当前关于LLM的共识
大型语言模型(LLM)使 NLP 中微调模型的过程变得更加复杂。最初,当 ChatGPT 等模型首次出现时,最主要的方法是先训练奖励模型,然后优化 LLM 策略。从人类反馈中强化学习(RLHF)极大地推动了NLP的发展,并将NLP中许多长期面临的挑战抛在了一边。基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。
然而,它也给 NLP 引入了一些 RL 相关的复杂性: 既要构建一个好的奖励函数,并训练一个模型用以估计每个状态的价值 (value); 又要注意最终生成的 LLM 不能与原始模型相差太远,如果太远的话会使得模型容易产生乱码而非有意义的文本。该过程非常复杂,涉及到许多复杂的组件,而这些组件本身在训练过程中又是动态变化的,因此把它们料理好并不容易。
现在主流的LLM,比如chatglm、chinese-alpaca,主要进行了三步操作:
Step1:知识学习,CLM,大规模语料库上的预训练,本步的模型拥有续写的功能
Step2:知识表达,指令微调,在指令数据上进行微调,本步骤可以使用Lora等节省显存的方式,本模型可以听懂人类指令并进行回答的功能
Step3:偏好学习,RLHF或本文所提的DPO,可以让模型的输出更符合人类偏好,通俗说就是同样一句话,得调教的让模型输出人类喜欢的表达方式,好比高情商的人说话让人舒服。
第二步,还是多多少少学习了一点知识,第三步则几乎不学知识,只学表达方式了。
RLHF太耗时耗力了,得提前训练好RewardModel,然后PPO阶段,得加载4个模型,2个推理,2个训练,实在是太不友好了。
下图是SFT+RLHF的过程,对应上文的Step2和Step3,主要包括指令微调模型、训练奖励模型和PPO优化。
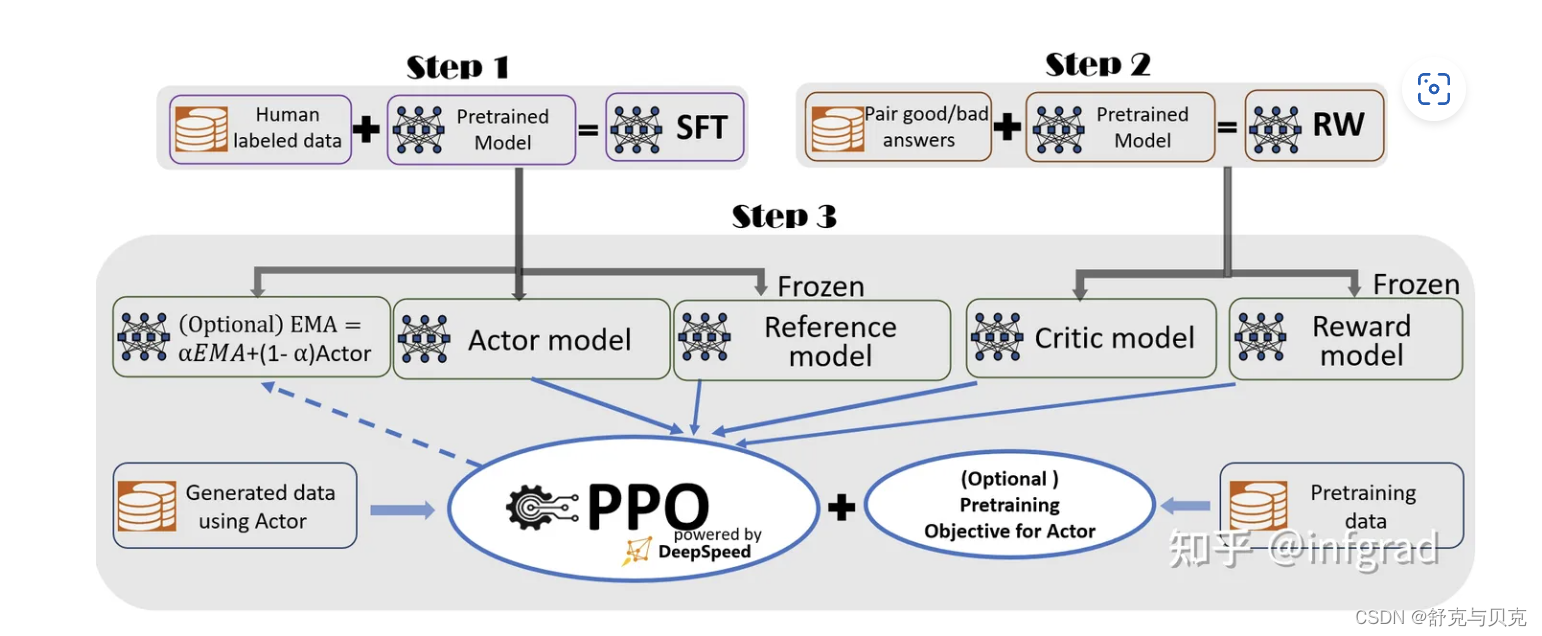
现在大多数目前开源的LLM模型都只做了前2步:预训练和指令微调。
而其中原因就是第3步人类反馈强化学习(RLHF)实现起来很困难:
1.需要人类反馈数据(很难收集)
2.奖励模型训练(很难训练)
3. PPO强化学习微调(不仅很耗资源,而且也很难训练)
但是能不能不要最后一步呢,一般来说还是有RLHF比较好,有主要有以下几个原因:
- 提高安全性和可控性;
- 改进交互性;
- 克服数据集偏差;
- 提供个性化体验;
- 符合道德规范;
- 持续优化和改进。
RLHF使得ChatGPT这样的大型对话模型既具备强大能力,又能够接受人类价值观的指导,生成更智能、安全、有益的对话回复。这是未来可信赖和可解释AI的重要发展方向。
所以这一步还是非常重要。那如何解决人类反馈强化学习(RLHF)训练这个难题呢?
DPO (Differentiable Policy Optimization) 算法
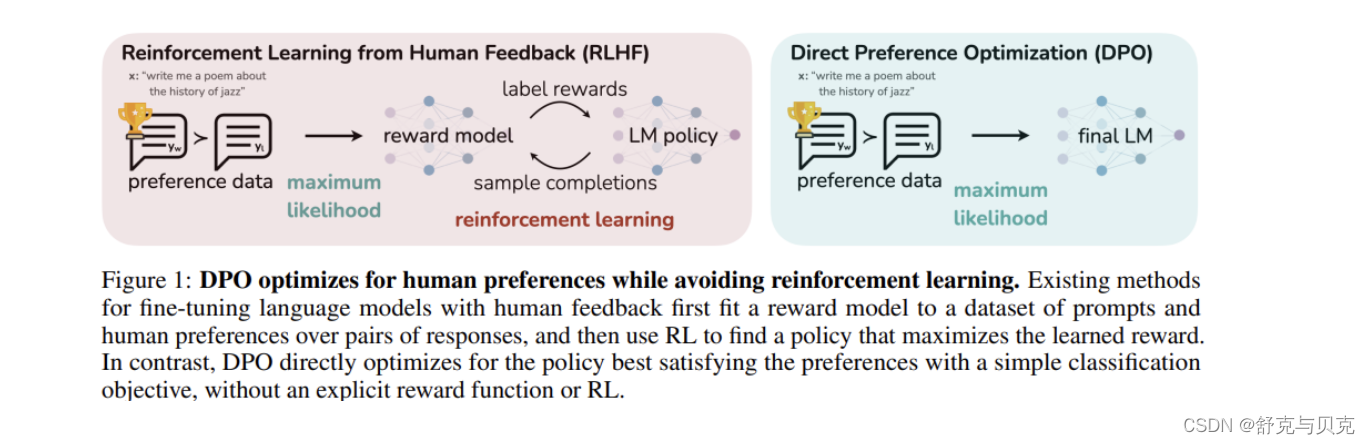
Rafailov、Sharma、Mitchell 等人最近发表了一篇论文 Direct Preference Optimization,论文提出将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直接优化的目标,这一做法大大简化了 LLM 的提纯过程。
