数据结构-二叉查找树
前言
**摘自百度百科:**二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。二叉搜索树作为一种经典的数据结构,它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;所以应用十分广泛,例如在文件系统和数据库系统一般会采用这种数据结构进行高效率的排序与检索操作。
简而言之,二叉查找树(Binary Search Tree)又称为 二叉搜索树、二叉排序树。它是一种 对搜索和排序都有用的特殊二叉树。而 红黑树、AVL树 都是特殊的二叉树(自平衡二叉树)。
定义
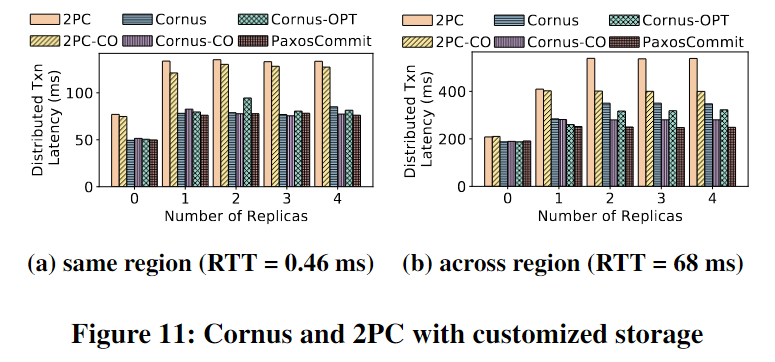
当一个二叉树为特殊二叉树时,势必会满足以下条件:
- 当其左子树不为空时,其左子树上所有的节点的值均小于根节点的值。
- 当其右子树不为空时,其右子树上所有节点的值均大于根节点的值。
- 该树上的所有子树(左右子树)均为一颗二叉查找树。
其结构如下图所示:
应用场景
-
电商系统的商品搜索与排序
-
秒杀系统中的库存管理
-
社交系统中的好友关系管理
-
文件系统中的目录和文件管理
-
图书管理系统中的书籍检索
以上应用场景只是举例说明,并不代表全部,二叉搜索树的应用场景非常广泛,当系统需要高效的执行:搜索、排序、插入、删除、范围查询等操作时均可考虑使用 二叉查找树。
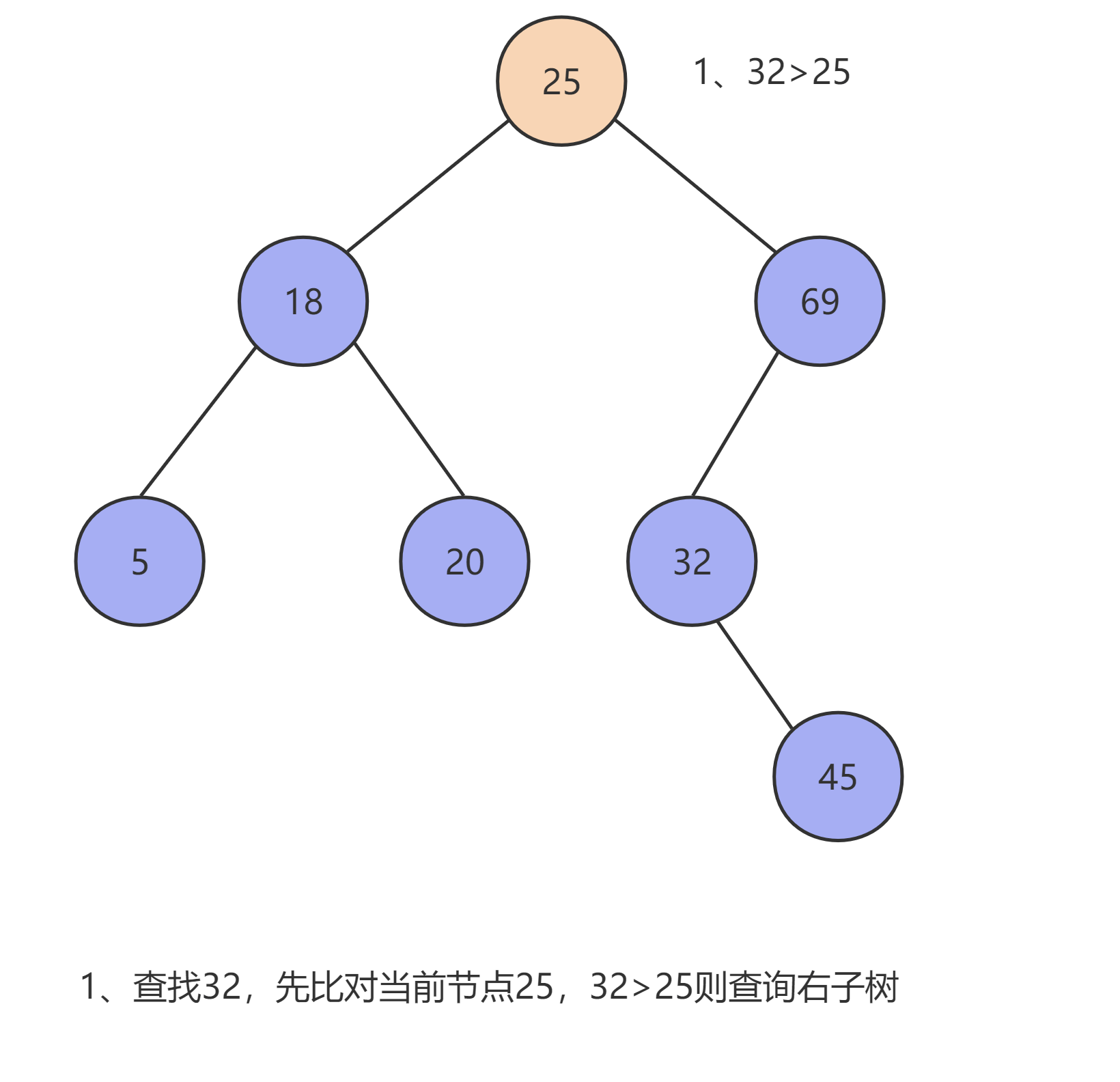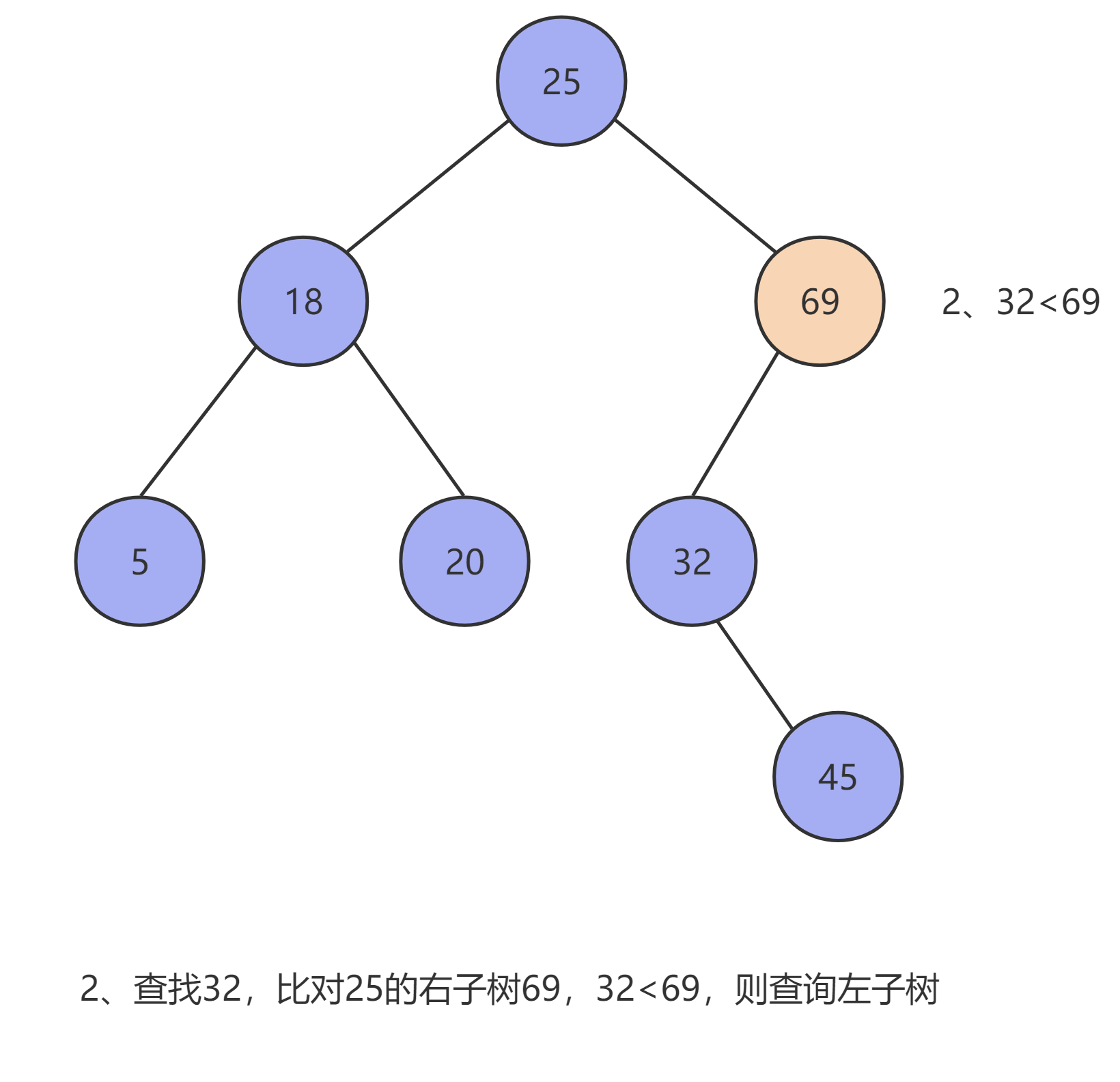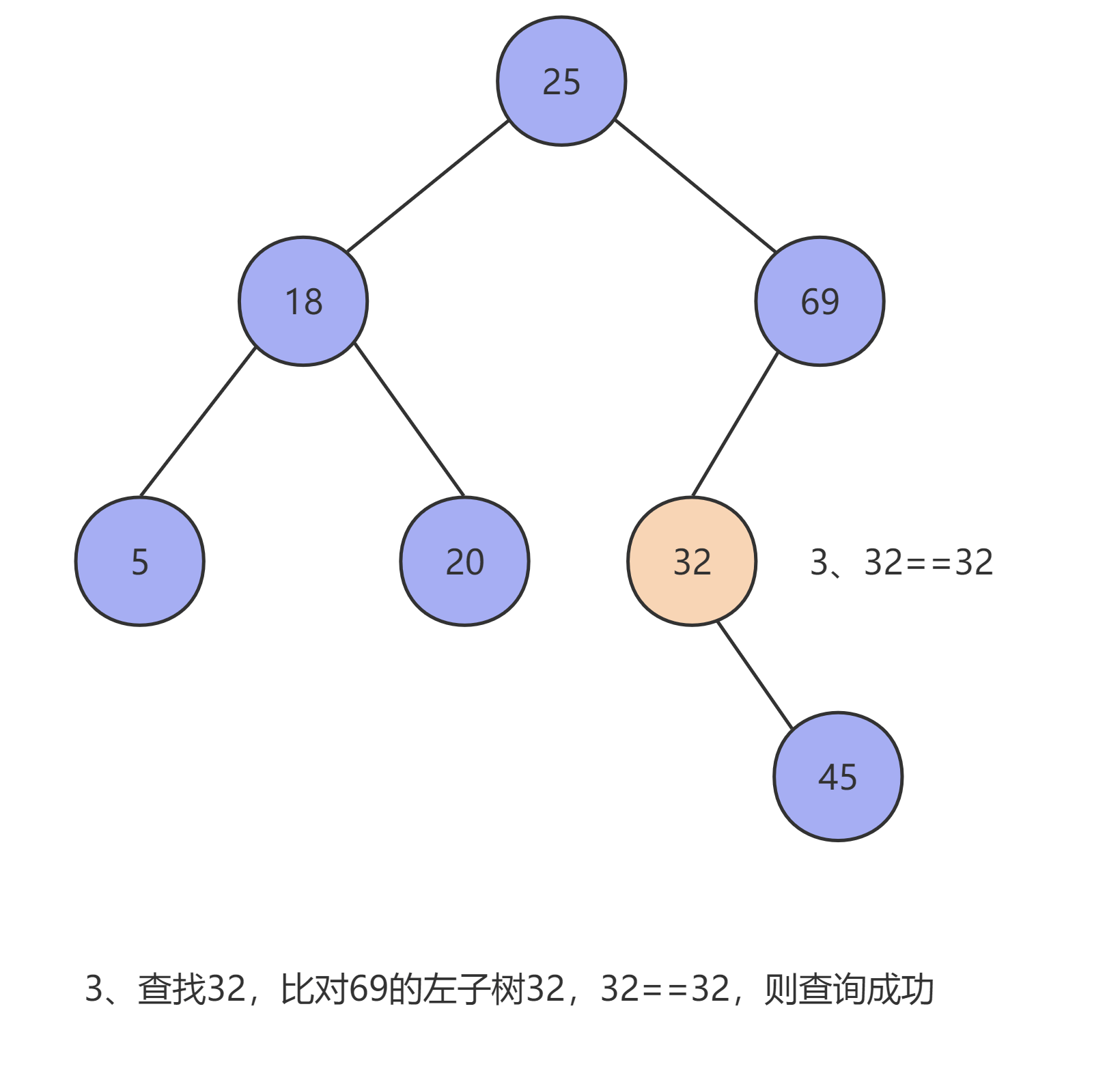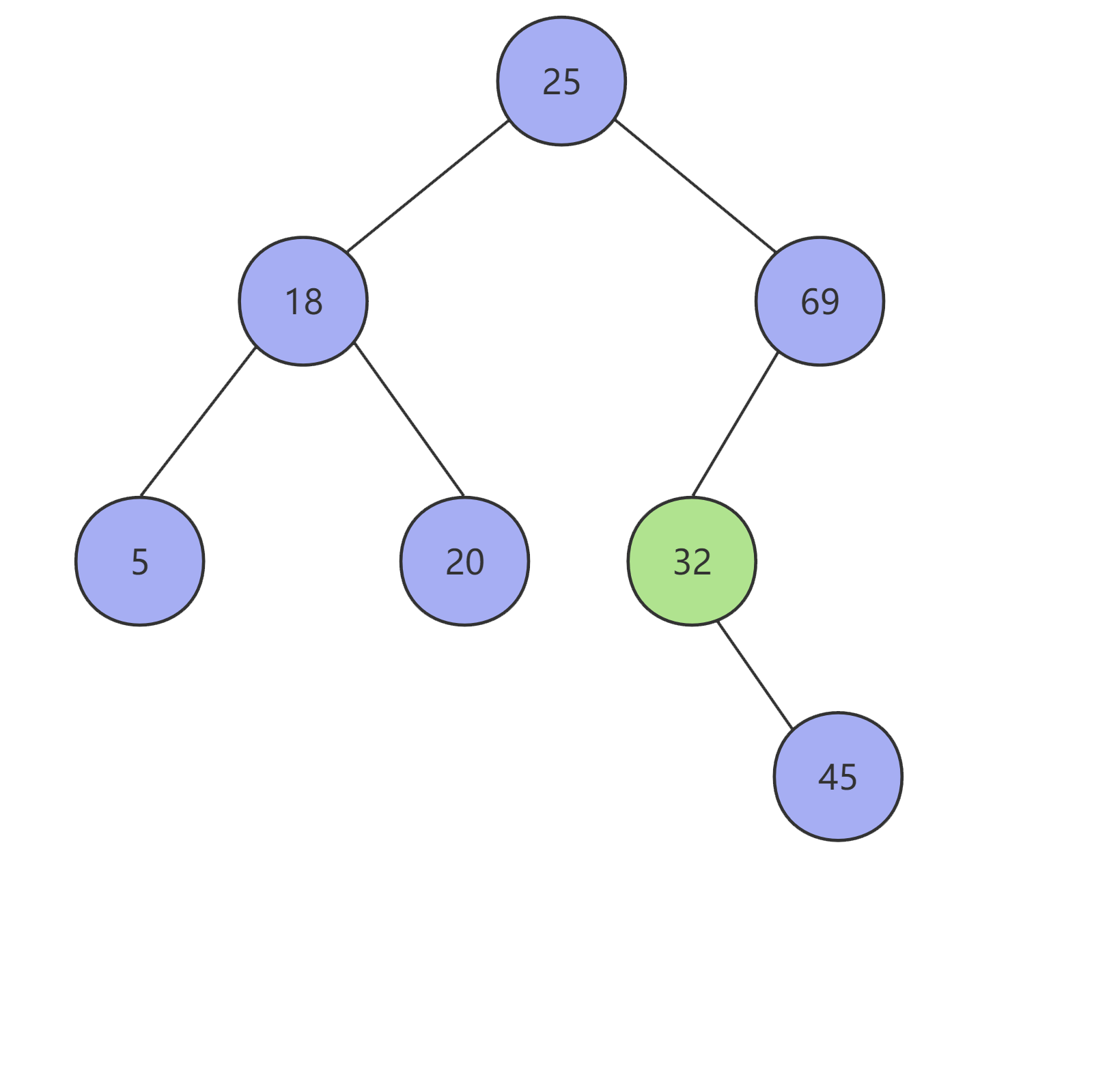
查询
在 二叉查找树 中,查询方式类似于 二分查找法,每次递归查询时都可以缩小一半的查找范围,其查询的速率也较高。
