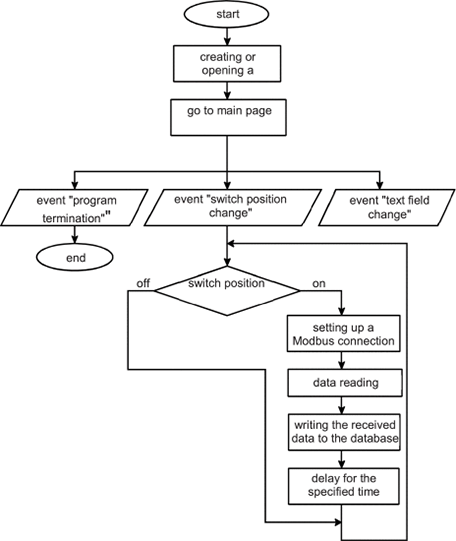
课程地址:https://learn.deeplearning.ai/finetuning-large-language-models/lesson/1/introduction
Introduction
动机:虽然编写提示词(Prompt)可以让LLM按照指示执行任务,比如提取文本中的关键词,或者对文本进行情绪分类。但是,微调LLM,可以让其更一致地做具体的任务。例如,微调LLM对话时的语气。
课程大纲:

Why finetune
简单理解,微调(fine-tuning)就是利用特有数据和技巧将通用模型转换为能执行具体任务的一种方式。例如,将 GPT-3 这种通用模型转换为诸如 ChatGPT 这样的专门用于聊天的模型。或者将 GPT-4 转换为诸如 GitHub Coplot 这样的专门用于写代码的模型。
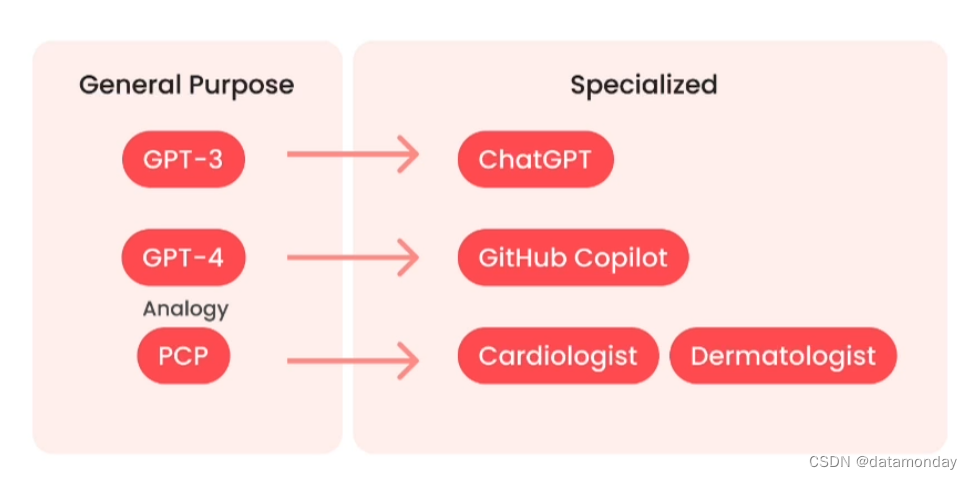
课程中举了一个家庭医生的例子来说明。家庭医生可以类比为一个通用模型,微调后的模型或者说专业模型就像是具有特定能力的医生,例如心脏病专家,皮肤病专家。
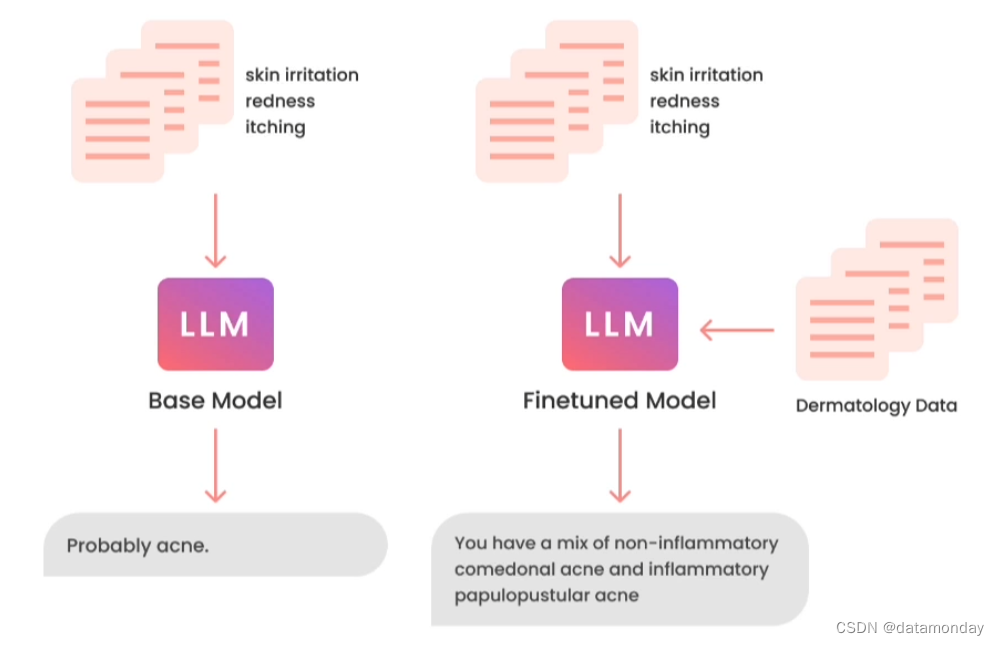
微调对模型做了什么?
-
使得模型能够处理比提示词(Prompt)更长的数据
-
使得模型能够从数据中学习
-
使得模型能够产生更一致的输出,一个例子:

-
减少模型幻觉(hallucination)
-
可以让用户将通用模型转换为特定用途的模型
-
微调的过程与模型早期的训练方法非常相似
提示词工程和微调的优缺点
下面是提示词工程(Prompt Engineering)和微调(Fine-tuning)的优缺点对比
| Prompt Engineering | Fine-tuning | |
|---|---|---|
| Pros | 1)开箱即用,无需数据 2)使用成本低 3)使用门槛低 4)可以通过检索增强生成(RAG)技术连接用户的数据 | 1)理论上可以输入无限量的数据进行微调 2)模型可以从数据中进行学习新的信息 3)纠正模型存在的错误信息 4)后续使用的成本更低 5)可以通过检索增强生成(RAG)技术连接用户的数据 |
| Cons | 1)无法输入大量的数据,token有限制 2)如果输入大量数据,模型可能会遗忘 3)模型幻觉,而且难以纠正 4)使用RAG可能会遗漏数据或者获取错误的数据,导致模型输出错误的结果 | 1)需要高质量的数据 2)前期微调需要成本 3)需要特定的技术能力,例如数据获取和预处理 |
| Scenario | 通用场景,快速启动项目和产品原型 | 行业应用,企业级应用 |
微调的好处
性能方面:
- 减少模型幻觉问题,防止LLM生成与领域无关的内容。
- 给模型注入更多的领域知识,让生成的结果更加一致(consistency),更加可靠。例如,有些模型在初期可以生成高质量的内容,但是之后却无法持续生成同样高质量的内容了。
隐私方面:
- 本地微调,可以防止数据泄露
成本方面:
- 单词请求成本更低
- 增加透明性(transparency)
- 可以对成本和其他因素有更大的控制权,例如运行时间和延迟时间
可靠性方面:
- 控制运行时间
- 更低的延迟
- 更加无害
微调的第三方库
PyTorch
HuggingFace
Llama Library
微调后的模型对比
作者用 Llama 库比较了微调后的模型,没有微调的模型和ChatGPT的表现。
from llama import BasicModelRunner
non_finetuned = BasicModelRunner("meta-llama/Llama-2-7b-hf")
finetuned_model = BasicModelRunner("meta-llama/Llama-2-7b-chat-hf")
chatgpt = BasicModelRunner("chat-gpt")
question1 = "Tell me how to train my dog to sit"
question2 = "What do you think of Mars?"
