- T5
- Architecture:The Best One
- 1. Main Body
- 2. Embedding
- 3. Pertrain and Finetune
- 4. Multi-Task Pertrain and Finetune
- 5. T5总结
- mT5
T5:
https://arxiv.org/pdf/1910.10683.pdf
T5 blog:https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
mT5:https://arxiv.org/pdf/2010.11934.pdf
mT5 code:https://github.com/google-research/multilingual-t5
T5
T5 (Transfer Text-to-Text Transformer),Transfer 来自 Transfer Learning,预训练模型大体在这范畴,Transformer 也不必多说,那么 Text-to-Text 是什么呢。那就是作者在这提出的一个统一框架,靠着大力出奇迹,将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。
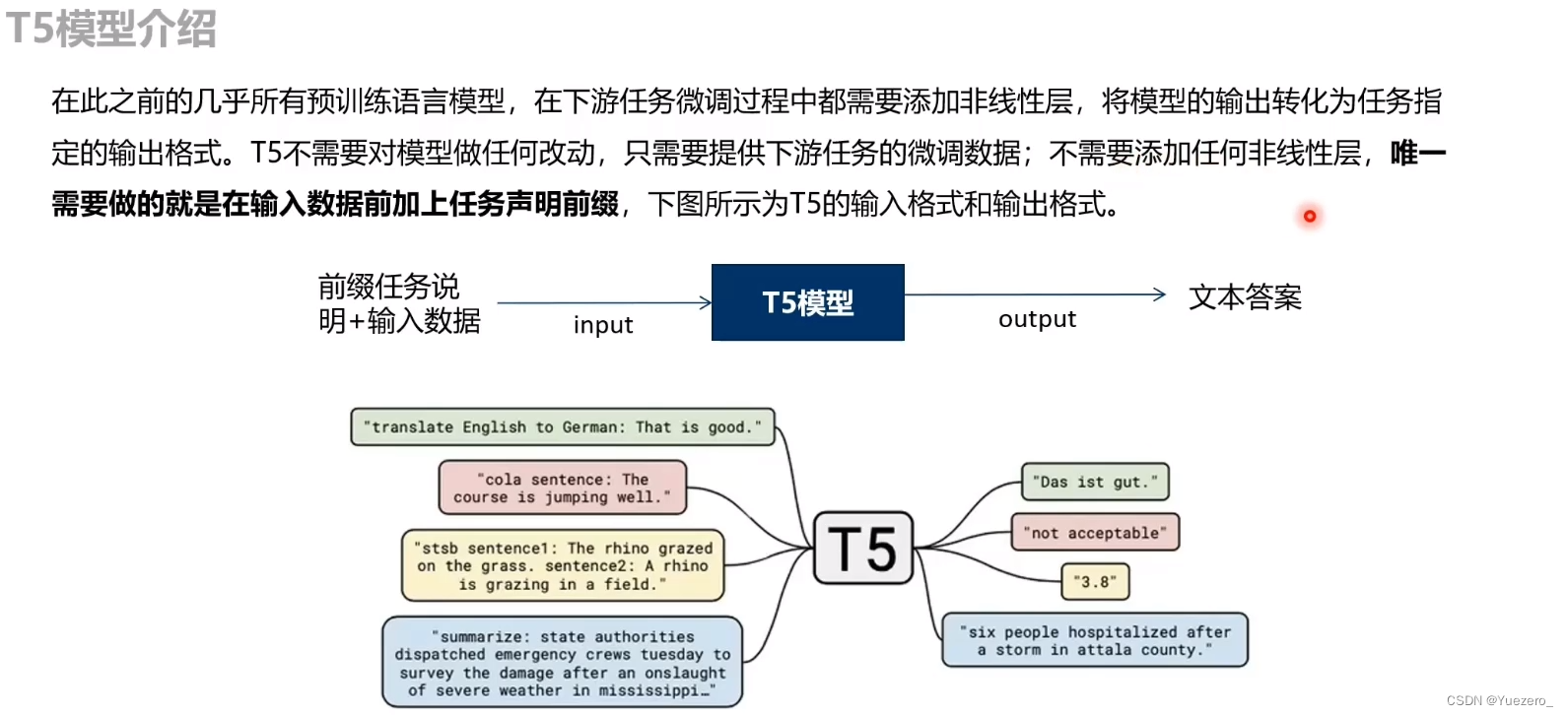
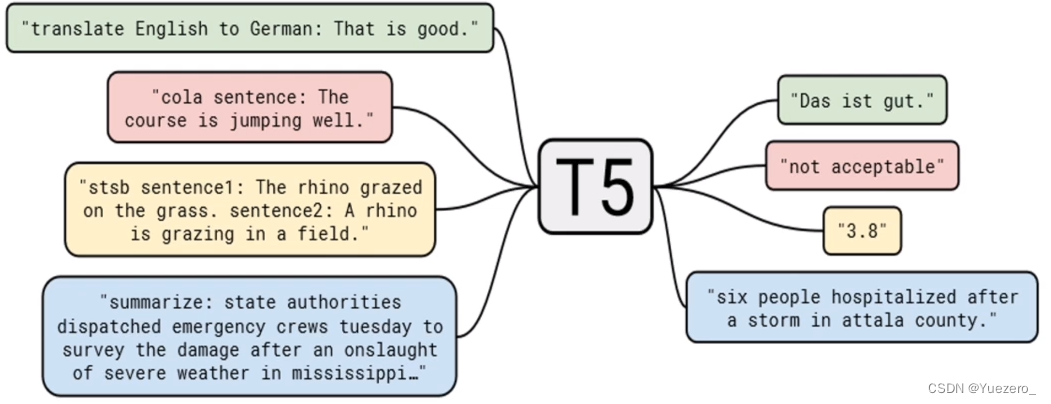
举几个例子就明白了,比如英德翻译,只需将训练数据集的输入部分前加上“translate English to German(给我从英语翻译成德语)” 就行。假设需要翻译"That is good",那么先转换成 “translate English to German:That is good.” 输入模型,之后就可以直接输出德语翻译 “Das ist gut.”
再比如情感分类任务,输入"sentiment:This movie is terrible!",前面直接加上 “sentiment:”,然后就能输出结果“negative(负面)”。
