ESDA in PySal (3):Geosilhouettes:集群拟合的地理测量
Silhouette statistics (Rousseeuw, 1987) 是观测值与给定聚类的拟合优度的非参数度量。 在聚类具有“地理”解释的情况下,例如当它们代表地理区域时,轮廓统计可以结合“空间思维”,以便提供更有用的聚类拟合度量。 Wolf、Knaap 和 Rey 的论文 (2019)。
(SocArXiv 上的预印本) 定义了两个:
- 路径轮廓,表征聚类中的联合地理和特征相似性。
- 边界轮廓,表征集群中地理边界的明确程度。
这两项新措施共同提供了测量地理数据科学中聚类问题中聚类拟合优度的新方法。
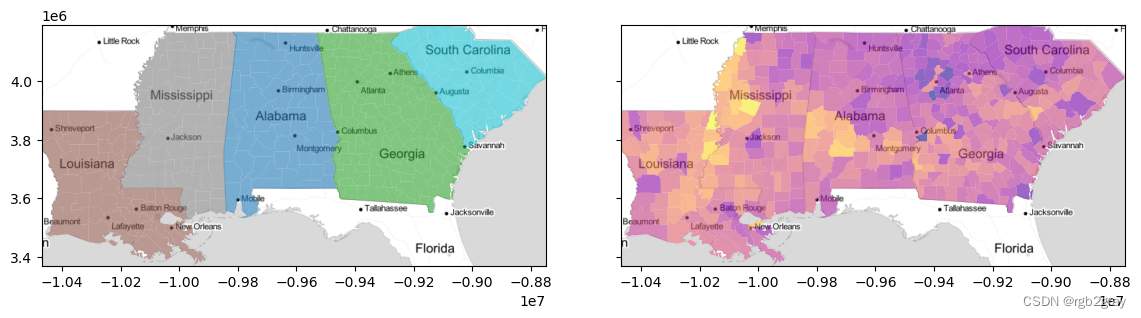
下面,我们将深入探讨这些是如何在“esda”包中实现的。 首先,让我们设置一些数据。 我们将考虑单个单变量数据集,即 1989 年美国南部腹地各县的基尼指数。
import libpysal
import numpy
import esda
import geopandas
import contextily
import matplotlib.pyplot as plt
%matplotlib inline
为了只关注南方腹地,我们将建立一系列位于南方腹地的州:
focus_states = ["Alabama", "Georgia", "Louisiana",
"Mississippi", "South Carolina"]
然后,我们将使用“libpysal”包中的示例数据集读取所有南部地区的数据:
south = libpysal.examples.example_manager.load('South')
south = geopandas.read_file(libpysal.examples.get_path('south.shp'))
然后,我们将仅过滤掉南部腹地的州:
deep = south.query('STATE_NAME in @focus_states').reset_index()
deep['state_label'] = deep.STATE_NAME.apply(lambda x: focus_states.index(x))
最后,出于绘图目的,让我们获取底图。 这是使用“contextily”包完成的,该包期望我们的数据位于特定的坐标投影系统中。 有关更多信息,请查看 contextily 用户指南。
deep.crs = {
'init':'epsg:4326'}
d:\work\miniconda3\envs\esda\lib\site-packages\pyproj\crs\crs.py:141: FutureWarning: '+init=<authority>:<code>' syntax is deprecated. '<authority>:<code>' is the preferred initialization method. When making the change, be mindful of axis order changes: https://pyproj4.github.io/pyproj/stable/gotchas.html#axis-order-changes-in-proj-6
in_crs_string = _prepare_from_proj_string(in_crs_string)
deep = deep.to_crs(epsg=3857)
basemap, extent = contextily.bounds2img(*deep.total_bounds, zoom=6,
source=contextily.providers.Stamen.TonerLite)
f,ax = plt.subplots(1,2, figsize=(12,3), sharex=True, sharey=True)
deep.plot('STATE_NAME', ax=ax[0], alpha=.6)
deep.plot('GI89', ax=ax[1], cmap='plasma', alpha=.6)
for ax_ in ax:
ax_.imshow(basemap, extent=extent, interpolation='bilinear')
ax_.axis(deep.total_bounds[[0,2,1,3]])
f.tight_layout()
plt.show()
1. The Silhouette Score
在分类/分组问题中使用的标准轮廓分数,用于衡量观察结果与其当前组的拟合程度。 该措施相当稳健,经过充分研究,并且在许多不同的问题领域都很常见。
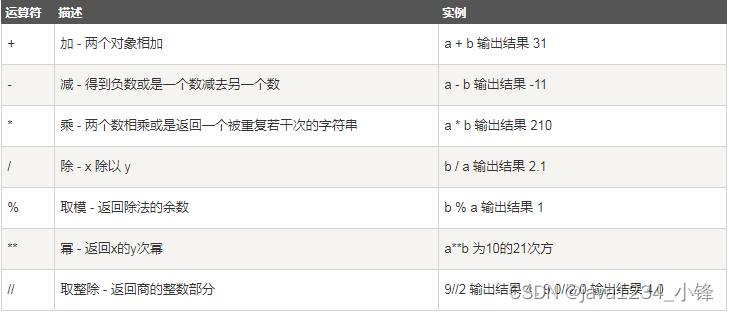
从统计上来说,轮廓得分由以下几个部分组成:
- c c c,分配 i i i的簇
- k k k,另一个当前未分配 i i i 的簇
- d i ( c ) d_i(c) di(c):观察值 i i i 和 i i i 自己的聚类 c c c 之间的差异
- d i ( k ) d_i(k) di(k):观察值 i i i 与 i i i 不在的聚类 k k k 之间的差异。
在这里,我们将 d d d 定义为任意相异度度量。 对于大多数情况,通常是欧氏距离。 因此,如果您看到 d i ( c ) d_i(c) di(c),则这是观察值 i i i 与集群 c c c 中所有其他观察值 j j j 之间的平均差异。
然后,我们需要定义第二最佳选择簇, k ^ \hat{k} k^,它是与 i i i 最相似的簇,但 i i i 当前不是其中的成员:
k ^ i = k ∣ min k { d i ( k ) } \hat{k}_i = k\ | \min_k \{d_i(k)\} k^i=k ∣kmin{
di(k)}
这让我们将轮廓分数定义为 i i i 与其聚类 c c c 以及 i i i 与第二最佳选择聚类







![CTF 全讲解:[SWPUCTF 2022 新生赛]webdog1__start](https://img-blog.csdnimg.cn/e7016e6fd4284eb0841346e36246766a.png)