Cornus
Paper
-
Preknowledge
Share-Nothing
-
Related Work
Cornus: Atomic Commit for a Cloud DBMS with Storage Disaggregation
ABSTRACT
传统2PC存在两个限制(缺点)
- Long Latency:long latency due to two eager log writes on the critical
path ?(性能问题:无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务 协调者 才会通知进行全局提交,参与者 进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。) - Blocking:coordinator fail的时候整个过程都会阻塞。(也就是coordinator单节点故障,partcipant会一直阻塞下去)
对于storage disaggregation的架构来说,利用这种存算分离架构可以有一种新的协议来解决这两个问题。Corns唯一额外需要的条件就是存储层支持原子的CAS(Compare And Swap)
On Azure Blob Storage and Redis进行了实验
1 Intro
-
云数据库的发展是主要看重了
弹性(可伸缩性)、高可用性和成本竞争力。
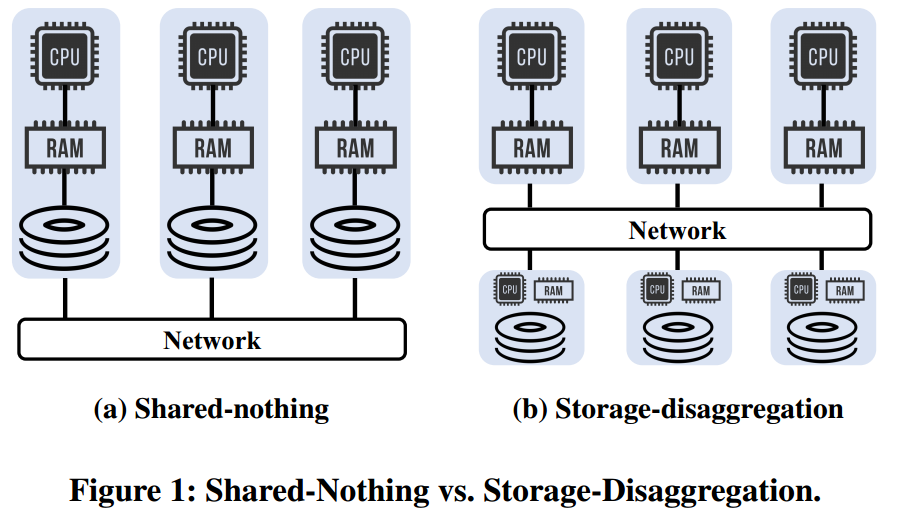
问题:存算分离架构的存储层为啥还有CPU RAM?
再一次强调了2PC的两个问题,Long Latency:两次RTT以及相关的日志操作;Blocking:coordinator failed在commit之前 会block。 这种问题特别是在存储服务化场景下不可容忍why?
有一些针对shared-nothing架构的优化,但是不能同时解决这两个问题。要么通过对工作负载和/或系统做出严格的假设来减少延迟,而这些假设并不总是适用于存储分解,要么通过增加额外的阶段和延长延迟来缓解阻塞问题。另一个研究方向是通过定制存储来解决这两个问题。然而,现有的解决方案并不适用于一般的存储服务,因为它们需要定制的存储设计来执行事务之间的冲突检测或需要特定的复制协议。
本文的目标是在不需要为存储服务定制api的情况下,最大化存储分解带来的灵活性。
目标是回答以下研究问题:存储层支持2PC优化解决高延迟和阻塞的最低要求是什么? 答案是:唯一的要求是能够提供log-once,来确保对于每个事务,只允许在日志中更新一次其状态。And log-once 语义可以通过简单的CAS API实现。 how?
Cornus的两个主要改进之处
- 减少coordinator决策日志,减少了latency。
- 只要所有的participants在第一(Prepare)阶段写入了VOTE-YES 到log中,事务就被提交
- 可行性:存算分离架构能够保证一旦写入了log就不会丢失。
- Cornus使用基于CAS的LogOnce( ) API来解决阻塞问题。 后面没看懂
2 Background and Motivation
2PC
正常流程:
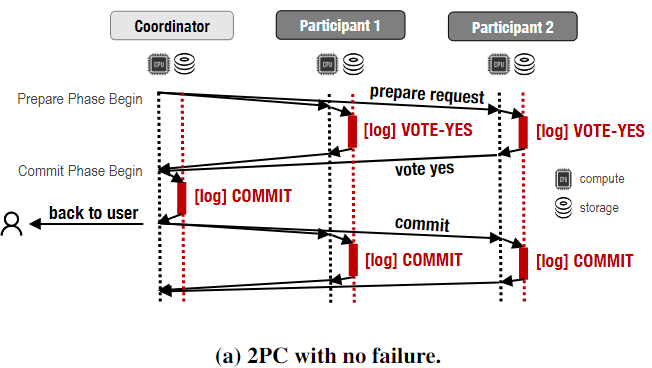
假设coordinator在第二阶段开始的时候fail,在将log[commit]发送就之前fail;participants会等待coordinator超时,然后发起一个termination protocol(终止协议)
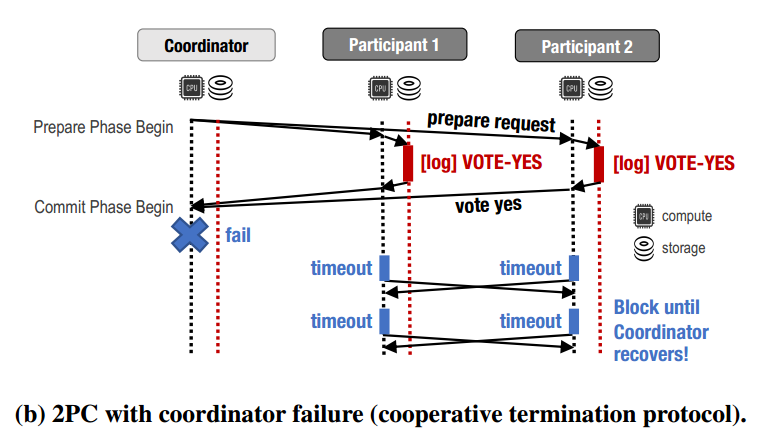
- Termination Protocol
- Naive :等待协调器恢复
- Cooperation Termination Protocol:如果coordinator在prepare阶段的request中包含了participants的列表发出去了,会去联系其他的参与者,但是是告诉呢还是得到别人的决定呢?总之仍然需要block直到coordinator恢复。 这里有问题
这里又总结了2PC的两个limitations
-
Latency of Two Phase
对于user来说一次rtt的时延以及两次logging操作
-
Blocking Problem
参与者从协调者或者其他参与者那得到决策结果,但是会出现uncertain transaction。会影响数据的可访问性以及性能。
2PC in Storage-Disaggregation Architecture
-
Paxos Commit Theoretical Framework(需要去读原论文)
- **一个事务的最终结果不再由协调者的决策日志desicion logging来决定,而是由所有参与者包括协调者记录的投票来决定。**每个参与者都会在第一阶段中记录一个“准备好”或“不准备好”的投票,并在第二阶段中记录一个“提交”或“中止”决策。只有当所有参与者都投票“准备好”并记录了投票后,该事务才会被提交。
- Paxos acceptors可以保存第一阶段的状态?事务的状态不再被存储在协调者的状态机中,而是由所有参与者记录在它们自己的状态机中。
- 参与者可以直接向副本(即acceptors)提出准备消息propose the prepared message,从而跳过Paxos leader以节省一个消息延迟
- 协调者也是所有Paxos实例的Paxos leader,它可以直接从acceptors中了解决策,以节省两个消息延迟。
通过paxos commit的思想以及定制化存储层是可以实现低延迟以及Non-Blocking的2PC,但是不具有普适性。本文的目标是在不定制存储服务的情况下解决长延迟和阻塞问题。即:开发一种协议,它在很大程度上保留了Paxos类提交优化的性能优势,同时可以部署到现有的存储服务中。
CORNUS
Cornus是一种非阻塞、低延迟的2PC变体,对存储分解服务的要求很低。唯一需要的新存储层功能是日志过程中的logonce(),它可以使用CAS来实现——许多云原生存储服务都支持这种功能。
Design Overview
Disaggregation storage的特性支持了cornus的优化,相比与shared-nothing有以下特性
- 存储分解的服务拥有内置的数据复制来支持高可用
- 存储分离的存储服务可以被所有的participants 获取access
- 存储分离的存储服务除了提供读写服务之外还可以提供一定的计算服务。
-
针对Latency reduction:
在传统的2PC中,事务的最终结果由协调器的决策日志desicion log决定。在Cornus里面,遵循paxos commit的第一个思想,衡量结果的标准是collective votes in all participants logs(所有参与者logs中的投票结果)。即:当且仅当所有参与者都记录了VOTE-YES时,事务才会提交。如下图所示,coordinator不需要记录log commit(也就是决策的log),减少了时延(多吗?存算分离的话代价好像高一点?)其中关于高可用以及可访问性的特性确保了这个改进正确。
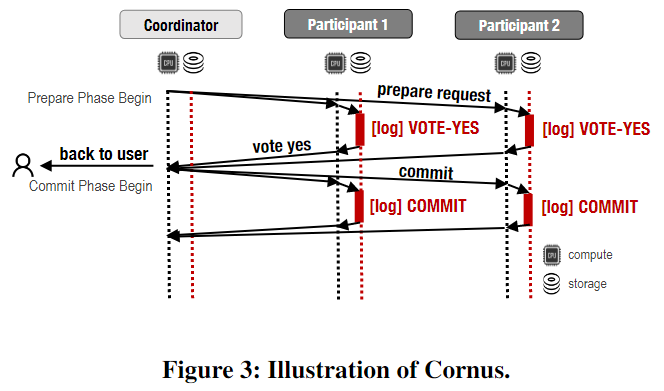
-
针对Non-blocking
因为cornus把集体决策日志the collective decision logs写入了存储服务中(而非协调者的本地disk)因此是高可用的,不会被阻塞。
- 如果参与者不确定事务结果,可以在存储服务中直接读取所有参与者的投票来得知结果。
- 不确定的参与者甚至可以代表无响应的参与者写入日志,以强制执行最终决策。(根据特性2 能够写,但是这么写对吗 合理吗?有待解释)
- 单分区事务写入相应数据分区中的log;分布式事务写入它所访问的所有相应分区的log(identical to 2PC)
带来的问题:如果多个participants都为了解决unresponsive participant来写入相同的日志,就会出现数据竞争。为了避免,同时利用特性3,引入API:LogOnce( )。它保证日志中的事务状态是write-once——在事务状态的第一次更新之后,以后对状态的更新不会产生影响。
当然 cornus也可以block,如果底层存储系统fail。但是当底层存储不可以用时,相应的存储分解数据库系统也会block。并且现在的云存储高可用很厉害,Azure Blob Storage在本地冗余存储方面具有“11个9”的持久性,在区域冗余存储方面具有“12个9”的持久性。所以概率很小而且不是问题不会影响正确性?
3.2 Cornus APIs
| RPC | 通讯方式使用RPCs,可以是synchronous(同步) ,也可以是asynchronous(异步)。同步调用阻塞,直到被调用方返回。异步调用允许调用方继续执行,直到显式地等待响应。 | R P C s y n c / a s y n c n : : F u n c N a m e ( ) RPC^n_{sync/async}::FuncName() RPCsync/asyncn::FuncName()n表示发往的目的地.FuncName()是要在远程站点上调用的函数,可以接受任意参数。 |
|---|---|---|
| Log(txn, type) | 将某种类型的日志记录附加到事务txn日志的末尾。它既用于传统的2PC协议,也用于Cornus。 | |
| LogOnce(txn, type) | LogOnce(txn, type)来保证事务的状态最多只能写一次。此功能在Cornus中使用,但在传统的2PC中不使用。 | 自动检查txn的日志记录是否已经存在,如果不存在,则将type中的值分配给该记录,即VOTE-YES、COMMIT或ABORT。它在执行原子操作后返回txn的状态(type or the existing state(取决于操作是否更新了状态)) |
3.3 Cornus Protocol
主要是三个API,下面依次介绍。
-
Coordinator::StartCornus(txn)
Coordinator调用开始原子提交:
- 协调者向所有参与者发送投票请求包括了所有参与者的列表。
- 等待所有参与者的responses
- 如果收到了ABORT,该事务则形成ABORT的决策。
- 如果收到了所有参与者的VOTE-YES,则事务达成提交决策。
- 如果超时,则调用TerminationProtocol(txn)来确定最终的决策。(这里与2PC不同,2PC直接在协调者终止事务不运行终止协议?)
- 一旦达成决策可以立即返回给txn caller,无需先记录决策
- 最后,coordinator异步向所有参与者发送decision。

-
Participant::StartCornus(txn)
- 参与者等待来自协调者的VOTE-REQ消息
- 如果超时可以单方面终止事务。向本地local log写log(abort) ??? 然后返回
- 在收到VOTE-REQ之后,参与者向本地写根据其本地事务状态来投票VOTE-YES或VOTE-NO。
- 如果是VOTE-NO,则本地记录一条ABORT然后回复ABORT给协调者。(REPLY和LOG可以异步执行提高效率)
- 如果是VOTE-YES,则参与者调用LogOnce(VOTE-YES),得到一个写日志的状态resp。
- 如果resp是ABORT,则说明有其他的参与者通过终止协议代替自己终止了该事务。则此时该参与者需要终止事务然后返回ABORT给协调者。
- 如果resp是VOTE-YES,参与者将VOTE-YES返回给协调者;然后等待协调者最终的决策。
- 如果decision超时,则将执行终止协议并且将结果写入decision。
- 最终将decision Log到本地日志中。

- 参与者等待来自协调者的VOTE-REQ消息
-
TerminationProtocol(txn)
参与者在等待消息超时时执行终止协议,并且不能单方面终止事务;在2PC中,运行协作终止协议cooperative termination protocol的参与者与所有其他参与者联系,以获取事务的结果。如果任何参与者返回结果,则不确定性得到解决。否则,它将阻塞,直到故障恢复。
在Cornus里面:
-
运行终止协议的参与者尝试使用LogOnce( )来在每个参与者的log中log 一个ABORT。
-
等待返回的结果
- 如果某个参与者的(远程)的storage恰好没有接收关于这个txn的log,那么ABORT将成功log并且返回ABORT。
- 如果其他参与者的log已经接收到了一个decision log record,即ABORT/COMMIT,将会返回ABORT or COMMIT
- 如果返回了一个VOTE-YES,暂时没啥用,但是如果其他所有participants都返回了VOTE-YES,则COMMIT txn。
- 如果超时则重新运行该终止协议。
Cornus唯一block的情况是无法reach到存储服务,但是通常被认为是既不可能发生的因为云数据库+存储分离的高可用性。

-
3.4 Failure and Recovery
只讨论一次只有一个site fail的情况?