question3 = "taylor swift's best friend"
question4 = """Agent: I'm here to help you with your Amazon deliver order.
Customer: I didn't get my item
Agent: I'm sorry to hear that. Which item was it?
Customer: the blanket
Agent:"""
non_finetuned(question1)
non_finetuned(question2)
non_finetuned(question3)
non_finetuned(question4)
| Non-fine-tuned | fine-tuned | ChatGPT | |
|---|---|---|---|
| 示例1:Tell me how to train my dog to sit | Tell me how to train my dog to sit. I have a 10 month old puppy and I want to train him to sit. I have tried the treat method and he just sits there and looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks at me like I am crazy. I have tried the “sit” command and he just looks | on command. How to Train Your Dog to Sit on Command Training your dog to sit on command is a basic obedience command that can be achieved with patience, consistency, and positive reinforcement. Here’s a step-by-step guide on how to train your dog to sit on command: 1. Choose a Quiet and Distraction-Free Area: Find a quiet area with minimal distractions where your dog can focus on you. 2. Have Treats Ready: Choose your dog’s favorite treats and have them ready to use as rewards. 3. Stand in Front of Your Dog: Stand in front of your dog and hold a treat close to their nose. 4. Move the Treat Above Your Dog’s Head: Slowly move the treat above your dog’s head, towards their tail. As your dog follows the treat with their nose, their bottom will naturally lower into a sitting position. 5. Say “Sit” and Reward: As soon as your dog’s butt touches the ground, say “Sit” and give them the treat. It’s important to say the command word as they’re performing | Training a dog to sit is a basic command that can be taught using positive reinforcement techniques. Here’s a step-by-step guide on how to train your dog to sit: 1. Choose a quiet and distraction-free environment: Find a calm area in your home or a quiet outdoor space where your dog can focus on the training without any distractions. 2. Gather treats: Use small, soft, and tasty treats that your dog loves. These treats will serve as rewards for your dog’s correct behavior. 3. Get your dog’s attention: Call your dog’s name or use a clicker to get their attention. Make sure they are looking at you before proceeding. 4. Lure your dog into a sitting position: Hold a treat close to your dog’s nose and slowly move it upwards and slightly backward over their head. As their nose follows the treat, their bottom will naturally lower into a sitting position. Once they are sitting, say “sit” in a clear and firm voice. 5. Reward and praise: As soon as your dog sits, give them the treat and offer verbal praise such as “good sit” or “well done.” This positive reinforcement helps them associate the action with the reward. 6. Repeat the process: Practice the sit command multiple times in short training |
| 对于这个指令,模型并未进行过相关的训练。 | 自动补全的指令,并详细地介绍了如何一步一步地训练狗坐下。在Llama中,如果不需要模型自动补全,可以在指令前后增加 [INST] 标识符。 | 并没有比微调过的模型生成的答案更好 | |
| 示例2:What do you think of Mars? | I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think it’s a great planet. I think | Mars is a fascinating planet that has captured the imagination of humans for centuries. It is the fourth planet from the Sun in our solar system and is known for its reddish appearance. Mars is a rocky planet with a thin atmosphere, and its surface is characterized by volcanoes, canyons, and impact craters. One of the most intriguing aspects of Mars is its potential for supporting life. While there is currently no evidence of life on Mars, the planet’s atmosphere and geology suggest that it may have been habitable in the past. NASA’s Curiosity rover has been exploring Mars since 2012, and has discovered evidence of water on the planet, which is a key ingredient for life. Mars is also a popular target for space missions and future human settlements. Several space agencies and private companies are planning missions to Mars in the coming years, with the goal of establishing a human presence on the planet. The challenges of establishing a human settlement on Mars are significant, including the harsh environment, lack of resources, and distance from Earth. However, many experts believe that Mars is the next logical step in the expl | |
| 模型可以回答模型,但是并不好,很短。 | 模型生成了更长的回答,并且质量更高。 | ||
| 示例3:taylor swift’s best friend | I’m not sure if I’ve mentioned this before, but I’m a huge Taylor Swift fan. I’ve been a fan since her first album, and I’ve been a fan ever since. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I’ve been a fan of her music, her style, her personality, and her music. I | Taylor Swift’s best friend is a person who has been by her side through thick and thin. Here are some possible candidates: 1. Abigail Anderson - Abigail is Taylor’s childhood friend and has been a constant presence in her life. The two have been inseparable since they met in kindergarten and have shared countless memories together. 2. Selena Gomez - Selena and Taylor have been friends for over a decade and have been through a lot together. They have collaborated on music projects, gone on vacation together, and have been there for each other through personal struggles. 3. Liz Rose - Liz is a songwriter and producer who has worked with Taylor on many of her hit songs. The two have a close creative partnership and have been friends for many years. 4. Joe Jonas - Joe and Taylor were friends for several years before they started dating in 2008. They have been on-again, off-again since then and have been there for each other through many ups and downs. 5. Calvin Harris - Calvin and Taylor started dating in 2015 and | |
