面相面试知识–Lottery项目
1.设计模式
- 为什么需要设计模式?
(设计模式是什么?优点有哪些?)
- 设计模式是一套经过验证的有效的软件开发指导思想/解决方案;
- 提高代码的可重用性和可维护性;
- 提高团队合作开发效率;
- 为了项目开发的代码更加具有可扩展性和灵活性,提高程序开发的效率,而提出了基于×××等原则的一些程序/项目设计模式。
- 设计模式的原则?
- 开放封闭原则Open-Closed Principle:对修改关闭,对扩展开放。是设计模式原则的总纲。其他的设计模式原则都是该总纲的具体实现。(父类没有实现的功能,不要直接在此修改,在子类中实现新功能,并调用子类的方法来使用。)软件实体应该在不修改原有代码基础上做扩展。
面向对象编程在开发时都要强调开放封闭原则。- 单一职责原则Simple Responsibility Principle:每个类应该实现单一的职责,否则应该拆分。如果一个类的功能过多,会很臃肿,复用性也比较差。
- 里氏替换原则Liskov Substitution Principle:使用父类的地方都能使用子类来替换;子类的所有方法必须在父类中声明。在定义时,尽量用父类对对象进行声明,在使用时用子类进行方法调用,比如定义为animal对象,用dog.eat()或者cat.eat()调用方法,类似于java的多态。子类能够替换父类而不产生异常。
- 依赖倒置原则Dependence Inversion Principle:自上而下的设计原则;对接口编程,依赖于抽象,而不依赖于具体,面向接口编程。
- 接口隔离原则Interface Segregation Principle:一个类对另一个类的依赖应该建立在最小的接口上。一个类不应该依赖他不需要的接口,每个接口不应该存在其子类不需要的方法,否则要将接口拆分。多个专门的接口好于一个通用的接口