Coordinator failed 情况:
| 协调者故障的时机 | Effect of Failure | During Recovery (恢复期间协调器要干的事) |
|---|---|---|
| Cornus开始之前 | 参与者timeout然后单边终止事务 | 无需额外操作 |
| 发送一些投票请求后 | 未收到请求的参与者超时并单方面中止;接收到请求的参与者超时等待决策并执行终止协议,终止事务。 | |
| 在发送所有投票请求之后,但在发送任何决定之前 | 所有参与者在等待决策最后超时,执行终止协议以了解决策结果。 | |
| 在发送一些决定之后 | 没有收到决策的参与者运行终止协议来学习决策。 | |
| 发送完所有决定后 | 没有影响 |
Participants failure:
| 参与者故障的时机 | Effect of Failure | During Recovery (恢复期间参与者要干的事) |
|---|---|---|
| 在收到投票请求之前 | 协调者将超时,协调者运行终止协议终止事务。协调者为失败的参与者记录ABORT记录,从而中止事务。然后协调器将该决定广播给剩余的参与者。 | 中止事务:当失败的参与者恢复后,它运行终止协议来学习最终的决定。 |
| 在收到投票请求后,在记录投票(logging vote)之前 | 同上 | 同上 |
| 在记录投票之后,回复协调器之前 | 协调者将运行终止协议以查看投票并了解最终结果。协调者超时等待投票并运行终止协议。然后,协调者可以从存储中查看所有参与者的投票并了解结果。其余参与者从协调者或通过自己运行终止协议来学习决策。 | 失败的参与者恢复后,如果发现本地投票为ABORT,则中止事务;否则,运行终止协议以了解结果。(不确定?如果是COMMIT呢?不可能是COMMIT?所以CORNUS就是悲观处理方式?) |
| 在回复给协调者投票结果之后 | 没影响 | 如果存在决策日志,则遵循该决策。否则,同上(运行终止协议来了解结果)。 |
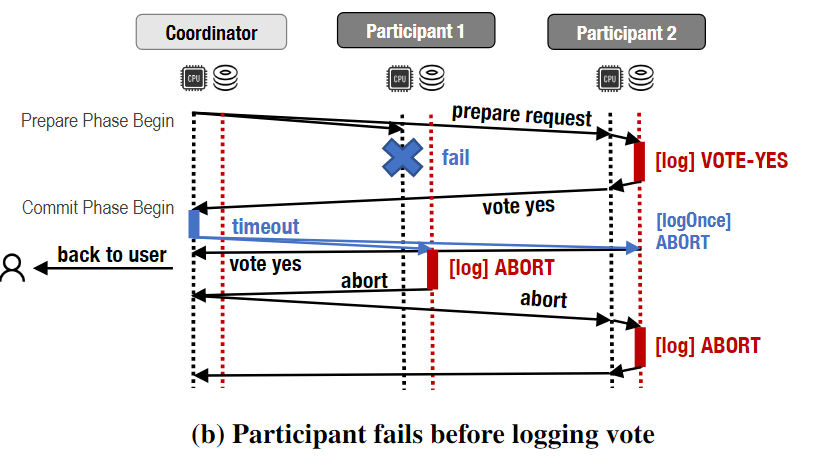
以下图为例,coordinator在send all reqeust 但是 在发送任何决定之前fail了(包括给caller吗?),相比2pc可以避免blocking问题,在参与者超时之后,它不联系协调者(协调者已经失败),而是使用LogOnce()函数联系共享存储中的所有日志。由于所有参与者的日志中都有VOTE-YES,因此每个参与者都学习了COMMIT的决策并避免了阻塞。
无论哪种情况,协调器在恢复期间都没有任何操作,因为它不保留任何状态,参与者可以自行终止事务。
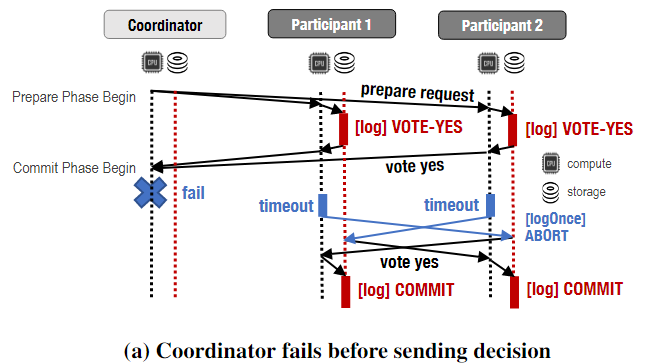
以下图为例:参与者在收到投票请求但未记录其投票之前失败。协调者从参与者2接收到VOTE-YES,并在等待参与者1的响应时超时。此时,协调器运行终止协议,试图通过LogOnce( )代表参与者Log ABORT。协调者先给participant 1 LogOnce(ABORT)成功返回的LogOnce( ).decision = ABORT,然后给participant 2 LogOnce(ABORT) 失败 返回的是VOTE-YES,得知了participant2记录了VOTE-YES。
再往下,在协调者运行终止协议结束(一次结束了 并非有VOTE-YES就得全收到才继续),coordinator.TerminationProtocol.decision = ABORT,先reply decision = ABORT → txn caller,然后将decision=ABORT 广播给所有参与者,OVER,abort the txn。 这个过程中可能participant 2等待coordinator回复超时然后运行终止协议,然后还是ABORT的结果。
3.5 Proof of Correctness
根据Concurrency Control and Recovery in Database Systems来证明,将原子提交分成五个独立属性,AC1-5。
定义1 [Global Decision]:如果所有参与者都记录了VOTE-YES,则事务会达到COMMIT的全局决定;如果任何参与者记录了ABORT,则会达到ABORT全局决策。否则,这个决定是未定的。
**引理1[不可逆的全局决策Irreversible Global Decision]😗*一旦达成了一个事务的全局决策,该决策将不会改变。
-
证明该引理(全局决策不可逆):
- 一个abort全局决策已经达成,这意味着有一个日志记录中存在ABORT log。根据LogOnce( )的语义,不能再向该日志追加VOTE-YES,这意味着全局决策不能切换到COMMIT。
- 所有participants VOTE-YES,全局决策达成。追加ABORT record的唯一办法是终止协议。但是LogOnce( ) check 到VOTE-YES不会添加ABORT。
