🔗 运行环境:Matlab
🚩 撰写作者:左手の明天
🥇 精选专栏:《python》
🔥 推荐专栏:《算法研究》
#### 防伪水印——左手の明天 ####
💗 大家好🤗🤗🤗,我是左手の明天!好久不见💗
💗今天开启新的系列——重新定义matlab强大系列💗
📆 最近更新:2023 年 09 月 17 日,左手の明天的第 290 篇原创博客
📚 更新于专栏:matlab
#### 防伪水印——左手の明天 ####
histcounts——直方图 bin 计数
函数说明
[N,edges] = histcounts(X)
将 X 的值划分为多个 bin,并返回每个 bin 中的计数以及 bin 边界。histcounts 函数使用自动分 bin 算法,返回均匀宽度的 bin,这些 bin 可涵盖 X 中的元素范围并显示基本分布的形状。
[N,edges] = histcounts(X,nbins)
使用标量 nbins 指定的 bin 数量。
[N,edges] = histcounts(X,edges)
将 X 划分为由向量 edges 来指定 bin 边界的 bin。如果 edges(k) ≤ X(i) < edges(k+1),值 X(i) 位于第 k 个 bin 中。最后一个 bin 也包含 bin 的右边界,这样如果 edges(end-1) ≤ X(i) ≤ edges(end),它包含 X(i)。
[N,edges,bin] = histcounts(___)
还使用以前的任何语法返回索引数组 bin。bin 是大小与 X 相同的数组,其元素是 X 中的对应元素的 bin 索引。第 k 个 bin 中的元素数量是 nnz(bin==k),与 N(k) 相同。
N = histcounts(C)
(其中 C 是分类数组)返回向量 N,该向量指示 C 中其值等于 C 的各类别的元素的数量。C 中的每个类别在 N 中都有一个对应元素。
N = histcounts(C,Categories)
仅对 C 中其值等于由 Categories 指定的类别子集的元素进行计数。
举例
bin 计数和 bin 边界
将 100 个随机值分布到多个 bin 内。histcounts 自动选择合适的 bin 宽度以显示数据的基本分布。
X = randn(100,1);
[N,edges] = histcounts(X)
N = 1×7
2 17 28 32 16 3 2
edges = 1×8
-3 -2 -1 0 1 2 3 4指定 bin 数
将 10 个随机数分布到 6 个等间距 bin 内。
X = [2 3 5 7 11 13 17 19 23 29];
[N,edges] = histcounts(X,6)
N = 1×6
2 2 2 2 1 1
edges = 1×7
0 4.9000 9.8000 14.7000 19.6000 24.5000 29.4000指定 bin 边界
将 1,000 个随机数分布到多个 bin 内。通过向量定义 bin 边界,其中第一个元素是第一个 bin 的左边界,而最后一个元素是最后一个 bin 的右边界。
X = randn(1000,1);
edges = [-5 -4 -2 -1 -0.5 0 0.5 1 2 4 5];
N = histcounts(X,edges)
N = 1×10
0 24 149 142 195 200 154 111 25 0
归一化的 bin 计数
将小于 100 的所有质数分布到多个 bin 内。将 'Normalization' 指定为 'probability' 以对 bin 计数进行归一化,从而 sum(N) 为 1。即,每个 bin 计数代表观测值属于该 bin 的可能性。
X = primes(100);
[N,edges] = histcounts(X, 'Normalization', 'probability')
N = 1×4
0.4000 0.2800 0.2800 0.0400
edges = 1×5
0 30 60 90 120确定 bin 放置
将介于 -5 和 5 之间的 100 个随机整数分布到多个 bin 内,并将 'BinMethod' 指定为 'integers' 以使用以整数为中心的单位宽度 bin。指定 histcounts 的第三个输出以返回代表数据 bin 索引的向量。