当使用 二叉查找树 去查找某条数据时(设这条数据为 x ,当前数据为 T ),其会按以下流程循环查询,直至查出结果,如果查到叶子节点仍无匹配数据时则返回 null :
- 当
x == T时,则T就是我们要查询的数据,返回T。 - 当
x < T时,则去查询当前节点的左子树进行比对。 - 当
x > T时,则去查询当前节点的右子树进行比对。
以上流程如下图所示:
实体
根据上述的二叉查找树的概念,我们可以抽离出来一个模型,代码如下:
public class Node {
public Integer data;
public Node parent;
public Node left;
public Node right;
public Node(){}
public Node(Integer data) {
this.data = data;
}
public Integer getData() {
return data;
}
public void setData(Integer data) {
this.data = data;
}
public Node getParent() {
return parent;
}
public void setParent(Node parent) {
this.parent = parent;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", parent=" + parent +
", left=" + left +
", right=" + right +
'}';
}
}
二叉查找树
建立好我们的实体后,我们可以单独创建一个类来进行二叉查找树的一些操作。
public class BinarySearchTree {
private final Logger log = Logger.getLogger(BinarySearchTree.class.getName());
private Node root;
/**
* @param data 需要查找的值
* @return {@link Node}
* @date 2023-09-16 10:53
* @author Bummon
* @description 二叉树查找
*/
public Node findDataByBTS(Node node, Integer data) {
while (Objects.nonNull(node)) {
if (Objects.equals(data, node.data)) {
return node;
} else if (data < node.data) {
//左子树
node = node.left;
} else if (data > node.data) {
//右子树
node = node.right;
}
}
return null;
}
}
测试
public class Main {
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
Node root = new Node(50);
Node node1 = new Node(30);
root.setLeft(node1);
Node node2 = new Node(70);
root.setRight(node2);
Node node3 = new Node(20);
node1.setLeft(node3);
Node node4 = new Node(40);
node1.setRight(node4);
Node node5 = new Node(60);
node2.setLeft(node5);
Node node6 = new Node(80);
node2.setRight(node6);
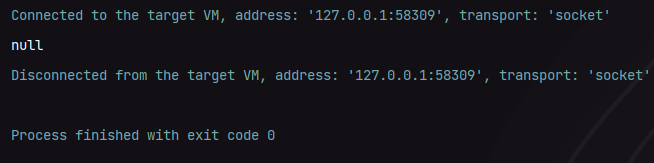
Node node = bst.findDataByBTS(root, 25);