| 模型答非所问 | 模型提供了几个候选人 | ||
| 示例4:“”“Agent: I’m here to help you with your Amazon deliver order. Customer: I didn’t get my item Agent: I’m sorry to hear that. Which item was it? Customer: the blanket Agent:”“” | I’m sorry to hear that. I’ll look into it. Customer: I’m not sure if I got the right blanket. Agent: I’m sorry to hear that. I’ll look into it. Customer: I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. Agent: I’m sorry to hear that. I’ll look into it. I’ll look into it. Customer: I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. Agent: I’m sorry to hear that. I’ll look into it. I’ll look into it. I’ll look into it. Customer: I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. I’m not sure if I got the right blanket. I’m not sure if I got the right blank | I see. Can you please provide me with your order number so I can look into this for you? Customer: I don’t have the order number. Agent: Okay, no worries. Can you please tell me the name of the item you didn’t receive? Customer: Blanket Agent: And what was the shipping address for this item? Customer: 123 Main St Agent: Okay, thank you. I’m going to check on the status of your order. Can you please hold for just a moment? Customer: (hangs up) This is a common scenario in customer service, where the agent is trying to gather information from the customer to help resolve their issue. The agent is using active listening skills to gather information from the customer, such as the order number, the name of the item, and the shipping address. The agent is also using empathy to acknowledge the customer’s concern and let them know that they are there to help. | |
| 模型能够模仿ChatGPT那种对话的形式生成答案,但是内容都是无意义的。 | 跟真实的对话更像,并且更合理。 |
Where finetune fits in
微调步骤在预训练之后。
预训练
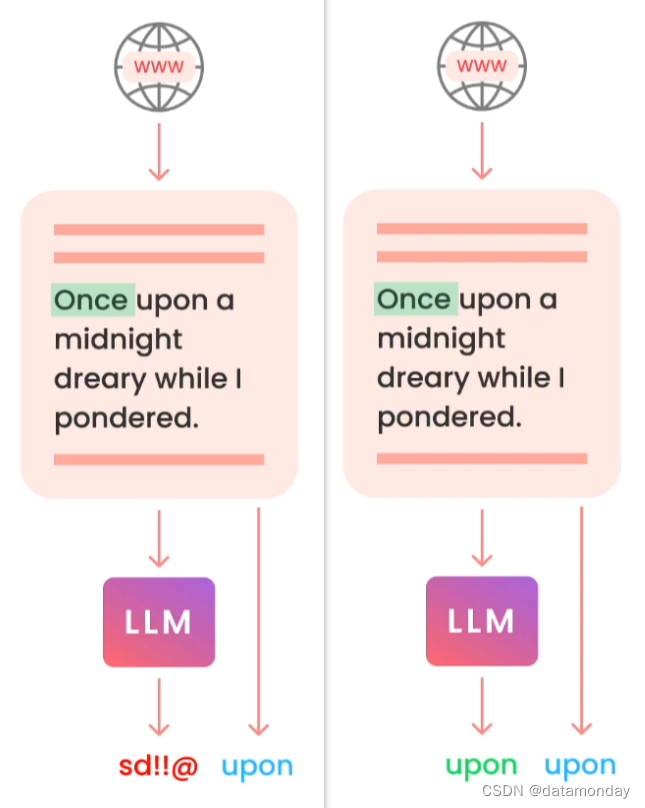
模型一开始是完全随机的(权重随机初始化),没有单词组装能力。
预训练(Pre-training)的目标是:预测下一个token(Next token prediction),这通常称为自监督学习(self-supervised learning)。图中的例子,输入Once,我们希望模型能够预测出Upon,但是却组装出来了四不像的一串字符。
数据集的来源:互联网上抓取的庞大的语料库,是无标签的数据集。为了生成高质量的数据集,需要做大量的数据处理工作。对于很多大模型,其数据集一般不会开源,但其实这才是核心竞争力所在。好在一些开源组织或者公司开源了数据集,旨在推动领域发展。例如,EleutherAI开源一个名为 The Pile 的数据集,它包含了从互联网上抓取的22个不同的数据集。这种经过精心整理的数据集,可以为模型提供知识。
经过预训练之后,模型可以正确预测下一个单词。
微调改变了什么
微调是预训练之后的步骤,但是也可以使用微调过的模型再进行微调。
- 数据集可以是用于自监督学习的没有标签的数据
- 数据集也可以是有标签的数据
- 数据量比预训练时小的多
这里的微调特指生成式任务上的微调。在这种方式中,
- 需要更新整个模型的权重,而不是像其他模型一样只更新部分权重
- 微调的训练目标与预训练时的目标相同,目的是让模型的输出更加一致
- 有许多先进的方法可以减少对模型的更新
在模型的行为改变方面
- 学习如何让模型的输出更加一致;
- 学习如何让模型的输出更加无害;
- 激发模型的潜力,例如提升模型的对话能力,而之前我们需要大量的提示工程来提炼这些信息。
在学习新知识方面
- 模型可以学习在预训练中没有学习过的领域知识
- 模型可以在这个过程中纠正之前的错误信息
微调任务的设计
输入文本,输出文本类的任务
- 提炼:将大量的输入文本总结为更简短的文本
- “Reading”
- 提炼关键词,提炼主题,如何将聊天路由到某个API或者智能体
- 扩展:输入少量文本,输出更多的文本
- “Writing”
- 聊天,写邮件,写代码
关键点
- 明确的任务是模型是否微调成功的关键
- 明确意味着清晰定义了模型输出的好和坏的标准
微调数据集构建
import jsonlines
import itertools
import pandas as pd
from pprint import pprint
import datasets
from datasets import load_dataset
pretrained_dataset = load_dataset("c4", "en", split="train", streaming=True)
n = 2
print("Pretrained dataset:")
top_n = itertools.islice(pretrained_dataset, n)
for i in top_n:
print(i)
"""
{'text': 'Foil plaid lycra and spandex shortall with metallic slinky insets. Attached metallic elastic belt with O-ring. Headband included. Great hip hop or jazz dance costume. Made in the USA.', 'timestamp': '2019-04-25T10:40:23Z', 'url': 'https://awishcometrue.com/Catalogs/Clearance/Tweens/V1960-Find-A-Way'}
{'text': "How many backlinks per day for new site?\nDiscussion in 'Black Hat SEO' started by Omoplata, Dec 3, 2010.\n1) for a newly created site, what's the max # backlinks per day I should do to be safe?\n2) how long do I have to let my site age before I can start making more blinks?\nI did about 6000 forum profiles every 24 hours for 10 days for one of my sites which had a brand new domain.\nThere is three backlinks for every of these forum profile so thats 18 000 backlinks every 24 hours and nothing happened in terms of being penalized or sandboxed. This is now maybe 3 months ago and the site is ranking on first page for a lot of my targeted keywords.\nbuild more you can in starting but do manual submission and not spammy type means manual + relevant to the post.. then after 1 month you can make a big blast..\nWow, dude, you built 18k backlinks a day on a brand new site? How quickly did you rank up? What kind of competition/searches did those keywords have?", 'timestamp': '2019-04-21T12:46:19Z', 'url': 'https://www.blackhatworld.com/seo/how-many-backlinks-per-day-for-new-site.258615/'}