-
证明五个性质(定理)
定理1[AC1]:每个参与者的decision与global decision相同。
证明:参与者要么通过coordinator了解决策要么通过终止协议直接查看或者强制在其他参与者的log写投票结果来完成决策。在这两种情况下,只有当所有参与者都同意提交时,才会提交,否则将中止。(最终一致性还是强一致性呢?感觉是最终一致性因为可能某些是VOTE-YES 但是全局决策ABORT都返回给caller了)
定理2[AC2]:参与者在做出决定后不能逆转。
证明:根据引理1,一旦达成一个全局决策,它就不能逆转。根据定理1,每个参与者都会得出与全局决策相同的决策,完成证明。
定理3[AC3]:参与者在做出决定后不能逆转。
证明:根据引理1,一旦达成一个全局决策,它就不能逆转。根据定理1,每个参与者都会得出与全局决策相同的决策,完成证明。
AC3:COMMIT decision只有在所有参与者都VOTE-YES才能达成。
AC4:如果没有意外的failure并且所有参与者都vote yes那么决定提交。
定理3 [AC3&4]:当且仅当所有参与者投赞成票并将VOTE-YES写入相应的日志时,事务的dicision是commit。
证明:根据定义1,一个事务的global decision is commit当且仅当所有参与者写VOTE-YES到自己log。根据定理1,每个参与者的决策与全局决策相同,完成证明。
AC5:只考虑算法设计过程中允许出现的失败的出现。在此执行过程中的任何时刻,如果所有现有故障都得到修复,并且在足够长的时间内没有出现新的故障,那么所有流程最终将达成一个决策。(最终一定有一个决策可以形成)
定理4 [AC5]:如果存储层是容错的,那么在计算层发生任何故障时,其余参与者将在有限的时间内达成决策,而不需要恢复故障站点。
证明:由于存储层是容错的,一旦达成全局决策,active participants总是可以通过终止协议学习全局决策。唯一不能达成决定的情况是当一个参与者没有记录其投票。在这种情况下,经历超时的协调器或参与者将运行终止协议,并直接将ABORT写入挂起pending 参与者的日志中,从而强制执行全局决策。
3.6 Read Only Transactions
对只读事务的优化。在2PC里面,如果一个事务向某个参与者只有读请求(只读参与者),那么该参与者在准备阶段不需要记录日志,可以直接释放锁。在Cornus中,这种优化有一个小的微妙之处。
如果整个事务是只读的,并且在进行2PC之前coordinator知道这个情况,所有的参与者都可以在prepare阶段跳过logging。在实际场景下,我们是可以提前提前知道一个事务是read-only的。
如果事务无法知道一个参与者是不是只读的,在这种情况下,包括只读分区的所有分区都必须在 Cornus协议中记录 VOTE-YES(2PC可以跳过只读分区logging)。为什么?如果只读事务跳过logging VOTE-YES,那么其他参与者会将只读参与者日志中缺少VOTE-YES解释为ABORT了(认为一个只读事务超时等待VOTE-REQ然后中止了)。尽管为只读参与者log这样的日志是额外的开销,但它可以与read-write participants的日志写入并行。因此,它不会增加关键路径上的日志写次数,尽管如果只读参与者速度较慢,它可能会影响尾部延迟(tail Latency: )。相比之下,在2PC中,协调器在关键路径上有一个额外的日志写入,以记录提交决策。因此,与传统的2PC相比,Cornus仍然具有更低的延迟。
-
Critical Path
影响整个流程完成时间的最长路径或最慢的步骤。在这篇论文中,指的是一个分布式事务的处理过程中,影响整个事务完成时间的最慢步骤。在传统的2PC协议中,协调者在关键路径上需要进行额外的日志写入,以记录提交决策,从而增加了整个事务的处理时间,而Cornus协议通过优化,避免了这个额外的日志写入,降低了事务的处理时间。
3.7 Futher Optimization Opportunities
-
Optimization #1
接收到一个请求之后,现有的存储服务只会respond发起request的participant。可以让storage service respond to multiple participants以此来进一步减少协议的延迟。存储层中记录参与者的投票后,response可以发送给请求参与者和协调者。因此,协调者可以直接从存储服务中了解投票结果,而不需要从参与者那里获得消息(需要另一个跳)。这在关键路径中节省了一个消息延迟,而不会引入任何额外的消息。
-
Optimization #2
让存储服务将其投票结果广播给事务的所有参与者来扩展。每个参与者可以通过这些投票来直接学习到决策结果,不需要等待coordinator收到所有response之后再发送decision。进一步减少了总体延迟,但不会影响用户观察到的延迟(user-observed latency)。由于广播,此优化会产生额外的网络消息。