System.out.println(node);
}
}
最终我们可以得到如下结果:
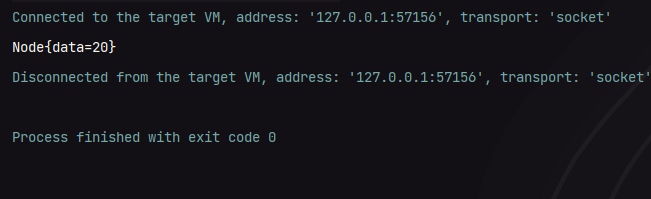
我们也可以去查找一个不存在的数据测试一下,这里使用25来测试,如下图所示:
新增
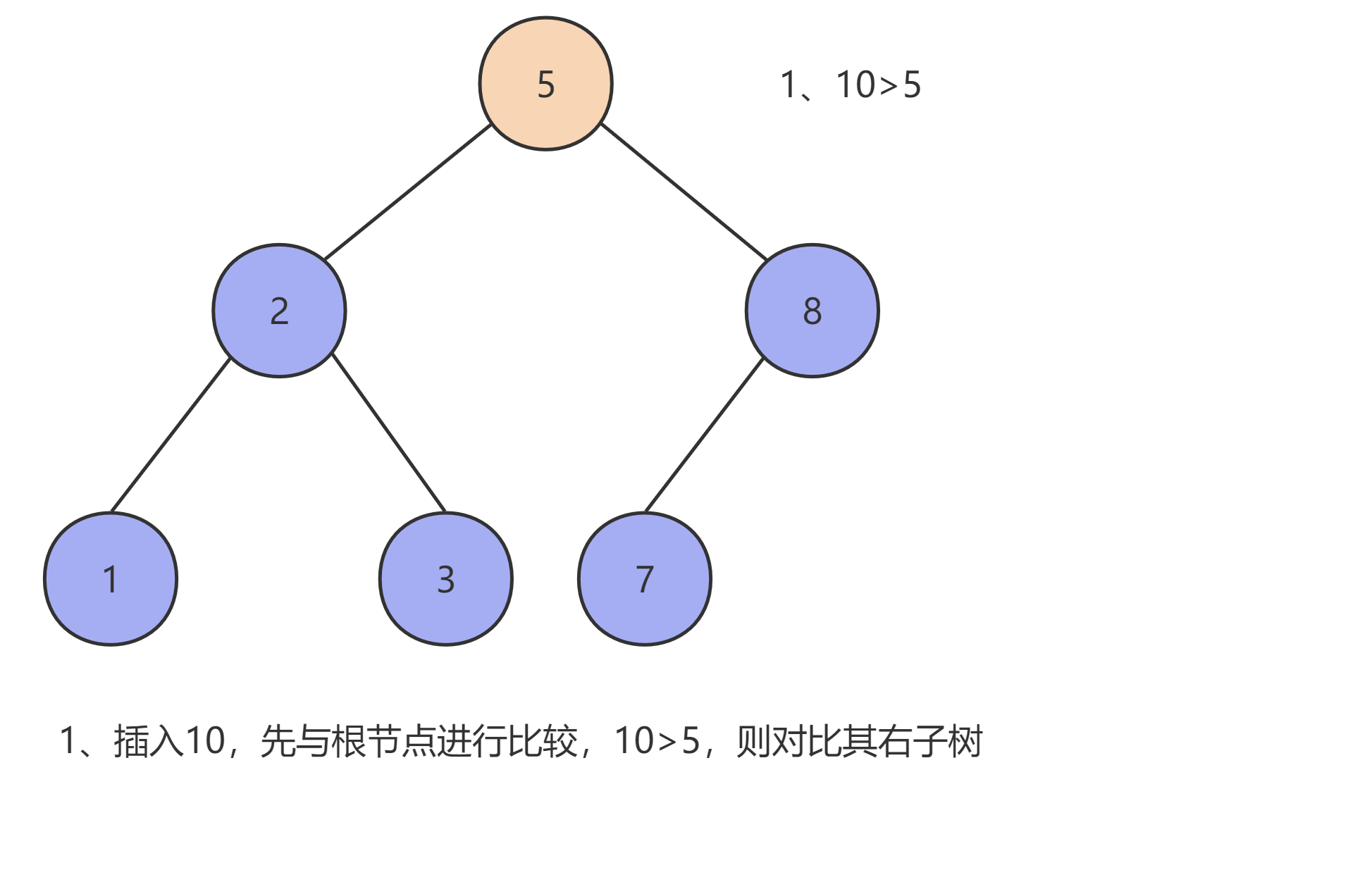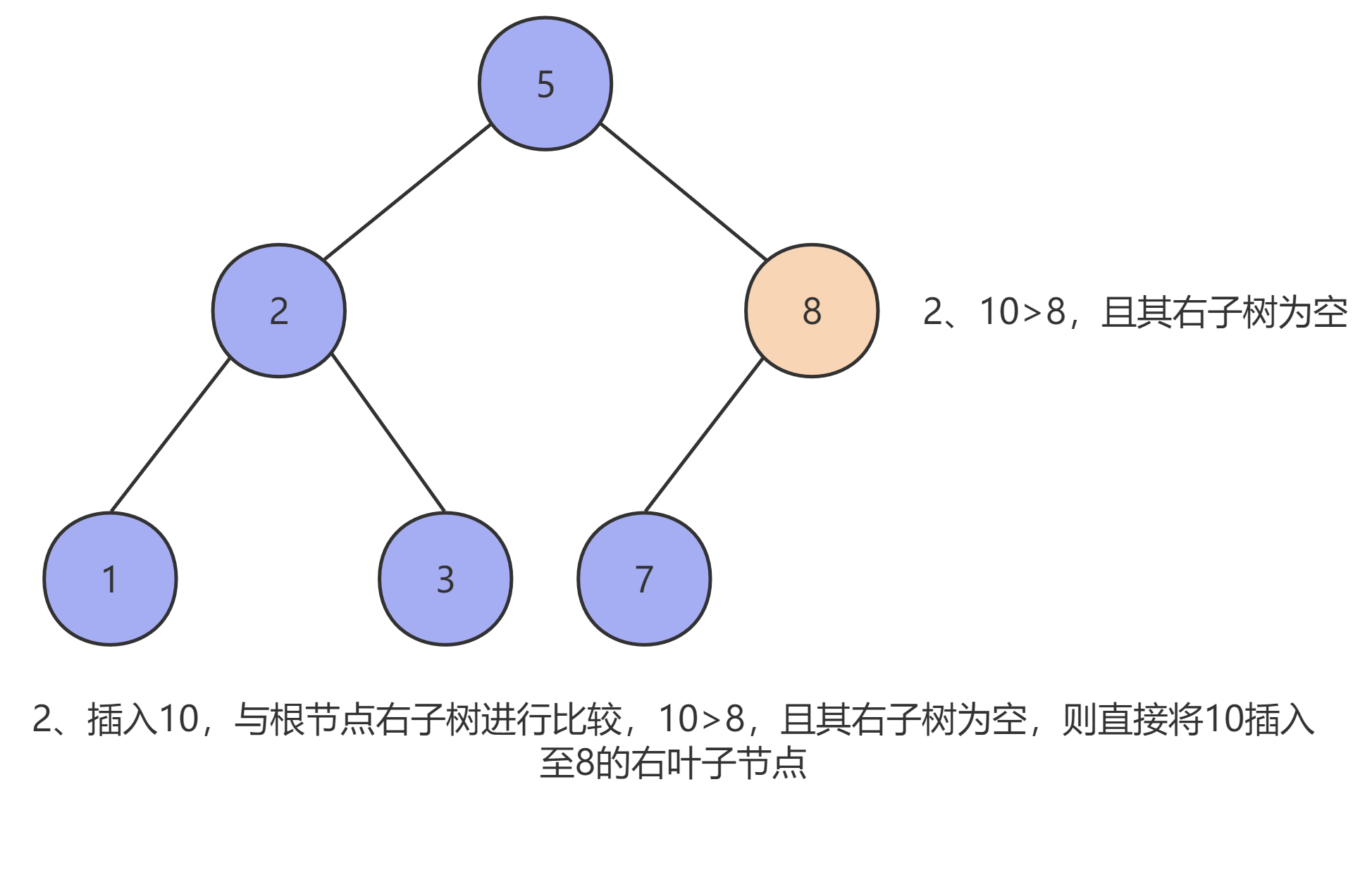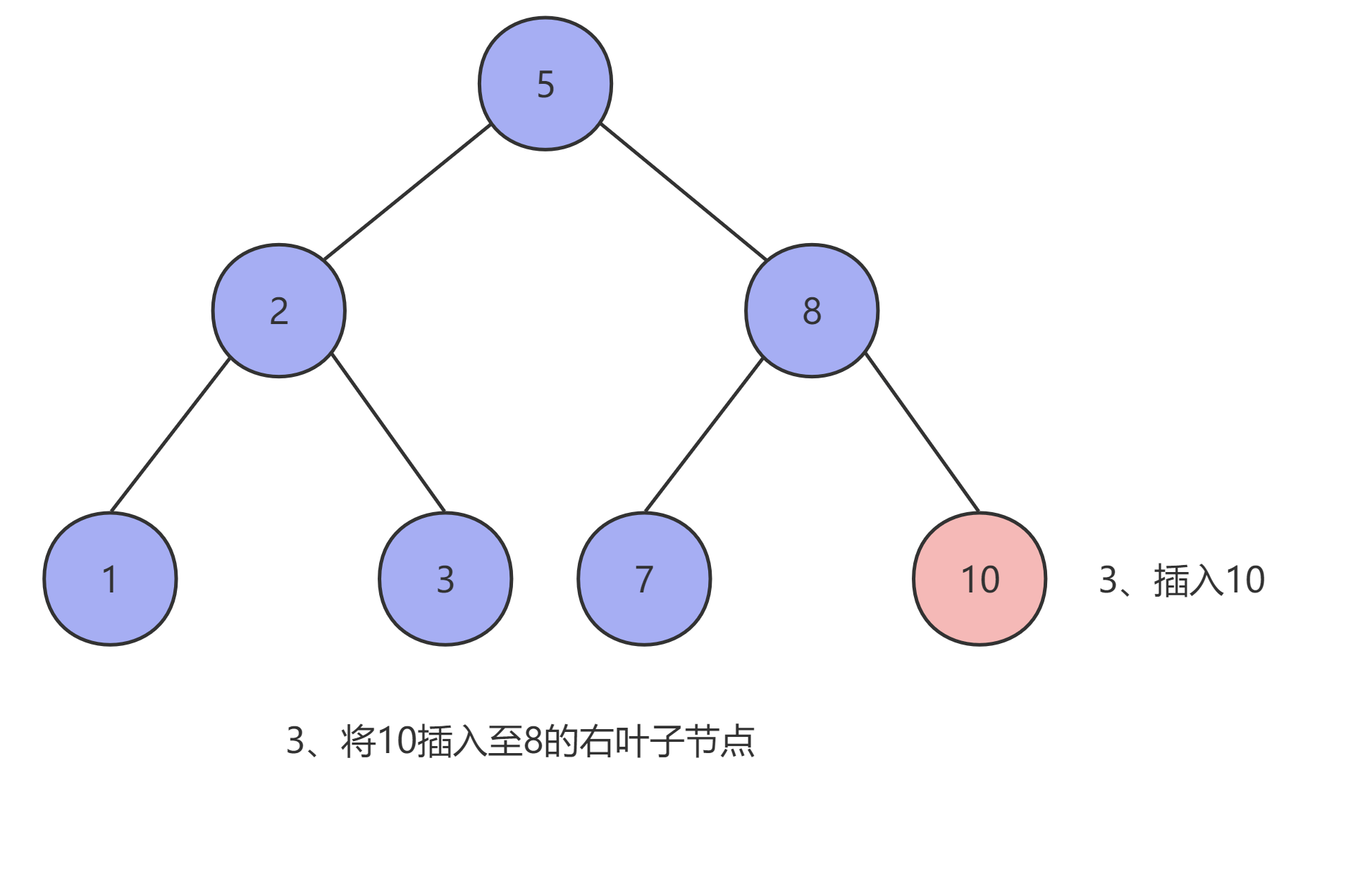
由于二叉查找树的特性,我们首先需要先找到插入元素的插入位置,设需要插入的元素为 x ,当前节点为 T ,则:
- 当二叉查找树为空时,创建一个新的节点,并将
x放到根节点的位置,且其 左子树 和 右子树 均为空。 - 当二叉树不为空且
x < T时,将x插入T的左子树中。 - 当二叉树不为空且
x > T时,将x插入T的右子树中。
如下图所示:
代码实现
为了方便测试这里也增加了一个分层遍历的方法
/**
* @param data 需要插入的值
* @date 2023-09-16 10:54
* @author Bummon
* @description 插入节点
*/
public void insert(int data) {
if (Objects.isNull(root)) {
root = initNode(root);
root.setData(data);
} else {
recursionInsert(root, data);
}
}
/**
* @param data 需要插入的值
* @date 2023-09-16 10:54
* @author Bummon
* @description 插入节点
*/
public void insert(int data) {
if (Objects.isNull(root)) {
root = initNode(root);