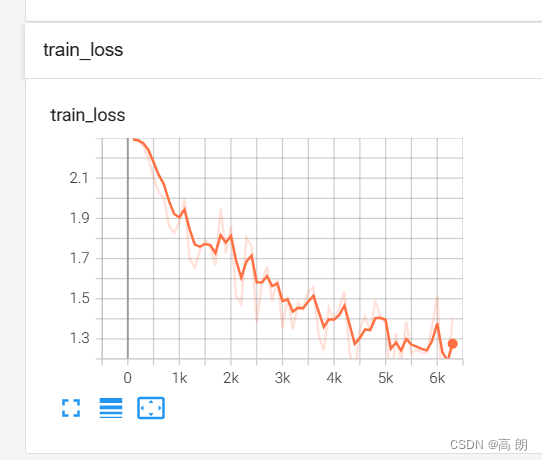
最神奇的是,对于需要输出连续值的 STS-B(文本语义相似度任务),居然也是直接输出文本,而不是加个连续值输出头。以每 0.2 为间隔,从 1 到 5 分之间分成 21 个值作为输出分类任务。比如上图中,输出 3.8 其实不是数值,而是一串文本,之所以能进行这样的操作,应该完全赖于 T5 模型强大的容量。
T5将任务指令设定在输入文本中,就不需要针对每类任务单独设置特定的FC输出层,所有任务都输出text。对于生成任务(例如机器翻译或文本摘要)很自然,因为任务格式要求模型生成以某些输入为条件的文本。对于分类任务,这是很不寻常的,其中训练T5输出 文本label (例如,用于情感分析的“正”或“负”)而不是类别索引。
通过这样的方式就能将 NLP 任务都转换成 Text-to-Text 形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。其实这个思想之前 GPT2 论文里有提,上斯坦福 cs224n 时 Socher 讲的 The Natural Language Decathlon 也有提。
Architecture:The Best One
一句话总结:T5就是对大型的seq2seq的Transformer结构上做微小改动,进行多任务预训练+微调,把所有NLP任务(翻译、分类、摘要、相似度)转化为text-to-text任务(加入prompt embedding)。
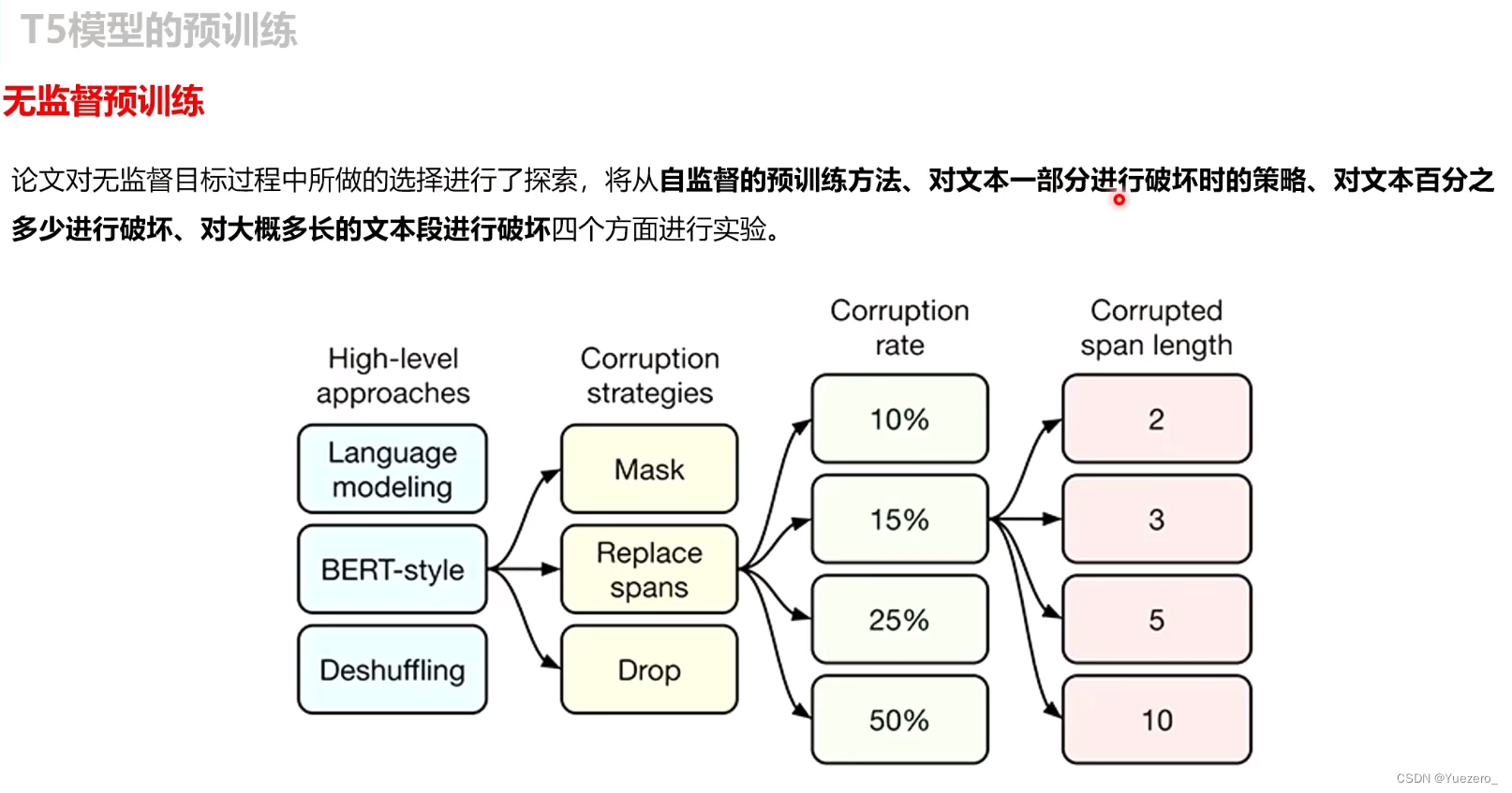
通过大量实验探索最佳的结构与训练方案:
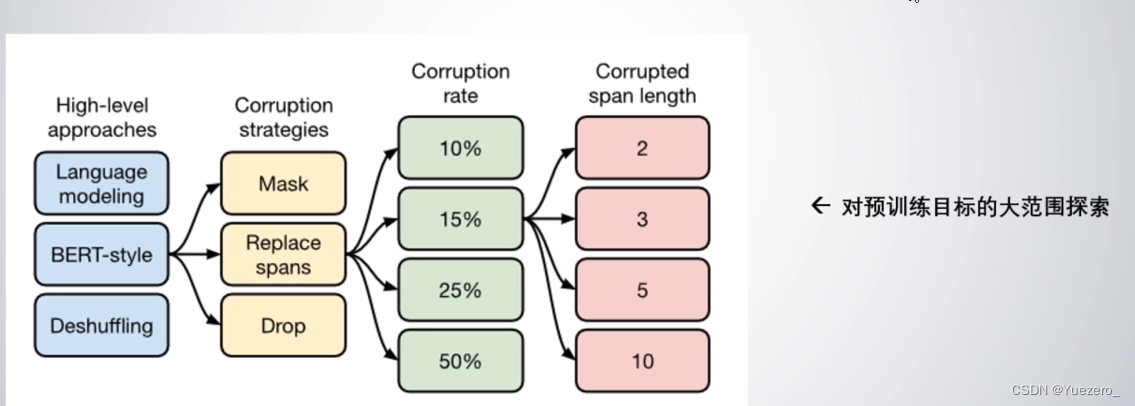
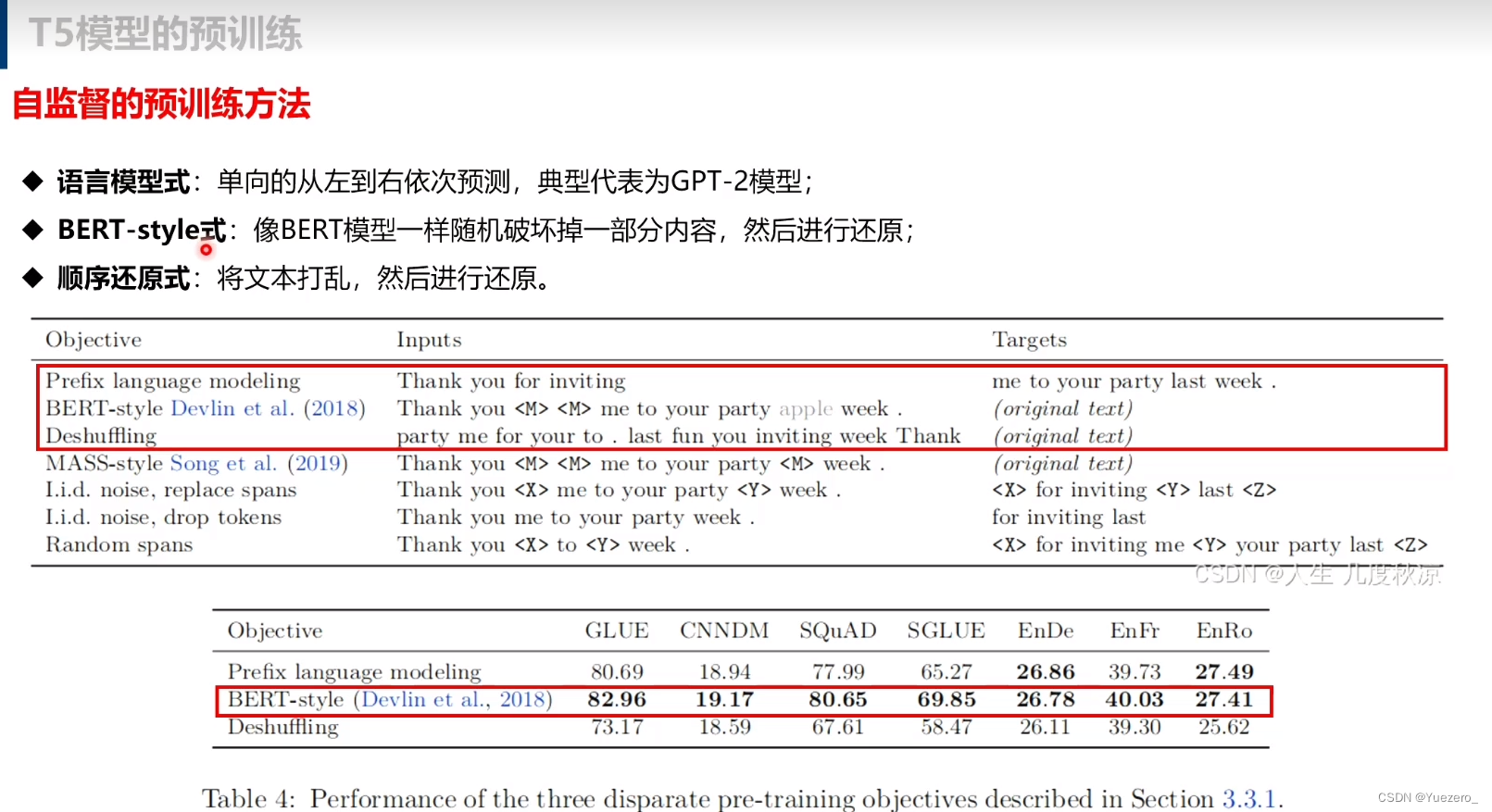
- 不同模型结构比较,LM,BERT-style,Deshuffling,BERT-style的encoder-decoder模型一般比decoder-only(LM)好;
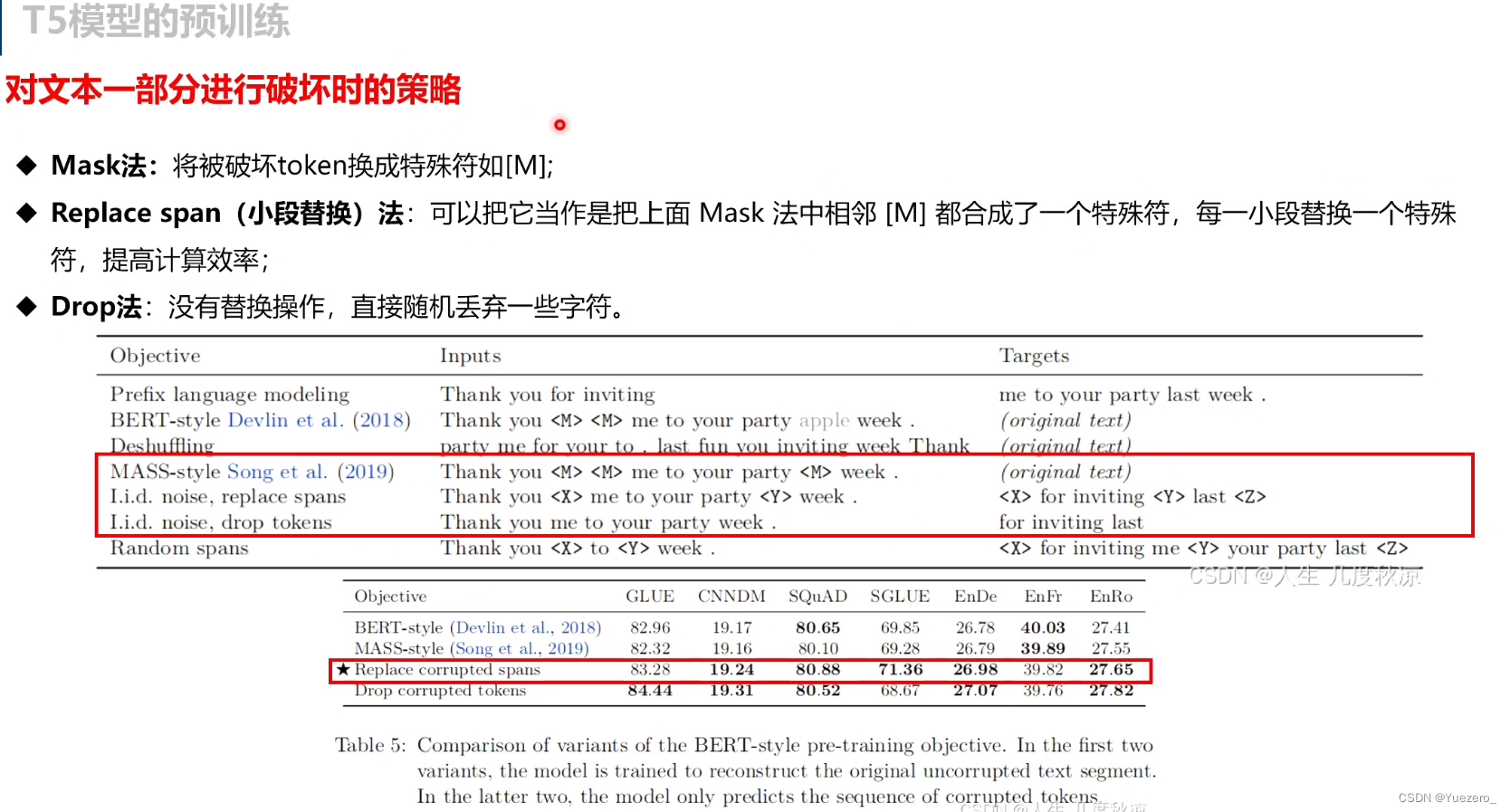
