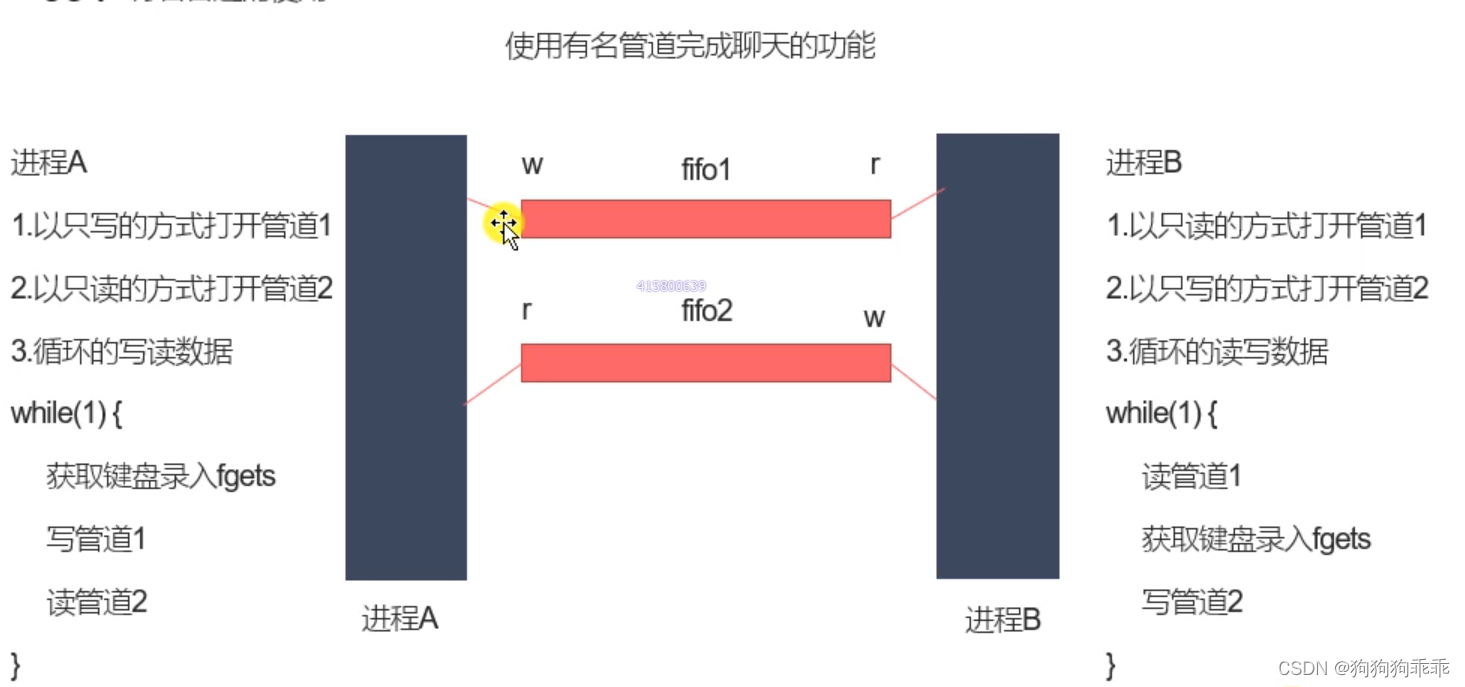
经过学习我们已经大致的学会了vim的使用,可以利用vim进行代码的编写了,在学习c语言的时候我们就知道,编译完成一个代码需要进行四个步骤:
那么在Linux下是如何进行的呢?
通过vim进行代码的编写,通过gcc/g++进行代码的,预处理,编译,汇编链接。
目录
1.Linux编译器-gcc/g++使用
1.什么是gcc?
2. gcc如何实现
预处理(进行宏替换)
编译(生成汇编)
汇编(生成机器可识别代码)
连接(生成可执行文件或库文件)
动静态库的理解与概念
3.Linux项目自动化构建代码
1.make/Makefile是什么?
