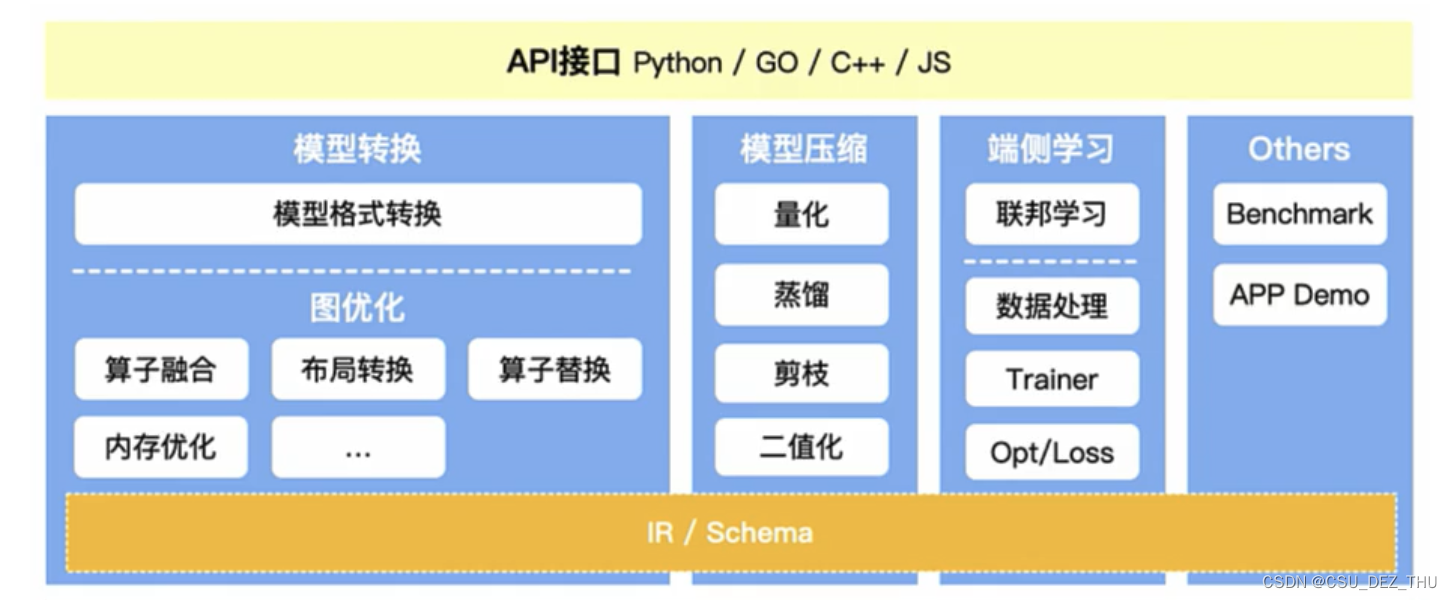
在推理引擎架构中,API 接口下来就是模型转换,狭义的模型转换是指将各种框架的模型转换为统一的格式,即模型格式转换;广义的模型转换则还包括图优化部分,因为不同的框架提供的算子不同,且类型太多,存在优化空间。
一、广义模型转换的挑战
1.1 格式转换的挑战
-
AI 框架算子的统一。AI 模型本身包含众多算子,特点是它们的重合度高但不完全相同,而推理引擎需要用有限的算子去实现不同框架的算子。
-
支持不同框架的模型文件格式。主流的 Tensorflow、PyTorch、Keras 等框架导出的模型文件格式不同,而且同一框架的不同版本间也存在算子的增改。
-
需要支持 CNN、RNN、Transformer 等主流网络结构。不同网络结构有各自擅长的领域,CNN 常用于图像处理、RNN 适合处理序列数据、Transformer 则适用于自然语言处理领域。
-
需要支持各类输入输出,如多输入多输出,任意维度的输入输出,动态输入,带控制流的模型等。
前两点挑战可以通过抽象出推理引擎自己的 IR 实现,而第三点需要推理引擎提供 Benchmark 以比较不同结构的效果。第四点挑战主要是对可扩展性提出挑战。

1.2 优化部分的挑战
优化的挑战其实就是模型的优化空间,受制于端侧或云部署的有限资源,对训练好的模型进行优化是必不可少的,主要可以从以下四个方面优化。