- 不同目标函数比较,BERT-style denoising objective最好;
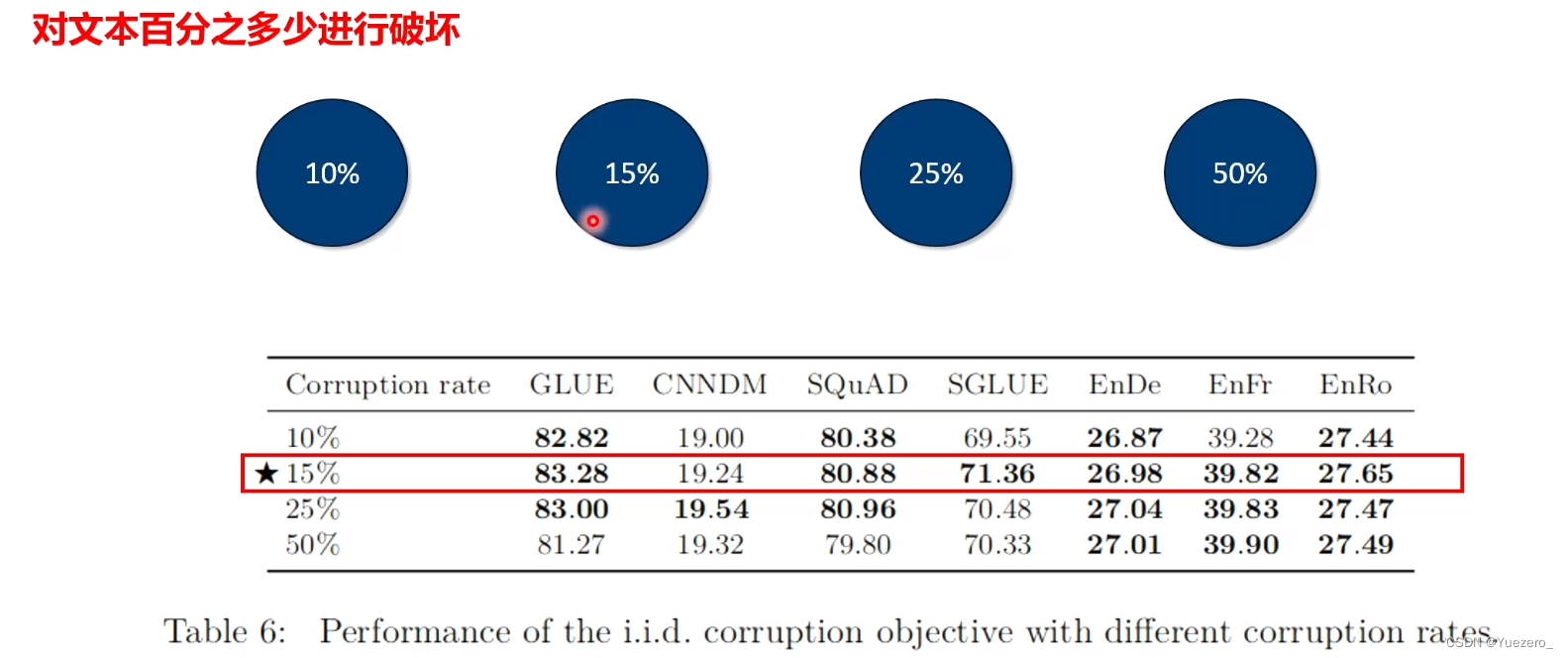
- 不同corruption rate(MLM)比较,10%,15%,25%,50%,15%最好;
- 不同corrupted span length比较,2,3,5,10,长度为3最好;
- 训练集数据重复比较;
- 训练策略比较:先pretrain再fine-tune的multitask learning非常有竞争力,但是需要谨慎选择不同任务训练频次;
- 模型规模比较:比较了不同size的模型(base,small,large,3B和11B),训练时间,以及融合模型,来决定如何充分利用计算性能。
1. Main Body
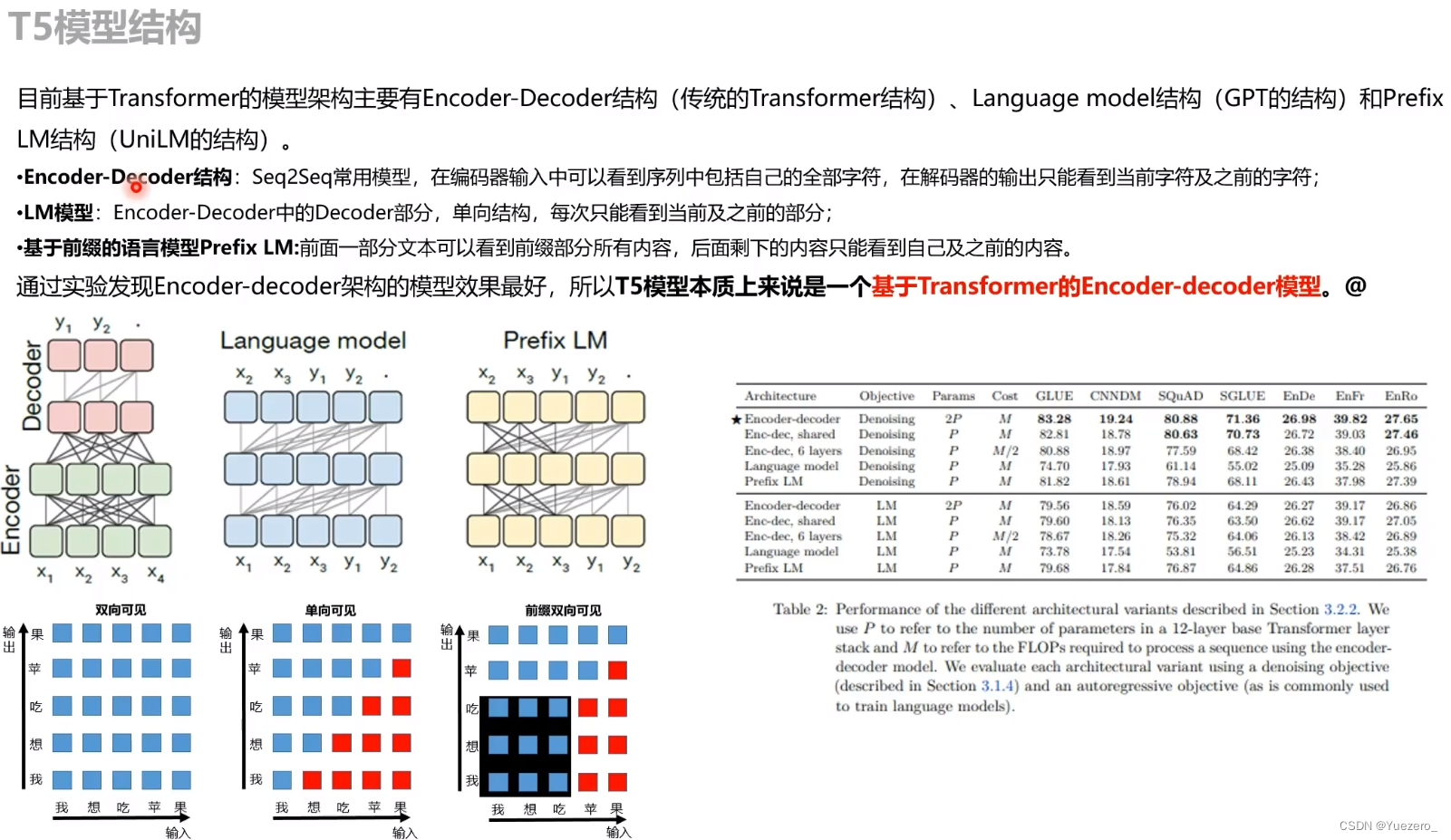
首先作者们先对预训练模型中的多种模型架构(Transformer)进行了比对,最主要的模型架构可以分成下面三种。
三种self-attention:
- fully-visible attention mask:输出序列的每个元素可以看见输入序列的每个元素,如BERT的Encoder结构。
- causal attention mask:输出序列的每个元素只能看对应位置及之前的输入序列的元素,无法看见未来的元素。
- causal with prefix attention mask:输入序列的一部分前缀采用fully-visible attention mask,其余部分采用 causal attention mask。
三种NLP模型结构:
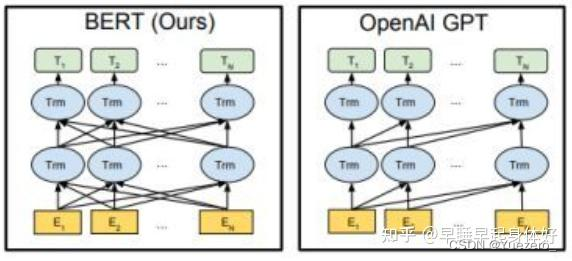
- BERT(NLU):是一个Transformer Encoder结构(双向attention)。把input从文本空间映射到向量空间,Input经过BERT得到每个token对应的hidden vector。通常我们会把第一个特殊token(CLS)的hidden作为整个input的表示(如图上左), 或者把所有tokens’ hidden的avg pooling作为整个input的表示(如上图右)。此时得到我们假设这个vector(图中黄色方块)包含了input的所有信息, 也就是把input从文本空间映射到向量空间。之后我们可以利用这个vector做分类或者生成等下游任务。