没有做优化的原因是因为Cornus的目标是让2PC优化与任何存储服务一起工作,只要它们支持所需最基础的CAS api。
4 Deployment
部署需要实现Log( ) and LogOnce() → 一个要求是保证决策做出之后不会被更改(CAS来支持)+ 另一个要求是access control访问控制(2PC里面prepare phase的logging 记录了txn state + user data,Cornus里面一个参与者需要访问其他参与者的txn state,所以需要txn.state 和 user data 分开访问控制避免在读别人事务状态的时候还读人家用户数据)
4.1 Deployment on Redis
Redis用作分布式内存中的键值数据库、缓存和消息代理。
EVAL command来实现CAS,+Lua scripting实现EVAL的原子执行。使用Redis Access Control List (ACL)来实现访问控制。“ACL SETUSER” pattern: “data-” and “state-”
4.2 Deployment on Microsoft Azure Blob Storage
Microsoft Azure Blob Storage是一个可扩展scalable的存储系统,支持云原生工作负载cloud-native workloads、archives, data lakes, high-performance computing, and machine learning的安全对象存储。
Azure存储为每个存储对象分配一个标识符。每次对象更新时,标识符都会更新。HTTP GET会返回这个identifier作为Etag(entity tag)的一部分。用户更新对象时可以发送带有“if - match”条件标头的原始Etag,这样只有当存储的Etag与请求中传递的Etag匹配时才会执行更新 → CAS了 LogOnce( )了
Azure Blob Storage支持Azure基于属性的访问控制(Azure ABAC)。它允许based on tags and custom security attributes对blob进行读访问。
4.3 Deployment on Key-Value Databases
Amazon DynamoDB是一个高可用的键值存储系统,具有丰富APIs。putItem & updateItem 提供了条件put 和 update来实现CAS。DynamoDB提供了项目级访问控制,事务数据和事务状态可以作为单独的属性保存在一个表中,也可以保存在不同的表中,同时它们可以使用单个“TransactWriteItems”请求同时更新。
Google Cloud Bigtable是一个结构化数据的分布式存储系统。它支持条件写入,所以Cornus可以在上面实现LogOnce()。Google Cloud使用身份访问管理(IAM)进行访问控制。它是一种基于角色的访问控制机制。对于Bigtable,它可以在表级别控制访问,以便事务状态和用户数据日志可以保存在单独的表中。每个参与者都可以对存储在一个表中的用户数据日志以及存储在另一个表中的所有事务状态具有读/写权限。然而,Bigtable不支持批量写入多个表,这和Azure Storage一样,在将其用于Cornus时会导致额外的开销。
5 EXPERIMENTAL EVALUATION
5.1 Experimental Setup
-
Architecture
计算层有多个节点访问同一个disaggregated storage service。数据是分区的,其中每个计算节点运行一个资源管理器,并对一个分区具有独占访问权。当计算节点执行事务时,它向相应的计算节点发送数据访问请求来访问相应的分区数据。在提交时,有一个计算节点协调参与事务的rms来提交事务。每个compute node都可以写入log records到storage service。在Sundial上实现了Cornus,这是一个开源的分布式DBMS测试平台。计算节点通过gRPC通信,gRPC可以是同步的,也可以是异步的。每个节点都有一个用于发送请求的gRPC客户端和一个管理服务器线程池来处理请求的gRPC服务器。
-
Compute Node Hardware and Storage Service
对于计算节点:使用多达8台服务器的集群。两个计算节点之间的网络往返时间为0.5 ms。对于存储服务:Cornus可以使用任何云存储服务。我们在三种不同的配置中使用以下两个服务。
- Microsoft Azure Blob Storage (Azure Blob):storage v2 store blobs 使用geo-redundant storage来replication。数据存储在两个region,在主分区,数据是同步三副本。然后将数据异步复制到距离主区域数百英里的第二分区。条件写请求的平均时间为10.40 ms,普通写请求的平均时间为10.29 ms。