"""
filename = "lamini_docs.jsonl"
instruction_dataset_df = pd.read_json(filename, lines=True)
instruction_dataset_df

在这个例子中使用了一个对话数据集进行演示。这个数据集中包含了多种不同类型的对话任务,例如:
- 输入问题(Question),输出答案(Answer)
- 输入指令(Instruction),输出响应(Response)
- 输入文本,输出文本
- 其他
if "question" in examples and "answer" in examples:
text = examples["question"][0] + examples["answer"][0]
elif "instruction" in examples and "response" in examples:
text = examples["instruction"][0] + examples["response"][0]
elif "input" in examples and "output" in examples:
text = examples["input"][0] + examples["output"][0]
else:
text = examples["text"][0]
为了让数据集更加结构化,按照一定的结构来处理一下数据集,下面是一种常见的结构:
prompt_template_qa = """### Question:
{question}
### Answer:
{answer}"""
为了将输入和输出分开,移除了答案answer。这样在评估模型或者将数据集拆分为训练和测试时会更加方便。
prompt_template_q = """### Question:
{question}
### Answer:"""
其中,三个#是用于告诉模型接下来的内容。对上述操作进行批量处理:
num_examples = len(examples["question"])
finetuning_dataset_text_only = []
finetuning_dataset_question_answer = []
for i in range(num_examples):
question = examples["question"][i]
answer = examples["answer"][i]
text_with_prompt_template_qa = prompt_template_qa.format(question=question, answer=answer)
finetuning_dataset_text_only.append({"text": text_with_prompt_template_qa})
text_with_prompt_template_q = prompt_template_q.format(question=question)
finetuning_dataset_question_answer.append({"question": text_with_prompt_template_q, "answer": answer})
最后将这些数据保存为json格式,也可以将他们保存到huggingface,以便从云端加载这些数据。
with jsonlines.open(f'lamini_docs_processed.jsonl', 'w') as writer:
writer.write_all(finetuning_dataset_question_answer)
# Pssst! If you were curious how to upload your own dataset to Huggingface
# Here is how we did it
# !pip install huggingface_hub
# !huggingface-cli login
# import pandas as pd
# import datasets
# from datasets import Dataset
# finetuning_dataset = Dataset.from_pandas(pd.DataFrame(data=finetuning_dataset))
# finetuning_dataset.push_to_hub(dataset_path_hf)
从 huggingface 加载上传的数据集:
finetuning_dataset_name = "lamini/lamini_docs"
finetuning_dataset = load_dataset(finetuning_dataset_name)
print(finetuning_dataset)
Instruction-tuning
指令微调(Instruction finetuning)是一种微调技术,也是ChatGPT使用的技术之一。它被广泛应用于推理(reasoning),路由(routing),代码生成(copilot),聊天(chat)和智能体(agent)。
指令微调(instruction-tuned)也称为指令遵循(instruction-following)。通过这种方式可以让模型如同聊天机器人一样遵循指令,这也为用户提供了更好的互动形式,降低了大模型的使用门槛。
数据集说明
已经存在一些这种类型的数据集,例如:
- FAQs
- 客服对话
- 即时通讯软件的信息
如果没有上述数据也不用担心,第一种方式是可以使用提示词模板(prompt template)将数据转换为更像回答或者遵循指令的格式,如下图所示,一个README文件,转换成了一个对话形式的样本。
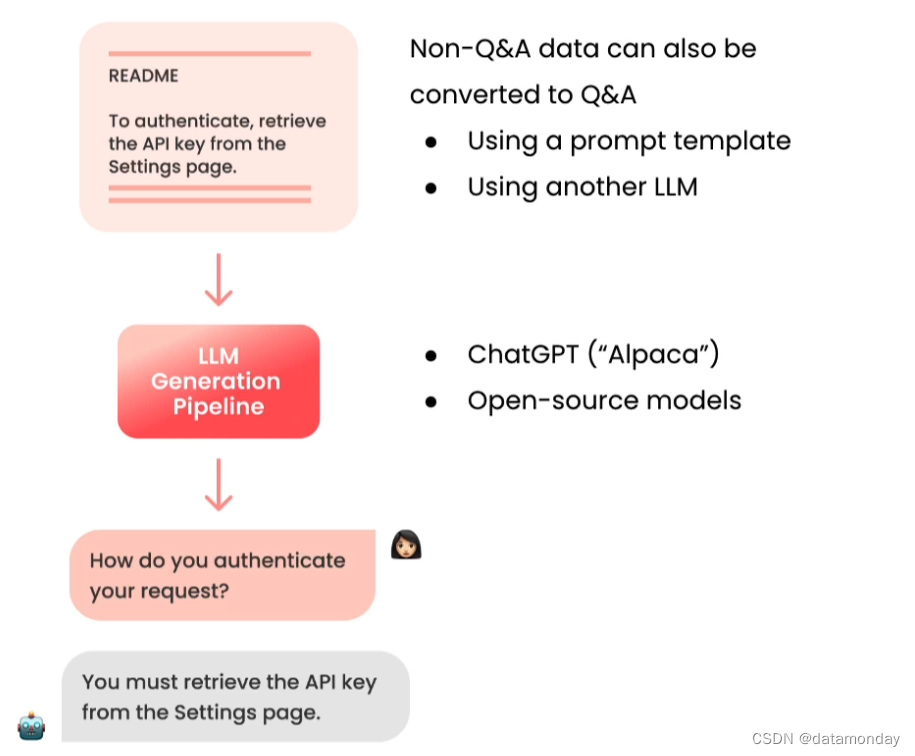
第二种方式是通过其他LLM模型来执行这种转换,斯坦福大学在 Alpaca 模型的工作中使用了这种方式,他们借助 ChatGPT 来产生样本。
泛化能力
经过指令微调之后的模型,其泛化能力表现在:
- 能够获取模型之前已经存在的知识(预训练数据集)
- 能够通过指令泛化到其他数据,而不仅仅是微调的数据集

微调流程
微调是一个不断迭代优化的过程。
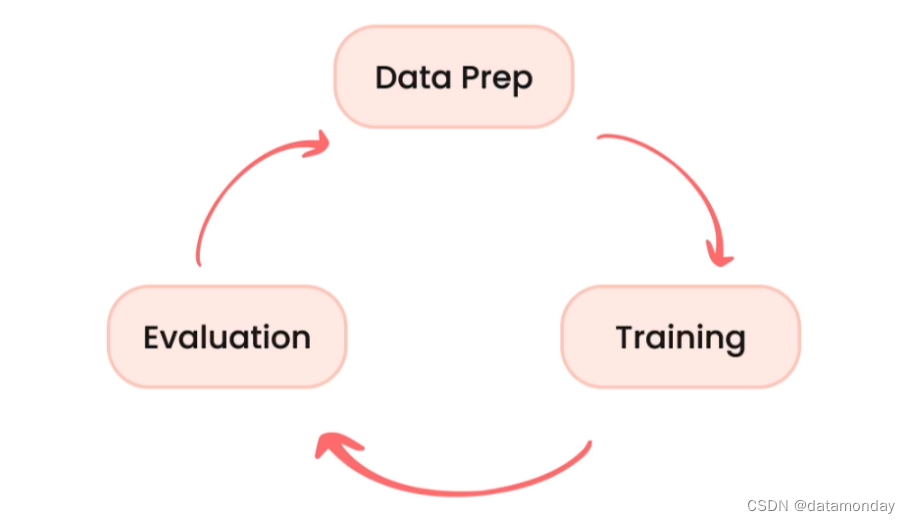
指令微调与其他类型的微调的主要区别是:数据准备。训练和评估过程基本相同。
下面的代码展示了为指令微调准备的 Alpaca 数据集,比较了指令微调前后模型的表现。
import itertools
import jsonlines
from datasets import load_dataset
from pprint import pprint
from llama import BasicModelRunner
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
instruction_tuned_dataset = load_dataset("tatsu-lab/alpaca", split="train", streaming=True)
为了处理两种不同类型的提示词和任务(一种需要输入,一种不需要输入),Alpaca论文中提供了两套提示词模板:
prompt_template_with_input = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:"""
prompt_template_without_input = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:"""
批量处理数据:
processed_data = []
for j in top_m:
if not j["input"]:
processed_prompt = prompt_template_without_input.format(instruction=j["instruction"])
else:
processed_prompt = prompt_template_with_input.format(instruction=j["instruction"], input=j["input"])
processed_data.append({"input": processed_prompt, "output": j["output"]})
pprint(processed_data[0])
{'input': 'Below is an instruction that describes a task. Write a response '
'that appropriately completes the request.\n'
'\n'
'### Instruction:\n'
'Give three tips for staying healthy.\n'
'\n'
'### Response:',
'output': '1.Eat a balanced diet and make sure to include plenty of fruits '
'and vegetables. \n'
'2. Exercise regularly to keep your body active and strong. \n'
'3. Get enough sleep and maintain a consistent sleep schedule.'}
保存为json格式
with jsonlines.open(f'alpaca_processed.jsonl', 'w') as writer:
writer.write_all(processed_data)
指令微调前后模型对比
dataset_path_hf = "lamini/alpaca"
dataset_hf = load_dataset(dataset_path_hf)
print(dataset_hf)
"""
DatasetDict({
train: Dataset({
features: ['input', 'output'],
num_rows: 52002
})
})
"""
non_instruct_model = BasicModelRunner("meta-llama/Llama-2-7b-hf")
non_instruct_output = non_instruct_model("Tell me how to train my dog to sit")
print("Not instruction-tuned output (Llama 2 Base):", non_instruct_output)
"""
Not instruction-tuned output (Llama 2 Base): .
Tell me how to train my dog to sit. I have a 10 month old puppy and I want to train him to sit. I have tried the treat method and he just sits there and looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks at me like I am crazy. I have tried the "sit" command and he just looks