2.伪目标
3.文件的三个时间属性
4.Makefile的自动推导
5.语法扩展
1.Linux编译器-gcc/g++使用
1.什么是gcc?
GCC(GNU Compiler Collection)是GNU工具链的关键组件,是与GNU、Linux相关项目的标准编译器。它最初仅用于处理C语言,紧接着扩展到C++、Objective-C/C++、Fortran、Java、Go等编程语言。GCC是一个可移植的编译器,支持多种硬件平台,例如ARM、X86等等。GCC不仅是个本地编译器,它还能跨平台交叉编译。
明白了gcc是一个最初 编译c语言的编译器,我们对于g++也就知道是对c++的编译器。
2. gcc如何实现
预处理(进行宏替换)
编译(生成汇编)
汇编(生成机器可识别代码)
连接(生成可执行文件或库文件)
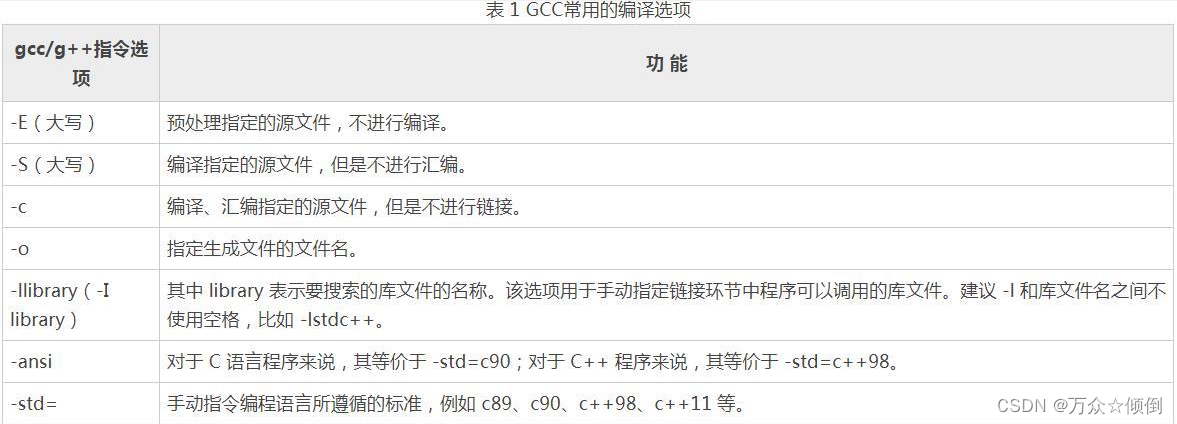
-E指向到.i文件完成预处理,-S指向到.s文件实现编译,-c指向到.o文件实现汇编, gcc 加.o文件指向到一个文件 ,最后该文件就是可执行文件。利用./加载到内存中,就可以看到编译的最终结果。
动静态库的理解与概念
在了解之前我们先了解什么是函数库?
在最后链接的过程中:
1.我们现在所写的所有代码都是站在巨人的肩旁上,已经有人帮我们已经写好了对应的接口(函数),即各种函数库。
2.我们知道头文件在哪里,我们可以找到头文件的所在地,那么那些实现方法的函数库又在哪里呢?

我们可以利用ldd指令(可以查找可执行程序所依赖的第三方库)来查找相对应的函数库,.

可以看到它是会依赖一个lib64/libc.so.6的函数库:

可以总结出,在安装软件的时候,系统就已经帮我们安装的乐对应的各种函数库并将它放在特定的路径底下。
头文件提供方法的声明,库文件提供方法的实现




注意:默认情况下我们的云服务器并不会有静态库的,只有动态库,如有需要则可以安装
c的静态库:
sudo yum isntall glibc-static c++的静态库:
sudo yum install -y libstdc++ -static3.Linux项目自动化构建代码
在我们用vs写代码时,由于是集成开发工具,包含了对代码一条龙服务的功能,预处理+编译+汇编+链接,但在linux下我们对文件汇编后再接链接要去生成一个重定向的可执行程序,最后在./调用,如果是很多个文件呢,如此操作,太过麻烦,且生成太多的文件我们无从下手,那么如何去将这些文件规划整理呢?