X = randi([-5,5],100,1);
[N,edges,bin] = histcounts(X,'BinMethod','integers');通过计算数字 3 在 bin 索引向量 bin 中的出现次数求第三个 bin 的 bin 计数。结果与 N(3) 相同。
count = nnz(bin==3)
count = 8分类 bin 计数
创建一个表示投票的分类向量。该向量中的类别是 'yes'、'no' 或 'undecided'。
A = [0 0 1 1 1 0 0 0 0 NaN NaN 1 0 0 0 1 0 1 0 1 0 0 0 1 1 1 1];
C = categorical(A,[1 0 NaN],{'yes','no','undecided'})
C = 1x27 categorical
no no yes yes yes no no no no undecided undecided yes no no no yes no yes no yes no no no yes yes yes yes 确定每个类别中的元素数量。
[N,Categories] = histcounts(C)
N = 1×3
11 14 2
Categories = 1x3 cell
{'yes'} {'no'} {'undecided'}binscatter——分 bin 散点图
函数说明
binscatter(x,y)
显示向量 x 和 y 的分 bin 散点图。分 bin 散点图将数据空间分成多个矩形 bin,并用不同颜色显示每个 bin 中的数据点数。放大绘图时,bin 的尺寸会自动调整,以显示更清晰的分辨率。
binscatter(x,y,N)
指定要使用的 bin 数。N 可以是标量或二元素向量 [Nx Ny]。如果 N 是标量,则 Nx 和 Ny 都设置为标量值。每个维度中的最大 bin 数为 250。
举例
向量的分 bin 散点图
在 x 和 y 维上生成随机数,并创建分 bin 散点图。binscatter 函数会自动选择合适的 bin 数量,以便涵盖数据中的值范围。
x = randn(1e6,1);
y = 2*x + randn(1e6,1);
binscatter(x,y)
指定 bin 数
绘制包含 10,000 个随机数的分 bin 散点图,这些随机数划分到 x 维的 30 个 bin 和 y 维的 10 个 bin 中。
rng default % for reproducibility
x = randn(1e4,1);
y = randn(1e4,1);
h = binscatter(x,y,[30 10]);
求 bin 计数。结果是一个矩阵,其左上方的元素对应于绘图中左下方的 bin 计数。x 维上的 bin 对应于矩阵行,y 维上的 bin 对应于矩阵列。
counts = h.Values;更改分 bin 散点图的颜色图
创建一些随机数据点的分 bin 散点图。
x = randn(1e5,1);
y = randn(1e5,1);
binscatter(x,y)
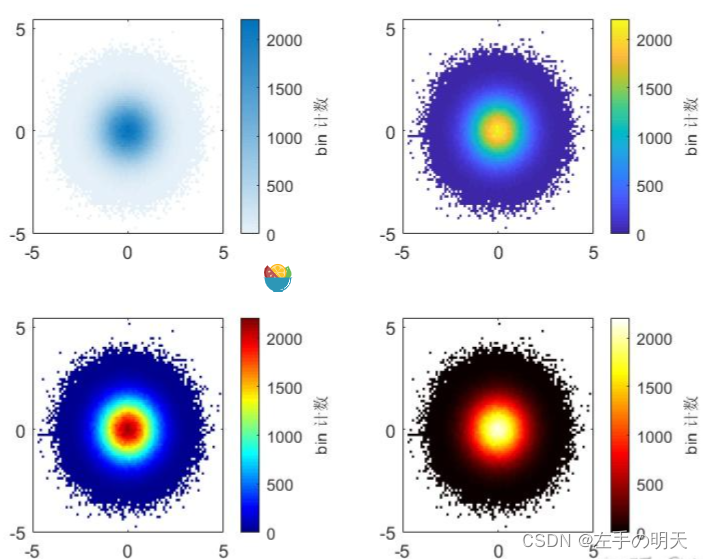
默认颜色图范围从浅色(小值)到深色(大值)。改用以深色表示小值的颜色图更容易发现离群值。
可以使用 colormap 函数更改绘图中的颜色。使用 gca 传入当前坐标区句柄。
colormap(gca,'parula')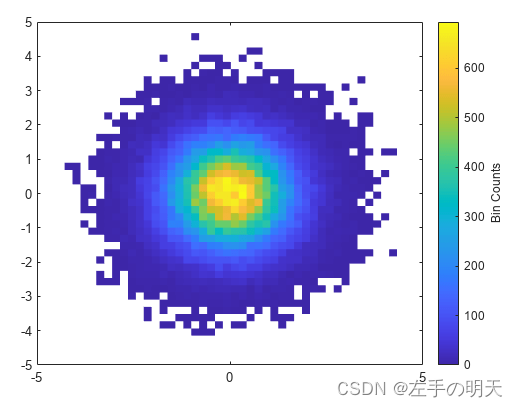
clc
clear all
close all
a = randn(1e6,1);
b = randn(1e6,1);
subplot(2,2,1)
b1 = binscatter(a,b);
axes2 = subplot(2,2,2);
b2 = binscatter(a,b);
colormap(axes2,'parula');
axes3 = subplot(2,2,3);
b3 = binscatter(a,b);
colormap(axes3,'jet');
axes4 = subplot(2,2,4);
b4 = binscatter(a,b);
colormap(axes4,'hot');