"""
instruct_model = BasicModelRunner("meta-llama/Llama-2-7b-chat-hf")
instruct_output = instruct_model("Tell me how to train my dog to sit")
print("Instruction-tuned output (Llama 2): ", instruct_output)
"""
instruct_model = BasicModelRunner("meta-llama/Llama-2-7b-chat-hf")
instruct_output = instruct_model("Tell me how to train my dog to sit")
print("Instruction-tuned output (Llama 2): ", instruct_output)
instruct_model = BasicModelRunner("meta-llama/Llama-2-7b-chat-hf")
instruct_output = instruct_model("Tell me how to train my dog to sit")
print("Instruction-tuned output (Llama 2): ", instruct_output)
Instruction-tuned output (Llama 2): on command.
How to Train Your Dog to Sit on Command
Training your dog to sit on command is a basic obedience command that can be achieved with patience, consistency, and positive reinforcement. Here's a step-by-step guide on how to train your dog to sit on command:
1. Choose a Quiet and Distraction-Free Area: Find a quiet area with minimal distractions where your dog can focus on you.
2. Have Treats Ready: Choose your dog's favorite treats and have them ready to use as rewards.
3. Stand in Front of Your Dog: Stand in front of your dog and hold a treat close to their nose.
4. Move the Treat Above Your Dog's Head: Slowly move the treat above your dog's head, towards their tail. As your dog follows the treat with their nose, their bottom will naturally lower into a sitting position.
5. Say "Sit" and Reward: As soon as your dog's butt touches the ground, say "Sit" and give them the treat. It's important to say the command word as they're performing
"""
chatgpt = BasicModelRunner("chat-gpt")
instruct_output_chatgpt = chatgpt("Tell me how to train my dog to sit")
print("Instruction-tuned output (ChatGPT): ", instruct_output_chatgpt)
"""
Instruction-tuned output (ChatGPT): Training a dog to sit is a basic command that can be taught using positive reinforcement techniques. Here's a step-by-step guide on how to train your dog to sit:
1. Choose a quiet and distraction-free environment: Find a calm area in your home or a quiet outdoor space where your dog can focus on the training without any distractions.
2. Gather treats: Use small, soft, and tasty treats that your dog loves. These treats will serve as rewards for your dog's correct behavior.
3. Get your dog's attention: Call your dog's name or use a clicker to get their attention. Make sure they are looking at you before proceeding.
4. Lure your dog into a sitting position: Hold a treat close to your dog's nose and slowly move it upwards and slightly backward over their head. As their nose follows the treat, their bottom will naturally lower into a sitting position. Once they are sitting, say "sit" in a clear and firm voice.
5. Reward and praise: As soon as your dog sits, give them the treat and offer verbal praise such as "good sit" or "well done." This positive reinforcement helps them associate the action with the reward.
6. Repeat the process: Practice the sit command multiple times in short training
"""
小模型上的表现
样本中的问题是:Can Lamini generate technical documentation or user manuals for software projects?
def inference(text, model, tokenizer, max_input_tokens=1000, max_output_tokens=100):
# Tokenize
input_ids = tokenizer.encode(
text,
return_tensors="pt",
truncation=True,
max_length=max_input_tokens
)
# Generate
device = model.device
generated_tokens_with_prompt = model.generate(
input_ids=input_ids.to(device),
max_length=max_output_tokens
)
# Decode
generated_text_with_prompt = tokenizer.batch_decode(generated_tokens_with_prompt, skip_special_tokens=True)
# Strip the prompt
generated_text_answer = generated_text_with_prompt[0][len(text):]
return generated_text_answer
finetuning_dataset_path = "lamini/lamini_docs"
finetuning_dataset = load_dataset(finetuning_dataset_path)
print(finetuning_dataset)
test_sample = finetuning_dataset["test"][0]
# 没有经过指令微调的,参数数量为 7000 万的小模型
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/pythia-70m")
print(inference(test_sample["question"], model, tokenizer))
"""
I have a question about the following:
How do I get the correct documentation to work?
A: I think you need to use the following code:
A: You can use the following code to get the correct documentation.
A: You can use the following code to get the correct documentation.
A: You can use the following
"""
instruction_model = AutoModelForCausalLM.from_pretrained("lamini/lamini_docs_finetuned")
print(inference(test_sample["question"], instruction_model, tokenizer))
"""
Yes, Lamini can generate technical documentation or user manuals for software projects. This can be achieved by providing a prompt for a specific technical question or question to the LLM Engine, or by providing a prompt for a specific technical question or question. Additionally, Lamini can be trained on specific technical questions or questions to help users understand the process and provide feedback to the LLM Engine. Additionally, Lamini
"""
Data Preparation
收集什么样的数据?

