修改 nginx 纯属巧合,任务是将 reuseport 的支持换一种方式。目前 nginx 的方式是 master 创建 worker 数量个 reuseport listening socket,由 worker 继承。在这种实现方式下,效果是 “所有 worker 可以处理所有 listening socket”
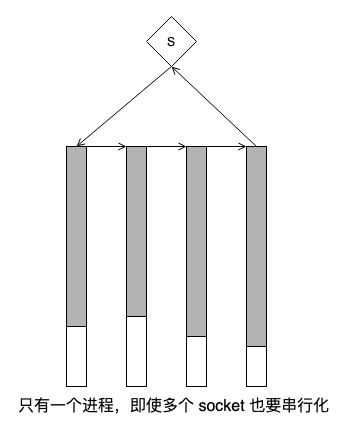
这不就是典型的全相联结构吗?挺好,但因不符合我们的依赖模型,不得不将 socket 的创建移到每一个 worker 中,因此,每一个 worker 只能看到自己创建的 socket,这是一一映射结构,在服务器/消费者模型中显然没有全相联结构更 “好”(好字要额外解释)。
再次牵涉到多队列还是单队列(超市收银台倾向右边,银行大厅倾向左边,为什么?):
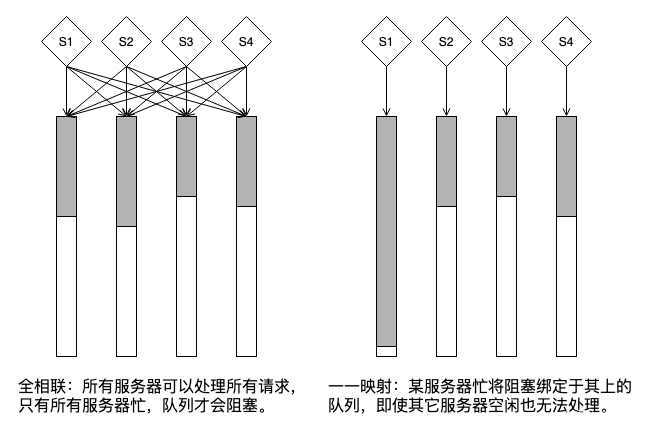
至于组相联,介于二者间,在组内全相联,组间一一映射。
这些惯常知识很重要但不是本文的重点,本文先讲个历史,再说个理念。
我将 nginx 从全相联改成一一映射属实开历史倒车,因为最开始 nginx 引入对 reuseport 的支持时就采用了一一映射的方式,最初的 patch:Initial SO_REUSEPORT support
但最终采用了全相联结构:
Socket Sharding in NGINX Release 1.9.1
RE: [Patch] SO_REUSEPORT support from master process
nginx reuseport 经历了从一一映射到全相联的过程,我给改回去了。但在最初的 patch 中还有个细节,作者没谈但应该已意识到。
该 patch 为每一个 worker 创建了 worker 个 listening socket,但没有必要,且平添 socket 结构的维护开销:
于是我又改了一下,在 ngx_open_listening_sockets 里的 for 循环遍历 listening socket 的开头加入下语句:
if (ls[i].sockaddr->sa_family == AF_INET &&
ls[i].type == SOCK_STREAM &&
worker != -1 && ls[i].worker != (ngx_uint_t)worker) {
continue;
}
ngx_configure_listening_sockets 同理,保持每一个 worker 仅持有一个 listening socket。
但这里是不是一个引入组相联的好契机呢?如:

我想是的,我要是编程编得好,应该能就这个点做一个类似 apache mem 的框架,把所有相联结构都引入,nginx 就成了 apache-like,并且,显然 nginx 牛叉的地方是异步 epoll(关于 epoll 机制,我曾写过一篇文章还不错:再谈Linux epoll惊群) 而不是 master/worker 模型,加入 mpm 岂不如虎添翼。
这引出一个理念。要分清什么才是资源。可落实到实际处理逻辑的硬件才是资源,软件只是为了易于管理资源,不是资源。这是一个反云原生的说辞,但正因为这样才有必要单独拿出来说,因为云原生的理念在抽象的道路上越走越远,我这里倒过来说。
容器不是资源,进程不是资源,线程不是资源,协程不是资源,socket 不是资源,它们只是 “虚拟层”,只有 CPU 核才是资源。是 CPU 在处理连接报文,而不是进程或线程在处理 socket。
