声明:这只是浅显的一个小试验,且借助了AI。使用的是jupyter notebook,所以代码是一块一块,从上往下执行的
知识点:正则删除除数字和字母外的所有字符、高频词云、混淆矩阵
参考:使用python和sklearn的中文文本多分类实战开发_文本多标签分类 用二分类器做 python 数据集中文_-派神-的博客-CSDN博客
数据:【免费】初步的文本多分类小实验资源-CSDN文库
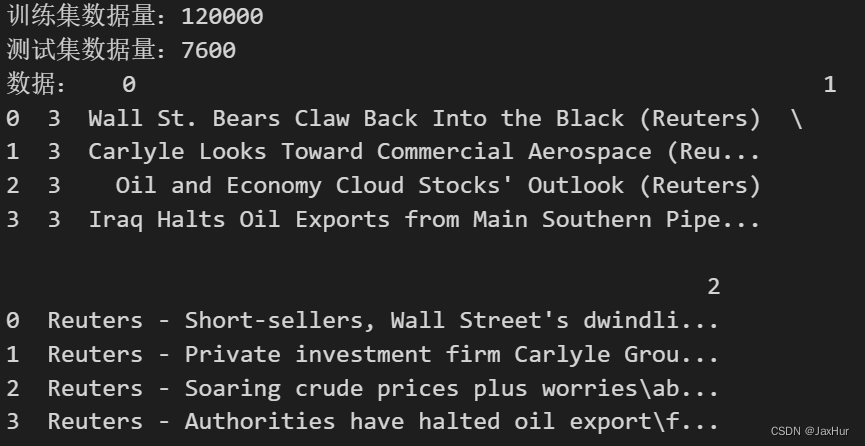
数据介绍:训练集train.csv中有120000条数据,测试集test.csv中有7600条数据。两个文件中记录的是新闻,均只有3列,第1列记录了新闻的种类(world,sports,sci/Tech,Business,记录与class.txt中),总共有4类[3,4,2,1],且每一类的占比均为25%;第2列记录了新闻标题,第3列记录了新闻的大致内容。
数据总体情况
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re # 正则匹配
plt.rcParams['font.sans-serif'] = ['STKaiTi']
plt.rcParams['axes.unicode_minus']=False
# 数据的情况
dfTrain = pd.read_csv('train.csv',header = None)
dfTest = pd.read_csv('test.csv',header = None)
print(f'训练集数据量:{len(dfTrain)}')
print(f'测试集数据量:{len(dfTest)}')
print(f'数据:{dfTrain.head(4)}')
数据预处理
空值与重复值
没有空值与重复值
# 检查是否有空值
print(f'数据情况{dfTrain.info()}')
print(f'第1列空值:{dfTrain.iloc[0].isnull().sum()}')
print(f'第2列空值:{dfTrain.iloc[1].isnull().sum()}')
print(f'第3列空值:{dfTrain.iloc[2].isnull().sum()}')
# 重复值分析与处理
print(f'重复值:{dfTrain.duplicated(keep=False).sum()}')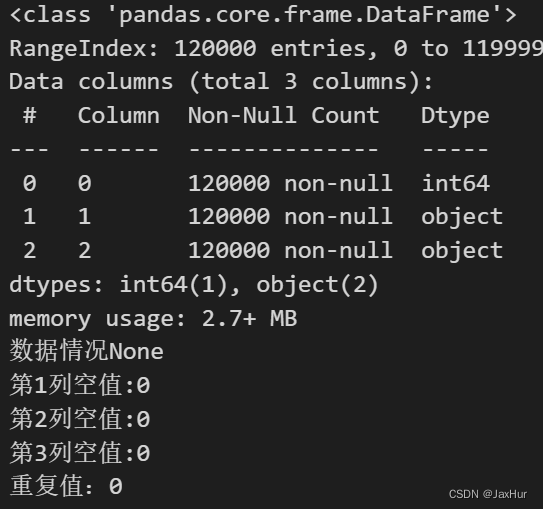
重命名列名
由于数据中没有列名,所以,读取的时候header=None(见第一段pd.read_csv),为了操作的方便,添加列名['category','title','content']。
# 列重命名
dfTrain.columns = ['category','title','content']
dfTest.columns = ['category','title','content']删除除数字和英文的所有字符
为了展示出高频词的词云以及后续的处理,这里使用正则表达式删除数据中第2、3列中除数字和字母外的所有字符,且各词汇之间采用空格切分。
# 在a-z A-Z 0-9范围外的字符替换为空格字符
def remove_punctuation(text):
cleaned_text = re.sub(r'[^a-zA-Z0-9]', ' ', text)
return cleaned_text
# 删除除数字和英文的所有字符
dfTrain['title'] = dfTrain['title'].apply(remove_punctuation)
dfTest['title'] = dfTest['title'].apply(remove_punctuation)
dfTrain['content'] = dfTrain['content'].apply(remove_punctuation)
dfTest['content'] = dfTest['content'].apply(remove_punctuation)补充