参考视频:谈谈设计模式6大原则
- 常用/使用过的设计模式有哪些?
- 单例模式:确保一个类只有一个实例存在,并且自行实例化并向整个系统提供这个实例。
那么,这个类不能在外部被初始化,因此构造方法应该是private的;
该类自行实例化,那么其构造方法以及相关成员变量要是static的,以在编译阶段自行生成。
单个的实例为整个系统提供服务,则需要一个静态方法,作为外界访问该实例的入口。
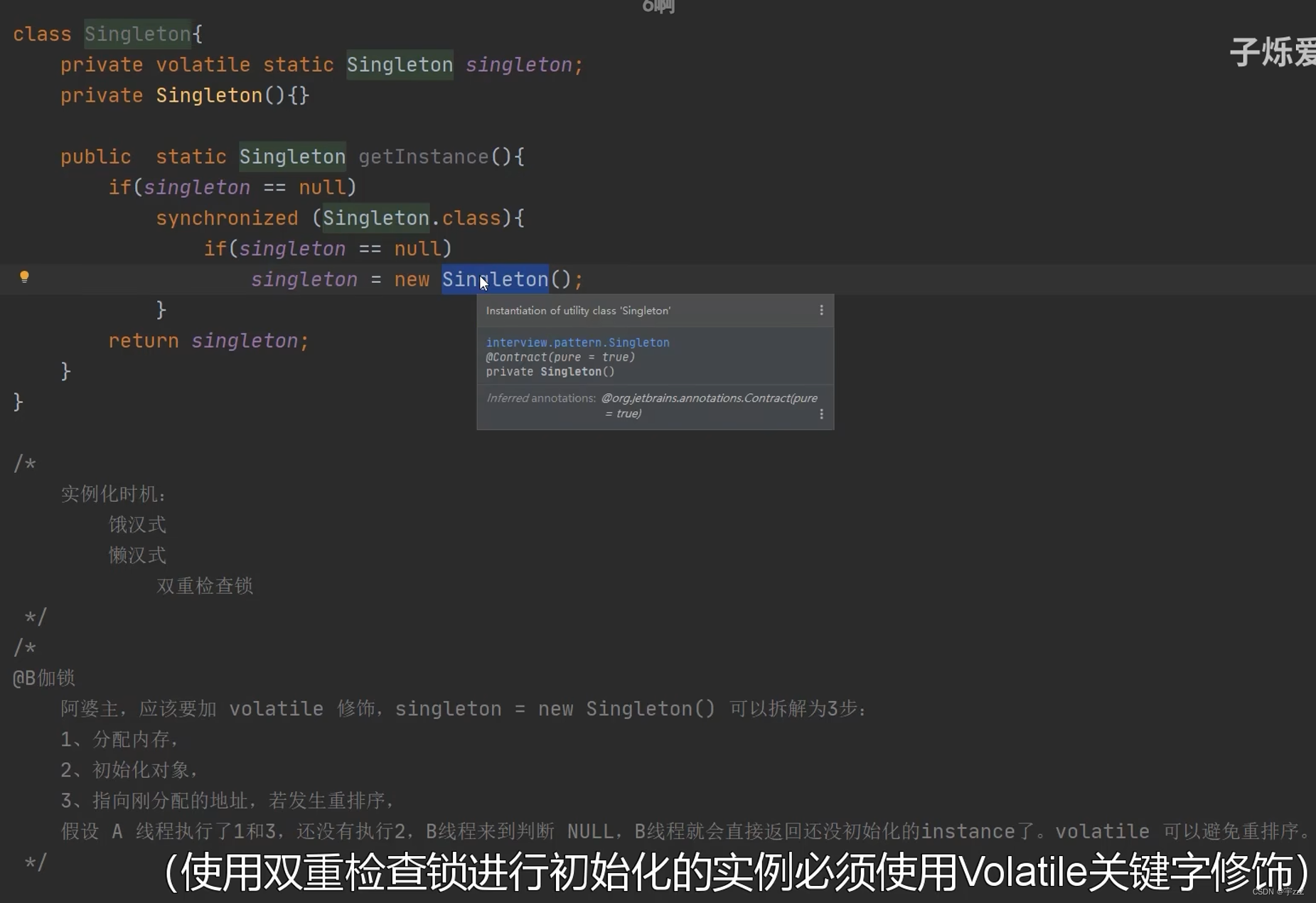
分为饿汉式和懒汉式:饿汉式在类加载时初始化单例实例,直接定义时new;懒汉式在第一次被访问时初始化,(示例访问方法)实例化。
懒汉式需要加锁防止被多线程多次实例化;还有一种双重检查锁的实现方式,如图。
单例模式的缺点:状态值可能会被修改,因此建议单例模式用在无状态的工具类- 简单工厂模式:专门定义一个类来负责创建其他类的实例。是类创建模式的一种,被创建的实例通常都具有共同的父类。(状态模式的一种特例)
缺点是不够灵活,如果创建新的类,就需要在工厂类中添加代码;- 策略模式:提前定义一组算法,将每个算法都封装起来,并且他们之间可以互换。策略模式让算法独立于使用它的客户而变化。比如洗衣机选择清洗模式的例子。
- 组合模式:太抽象了,是一种结构型设计模式,可以使用它将对象组合成树状结构,并且能够像使用独立对象一样使用它们。
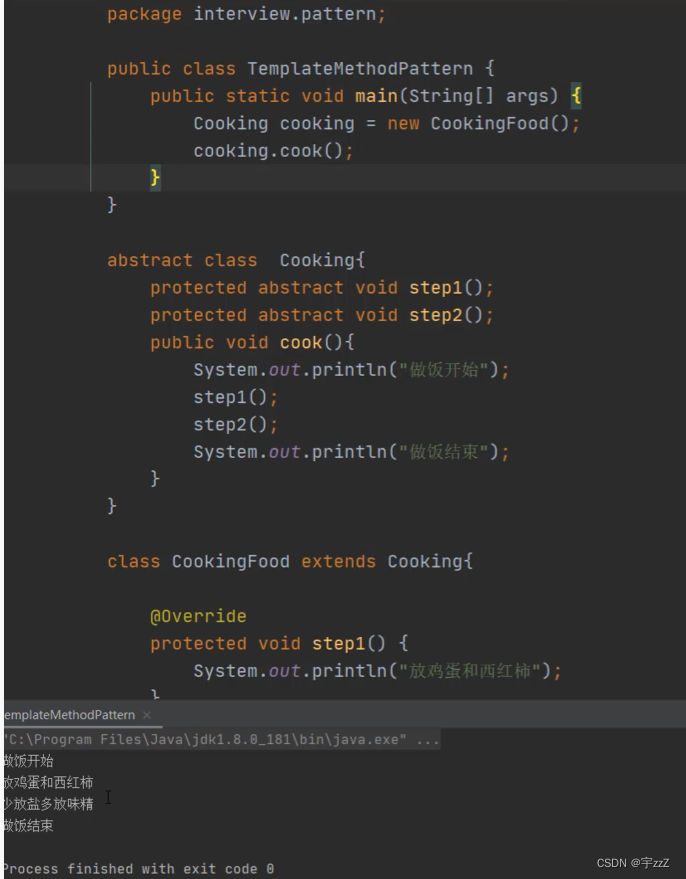
- 模板模式:定义一个操作中的算法框架,而将一些步骤延迟到子类中。使得子类可以不改变算法结构即可重新定义该算法的某些特定步骤。(提前规定好业务执行的流程顺序,子类只需要逐个实现相应方法即可。)
父类控制框架流程,子类负责某些方法的具体实现
缺点是:类的个数会增多。参考视频:五分钟学设计模式
2.SQL调优
- 什么契机需要进行SQL调优?