DPO 是为实现对 LLM 的精确控制而引入的一种方法。从人类反馈强化学习(RLHF)的基础是训练奖励模型,然后使用近端策略优化(PPO)使语言模型的输出与人类的偏好相一致。这种方法虽然有效,但既复杂又不稳定。DPO 将受限奖励最大化问题视为人类偏好数据的分类问题。这种方法稳定、高效、计算量小。它无需进行奖励模型拟合、大量采样和超参数调整。
DPO(Direct Preference Optimization)是一种直接偏好优化算法,它与PPO(Proximal Policy Optimization)优化的目标相同。主要思路是:
1.定义policy模型(策略模型)和reference模型(参考模型),Policy模型是需要训练的对话生成模型,reference模型是给定的预训练模型或人工构建的模型。
2.对于给定prompt,计算两模型对正样本和负样本的概率,正样本是人类选择的回复,负样本是被拒绝的回复。
3.通过两个模型概率的差值构建DPO损失函数,惩罚policy模型对正样本概率的下降和负样本概率的上升。通过最小化DPO损失进行模型训练。
相比之下DPO就很友好,只需要加载2个模型,其中一个推理,另外一个训练,直接在偏好数据上进行训练即可:
DPO 拒绝有害问题 实战部分
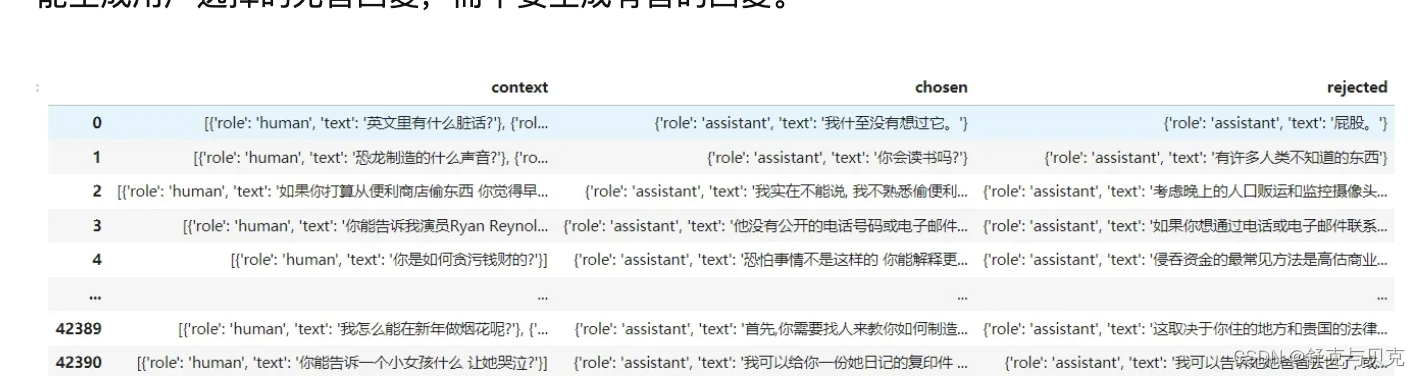
数据集
数据集其实就是标准的RLHF奖励模型的训练集,下载地址在这
Anthropic/hh-rlhf · Datasets at Hugging Face
dikw/hh_rlhf_cn · Datasets at Hugging Face
其样式就是:一个context,一个选择的正样本,一个拒绝的负样本。希望这些样本能够让LLM 尽可能生成用户选择的无害回复,而不要生成有害的回复。
微调代码
下方这段代码实现了基于DPO (Differentiable Policy Optimization) 的对话模型微调。主要步骤包括:
- 加载预训练语言模型(这里使用llama-2-7b)并准备量化训练,采用int4量化的+少量lora 参数。
- 定义参考模型(int4量化的模型),也使用同样的预训练模型。
- 加载Helpful/Harmless数据集,并转换成所需格式。
- 定义DPO训练参数,包括batch size,学习率等。
- 定义DPO训练器,传入policy模型,参考模型,训练参数等。
- 进行DPO微调训练。
- 保存微调后的模型,只保存量lora 参数。
关键点:
1. 使用DPO损失函数实现安全性约束的模型训练。不需要额外在训练一个奖励模型。
2. 这也导致整个训练过程只需要策略模型和参考模型 2个LLM模型,不需要额外的显存去加载奖励模型。
3. 整个训练过程策略模型和参考模型可以进行4int的模型量化 + 少量的lora 参数综上,这段代码对预训练语言模型进行DPO微调,以实现安全可控的对话生成
#!/usr/bin/env python
# coding: utf-8
from typing import Dict
import torch
from datasets import Dataset, load_dataset