- GPT(NLG):是一个Transformer decoder结构(单向attention,从左到右),给定一个向量空间的向量,GPT将会把这个向量映射到文本空间。GPT的主要功能是做生成比如对话生成,给定对话历史在向量空间的vector,GPT可以相应生成文本回复。所以可以理解成我们给定一个向量空间的向量,GPT将会把这个向量映射到文本空间。
- T5(NLU+NLG):不仅仅是BERT+GPT模型,Encoder: 将文本映射到向量空间; Decoder: 将向量映射到文本空间。T5 encoder和decoder间的关联除了上面提到的hidden vector,还有cross attention。并且T5再做NLU任务时也不是仅仅依靠encoder,而是整个模型都参与进来,由decoder直接生成结果。这样一来,T5淡化了中间的hidden vector(通过encoder得到),把encoder和decoder连为一体,这就使得T5的文本表示功能会存疑。
三种语言模型结构:
-
第一种,Encoder-Decoder 型(Transformer),即 Seq2Seq 常用模型,分成 Encoder 和 Decoder 两部分,对于 Encoder 部分,输入可以看到全体,之后结果输给 Decoder,而 Decoder 因为输出方式只能看到之前的。(Encoder-Decoder结构中,Encoder部分采用fully-visible attention mask,而Decoder部分采用causal attention mask)
-
第二种,Language Model型(GPT), 相当于上面的 Transformer Decoder 部分,当前时间步只能看到之前时间步信息。典型代表是 GPT2 还有最近 CTRL 这样的(Language model结构中,采用causal attention mask)