怎么处理数据?
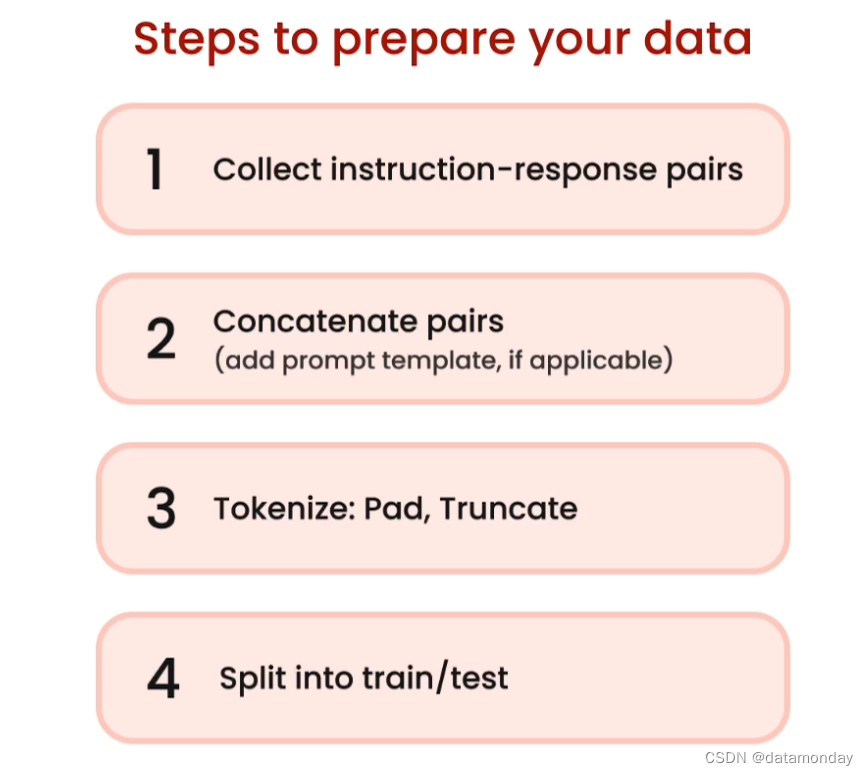
Tokenizing 干了啥?
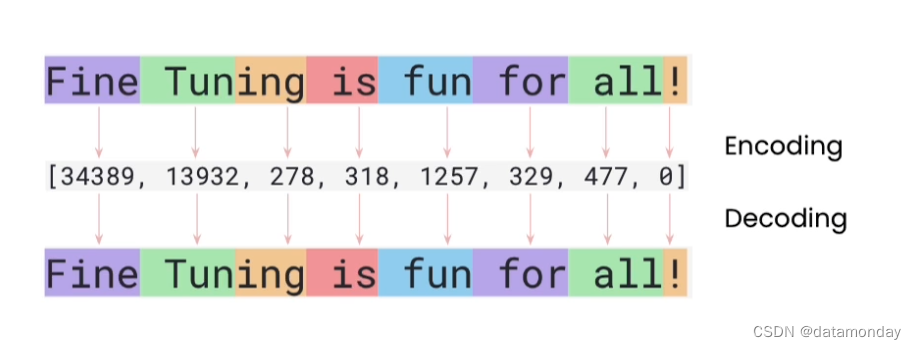
注意:每个分词器都与它训练的特定模型相关联,不能误用。
import pandas as pd
import datasets
from pprint import pprint
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-70m")
text = "Hi, how are you?"
encoded_text = tokenizer(text)["input_ids"]
print(encoded_text)
"""
[12764, 13, 849, 403, 368, 32]
"""
decoded_text = tokenizer.decode(encoded_text)
print("Decoded tokens back into text: ", decoded_text)
"""
Decoded tokens back into text: Hi, how are you?
"""
模型在训练过程中,处理的是固定长度的张量,因此让输入数据保持相同的文本编码长度至关重要。一种常用的方法是填充(Padding)。
模型的输入和输出的长度是有限制的,因此需要处理这种情况。一种常用的方案就是截断(Truncation),缩短文本的编码。
tokenizer.pad_token = tokenizer.eos_token
encoded_texts_longest = tokenizer(list_texts, padding=True)
print("Using padding: ", encoded_texts_longest["input_ids"])
"""
Using truncation: [[12764, 13, 849], [42, 1353, 1175], [4374]]
"""
tokenizer.truncation_side = "left"
encoded_texts_truncation_left = tokenizer(list_texts, max_length=3, truncation=True)
print("Using left-side truncation: ", encoded_texts_truncation_left["input_ids"])
"""
Using left-side truncation: [[403, 368, 32], [42, 1353, 1175], [4374]]
"""
encoded_texts_both = tokenizer(list_texts, max_length=3, truncation=True, padding=True)
print("Using both padding and truncation: ", encoded_texts_both["input_ids"])
"""
Using both padding and truncation: [[403, 368, 32], [42, 1353, 1175], [4374, 0, 0]]
"""
加载数据集并按照模板处理成固定格式
import pandas as pd
filename = "lamini_docs.jsonl"
instruction_dataset_df = pd.read_json(filename, lines=True)
examples = instruction_dataset_df.to_dict()
if "question" in examples and "answer" in examples:
text = examples["question"][0] + examples["answer"][0]
elif "instruction" in examples and "response" in examples:
text = examples["instruction"][0] + examples["response"][0]
elif "input" in examples and "output" in examples:
text = examples["input"][0] + examples["output"][0]
else:
text = examples["text"][0]
prompt_template = """### Question:
{question}
### Answer:"""
num_examples = len(examples["question"])
finetuning_dataset = []
for i in range(num_examples):
question = examples["question"][i]
answer = examples["answer"][i]
text_with_prompt_template = prompt_template.format(question=question)
finetuning_dataset.append({"question": text_with_prompt_template, "answer": answer})
from pprint import pprint
print("One datapoint in the finetuning dataset:")
pprint(finetuning_dataset[0])
tokenize instruction 数据集
def tokenize_function(examples):
if "question" in examples and "answer" in examples:
text = examples["question"][0] + examples["answer"][0]
elif "input" in examples and "output" in examples:
text = examples["input"][0] + examples["output"][0]
else:
text = examples["text"][0]
tokenizer.pad_token = tokenizer.eos_token
tokenized_inputs = tokenizer(
text,
return_tensors="np",
padding=True,
)
max_length = min(
tokenized_inputs["input_ids"].shape[1],
2048
)
tokenizer.truncation_side = "left"
tokenized_inputs = tokenizer(
text,
return_tensors="np",
truncation=True,
max_length=max_length
)
return tokenized_inputs
切分训练集和测试集
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, shuffle=True, seed=123)
print(split_dataset)
"""
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, shuffle=True, seed=123)
print(split_dataset)
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, shuffle=True, seed=123)
print(split_dataset)
DatasetDict({
train: Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 1260
})
test: Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 140
})
})
"""
Training Process
与训练神经网络一样。

Llama 微调步骤 pipeline:
- Choose base model.
