tokenizer.save_pretrained("本地文件夹路径")
''' 文件夹内的文件格式
('./roberta_tokenizer\\tokenizer_config.json',
'./roberta_tokenizer\\special_tokens_map.json',
'./roberta_tokenizer\\vocab.txt',
'./roberta_tokenizer\\added_tokens.json',
'./roberta_tokenizer\\tokenizer.json')
'''
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("本地文件夹路径")
"""
BertTokenizerFast(name_or_path='uer/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
"""
Step2 句子分词 :
sen = "弱小的我也有大梦想!"
tokens = tokenizer.tokenize(sen)
# ['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
Step3 查看词典:
tokenizer.vocab
"""
{'湾': 3968,
'訴': 6260,
'##轶': 19824,
'洞': 3822,
' ̄': 8100,
'##劾': 14288,
'##care': 11014,
'asia': 8339,
'##嗑': 14679,
'##鹘': 20965,
'washington': 12262,
'##匕': 14321,
'##樟': 16619,
'癮': 4628,
'day3': 11649,
'##宵': 15213,
'##弧': 15536,
'##do': 8828,
'詭': 6279,
'3500': 9252,
'124': 9377,
'##価': 13957,
'##玄': 17428,
'##積': 18005,
'##肝': 18555,
...
'##维': 18392,
'與': 5645,
'##mark': 9882,
'偽': 984,
...}
"""
tokenizer.vocab_size
# 21128
Step4 索引转换:
# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
ids
# [2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106]
# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
tokens
# ['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
str_sen
# '弱 小 的 我 也 有 大 梦 想!'
总结——更便捷的实现方式:
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True)
ids
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102]
# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
str_sen
# '[CLS] 弱 小 的 我 也 有 大 梦 想! [SEP]'
Step5 填充与截断:
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
ids
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
ids
# [101, 2483, 2207, 4638, 102]
Step6 其他输入部分:
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
ids
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
attention_mask = [1 if idx != 0 else 0 for idx in ids]
token_type_ids = [0] * len(ids)
ids, attention_mask, token_type_ids
"""
([101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
"""
2.2 Tokenizer快速调用
tokenizer.encode_plus()和tokenizer()效果相同
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
inputs
"""
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
"""
inputs = tokenizer(sen, padding="max_length", max_length=15)
inputs
"""
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]}
"""
2.3 处理batch数据
sens = ["弱小的我也有大梦想",
"有梦想谁都了不起",
"追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
res
"""
{'input_ids': [[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 102], [101, 3300, 3457, 2682, 6443, 6963, 749, 679, 6629, 102], [101, 6841, 6852, 3457, 2682, 4638, 2552, 8024, 3683, 3457, 2682, 3315, 6716, 8024, 3291, 1377, 6586, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
"""
%%time
# 单条循环处理
for i in range(1000):
tokenizer(sen)
# CPU times: total: 15.6 ms
# Wall time: 32.5 ms
%%time
# 处理batch数据
sen_list = [sen] * 1000
res = tokenizer(sen_list)
# CPU times: total: 0 ns
# Wall time: 6 ms
2.4 Fast / Slow Tokenizer

sen = "弱小的我也有大Dreaming!"
fast_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
fast_tokenizer
# BertTokenizerFast(name_or_path='uer/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
inputs = fast_tokenizer(sen, return_offsets_mapping=True)
inputs
# {'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 10252, 8221, 106, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 12), (12, 15), (15, 16), (0, 0)]}
inputs.word_ids()
# [None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
slow_tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", use_fast=False)
slow_tokenizer
# BertTokenizer(name_or_path='uer/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
3. Model模型






3.1 模型加载与保存
在线下载: 会遇到HTTP连接超时
from transformers import AutoConfig, AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("hfl/rbt3", force_download=True)
离线下载 : 需要挂梯子自己进去下载,在本地创建文件夹
!git clone "https://huggingface.co/hfl/rbt3"
!git lfs clone "https://huggingface.co/hfl/rbt3" --include="*.bin"
离线加载:
model = AutoModel.from_pretrained("本地文件夹")
模型加载参数
model = AutoModel.from_pretrained("本地文件夹")
model.config
"""
BertConfig {
"_name_or_path": "rbt3",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
...