- 有哪些调优方法?如何实现?
表结构优化:
SQL语句优化:
a) 避免使用SELECT *;而是使用具体的列;
b) 用union all 代替union;union可以排除重复的数据,union all无法排除重复语句;
c) 小表驱动大表:小表在前,则用exist接大表;大表在前,则用in关键字接小表;
① 比如:order表1w条数据,大表;user表100条数据,小表;如果order表在左边,使用in关键字性能更好,因为in关键字先在小表user中查;如果user表在左边,则用exist关键字性能更好,因为exist关键字先查小表user;
d) 批量操作:比如批量插入,需要控制没批数据在500行以内,多余500可分多批次处理;
e) 多用limit:用SQL语句排序查找第一或者最新数据时,可以加上limit1,只返回一条数据即可;
f) 业务代码优化,见5.
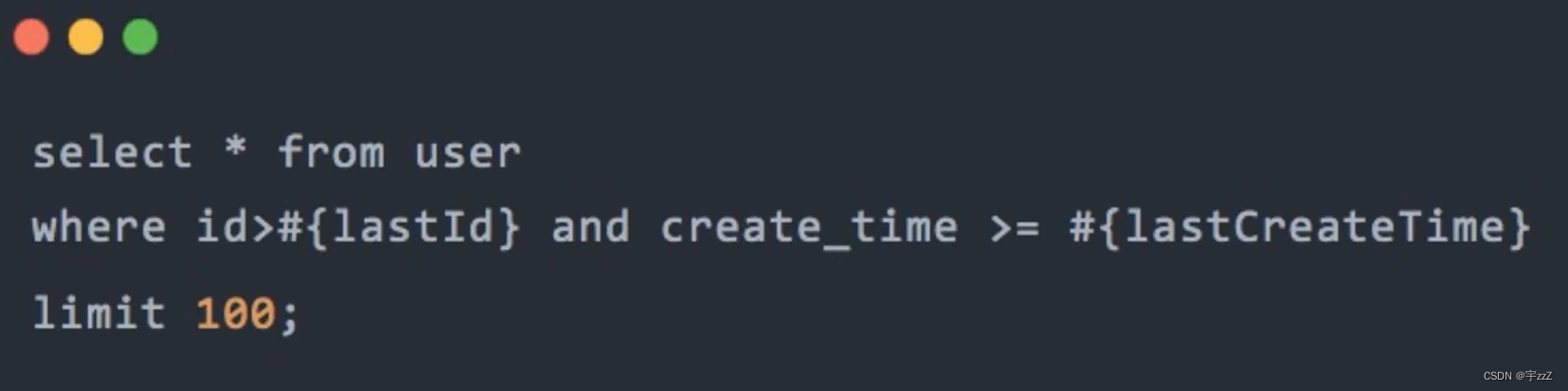
g)增量查询:对于查询整个数据库,然后同步到另一个数据库,会用到select *,对于这种情况,可以分轮次,按照id和时间顺序,每轮查询100条,增量查询。
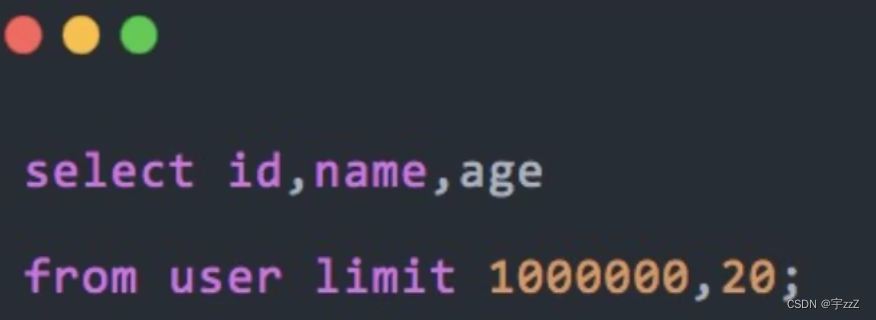