-
第三种,前缀双向可见 Prefix LM 型,可看作是上面 Encoder 和 Decoder 的融合体,一部分如 Encoder 一样能看到全体信息,一部分如 Decoder 一样只能看到过去信息。最近开源的 UniLM 便是此结构。(最右侧的Prefix LM结构中,采用causal with prefix attention mask)
上面这些模型架构都是 Transformer 构成,之所以有这些变换,主要是对其中注意力机制的 Mask 操作。
通过实验作者们发现,在提出的这个 Text-to-Text 架构中,Encoder-Decoder 模型效果最好。于是乎,就把它定为 T5 模型,因此所谓的 T5 模型其实就是个 Transformer 的 Encoder-Decoder 模型(12层Encoder、12层Decoder)。
T5模型和原始的Transformer结构基本一致,除了做了如下几点改动:
- remove the Layer Norm bias
- place the Layer Normalization outside the residual path
- use a different position embedding
2. Embedding
分词:
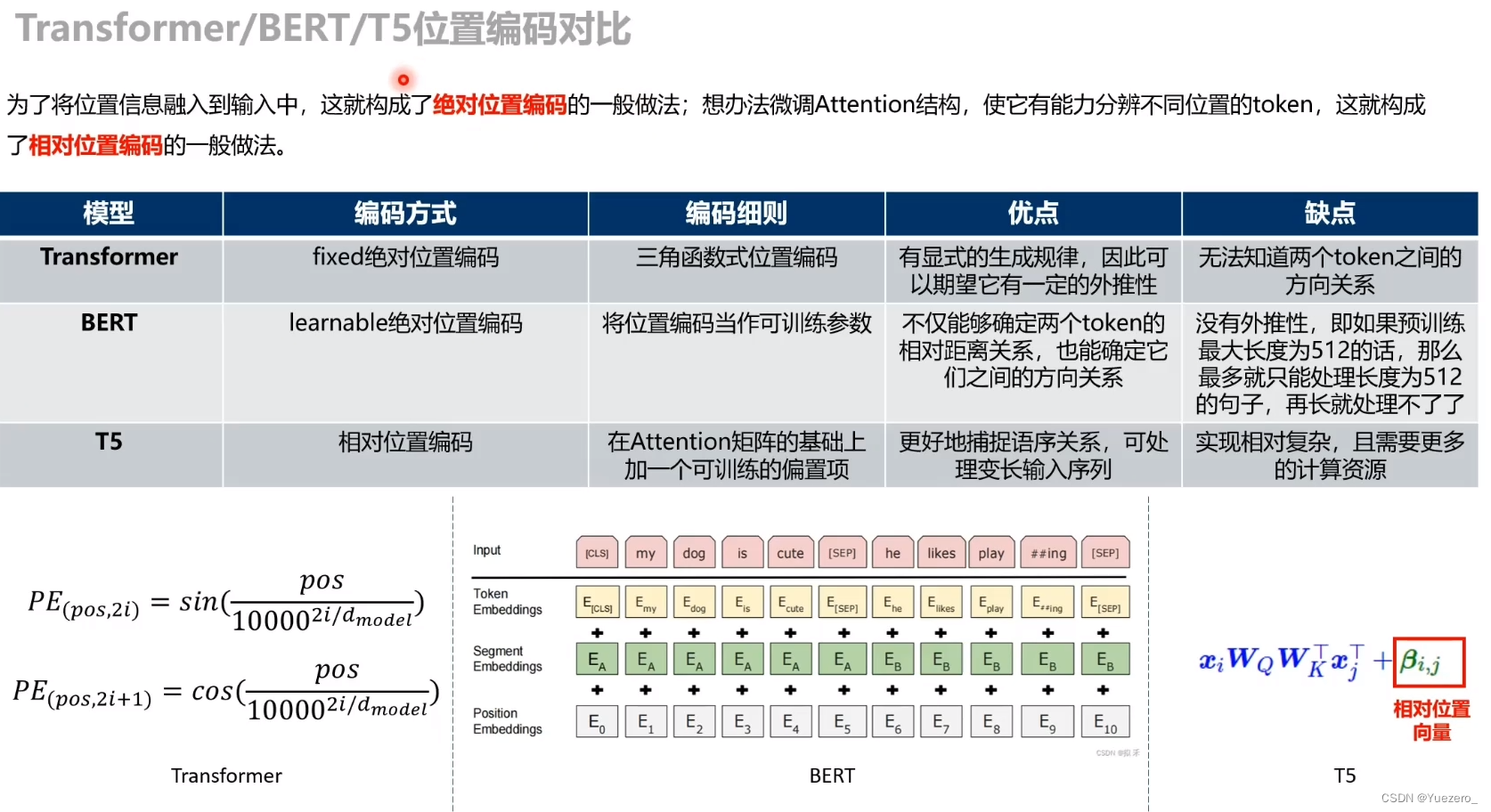
位置编码:相对位置编码

朴素思想解决位置远距离位置编码:为了防止输入序列过长导致位置编码无限增大,设置阈值k限制位置编码增长(类似梯度裁剪)

T5位置编码:

T5的 Position Embedding 在 self-attention 的 QK 乘积之后进行:
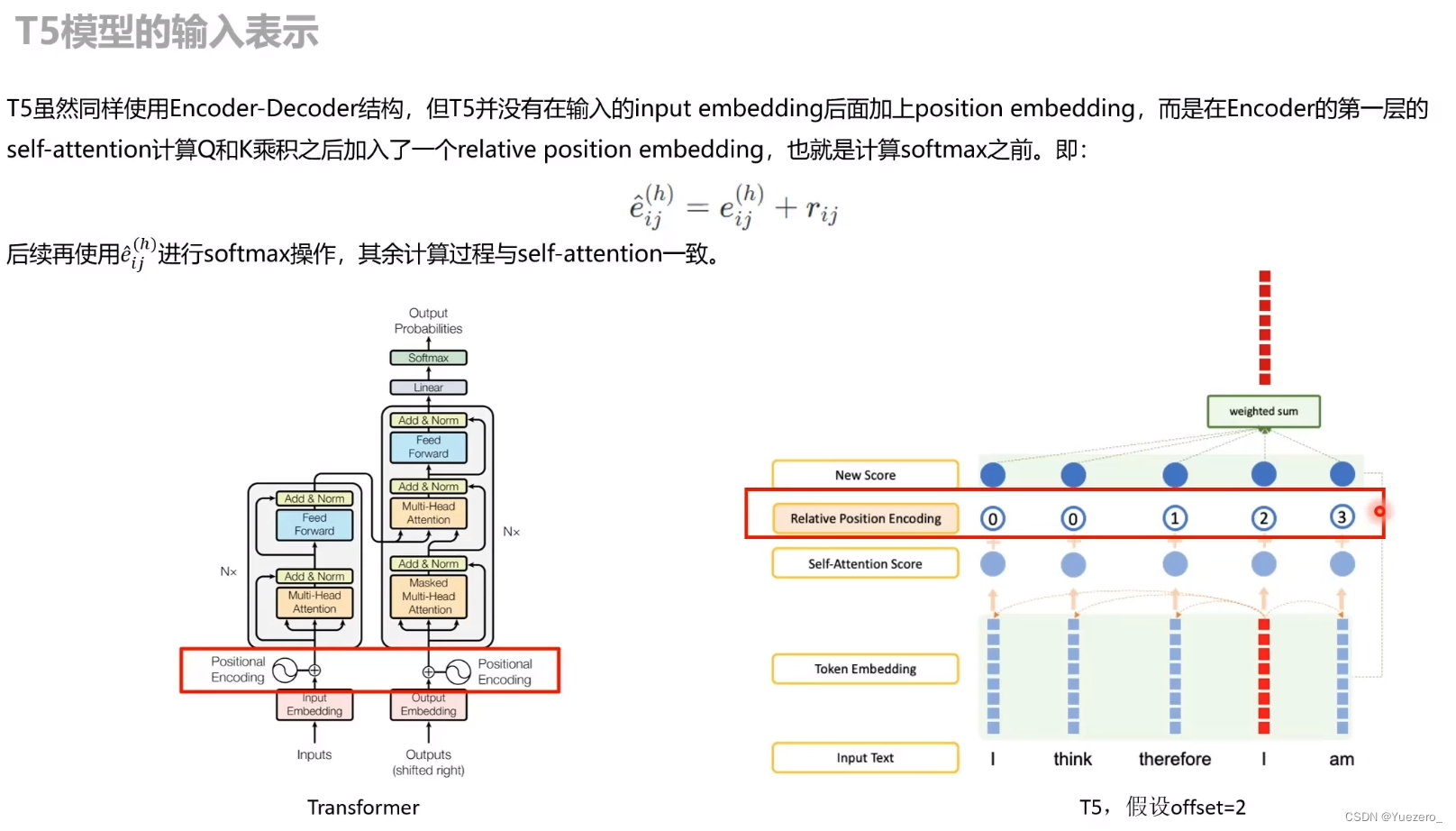
相对位置编码 和 绝对位置编码:
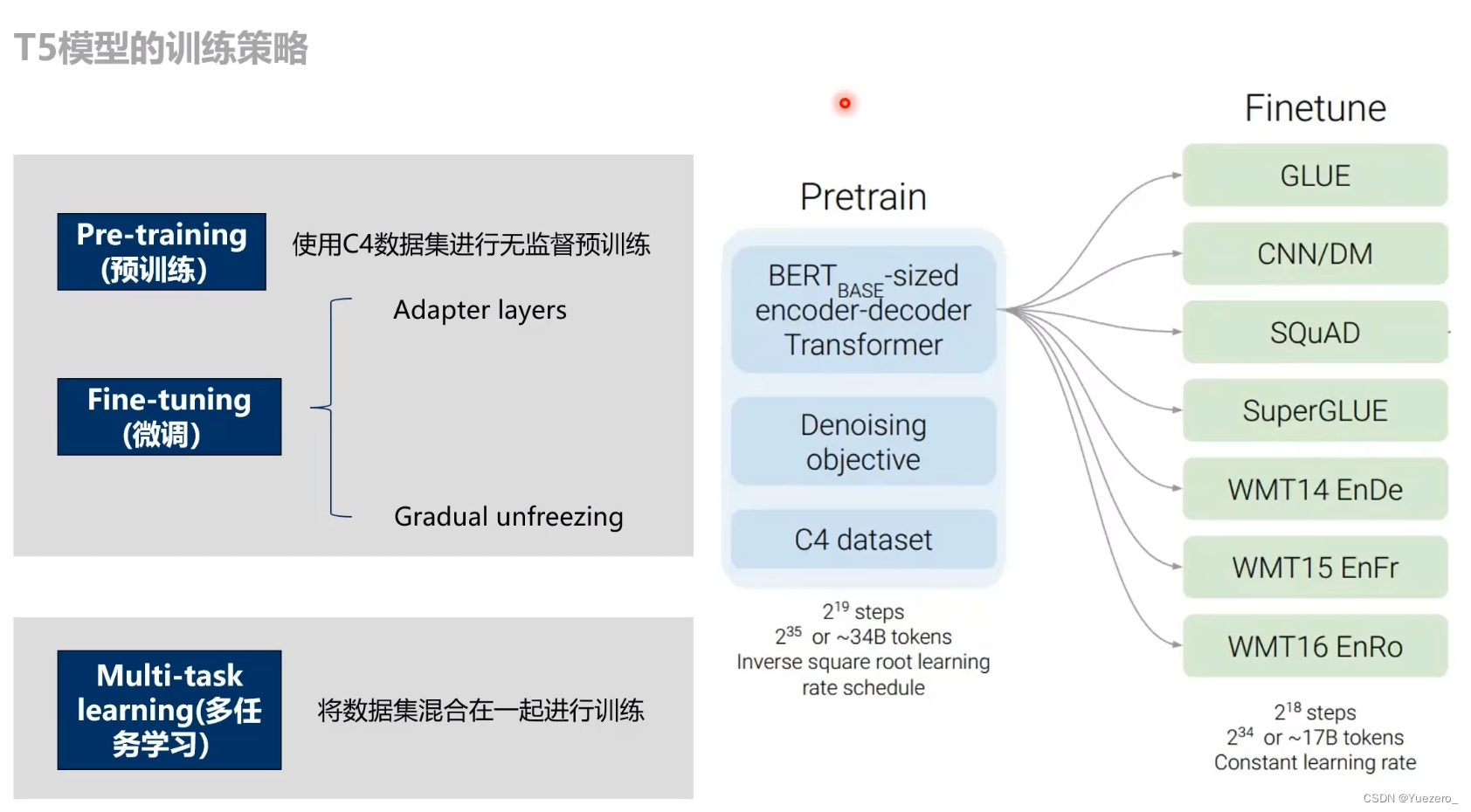
3. Pertrain and Finetune
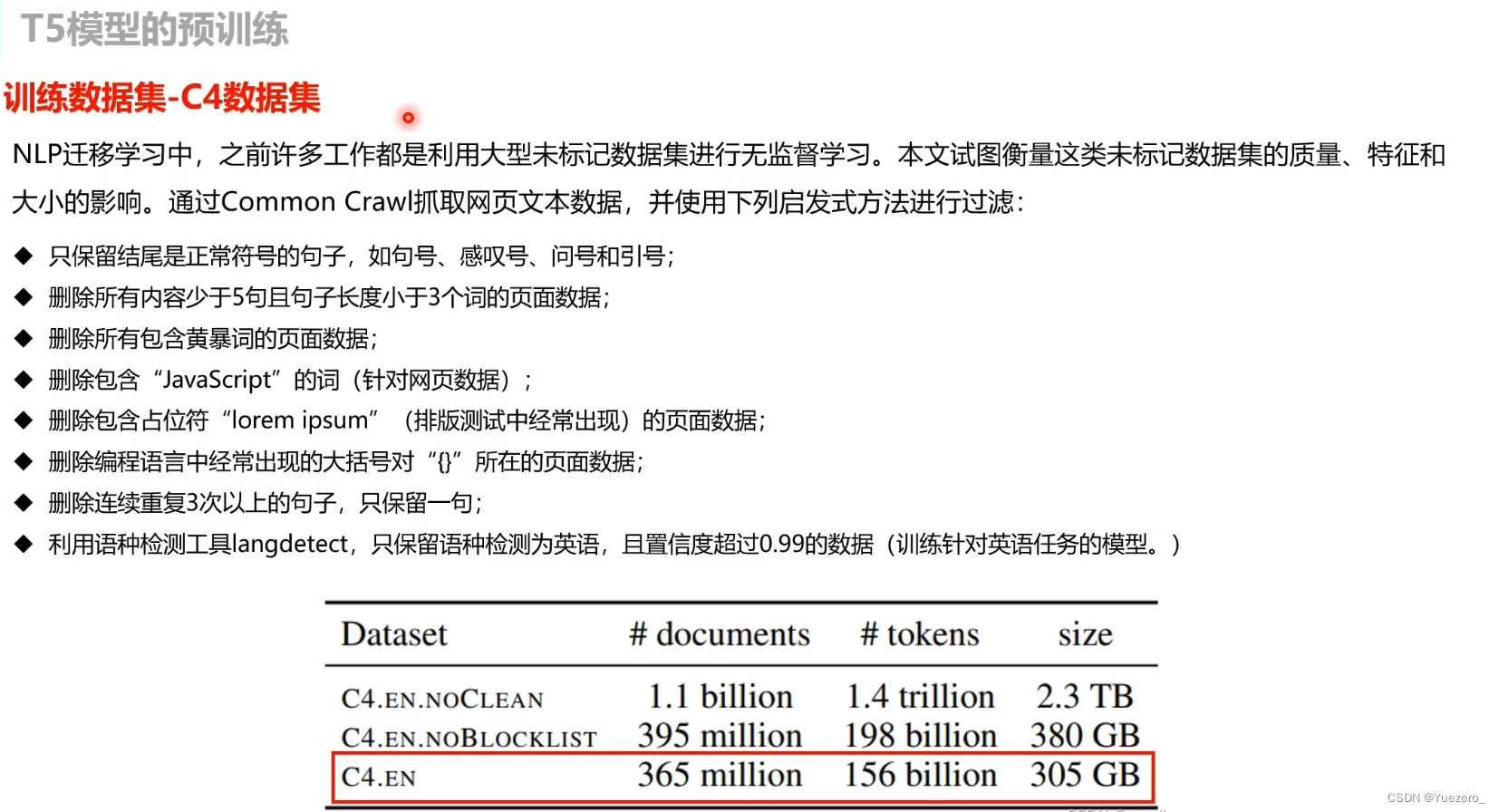