我这个试验只采用了第2列title的内容,没有用第3列content 里的内容,预测精度会有所下降。
这里呢其实还是可以有其他操作的。比如将第2列和第3列合并成新的一列,然后用新的一列作为输入。还可以删除英文里面的停用词,减少无意义的高频词。
不同分类对数据进行可视化
# 训练集种类
print(f'种类:{dfTrain.iloc[:,0].unique()}')
# 训练集各类别数据量
d= {'类别':dfTrain['category'].value_counts().index,'数量':dfTrain['category'].value_counts()}
Num = pd.DataFrame(data = d).reset_index(drop = True)
# 柱状图
plt.figure(1,figsize = (10,6),dpi = 400)
plt.title('训练集类别数据量',fontsize = 15) # 标题
labels = ['World','Sports','Business','Sci/Tech']
colors = ['skyblue', 'green', 'orange','red']
plt.bar(labels,Num['数量'], width=0.6,color=colors)
# 添加数据标签
for i in range(len(Num)):
plt.text(labels[i], Num['数量'][i]+0.01, f'{Num["数量"][i]}', ha='center',rotation = 0,fontsize = 15)
plt.xlabel('种类',fontsize = 15)
plt.ylabel('数量',fontsize = 15)
plt.show()
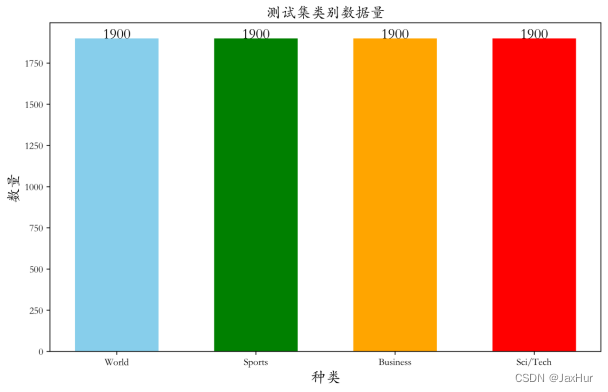
# 测试集种类
print(f'种类:{dfTest.iloc[:,0].unique()}')
# 测试集各类别数据量
d2= {'类别':dfTest['category'].value_counts().index,'数量':dfTest['category'].value_counts()}
Num2 = pd.DataFrame(data = d2).reset_index(drop = True)
# 柱状图
plt.figure(2,figsize = (10,6),dpi = 400)
plt.title('测试集类别数据量',fontsize = 15) # 标题
labels = ['World','Sports','Business','Sci/Tech']
colors = ['skyblue', 'green', 'orange','red']
plt.bar(labels,Num2['数量'], width=0.6,color=colors)
# plt.xlabel(Num['类别'])
# 添加数据标签
for i in range(len(Num2)):
plt.text(labels[i], Num2['数量'][i]+0.05, f'{Num2["数量"][i]}', ha='center',rotation = 0,fontsize = 15)
plt.xlabel('种类',fontsize = 15)
plt.ylabel('数量',fontsize = 15)
plt.show()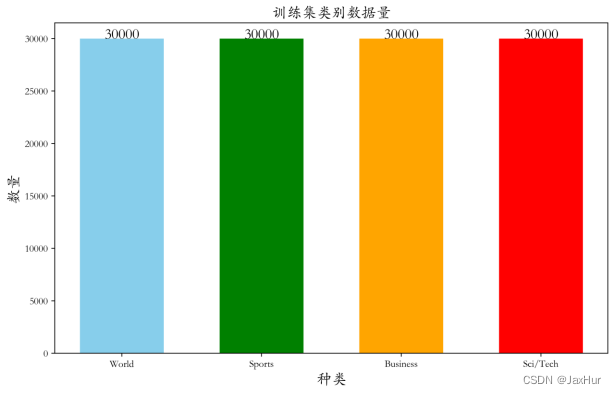
高频词词云
画出训练集中,4种分类的新闻标题的top10的高频词云,需要借助wordcloud库
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import defaultdict
# 创建一个存储每个类别文本的字典
category_text = defaultdict(str)
# 将每个类别的文本合并到对应的字典项中
for category, sentence in zip(dfTrain['category'], dfTrain['title']):