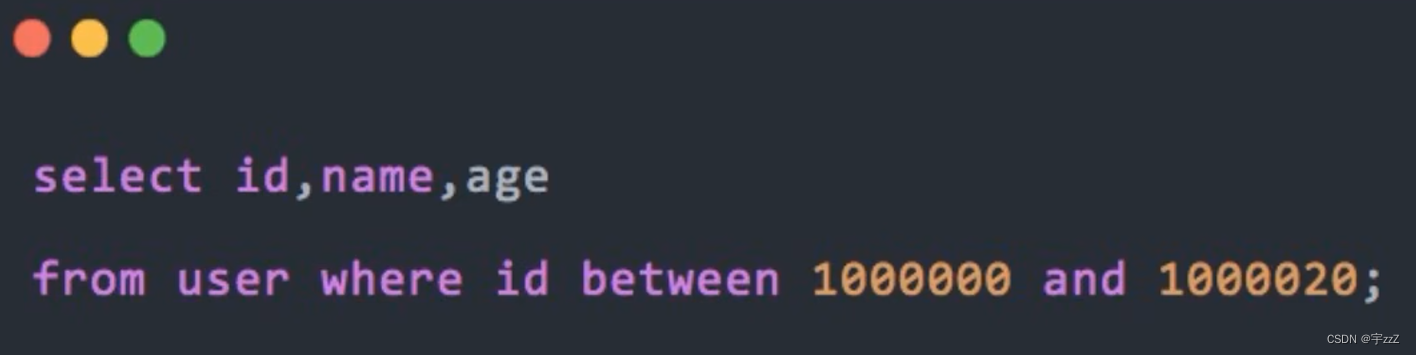
h) 高效的分页:反例:
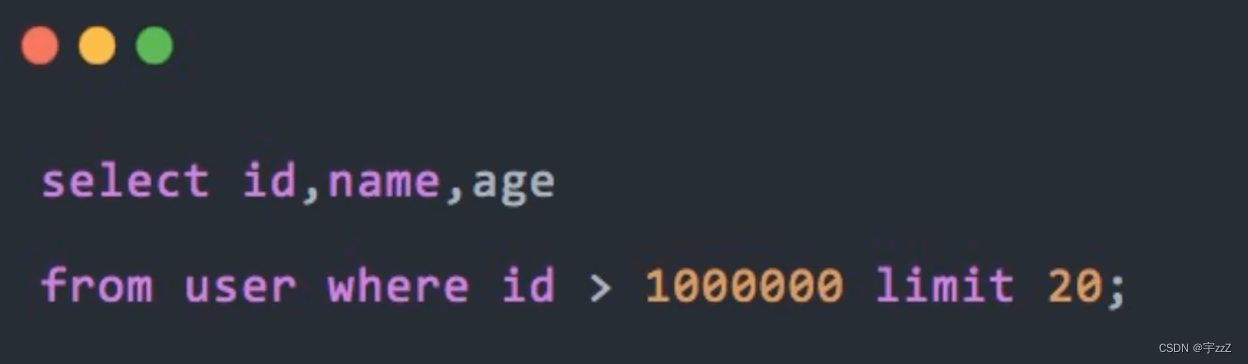
优化为:
①但是该方案要求id连续且有序;
②between优化分页:
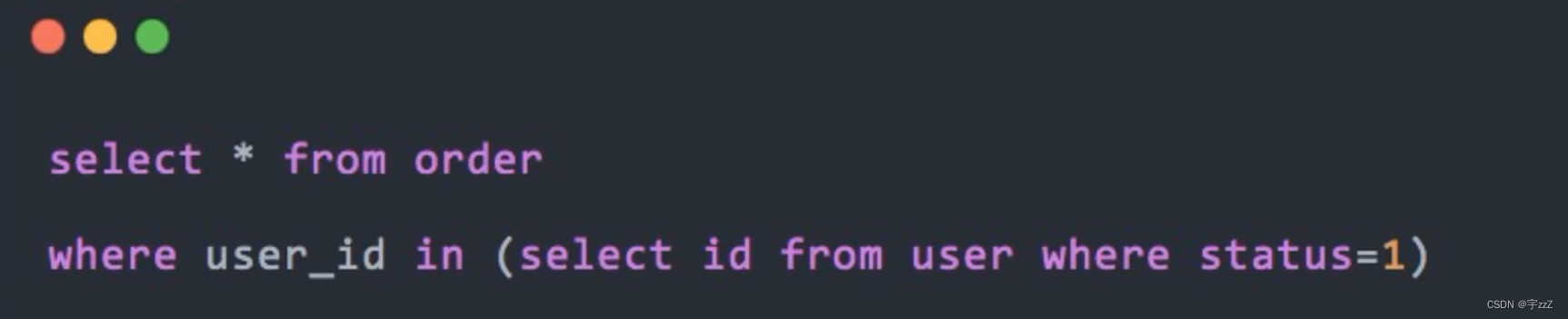
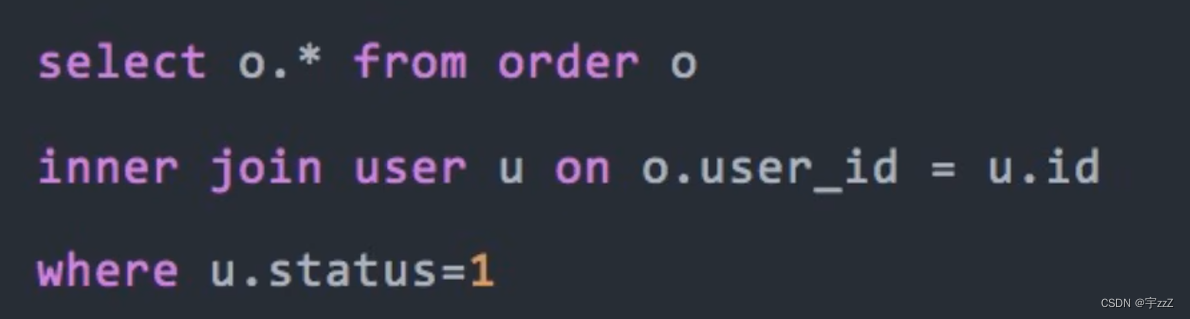
i) 用连接查询代替子查询:反例:
优化为连接查询:
j)join表不宜过多:join表不应该超过三个(阿里开发者手册),如果表内数据量不太大,可以适当允许更多表的联查;即视情况而定。
k)join时要注意:尽量用inner join,如果非要用left join,则left join左边的表最好是小表,右边可以用大表;
l) 控制索引的数量:索引占用一定的内存,能加快查表速度,但是当需要插入(insert)/更新(update)/删除(delete)数据时,需要修改索引,会有一定的性能消耗,因此不能太多索引。阿里巴巴开发者手册:高并发场景下,单表的索引数量控制在五个以内。能建立联合索引就不要建立单个索引
m) 选择合理的字段类型;varchar和char的选择;能用int尽量用int;