- Microsoft Azure Cache for Redis (Redis):使用Microsoft Azure提供的Redis服务。使用主从复制,在同一区域中只有一个master一个slave。只有主节点接受读和写。它异步地将更改应用到从属节点。条件写请求的平均时间为1.96 ms,普通写请求的平均时间为1.84 ms。
-
Workloads
使用YCSB(Yahoo Cloud Serving Benchmark)用于性能评估,是一个基于云服务的benchmark。它包含一个以循环方式跨服务器分区的表。每个分区包含10gb的数据和1kb的元组。每个事务访问16个元组作为读(50%)和写(50%)的混合。查询访问的元组遵循Zipfian law 幂等分布齐夫定律。 θ = 0 \theta = 0 θ=0表示数据访问均匀分布。
-
Implementation Details and Parameter Setup
在最多8个计算节点和1个存储服务上对系统进行评估。每个节点有8个工作线程执行事务逻辑,每个节点有8个工作线程为远程请求服务。默认并发控制算法为NO-WAIT。对于每个数据点,我们运行5次试验,每次30秒。我们收集分布式事务(涉及多个分区(节点)的事务)的延迟,并从平均延迟中位数的试验中获取结果。
假设事务的协调器可以在执行阶段结束时了解某个事务是否为只读事务。因此,Cornus和2PC可以跳过只读事务的准备和提交阶段。
由于Azure Blob不支持对具有单独访问控制的两个资源进行批量更新,因此我们实现了两个版本。在默认版本中,对事务数据和事务状态使用相同的访问控制。Azure Blob的第二个版本使用单独的ACLs。分析显示,第二个版本的LogOnce()时间从平均10.40 ms增加到平均18.43 ms。
5.2 Scalability
通过将计算节点从2增加到8先测试了Cornus的可扩展性。
Cornus和2PC在使用Redis或Azure Blob的YCSB中都可以很好地扩展。随着节点数量的增加,2PC和Cornus的延迟都呈线性增加。随着节点数量的增加,Cornus在2PC上的平均延迟加速略有下降。这是由于在执行阶段用于RPC调用的时间增加了。
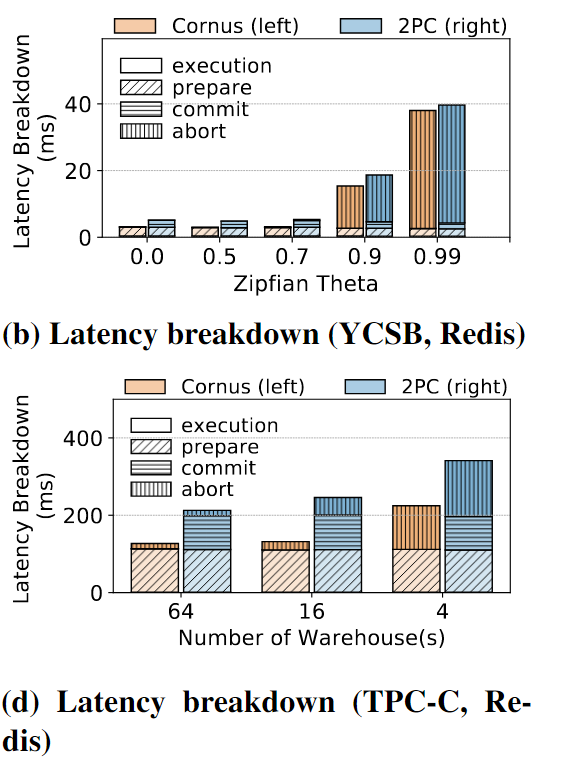
看图:99%的意思是在99%的情况下,Cornus和2PC的延迟分别达到了多少。换句话说,99%的请求的延迟不超过这个数值;Latency Breakdown的意思是具体每个阶段的执行时间对比,Cornus无需COMMIT PAHSE。
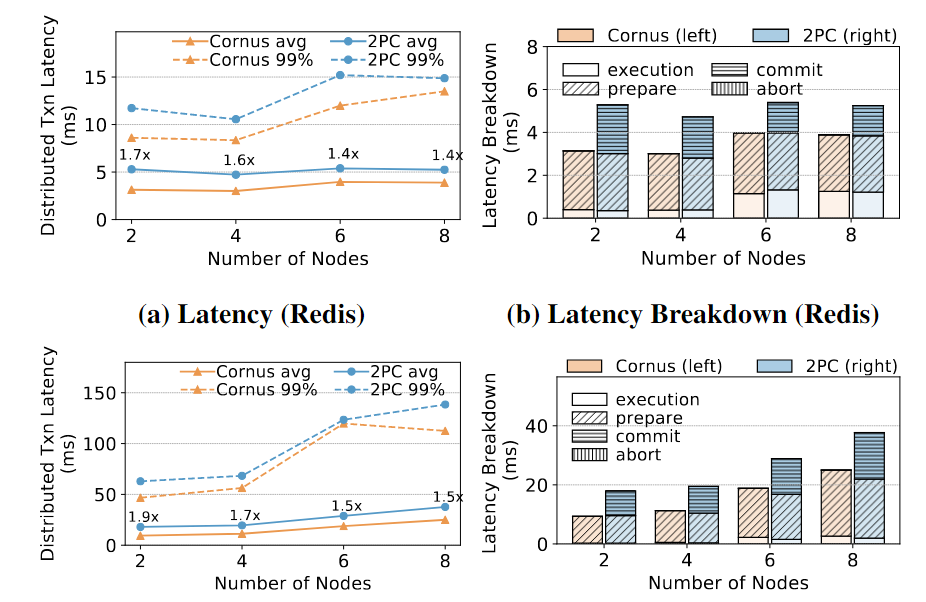
在2PC中,数据和状态存储在同一个访问控制组中的资源中,因为它们不会被其他分区访问。然而,在Cornus中,数据和状态存储在单独的访问控制组中,因此LogOnce()必须使用两个而不是一个远程日志记录请求。因此,Cornus在日志准备阶段花费的时间比2PC多约9.48 ms(图5f),并且没有任何改善。我们得出的结论是,当前版本的Azure Blob不能从Cornus中受益,因为应用程序需要在数据和事务状态之间进行单独的访问控制。
5.3 Percentage of Read-only Transactions
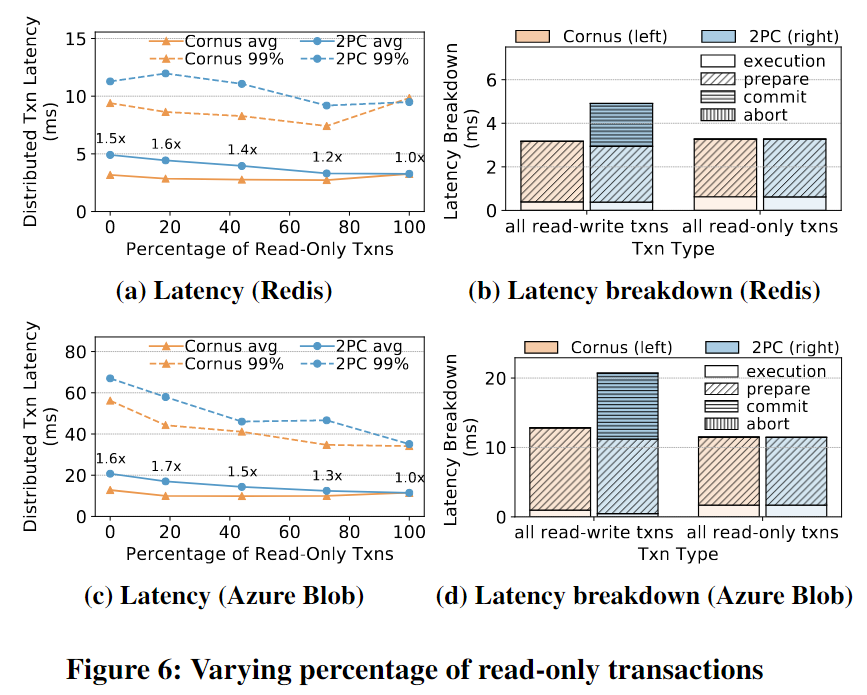
用不同比例的只读事务来评估Cornus在YCSB下的性能。通过控制在一个事务中读取每个请求的概率来管理只读事务的百分比。每个事务有n个request,每个request有p的概率是读。read-only的比例是 n p n^p np。预期结果是Cornus只在读写事务上获得延迟加速,因为Cornus和2PC都省略了只读事务的准备和提交阶段(没啥改进)。
Cornus的改进(相对于2PC)随着只读事务百分比的减少而增长。当有更多的读写事务时,Cornus在2PC上将平均和P99延迟都提高了1.7倍。
这个结果可以用图6b和图6d所示的延迟分解来解释。Cornus通过消除commit phase来改善读写事务的延迟,提交阶段需要花费大量时间,特别是在具有地理分布和同步复制的Azure Blob中。由于Log( )和LogOnce( )之间的细微差异,Cornus在准备阶段花费的时间比2PC稍微多一些。
5.4 Contention
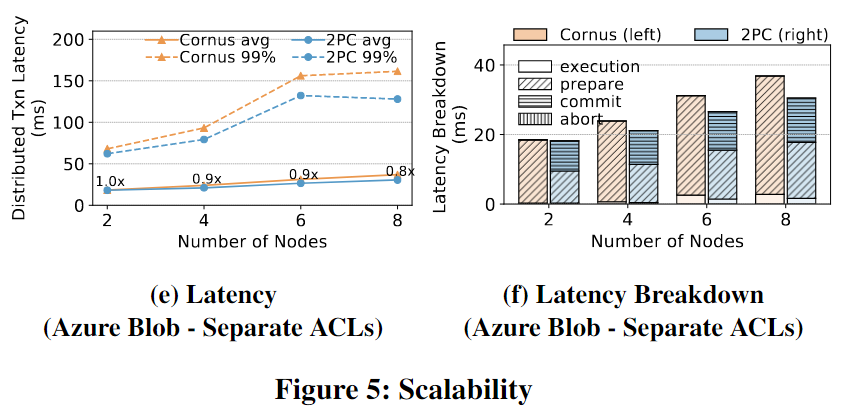
使用YCSB和TPC-C工作负载评估了Cornus在不同contention下的性能。对于YCSB,增加 θ \theta θ来增加contention。对于TPC-C,我们改变仓库warehouses的数量;仓库warehouses越少表明工作负载中的争用越高。
从左到右的x轴表示YCSB和TPC-C的争用从低到高。Cornus总是改善了Latency,在YCSB上改善1.8x,在TPC-C上改善1.9x。