- 结构冗余:深度学习网络模型结构中的无效计算节点、重复的计算子图、相同的结构模块,可以在保留相同计算图语义的情况下去除的冗余类型。
- 精度冗余:推理引擎数据单元是张量,一般为 Float32,它在某些场景中存在冗余,可压缩到 Float16、Int8 甚至更低。还有如大量的连续0或重复数据。(模型压缩的工作)
- 算法冗余:算子或 Kernel 层面的实现算法本身存在计算冗余,例如拉普拉斯卷积核和均值平滑卷积核,它们都有对某像素点周围的范围内像素的求和操作,只不过拉普拉斯卷积核是直接将求和结果作为新的像素值,而均值平滑卷积核是求其平均值。
- 读写冗余:在一些计算场景中重复读写内存,或内存访问不连续导致无法充分利用硬件缓存。 —> 内存分配优化、数据排布优化。
二、模型转换(Converter)的架构
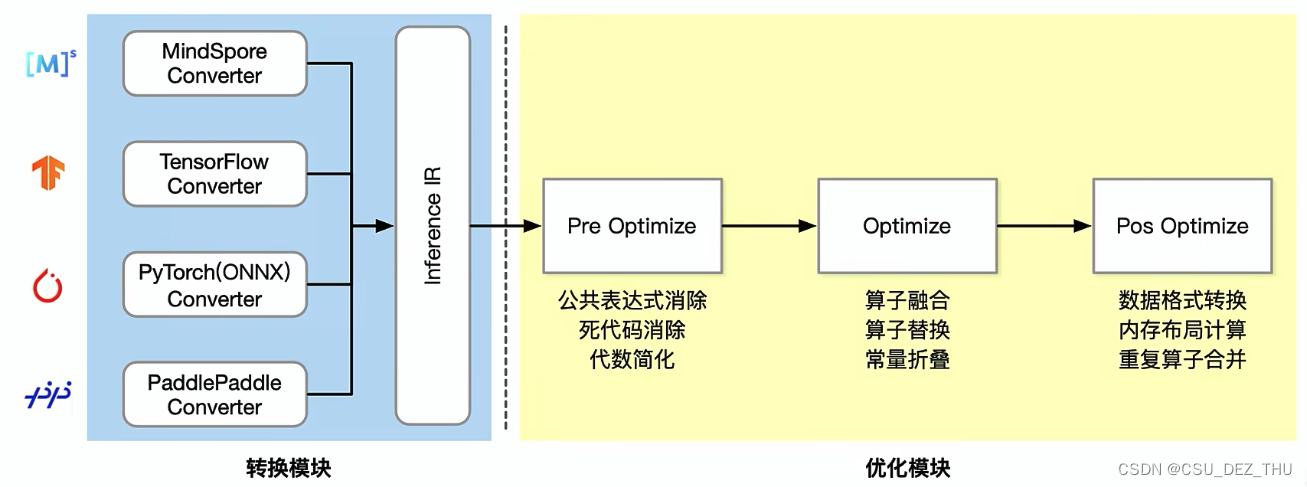
广义的模型转换包括格式转换和优化模块,下图的蓝色部分就是格式转换,右图的黄色部分是优化模块。将不同的模型转换为统一的 IR 来描述,之后的优化部分可以再细分为三步骤:
- 预优化,主要是语法上的检查,如消除死代码、简化代数和消除公共表达式。
- 优化,主要是对算子的处理,如算子融合、算子替换和常量折叠。
- Pos Optimize,主要是对读写冗余的优化,如内存布局计算、数据格式转换和重复算子合并等。