root.setData(data);
} else {
recursionInsert(root, data);
}
}
/**
* @param node 插入节点
* @param data 需要插入的值
* @return {@link Node}
* @date 2023-09-16 10:53
* @author Bummon
* @description 私有化插入节点
*/
private Node recursionInsert(Node node, int data) {
if (Objects.isNull(node)) {
node = new Node(data);
}
if (data < node.data) {
node.left = recursionInsert(node.left, data);
node.left.parent = node;
} else if (data > node.data) {
node.right = recursionInsert(node.right, data);
node.right.parent = node;
}
return node;
}
/**
* @param node 需要初始化的节点
* @return {@link Node}
* @date 2023-09-16 10:52
* @author Bummon
* @description 初始化节点
*/
private Node initNode(Node node) {
if (Objects.isNull(node)) {
return new Node();
}
return node;
}
/**
* @date 2023-09-16 14:18
* @author Bummon
* @description 分层遍历树
*/
public void levelOrderTraversal() {
Queue<Node> nodes = new ConcurrentLinkedDeque<>();
nodes.add(root);
while (nodes.size() > 0) {
Node currNode = nodes.poll();
if (Objects.nonNull(currNode.left)) {
nodes.add(currNode.left);
}
if (Objects.nonNull(currNode.right)) {
nodes.add(currNode.right);
}
String msg = String.format("{%s}(%s)", currNode.data, currNode.parent != null ? currNode.parent.data : "null");
log.info(msg);
}
}
测试
public class Main {
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
bst.insert(50);
bst.insert(30);
bst.insert(20);
bst.insert(40);
bst.insert(70);
bst.insert(60);
bst.insert(80);
bst.levelOrderTraversal();
}
}
我们执行的结果如下:
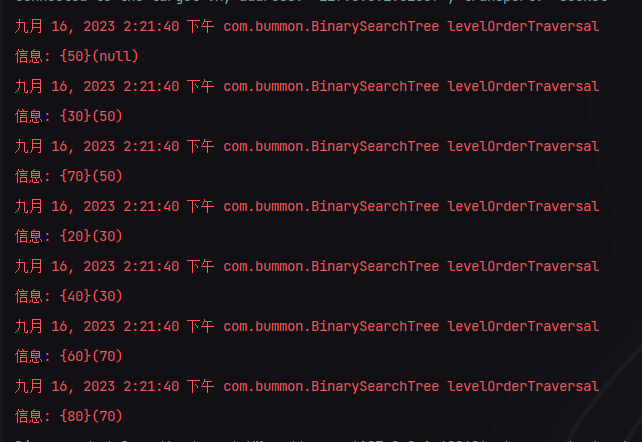
如果以树的形式来展示的话长以下这样:
删除
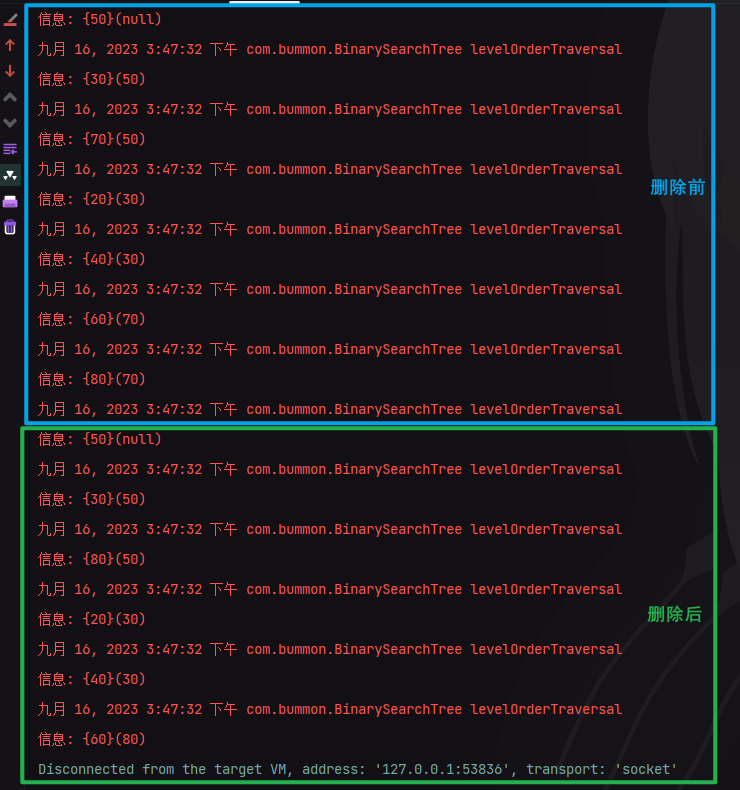
当我们想要从二叉查找中删除某个节点时,会经历以下历程:首先先要查找到我们要删除的节点位置,如果查找成功则继续执行删除操作,否则直接返回。而删除操作会有以下四种情况:
- 当被删除的节点左右子树均为空时,则直接删除即可。