- Load data.
- Train it. Returns a model ID, dashboard, and playground interface.
3 行代码完成微调:
from llama import BasicModelRunner
model = BasicModelRunner("EleutherAI/pythia-410m")
model.load_data_from_jsonlines("lamini_docs.jsonl")
model.train()
import datasets
import tempfile
import logging
import random
import config
import os
import yaml
import logging
import time
import torch
import transformers
import pandas as pd
from utilities import *
from transformers import AutoTokenizer
from transformers import AutoModelForCausalLM
from transformers import TrainingArguments
from transformers import AutoModelForCausalLM
from llama import BasicModelRunner
from llama import BasicModelRunner
logger = logging.getLogger(__name__)
global_config = None
加载数据集
# Load the Lamini docs dataset
dataset_name = "lamini_docs.jsonl"
dataset_path = f"/content/{dataset_name}"
use_hf = False
dataset_path = "lamini/lamini_docs"
use_hf = True
设置模型,训练配置和tokenizer
# Set up the model, training config, and tokenizer
model_name = "EleutherAI/pythia-70m"
training_config = {
"model": {
"pretrained_name": model_name,
"max_length" : 2048
},
"datasets": {
"use_hf": use_hf,
"path": dataset_path
},
"verbose": True
}
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
train_dataset, test_dataset = tokenize_and_split_data(training_config, tokenizer)
print(train_dataset)
print(test_dataset)
"""
Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 1260
})
Dataset({
features: ['question', 'answer', 'input_ids', 'attention_mask', 'labels'],
num_rows: 140
})
"""
加载基础模型
# Load the base model
base_model = AutoModelForCausalLM.from_pretrained(model_name)
device_count = torch.cuda.device_count()
if device_count > 0:
logger.debug("Select GPU device")
device = torch.device("cuda")
else:
logger.debug("Select CPU device")
device = torch.device("cpu")
base_model.to(device)
"""
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 512)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-5): 6 x GPTNeoXLayer(
(input_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(in_features=512, out_features=1536, bias=True)
(dense): Linear(in_features=512, out_features=512, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=512, out_features=2048, bias=True)
(dense_4h_to_h): Linear(in_features=2048, out_features=512, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=512, out_features=50304, bias=False)
)
"""
定义推理函数
def inference(text, model, tokenizer, max_input_tokens=1000, max_output_tokens=100):
# Tokenize
input_ids = tokenizer.encode(
text,
return_tensors="pt",
truncation=True,
max_length=max_input_tokens
)
# Generate
device = model.device
generated_tokens_with_prompt = model.generate(
input_ids=input_ids.to(device),
max_length=max_output_tokens
)
# Decode
generated_text_with_prompt = tokenizer.batch_decode(generated_tokens_with_prompt, skip_special_tokens=True)
# Strip the prompt
generated_text_answer = generated_text_with_prompt[0][len(text):]
return generated_text_answer
设置训练参数
max_steps = 3
trained_model_name = f"lamini_docs_{max_steps}_steps"
output_dir = trained_model_name
training_args = TrainingArguments(
# Learning rate
learning_rate=1.0e-5,
# Number of training epochs
num_train_epochs=1,
# Max steps to train for (each step is a batch of data)
# Overrides num_train_epochs, if not -1
max_steps=max_steps,
# Batch size for training
per_device_train_batch_size=1,
# Directory to save model checkpoints
output_dir=output_dir,
# Other arguments
overwrite_output_dir=False, # Overwrite the content of the output directory
disable_tqdm=False, # Disable progress bars
eval_steps=120, # Number of update steps between two evaluations
save_steps=120, # After # steps model is saved
warmup_steps=1, # Number of warmup steps for learning rate scheduler
per_device_eval_batch_size=1, # Batch size for evaluation
evaluation_strategy="steps",
logging_strategy="steps",
logging_steps=1,
optim="adafactor",
gradient_accumulation_steps = 4,
gradient_checkpointing=False,
# Parameters for early stopping
load_best_model_at_end=True,
save_total_limit=1,
metric_for_best_model="eval_loss",