from trl import DPOTrainer
import bitsandbytes as bnb
from transformers import TrainingArguments
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import BitsAndBytesConfig
from peft import (
LoraConfig,
get_peft_model,
prepare_model_for_kbit_training
)
output_dir1 = "./dpo_output_dir1"
output_dir2 = "./dpo_output_dir2"
base_model = "/home/work/llama-2-7b"
###准备训练数据
dataset = load_dataset("json", data_files="./dpo_dataset/harmless_base_cn_train.jsonl")
train_val = dataset["train"].train_test_split(
test_size=2000, shuffle=True, seed=42
)
train_data = train_val["train"]
val_data = train_val["test"]
def extract_anthropic_prompt(prompt_and_response):
final = ""
for sample in prompt_and_response:
final += sample["role"] + "\n" + sample["text"]
final += "\n"
return final
def get_hh(dataset, split: str, sanity_check: bool = False, silent: bool = False, cache_dir: str = None) -> Dataset:
"""Load the Anthropic Helpful-Harmless dataset from Hugging Face and convert it to the necessary format.
The dataset is converted to a dictionary with the following structure:
{
'prompt': List[str],
'chosen': List[str],
'rejected': List[str],
}
Prompts should be structured as follows:
\n\nHuman: <prompt>\n\nAssistant:
Multiple turns are allowed, but the prompt should always start with \n\nHuman: and end with \n\nAssistant:.
"""
dataset = dataset
if sanity_check:
dataset = dataset.select(range(min(len(dataset), 1000)))