- 当被删除的节点只有左子树时,即右子树为空,则直接删除,并将其左子树的节点代替被删除的节点,代替后删除其左子树原先的节点。
- 当被删除的节点只有右子树时,即左子树为空,则直接删除,并将其右子树的节点代替被删除的节点,代替后删除其右子树原先的节点。
- 当被删除的节点左右子树均不为空时,则将其直接前驱或直接后续作为替代节点,将被删除的节点删除后,将替代节点放至被删除的节点位置,代替后删除替代节点原先的节点。
如下所示:

代码实现
public void deleteNode(int data) {
if (root == null) {
System.out.println("删除失败,为空树");
}
Node delNode = root;
Node parent = null;
//首先要先找到待删除的节点
while (delNode != null) {
if (data < delNode.data) {
parent = delNode;
delNode = delNode.left;
} else if (data > delNode.data) {
parent = delNode;
delNode = delNode.right;
} else {
break;
}
}
if (delNode == null) {
log.info("Not Found " + data);
return;
}
//删除节点左子树为空
if (delNode.left == null) {
if (delNode == root) {
root = delNode.right;
} else if (delNode == parent.left) {
parent.left = delNode.left;
} else {
parent.right = delNode.right;
}
} else if (delNode.right == null) {
//删除节点右子树为空
if (delNode == root) {
root = delNode.left;
} else if (delNode == parent.left) {
parent.left = delNode.left;
} else {
parent.right = delNode.left;
}
} else {
//删除有节点左右子树均不为空
Node nextParent = delNode;
Node next = delNode.right;
while (next.left != null) {
nextParent = next;
next = next.left;
}
delNode.data = next.data;
if (nextParent == delNode) {
nextParent.right = next.right;
} else {
nextParent.left = next.right;
}
}
}
测试
public class Main {
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
bst.insert(50);
bst.insert(30);
bst.insert(20);
bst.insert(40);
bst.insert(70);
bst.insert(60);
bst.insert(80);
bst.levelOrderTraversal();
bst.deleteNode(70);
bst.levelOrderTraversal();
}
}
我们会得到如下结果:
总结
二叉查找树 是一种特殊的二叉树,其搜索速率较快,类似于 二分查找法 ,其在查询时先确定查找值的查询范围,再逐步缩小范围,直至查出结果或查完所有节点仍未找到返回 null 。其最坏情况为遍历所有节点,即时间复杂度为 O(n),空间复杂度为 O(1)。
推荐
关注博客和公众号获取最新文章
Bummon’s Blog | Bummon’s Home | 公众号