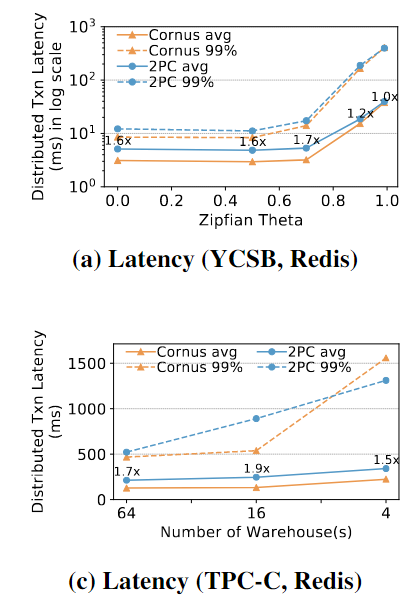
在高争用情况下,Cornus提供的改进较少,因为中止时间占总事务运行时间的大部分。
5.5 Time to Terminate Transactions on Failure
在触发终止协议后在Cornus中运行该协议所需的时间:
在2PC中,运行终止协议的时间没有限制——陷入不确定状态的事务(由于协调器在将决策发送给任何参与者之前失败)将被无限期阻塞,直到协调器恢复。而在Cornus中,计算节点故障不会导致阻塞。
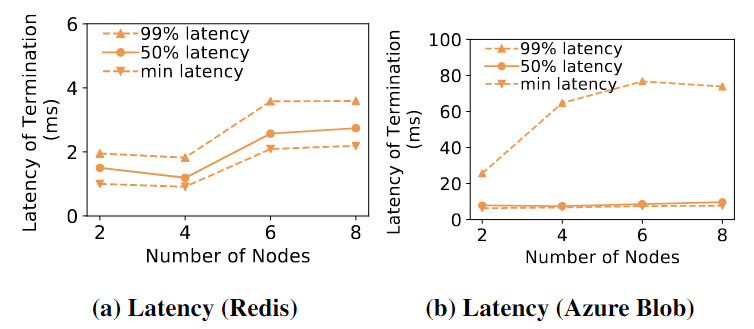
对于Redis, Cornus总是在4毫秒内终止事务,而对于Azure Blob, Cornus平均在20毫秒内终止事务。随着节点数量的增加,Azure Blob的尾部延迟比Redis增加得更多。这是由于Azure中的地理分布设置和一些同步复制,而Redis的两个副本位于同一区域,并且只执行异步复制
5.6 2PC Optimizations
评估并且比较常见的2PC优化with Cornus,看看是否适用于Cornus以及相比之下的效果。
Speculative Precommit
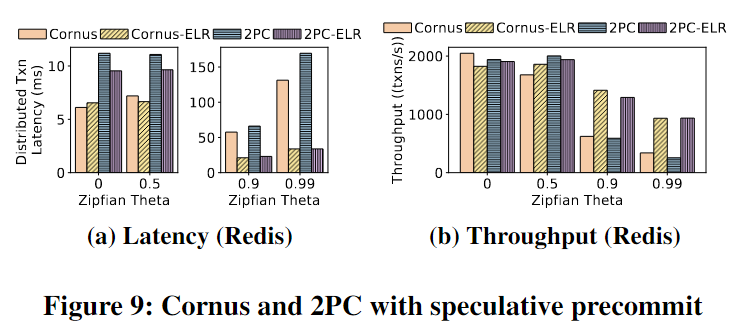
第一个优化是推测性地假定在准备阶段会commit提交。此优化假设进入准备阶段的事务不太可能因系统崩溃而中断。因此,事务可以允许其他事务读取其预提交的数据,同时等待日志持久化。
这种2PC的优化同样适用于Cornus。基于悲观并发控制实现Cornus-ELR,2PC-ELR。Early Lock Release (ELR)。使用Azure Redis作为远程存储。ELR特别是在工作负载争用高的情况下可以显著改善2PC和Cornus。Cornus和2PC的吞吐量分别提高了175%和267%(theta = 0.99时)。通过优化,在高争用情况下,Cornus和2PC在吞吐量和延迟方面的差异减小,因为争用成为主要因素。使用PCC+ELR的方式。
对于在准备阶段很少崩溃的系统,可以将此技术应用于Cornus,以进一步提高高争用下的性能。
Coordinator Log
另一个常见的2PC优化是让协调器代表所有参与节点进行日志记录,这样事务就不必等待其他节点持久化日志。
本文的实现:要求协调器在准备阶段记录所有分区的日志。同时,我们向参与者发送准备请求,参与者在不记录的情况下回复他们的投票。在收到投票后,协调器做出决定并将其附加到其日志中。
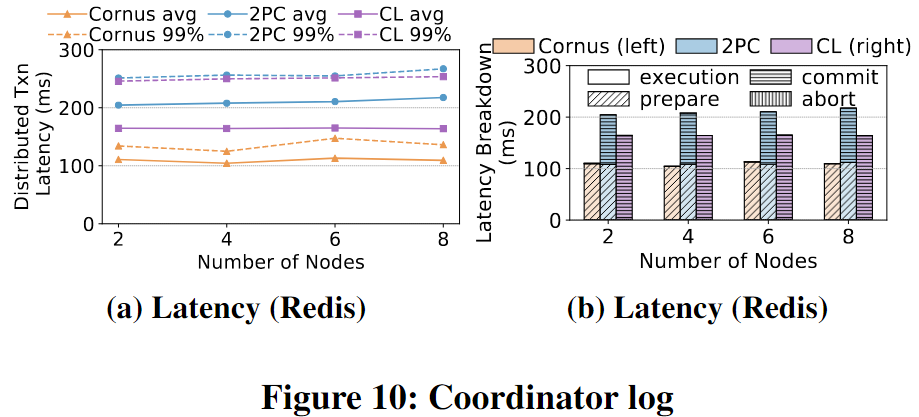
与2PC或Cornus相比,协调器日志优化有几个限制。首先,它增加了确认消息的大小。其次,它增加了恢复的复杂性,并引发了安全问题。具体来说,它违反了站点自治site autonomy,因为站点自治要求有关事务本地执行的内部信息(如日志记录)对站点保持私有,不能导出。尽管包括Cornus在内的一些工作允许其他站点访问事务状态的日志,但其他站点不会访问Cornus中的实际用户数据?
Integration with Replication Protocol
许多先前的工作与复制协议共同设计2PC,以进一步优化。虽然这些协议不能直接应用于现有的存储服务,但仍然对它们进行了评估,以显示在不同假设下的潜在优化空间。
首先对协议与Paxos结合的预期延迟进行了理论评估。下表显示了rtt数——从协调器启动协议到可以将决策返回给用户。A + B = C (A)准备阶段的rtt数量,(B)提交阶段的rtt数量,以及©总和。
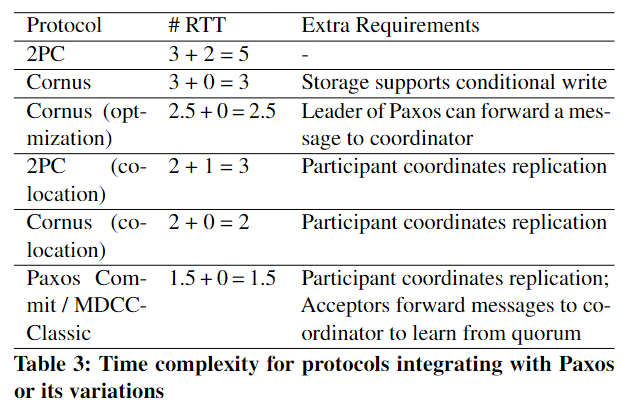
对于2PC和Cornus,我们假设每个进程(协调器/参与者)在底层存储中运行一个Multi-Paxos实例。当参与者向存储发送日志请求时,它将其发送给Paxos实例的leader,该leader指的是已经运行阶段1成为稳定leader的proposer。然后,leader使用一个RTT发起第二轮Paxos,然后返回给参与者。Cornus可以从对应于2个rtt(一个用于与Paxos领导者通信的参与者,另一个用于第二轮Paxos)的关键路径中消除协调器日志记录。
表中说的是rtt数——从协调器启动协议到可以将决策返回给用户。
2PC的prepare phase rtt=3:协调者给参与者,参与者给存储服务(具体是Multi-Paxos的leader)leader进行paxos,总共3rtt,commit phase是协调者给存储服务 + leader paxos 两个rtt,总共五个。
Cornus就是少了commit phase。
Cornus(optimization):通过将消息转发到协调器,可以节省从Paxos领导者到参与者的日志确认延迟(0.5 RTT)。此优化要求存储能够将消息发送给额外的收件人,但复制细节仍然完全由存储处理。(讲的时候画个图?