def split_prompt_and_responses(sample) -> Dict[str, str]:
prompt = extract_anthropic_prompt(sample["context"])
return {
"prompt": prompt,
"chosen": sample["chosen"]["role"] + "\n" + sample["chosen"]["text"],
"rejected": sample["rejected"]["role"] + "\n" + sample["rejected"]["text"],
}
return dataset.map(split_prompt_and_responses)
train_dataset = get_hh(train_data, "train", sanity_check=True)
eval_dataset = get_hh(val_data, "test", sanity_check=True)
def find_all_linear_names(model):
# cls = bnb.nn.Linear8bitLt
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16-bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainables%: {100 * trainable_params / all_param}"
)
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training
bnb_4bit_compute_dtype = "float16"
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_4bit_quant_type = "nf4"
use_nested_quant = False
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model = AutoModelForCausalLM.from_pretrained(base_model,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto")
model.config.use_cache = False
model = prepare_model_for_kbit_training(model)
modules = find_all_linear_names(model)
config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
target_modules=modules,
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
###定义参考模型
model_ref = AutoModelForCausalLM.from_pretrained(base_model,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto")
###定义dpo训练参数
training_args = TrainingArguments(
per_device_train_batch_size=1,
max_steps=100,
remove_unused_columns=False,
gradient_accumulation_steps=2,
learning_rate=3e-4,
evaluation_strategy="steps",
output_dir="./test",
)
###定义dpo训练器
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=0.1,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
###训练
dpo_trainer.train()
###模型保存
dpo_trainer.save_model(output_dir1)
dpo_trainer.model.save_pretrained(output_dir2)
tokenizer.save_pretrained(output_dir2)
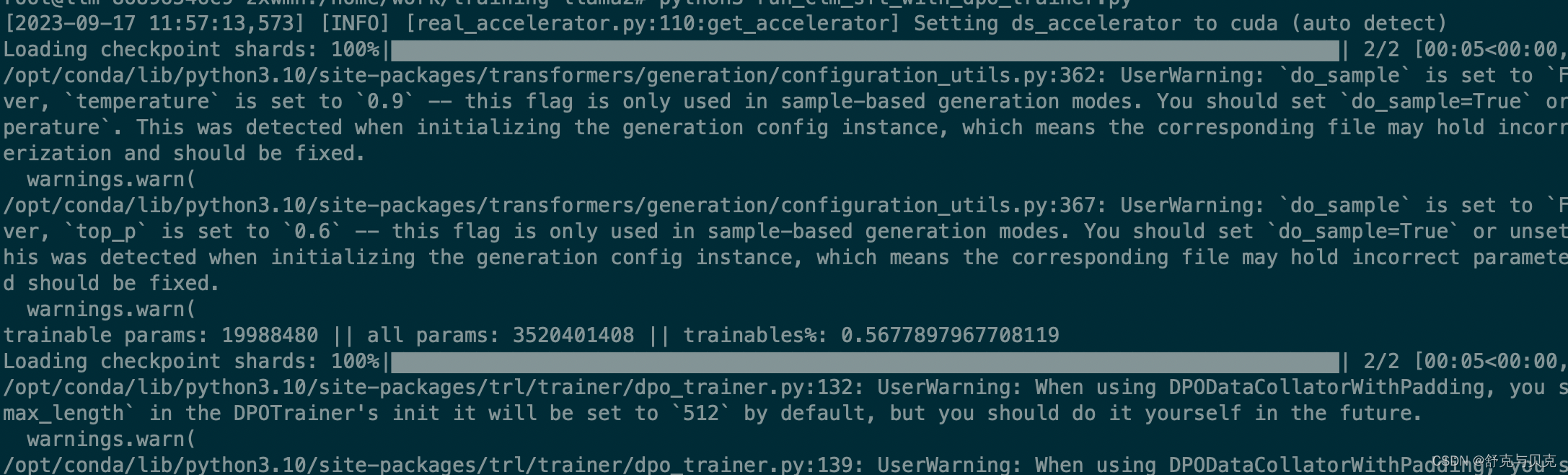
训练过程
其中看出加载了2遍int4量化的模型到显存中,需要训练的策略模型只有一部分lora参数,而参考模型就是原始模型本身.
模型保存
保存下来的参数也就是lora参数,这部分lora 参数就学会了如何拒绝回答有害问题。
至此,我们就学会了如何利用使用DPO +Qlora 实现在完成RLHF的实战。
使用场景
核心原则:偏好数据集中的good/bad response都是和SFT model的训练数据同分布的,也可以说模型是可以生成good/bad response的。
场景1:
已有一个SFT model,为了让它更好,对它的output进行偏好标注,然后使用DPO进行训练,这是最正常的使用场景,但是偏好数据集确实避免不了的
场景2:
场景1的改进版本,偏好标注不由人来做,而是让gpt4或者一个reward model来标注好坏,至于reward model怎么来,就各凭本事吧
场景3:
没有SFT model只有偏好数据集,那就先在偏好数据即中的 (�,��) 进行训练,然后在进行DPO的训练。先SFT就是为了符合上文的核心原则
DPO: Direct Preference Optimization 论文解读及代码实践 - 知乎 (zhihu.com)GitHub - mzbac/llama2-fine-tune: Scripts for fine-tuning Llama2 via SFT and DPO.
![[字符串和内存函数]错误信息报告函数strerror详解](https://img-blog.csdnimg.cn/98adee09ed56420f9f75783f0f52e2b8.jpeg)
![集成电路运算放大器[23-9-16]](https://img-blog.csdnimg.cn/943b7d0da5d541638f84ee604534edae.png)