Hbase:HBase 底层原理详解(深度好文,建议收藏) - 腾讯云开发者社区-腾讯云
Hbase架构图

同一个列族如果有多个store,那么这些store在不同的region
Hbase写流程(读比写慢)

MemStore Flush

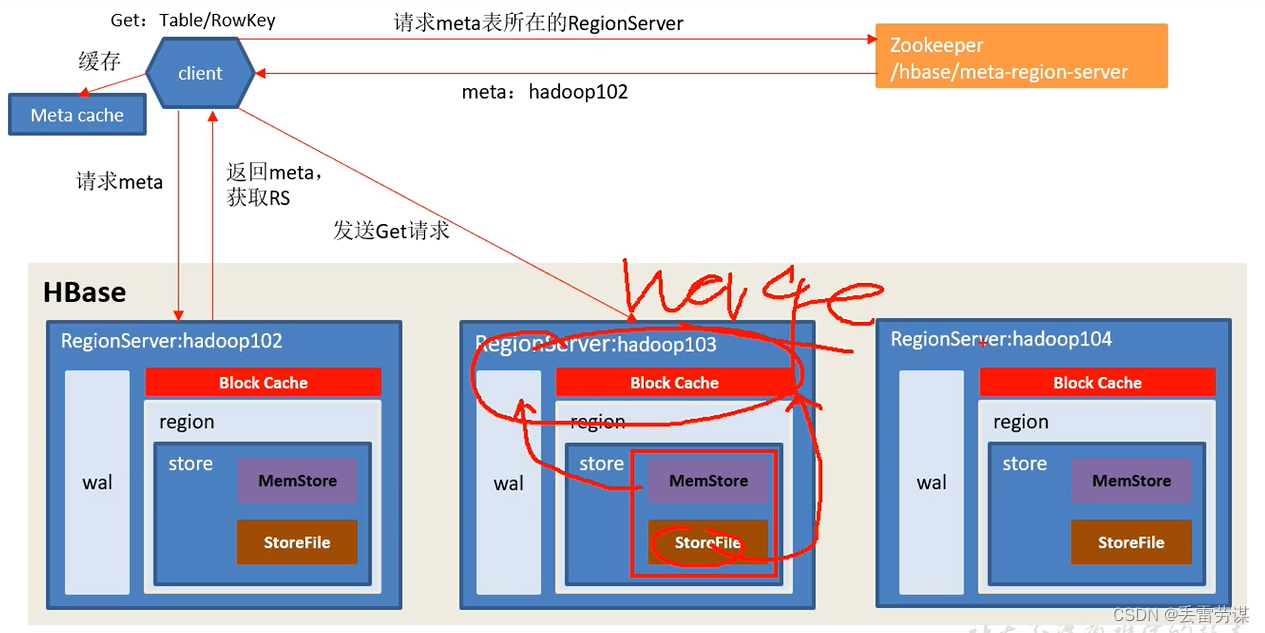
Hbase读流程:
先读block Cache,若命中了结果,则不读磁盘;若没有命中结果,那么同时读MemStore(内存)和StoreFile(磁盘),将从磁盘读取的结果放到内存(Block Cache)中,然后和从MemStore读取结果进行merge(比较时间戳返回最新数据)
Compact操作:
该操作非常消耗资源,一般关闭该操作的自动执行。有需要的话,手动执行。
数据真正的删除时机:
Flush时会删数据,合并文件时会删除数据。
HBase 不直接操作文件,而是通过 HDFS(Hadoop Distributed File System)进行数据存储。因此,HBase 中的数据删除并不涉及直接删除底层文件。相反,HBase 通过维护一系列称为“HFile”的底层数据文件来管理数据。
当执行删除操作时,HBase 实际上是将删除标记(Tombstone)写入相应的 HFile 中。这个删除标记会告诉 HBase 在查询时跳过这些被标记为删除的数据。随着时间的推移,HBase 会定期进行合并(compaction)操作,将多个 HFile 合并为更大的文件,并在此过程中清理掉已经被标记为删除的数据块。
由于合并操作是由 HBase 自动触发和处理的,因此具体删除标记从被写入到实际清理的时间会有一定的延迟。这个延迟取决于多个因素,包括表的负载、合并策略以及系统配置等。
总之,HBase 中删除数据的时间可以说是异步的,并且受到 HBase 的自动合并和清理机制的影响。根据具体的情况,可以通过调整 HBase 的合并策略和配置参数来控制删除操作对存储空间的影响和清理速度。
Split操作:
split时机:
HBase 的拆分(split)是根据一定的策略和条件自动触发和执行的。以下是一些常见的 HBase 拆分时机:
-
Region 大小超过设定的阈值:HBase 监测每个 Region 的大小,并在某个 Region 的大小超过预设的阈值(称为 split size)时触发拆分。这个阈值可以通过配置参数进行设置,通常以字节数或行数来表示。
-
基于 Region 数量的拆分:当集群中的 Region 数量达到了预设的最大 Region 数量时,HBase 可能会触发拆分操作。这是一种基于负载均衡的策略,确保数据在不同的 RegionServer 上更加均匀地分布。
-
定期拆分:HBase 还可以按照一定的时间间隔或频率定期执行拆分操作。这样可以避免 Region 过大导致查询性能下降,同时也有助于数据的均衡分布。
-
手动触发拆分:除了自动触发,HBase 还支持手动触发拆分操作。管理员可以通过 HBase Shell 或 API 来手动指定需要拆分的 Region,以满足特定的需求。
需要注意的是,拆分操作是一个比较昂贵的操作,可能会对系统产生一些开销。因此,拆分的时机需要谨慎选择,避免过于频繁或不必要的拆分操作。可以通过定期监测和调整配置参数来优化拆分策略,以适应具体的业务需求和系统负载情况。
Split流程:
在 HBase 中,split(拆分)是指将一个大的 Region 拆分成多个较小的子 Region 的过程。这个过程是自动进行的,由 HBase 系统根据一定的策略和条件触发和执行的。
下面是 HBase 的拆分流程概述:
-
监测 Region 大小:HBase 运行时会监测每个 Region 的大小。当一个 Region 的大小超过了预设的阈值(称为 split size),就会被标记为需要拆分。
-
触发拆分:一旦有一个或多个需要拆分的 Region 被标记,HMaster(HBase 的主节点)会收到这些拆分请求,并决定如何进行拆分操作。
-
拆分策略:HBase 提供了两种拆分策略:按行键范围拆分和按 Region 数量拆分。
-
按行键范围拆分:HBase 将会根据 Region 当前的行键范围,计算出新的行键范围并生成新的子 Region。
-
按 Region 数量拆分:HBase 将会根据当前 Region 的数量和预设的最大 Region 数量,将一个大的 Region 均匀地拆分成多个子 Region。
-
-
创建新的子 Region:根据选定的拆分策略,HBase 会创建新的子 Region,并将其分配给适当的 RegionServer 进行处理。
-
数据拷贝:新的子 Region 在创建后会开始从父 Region 拷贝数据。这个过程可能需要一些时间,具体取决于数据量和系统的负载情况。
-
更新元数据:拆分完成后,HBase 会更新相应的元数据(例如 .META. 表)以反映新的子 Region 的信息和位置。
整个拆分流程是自动进行的,并且由 HBase 系统根据配置和内部算法来管理和执行。拆分操作可以使数据在集群中更均衡地分布,提高系统的性能和可扩展性。