category_text[category] += sentence + ' '
# 生成词云图像并绘制
for category, text in category_text.items():
wordcloud = WordCloud(width=800, height=400,max_words=10, background_color="white").generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.title(f'Word Cloud for Category {category}',fontsize = 30)
plt.axis("off")
plt.show()
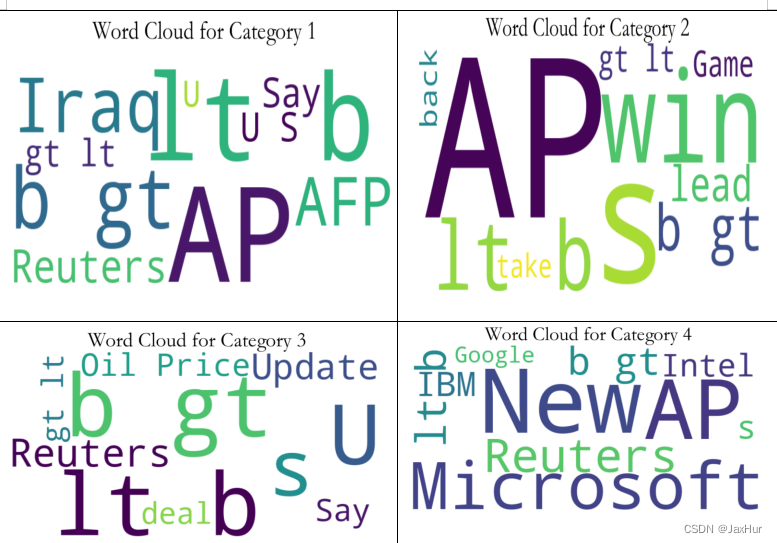
根据我们事先的得知的数字与类别的对应关系:1-World,2-Sports,3-Business,4-Sci/Tech,观察每种类别的高频词云图,可以看出对于world,常出现诸如Iraq、US等国家名称,对于Sports类,常出现Win,Game等相关词汇,对于Business类,常出现deal,oil,price等相关词汇,对于Sci/Tech类,常出现MicroSoft,Intel等相关词汇。因此,每一类的高频词云是符合当前类的特征的。
模型预测
思路:为了能使模型能够对文本进行预测,首先需要使用TF-IDF向量化器进行文本特征提取(至于原理什么的,我不知道,AI生成的)。然后再次基础上借助预测模型进行多分类预测,在训练集中训练,测试集中测试
使用朴素贝叶斯
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 划分x,y
X_train = dfTrain['title']
X_test = dfTest['title']
y_train = dfTrain['category']
y_test = dfTest['category']
# 文本特征提取,使用词袋模型
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# 训练朴素贝叶斯分类器
clf = MultinomialNB()
clf.fit(X_train_vec, y_train)
# 预测
y_pred = clf.predict(X_test_vec)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# 输出分类报告
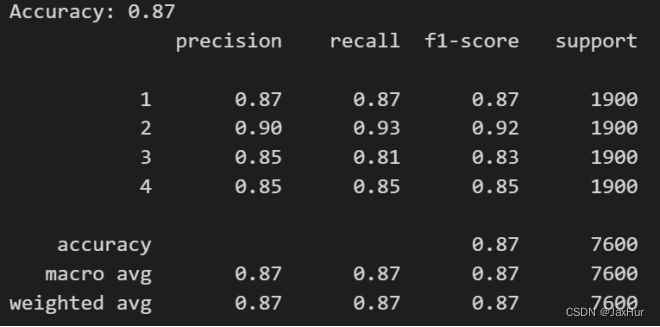
print(classification_report(y_test, y_pred))下图为朴素贝叶斯的预测结果,总体的预测准确率为0.87。但是对于不同类别的预测效果也不同,可以看出朴素贝叶斯对类别2的预测效果最好的,精确度、召回率、f1分数均能达到0.9以上
画出混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵
plt.figure(figsize=(8, 6),dpi = 400)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=clf.classes_, yticklabels=clf.classes_)
plt.xlabel('预测')
plt.ylabel('实际')
plt.title('混淆矩阵')
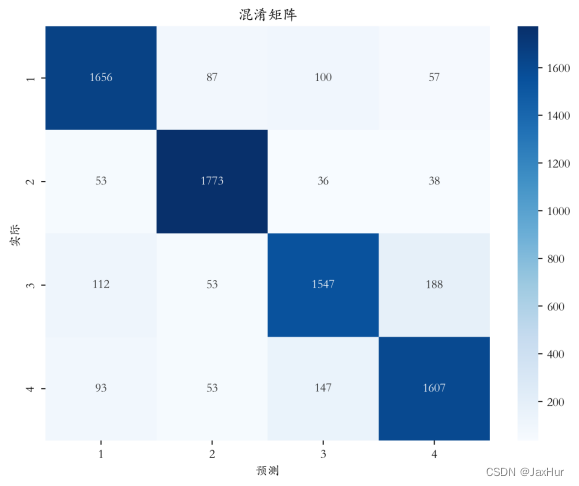
plt.show()下图为朴素贝叶斯预测的混淆矩阵。可以看出对于朴素贝叶斯模型来说,容易将第1类错误预测为第3类,第2类错误预测为第1类,第3类错误预测为第1、4类,第4类错误预测为第3类。




![[管理与领导-96]:IT基层管理者 - 扩展技能 - 5 - 职场丛林法则 -10- 七分做,三分讲,完整汇报工作的艺术](https://img-blog.csdnimg.cn/a3dfdab67f38429fa509890817156731.png)