"transformers_version": "4.28.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
"""
config = AutoConfig.from_pretrained("./rbt3/")
config
"""
BertConfig {
"_name_or_path": "rbt3",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
...
"transformers_version": "4.28.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
"""
3.2 模型调用
sen = "弱小的我也有大梦想!"
tokenizer = AutoTokenizer.from_pretrained("rbt3")
inputs = tokenizer(sen, return_tensors="pt")
inputs
"""
{'input_ids': tensor([[ 101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 8013, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
"""
不带Model Head的模型调用
model = AutoModel.from_pretrained("rbt3", output_attentions=True)
output = model(**inputs)
output
"""
BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.6804, 0.6664, 0.7170, ..., -0.4102, 0.7839, -0.0262],
[-0.7378, -0.2748, 0.5034, ..., -0.1359, -0.4331, -0.5874],
[-0.0212, 0.5642, 0.1032, ..., -0.3617, 0.4646, -0.4747],
...,
[ 0.0853, 0.6679, -0.1757, ..., -0.0942, 0.4664, 0.2925],
[ 0.3336, 0.3224, -0.3355, ..., -0.3262, 0.2532, -0.2507],
[ 0.6761, 0.6688, 0.7154, ..., -0.4083, 0.7824, -0.0224]]],
grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[-1.2646e-01, -9.8619e-01, -1.0000e+00, -9.8325e-01, 8.0238e-01,
-6.6268e-02, 6.6919e-02, 1.4784e-01, 9.9451e-01, 9.9995e-01,
-8.3051e-02, -1.0000e+00, -9.8865e-02, 9.9980e-01, -1.0000e+00,
9.9993e-01, 9.8291e-01, 9.5363e-01, -9.9948e-01, -1.3219e-01,
-9.9733e-01, -7.7934e-01, 1.0720e-01, 9.8040e-01, 9.9953e-01,
-9.9939e-01, -9.9997e-01, 1.4967e-01, -8.7627e-01, -9.9996e-01,
-9.9821e-01, -9.9999e-01, 1.9396e-01, -1.1277e-01, 9.9359e-01,
-9.9153e-01, 4.4752e-02, -9.8731e-01, -9.9942e-01, -9.9982e-01,
2.9360e-02, 9.9847e-01, -9.2014e-03, 9.9999e-01, 1.7111e-01,
4.5071e-03, 9.9998e-01, 9.9467e-01, 4.9726e-03, -9.0707e-01,
6.9056e-02, -1.8141e-01, -9.8831e-01, 9.9668e-01, 4.9800e-01,
1.2997e-01, 9.9895e-01, -1.0000e+00, -9.9990e-01, 9.9478e-01,
-9.9989e-01, 9.9906e-01, 9.9820e-01, 9.9990e-01, -6.8953e-01,
9.9990e-01, 9.9987e-01, 9.4563e-01, -3.7660e-01, -1.0000e+00,
1.3151e-01, -9.7371e-01, -9.9997e-01, -1.3228e-02, -2.9801e-01,
-9.9985e-01, 9.9662e-01, -2.0004e-01, 9.9997e-01, 3.6876e-01,
-9.9997e-01, 1.5462e-01, 1.9265e-01, 8.9871e-02, 9.9996e-01,
9.9998e-01, 1.5184e-01, -8.9714e-01, -2.1646e-01, -9.9922e-01,
...
1.7911e-02, 4.8672e-01],
[4.0732e-01, 3.8137e-02, 9.6832e-03, ..., 4.4490e-02,
2.2997e-02, 4.0793e-01],
[1.7047e-01, 3.6989e-02, 2.3646e-02, ..., 4.6833e-02,
2.5233e-01, 1.6721e-01]]]], grad_fn=<SoftmaxBackward0>)), cross_attentions=None)
"""
output.last_hidden_state.size()
# orch.Size([1, 12, 768])
len(inputs["input_ids"][0])
# 12
带Model Head的模型调用
from transformers import AutoModelForSequenceClassification, BertForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained("rbt3", num_labels=10)
clz_model(**inputs)
# SequenceClassifierOutput(loss=None, logits=tensor([[-0.1776, 0.2208, -0.5060, -0.3938, -0.5837, 1.0171, -0.2616, 0.0495, 0.1728, 0.3047]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
clz_model.config.num_labels
# 2