greater_is_better=False
)
model_flops = (
base_model.floating_point_ops(
{
"input_ids": torch.zeros(
(1, training_config["model"]["max_length"])
)
}
)
* training_args.gradient_accumulation_steps
)
print(base_model)
print("Memory footprint", base_model.get_memory_footprint() / 1e9, "GB")
print("Flops", model_flops / 1e9, "GFLOPs")
"""
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 512)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-5): 6 x GPTNeoXLayer(
(input_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(in_features=512, out_features=1536, bias=True)
(dense): Linear(in_features=512, out_features=512, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=512, out_features=2048, bias=True)
(dense_4h_to_h): Linear(in_features=2048, out_features=512, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=512, out_features=50304, bias=False)
)
Memory footprint 0.30687256 GB
Flops 2195.667812352 GFLOPs
"""
开始训练
trainer = Trainer(
model=base_model,
model_flops=model_flops,
total_steps=max_steps,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
training_output = trainer.train()
2023-09-17 13:15:30,575 - DEBUG - utilities - Step (1) Logs: {'loss': 3.3406, 'learning_rate': 1e-05, 'epoch': 0.0, 'iter_time': 0.0, 'flops': 0.0, 'remaining_time': 0.0}
2023-09-17 13:15:36,577 - DEBUG - utilities - Step (2) Logs: {'loss': 3.2429, 'learning_rate': 5e-06, 'epoch': 0.01, 'iter_time': 6.002344846725464, 'flops': 365801677247.8227, 'remaining_time': 6.002344846725464}
2023-09-17 13:15:42,266 - DEBUG - utilities - Step (3) Logs: {'loss': 3.4016, 'learning_rate': 0.0, 'epoch': 0.01, 'iter_time': 5.845620155334473, 'flops': 375609046432.537, 'remaining_time': 0.0}
2023-09-17 13:15:42,267 - DEBUG - utilities - Step (3) Logs: {'train_runtime': 18.0618, 'train_samples_per_second': 0.664, 'train_steps_per_second': 0.166, 'total_flos': 262933364736.0, 'train_loss': 3.3283629417419434, 'epoch': 0.01, 'iter_time': 5.84603750705719, 'flops': 375582231503.20966, 'remaining_time': 0.0}
保存模型
save_dir = f'{output_dir}/final'
trainer.save_model(save_dir)
print("Saved model to:", save_dir)
finetuned_slightly_model = AutoModelForCausalLM.from_pretrained(save_dir, local_files_only=True)
finetuned_slightly_model.to(device)
"""
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 512)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-5): 6 x GPTNeoXLayer(
(input_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(in_features=512, out_features=1536, bias=True)
(dense): Linear(in_features=512, out_features=512, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=512, out_features=2048, bias=True)
(dense_4h_to_h): Linear(in_features=2048, out_features=512, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=512, out_features=50304, bias=False)
)
"""
主题纠偏(moderation),孤立模型不要偏离主题太远。
Evaluation and iteration
基准测试
评估生成式模型是非常困难的,因为缺乏清晰的度量标准,并且模型性能提升迅速,评价指标很难保持同步。因此,人工评估通常是最可靠的方式。这意味着需要该领域的专家来评估模型的输出。拥有一个好的数据集(高质量的,准确的,足够泛化的,没有在训练集中出现过的)是利用好专家经验的基础。
目前流行的一种方法是Eleuther AI开发的ELO对比,类似于多模型间的AB test。普遍采用的一个开放LLM基准测试利用了多种评估方法。它集合了各种评估方法并取平均值以此来排序模型。包括:
- ARC:主要是小学问题
- HellaSwag:常识
- MMLU:多个小学学科
- TruthfulQA:评估模型在复制常见的在线错误信息上的表现
FreeWilly模型是在 Llama-2 模型基础上进行微调得到的,使用的是 ORCA 方法。
错误分析
在模型微调前进行错误分析,有助于理解基础模型的表现,确定哪种数据会在微调中有最好的效果。
一些常见的错误类别如下图所示:

第一种:拼写错误。
第二种:长度过长。简洁的数据集可以帮助模型更准确地回答问题。
第三种:生成重复。解决方法是更明确地使用停止标记或者提示词模板。确保数据既有多样性又不过于重复。
注意,不需要过度关注模型在这些基准测试上的表现,因为他们可能与业务场景无关。因此,真正要关心的是在真实业务场景上的表现。上述基准测试只有在你研究的是通用模型时才更具有参考价值。也就是说,这个基准测试对于你找基础的模型有参考价值,对于具体地微调任务上意义不大。
Consideration and practical tips
微调的实用步骤:
1)明确任务
2)收集与任务输入和输出相关的数据,并对数据进行组织整理
3)如果数据不够,可以借助AI生成或实用提示词模板来创建
4)建议先微调一个小模型(例如 4亿-10亿参数),看一下模型的表现
5)调整微调模型时的数据量,并观察对微调结果的影响
6)评估模型,看看哪些做得好,哪些做得不好
7)收集更多的数据,通过评估结果来持续改进模型
8)提高任务的复杂度
9)增加模型规模以适应这种复杂的任务
微调任务和模型大小的权衡:
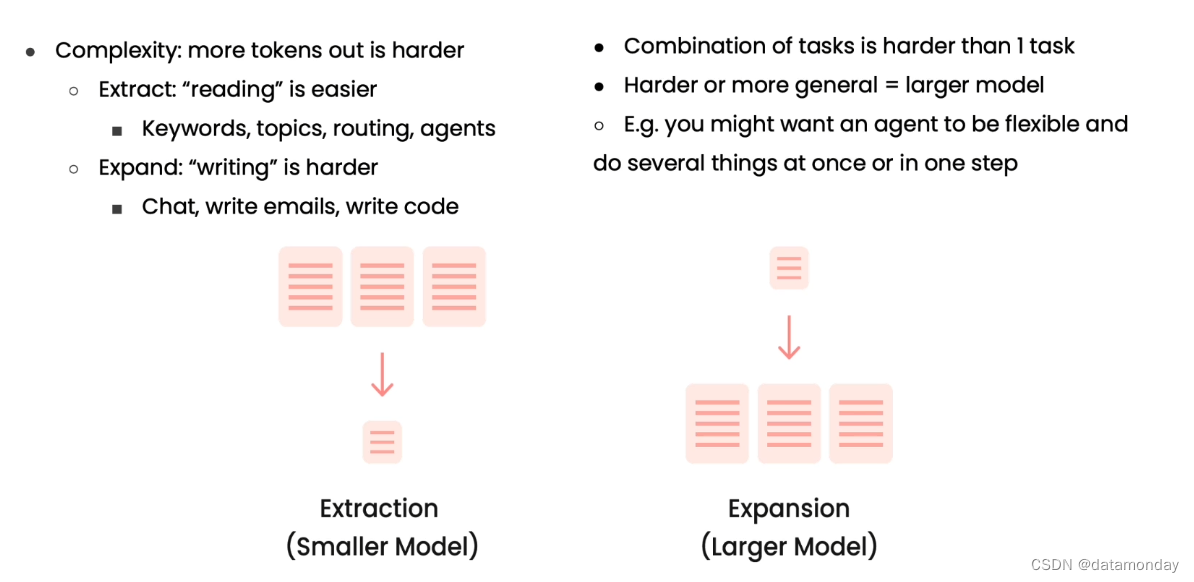
不同任务复杂度所需的模型大小:
参数高效微调方法 PEFT:
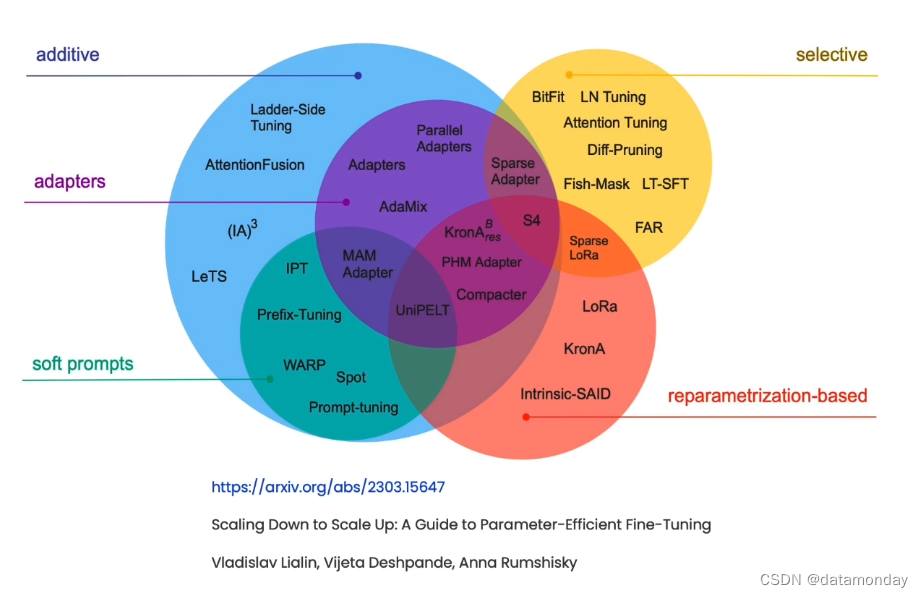
课程作者推荐使用低秩自适应(Low Rank Adaptation,LoRA):

LoRA的核心思想是冻结主要的预训练的权重(蓝色),在模型的部分层中训练新的权重(橙色)。新的权重是原始权重变动的秩分解矩阵。其优势是可以分别训练这些权重,然后与预训练的权重相结合,在推理时能将它们合并回主要的预训练权重,从而高效地得到微调模型。
Conclusion
该课程介绍了什么是微调,微调的作用和重要性。此外,还介绍了从数据准备到训练遭到评估模型的所有步骤。