将所有连接在所有 CPU 上调度,自然而然就是一个全相联结构。至于进程,线程,协程,socket 这些抽象层,其威力在工程,生产力和生态,而非性能,当你觉得事情错综复杂时,“加一个层解决”,但加一个层势必影响性能。
去年那篇 It’s Time to Replace TCP in the Datacenter 中,作者提到 TCP 不宜多核心发挥优势,TCP 明确串行处理,无法发挥并行优势。按上述理念理解,根因在于 TCP 也是一个抽象层。故,抽象不是解决问题的手段,而是问题产生的原因。
关于 TCP 的问题,回到本文第一幅图,看右边,TCP 是个一一映射结构的抽象。
要么把逻辑装进 task(各种 x 程),托管给系统调度,要么自己调度,总之都是调度,不同的是,托管费省不了,task 内存开销,task 切换的 CPU 开销,无论创建多少 task,可同时运行的也不超过 CPU 核数(再次强调,task 不是资源,CPU,内存才是),挂起的 task 就是纯消耗资源,比如 TCP 连接的 CPU 开销,不活跃长连接的内存开销。有人想直触 CPU,有人想自研传输协议,都一回事,绕开抽象层。
一路向下越过所有抽象层,一直触碰到实际硬件资源,就在那个层面上调度。反之,将会产生过度设计,用尽各种 “x 程”,将系统人为喂胖,典型的为了一碟醋包了一顿饺子。
回到 nginx。
即使 nginx worker 和 连接报文全相联,还是有 gap,因为 worker 是一个进程抽象而不是 CPU 本身。进程的粒度是一条一直执行到睡眠等待的指令流,而 CPU 的粒度是指令,这是一个和 TCP 一样的问题。如果所有 worker 都睡眠在文件 IO 上,所有 CPU 都会 idle,即使这样这些 CPU 也无法处理到达 socket 的数据,因为没有任何进程在 socket 上等待。
解决方案似乎回到了传统 mpm,多创建几个进程,在其它进程等待其它事件时,总有一些进程等待 socket,但这无非是在利用统计学,代价也大:
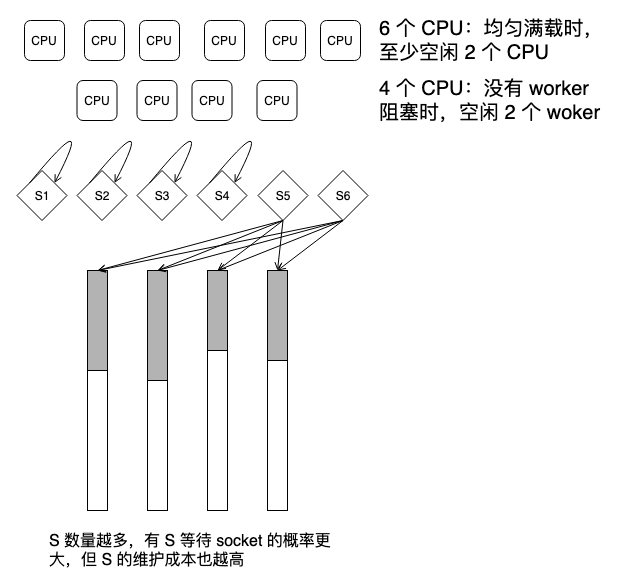
CPU 的粒度为指令,理论上一个 worker 的粒度无限接近指令粒度就 OK,因此要为 worker 选择一个足够小的粒度,那就以 worker 的睡眠等待作为分割边界咯。以下是一个例子。
以 CPU 数量为依据创建数量固定的 worker,将 worker 分类,每类若干实例,保证每类 worker 只在一个点等待,比如第一类 worker 只等待文件 IO,第二类 worker 只等待 socket,第三类 worker 只处理数据等等,总之执行程足够短,足够小,就能最大化效能:

剩下的交给统计学,不要绑核。大概协程就有点这个意思,看似回到了 mpm 的设计原点,但这回抓住了本质。
full-mesh 结构是好的,被认为硬件成本过高而取而代之以各种折中方案,对于软件虚拟结构,full-mesh 的成本可低到被忽略,它和全相联是一回事。
当然,上图这么复杂的结构显然涉及很多锁,远不如 nginx worker 简洁高效,但这显然是实现问题而非架构问题了,显然上图的全相联(full-mesh)结构的可扩展性更强。
理解了资源的本质,再辅以抽象思想,就彻底解决了 “三高” (高并发,高性能,高可用)问题。画完最后一幅图后,想起了 wireguard-go,于是我删掉了协程绑定 channel 的代码,统计学比我更了解系统。
皮鞋没有蹬上,露着白袜子。
浙江温州皮鞋湿,下雨进水不会胖。