Pertrain dataset:C4
Pertrain :
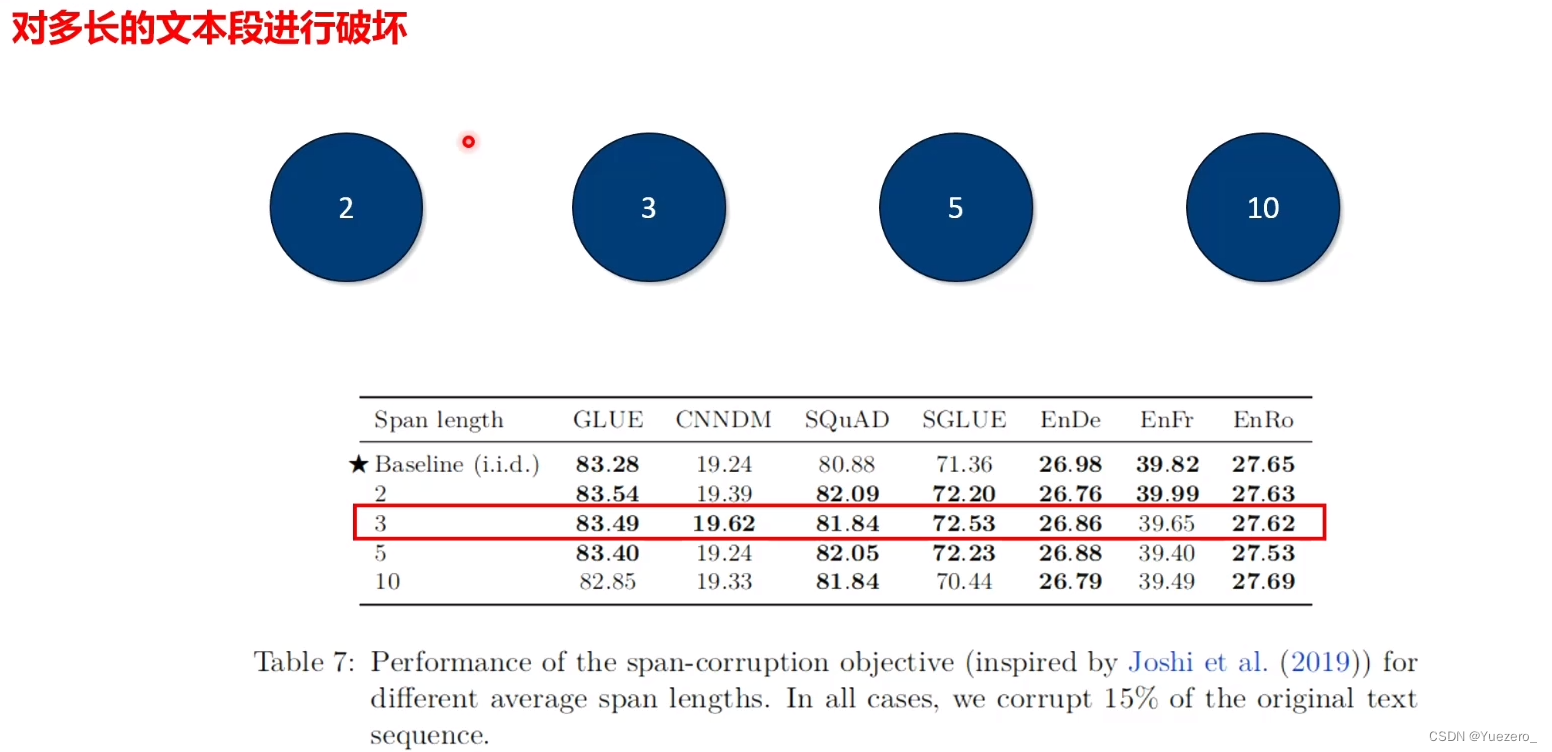
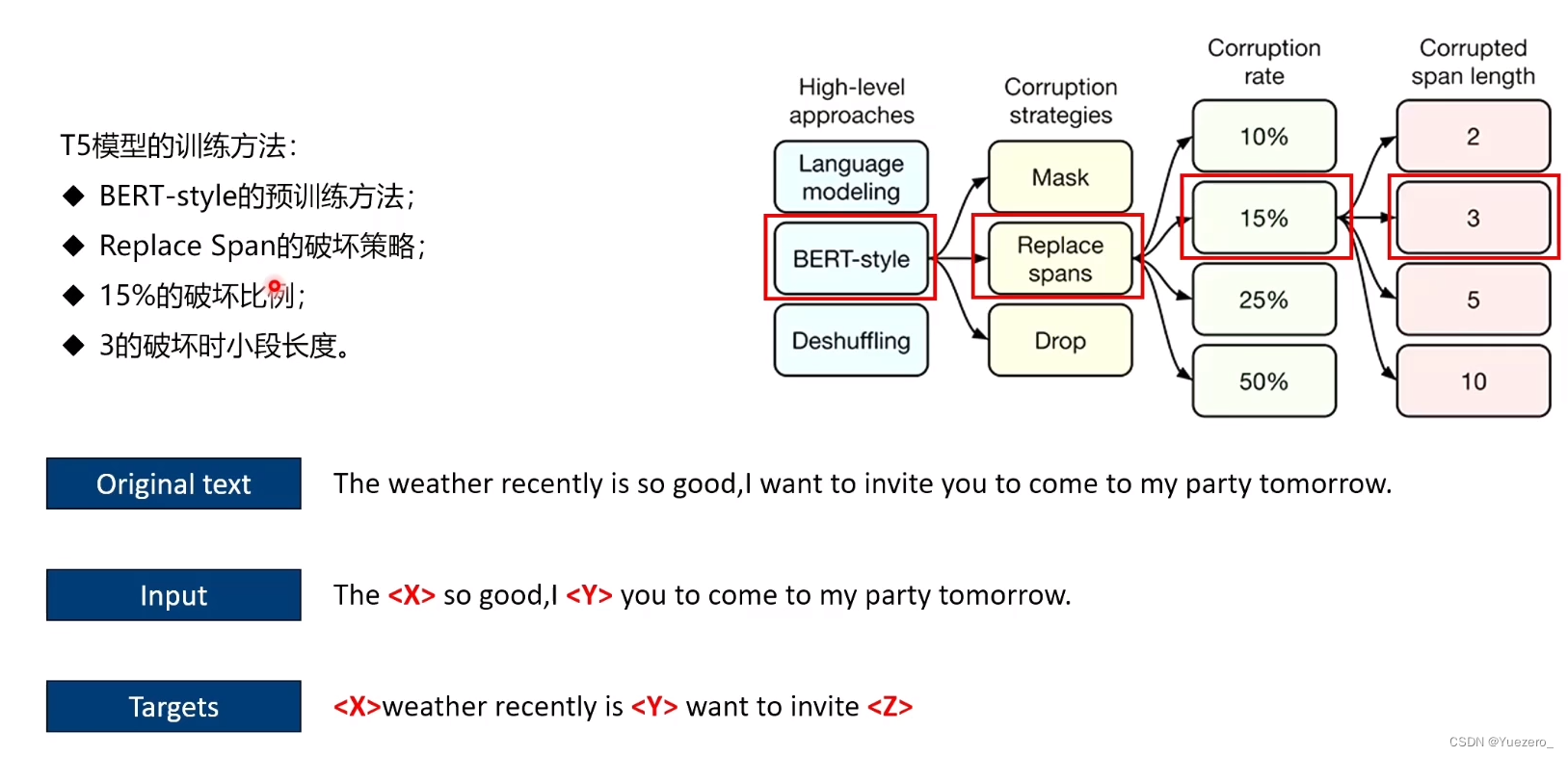
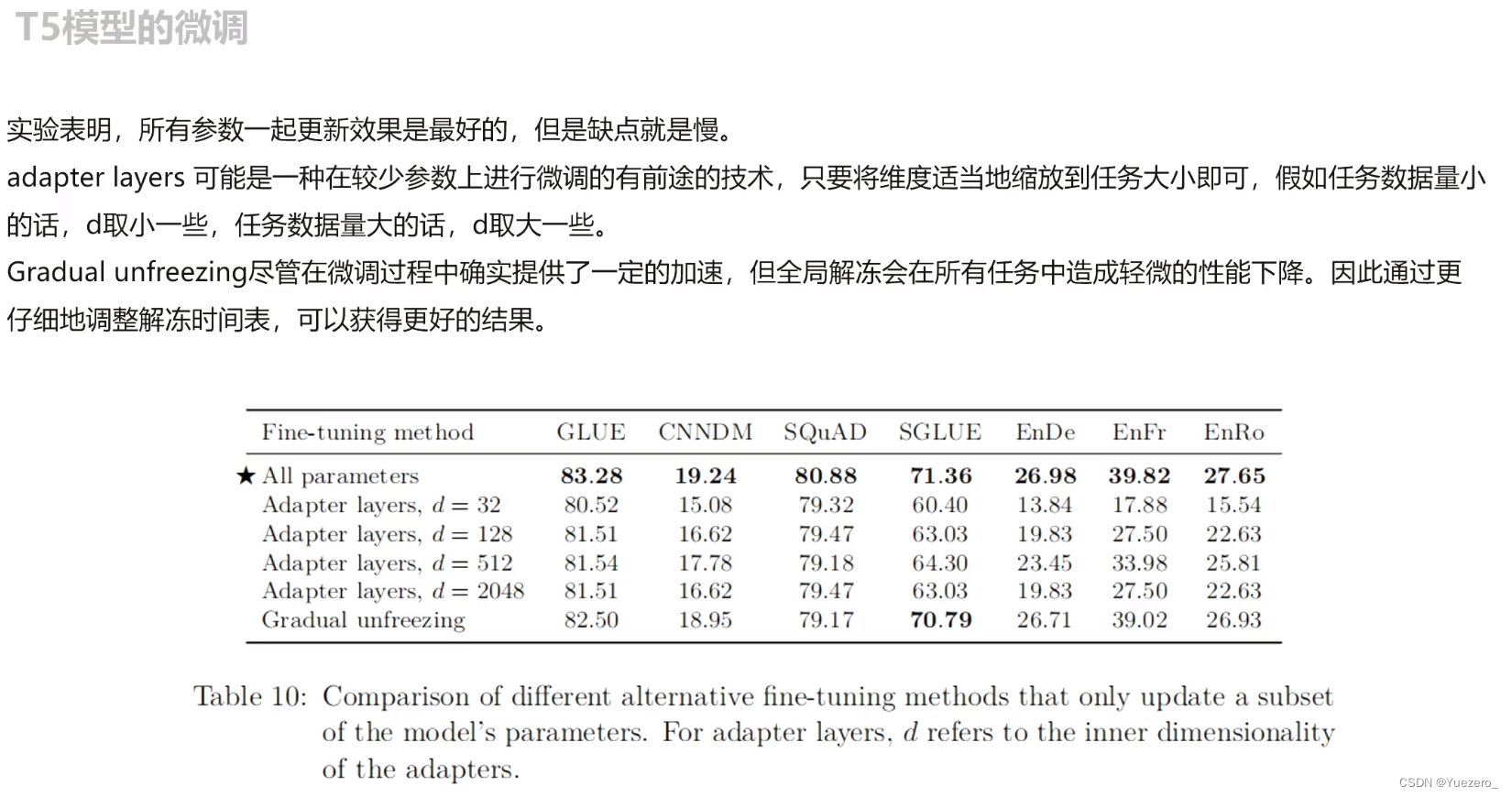
Finetune: T5采用2种微调方法。

不冻结模型训练效果最佳,但缺点是慢!Adapter layers效果比Gradual unfreezing效果更好。
4. Multi-Task Pertrain and Finetune
仅仅多任务训练不微调,效果不如单任务
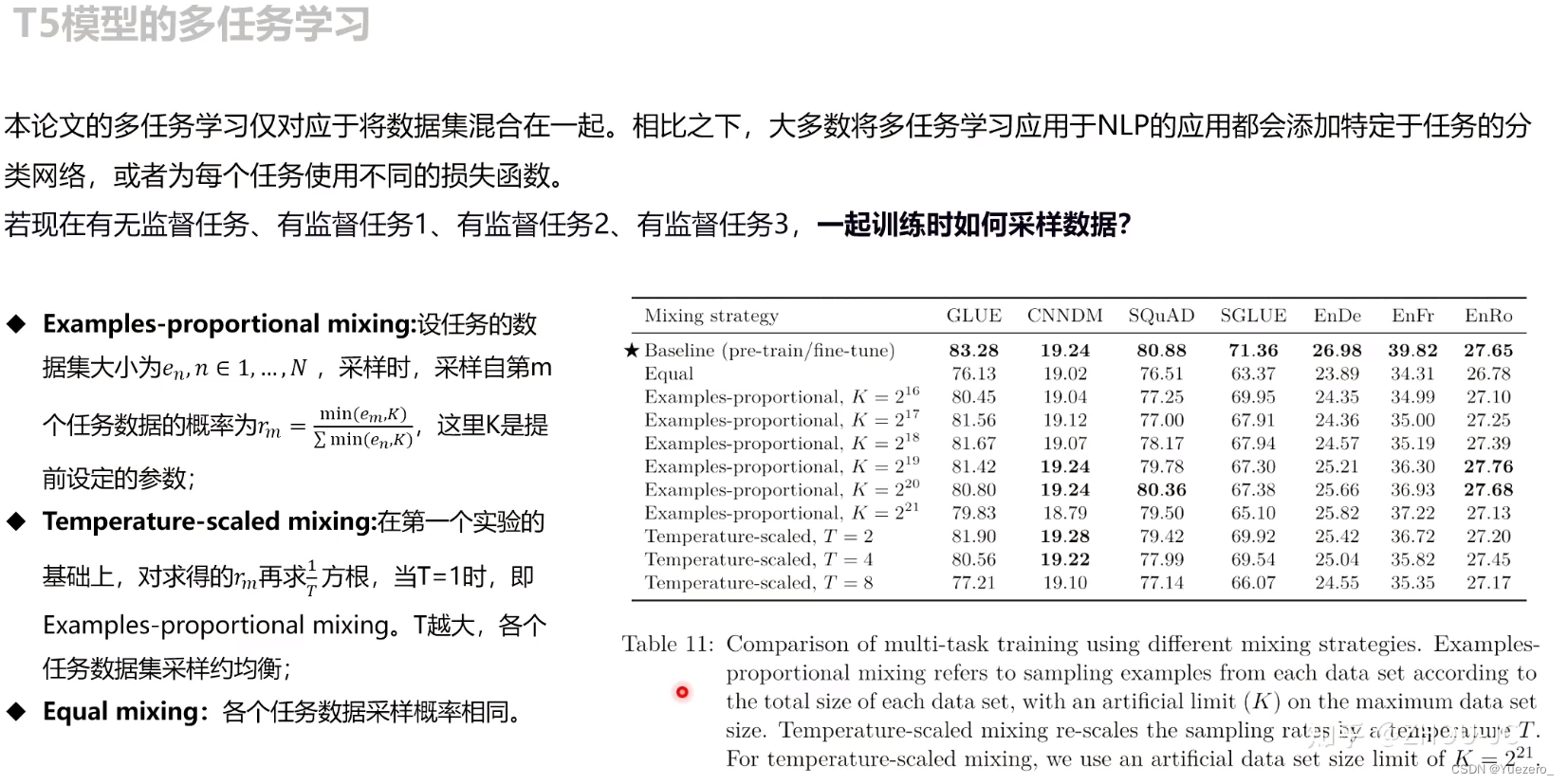
有监督预训练:针对不同的任务设定不同的label进行训练

多任务有监督预训练+微调:
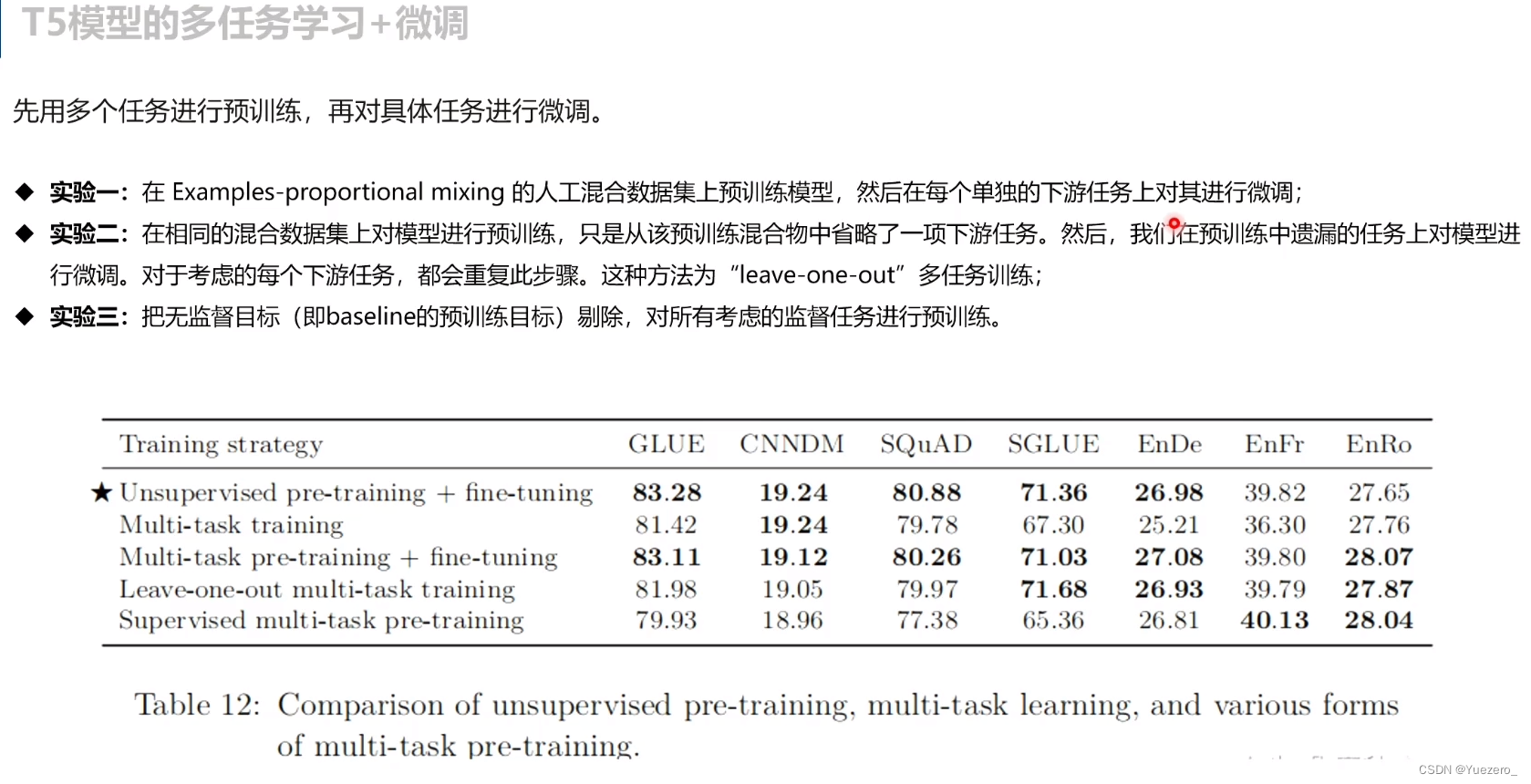
模型规模
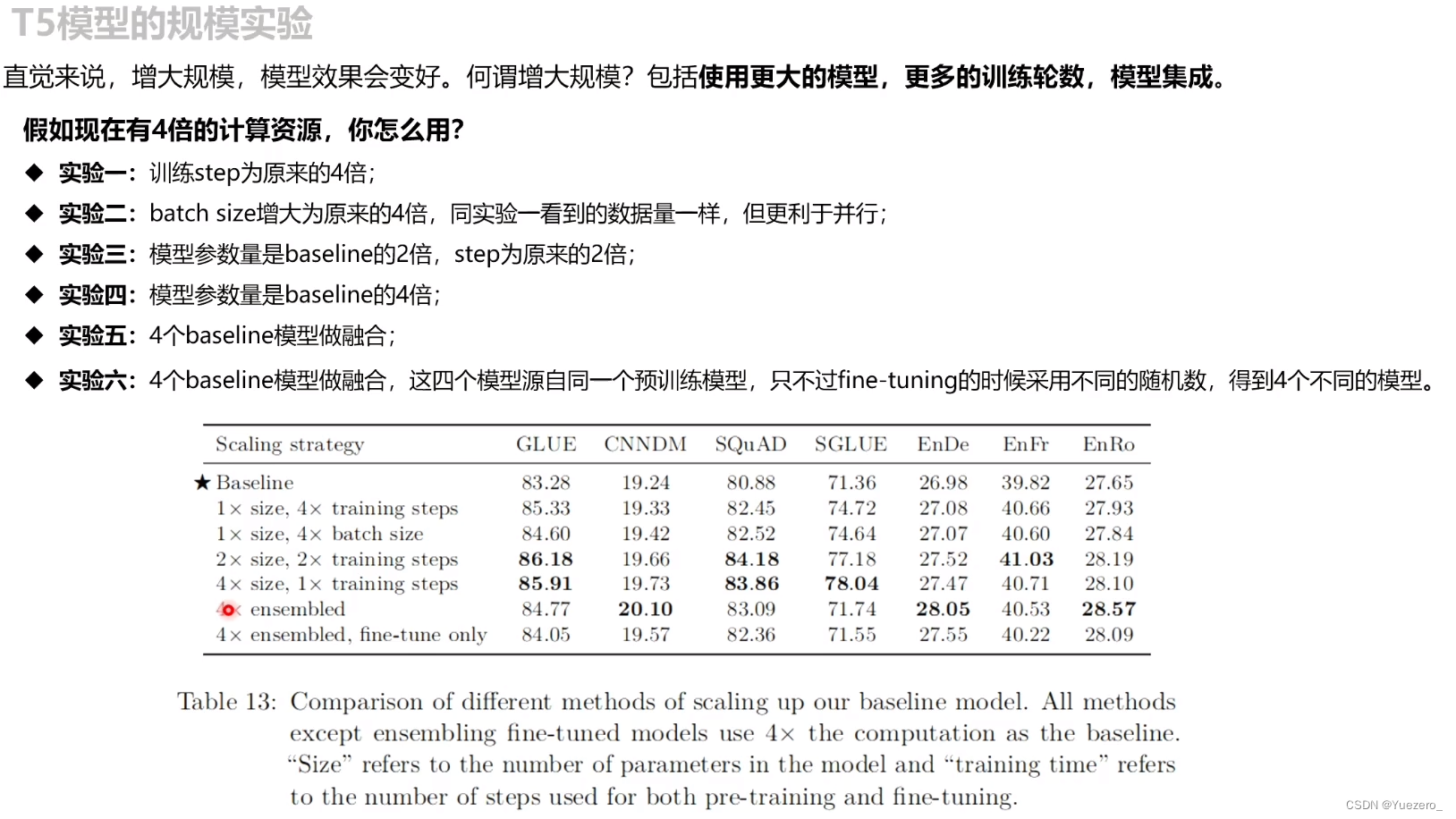
5. T5总结
- 预训练策略:无监督预训练(破坏原sequence的15%,然后进行预测Maks的token)+ 有监督multi-task预训练(针对不同任务数据集分别进行训练)
- 5种模型大小:S、B、L、3B、11B。
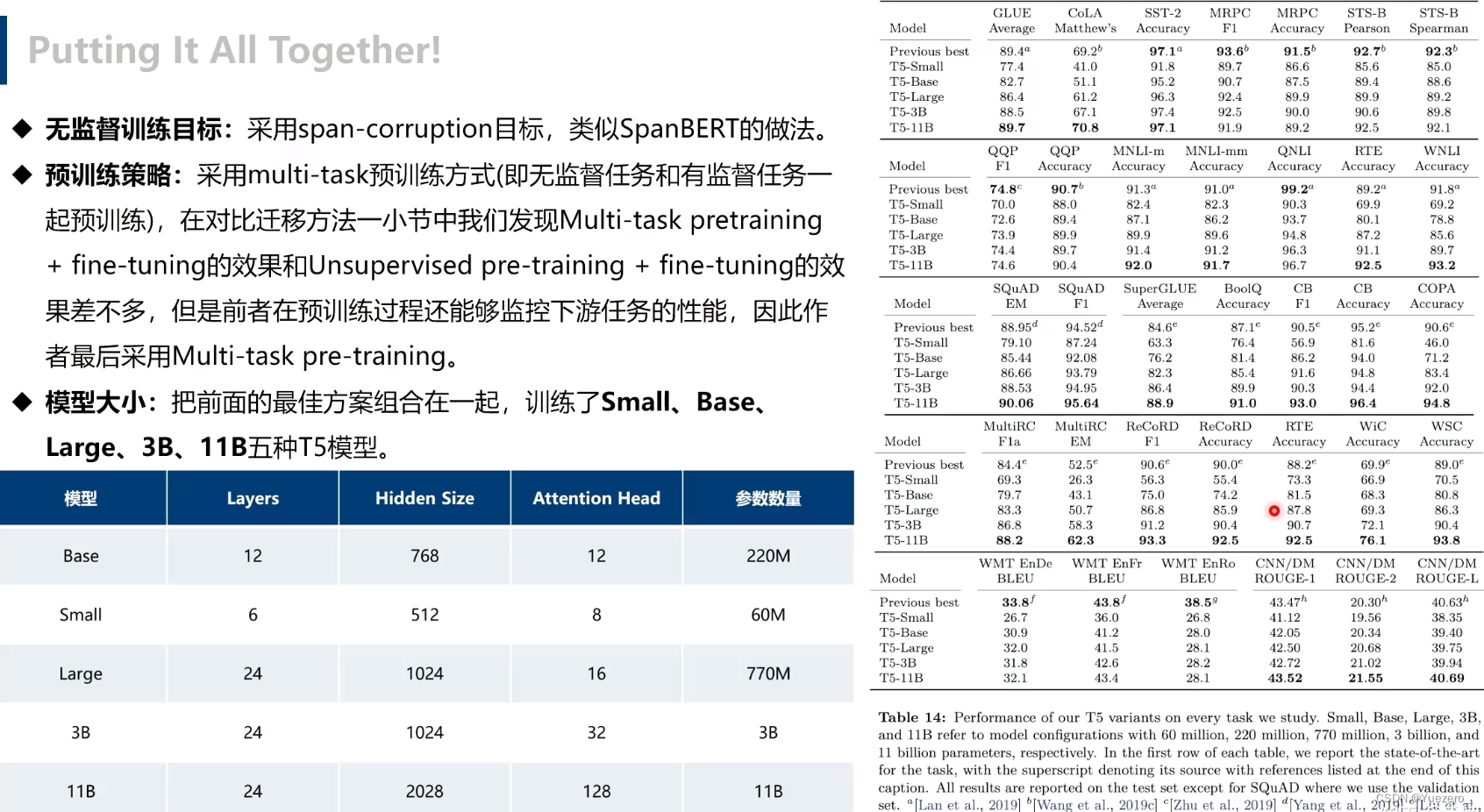
最后就是结合上面所有实验结果,训练了不同规模几个模型,由小到大:
- Small,Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头;
- Base,相当于 Encoder 和 Decoder 都用 BERT-base;
- Large,Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层;
- 3B(Billion)和11B,层数都用 24 层,不同的是其中头数量和前向层的维度。
- 11B,最后在 GLUE,SuperGLUE,SQuAD,还有 CNN/DM 上取得了 SOTA,而 WMT 则没有。看了性能表之后,我猜想之所以会有 3B 和 11B 模型出现,主要是为了刷榜。看表就能发现
