文章目录
- 一、启动耗时统计
- printk time
- initcall_debug
- bootgraph
- bootchart
- gpio+示波器
- 二、内核优化方法
- kernel压缩方式
- 加载位置
- 内核裁剪
- 预设置lpj数值
- initcall优化
- 内核initcall_module并行
- 减少pty/tty个数
- 内核module
- 三、其他优化
- uboot
- XIP
- 四、总结
要对Linux系统启动速度进行优化,首先要知道如何统计系统启动的时间。
下面介绍几种统计内核启动耗时的方法,以及对内核启动速度优化的几个方法。
一、启动耗时统计
printk time
打开kernel配置:
kernel hacking --->
[*] Show timing information on printks
打开后,每个printk的前面都会显示时间戳
主要用来测量内核启动过程各个阶段的耗时
initcall_debug
众所周知,kernel启动时会执行不同等级的initcall,而每个initcall的耗时也是可以统计的。
在kernel的cmdline中加入参数initcall_debug=1:
initcall_debug=1
setargs_nand=setenv bootargs console=${console} earlyprintk=${earlyprintk} root=${nand_root} initcall_debug=${initcall_debug} init=${init}
开启后,就能打印每个initcall函数调用及耗时。
bootgraph
内核自带了一个工具用于统计启动时间:scripts/bootgraph.pl
使用该工具需要打开内核配置CONFIG_PRINTK_TIME=y,并且在cmdline中加上"initcall_debug=1"
系统启动之后,执行命令:
dmesg|perl $(kernel_dir)/script/bootgraph.pl > out.svg
用浏览器查看out.svg文件,可以看到内核启动过程中各个阶段的耗时。
这个工具有点类似于perf的火焰图,可以统计启动各阶段的耗时。
bootchart
除了内核自带的工具,也有开源的工具可用:bootchart。
bootchart是一个用于linux启动过程性能分析的开源软件工具,在系统启动过程自动收集CPU占用率、进程等信息,并以图形方式显示分析结果,可用作指导优化系统启动过程。
- 修改
kernel cmdline。将其中的init修改为“init=/sbin/bootchartd”。 - 收集信息。
bootchartd会从/proc/stat,/proc/diskstat,/proc/[pid]/stat中采集信息,经过处理后保存为bootchart.tgz文件 - 转换图片。在
pc上通过pybootchartgui.py工具将bootchart.tgz转换为bootchart.png,方便分析
最后也会成图片供做分析,例如:
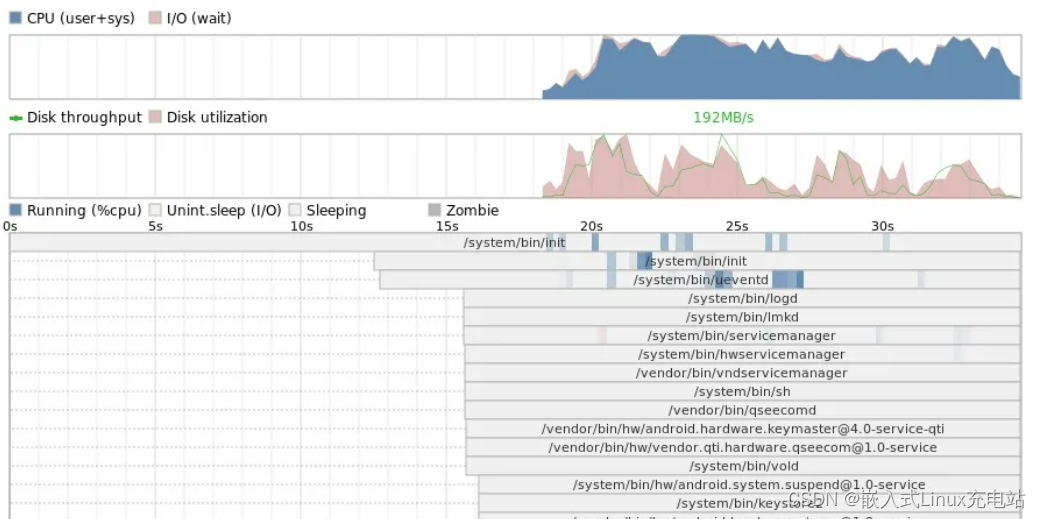
bootchar主要用来测量挂载文件系统到主应用程序启动过程中的耗时
gpio+示波器
可以找一个在系统启动过程中空闲的GPIO,在适当位置设置GPIO电平。
通过示波器抓取波形可以得到各阶段耗时。
通常该方法被用来测量整个启动的耗时,或者各阶段的耗时,该方法也是用的比较多的。
二、内核优化方法
kernel压缩方式
kernel有不同的压缩格式,常见的如gz、xz、lzma等。
不同的压缩格式,解压速度就不同,通过比较不同压缩方式的启动时间和flash占用情况,选择一种符合实际情况的,以此进行优化。
加载位置
内核镜像可以由kernel自解压,也可以由uboot进行解压。