1.make/Makefile是什么?
make:是一个命令符
makefile是一个在当前目录下存在的具有特定格式的文本文件。
对于Makefilede
那么如何去使用呢:
1.首先我们创建一个makefile(名字必须保证是这个,首字母可大写)文件,之后vim打开这个文件
,在此里面写我们要写对应可执行程序的名字,我们这里以一个code.c文件为例:
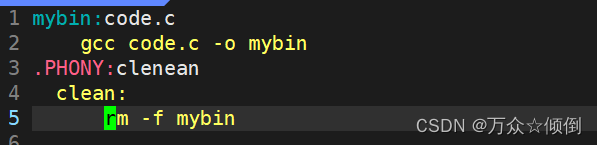
注意:这是makefile的语法格式,对于一个指令的编写:第一行我们称之为依赖关系,第二行我们称之为依赖方法。我们不能更改它的格式。
第一行写入生成可执行程序名,这里我写入为mybin,冒号和后面接.c文件
第二行先按以下TAB键,而不是四个空格,之后我们gcc编译文件并重定向我们所要给的名字。
这样前两行就完成了一个make的脚本指令。
编译后之后,因为代码在编译错之后改正后重新执行时,我们需要删掉之前生成的可执行程序来重新生成这里我们会引入一个新语法.PHONY。
2.伪目标
.PHONY叫做伪目标,.PHONY修饰clean后,clean就是一个伪目标文件,依赖关系可以为空,依赖方法为rm -f mybin
目标文件与其他文件差不多,只不过被PHONY修饰后,增加了一个特点:它总是被执行。
之后我们保存退出,同时使用make clean 指令,可以看到他会执行我们在其中写入的指令.
对于makefile,在调用时,自顶向下扫描,如果遇到第一个目标文件,他会直接执行相关指令。
3.文件的三个时间属性
为了提高编译效率,需要注意的是make是不会允许重复编译我们的文件,这是它特有的,如下:
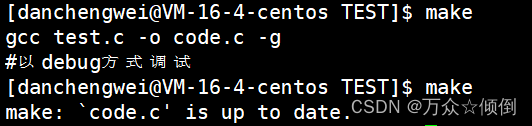
那这是如何做到的呢,这应该取决于文件的属性--文件的修改时间,可是一个文件的时间怎么就确定了它是旧还是新文件,时间是在增长的,故还是需要去对比。那么和谁去对比呢?理所应当源文件应该和生成的可执行文件的时间来对比,我们可以知道源文件的修改时间时肯定小于生成可执行文件,若文件修改了,则新的时间大于可执行文件的时间,故通过对比两文件时间,确定是否还需要去编译。但有的文件,因为历史问题,修改时间也不会重新编译,需要删除可执行文件才能重新编译。
那么如何去查看一个文件的时间信息?