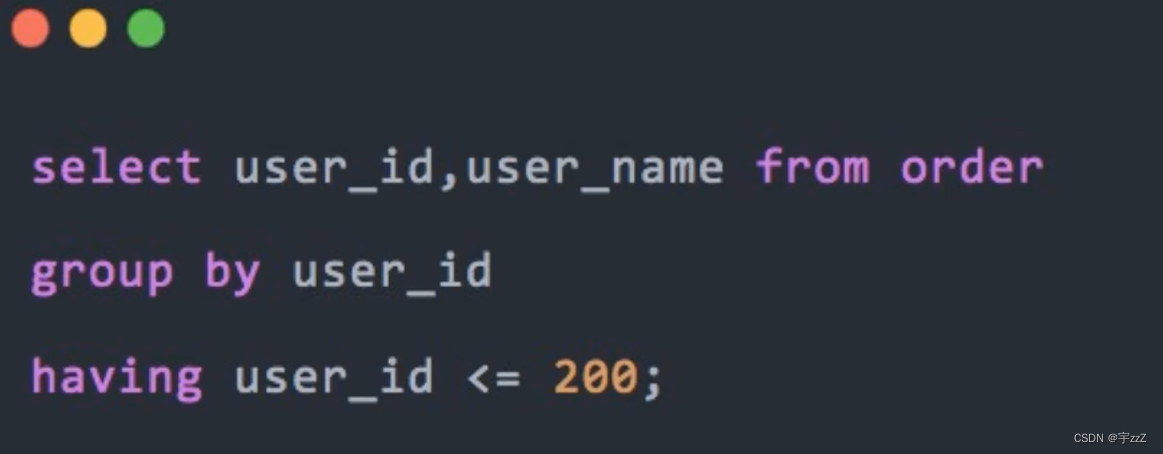
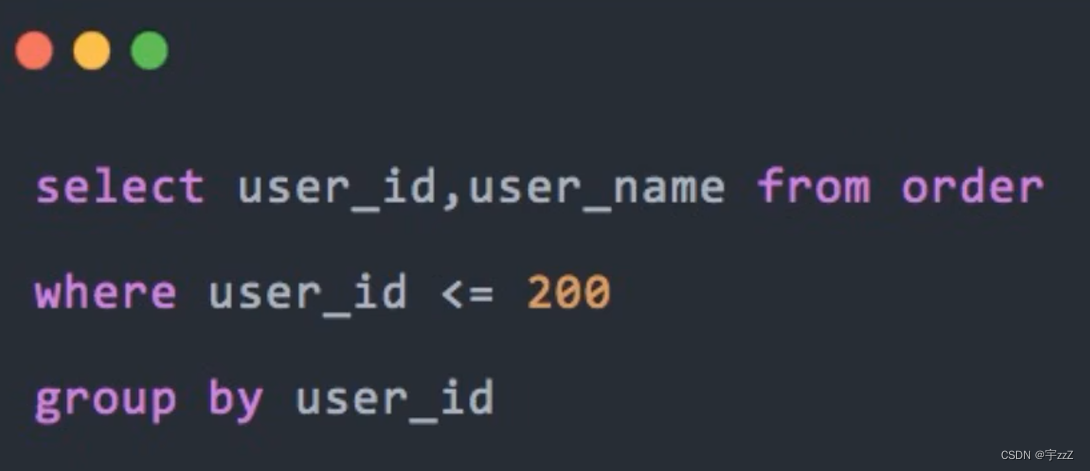
n) 提升group by的效率:group by的作用就是去除重复和分组,通常和having一起使用;先group by 再设定范围:
反例:
优化:
o) 索引优化:使用explain命令查看数据库的执行计划,看其是否走了索引;合理的使用索引:
- 索引
a) 控制索引的数量:索引占用一定的内存,能加快查表速度,但是当需要插入(insert)/更新(update)/删除(delete)数据时,需要修改索引,会有一定的性能消耗,因此不能太多索引。阿里巴巴开发者手册:高并发场景下,单表的索引数量控制在五个以内。能建立联合索引就不要建立单个索引
b)索引优化:
索引失效是SQL查询语句效率不太高的原因之一;
- 事务(四种隔离等级)
- 业务代码优化:
业务代码:大范围的查询,手动分批次查,每批不大于500个的查;
- ?
3.Redis
- 为什么使用redis?
- Redis如何保证数据一致性?
- Redis中缓存击穿、缓存雪崩、缓存穿透出现的原因和解决方案?
4.消息重复(Redis实现消息队列)
- 什么是消息队列?
- 为什么需要消息队列?
- 如何保证消息队列中的消息不重复、不丢失?
5.补充内容
- 抽象类和接口的本质区别是什么?
本质区别一般要从设计层面进行回答:
抽象类是自下而上的设计,是对一些类的向上抽象,可以包含方法的具体实现;而接口是自上而下的设计,约束和规范实现类的方法。
- static关键字的作用?
对于类中的变量,如果被static修饰,那么该变量就是类变量,其在没有创建对象时就可以使用,该类的所有对象共享该静态变量;
对于类中的方法,如果被static修饰,则在编译阶段就静态绑定该方法,无法访问非静态成员,不允许子类重写;
对于static修饰的类,不能被实例化,一般用来提供一组静态变量和静态成员方法,不需要实例化就可以被访问,以实现一些特定的功能;
- 反射机制是?
- JavaIO的知识点有哪些?
- Abstract修饰的类必须被继承,Abstract修饰的方法必须被重写。
- SQL语句limit:单个int数,取个数,比如limit 5;取5条数据;两个int表示范围,比如:limit 2,7;第三个到第九个,共7个。
- ?
编程小技巧
- 在字符串对比时,为了防止变量为null,可以用
"ABC".equals(s);而不是s.equals("ABC");;