比如说 GLUE,到 3B 时效果还并不是 SOTA,大概和 RoBERTa 评分差不多都是 88.5,而把模型加到 11B 才打破 ALBERT 的记录。然后其他实验结果也都差不多,3B 时还都不是 SOTA,而是靠 11B 硬拉上去的。除了 WMT 翻译任务,可能感觉差距太大,要拿 SOTA 代价过大,所以就没有再往上提。根据这几个模型的对比,可以发现即使是容量提到 11B,性能提升的间隔还是没有变缓,因此我认为再往上加容量还是有提升空间。

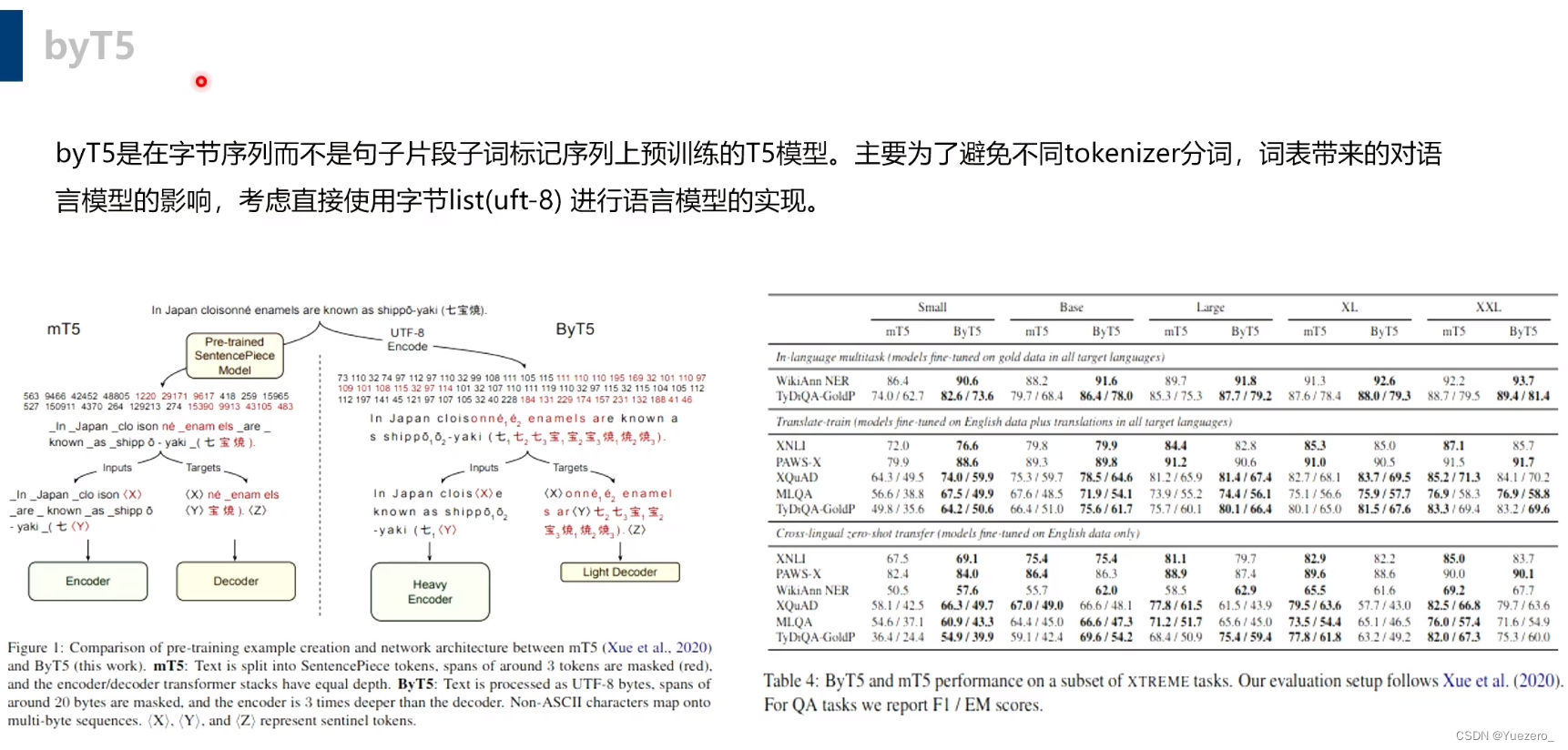

mT5
不幸的是,许多这样的语言模型仅在英语文本上进行过预训练。鉴于世界上大约80%的人口不会说英语,这极大地限制了它们的使用(Crystal,2008年)。 社区解决这种以英语为中心的方法之一就是发布数十种模型,这些模型已经在一种非英语语言上进行了预训练(Carmo等人,2020; de Vries等人,2019; Le等人 ; 2019; Martin等人,2019; Delobelle等人,2020; Malmsten等人,2020; Nguyen和Nguyen,2020; Polignano等人,2019等)。 一个更通用的解决方案是生成,已经在多种语言的混合中进行了预训练的多语言模型。 这种类型的流行模型是mBERT(Devlin,2018),mBART(Liu等,2020)和XLM-R(Conneau等,2019),它们是BERT的多语言变体(Devlin等,2018)。 ,BART(Lewis等人,2019a)和RoBERTa(Liu等人,2019)。
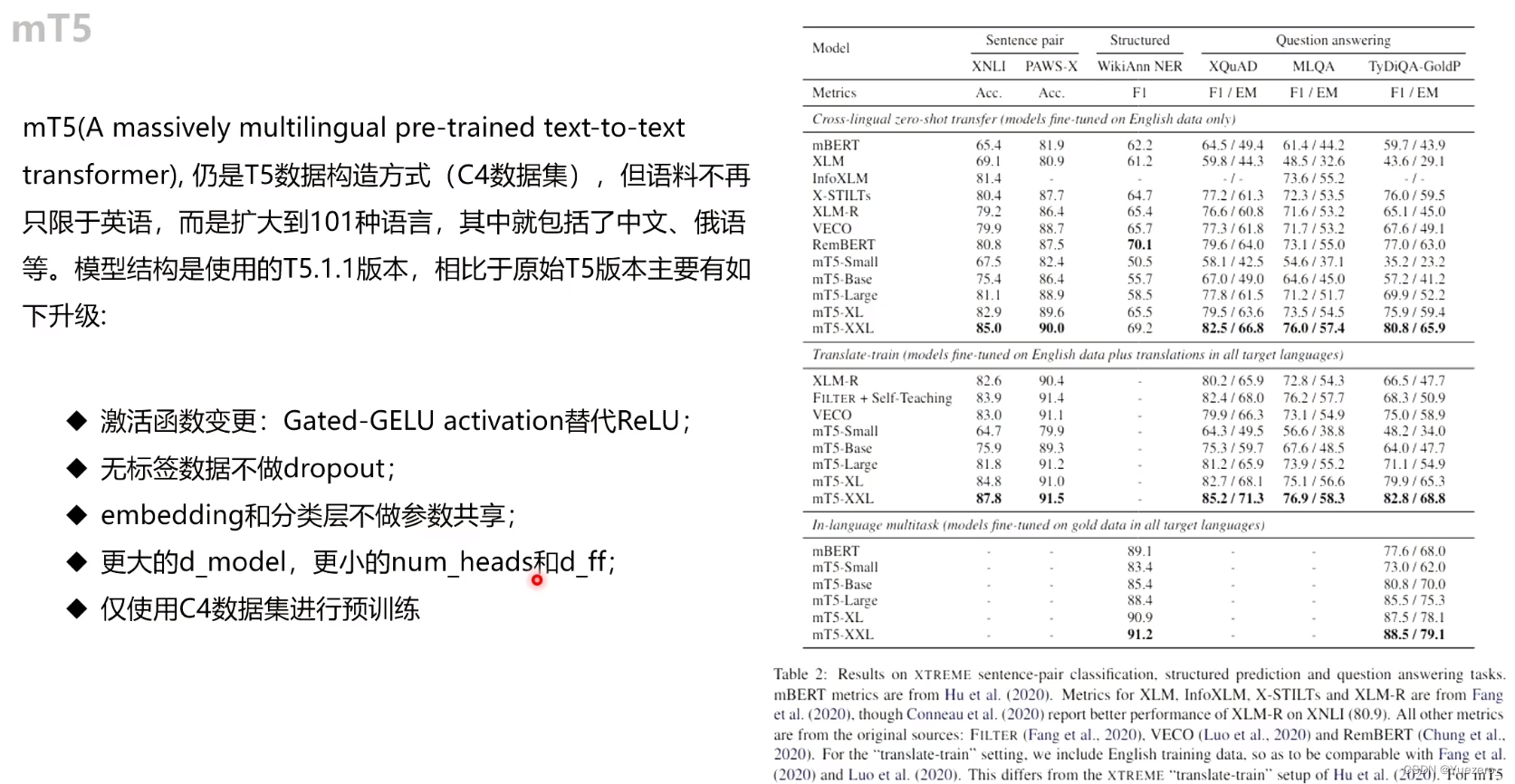
在本文中,我们通过发布mT5(T5的多语言变体)来延续这一传统。 我们使用mT5的目标是生成一个大规模的多语言模型,该模型尽可能少地偏离用于创建T5的方法。 因此,mT5继承了T5的所有优点,例如其通用的文本到文本格式,基于大规模实证研究得出的观点的设计及其规模。 为了训练mT5,我们引入了称为mC4的C4数据集的多语言变体。 mC4包含从公共“Common Crawl”网络抓取中提取的101种语言的自然文本。