Cornus (co-location)和2PC (co-location)代表了参与者与Paxos leader共同定位的设计,即参与者通过直接与所有副本对话来启动第二轮Paxos,而不是通过先给leader发然后leader再给follower发。~~文中说的是节省了leader和其他follower的rtt,但是我感觉实际是节省了participant和leader的rtt。~~有点像leader上提,总之,2PC:prepare 2个RTT(coordinator→participant(leader), leader→存储服务上的follower),commit phase: 1 rtt(coordinator也是paxos leader → followers on storage service)。
Paxos Commit and MDCC。在准备阶段,参与者直接与所有接收方对话以进行日志记录,所有接收方将日志记录确认转发给协调器。然后协调器从quorum中学习所有的投票。与Cornus相比,它可以为leader→replicas副本间通信节省1 RTT(co-location),为从Paxos发送到协调器的日志确认节省0.5 RTT(optimization 转发)。但是,它也具有所有相应的需求,包括参与者/协调器协调复制和接收方将日志确认转发给协调器。
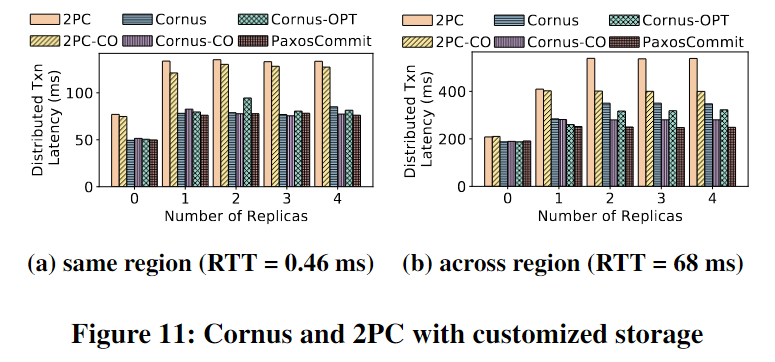
在两种情况下运行该实验——一种情况是所有副本都在同一区域(图11a),另一种情况是副本分布在美国的各个区域。从美东到美西(图11b)。这组实验证明了将存储作为一个具有共识不可知抽象的黑盒可能会牺牲多少性能,以及协同设计具有不同程度共识协议和2PC协议的潜在优化空间。
6 Related Work
介绍优化2PC的相关工作。我们将之前的工作分为三类:减少延迟的技术,解决阻塞的技术,以及解决这两个问题的2PC和复制的协同设计codesign of 2PC and replication。
6.1 Techniques Reducing Latency
-
Centralized Logging
集中式日志记录要求协调器代表所有参与者记录日志,以减少延迟。
协调器日志[A low-cost atomic commit protocol,Coordinator log transaction execution protocol****]****隐含的赞成投票[Y Al-Houmaily and P Chrysanthis. 1995. Two-phase commit in gigabit-networked distributed databases. In Int. Conf. on Parallel and Distributed Computing Systems (PDCS).],以及Lee和Yeom的协议[Inseon Lee, and H. Y. Yeom. “A Single Phase Distributed Commit Protocol for Main Memory Database Systems.]主要思想是让每个参与者将其日志及其对其准备请求的确认发送给协调器。协调器将这些确认与提交决策一起强制写入其日志,以便消除准备阶段的日志记录延迟。这些设计增加了确认的大小,增加了恢复的复杂性,并且由于违反了站点自主权而引起了安全问题。
-
Early Prepare During Execution
减少2PC延迟的技术是让参与者在执行期间进行准备,这样事务就可以在提交时跳过准备阶段。许多先前的工作都采用了这个想法来减少提交延迟。
in Early Prepare (EP):在执行期间接收到工作请求时,每个参与者在回复协调器之前force a prepare record。它还要求协调器在发送工作请求之前在日志中记录参与者的身份。但是,如果事务访问多个分区,或者每个分区的工作请求不能批处理到一个请求中,EP需要在关键路径上比2PC记录更多的log record。
为了解决这个问题,后续的工作尝试将这种技术与集中记录或分散决策centralized logging or decentralized decision.结合起来。
-
Speculative Pre-Commit
如果已经进入准备阶段的事务不太可能由于系统崩溃而中止,则数据库可以推测地假定在准备阶段提交。事务可以让其他事务读取其预提交的数据,同时等待日志持久化。
6.2 Techniques Addressing Blocking
-
Extra Network Roundtrip
Skeen给出了正确的无阻塞提交协议的充分必要条件,称为基本无阻塞定理。它证明了除了初始化、等待、中止和提交之外,还可以添加第五种状态来避免阻塞,这与2PC中的假设相同。添加此状态需要再进行一次网络往返,从而形成一个三阶段提交(3PC)协议。虽然它解决了阻塞问题,但3PC放大了2PC的延迟问题。
-
Extra Message Count
一些协议通过要求每个站点在接收消息时广播消息来减少阻塞的机会。EasyCommit通过要求每个参与者在记录决策之前将其转发给其他参与者来解决阻塞问题。但是,只有当至少有一个参与者在发送方将决策刷新到其日志之前接收到转发的消息时,协议才满足原子提交属性。它还会在正常执行期间引入额外的消息,并在发生故障时增加复杂性。Babaoglu和Toueg提出了一种基于2PC的非阻塞原子提交协议。它采用三种策略:(1)同步不同站点上的时钟,以便忽略超时消息;(二)由参与者在收到协调者的信息后,将决定转发给其他参与者;(3)在超时的时候假定中止而不是运行终止协议。该协议在没有故障的情况下引入了更多的通信,并且该算法依赖于同步时钟,这是实际应用程序的一个重要需求。
6.3 Co-design of 2PC and Replication
Gray和Lamport提出了Paxos Commit,它是一个优化2PC和Paxos的理论框架,具有优化空间。它提出了一些特定于Paxos的优化,如pre-preparing acceptors and piggybacking messages of 2PC and Paxos.一些实现遵循了Paxos Commit的精神,并根据他们的场景进行了调整。
Multi Data Center Consistency (MDCC):它假设资源管理器和Paxos领导者位于同一站点上,以便它可以将Paxos的消息与2PC请求一起承载,以节省消息往返。他们还提出了一个结合2PC和Fast Paxos的无领导版本。这个版本假设每个接受者都可以独立地执行乐观并发控制的冲突检测,并产生相同的验证结果。当冲突很少时,它可以进一步减少延迟。此外,它通过使用更新意图(“选项”)而不是实际的更新来优化交换操作。update intents (“options”) instead of the actual updates.
TAPIR:它使用自定义的复制协议“不一致复制”来放松存储副本的一致性,并依赖于应用程序协议(application protocols?)来解决不一致性。Mahmoud等人提出了在不同数据中心运行2PC的Replicated Commit协议。它使用Paxos在数据中心之间达成共识,以确定是否应该提交事务…
最后,确定性数据库采用完全不同的方法来处理2PC和复制。确定性数据库不是将计算节点和存储服务视为水平分离的层,而是将集群垂直地划分为多个副本,并通过在所有副本中确定性地运行相同的输入事务来确保副本之间的一致性,从而产生相同的结果。确定性数据库还简化了2PC,因为只有事务的输入被持久化,并且在事务执行期间不会发生日志记录。与2PC和Cornus相比,确定性数据库有一些限制。例如,事务需要是一次性的(即,不能支持与DBMS的多个交互);事务必须分批运行,这样单个长时间运行的事务会延长整个批处理的响应时间;大多数确定性数据库(除了Aria[)需要在执行之前知道事务的读/写集。
7 CONCLUSION
提出了一种针对存储分解架构的2PC优化协议-Cornus。通过利用云数据库架构提供的新特性,Cornus解决了2PC中的长延迟和阻塞问题。证明了Cornus的正确性,并在包括Redis和Azure Blob storage在内的实际存储服务上对其进行了实验。对YCSB的评估显示,延迟方面的加速高达1.9倍。