stat 文件名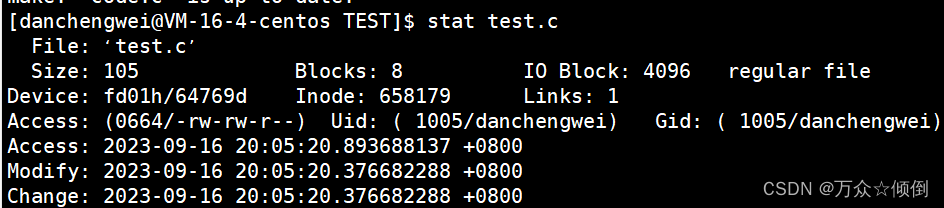
我们可以看到文件的基本属性,尤其是这三个文件的时间:
Acess:访问文件的时间(包括打开文件,修改文件等)只要被访问,就会被重新记录。
Modify: 修改文件内容的时间(包括删除,增加),修改文件内容时所记录的时间。
Change:修改文件属性的时间(包括文件大小,权限,时间等),只要被修改,就会记录。
我们知道文件=内容+属性,但对于这里的Change,更改Modify与Acess也会更改Change,换言之,这里的内容修改与访问修改本质上是属性修改的一部分。
当然这里编译时看的就是modify,其次我们自己也可以手动更改时间:
touch -a 文件名 //更改access time
touch -m 文件名 //更改modify time 修改为当前时间通过时间对比,我们可以让代码可以一直被或者不被执行,而PHONY总会被执行,就是不被时间影响,我们可以在makefile中给我们的指令做.PHONY修饰是的可以被一直操作,不受影响。
4.Makefile的自动推导
对于make/Makefile是具有依赖性的自动推导能力的,比如:



可以看到,我们直接写的编译.o文件,运行时可以执行,而我们最初是没有.o文件的,我们也没让它生成.o文件,由此判断make是具有自动推导能力的,根据我们的需要自动补充改文件。
完整的应该是这样:
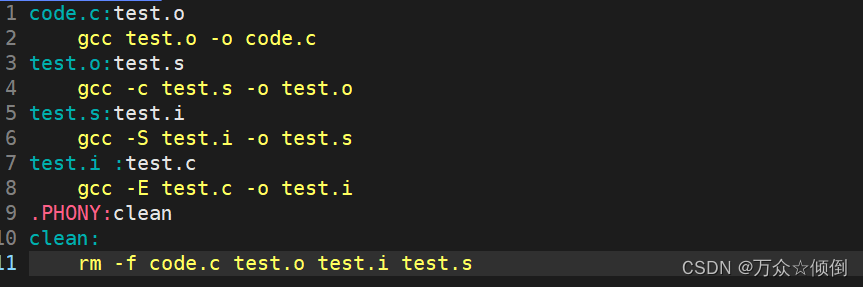
5.语法扩展
1.通过添加@符号,使得执行命令时不打印依赖方法
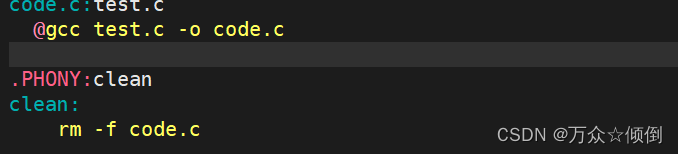
make时不再打印gcc test.c -o code.c。
利用这点可以编写一些信息,例如echo不会打印这条指令,执行时打印其中内容,编写信息时更加简洁。
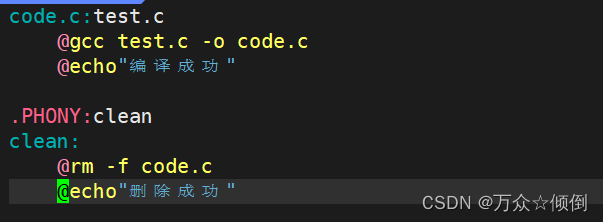
2.利用#注释

3.可编写变量
我们可以理解通过编写变量实现和宏一样的替换效果。
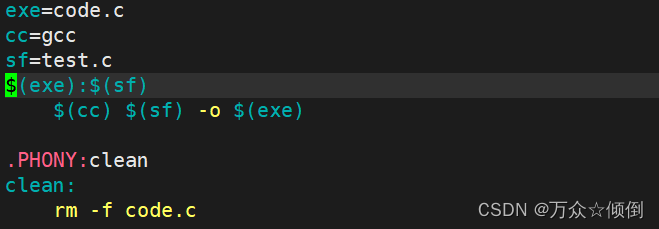
这段代码的效果和上面的效果一样
4.依赖关系与依赖方法的简写
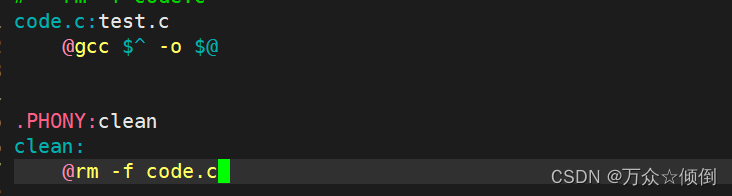
因为在依赖关系中已经指明了目标文件与源文件,故此可以利用$^代替源文件,使用$@表示目标文件。