具体来说,我们基于“T5.1.1”方法建立了mT5,对mT5进行了改进,使用GeGLU非线性(Shazeer,2020年)激活函数,在更大模型中缩放dmodel而不是改变dff, 对无标签数据进行预训练而没有dropout等措施。 为简洁起见,更多详细信息请参考Raffel et al. (2019)。
预训练多语言模型的主要因素是如何从每种语言中采样数据。最终,这种选择是零和博弈:如果对低资源语言的采样过于频繁,则该模型可能过拟合;反之亦然。如果高资源语言没有经过足够的训练,则该模型将欠拟合。因此,我们采用(Devlin,2018; Conneau et al.,2019; Arivazhagan et al.,2019)中使用的方法,并根据p(L)∝ |L|α的概率通过采样样本来增强资源较少的语言,其中p(L)是在预训练期间从给定语言采样文本的概率和|L|是该语言中样本的数量。超参数α(通常α<1)使我们可以控制在低资源语言上“boost”训练概率的程度。先前工作使用的值,mBERT(Devlin,2018)是α= 0.7,XLM-R(Conneau等人,2019)的α= 0.3,MMNMT(Arivazhagan等人,2019)的α= 0.2。我们尝试了所有这三个值,发现α= 0.3可以在高资源语言和低资源语言的性能之间做出合理的折衷。
我们的模型涵盖了100多种语言,这需要更大的单词表量。 遵循XLM-R(Conneau et al.,2018)之后,我们将单词表量增加到250,000个单词。 与T5一样,我们使用SentencePiece(Kudo and Richardson,2018; Kudo,2018)单词模型,这些单词模型以与训练期间,使用的相同语言采样率进行训练。 为了适应具有大字符集(例如中文)的语言,我们使用0.99999的字符覆盖率,但还启用了SentencePiece的“byte-fallback”特征,以确保可以唯一编码任何字符串。