对于kernel自解压的情况,如果压缩过的kernel与解压后的kernel地址冲突,则会先把自己复制到安全的地方,然后再解压,防止自我覆盖。这就需要耗费复制的时间。
即把加载地址和运行地址设置为不同地址,可以减少耗时。
内核裁剪
裁剪内核是必要的,如果内核镜像太大,那么解压内核就需要很长时间,所以内核要尽量裁剪。
裁剪内核,可以减少解压耗时。初始化内容少了,也会减少耗时。
因此裁剪内核时,要考虑将不需要的功能都去掉。
预设置lpj数值
LPJ也就是loops_per_jiffy,每次启动都会计算一次,但如果没有做修改的话,这个值每次启动算出来都是一样的,可以直接提供数值跳过计算。
如下log所示,有skipped,lpj由timer计算得来,不需要再校准calibrate了。
[ 0.019918] Calibrating delay loop (skipped), value calculated using timer frequency.. 48.00 BogoMIPS (lpj=240000)
如果没有skipped,则可以在cmdline中添加lpj=xxx进行预设
initcall优化
如前面提到initcall耗时是可以打印出来的,在cmdline中设置initcall_debug=1,即可打印跟踪所有内核初始化过程中调用的顺序以及耗时。
[ 0.021772] initcall sunxi_pinctrl_init+0x0/0x44 returned 0 after 9765 usecs
[ 0.067694] initcall param_sysfs_init+0x0/0x198 returned 0 after 29296 usecs
[ 0.070240] initcall genhd_device_init+0x0/0x88 returned 0 after 9765 usecs
[ 0.080405] initcall init_scsi+0x0/0x90 returned 0 after 9765 usecs
[ 0.090384] initcall mmc_init+0x0/0x84 returned 0 after 9765 usecs
根据打印信息,可以对耗时较多的initcall进行优化。
内核initcall_module并行
initcall有很多等级,但比较耗时的是module。
如果是多核,可以考虑将module_initcall并行执行来节省时间。
目前内核do_initcalls是一个一个按照顺序来执行,可以修改成新建内核线程来执行
减少pty/tty个数
加入initcall打印之后,发现pty/tty init耗时很多,可减少个数来缩短init时间。
initcall pty_init+0x0/0x3c4 returned 0 after 239627 usecs
initcall chr_dev_init+0x0/0xdc returned 0 after 36581 usecs
内核module
只把必须要加进内核的才编译进内核,其他的编译成模块。
例如将必要的clock、tty、pinctrl等编译进内核
三、其他优化
uboot
如果是RISC-V架构,可以考虑去掉uboot。
XIP
xip:eXecute In Place。即芯片内执行,是指CPU直接从存储器中读取程序代码执行,而不用再读到内存中。
一般我们的程序都是放到flash中,系统启动时,把程序从flash拷贝到ddr中执行,而xip技术则不需要拷贝程序到ddr,所以速度会很快。这项技术是必须要芯片支持才行,可以看看芯片手册中对SPI的描述是否支持XIP功能。
四、总结
以上对系统启动速度的优化,归根结底是提供一些思路、一些方法。
要优化启动速度,通常来说需要对整个系统的启动有比较深入的了解。
优化无止境,需要根据目标来进行优化,综合考虑启动速度和效果。